
 Привет! В прошлый раз мы рассказали о том, как устроена технология понимания и анализа текстов на естественных языках ABBYY Compreno. Многие спрашивают нас – сколько уже можно разрабатывать технологию и где уже, наконец, продукты на базе Compreno. Как и обещали, сегодняшний материал посвящен продуктам и тому, какие именно задачи бизнеса они решают уже сегодня.
Привет! В прошлый раз мы рассказали о том, как устроена технология понимания и анализа текстов на естественных языках ABBYY Compreno. Многие спрашивают нас – сколько уже можно разрабатывать технологию и где уже, наконец, продукты на базе Compreno. Как и обещали, сегодняшний материал посвящен продуктам и тому, какие именно задачи бизнеса они решают уже сегодня.На основе нашей технологии можно создать ряд решений для разного типа задач. Но фокус нашего внимания сегодня – это корпоративный рынок, компании, которым необходимо в сжатые сроки получать значимую информацию из массивов данных. Это направление перспективно для нас и с точки зрения востребованности таких технологий клиентами, и с точки зрения скорейшего возврата наших инвестиций в технологию.
Сразу отметим, что решения на базе технологии Compreno – это аппликационные или технологические модули, которые встраиваются в любые решения, добавляя им возможности. Например, решения на базе Compreno могут использоваться вместе с технологией для потокового ввода данных ABBYY FlexiCapture.
Извлечь всё. ABBYY InfoExtractor SDK
Документы любой организации содержат важную для бизнеса информацию, например, персоны, организации, даты, события и другие существенные факты. C помощью нашей технологии можно выделить в тексте конкретные объекты и установить связи между ними. Для этой задачи мы сделали ABBYY InfoExtractor SDK.
Например, ABBYY InfoExtractor SDK может автоматически решать такую актуальную для многих организаций задачу, как распределение платежей по статьям выплат. Поле «Назначение платежа» в счете описывает в свободной форме, от кого и за что поступил платеж, а также его период. Соответственно, эту информацию необходимо отразить в учетной или биллинговой системе, что отнимает много времени у сотрудников бухгалтерии. Решение ABBYY InfoExtractor SDK «понимает» смысл написанного в счете, а затем извлекает необходимые данные: номер договора, организацию-плательщика, сумму, НДС и др. Затем эти данные можно передать в ERP-систему или биллинговую систему для последующего учета бухгалтерией и контроля дебиторской задолженности. Таким образом, конечное решение может автоматически сравнивать извлеченные данные с базой договоров и «привязывать» заказы к платежному документу, сравнивать значения НДС в назначении платежа с НДС, указанным в договоре.
За счет автоматизации извлечения данных о заемщике из предоставленных банку материалов ABBYY InfoExtractor SDK также позволяет, например, оптимизировать процесс оценки рисков при выдаче кредитов. А это очень актуально для банков. Банковским специалистам необходимо своевременно получать полную и качественную информацию о заемщиках (физических и юридических лицах) для принятия решения о выдаче кредита, а также для оперативной реакции на финансовые проблемы клиентов.
Решения, в которые интегрирован ABBYY InfoExtractor SDK могут:
• Проанализировать информацию о потенциальном заемщике для оценки его платежеспособности, а также о связанных с ним лицах и организациях (для оценки дополнительных рисков или источников финансирования). Для получения полной картины о заемщике, может быть проанализирована как информация из различных информационных систем банка — электронное досье клиентов, АБС и прочее, так и с внешних ресурсов — сайт Высшего арбитражного суда, сайты службы судебных приставов, судов общей юрисдикции, из СМИ и социальных сетей.
• Проверить на соответствие однотипные данные из различных источников (это позволяет выявить риски фальсификации документов).
• Проанализировать состояние объектов залога: стоимость, расположение, факты обременения или ареста и прочие факторы;
Таким образом можно создать решение, которое будет отслеживать важную информацию о деятельности заемщика.
Как ABBYY InfoExtractor SDK решает эту задачу?
Решение структурирует текст, выделяя сущности (даты, объекты, персоны и т.д.) и их свойства. После извлечения всех сущностей, решение выделяет из них все необходимые данные и строит связи между ними. На основе этих связей строится карточка потенциального заемщика со сводным риск-профилем по всей базе судебных решений:
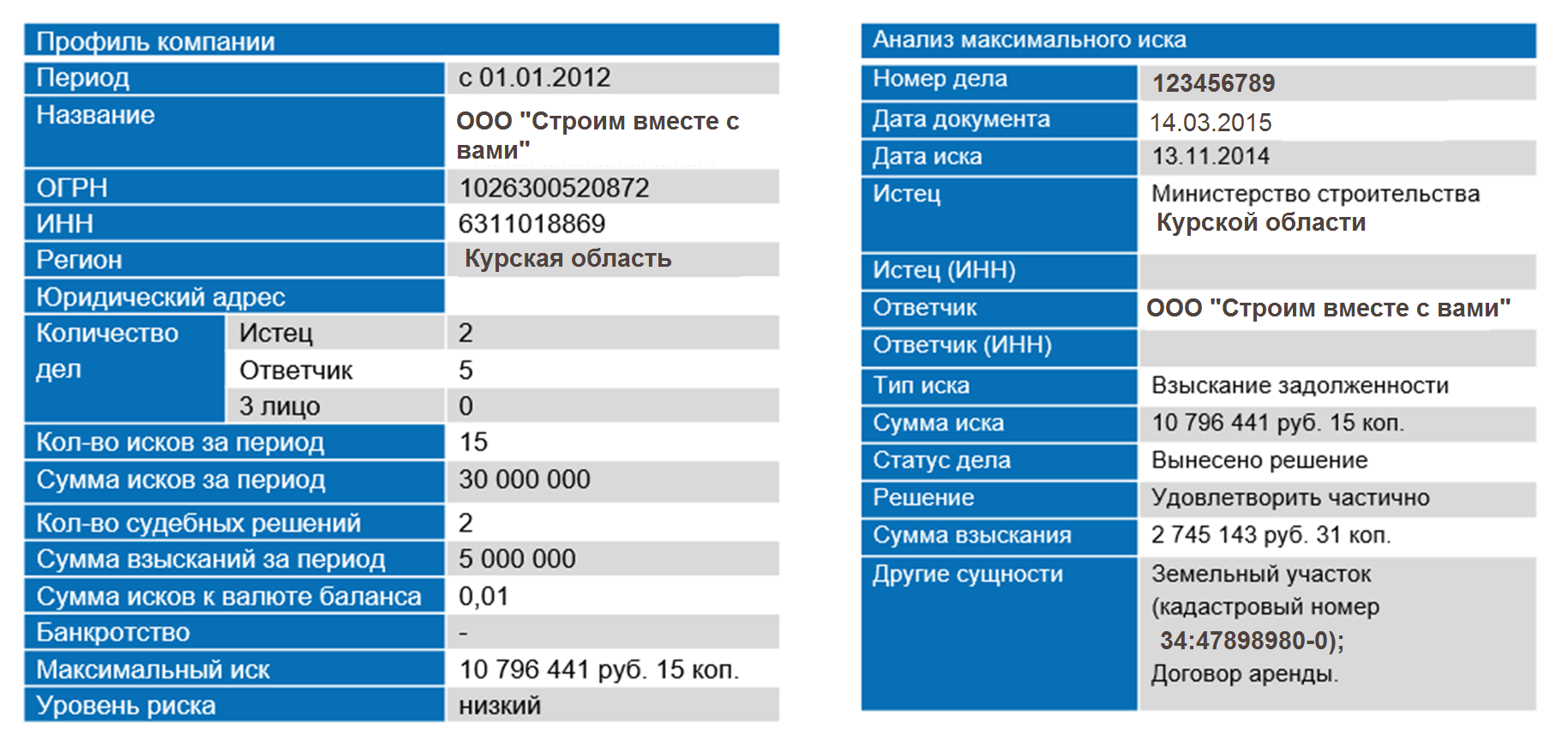
Еще одна немаловажная задача, которая стоит перед банками, – мониторинг сделок для противодействия финансированию терроризма и отмыванию доходов, полученных преступным путем. По требованию российского законодательства банки обязаны быстро устанавливать экономический смысл операций и сделок. Если возникают подозрения, что операция направлена на финансирование террористической деятельности, банки должны оперативно направлять сведения о нарушении в уполномоченные органы.
В рамках этой задачи сотрудникам банков необходимо анализировать большой поток неструктурированных документов – договоров, чтобы занести в ИС Банка данные о плательщиках, суммах, предмете договора и т.д. Доступ к этой информации могут в любой момент запросить контролирующие органы, и банкам нужно очень оперативно ее предоставить, не допуская при этом ошибок в данных. ABBYY InfoExtractor SDK позволяет выполнять эту задачу автоматически: решение определяет тип договора, понимает, какие именно данные необходимо извлечь из текста документа. Также возможно извлекать комплексные связи, когда два и более однотипных объекта (например, объекты недвижимости) со своими атрибутами (тоже однотипными, например, площадь, цена и пр.) разбросаны по тексту документа. После обработки все эти данные экспортируются в целевую ИС.
Также ABBYY InfoExtractor SDK может помочь оперативно обрабатывать запросы государственных органов, поступающие в кредитные организации. Можно создать решение с интегрированным в него модулем InfoExtractor, которое будет анализировать информацию, автоматически создавать карточки запросов и предоставлять быстрый доступ к этим данным. Наличие полной информации позволит контролировать сроки рассмотрения запросов и соблюдать требования по исполнительным листам. Кроме того, значительно сократится время на обработку документов.
Теперь пара слов о внедрениях ABBYY InfoExtractor. Пара – потому что клиенты, к нашему сожалению, пока не готовы раскрывать публично подробности проектов. Одна из крупнейших российских нефтяных компаний решает с помощью ABBYY InfoExtractor задачу формирования аналитических отчетов и поиска дубликатов документов в корпоративной информационной системе.
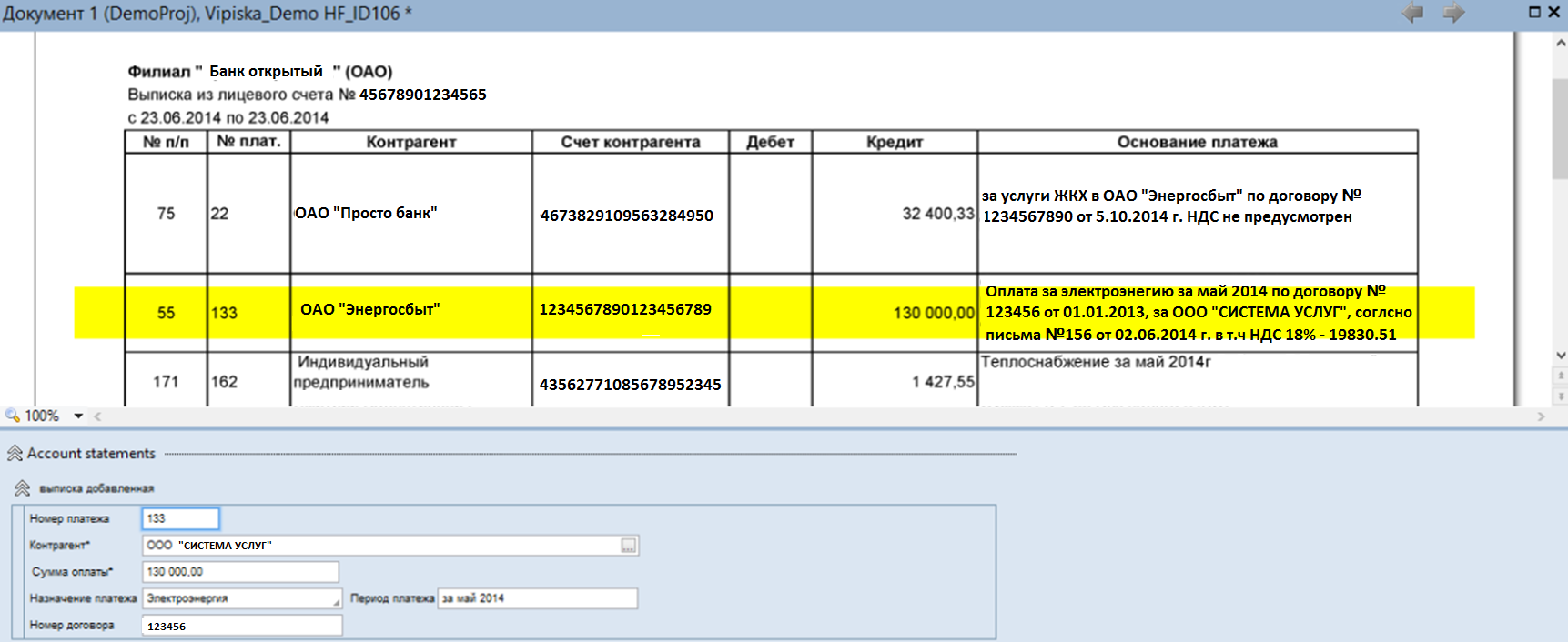
Крупная энергетическая компания использует интеграционное решение ABBYY FlexiCapture+ InfoExtractor для распределения платежей в биллинговых системах. В платёжных документах (см. иллюстрацию ниже) есть графа «Назначение платежа» – в неё вписана информация, позволяющая соотнести платеж с конкретным договором, клиентом, обязательством. «Понимание» сущностей, обозначенных в этом поле, а также связанных с ними деталей упрощает дальнейшую обработку документа, и ускоряет важные для компании бизнес-процессы.
Классифицируй это. ABBYY Smart Classifier
Основная задача ABBYY Smart Classifier – классификация текстов и документов по содержанию. Надо сказать, в наших продуктах и раньше был инструмент для классификации документов. В ABBYY FineReader Engine, ABBYY FlexiCapture Engine и ABBYY FlexiCapture классификатор разделяет документы и по внешнему виду, и по содержанию (подробнее об этом мы писали в нашем блоге раньше). Однако принцип работы ABBYY Smart Classifier с текстом существенно отличается от того, как это сделано в предыдущих продуктах.
ABBYY Smart Classifier «читает» текст, чтобы из слов, предложений и общего контекста понять, о чем этот документ и к какой категории его отнести. В решении есть два типа классификации: семантическая – для русского и английского языков, текстовая – для 42 других языков. И в том и в другом случае сначала классификатору даётся обучающее множество (например, 10 категорий по 50 текстов в каждой, которые мы сами заранее разложили по этим категориям и присвоили название каждой из них).
Классификатор анализирует каждую категорию, из каждого текста в группе выделяет признаки: слова, словосочетания, семантические классы, которые определяются на основе нашей иерархии (здесь работает у нас парсер, о котором мы писали в прошлой статье о Compreno) и определяет частотность этих признаков. После извлечения признаков классификатор строит модель, которая описывает, какие признаки отличают каждую из категорий друг от друга. Такой классификатор способен разрешать омонимию и более глубоко анализировать текст, ему для хорошего результата нужно значительно меньше документов в обучающей выборке, чем исключительно морфологическому.
Когда после обучения на классификацию приходит новый документ, ABBYY Smart Classifier также извлекает признаки из этого документа, примеряет на него модель для каждой из категорий, смотрит, с какой категорией новый текст лучше совпадает. На выходе получается ответ примерно следующего вида: «Документ 1 относится к категории А на 60%, к категории Б на 35%, к категории С на 5%). В дальнейшем на основе этих результатов разработчики могут писать свои правила, определяющие, в какую категорию записывать документ: просто по наибольшему проценту или при превышении какого-то порога (например, если классификатор определил принадлежность к категории А на 80 и более процентов) и т.п. Решение точно определяет категорию документа на основе смысла текста.
Области применения ABBYY Smart Classifier могут быть различными. Решение на базе нашей технологии позволяет автоматически классифицировать запросы от пользователей и, в частности, и обращения в техническую поддержку (неважно, поданы ли они в электронном виде или в бумажном) в различных системах документооборота или почтовых системах и направить их ответственному подразделению или специалисту. Решение автоматически определяет категорию входящего запроса, на основе анализа его содержания (это решение, например, использует Госдума в проекте «Электронный парламент» при классификации входящих обращений граждан).
Далее на основе категории, опять же в автоматическом режиме, можно осуществлять поиск информации об инциденте в базе знаний и сразу предлагать имеющийся ответ пользователю. За счет такой автоматизации сроки обработки входящих сообщений и нагрузка на специалистов существенно сокращаются.
Кроме того, решение, использующее наш классификатор, позволяет без привлечения специалиста технической поддержки на основе обращения высылать пользователю автоответ. В этом сообщении содержится несколько ссылок на наиболее релевантные статьи базы знаний, которые могут решить проблему клиента.
Найти только нужное. ABBYY Intelligent Search
Сотрудники многих компаний ежедневно сталкиваются со сложностями в поиске необходимых документов – от договоров до писем. Часто мы помним только суть документа, но забыли его название или дату. В таком случае поиск нужной информации затягивается, и работа совсем не движется. С этой проблемой позволяет справиться ABBYY Intelligent Search – решение, которое можно встроить в корпоративную систему, и таким образом расширить и дополнить ее возможности.
ABBYY Intelligent Search ищет документы по смыслу, учитывая не только все формы слов, но и их значения, смысловые связи между словами и контекст употребления. Это достигается за счет системы ранжирования и полного семантико-синтаксического анализа текста, о котором мы писали в предыдущем посте. Все это делает решение более эффективным по сравнению с традиционными системами полнотекстового поиска. Сейчас пилотный проект с использование Intelligent Search запущен в Т ПЛЮС ГРУПП.
Как работает ABBYY Intelligent Search в корпоративной информационной системе?
Шаг первый: запускаем индексацию, то есть делаем полный семантико-синтаксический анализ всей коллекции документов (например, финансовых). Так мы получаем «индекс» – информацию о каждом слове и его значениях, о том, как это слово связано с другими, а также в каких документах оно находится. На этом же этапе происходит извлечение данных. Автоматически собираются метаданные (автор, дата создания) и находятся в тексте документов сущности (названия организаций, персон, геообъекты, даты и денежные суммы). Эти метаданные сохраняются вместе с информацией о тексте документов и могут дополнять документы (например, в MS Share Point они сохраняются в поле «теги»), чтобы потом с ними было проще работать: классифицировать, сортировать или фильтровать.
Шаг второй: начинаем поиск. Так как у нас вся информация проиндексирована, мы можем задать параметры поиска, указав нужное значение слов в запросе и выстроив фильтры. Пользователь может выбрать, хочет ли он найти среди документов, например, слово «application» в значении «software», «request» или «use». Пользователь может задать запрос на естественном языке: например, «обязанности руководителя предприятия» и получить документы, близкие по смыслу к запросу. К примеру, документ, в котором будет вот такое предложение: «Расследование велось также в отношении еще ряда городских чиновников Дуйсбурга, менеджера компании Lopavent, который отвечал за пропуск гостей на мероприятие, а также тогдашнего руководителя оперативными действиями полиции».
Также мы можем искать информацию, используя «фасеты» — наиболее важные и часто встречающиеся атрибуты документа, сформированные на основе метаданных документа, извлеченных из него сущностей (т.е. список всегда конкретный), которые можно использовать для фильтрации коллекции: упомянутые персоны, географические объекты и даты.
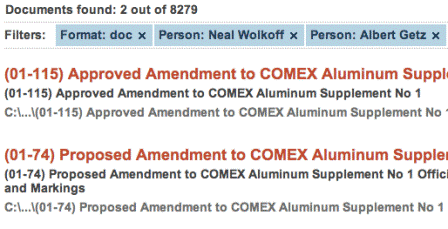
Шаг третий: пользователь получает результаты, ранжированные с использованием различных признаков (то есть документы сортированы таким образом, что сначала показываются наиболее релевантные).
Вот, собственно и все, что мы хотели рассказать о решениях на основе Compreno в первом приближении. Сегодня более 25 крупных российских компаний различных отраслей запустили пилотные проекты c использованием ABBYY InfoExtractor SDK, ABBYY Smart Classifier или ABBYY Intelligent Search. Большинство клиентов пока не хотят раскрывать карты, ведь речь идёт о повышении конкурентоспособности их бизнеса, и в этом смысле их можно понять. Думаем, в обозримом будущем мы все же сможем вам рассказать о внедрениях со всеми подробностями, а пока – задавайте вопросы, если они у вас остались.
Комментарии (10)
Fedorkov
10.12.2015 18:23ABBYY создают ИИ с гуманитарным складом мышления (прикрываясь коммерческими разработками).

worldmind
10.12.2015 22:16+1Кстати, саом понятие «тег» становится принципиально круче если тег это не слово, а элемент универсальной иерархии понятий т.е. не «тяпка», а условно «изделие->инструмент->садовый_инструмент->тяпка», тогда выборка по тегу «садовый_инструмент» может включать документ где стоит тег «тяпка»

qw1
11.12.2015 02:22Теги ввели как альтернативу иерархиям, потому что в сложных системах нельзя предложить однозначную и всегда подходящую иерархию.
worldmind
11.12.2015 09:51вы не поняли о чём я, я не о замене тегирования на иерархию, а об уточнении понятия тега
qw1
11.12.2015 11:24Когда будет создаваться новый тег, чтобы придумать название «изделие->инструмент->садовый_инструмент->тяпка» придётся обращаться к некоторой иерархии. Если её не будет, другой человек создаст тег «промтовары->для_сада->инструмент->тяпка».

xenohunter
11.12.2015 13:15Можно попробовать сделать «близкие» теги, по принципу «с этим товаром также ищут».
qw1
11.12.2015 13:50+1Это избыточно. Придётся назначить несколько тегов, чтобы всегда искалось по любому тегу.
Например,
Тяпка: тяпка, мотыжка, лейка;
Мотыжка: тяпка, мотыжка, лейка;
Лейка: тяпка, мотыжка, лейка.
xytop
Я 3 недели назад попросил инвайт для InfoExtractor SDK у вас на сайте, ни ответа, ни привета :(
Интересно опробовать ваш extractor для парсинга резюме.
luciana
Здравствуйте! Здесь мы, конечно, неправы :( Написала в личку