
Современные программы, претендующие на звание эффективных, должны учитывать особенности аппаратного обеспечения, на котором они будут исполняться. В частности, речь идёт о многоядерных процессорах, например, таких, как Intel Xeon и Intel Xeon Phi, о больших размерах кэш-памяти, о наборах инструкций, скажем, Intel AVX2 и Intel AVX-512, позволяющих повысить производительность вычислений.

Еле удержались, чтобы не пошутить про руссиано)
Вот, например, Caffe – популярная платформа для разработки нейронных сетей глубокого обучения. Её создали в Berkley Vision and Learning Center (BVLC), она пришлась по душе сообществу независимых разработчиков, которые вносят посильный вклад в её развитие. Платформа живёт и развивается, доказательство тому – статистика на странице проекта в GitHub. Caffe называют «быстрой открытой платформой для глубокого обучения». Можно ли ускорить такой вот «быстрый» набор инструментов? Задавшись этим вопросом, мы решили оптимизировать Caffe для архитектуры Intel.
Забегая вперёд, отметим, что Caffe, благодаря интеграции с Intel Math Kernel Library 2017 и набору оптимизаций, которые мы выполнили, следуя плану, изложенному в этом материале, стала работать на процессорах Intel более чем в 10 раз быстрее базовой версии, которую мы, в дальнейшем, будем называть BVLC Caffe. Версию, оптимизированную для архитектуры Intel, дальше, для краткости, будем называть Intel Caffe. Вот её исходный код.
Основные направления улучшения производительности, подробности о которых читайте ниже, заключались в рефакторинге кода, в его оптимизации в расчёте на использование наборов векторных инструкций, таких, как Intel AVX2, в тонкой настройке компиляции, в повышении эффективности многопоточного исполнения кода с использованием OpenMP. Испытания проводились на системе с двумя процессорами Intel Xeon. В частности, мы исследовали скорость нейронной сети, построенной средствами Caffe, при работе с изображениями из набора CIFAR-10. Результаты исполнения программы анализировали в Intel VTune Amplifier XE 2017 и с помощью других инструментов.
Похожий подход можно использовать для улучшения производительности самых разных программ, например, других платформ для глубокого обучения нейронных сетей.
Прежде чем переходить к вопросам оптимизации, расскажем об алгоритмах глубокого обучения и о задачах, которые решают с их помощью.
Алгоритмы глубокого обучения – это часть более общего класса алгоритмов машинного обучения, которые в последние годы показали значительные результаты в распознавании образов на фото и видео, в распознавании речи, в обработке естественного языка, и в других областях, где приходится иметь дело с огромными объёмами информации и решать задачи анализа данных. Успех глубокого обучения базируется на последних достижениях в области вычислений и алгоритмов, в возможностях обрабатывать большие наборы данных. Принцип работы таких алгоритмов заключается в том, что данные пропускают через слои сети, в которых производится преобразование информации, извлечение из неё всё более сложных признаков.
Вот пример того, как каждый уровень глубокой нейронной сети обучен идентифицировать признаки всё более высокой сложности. Здесь показан небольшой набор признаков, распознаваемых глубокой сетью, визуализированный в виде изображений в оттенках серого. Здесь же показаны исходные цветные изображения, обработка которых ведёт к выделению этих признаков. Изображение взято отсюда.

Свёрточная нейронная сеть
Для работы алгоритмов глубокого обучения с учителем требуется размеченный набор данных. Три популярных типа глубоких нейронных сетей, которые обучают с учителем, это многослойный перцептрон (Multilayer Perceptron, MLM), свёрточные нейронные сети (Convolution Neural Network, CNN), и рекуррентные нейронные сети (Recurrent Neural Network, RNN). В этих сетях входные данные, при прохождении их через каждый слой сети, подвергают сериям линейных и нелинейных преобразований. В итоге формируются выходные данные сети. Ответ сети сравнивают с ожидаемым результатом, находят ошибки, затем, для выходного слоя, вычисляют вектор градиента поверхности ошибок, выясняют, какой вклад в ответ сети вносят синаптические веса нейронов, с учётом активационных функций, после чего выполняют такую же процедуру для других слоёв, применяя ранее полученные данные. Этот метод обучения называют алгоритмом обратного распространения ошибки, в результате его применения производится пошаговая модификация весовых коэффициентов нейронов сети.
В многослойных перцептронах входные данные в каждом слое (представленном вектором) сначала умножают на полностью заполненную матрицу весовых коэффициентов, уникальную для слоя. В рекуррентных сетях такая матрица (или матрицы) одна и та же для каждого слоя (так как слой рекуррентный), и свойства сети зависят от входного сигнала. Свёрточные сети похожи на многослойные перцептроны, но они используют разреженные матрицы для скрытых слоёв, называемых свёрточными. В таких сетях умножение матриц представлено свёрткой матричного представления весов с матричным представлением входных данных слоя. Свёрточные сети популярны в распознавании изображений, но они находят применение и в распознавании речи, и в обработке естественных языков. Здесь можно почитать о таких сетях подробнее.
Как уже было сказано, здесь мы собираемся оптимизировать для архитектуры Intel BVLC Caffe – популярную платформу для создания и исследования сетей глубокого обучения. Испытывать исходную и оптимизированную версию платформы будем, используя набор данных CIFAR-10, который часто применяют в задачах классификации изображений, и модель нейронной сети, построенную в Caffe.

Пример изображений из набора CIFAR-10
Набор данных CIFAR-10 состоит из 60000 цветных изображений размером 32x32 пикселя, разделённых на 10 классов: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик. Классы не пересекаются. Например, здесь нет перекрытия между классами «автомобиль» и «грузовик». К «автомобилям» относятся, например, седаны и внедорожники. В класс «грузовик» входят только тяжёлые грузовики, а, например, грузовиков-пикапов нет ни в одной из групп изображений.
Сеть, используемая в ходе тестирования производительности, содержит слои различных типов. В частности, это слои с сигмоидной функцией активации (такие слои, в терминологии Caffe, имеют тип Sigmoid), свёрточные слои (тип Convolution), слои пространственного объединения или, как их ещё называют, слои подвыборки (тип Pooling), слои пакетной нормализации (тип BatchNorm), полносвязные слои (тип InnerProduct). На выходе сети находится слой с активационной функцией Softmax (тип SoftmaxWithLoss). Подробнее об этой сети и её слоях мы поговорим ниже. А сейчас приступим к анализу исходной версии Caffe.
Один из методов оценки производительности BVLC Caffe и Intel Caffe заключается в использовании команды time, которая вычисляет время, необходимое для прохождения сигнала по слоям в прямом и обратном направлении. Эта команда весьма полезна для измерения времени, которое затрачивается на вычисления в каждом уровне, и для получения сравнительного времени исполнения для различных моделей:
В данном случае «итерацией» (тем, что задаёт параметр iteration) называется один прямой и обратный проход по пакету изображений. Вышеприведённая команда выводит среднее время исполнения для 1000 итераций, как для отдельных слоёв, так и для всей сети. Вот результаты работы этой команды для BVLC Caffe.

Вывод команды time для BVLC Caffe
В тестах мы использовали систему с двумя сокетами. В каждом был установлен процессор Intel Xeon E5-2699 v3 (2.3 ГГц) с 18-ю физическими ядрами. При этом технология Intel Hyper-Threading была отключена. В системе, таким образом, было всего 36 физических процессорных ядер и такое же число потоков OpenMP, что было задано с помощью переменной окружения OMP_NUM_THREADS. Если не указано иное, в наших экспериментах использовалась именно такая конфигурация. Обратите внимание на то, что мы рекомендуем позволить Intel Caffe автоматически настраивать переменные окружения OpenMP, вместо того, чтобы задавать их самостоятельно. В системе, кроме того, установлено 64 Гб DDR4-памяти, которая работает на частоте 2.133 МГц.
Здесь показаны результаты тестирования производительности, которых удалось достичь благодаря оптимизации кода инженерами Intel. Для измерения производительности мы использовали следующие инструменты:
Средства из Intel VTune Amplifier XE предоставляют следующие сведения:
Анализы производительности можно использовать для поиска подходящих кандидатов на оптимизацию, таких, как функции, создающие большую нагрузку на систему, и вызовы функций, которые выполняются сравнительно долго.
На рисунке ниже показаны обобщённые данные анализа производительности BVLC Caffe из Intel VTune, полученные после выполнения 100 итераций. Показатель Elapsed Time, расположенный в верхней части рисунка, составляет 37 секунд. Это – время, которое понадобилось для выполнения кода на тестовой системе. Показатель CPU Time, процессорное время, составляет 1306 секунд. Это немного меньше, чем 37 секунд, умноженные на 36 ядер (1332 секунды). Данный показатель представляет собой общую длительность исполнения кода во всех потоках (или на всех ядрах, так как в нашем случае технология Intel HT была отключена), которые используются в вычислениях.

Общие результаты анализа исполнения BVLC Caffe на наборе данных CIFAR-10 в Intel VTune Amplifier XE 2017 beta
Гистограмма использования процессора, которая находится в нижней части рисунка, указывает на то, как часто в ходе теста определённое количество потоков задействуется одновременно. В данном случае, из 37 секунд, 14 приходится на один поток (то есть – на одно ядро). Всё остальное время мы видим весьма неэффективную многопоточную обработку, при этом, в основном, в работе участвуют менее 20 потоков.
Раздел Top Hotspots, расположенный в середине рисунка, указывает на то, на какие функции приходится больше всего работы. Здесь перечислены вызовы функций и вклад каждой из них в общее время работы процессора. Функция kmp_fork_barrier – это внешняя OpenMP-функция, на исполнение кода которой уходит 1130 секунд процессорного времени. Это означает, что около 87% рабочего времени процессора уходит на то, что потоки бездействуют в этой барьерной функции, не делая ничего полезного.
В исходном коде BVLC Caffe имеется строчка #pragma omp parallel. Однако в самом коде не наблюдается явного использования библиотеки OpenMP для организации многопоточной обработки данных. При этом внутри Intel MKL потоки OpenMP используются для распараллеливания выполнения некоторых базовых математических расчётов. Для того, чтобы подтвердить это распараллеливание, мы можем воспользоваться вкладкой Bottom-up в Intel VTune XE, содержимое которой, после тестирования BVLC Caffe на наборе данных CIFAR-10, приведено на рисунке ниже. Здесь можно найти перечень вызовов функций и дополнительные сведения о них. В частности, нас интересуют показатели Effective Time by Utilization (верхняя часть вкладки) и показатели распределения нагрузки, создаваемой функциями, по потокам (нижняя часть).

Визуализация временных параметров исполнения функций и перечень функций, сильнее всего нагружающих систему при исполнении BVLC Caffe на наборе данных CIFAR-10
Функция gemm_omp_driver_v2 – это часть библиотеки libmkl_intel_thread.so – обобщённая реализация умножения матриц (GEMM) из Intel MKL. Во внутренних механизмах этой функции задействована OpenMP-многопоточность. Функция умножения матриц из Intel MKL – это основная функция, используемая в процедурах прямого и обратного распространения, то есть, в операциях получения ответа сети и её обучения. Intel MKL использует многопоточное исполнение, что обычно уменьшает время выполнения GEMM-вычислений. Однако, в данном конкретном случае операция свёртки для изображений размером 32x32 создаёт не слишком большую нагрузку на систему, что не позволяет эффективно использовать все 36 OpenMP-потока на 36 ядрах в одной GEMM-операции. Поэтому, как будет показано ниже, требуется использование различных схем многопоточности и параллелизации исполнения кода.
Для того, чтобы продемонстрировать дополнительную нагрузку на систему, которую создаёт необходимость работать со множеством потоков OpenMP, мы запустили тот же код с переменной окружения OMP_NUM_THREADS=1, а затем сравнили время исполнения с предыдущим результатом. То, что у нас получилось, представлено на рисунке ниже. Здесь мы видим показатель Elapsed Time, равный 31.1 секунде, вместо 37 секунд из предыдущего испытания. Записав в переменную окружения единицу, мы принудили OpenMP к созданию только одного потока и к использованию его для исполнения кода. Полученная разница в почти шесть секунд указывает на дополнительную нагрузку на систему, которую вызывают операции инициализации и синхронизации потоков OpenMP.

Общие результаты анализа исполнения BVLC Caffe на наборе данных CIFAR-10 в Intel VTune Amplifier XE 2017 beta при использовании одного потока
В центральной части вышеприведённого рисунка имеется список функций, наиболее сильно нагружающих систему. Среди них мы обнаружили три основных кандидата на оптимизацию. А именно – это функции im2col_cpu, col2im_cpu, и PoolingLayer::Forward_cpu.
Работа с набором данных CIFAR-10 с в среде Caffe, оптимизированной для архитектуры Intel, примерно в 13.5 раз быстрее, чем при использовании BVLC Caffe. На рисунке ниже представлены средние результаты после 1000 итераций. Слева приведены данные BVLC Caffe, справа – Intel Caffe. Видно, что в первом случае общее время выполнения составило 270 мс., а во втором – 20 мс.

Сравнение производительности BVLC Caffe и Intel Caffe
Подробности о том, как задавать параметры вычислений для слоёв, можно найти здесь.
В следующем разделе будут описаны оптимизации, использованные для улучшения производительности расчётов, применяемых в различных слоях. Мы следовали методическим руководствам из программы Intel Modern Code. Некоторые из оптимизаций основаны на базовых математических функциях из Intel MKL 2017.
После профилирования кода BVLC Caffe и выявления наиболее нагруженных функций, потребляющих больше всего процессорного времени, мы начали работу над векторизацией кода. Среди внесённых изменений были следующие:
В BVLC Caffe имеется возможность использования вызовов функции Intel MKL BLAS или других реализаций тех же механизмов. Например, функция GEMM оптимизирована в расчёте на векторизацию, многопоточное исполнение и эффективное использование кэш-памяти. Для улучшения векторизации мы так же использовали Xbyak – JIT-ассемблер для архитектур x86 (IA-32) и x64 (AMD64 или x86-64). Xbyak поддерживает следующие наборы векторных инструкций: MMX, Intel Streaming SIMD Extensions (Intel SSE), Intel SSE2, Intel SSE3, Intel SSE4, модуль вычислений с плавающей запятой, Intel AVX, Intel AVX2 и Intel AVX-512.
Xbyak – это x86/x64-ассемблер для C++, библиотека, специально созданная для повышения эффективности исполнения кода. Xbyak предоставляется в виде заголовочного файла. Он может динамически собирать мнемонические инструкции для архитектур x86 и x64. JIT-генерация двоичного кода в процессе исполнения даёт дополнительные возможности оптимизации. Например, это оптимизация квантования, операции поэлементного деления одного массива на другой, или оптимизация полиномиальных вычислений благодаря автоматическому созданию нужных функций во время выполнения программы. Благодаря поддержке наборов векторных инструкций Intel AVX и Intel AVX2, с помощью Xbyak можно достичь лучшего уровня векторизации кода в Caffe, оптимизированном для архитектуры Intel. В самой свежей версии Xbyak имеется поддержка набора векторных инструкций Intel AVX-512. Это позволяет улучшить производительность вычислений на процессорах Intel Xeon Phi семейства x200.
Улучшение показателей векторизации даёт возможность Xbyak, с помощью SIMD-инструкций, обрабатывать больше данных одновременно, что позволяет более эффективно задействовать параллельную обработку данных. Мы использовали Xbyak при оптимизации кода, что значительно улучшило производительность расчётов в слоях пространственного объединения. Если известны параметры пространственного объединения, можно сгенерировать ассемблерный код для конкретных моделей объединения, в которых используется определённое окно обработки данных или алгоритм. В результате получается вполне обычная с виду сборка, которая, что доказано, работает эффективнее, чем код на C++, скомпилированный без использования Xbyak.
Другие последовательные оптимизации включали в себя следующее:
Избавление от многократного выполнения кода, результаты которого не меняются – это одна из техник скалярной оптимизации, которую мы применили. Это было сделано для того, чтобы заранее вычислить то, что иначе бы вычислялось внутри цикла с максимальной глубиной вложенности.
Рассмотрим, например, такой фрагмент кода:
В третьей строке этого фрагмента, для вычисления переменной h_im, не используется индекс внутреннего цикла w_col. Но, несмотря на это, вычисление данной переменной производится в каждой итерации вложенного цикла. Как вариант, мы можем переместить эту строчку за пределы внутреннего цикла, приведя код к такому виду:
Вот какие дополнительные общие оптимизации кода были применены:
Intel VTune Amplifier XE выяснил, что функция im2col_cpu – одна из наиболее сильно нагружающих систему. Это значит, что она – хороший кандидат на оптимизацию производительности. Функция im2col_cpu – это реализация стандартного шага в операции прямой свёртки. Каждый локальный фрагмент разворачивается в отдельный вектор, всё изображение конвертируется в более крупную матрицу (что повышает интенсивность работы с памятью), строки которой соответствуют множеству мест, где были применены фильтры.
Одна из техник оптимизации для функции im2col_cpu заключается в сокращении числа операций, необходимых для доступа к данным. В коде BVLC Caffe имеется три вложенных цикла, в которых выполняется проход по пикселям изображения:
В этом фрагменте кода BVLC Caffe изначально вычислял соответствующие индексы массива элементов data_col, хотя индексы этого массива просто обрабатываются последовательно. Таким образом, четыре арифметических операции (два сложения и два умножения) можно заменить одной операцией инкрементации индекса. Кроме того, сложность проверки условия можно уменьшить исходя из следующего:
В коде BVLC Caffe была проверка условия вида if (x >= 0 && x < N), где x и N – целые числа со знаком, при этом N – всегда положительное число. Преобразование этих целых чисел к целым числам без знака позволяет изменить интервал сравнения. Вместо того, чтобы выполнять две операции сравнения и вычисление логического И, после преобразования типа достаточно одного сравнения:
Для того, чтобы избежать перемещения потоков операционной системой между вычислительными ядрами, мы использовали переменную среды OpenMP: KMP_AFFINITY = compact, granularity = fine. Компактное расположение соседних потоков может улучшить производительность операций GEMM, так как потоки, которые совместно работают с одним и тем же кэшем последнего уровня (last-level cache, LLC), могут повторно использовать данные, ранее записанные в строки кэша.
Вот материал, в котором можно найти подробности об оптимизации, связанной с блокированием кэша, об особенностях оптимальной компоновки данных и векторизации.
В ходе применения OpenMP-параллелизации были оптимизированы следующие механизмы нейронной сети:
Слой свёртки, что вполне соответствует его названию, выполняет свёртку входных данных, используя набор модифицированных в ходе обучения сети весов, или фильтров, каждый из которых позволяет получить одну карту признаков в выходном изображении. Эта оптимизация предотвращает недостаточное использование аппаратных ресурсов для одного набора входных карт признаков.
Мы обрабатываем k = min(num_threads,batch_size) наборов карт input_feature. Например, k операций im2col происходят параллельно и выполняется k обращений к Intel MKL. Intel MKL переключается в однопоточный режим исполнения автоматически и общая производительность оказывается лучше, чем ранее, когда Intel MKL обрабатывала один пакет. Такое поведение задано в файле с исходным кодом src/caffe/layers/base_conv_layer.cpp. Это реализация оптимизированной многопоточной обработки с использованием OpenMP из файла с исходным кодом src/caffe/layers/conv_layer.cpp.
Max-pooling, average-pooling, и stochastic-pooling (ещё не реализованный) – это разные методы понижающей дискретизации, при этом max-pooling – самый популярный метод. Слой подвыборки разбивает результат, полученный от предыдущего слоя, на набор обычно не перекрывающихся прямоугольных фрагментов. Для каждого такого фрагмента слой затем выводит максимум (max-pooling), арифметическое среднее (average-pooling), или (в будущем) стохастическое значение (stochastic-pooling), полученное из мультиномиального распределения, сформированного из функций активации каждого фрагмента.
Слои подвыборки полезны в свёрточных сетях по трём основным причинам:
Подвыборка работает на одной карте признаков, поэтому мы использовали Xbyak для того, чтобы выполнить эффективную процедуру сборки, которая поможет создать нужную нам выборку для одной или большего количества входных карт признаков. Эта методика может быть реализована для пакета входных карт признаков, когда процедура выполняется параллельно в OpenMP.
Вычисления слоя подвыборки выполняются параллельно, с использованием OpenMP-многопоточности. Это возможно благодаря тому, что изображения независимы:
Благодаря выражению collapse(2), директива OpenMP #pragma omp parallel распространяется на оба вложенных цикла for, которые выполняют проход по изображениям в пакете и каналам изображений, комбинируя циклы в один и исполняя параллельно то, что получилось.
Функция потерь – это ключевой компонент в машинном обучении. Именно эта функция используется при сравнении выхода сети с целевым показателем, для поиска ошибки. После этого производится настройка весовых коэффициентов сети для уменьшения значения этой функции, то есть, для уменьшения ошибки, отклонения того, что выдаёт сеть, от желаемого выхода. В нашей модели в качестве функции потерь используется softmax (тип слоя – SoftmaxWithLoss).
Такую функцию активации используют в том случае, когда выходы сети символизируют вероятность неких событий, или, как в нашем случае, вероятность принадлежности изображений к различным классам. В частности, в мультиномиальной логистической регрессии (проблема классификации на множество классов), входные данные для этой функции – результат K различных линейных функций, и предсказанная вероятность j-того класса для вектора x вычисляется по такой формуле:
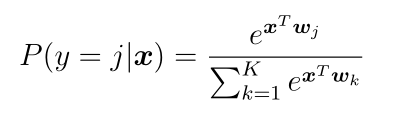
При многопоточном выполнении этих вычислений применяется подход с использованием главного и подчинённого потоков. Так, главный поток запускает некое число подчинённых, распределяя задачи между ними. Подчинённые потоки затем выполняются параллельно, так как они назначаются различным ядрам.
Например, в следующем коде параллельное выполнение отдельных арифметических операций с независимым доступом к данным реализовано с помощью разделения вычислений для различных каналов изображений:
ReLU – это самый популярный на сегодня класс нелинейных функций, используемых в алгоритмах глубокого обучения. Полносвязные слои – это поэлементные операторы, которые берут двоичный объект (blob в терминологии Caffe), выдаваемый нижележащим слоем, и подают на вышележащий слой преобразованный набор данных того же размера. (Такой набор данных – это обычный массив, представляющий унифицированный интерфейс платформы Caffe. Когда данные и найденные ошибки распространяются по сети, Caffe работает с информацией в виде таких объектов).
Слой с активационной функцией ReLU берёт входное значение x и подаёт на выход то же самое x, если оно больше нуля, а отрицательные значения перемножает на параметр negative_slope по такой формуле:
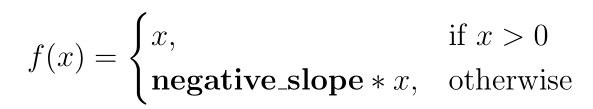
По умолчанию значение параметра negative_slope равняется нулю, что эквивалентно стандартной функции ReLU, которая возвращает максимальное значение после сравнения переданного ей значения с нулём: max(x, 0). Из-за независимости процесса активации от данных, каждый набор данных может быть обработан параллельно:
Похожие параллельные вычисления можно использовать и в процедуре обратного распространения ошибки:
Таким же образом можно распараллелить вычисление сигмоидной функции S(x) = 1 / (1 + exp(-x)):
Так как MKL не предоставляет базовых математических операций для реализации ReLU-функций, для того, чтобы добавить этот функционал в систему, мы попытались реализовать оптимизированную версию ReLU-слоя на ассемблере (с использованием Xbyak). Однако, после испытаний, мы не обнаружили заметного роста производительности на процессорах Intel Xeon. Возможно это так из-за ограниченной пропускной способности памяти. Параллелизация существующего кода на C++ оказалась достаточно хорошей для улучшения общей производительности.
В предыдущем разделе мы рассмотрели различные компоненты и слои нейронных сетей, и то, как данные, обрабатываемые в этих слоях, распределяются по потокам OpenMP и Intel MKL. Гистограмма использования процессора, приведённая ниже, показывает, насколько часто некое число потоков выполняется параллельно после оптимизации кода.
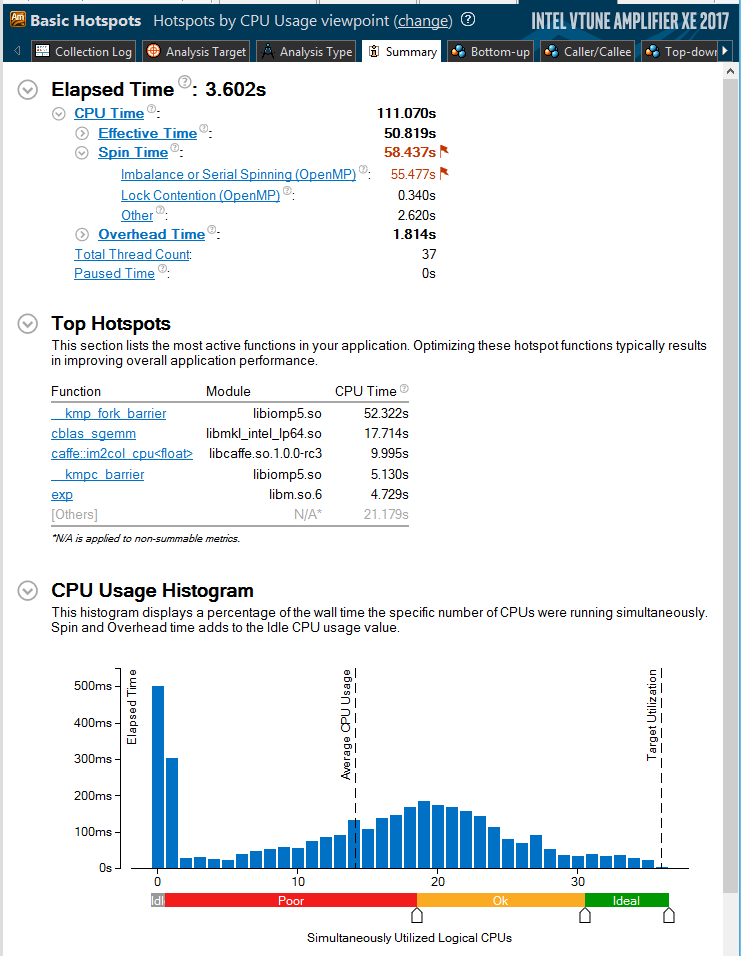
Общие результаты анализа исполнения реализации Caffe, оптимизированной для архитектуры Intel, на задаче CIFAR-10 в Intel VTune Amplifier XE 2017 beta
С использованием Caffe, оптимизированного для архитектуры Intel, число одновременно выполняющихся потоков значительно возросло. Время исполнения на нашей тестовой системе упало с 37 секунд для неоптимизированного кода BVLC Caffe, до всего 3.6 секунд для оптимизированной версии. Общая производительность выросла более чем в 10 раз.
Ка показано в разделе Elapsed Time, в верхней части рисунка, часть времени исполнения относится к показателю Spin Time, что указывает на время, которое тратится на ожидание, а не на полезную работу. В результате производительность не растёт линейно при увеличении числа потоков (в соответствии с законом Амдала). Кроме того, здесь всё ещё имеются участки, исполняющиеся последовательно, не параллелизованные с использованием OpenMP. Повторная инициализация параллельных участков OpenMP была значительно оптимизирована для последних реализаций библиотеки OpenMP, но она всё ещё создаёт довольно заметную дополнительную нагрузку на систему. Перемещение параллельных участков в главную функцию может, в потенциале, улучшить производительность даже больше, но это потребует значительного рефакторинга кода.
На рисунке ниже обобщены описанные техники оптимизации и принципы переработки кода, которым мы следовали, занимаясь оптимизацией Caffe для архитектуры Intel.
Пошаговый подход программы Intel Modern Code
В ходе испытаний мы пользовались Intel VTune Amplifier XE 2017 beta для поиска участков кода, которые создают наибольшую нагрузку на систему, и оптимизация которых способна принести заметный выигрыш в производительности. Мы реализовали скалярные и последовательные оптимизации, включая устранение кода, результаты выполнения которого оказываются одними и теми же при многократном вызове. Так же мы провели сокращение или упрощение арифметических операций, оптимизировав циклы и проверки условий. Далее мы улучшили код в расчёте на его векторизацию, следуя общим принципам, изложенным в материале об автоматической векторизации в GCC. Применение JIT-ассемблера Xbyak позволило нам более эффективно задействовать SIMD-инструкции.
Мы реализовали многопоточность для вычислений, проводимых внутри слоёв нейронной сети с помощью библиотеки OpenMP, там, где операции над изображениями или каналами были независимы от данных. Последний шаг в применении подхода программы Intel Modern Code включал масштабирование приложения, которое изначально исполнялось на одном узле, на многоядерную архитектуру, и на кластерную среду с множеством узлов. Это, на настоящий момент, основной предмет нашего исследования. Кроме того, мы применили оптимизации, ориентированные на повторное использование кэш-памяти, что позволило улучшить производительность вычислений. Подробности о подобных оптимизациях можно найти здесь. Оптимизация кода для процессоров Intel Xeon Phi семейства x200 включала в себя использование памяти MCDRAM с высокой пропускной способностью и работу в режиме NUMA.
Оптимизация Caffe для архитектуры Intel не только значительно улучшила производительность вычислений, но и позволила извлекать гораздо более сложные наборы признаков из графических данных. Если вы используете в собственных нейросетевых исследованиях Caffe, запуская код на системах с процессорами Intel, оптимизированная версия этой платформы значительно расширит ваши возможности.
Кроме того, надеемся, что наш рассказ об улучшении кода, об инструментах для анализа скорости работы и оптимизации программ, поможет вам в деле улучшения производительности ваших приложений, как относящихся к сфере глубокого обучения нейронных сетей, так и любых других.
Intel хотела бы выразить благодарность Борису Гинзбургу за его идеи и первоначальный вклад в разработку многопоточной OpenMP-версии Caffe, оптимизированной для архитектуры Intel.
Подробности о программе Intel Modern Code можно почитать здесь и здесь.
Еле удержались, чтобы не пошутить про руссиано)
Вот, например, Caffe – популярная платформа для разработки нейронных сетей глубокого обучения. Её создали в Berkley Vision and Learning Center (BVLC), она пришлась по душе сообществу независимых разработчиков, которые вносят посильный вклад в её развитие. Платформа живёт и развивается, доказательство тому – статистика на странице проекта в GitHub. Caffe называют «быстрой открытой платформой для глубокого обучения». Можно ли ускорить такой вот «быстрый» набор инструментов? Задавшись этим вопросом, мы решили оптимизировать Caffe для архитектуры Intel.
Забегая вперёд, отметим, что Caffe, благодаря интеграции с Intel Math Kernel Library 2017 и набору оптимизаций, которые мы выполнили, следуя плану, изложенному в этом материале, стала работать на процессорах Intel более чем в 10 раз быстрее базовой версии, которую мы, в дальнейшем, будем называть BVLC Caffe. Версию, оптимизированную для архитектуры Intel, дальше, для краткости, будем называть Intel Caffe. Вот её исходный код.
Основные направления улучшения производительности, подробности о которых читайте ниже, заключались в рефакторинге кода, в его оптимизации в расчёте на использование наборов векторных инструкций, таких, как Intel AVX2, в тонкой настройке компиляции, в повышении эффективности многопоточного исполнения кода с использованием OpenMP. Испытания проводились на системе с двумя процессорами Intel Xeon. В частности, мы исследовали скорость нейронной сети, построенной средствами Caffe, при работе с изображениями из набора CIFAR-10. Результаты исполнения программы анализировали в Intel VTune Amplifier XE 2017 и с помощью других инструментов.
Похожий подход можно использовать для улучшения производительности самых разных программ, например, других платформ для глубокого обучения нейронных сетей.
Прежде чем переходить к вопросам оптимизации, расскажем об алгоритмах глубокого обучения и о задачах, которые решают с их помощью.
Об алгоритмах глубокого обучения
Алгоритмы глубокого обучения – это часть более общего класса алгоритмов машинного обучения, которые в последние годы показали значительные результаты в распознавании образов на фото и видео, в распознавании речи, в обработке естественного языка, и в других областях, где приходится иметь дело с огромными объёмами информации и решать задачи анализа данных. Успех глубокого обучения базируется на последних достижениях в области вычислений и алгоритмов, в возможностях обрабатывать большие наборы данных. Принцип работы таких алгоритмов заключается в том, что данные пропускают через слои сети, в которых производится преобразование информации, извлечение из неё всё более сложных признаков.
Вот пример того, как каждый уровень глубокой нейронной сети обучен идентифицировать признаки всё более высокой сложности. Здесь показан небольшой набор признаков, распознаваемых глубокой сетью, визуализированный в виде изображений в оттенках серого. Здесь же показаны исходные цветные изображения, обработка которых ведёт к выделению этих признаков. Изображение взято отсюда.
Свёрточная нейронная сеть
Для работы алгоритмов глубокого обучения с учителем требуется размеченный набор данных. Три популярных типа глубоких нейронных сетей, которые обучают с учителем, это многослойный перцептрон (Multilayer Perceptron, MLM), свёрточные нейронные сети (Convolution Neural Network, CNN), и рекуррентные нейронные сети (Recurrent Neural Network, RNN). В этих сетях входные данные, при прохождении их через каждый слой сети, подвергают сериям линейных и нелинейных преобразований. В итоге формируются выходные данные сети. Ответ сети сравнивают с ожидаемым результатом, находят ошибки, затем, для выходного слоя, вычисляют вектор градиента поверхности ошибок, выясняют, какой вклад в ответ сети вносят синаптические веса нейронов, с учётом активационных функций, после чего выполняют такую же процедуру для других слоёв, применяя ранее полученные данные. Этот метод обучения называют алгоритмом обратного распространения ошибки, в результате его применения производится пошаговая модификация весовых коэффициентов нейронов сети.
В многослойных перцептронах входные данные в каждом слое (представленном вектором) сначала умножают на полностью заполненную матрицу весовых коэффициентов, уникальную для слоя. В рекуррентных сетях такая матрица (или матрицы) одна и та же для каждого слоя (так как слой рекуррентный), и свойства сети зависят от входного сигнала. Свёрточные сети похожи на многослойные перцептроны, но они используют разреженные матрицы для скрытых слоёв, называемых свёрточными. В таких сетях умножение матриц представлено свёрткой матричного представления весов с матричным представлением входных данных слоя. Свёрточные сети популярны в распознавании изображений, но они находят применение и в распознавании речи, и в обработке естественных языков. Здесь можно почитать о таких сетях подробнее.
Caffe, CIFAR-10 и классификация изображений
Как уже было сказано, здесь мы собираемся оптимизировать для архитектуры Intel BVLC Caffe – популярную платформу для создания и исследования сетей глубокого обучения. Испытывать исходную и оптимизированную версию платформы будем, используя набор данных CIFAR-10, который часто применяют в задачах классификации изображений, и модель нейронной сети, построенную в Caffe.
Пример изображений из набора CIFAR-10
Набор данных CIFAR-10 состоит из 60000 цветных изображений размером 32x32 пикселя, разделённых на 10 классов: самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик. Классы не пересекаются. Например, здесь нет перекрытия между классами «автомобиль» и «грузовик». К «автомобилям» относятся, например, седаны и внедорожники. В класс «грузовик» входят только тяжёлые грузовики, а, например, грузовиков-пикапов нет ни в одной из групп изображений.
Сеть, используемая в ходе тестирования производительности, содержит слои различных типов. В частности, это слои с сигмоидной функцией активации (такие слои, в терминологии Caffe, имеют тип Sigmoid), свёрточные слои (тип Convolution), слои пространственного объединения или, как их ещё называют, слои подвыборки (тип Pooling), слои пакетной нормализации (тип BatchNorm), полносвязные слои (тип InnerProduct). На выходе сети находится слой с активационной функцией Softmax (тип SoftmaxWithLoss). Подробнее об этой сети и её слоях мы поговорим ниже. А сейчас приступим к анализу исходной версии Caffe.
Первоначальный анализ производительности
Один из методов оценки производительности BVLC Caffe и Intel Caffe заключается в использовании команды time, которая вычисляет время, необходимое для прохождения сигнала по слоям в прямом и обратном направлении. Эта команда весьма полезна для измерения времени, которое затрачивается на вычисления в каждом уровне, и для получения сравнительного времени исполнения для различных моделей:
./build/tools/caffe time --model=examples/cifar10/cifar10_full_sigmoid_train_test_bn.prototxt -iterations 1000В данном случае «итерацией» (тем, что задаёт параметр iteration) называется один прямой и обратный проход по пакету изображений. Вышеприведённая команда выводит среднее время исполнения для 1000 итераций, как для отдельных слоёв, так и для всей сети. Вот результаты работы этой команды для BVLC Caffe.
Вывод команды time для BVLC Caffe
В тестах мы использовали систему с двумя сокетами. В каждом был установлен процессор Intel Xeon E5-2699 v3 (2.3 ГГц) с 18-ю физическими ядрами. При этом технология Intel Hyper-Threading была отключена. В системе, таким образом, было всего 36 физических процессорных ядер и такое же число потоков OpenMP, что было задано с помощью переменной окружения OMP_NUM_THREADS. Если не указано иное, в наших экспериментах использовалась именно такая конфигурация. Обратите внимание на то, что мы рекомендуем позволить Intel Caffe автоматически настраивать переменные окружения OpenMP, вместо того, чтобы задавать их самостоятельно. В системе, кроме того, установлено 64 Гб DDR4-памяти, которая работает на частоте 2.133 МГц.
Здесь показаны результаты тестирования производительности, которых удалось достичь благодаря оптимизации кода инженерами Intel. Для измерения производительности мы использовали следующие инструменты:
- Callgrind из набора инструментов Valgrind.
- Intel VTune Amplifier XE 2017 beta.
Средства из Intel VTune Amplifier XE предоставляют следующие сведения:
- Функции, создающие наибольшую нагрузку на систему (hotspots).
- Системные вызовы (в том числе – переключение задач).
- Использование процессора и кэш-памяти.
- Распределение нагрузки по потокам OpenMP.
- Блокировки потоков.
- Использование памяти.
Анализы производительности можно использовать для поиска подходящих кандидатов на оптимизацию, таких, как функции, создающие большую нагрузку на систему, и вызовы функций, которые выполняются сравнительно долго.
На рисунке ниже показаны обобщённые данные анализа производительности BVLC Caffe из Intel VTune, полученные после выполнения 100 итераций. Показатель Elapsed Time, расположенный в верхней части рисунка, составляет 37 секунд. Это – время, которое понадобилось для выполнения кода на тестовой системе. Показатель CPU Time, процессорное время, составляет 1306 секунд. Это немного меньше, чем 37 секунд, умноженные на 36 ядер (1332 секунды). Данный показатель представляет собой общую длительность исполнения кода во всех потоках (или на всех ядрах, так как в нашем случае технология Intel HT была отключена), которые используются в вычислениях.
Общие результаты анализа исполнения BVLC Caffe на наборе данных CIFAR-10 в Intel VTune Amplifier XE 2017 beta
Гистограмма использования процессора, которая находится в нижней части рисунка, указывает на то, как часто в ходе теста определённое количество потоков задействуется одновременно. В данном случае, из 37 секунд, 14 приходится на один поток (то есть – на одно ядро). Всё остальное время мы видим весьма неэффективную многопоточную обработку, при этом, в основном, в работе участвуют менее 20 потоков.
Раздел Top Hotspots, расположенный в середине рисунка, указывает на то, на какие функции приходится больше всего работы. Здесь перечислены вызовы функций и вклад каждой из них в общее время работы процессора. Функция kmp_fork_barrier – это внешняя OpenMP-функция, на исполнение кода которой уходит 1130 секунд процессорного времени. Это означает, что около 87% рабочего времени процессора уходит на то, что потоки бездействуют в этой барьерной функции, не делая ничего полезного.
В исходном коде BVLC Caffe имеется строчка #pragma omp parallel. Однако в самом коде не наблюдается явного использования библиотеки OpenMP для организации многопоточной обработки данных. При этом внутри Intel MKL потоки OpenMP используются для распараллеливания выполнения некоторых базовых математических расчётов. Для того, чтобы подтвердить это распараллеливание, мы можем воспользоваться вкладкой Bottom-up в Intel VTune XE, содержимое которой, после тестирования BVLC Caffe на наборе данных CIFAR-10, приведено на рисунке ниже. Здесь можно найти перечень вызовов функций и дополнительные сведения о них. В частности, нас интересуют показатели Effective Time by Utilization (верхняя часть вкладки) и показатели распределения нагрузки, создаваемой функциями, по потокам (нижняя часть).
Визуализация временных параметров исполнения функций и перечень функций, сильнее всего нагружающих систему при исполнении BVLC Caffe на наборе данных CIFAR-10
Функция gemm_omp_driver_v2 – это часть библиотеки libmkl_intel_thread.so – обобщённая реализация умножения матриц (GEMM) из Intel MKL. Во внутренних механизмах этой функции задействована OpenMP-многопоточность. Функция умножения матриц из Intel MKL – это основная функция, используемая в процедурах прямого и обратного распространения, то есть, в операциях получения ответа сети и её обучения. Intel MKL использует многопоточное исполнение, что обычно уменьшает время выполнения GEMM-вычислений. Однако, в данном конкретном случае операция свёртки для изображений размером 32x32 создаёт не слишком большую нагрузку на систему, что не позволяет эффективно использовать все 36 OpenMP-потока на 36 ядрах в одной GEMM-операции. Поэтому, как будет показано ниже, требуется использование различных схем многопоточности и параллелизации исполнения кода.
Для того, чтобы продемонстрировать дополнительную нагрузку на систему, которую создаёт необходимость работать со множеством потоков OpenMP, мы запустили тот же код с переменной окружения OMP_NUM_THREADS=1, а затем сравнили время исполнения с предыдущим результатом. То, что у нас получилось, представлено на рисунке ниже. Здесь мы видим показатель Elapsed Time, равный 31.1 секунде, вместо 37 секунд из предыдущего испытания. Записав в переменную окружения единицу, мы принудили OpenMP к созданию только одного потока и к использованию его для исполнения кода. Полученная разница в почти шесть секунд указывает на дополнительную нагрузку на систему, которую вызывают операции инициализации и синхронизации потоков OpenMP.
Общие результаты анализа исполнения BVLC Caffe на наборе данных CIFAR-10 в Intel VTune Amplifier XE 2017 beta при использовании одного потока
В центральной части вышеприведённого рисунка имеется список функций, наиболее сильно нагружающих систему. Среди них мы обнаружили три основных кандидата на оптимизацию. А именно – это функции im2col_cpu, col2im_cpu, и PoolingLayer::Forward_cpu.
Оптимизация кода
Работа с набором данных CIFAR-10 с в среде Caffe, оптимизированной для архитектуры Intel, примерно в 13.5 раз быстрее, чем при использовании BVLC Caffe. На рисунке ниже представлены средние результаты после 1000 итераций. Слева приведены данные BVLC Caffe, справа – Intel Caffe. Видно, что в первом случае общее время выполнения составило 270 мс., а во втором – 20 мс.
Сравнение производительности BVLC Caffe и Intel Caffe
Подробности о том, как задавать параметры вычислений для слоёв, можно найти здесь.
В следующем разделе будут описаны оптимизации, использованные для улучшения производительности расчётов, применяемых в различных слоях. Мы следовали методическим руководствам из программы Intel Modern Code. Некоторые из оптимизаций основаны на базовых математических функциях из Intel MKL 2017.
Скалярная и последовательная оптимизация
?Векторизация кода
После профилирования кода BVLC Caffe и выявления наиболее нагруженных функций, потребляющих больше всего процессорного времени, мы начали работу над векторизацией кода. Среди внесённых изменений были следующие:
- Улучшение работы с библиотеками Basic Linear Algebra Subprograms (BLAS), а именно – переход с Automatically Tuned Linear Algebra System (ATLAS) на Intel MKL.
- Оптимизации в процессе сборки кода (использование JIT-ассемблера Xbyak).
- Векторизация кода с использованием GNU Compiler Collection (GCC) и OpenMP.
В BVLC Caffe имеется возможность использования вызовов функции Intel MKL BLAS или других реализаций тех же механизмов. Например, функция GEMM оптимизирована в расчёте на векторизацию, многопоточное исполнение и эффективное использование кэш-памяти. Для улучшения векторизации мы так же использовали Xbyak – JIT-ассемблер для архитектур x86 (IA-32) и x64 (AMD64 или x86-64). Xbyak поддерживает следующие наборы векторных инструкций: MMX, Intel Streaming SIMD Extensions (Intel SSE), Intel SSE2, Intel SSE3, Intel SSE4, модуль вычислений с плавающей запятой, Intel AVX, Intel AVX2 и Intel AVX-512.
Xbyak – это x86/x64-ассемблер для C++, библиотека, специально созданная для повышения эффективности исполнения кода. Xbyak предоставляется в виде заголовочного файла. Он может динамически собирать мнемонические инструкции для архитектур x86 и x64. JIT-генерация двоичного кода в процессе исполнения даёт дополнительные возможности оптимизации. Например, это оптимизация квантования, операции поэлементного деления одного массива на другой, или оптимизация полиномиальных вычислений благодаря автоматическому созданию нужных функций во время выполнения программы. Благодаря поддержке наборов векторных инструкций Intel AVX и Intel AVX2, с помощью Xbyak можно достичь лучшего уровня векторизации кода в Caffe, оптимизированном для архитектуры Intel. В самой свежей версии Xbyak имеется поддержка набора векторных инструкций Intel AVX-512. Это позволяет улучшить производительность вычислений на процессорах Intel Xeon Phi семейства x200.
Улучшение показателей векторизации даёт возможность Xbyak, с помощью SIMD-инструкций, обрабатывать больше данных одновременно, что позволяет более эффективно задействовать параллельную обработку данных. Мы использовали Xbyak при оптимизации кода, что значительно улучшило производительность расчётов в слоях пространственного объединения. Если известны параметры пространственного объединения, можно сгенерировать ассемблерный код для конкретных моделей объединения, в которых используется определённое окно обработки данных или алгоритм. В результате получается вполне обычная с виду сборка, которая, что доказано, работает эффективнее, чем код на C++, скомпилированный без использования Xbyak.
?Общие оптимизации кода
Другие последовательные оптимизации включали в себя следующее:
- Уменьшение сложности алгоритмов.
- Уменьшение объёма вычислений.
- Разворачивание циклов.
Избавление от многократного выполнения кода, результаты которого не меняются – это одна из техник скалярной оптимизации, которую мы применили. Это было сделано для того, чтобы заранее вычислить то, что иначе бы вычислялось внутри цикла с максимальной глубиной вложенности.
Рассмотрим, например, такой фрагмент кода:
for (int h_col = 0; h_col < height_col; ++h_col) {
for (int w_col = 0; w_col < width_col; ++w_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
int w_im = w_col * stride_w - pad_w + w_offset;В третьей строке этого фрагмента, для вычисления переменной h_im, не используется индекс внутреннего цикла w_col. Но, несмотря на это, вычисление данной переменной производится в каждой итерации вложенного цикла. Как вариант, мы можем переместить эту строчку за пределы внутреннего цикла, приведя код к такому виду:
for (int h_col = 0; h_col < height_col; ++h_col) {
int h_im = h_col * stride_h - pad_h + h_offset;
for (int w_col = 0; w_col < width_col; ++w_col) {
int w_im = w_col * stride_w - pad_w + w_offset;Оптимизации, специфичные для процессора, системы и другие общие подходы к улучшению кода
Вот какие дополнительные общие оптимизации кода были применены:
- Улучшение реализации функций im2col_cpu и col2im_cpu.
- Уменьшение сложности операции пакетной нормализации.
- Оптимизации, специфичные для процессора и системы.
- Использование одного ядра на вычислительный поток.
- Устранение перемещения потоков между вычислительными ядрами.
Intel VTune Amplifier XE выяснил, что функция im2col_cpu – одна из наиболее сильно нагружающих систему. Это значит, что она – хороший кандидат на оптимизацию производительности. Функция im2col_cpu – это реализация стандартного шага в операции прямой свёртки. Каждый локальный фрагмент разворачивается в отдельный вектор, всё изображение конвертируется в более крупную матрицу (что повышает интенсивность работы с памятью), строки которой соответствуют множеству мест, где были применены фильтры.
Одна из техник оптимизации для функции im2col_cpu заключается в сокращении числа операций, необходимых для доступа к данным. В коде BVLC Caffe имеется три вложенных цикла, в которых выполняется проход по пикселям изображения:
for (int c_col = 0; c_col < channels_col; ++c_col)
for (int h_col = 0; h_col < height_col; ++h_col)
for (int w_col = 0; w_col < width_col; ++w_col)
data_col[(c_col*height_col+h_col)*width_col+w_col] = // ...В этом фрагменте кода BVLC Caffe изначально вычислял соответствующие индексы массива элементов data_col, хотя индексы этого массива просто обрабатываются последовательно. Таким образом, четыре арифметических операции (два сложения и два умножения) можно заменить одной операцией инкрементации индекса. Кроме того, сложность проверки условия можно уменьшить исходя из следующего:
/* Функция использует приведение типа int к unsigned для проверки
того, является ли значение параметра a большим или равным нулю,
и меньшим, чем значение параметра b. Тип параметра b – unsigned,
он всегда положителен, таким образом, его значение всегда меньше,
чем 0x800…, при этом преобразование типа параметра с отрицательным
значением всегда приводит его к числу, которое больше, чем 0x800…
Приведение типов позволяет использовать одно условие вместо двух. */
inline bool is_a_ge_zero_and_a_lt_b(int a, int b) {
return static_cast<unsigned>(a) < static_cast<unsigned>(b);
}В коде BVLC Caffe была проверка условия вида if (x >= 0 && x < N), где x и N – целые числа со знаком, при этом N – всегда положительное число. Преобразование этих целых чисел к целым числам без знака позволяет изменить интервал сравнения. Вместо того, чтобы выполнять две операции сравнения и вычисление логического И, после преобразования типа достаточно одного сравнения:
if (((unsigned) x) < ((unsigned) N))Для того, чтобы избежать перемещения потоков операционной системой между вычислительными ядрами, мы использовали переменную среды OpenMP: KMP_AFFINITY = compact, granularity = fine. Компактное расположение соседних потоков может улучшить производительность операций GEMM, так как потоки, которые совместно работают с одним и тем же кэшем последнего уровня (last-level cache, LLC), могут повторно использовать данные, ранее записанные в строки кэша.
Вот материал, в котором можно найти подробности об оптимизации, связанной с блокированием кэша, об особенностях оптимальной компоновки данных и векторизации.
Параллелизация кода с использованием OpenMP
?Слои нейронной сети
В ходе применения OpenMP-параллелизации были оптимизированы следующие механизмы нейронной сети:
- Слой свёртки (Convolution).
- Слой обратного преобразования свёртки (Deconvolution).
- Слой локальной нормализации (Local response normalization, LRN).
- Слой с полулинейной функцией активации (Rectified-Linear Unit, ReLU)
- Слой с функцией активации Softmax.
- Слой объединения (Concatenation).
- Утилиты для OpenBLAS-оптимизации, такие как операция vPowx — y[i] = x[i]?, операции caffe_set, caffe_copy, и caffe_rng_bernoulli.
- Слой пространственного объединения, или подвыборки (Pooling).
- Слой «прореживания» сети для предотвращения эффекта переобучения (Dropout).
- Слой пакетной нормализации (Batch normalization).
- Слой данных (Data).
- Слой для выполнения поэлементных операций (Eltwise).
?Слой свёртки
Слой свёртки, что вполне соответствует его названию, выполняет свёртку входных данных, используя набор модифицированных в ходе обучения сети весов, или фильтров, каждый из которых позволяет получить одну карту признаков в выходном изображении. Эта оптимизация предотвращает недостаточное использование аппаратных ресурсов для одного набора входных карт признаков.
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
// Если имеется больше доступных потоков, чем пакетов для обработки, значит
// мы впустую используем ресурсы (меньше пакетов, чем 36
// на нашей тестовой системе).
// Сообщим об этом MKL.
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
#ifdef _OPENMP
#pragma omp parallel for num_threads(this->num_of_threads_)
#endif
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n*this->bottom_dim_,
weight,
top_data + n*this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}Мы обрабатываем k = min(num_threads,batch_size) наборов карт input_feature. Например, k операций im2col происходят параллельно и выполняется k обращений к Intel MKL. Intel MKL переключается в однопоточный режим исполнения автоматически и общая производительность оказывается лучше, чем ранее, когда Intel MKL обрабатывала один пакет. Такое поведение задано в файле с исходным кодом src/caffe/layers/base_conv_layer.cpp. Это реализация оптимизированной многопоточной обработки с использованием OpenMP из файла с исходным кодом src/caffe/layers/conv_layer.cpp.
?Слой подвыборки
Max-pooling, average-pooling, и stochastic-pooling (ещё не реализованный) – это разные методы понижающей дискретизации, при этом max-pooling – самый популярный метод. Слой подвыборки разбивает результат, полученный от предыдущего слоя, на набор обычно не перекрывающихся прямоугольных фрагментов. Для каждого такого фрагмента слой затем выводит максимум (max-pooling), арифметическое среднее (average-pooling), или (в будущем) стохастическое значение (stochastic-pooling), полученное из мультиномиального распределения, сформированного из функций активации каждого фрагмента.
Слои подвыборки полезны в свёрточных сетях по трём основным причинам:
- Подвыборка уменьшает размерность задачи и вычислительную нагрузку на вышележащие слои.
- Подвыборка для нижележащих слоёв позволяет ядрам свёртки в слоях, расположенных выше, покрывать большие области входных данных, и, таким образом, обучаться более сложным признакам. Например, ядро из слоя, расположенного ниже, обычно обучается распознавать небольшие элементы изображения, в то время как ядро слоя, расположенного выше, может обучаться распознаванию более сложных структур, таких, как изображения лесов или пляжей.
- Метод max-pooling повышает устойчивость сети к сдвигу изображения. Из восьми возможных направлений в которых фрагмент 2x2 (обычный размер окна подвыборки) может быть сдвинут на один пиксель, три дадут то же самое максимальное значение. Для окна 3x3 уже пять направлений дадут то же самое максимальное значение.
Подвыборка работает на одной карте признаков, поэтому мы использовали Xbyak для того, чтобы выполнить эффективную процедуру сборки, которая поможет создать нужную нам выборку для одной или большего количества входных карт признаков. Эта методика может быть реализована для пакета входных карт признаков, когда процедура выполняется параллельно в OpenMP.
Вычисления слоя подвыборки выполняются параллельно, с использованием OpenMP-многопоточности. Это возможно благодаря тому, что изображения независимы:
#ifdef _OPENMP
#pragma omp parallel for collapse(2)
#endif
for (int image = 0; image < num_batches; ++image)
for (int channel = 0; channel < num_channels; ++channel)
generator_func(bottom_data, top_data, top_count, image, image+1,
mask, channel, channel+1, this, use_top_mask);
}Благодаря выражению collapse(2), директива OpenMP #pragma omp parallel распространяется на оба вложенных цикла for, которые выполняют проход по изображениям в пакете и каналам изображений, комбинируя циклы в один и исполняя параллельно то, что получилось.
?Слой Softmax и функция потерь
Функция потерь – это ключевой компонент в машинном обучении. Именно эта функция используется при сравнении выхода сети с целевым показателем, для поиска ошибки. После этого производится настройка весовых коэффициентов сети для уменьшения значения этой функции, то есть, для уменьшения ошибки, отклонения того, что выдаёт сеть, от желаемого выхода. В нашей модели в качестве функции потерь используется softmax (тип слоя – SoftmaxWithLoss).
Такую функцию активации используют в том случае, когда выходы сети символизируют вероятность неких событий, или, как в нашем случае, вероятность принадлежности изображений к различным классам. В частности, в мультиномиальной логистической регрессии (проблема классификации на множество классов), входные данные для этой функции – результат K различных линейных функций, и предсказанная вероятность j-того класса для вектора x вычисляется по такой формуле:
При многопоточном выполнении этих вычислений применяется подход с использованием главного и подчинённого потоков. Так, главный поток запускает некое число подчинённых, распределяя задачи между ними. Подчинённые потоки затем выполняются параллельно, так как они назначаются различным ядрам.
Например, в следующем коде параллельное выполнение отдельных арифметических операций с независимым доступом к данным реализовано с помощью разделения вычислений для различных каналов изображений:
// разделение
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data + j*inner_num_, scale_data,
top_data + j*inner_num_);
}?ReLU и сигмоидальная функции активации в полносвязных слоях
ReLU – это самый популярный на сегодня класс нелинейных функций, используемых в алгоритмах глубокого обучения. Полносвязные слои – это поэлементные операторы, которые берут двоичный объект (blob в терминологии Caffe), выдаваемый нижележащим слоем, и подают на вышележащий слой преобразованный набор данных того же размера. (Такой набор данных – это обычный массив, представляющий унифицированный интерфейс платформы Caffe. Когда данные и найденные ошибки распространяются по сети, Caffe работает с информацией в виде таких объектов).
Слой с активационной функцией ReLU берёт входное значение x и подаёт на выход то же самое x, если оно больше нуля, а отрицательные значения перемножает на параметр negative_slope по такой формуле:
По умолчанию значение параметра negative_slope равняется нулю, что эквивалентно стандартной функции ReLU, которая возвращает максимальное значение после сравнения переданного ей значения с нулём: max(x, 0). Из-за независимости процесса активации от данных, каждый набор данных может быть обработан параллельно:
template <typename Dtype>
void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const int count = bottom[0]->count();
Dtype negative_slope=this->layer_param_.relu_param().negative_slope();
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
top_data[i] = std::max(bottom_data[i], Dtype(0))
+ negative_slope * std::min(bottom_data[i], Dtype(0));
}
}Похожие параллельные вычисления можно использовать и в процедуре обратного распространения ошибки:
template <typename Dtype>
void ReLULayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = bottom[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const int count = bottom[0]->count();
Dtype negative_slope=this->layer_param_.relu_param().negative_slope();
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0)
+ negative_slope * (bottom_data[i] <= 0));
}
}
}Таким же образом можно распараллелить вычисление сигмоидной функции S(x) = 1 / (1 + exp(-x)):
#ifdef _OPENMP
#pragma omp parallel for
#endif
for (int i = 0; i < count; ++i) {
top_data[i] = sigmoid(bottom_data[i]);
}Так как MKL не предоставляет базовых математических операций для реализации ReLU-функций, для того, чтобы добавить этот функционал в систему, мы попытались реализовать оптимизированную версию ReLU-слоя на ассемблере (с использованием Xbyak). Однако, после испытаний, мы не обнаружили заметного роста производительности на процессорах Intel Xeon. Возможно это так из-за ограниченной пропускной способности памяти. Параллелизация существующего кода на C++ оказалась достаточно хорошей для улучшения общей производительности.
Выводы
В предыдущем разделе мы рассмотрели различные компоненты и слои нейронных сетей, и то, как данные, обрабатываемые в этих слоях, распределяются по потокам OpenMP и Intel MKL. Гистограмма использования процессора, приведённая ниже, показывает, насколько часто некое число потоков выполняется параллельно после оптимизации кода.
Общие результаты анализа исполнения реализации Caffe, оптимизированной для архитектуры Intel, на задаче CIFAR-10 в Intel VTune Amplifier XE 2017 beta
С использованием Caffe, оптимизированного для архитектуры Intel, число одновременно выполняющихся потоков значительно возросло. Время исполнения на нашей тестовой системе упало с 37 секунд для неоптимизированного кода BVLC Caffe, до всего 3.6 секунд для оптимизированной версии. Общая производительность выросла более чем в 10 раз.
Ка показано в разделе Elapsed Time, в верхней части рисунка, часть времени исполнения относится к показателю Spin Time, что указывает на время, которое тратится на ожидание, а не на полезную работу. В результате производительность не растёт линейно при увеличении числа потоков (в соответствии с законом Амдала). Кроме того, здесь всё ещё имеются участки, исполняющиеся последовательно, не параллелизованные с использованием OpenMP. Повторная инициализация параллельных участков OpenMP была значительно оптимизирована для последних реализаций библиотеки OpenMP, но она всё ещё создаёт довольно заметную дополнительную нагрузку на систему. Перемещение параллельных участков в главную функцию может, в потенциале, улучшить производительность даже больше, но это потребует значительного рефакторинга кода.
На рисунке ниже обобщены описанные техники оптимизации и принципы переработки кода, которым мы следовали, занимаясь оптимизацией Caffe для архитектуры Intel.
Пошаговый подход программы Intel Modern Code
В ходе испытаний мы пользовались Intel VTune Amplifier XE 2017 beta для поиска участков кода, которые создают наибольшую нагрузку на систему, и оптимизация которых способна принести заметный выигрыш в производительности. Мы реализовали скалярные и последовательные оптимизации, включая устранение кода, результаты выполнения которого оказываются одними и теми же при многократном вызове. Так же мы провели сокращение или упрощение арифметических операций, оптимизировав циклы и проверки условий. Далее мы улучшили код в расчёте на его векторизацию, следуя общим принципам, изложенным в материале об автоматической векторизации в GCC. Применение JIT-ассемблера Xbyak позволило нам более эффективно задействовать SIMD-инструкции.
Мы реализовали многопоточность для вычислений, проводимых внутри слоёв нейронной сети с помощью библиотеки OpenMP, там, где операции над изображениями или каналами были независимы от данных. Последний шаг в применении подхода программы Intel Modern Code включал масштабирование приложения, которое изначально исполнялось на одном узле, на многоядерную архитектуру, и на кластерную среду с множеством узлов. Это, на настоящий момент, основной предмет нашего исследования. Кроме того, мы применили оптимизации, ориентированные на повторное использование кэш-памяти, что позволило улучшить производительность вычислений. Подробности о подобных оптимизациях можно найти здесь. Оптимизация кода для процессоров Intel Xeon Phi семейства x200 включала в себя использование памяти MCDRAM с высокой пропускной способностью и работу в режиме NUMA.
Оптимизация Caffe для архитектуры Intel не только значительно улучшила производительность вычислений, но и позволила извлекать гораздо более сложные наборы признаков из графических данных. Если вы используете в собственных нейросетевых исследованиях Caffe, запуская код на системах с процессорами Intel, оптимизированная версия этой платформы значительно расширит ваши возможности.
Кроме того, надеемся, что наш рассказ об улучшении кода, об инструментах для анализа скорости работы и оптимизации программ, поможет вам в деле улучшения производительности ваших приложений, как относящихся к сфере глубокого обучения нейронных сетей, так и любых других.
Intel хотела бы выразить благодарность Борису Гинзбургу за его идеи и первоначальный вклад в разработку многопоточной OpenMP-версии Caffe, оптимизированной для архитектуры Intel.
Подробности о программе Intel Modern Code можно почитать здесь и здесь.
Поделиться с друзьями
ternaus
xgboost бы вы так оптимизировали — цены бы вам не было
atikhonov
так он же OpenMP поддерживает, да и реализовано оно.