

Сначала этот текст был написан в виде комментария к теме победителя данного конкурса. Но в итоге объем текста стал таким большим, что было решено выделить его в отдельную тему. Так что предполагается, что читатель в курсе о конкурсе и прочёл тему победителя. Также можете почитать историю 30-го места.
Сразу дам ссылку на репозиторий с исходным кодом — помимо непосредственно исходников там же есть вся история коммитов. Например, интересным может показаться время, в которое был совершён коммит с комментарием «спать пора».
В целом, сложилось такое ощущение, что у большинства лидеров были примерно одинаковые основные идеи для итоговой стратегии:
- Поиск пути по карте между вейпоинтами
- Симуляция движения, коллизий и прочей физики
- Перебор различных действий, которые приводят к разным траекториям из текущей позиции в будущее
- Выбор лучшего действия или траектории на основе какой-то функции оценки
Так что в данной теме я расскажу чуть подробнее о том, как эти идеи были реализованы в моём случае.
Поиск пути
Я рассматривал задачу поиска пути чуть более широко, чем может показаться. Хотелось сделать такую структуру данных и алгоритм, чтобы можно было быстро узнавать ответ на вопрос следующего вида: «если я нахожусь в точке X, Y и мой следующий вейпоинт N, то сколько мне осталось до следующего вейпоинта?». Такое требование пришло от того, что подобные запросы будут поступать от «переборщика» несколько тысяч раз в течение одного принятия решения, чтобы оценивать полученные траектории.
Первая версия работала просто с помощью поиска пути из произвольной клетки, куда попала точка X Y до следующего вейпоинта, а в качестве ответа выдавала длину пути. При этом за относительное расположение точки X Y внутри клетки также давался некоторый бонус, чтобы сделать оценку чуть более похожей на непрерывную.
Где-то ко второму раунду стали появляться карты, где у такого простого поиска пути по клеткам появлялись проблемы. Например:
— С какой стороны подъезжать к вейпоинту?
— Как бы сделать так, чтобы при взятии вейпоинта машина не пыталась ехать задним ходом к следующему, если можно почти без потерь просто проехать прямо и сделать небольшой крюк?
— Как сделать поиск пути с учётом разворота для заднего хода?
В результате появилась идея изменить структуру данных и сам запрос: «если я нахожусь в точке X, Y, мой угол A и следующий вейпоинт N, то сколько мне осталось до финиша?»
Для того, чтобы отвечать на такой запрос, нужно было придумать устройство графа, по которому будет идти поиск пути. В результате получилось следующее:
— Узел графа — это «подклетка с направлением» — клетка размером 400х400, с 8 возможными направлениями (с шагом 45 градусов).
— Соседей у такого узла было 6 штук: 1 сосед — ехать «прямо», 2 соседа — ехать «прямо с поворотами», 1 сосед — ехать «назад», 2 соседа — ехать «назад с поворотами».
— Длина рёбер соответственно была 1 для прямого движения, sqrt(2) для диагонального, а для заднего хода — умножалось ещё на какую-то константу. В финальной версии эта константа была равна 15. Такое значение было подобрано руками, чтобы автомобиль не сильно долго ездил задним ходом и при первой же возможности разворачивался, но при этом позволяло брать всякие идиотские вейпоинты, которые находятся на пару тайлов сзади от текущего, без разворотов.
— Учёт стен от «больших» 800х800 клеток, чтобы не порождать лишних соседей на уровне «подклеток» 400х400.
Было очень много багов с таким поиском пути. В частности потому, что сам путь искался начиная не от точки запроса, а начиная от финиша. То есть если у нас спросили «если я нахожусь в точке 0, 0, мой угол 0 и следующий вейпоинт 1», то надо было сначала найти расстояние от финиша (0-й вейпоинт) до предыдущего вейпоинта (N-1-й вейпоинт), потом от предыдущего вейпоинта рекурсивно находить путь до 1-го вейпоинта и только потом искать путь от 1-го вейпоинта до точки запроса. Из-за того, что такой поиск происходил с «конца» в «начало», было много путаницы с определением соседей для узла — особенно сложно было определить направление у соседей.
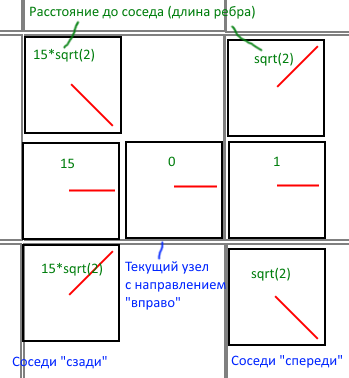
Выше — пример соседей для узла с направлением кратным 90 градусов. Немного по-другому выглядят соседи для «диагональных» направлений, но суть та же.
Ближе к финалу удалось отладить такой механизм и на неизвестных картах автомобиль выбирал довольно интересные пути, чтобы можно было объезжать вейпоинты в правильном порядке и с минимальным задним ходом. При этом сначала штраф за задний ход не был таким высоким и в отсутствии помех такое решение даже ездило быстрее. Но в финале на «проблемных» вейпоинтах постоянно была свалка и хаос, так что было лучше проскочить такой вейпоинт без замедления и сделать крюк — это позволит избежать толкучки на вейпоинте и взять побольше бонусов по дороге. Надо также понимать, что сама траектория не обязана следовать пути, полученному из точки с автомобилем — главное, чтобы лучшая траектория вывела в точку, которая будет «ближе всего к финишу».
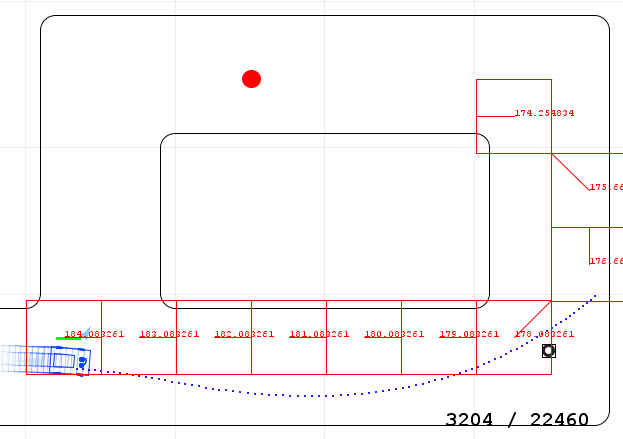
Вот как-то так выглядел «лучший путь», найденный от текущей точки автомобиля в будущее. Можно заметить, что автомобиль решил поворачивать не сразу «по-жадному» к вейпоинту, а заехать к нему «сзади».
Сам алгоритм поиска пути — это была ленивая реализация алгоритма Дейкстры, где все пути считались по запросу и кэшировались. В финале кэш иногда сбрасывался, если открывались новые неизвестные клетки.
Исходный код — см. класс CWaypointsDistanceMap
Симуляция
Изначально физика работала только в виде следующего механизма: на вход подавалась «машина» + «действие», на выходе получалась «машина на следующем тике». Сам код симуляции был честно позаимствован у Mr.Smile из его сообщения на форуме и адаптирован в дальнейшем, добавив простейшие проверки на столкновения со стенами — в таком случае перебор просто прекращался. Затем к этому коду потихоньку были прикручены правильные расчёты торможения, нитро, масла. В конце концов возникла необходимость правильного рассчёта коллизий, т.к. некоторые повороты было выгоднее проходить с коллизиями, чем без. Особенно на старте при неудачной позиции.
В общем, где-то к окончанию второго раунда удалось разобраться в коде коллизий из notreal2d, добиться практически абсолютной точности, а потом даже упростить код — ведь notreal2d это слишком «общий» движок, а в нашем мире стены есть только 3-х типов — прямая вертикальная или горизонтальная линия, кружок радиусом 80 и вогнутая арка. На вогнутые арки было решено забить, т.к. код с ними не удалось отладить, чтобы работал стабильно и точно.
Но также мою голову не покидала мысль одновременной симуляции всех объектов в мире — всех автомобилей, снарядов и т.д. В конце концов симулятор одной машины превратился в симулятор «мира», т.е. ему на вход подавался «мир» + «действия всех автомобилей», а на выходе получался «мир на следующем тике». Действия вражеских автомобилей предполагались, как «тапка в пол».
На реализацию и отладку такого симулятора ушла наверное большая часть всего времени. Коэффициенты трения подбирались вручную, код поиска и разрешения коллизий копировался и переписывался из notreal2d, а в конце концов поиск коллизий был написан вручную для оптимизации. Было огромное количество багов, связанных с коллизиями с «концами» стен — в итоге я просто избавился от концов стен. Также нужно было аккуратно отладить коллизии машин друг с другом и с шинами. А коллизии с бонусами так и не были написаны правильно. Очень много слабых мест по скорости помог найти встроенный в VS 2015 профилировщик — огромное ему спасибо.
Исходный код — см. класс CWorldSimulator.
Переборщик
Сравнивая с тем, что сделал santa324 можно сказать, что переборщик — это было самое слабое место моей стратегии. Были идеи сделать что-то существенно новое: генетический алгоритм, или «мутирующие» деревья, или ещё что-нибудь, но сил уже не осталось.
В целом, основная идея того переборщика, который в итоге использовался, была в том, что траектории будут искаться с помощью перебора некоторого фиксированного множества действий. Например:
- Ехать прямо/налево/направо 0/7/15/40/60 тиков с тормозом/без тормоза
- Потом ехать прямо/налево/направо 0/40 тиков
- Потом ещё раз ехать прямо/налево/направо 0/40 тиков
- И в качестве последнего действия — ехать прямо до окончания глубины перебора
Одна из первых версий умела перебирать только один поворот и одно торможение и этого было недостаточно для выполнения манёвров типа «перестроиться подальше от поворота, чтобы потом зайти в поворот с большим радиусом» или дрифта. В конце концов была выбрана описанная выше структура с тремя поворотами/торможениями и ездой прямо до окончания глубины перебора, которая была равна 150 тикам. Но даже такую структуру пришлось существенно урезать, когда симуляция физики была изменена с одного автомобиля без коллизий до симуляции «всего мира» с коллизиями. Чтобы уложиться в таймлимит некоторые ветви включались и выключались с шансом 50%. А также длины действий были размазаны с помощью рандома.
Существенное улучшение траекторий произошло тогда, когда лучшая найденная последовательность действий на текущем тике сохранялась для того, чтобы вспомнить её на следующем тике и заново оценить с коррекцией длительностей всех действий на минус 1. Такое «запоминание лучшей траектории» добавило элемент эволюционного алгоритма в переборщик и помогло рулить более-менее адекватно даже тогда, когда из-за рандома несколько тиков подряд не находилось новой хорошей траектории.
В качестве функции оценки в переборщике служила сумма из различных слагаемых. Основное слагаемое — то самое «сколько осталось до финиша, если я оказался в точке X Y с углом A и мой следующий вейпоинт N?». Затем были добавлены слагаемые за бонусы, въезд в лужи, потерю жизней и т.д — это позволяло выбирать возможно не самые оптимальные траектории с точки зрения расстояния до финиша, но зато подбирать бонусы, уворачиваться от снарядов и объезжать лужи.
Также под конец удалось переместить эвристики по нитро/стрельбе/лужам в этот переборщик следующим образом — для самой лучшей найденной траектории проверяли «а что будет, если я прямо сейчас включу нитро/выстрелю/разолью лужу?» и для каждого типа такого действия считалась своя собственная оценка. Если эта оценка преодолевала порог, то выполнялось действие.
Ещё в переборщик в самый последний момент перед финалом был добавлен «длинный задний ход», он запускался в том случае, если лучший путь из текущей клетки был «назад». К сожалению, мои тесты не показали существенного замедления от такого «длинного заднего хода», т.к. на всех картах, которых я тестировался локально задний ход практически не использовался. А тот код, который отвечал за задний ход до этого — был набор костылей в стиле смартгая и соответственно практически не отъедал времени. Пропущенное мною повышенное потребление времени стратегии привело к падениям по таймлимиту в первой волне карт финала, но об этом будет ниже.
Было потрачено очень много времени на задний ход и эксперименты над функцией оценки. Ведь такая «симуляция всего мира» давала огромные возможности. Например, в результате некоторых экспериментов джип мог выстрелить шиной в союзника, чтобы тот быстрее ехал. Или джип мог притормозить специально, чтобы едущий сзади противник с 1% жизнями врезался в джип и умер. Или когда автомобили на старте пытались вытолкнуть крайнего противника, чтобы тот столкнулся со стеной. Но к моему большому сожалению у меня не удалось отладить такие сложные функции оценки. Да и я не мог позволить себе глубокую симуляцию всех коллизий — в конечной версии «честная физика» просчитывалась только первые 40 тиков с точностью 2 подтика. А дальше уже коллизии не считались, и подтик был только один.
Ролик с визуализацией лучшего найденного пути и траектории для джипа (у остальных рисуется предполагается траектория на 40 тиков).
Исходный код — см. класс CBestMoveFinder
Контроль времени
На первой части финала моя стратегия проиграла 40 игр из-за таймлимитов, которые я по своей невнимательности не проконтролировал — стратегия отъедала в среднем 42мс на тик, при отведённых 30мс в среднем на тик. Первая волна карт в финале отличалась от всех остальных тем, что была о-о-очень медленной и большинство карт проходилось «впритык» по отведённым тикам, а в моём случае — даже впритык не удавалось, т.к. кончалось отведённое процессорное время. На остальных же картах чаще всего удавалось финишировать быстрее отведённого времени, т.к. оно было отведено «с запасом».
На КДПВ как раз скриншот типичного случая — стратегия не доезжала до финиша. Но в данной игре меня практически дотолкал до финиша участник под ником Antmsu.
Так что я был очень сильно расстроен, зол и практически в депрессии из-за
Другое
В этот раз было совершенно неясно, как тестировать стратегии и принимать решения о том, стало ли лучше или хуже. Так что дополнительно были написаны скрипты для запуска локальных тестов на всех картах, а также для беспрерывного запуска игр с ближайшими соперниками через интерфейс сайта. Плюс отдельные скрипты для скачивания и разбора результатов. Также был немного модифицирован код стратегии, чтобы была возможность «сохранять карты из repeater-а», которые в финале были полностью случайные.
Была ещё глупая попытка переписать класс-в-класс полностью весь движок notreal2d, на это было убито часов 10 и всё было удалено.
Ещё была попытка переделать переборщик на генетический алгоритм, где ген — это одно действие с длительностью. Но чего-то работающего достичь не удалось, как и придумать адекватную операцию скрещивания.
Ещё немного обидно, но в MyStrategy остался костыльный код для заднего хода, если машинка долго не двигалась, а также для переднего хода в стиле смартгая, если по каким-то причинам переборщик вообще не нашёл хороших траекторий. Сделать честный обсчёт таких ситуаций в переборщике не удалось.
Итого
В итоге на весь конкурс было потрачено очень большое количество времени. Не менее 100 часов, а скорее даже 150 или более. Конечно, не всё это — время кодирования, но мозг кипел и работал беспрерывно, даже во сне. В целом доволен результатом и очень рад, что удалось вырвать приз. Моё предыдущее участие в конкурсе было только в 2013 году и ограничилось 30-каким-то местом.
Огромное спасибо организаторам — по-моему, это был самый зрелищный и возможно самый интересный конкурс из прошедших. Соперники были очень сильные, приходилось «бежать со всех ног, чтобы только оставаться на месте», им тоже спасибо. Ну и отдельные благодарности Mr.Smile за ранее выкладывания «физики движения» автомобиля, JustAMan за удобный визуализатор на сокетах, Romka за интересные видео-новости и коллеге Angor за проведённые брейнштормы.
SannX
Пора заводить отдельный хаб «История N-ого места на Russian AI Cup YYYY». А так-то вы, участники, конечно молодцы.