
В этом руководстве представлен пошаговый пример анализа производительности, поиска узких мест и оптимизации вывода графики в Android-игре, которая использует OpenGL ES 3.0. Пример игры, которым мы пользуемся в экспериментах, называется «City Racer». Это – симулятор городских автогонок. Анализ производительности приложения выполнен с использованием набора инструментов Intel Graphics Performance Analyzers (Intel GPA).

Игра City Racer
Городское окружение и автомобиль построены из примерно 230000 полигонов (690000 вершин). Здесь применяется наложение диффузных материалов, освещённых единственным источником направленного света без теней. В демонстрационных материалах к этой статье находится программный код, файлы проекта и графические ресурсы, которые необходимы для сборки и запуска приложения. Рассматриваемые здесь оптимизации можно включать и отключать, в коде представлен и исходный, и улучшенный варианты игры.
Предварительные сведения
В основе этого материала лежит руководство Intel Graphics Performance Workshop for 3rd Generation Intel Core Processor (Ivy Bridge), которое поставляется с GPA. Мы перенесли идеи и методики этого руководства на OpenGL ES 3.0.
В ходе рассмотрения материала мы пройдём по последовательным шагам оптимизации игры. На каждом шаге выполняется анализ приложения средствами GPA для поиска узких мест. Затем, для того, чтобы решить найденную проблему, мы улучшаем приложение, после чего производительность замеряется вновь – для оценки эффекта оптимизации. Мы придерживаемся здесь плана работы, который используется в руководстве, имеющемся в документе Developer’s Guide for Intel Processor Graphics.
Для сборки игрового примера City Racer используется Android API 20 и Android NDK 10. Анализ производительности производится с помощью набора инструментов Intel GPA.
Intel GPA совместим с большинством Android-устройств. Однако, с тех из них, которые построены на платформе x86, можно получить наиболее подробные сведения о профилируемых метриках.
Забегая вперёд, хотим отметить, что в ходе оптимизации графическая производительность City Racer выросла на 83%.
О City Racer
Демонстрационная игра City Racer логически разделена на две части. Первая отвечает за симуляцию процесса автогонок, вторая – за вывод графики. Симуляция гонки включает в себя моделирование ускорения, торможения, поворотов автомобиля. Здесь же присутствует система, построенная по принципам искусственного интеллекта, ответственная за следование по маршруту и уклонение от столкновений. Код, реализующий этот функционал, находится в файлах track.cpp и vehicle.cpp, он не подвергается оптимизации.
Компоненты вывода графики, вторая логическая часть игры, включают в себя код для отрисовки моделей автомобилей и игровой сцены с использованием OpenGL ES 3.0. и нашего движка собственной разработки CPUT. Исходная версия кода представляет собой типичную первую попытку создания рабочего приложения. Некоторые архитектурные решения, использованные при его написании, ограничивают производительность.
Сетки моделей и текстуры загружаются из файла Media/defaultScene.scene. Отдельные сетки промаркированы в соответствии с тем, являются ли они частью сцены, размещаемой заранее, объектом, который размещается в игровом мире в ходе прохождения игры, или автомобилем, параметры вывода которого вычисляются в ходе симуляции. В игровом пространстве можно пользоваться несколькими видами камер. Основная камера следует за автомобилем. Дополнительная камера позволяет пользователю свободно осматривать сцену. Анализ производительности и оптимизация кода нацелены на работу с камерой, которая следует за автомобилем.
Для целей данного руководства City Racer, при запуске, оказывается в режиме паузы. Это позволяет пройти по всем шагам профилирования, используя идентичные наборы данных. Снять игру с паузы можно, либо сбросив флажок Pause в её интерфейсе, либо записав в переменную g_Paused значение false. Эту переменную можно найти в начале файла CityRacer.cpp.
Потенциал оптимизации
City Racer – функциональный, но неоптимизированный прототип приложения. В исходном состоянии он способен сгенерировать картинку, которая нам нужна, но производительность вывода графики City Racer нас не устраивает. В игре присутствует множество технических приёмов и архитектурных решений, ограничивающих скорость визуализации. Они похожи на те, что можно найти в типичной игре, находящейся в процессе разработки. Цель этапа оптимизации при создании игры заключается в поиске узких мест и поочерёдном их устранение путём модификации кода и повторного замера производительности после каждого изменения.
Обратите внимание на то, что в этом руководстве мы затрагиваем небольшой набор улучшений, которым можно подвергнуть City Racer. В частности, они касаются лишь оптимизации исходного кода игры, а ресурсы, вроде моделей и текстур, мы не меняем. Рассказ об оптимизациях, затрагивающих графические или иные ресурсы игры, сделал бы наш рассказ слишком громоздким, поэтому этим мы здесь не занимаемся. Однако с помощью Intel GPA можно выявить и проблемы с игровыми ресурсами. При разработке и тонкой настройке реальной игры оптимизация ресурсов так же важна, как оптимизация кода.
Значения производительности, которые мы здесь приводим, получены на Android-устройстве, в котором установлен процессор Intel Atom (Bay Trail). Если вы повторите наши испытания, полученные результаты могут отличаться, однако относительные показатели изменения производительности должны быть теми же самыми. Описанные процедуры улучшения игры должны привести к сопоставимому росту производительности.
Код, его исходный и улучшенный варианты, находится в файле CityRacer.cpp. Использование оптимизаций можно включать и выключать в интерфейсе программы или путём модификации значения некоторых переменных в данном файле.

Включение и выключение оптимизаций в интерфейсе игры
В нижеприведённом коде из CityRacer.cpp показаны переменные, ответственные за включение и выключение оптимизаций. Состояние кода соответствует состоянию вышеприведённого фрагмента интерфейса.
bool g_Paused = true;
bool g_EnableFrustumCulling = false;
bool g_EnableBarrierInstancing = false;
bool g_EnableFastClear = false;
bool g_DisableColorBufferClear = false;
bool g_EnableSorting = false;В руководстве мы будем описывать различные техники оптимизации. Каждая переменная позволяет переключаться между оптимизированным и неоптимизированным вариантом кода. Если вы читаете руководство и попутно проверяете то, о чём узнали, на собственном устройстве, вы можете постепенно включать использование оптимизированных вариантов кода и наблюдать за изменениями производительности.
Оптимизация
Первый шаг заключается в компиляции игры City Racer и установке её на Android-устройство. Если в вашей системе присутствует правильно настроенная среда разработки Android, то всё необходимое можно сделать с помощью файла buildandroid.bat, который находится в папке CityRacer/Game/Code/Android.
После того, как игра установлена на устройстве, запустите Intel GPA Monitor, щёлкните правой кнопкой мыши по значку в системной области уведомлений и выберите System Analyzer.
System Analyzer покажет список платформ, к которым можно подключиться. Выберите ваше Android-x86 устройство и нажмите кнопку Connect.

Выбор платформы для анализа производительности
Когда System Analyzer подключится к устройству, он покажет список приложений, которые можно профилировать. Выберите City Racer и дождитесь запуска игры.

Список приложений, отображённый System Analyzer
Когда программа запустится, нажмите на кнопку захвата кадра для того, чтобы сделать снимок GPU-кадра для анализа.

Захват GPU-кадра для анализа
Исследование кадра
Откройте Frame Analyzer for OpenGL и выберите только что захваченный кадр City Racer. Это позволит в деталях проанализировать производительность GPU.
Запуск Frame Analyzer для исследования производительности GPU
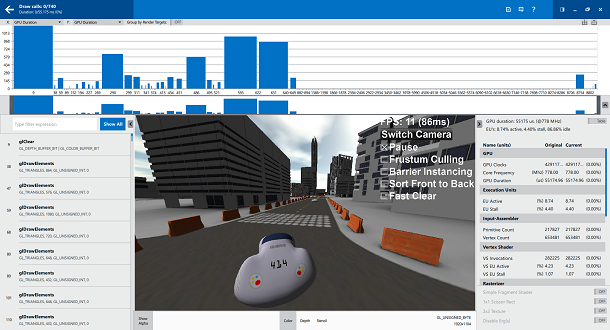
Шкала времени, соответствующая вызовам OpenGL
На временной шкале, которая расположена в верхней части экрана, показаны равномерно распределённые «эрги» — единицы, в которых измеряется работа по выводу изображения. Обычно они соответствуют вызовам команд рисования OpenGL. Для того чтобы переключиться к более традиционному отображению шкалы времени, выберите параметр GPU Duration по осям X и Y. Благодаря этой установке мы сможем быстро понять, какие из эргов занимают больше всего времени видеоядра. Это позволит выяснить, на чём именно следует сосредоточить усилия по оптимизации. Если ни один из эргов не выделен, на панели справа отображается общее время, необходимое GPU для вывода кадра. В нашем случае это 55 мс.

Время, необходимое GPU для вывода кадра
Оптимизация №1. Отсечение по пирамиде видимости
Взглянув на вызовы команд рисования, мы можем обнаружить, что выполняется вывод множества элементов, которые, на самом деле, на экране не видны. Изменив, при просмотре результатов анализа кадра, данные, выводимые по оси Y, на Post-Clip Primitives, мы можем увидеть разрывы, которые помогают понять, какие вызовы рисования тратятся впустую из-за того, что объекты, которые они выводят, полностью скрыты другими.

Анализ вывода объектов, которые полностью перекрыты другими объектами
Здания в City Racer собраны в группы, соответствующие их пространственному расположению. Группы, которые не видны, мы можем не выводить, не загружая GPU работой, связанной с ними. Если, в интерфейсе игры, установить флаг Frustum Culling, каждый вызов команды рисования, прежде чем он будет передан видеоядру, проходит «проверку на видимость» в коде, который выполняется на центральном процессоре.
Установим флаг Frustum Culling, захватим с помощью System Analyzer ещё один кадр для анализа и взглянем на него с помощью Frame Analyzer.

Анализ кадра, полученного после оптимизации
Анализируя кадр, мы можем заметить, что число вызовов рисования снизилось на 22% — с 740 до 576. Общее время, необходимое GPU для вывода кадра, снизилось на 18%.

Количество вызовов команд рисования после оптимизации отсечения по пирамиде видимости

Время вывода кадра после оптимизации
Оптимизация №2. Вывод мелких объектов
Отсечение по пирамиде видимости уменьшает общее число эргов, однако, в ходе анализа кадра можно наблюдать большое количество маленьких операций рисования (выделены жёлтым). Все вместе эти операции серьёзно нагружают видеоядро.

Мелкие операции рисования
Разобравшись с тем, какие конкретно объекты соответствуют маленьким эргам, мы выяснили, что основное их количество приходится на вывод бетонных блоков, которыми ограничена трасса.

Блоки, на которые приходятся мелкие операции рисования
Устранить большую часть ненужной нагрузки на видеоядро можно, объединив разрозненные операции по выводу блоков в одну операцию. При установке флага Barrier Instancing, рисование блоков, присутствующих на сцене, выполняется как одна операция. Это избавляет центральный процессор от необходимости отправлять видеоядру команду рисования каждого блока в отдельности.
Если, после включения флага Barrier Instancing, захватить кадр с помощью System Analyzer и проанализировать его в Frame Analyzer, можно заметить серьёзный рост производительности.

Анализ после оптимизации вывода мелких объектов
Проанализировав кадр, мы видим, что число вызовов рисования сократилось на 90%, а именно – с 576 до 60.

Вызовы команд рисования до оптимизации

Вызовы команд рисования после оптимизации
Теперь общее время работы видеоядра, необходимое для вывода кадра, сократилось на 71%, до 13 мс.

Время вывода кадра после оптимизации
Оптимизация №3. Сортировка объектов – от близких к далёким
Термином «перерисовка» («overdraw») называется многократное рисование одних и тех же пикселей результирующего изображения. Перерисовка пикселей может повлиять на пиксельную скорость заполнения и увеличить время вывода кадра. Изучив метрику Samples Written, мы можем видеть, что каждый пиксель изображения в каждом кадре перерисовывается, в среднем, 1,8 раза (Resolution / Samples Written).
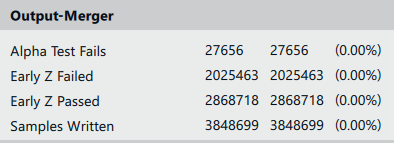
Показатель Samples Written до оптимизации
Сортировка вызовов рисования от близких к далёким объектам – это довольно простой способ уменьшить эффект перерисовки. При таком подходе конвейер видеоядра не станет перерисовывать пиксели, выведенные на предыдущем шаге.
Установим флаг Sort Front to Back, захватим с помощью System Analyzer кадр и проанализируем его с помощью Frame Analyzer.

Анализ результатов применения сортировки вызовов команд рисования
В итоге метрика Samples Written уменьшилась на 6%, а время работы GPU – на 8%.

Показатель Samples Written после оптимизации

Время вывода кадра после оптимизации
Оптимизация №4. Быстрая очистка
Изучая временную шкалу, мы заметили, что самый первый эрг требует максимального, для одной операции, времени GPU. Выбрав его, видим, что это – не вызов команды рисования draw, а вызов команды очистки экрана glClear.

Первый эрг

Действие, выполняемое в первом эрге
Видеоядро от Intel имеет встроенную возможность выполнения так называемой «быстрой очистки». Она занимает небольшую часть времени, которое требуется для стандартной очистки. Быструю очистку можно выполнить, если использовать при вызове glClearColor чёрный или белый цвета, задаваемые, соответственно, как (0, 0, 0, 0) или (1, 1, 1, 1).
Установим флаг Fast Clear и выполним традиционную процедуру по захвату кадра с помощью System Analyzer и его анализа средствами Frame Analyzer.
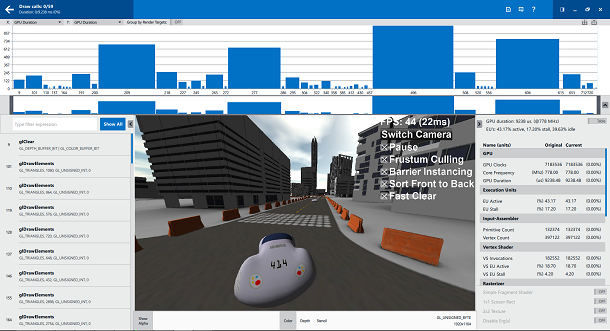
Анализ кадра после использования быстрой очистки
Проанализировав кадр, видим, что время GPU, необходимое для выполнения операции очистки, снизилось на 87%. А именно, на обычную очистку надо примерно 1,2 мс., а на быструю – лишь 0.2

Время работы GPU, необходимое для выполнения обычной очистки

Время работы GPU, необходимое для выполнения быстрой очистки
В результате общее время вывода кадра сократилось на 24% — до 9,2 мс.

Общее время работы GPU
Выводы
Мы взяли типичную мобильную игру, находящуюся на ранней стадии разработки. Игру проанализировали с помощью Intel GPA и внесли в код изменения, рассчитанные на увеличение производительности. Сведём результаты различных этапов оптимизации в таблицу.
| Оптимизация |
До |
После |
Улучшение, в % |
| Отсечение по пирамиде видимости |
55,2 мс. |
45,0 мс. |
18% |
| Оптимизация вывода объектов |
45,0 мс. |
13,2 мс. |
71% |
| Сортировка объектов |
13,2 мс. |
12,1 мс. |
8% |
| Быстрая очистка |
12,1 мс. |
9,2 мс. |
24% |
| Общий результат оптимизации GPU |
55,2 мс. |
9,2 мс. |
83% |
Оценивая любые результаты тестов производительности, следует учитывать то, что тестовое ПО и рабочие нагрузки могут быть оптимизированы, например, только для процессоров Intel. Приложения для тестирования, например, SYSmark и MobileMark, вычисляют показатели производительности, основываясь на измерениях, проведённых на конкретных вычислительных системах. На результаты может повлиять всё, что угодно: компоненты этих систем, установленное программное обеспечение, да и сам набор испытаний, и их последовательность – тоже.
Любое изменение каждого из этих факторов может привести к изменению результатов теста. Поэтому, принимая на основе информации из тестовых отчётов какие-либо решения, например, о покупке оборудования, следует собрать как можно больше сведений из различных источников. Нужно учитывать, что, например, тесты процессора «А», работающего в паре с оперативной памятью «Б», могут отличаться от тестов того же процессора в системе, в которой установлена память «В». Для того чтобы узнать подробности о производительности систем, загляните сюда.
Если подвести итоги всех оптимизаций, применённых к City Racer, то окажется, что частота кадров выросла на 300% — с 11 кадров в секунду – до 44. Рассматривая этот результат, стоит помнить о том, что мы начинали работу с изначально весьма неоптимальным приложением. Поэтому, если использовать ту же цепочку улучшений, которую мы здесь привели, в реальном проекте, выигрыш в производительности может и не оказаться столь же существенным.
Мобильная игра, конечно, это не только производительность. Но какой бы гениальной ни была задумка, как хорошо ни был бы просчитан игровой баланс, какими бы невероятными цветами ни переливалась бы картинка, низкое FPS способно убить всё, что угодно.
Мы оптимизировали в этом руководстве учебную игру City Racer для того, чтобы дать вам лучшее оружие для борьбы с «тормозами»: рекомендации из Developer’s Guide for Intel Processor Graphics и Intel GPA. Желаем пятизвёздочных отзывов вашим играм.
Комментарии (10)

MrShoor
16.12.2015 20:36А что за Fast Clear? Где про это можно почитать? Почему очищать нулем или единицей колорбуфер быстрее?
И кажется в вашем случае колорбуфер можно вообще не чистить, а чистить только буфер глубины, не?
XProger
17.12.2015 09:58Буфер глубины можно и при отрисовке скайбокса затереть с GL_ALWAYS

beeruser
17.12.2015 12:28+1Это очень плохая идея. Очистка Z не займёт много времени, а вот заливка на TBDR GPU вызовет загрузку мусорных данных в тайл-буфер на чипе.
Механизмы оптимизации рендера в современных GPU рассчитаны на то, что глубину вы будете чистить каждый кадр.
Подробнее тут:
http://developer.amd.com/wordpress/media/2012/10/Depth_in-depth.pdf
>> Clear the depth-stencil buffer
beeruser
17.12.2015 11:54У рендертаргета есть метаинформация, которая для определённого блока/тайла поверхности указывает, имеют ли все пиксели тайла общий цвет или не имеют.
На примере AMD об этом можно почитать тут:
http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/10/evergreen_cayman_programming_guide.pdf#page23
FMASK/CMASK

DjOnline
19.12.2015 16:55Я одно не понимаю, разве почти это всё не должны делать драйвера видеокарты или даже сама видеокарта? Отсекать по пирамиде видимости, не выводить далёкие мелкие объекты (или упрощать их автоматически перед выводом с помощью тесселяции и кэширования упрощённой модели), сортировать объекты перед отображением для отсечения.
Что, драйвера под андроид настолько тупые, что не могут подменить команду очистки glClear на быструю очистку glClearColor?
Я же помню ещё 13 лет назад в десктопных видеокартах были радужные анонсы о том что это почти всё это умеет теперь делать сама видеокарта (анонс T&L 2002 года), неужели в мобильных платформах не так?beeruser
20.12.2015 19:15«Я одно не понимаю, разве почти это всё не должны делать драйвера видеокарты или даже сама видеокарта? Отсекать по пирамиде видимости, не выводить далёкие мелкие объекты (или упрощать их автоматически перед выводом с помощью тесселяции и кэширования упрощённой модели), сортировать объекты перед отображением для отсечения. „
Нет. Драйвер эти вещи не делает и не должен (ни на какой платформе).
“драйвера под андроид настолько тупые, что не могут подменить команду очистки glClear на быструю очистку glClearColor?»
Что? glClearColor лишь задаёт цвет для glClear.
FastClear это аппаратная фича. У Intel HD она просто очень убогая.
«Я же помню ещё 13 лет назад в десктопных видеокартах были радужные анонсы о том что это почти всё это умеет теперь делать сама видеокарта (анонс T&L 2002 года),»
Память вас подводит. T&L (~1999г) это просто просто трансформация вертексов и освещение, что в 2002 уже устарело.
XProger
Какой такой overdraw на железе с тайловым рендером? Хотелось бы в таком объёме текста увидеть больше вариантов оптимизаций, относительно специфики мобильных устройств. Так например объяснения почему alpha test даёт прирост на PC, и дикую просадку на мобилках.
beeruser
С чего вы решили что там тайловый рендер? Там же явно написано Intel HD Graphics и Baytrail.
Альфатест в тайловом GPU конфликтует с работой HSR механизма.
«Сплошные» треугольники рисуются таким образом, что шейдер выполняется лишь один раз для ближнего пикселя, без overdraw.
После того как сцена из «сплошных» треугольников будет построена, в тайл последовательно отрисовываются альфатестовые и альфаблендовые треугольники.
XProger
Это всё очень здорово, только вот кому интересны оптимизации вывода графики в Android на x86 архитектуре?
beeruser
Этот вопрос было бы более уместно задать автору статьи :-)