

В английском есть такая аббревиатура — TIFU. Привести здесь её точное значение мы не можем, но вы без труда найдёте его в Сети. А после «литературной обработки» TIFU можно перевести как «сегодня я всё испортил». В контексте этого поста данная фраза относится к использованию функции Math.random() в JavaScript-движке V8. Хотя случилось это не сегодня, а пару лет назад. Да и дров я наломал не по своей вине, корень зла таится в самой этой функции.
«Многие генераторы случайных чисел, используемые сегодня, работают не слишком хорошо. Разработчики обычно стараются не вникать, как устроены такие подпрограммы. И часто бывает так, что какой-то старый, неудовлетворительно работающий метод раз за разом слепо перенимается многими программистами, которые зачастую просто не знают о присущих ему недостатках»
Дональд Кнут, «Искусство программирования», том 2.
Надеюсь, что к концу этого поста вы согласитесь с двумя утверждениями:
- Мы были идиотами, поскольку использовали генератор псевдослучайных чисел в V8, не понимая его ограничений. И если очень лень, то безопаснее использовать криптографически стойкие генераторы псевдослучайных чисел.
- В V8 необходима новая реализация Math.random(). Работу текущего алгоритма, кочующего от одного программиста к другому, нельзя считать удовлетворительной из-за слабой, неочевидной деградации, часто встречающейся в реальных проектах.
Хочу подчеркнуть, что сам движок V8 — замечательный продукт и его создатели очень талантливы. Я ни в коей мере не обвиняю их. Просто эта ситуация иллюстрирует, насколько сильно влияют на процесс разработки даже небольшие нюансы.
Работа проекта Betable зависит от случайных чисел. Помимо прочего, с их помощью генерируются идентификаторы. Поскольку архитектура представляет собой систему распределённых микросервисов, то реализовать случайные идентификаторы было легче, чем последовательные. К примеру, при каждом запросе API генерируются случайные идентификаторы запроса. Они помещаются в подзапросы в заголовках, логируются и используются для сравнения и корреляции всех происходящих событий во всех сервисах, в качестве результата одного-единственного запроса. Ничего сложного в генерировании случайных идентификаторов нет. Требование одно:
Вероятность двукратного генерирования одного и того же идентификатора — возникновения коллизии — должна быть крайне мала. На вероятность возникновения коллизии влияют два фактора:
- Размер идентификационного пространства — количество возможных уникальных идентификаторов.
- Метод генерирования идентификаторов — каким образом идентификатор выбирается из общего пространства.
В идеале нам нужно большое пространство, из которого случайно выбираются равномерно распределённые идентификаторы (раз уж мы предполагаем, что любой «случайный» процесс использует равномерное распределение).
Мы посчитали вероятность коллизии из парадокса дней рождений и приняли, что размер идентификатора запроса будет длиной в 22 символа, выбранных из словаря, содержащего 64 буквы. Например, EB5iGydiUL0h4bRu1ZyRIi или HV2ZKGVJJklN0eH35IgNaB. Поскольку каждый символ идентификатора может принимать одно из 64 значений, то наше идентификационное пространство имеет размер 6422 ? 2132. При таком размере пространства, если идентификаторы генерируются случайным образом со скоростью 1 млн в секунду, то вероятность возникновения коллизии в течение 300 лет будет составлять 1 к 6 млрд.
Хорошо, пространство получилось достаточно большим. Как нам осуществлять случайное генерирование? Напрашивается ответ: с помощью приличного псевдослучайного генератора (PRNG), который обычно можно найти во многих стандартных библиотеках. На верхнем уровне нашего стека находится сервис Node.js, а тот, в свою очередь, использует движок V8, разработанный Google для Chrome. Все совместимые реализации ECMAScript (JavaScript) должны использовать Math.random(), который без каких-либо аргументов возвращает случайное число от 0 до 1. На основе последовательности этих чисел от 0 до 1 нужно сгенерировать случайное слово, состоящее из 64 символов алфавита. Это довольно распространённая задача, для которой выработано стандартное решение:
var ALPHABET = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_';
random_base64 = function random_base64(length) {
var str = "";
for (var i=0; i < length; ++i) {
var rand = Math.floor(Math.random() * ALPHABET.length);
str += ALPHABET.substring(rand, rand+1);
}
return str;
}
Ссылка.
Не надо критиковать этот код, с ним всё в порядке, он делает именно то, что должен. Идём дальше. Разработали процедуру генерирования случайных идентификаторов с чрезвычайно низкой вероятностью возникновения коллизии. Тестируем, коммитим, пушим, тестируем, развёртываем. Вышеприведённый пример попал в production, и мы забыли о нём. Но однажды пришло письмо от одного коллеги, в котором сообщалось, что случилось невероятное:

«Каждый, кто допускает использование арифметических методов для генерирования случайных чисел, совершает грех». Джон фон Нейман говорил об очевидном: утверждение, что детерминистические методы (например, арифметические) не могут генерировать случайные числа, является тавтологией. Так что же такое PRNG?
Что такое генераторы псевдослучайных чисел?
Давайте рассмотрим простенький PRNG и результаты его работы:

Эта иллюстрация поясняет мысль фон Неймана: очевидно, что сгенерированная последовательность чисел не является случайной. Для многих задач этого вполне достаточно. Но нам нужен алгоритм, генерирующий числа, которые кажутся случайными. Технически они должны казаться независимыми и одинаково распределёнными случайными переменными, равномерно распределёнными по всему диапазону генератора. Другими словами, нам нужно безопасно притвориться, что наши псевдослучайные числа являются истинно случайными.
Если результат работы генератора очень трудно отличить от истинно случайной последовательности, то его называют высококачественным генератором. В противном случае — низкокачественным. По большей части качество определяется эмпирически, путём прогона статистических тестов на уровень случайности. Например, оценивается количество нулей и единиц, вычисляется число коллизий, применяется метод Монте-Карло для вычисления ? и т. д. Другой, более прагматичный метод оценки качества PRNG заключается в анализе его работы на практике и сравнении с истинно случайными числами.
Помимо неслучайности результата, рассматриваемый нами простой алгоритм демонстрирует и другие важные особенности, свойственные всем PRNG. Если долго генерировать числа, то рано или поздно начнёт повторяться одна и та же последовательность. Это свойство называется периодичностью, и ею «страдают» все PRNG.
Период, или длина цикла, — это длина последовательности чисел, создаваемых генератором до первого повторения.
Можно рассматривать PRNG как сильно сжатую шифровальную книгу, содержащую последовательность чисел. Какой-нибудь шпион мог бы использовать его в качестве одноразового блокнота. Начальной позицией в этой «книге» является seed(). Постепенно вы дойдёте до её конца и вернётесь к началу, завершив цикл.
Большая длина цикла не гарантирует высокое качество, но весьма ему способствует. Часто он гарантируется каким-то математическим доказательством. Даже когда мы не можем точно вычислить длину цикла, нам вполне по силам определить его верхнюю границу. Поскольку следующее состояние PRNG и его результат являются детерминистическими функциями текущего состояния, то длина цикла не может быть больше количества возможных состояний. Для достижения максимальной длины генератор должен пройти через все возможные состояния, прежде чем вернуться в текущее.
Если состояние PRNG описывается как k-бит, то длина цикла ? 2k. Если она действительно достигает этого значения, то такой генератор называют генератором полного цикла. В хороших PRNG длина цикла близка к этой верхней границе. В противном случае вы будете зря тратить память.
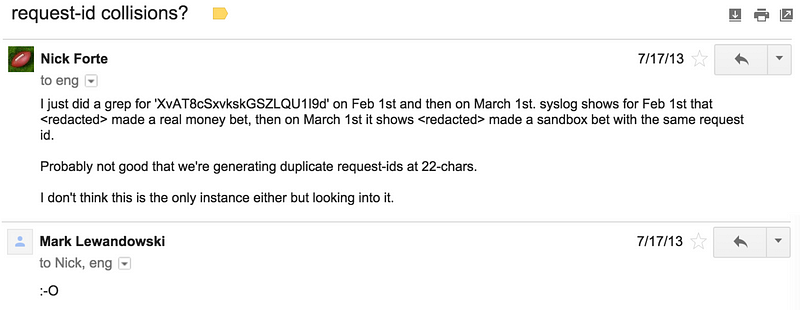
Давайте теперь проанализируем количество уникальных случайных значений, генерируемых PRNG с помощью некой детерминистической трансформации выходных данных. Допустим, нам надо сгенерировать три случайных числа от 0 до 15, вроде 2, 13, 4 или 5, 12, 15. У нас может быть 163 = 4096 таких тройных комбинаций, но рассматриваемый нами простой генератор может выдать лишь 16 комбинаций:
Так мы приходим к ещё одному свойству всех PRNG: количество уникальных значений, которые могут быть сгенерированы из псевдослучайной последовательности, ограничивается длиной цикла последовательности.
Неважно, какие значения мы генерируем в данном случае. Их может быть 16 комбинаций из четырёх значений (или любой другой длины), 16 уникальных матричных массивов и т. д. Не более 16 уникальных значений любого типа.
Вспомните наш алгоритм для генерирования случайных идентификаторов, состоящих из 22 символов, берущихся из 64-символьного словаря. Получается, что мы генерируем комбинации из 22 чисел от 0 до 63. И здесь мы сталкиваемся с той же проблемой: количество возможных уникальных идентификаторов ограничено размером внутреннего состояния PRNG и длиной его цикла.
Math.random()
Вернёмся к нашим баранам. Получив письмо о возникновении коллизии, мы быстро пересмотрели наши математические выкладки по парадоксу дней рождений и проверили код. Ничего криминального не обнаружили, значит, проблема лежит глубже. Начали разбираться.
Вот что говорится о Math.random() в спецификации ECMAScript:
Возвращает положительное числовое значение, больше либо равное 0, но меньше 1, выбранное случайно или псевдослучайно с приблизительно равномерным распределением в этом диапазоне, с использованием алгоритма или стратегии, зависящих от конкретной реализации.
Спецификация оставляет желать лучшего. Во-первых, тут ничего не сказано о точности. Поскольку в ECMAScript используются числа с плавающей запятой двойной точности IEEE 754 binary64, то мы можем ожидать точность на уровне 53 бит (т. е. случайные значения принимают вид x/253, где x = 0…253 – 1). Движок SpiderMonkey от Mozilla придерживается того же мнения, но это не так. Как будет показано ниже, точность Math.random() в V8 составляет всего 32 бита (значения принимают вид x/232, где x = 0…232 – 1). Впрочем, это не важно, поскольку нам нужно шесть бит для генерирования случайных букв из нашего словаря.
А вот что для нас оказалось действительно важно, так это то, что спецификация не определяет конкретный алгоритм. Нет никаких требований к минимальной длине цикла, так что прощай, качество: распределение должно быть лишь «приблизительно равномерным». Значит, чтобы найти причину коллизии, нужно проанализировать конкретный алгоритм, используемый V8. В документации мы ничего не нашли, так что пришлось обращаться к исходному коду.
Генератор псевдослучайных чисел в V8
«Мне пришлось смириться с вихрем Мерсенна, потому что его используют все подряд (Python, Ruby и т. д.)». Эта краткая характеристика Дина Мак-Нами является единственным содержательным отзывом на анализ кода PRNG в V8, когда он был впервые закоммичен 15 июня 2009 года.
За прошедшие шесть лет код PRNG в V8 переделывался и рихтовался. Раньше это был нативный код, а теперь он находится в пользовательском пространстве. Но алгоритм остался без изменений. Текущая реализация использует внутренний API и довольно запутана, поэтому рассмотрим более читабельную реализацию того же алгоритма:
var MAX_RAND = Math.pow(2, 32);
var state = [seed(), seed()];
var mwc1616 = function mwc1616() {
var r0 = (18030 * (state[0] & 0xFFFF)) + (state[0] >>> 16) | 0;
var r1 = (36969 * (state[1] & 0xFFFF)) + (state[1] >>> 16) | 0;
state = [r0, r1];
var x = ((r0 << 16) + (r1 & 0xFFFF)) | 0;
if (x < 0) {
x = x + MAX_RAND;
}
return x / MAX_RAND;
}
Ссылка.
Выглядит малопонятно, будем разбираться.
Есть одна подсказка. В старых версиях V8 был комментарий: «генератор случайных чисел использует алгоритм MWC Джорджа Марсальи (George Marsaglia)». В поисковике нашлось следующее:
- Джордж Марсалья был математиком, большую часть карьеры занимался изучением PRNG. Он также разработал тесты Diehard для измерения качества генераторов случайных чисел.
- MWC означает multiply-wit-carry. Это класс генераторов псевдослучайных чисел, разработанный Марсальей. Они очень похожи на классические линейные конгруэнтные генераторы (LCG), пример которого мы рассмотрели выше. А если верить пункту 3.6 этого документа, то MWC полностью соответствует LCG. Разница лишь в том, что MWC могут генерировать последовательности с большей длиной цикла при сравнимом количестве циклов работы процессора.
Так что если вам нужен PRNG, то MWC кажется неплохим выбором.
Но реализованный в V8 алгоритм непохож на типичный MWC. Вероятно, причина в том, что это не MWC, а сразу два MWC-генератора — один в строке 5, второй в строке 6, — совместно генерирующих одно случайное число в строке 9. Не стану выкладывать тут все расчёты, но каждый из этих подгенераторов имеет длину цикла примерно 230, что даёт суммарную длину генерируемой последовательности примерно 260.
Но у нас, как вы помните, 2132 возможных идентификаторов. Допустим, что соблюдается условие равномерного распределения. Тогда вероятность коллизии после случайно сгенерированных 100 млн идентификаторов должна быть менее 0,4%. Но коллизии стали возникать гораздо раньше. Наверное, мы где-то ошиблись с нашим анализом. Возможно, проблема заключается в равномерном распределении — вероятно, есть какая-то дополнительная структура в генерируемой последовательности.
История двух генераторов
Давайте ещё раз посмотрим на код генерирования идентификаторов:
var ALPHABET = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_';
random_base64 = function random_base64(length) {
var str = "";
for (var i=0; i < length; ++i) {
var rand = Math.floor(Math.random() * ALPHABET.length);
str += ALPHABET.substring(rand, rand+1);
}
return str;
}
Ссылка.
Большое значение имеет метод масштабирования в шестой строке. Он рекомендован MDN для масштабирования случайных чисел и используется очень широко (пример 1, пример 2, пример 3, пример 4, пример 5, пример 6). Метод известен под названиями multiply-and-floor, take-from-top. Последнее название он получил потому, что нижние биты случайного числа отсекаются, а левые — верхние, top, — используются в качестве масштабированного целочисленного результата.
Примечание: если отношение выходного диапазона PRNG к масштабируемому диапазону представляет дробное число, то этот метод работает с небольшим смещением (biased). Обычно это решается с помощью выборки с отклонением, используемой в стандартных библиотеках других языков.

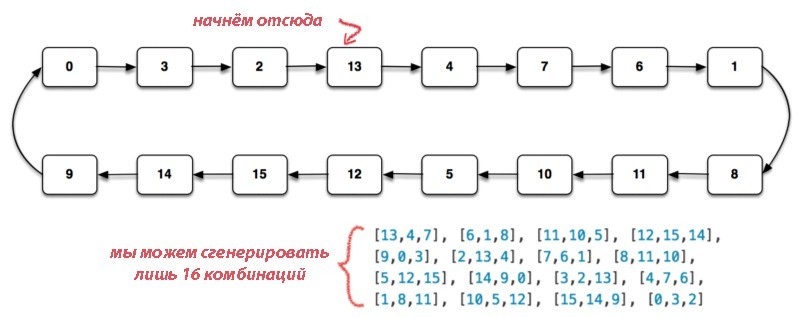
Замечаете, в чём проблема? Два генератора довольно странно миксуются в алгоритме V8. Числа из двух потоков не объединяются по модулю 2 (xor). Вместо этого просто конкатенируются нижние 16 бит выходных данных каждого подгенератора. Похоже, проблема именно в этом. Когда мы умножим Math.random() на 64 и приведём к наименьшему (floor), то у нас останутся верхние 6 битов. Эти биты генерируются исключительно одним из двух MWC-подгенераторов.
Красным выделены биты от PRNG № 1, синим — от PRNG № 2.
Если независимо проанализируем первый подгенератор, то увидим, что его внутреннее состояние имеет длину 32 бита. Это не генератор полного цикла, реальная длина составляет около 590 млн: 18,030 * 215 – 1, подробности вычислений можно узнать здесь — ссылка 1, ссылка 2. То есть мы можем сгенерировать не более 590 млн уникальных идентификаторов запроса. И если бы они выбирались случайным образом, то после 30 тыс. генераций вероятность коллизии составила бы 50%.
Но будь это так, мы почти сразу же начали бы замечать коллизии. Но мы их не замечали. Чтобы понять, почему этого не происходило, давайте вспомним пример с генерированием комбинаций из трёх чисел средствами 4-битного LCG.
В данном случае парадокс дней рождений неприменим — последовательность даже близко нельзя назвать случайной, так что мы не можем притвориться. Очевидно, что до 17-й комбинации дублей не будет. То же самое происходит и с PRNG в V8: при определённых условиях недостаток случайности снижает вероятность того, что мы увидим коллизию.
То есть детерминированность генератора сыграла нам на руку. Но так бывает не всегда. Главный вывод, который мы сделали, заключается в том, что даже в высококачественном PRNG нельзя предполагать случайность распределения, если длина цикла не будет гораздо больше, чем количество генерируемых вами значений.
Если вам нужно N случайных значений, то необходимо использовать PRNG с длиной цикла как минимум N2. Причина этого в том, что, с учётом периода PRNG, избыточная равномерность может снизить производительность в некоторых важных статистических тестах (в особенности в тестах на наличие коллизий). Чтобы этого не происходило, размер выборки N должен быть пропорционален квадратному корню из длины периода. Подробнее об этом можно почитать на странице 22 замечательной работы Пьера Лекюйе, в главе, посвящённой генераторам случайных чисел.
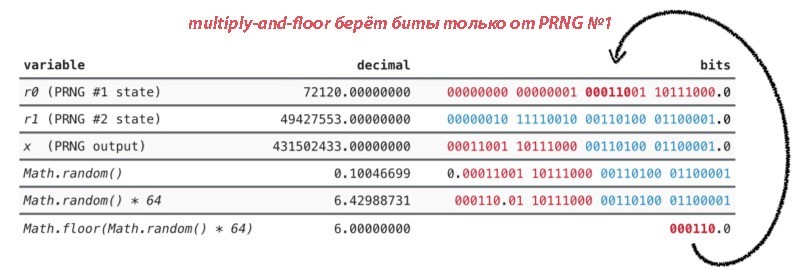
В случаях, подобных нашему, когда пытаются генерировать уникальные значения с помощью нескольких независимых последовательностей от одного генератора, беспокоятся не столько о случайности, сколько о том, чтобы последовательности не совпадали. Допустим, у нас есть N последовательностей с длиной L от генератора с периодом P. Тогда вероятность совпадения будет равна
Для достаточно больших значений P вероятность будет примерно равна LN2/P (подробности: ссылка 1, ссылка 2). Значит, нам нужен цикл большой длины, иначе мы будем ошибочно притворяться, что наша последовательность является случайной.
Короче, если вы используете Math.random() в V8 и вам нужна достаточно качественная последовательность случайных чисел, то не используйте более 24 тыс. чисел. А если генерируете в несколько мощных потоков и вам нужно избегать совпадений, то вообще забудьте о Math.random().
Краткая история MWC1616
«Генератор MWC конкатенирует два 16-битных multiply-with-carry-генератора […] обладает периодом 260 и, похоже, проходит все тесты на случайность. Любимый отдельный генератор — быстрее, чем содержащий его KISS». Это отрывок из описания алгоритма MWC1616, лежащего в основе Math.random() в V8. Судя по словам Марсальи, удовлетворяет большинству основных критериев, по которым выбирают PRNG.
MWC1616 был представлен в 1997 году в качестве простого основного генератора. Фраза «похоже, проходит все тесты на случайность» выдаёт эмпиричность методологии Марсальи. Он, кажется, доверял алгоритму, раз тот прошёл тесты Diehard. К сожалению, те тесты, что он использовал в конце 1990-х, были недостаточно хороши, по крайней мере исходя из современных стандартов. Если прогнать MWC1616 через более современный тестировочный фреймворк вроде TestU01, то результат будет катастрофическим. Даже генератор MINSTD показывает результат лучше, а он устарел ещё в 1990-х. Вероятно, тесты Diehard просто не были достаточно детализированными, поэтому Марсалья сделал такой вывод.
// January 12, 1999 / V8 PRNG: ((r0 << 16) + (r1 ^ 0xFFFF)) % 2^32
var x = ((r0 << 16) + (r1 & 0xFFFF)) | 0;
// January 20, 1999: (r0 << 16) + r1) % 2^32
var x = ((r0 << 16) + r1) | 0;
Ссылка.
Насколько мне известно, у процедуры конкатенации двух подмножеств сгенерированных битов, выполняемой в MWC1616, нет никакой математической базы. Обычно биты от подгенераторов объединяются с помощью арифметических операций по модулю (например, xor). Похоже, Марсалья озаботился отсутствием математической базы вскоре после опубликования своего алгоритма в качестве компонента одной из версий генератора KISS. 12 января 1999 года вышла версия MWC1616, использовавшаяся в V8. А уже 20 января Марсалья опубликовал другую версию своего алгоритма. В ней верхние биты второго генератора не отбрасываются, потоки смешиваются точнее.
Обе версии алгоритма появились на разных ресурсах, что внесло путаницу. Поздняя (улучшенная) версия, названная MWC with Base b = 216, опубликована на Numerical Recipes под заголовком «Когда у вас только 32-битные вычисления». И вместо внедрения одного из алгоритмов предлагалось «использовать компилятор получше!». Довольно унылый совет по отношению к алгоритму, который лучше используемого в V8. По необъяснимой причине версия от 20 января приводится в Википедии в качестве примера вычислительного метода для генерирования случайных чисел. Более старая версия от 12 января дважды включалась в TestU01, сначала под названием MWC1616, а потом MWC97R. Также этот алгоритм применяется в качестве одного из генераторов в языке R.
В общем, MWC используется довольно широко. И надеюсь, эта статья послужит предостережением для многих разработчиков, став развитием и подтверждением наблюдений Кнута:
- В целом, вам нужно самостоятельно анализировать работу PRNG, чтобы понять ограничения используемых или реализуемых алгоритмов.
- Не используйте MWC1616, от него мало толку.
Есть немало более полезных вариантов. Давайте рассмотрим парочку.
Альтернатива в виде CSPRNG
Итак, нам надо было чем-то быстро заменить Math.random(). Для JavaScript существует множество других PRNG, но у нас было два условия:
- У генератора должен быть достаточно долгий период, чтобы нагенерировать 2132 идентификаторов.
- Он должен быть тщательно протестирован и иметь хорошую поддержку.
К счастью, в стандартной библиотеке Node.js есть другой генератор, удовлетворяющий нашим требованиям: crypto.randomBytes(), криптографически безопасный PRNG (CSPRNG), вызывающий RAND_bytes, используемый в OpenSSL. Согласно документам, тот выдаёт случайное число с помощью хэша SHA-1 с внутренним состоянием на 8184 бита, который регулярно перерандомизируется (reseed) из разных энтропических источников. В веб-браузере то же самое должен делать crypto.getRandomValues().
У этого решения есть три недостатка:
- В CSPRNG почти всегда используются нелинейные трансформации, и поэтому они работают медленнее, чем некриптографические альтернативы.
- Многие CSPRNG-системы нельзя рандомизировать (seed), что делает невозможным создание воспроизводимой последовательности (например, для целей тестирования).
- CSPRNG могут непредсказуемо выделяться на фоне всех остальных мер качества, отдельные из которых могут оказаться важнее для вашего проекта.
Однако есть и преимущества:
- В большинстве случаев производительности CSPRNG вполне достаточно (на моей машине я могу с помощью crypto.getRandomValues() получить в Chrome около 100 Мб/с случайных данных).
- В определённых пределах непредсказуемость подразумевает невозможность отличить результат работы генератора от истинно случайных данных. Значит, мы можем получить всё, что нам нужно, от псевдослучайной последовательности.
- Если генератор позиционируется как «криптографически безопасный», то можно предположить, что его код анализировался более тщательно и подвергался многим практическим тестам на случайность.
Всё ещё приходится делать некие допущения, но они хотя бы прагматичны и базируются на каких-то доказательствах. Если вы не уверены в качестве своих некриптографических альтернатив, то лучше всего пользоваться CSPRNG. По крайней мере, до тех пор, пока вам не понадобятся детерминистическое рандомизирование или строгие доказательства качества генератора. Если вы не доверяете CSPRNG из своей стандартной библиотеки (а ради надёжности криптографии этого и нельзя делать), то можете воспользоваться urandom, который управляется ядром (в Linux используется схема, аналогичная OpenSSl, а в OS X — генератор Yarrow).
Я не знаю, какова длина цикла в crypto.randomBytes(). Насколько мне известно, у этой проблемы не существует решения в замкнутой форме. Могу сказать лишь, что при большом пространстве состояния и длительном потоке входящей энтропии алгоритм должен быть достаточно безопасен. Раз уж вы доверяете OpenSSL генерирование пар публичных/личных ключей, то какой смысл беспокоиться по этому поводу? После того как мы заменили Math.random() на crypto.randomBytes(), проблема коллизий исчезла.
На самом деле Chrome мог бы заставить Math.random() вызвать тот же CSPRNG, который используется для crypto.randomBytes(). Судя по всему, WebKit именно это и делает. В любом случае есть немало других быстрых и высококачественных некриптографических альтернатив.
Недостатки PRNG в V8
Я хочу доказать вам, что использовать Math.random() в V8 нельзя, этот инструмент необходимо заменить. Мы уже обсудили наличие очевидных структурных паттернов в выходных данных, проваленные практические тесты и низкую производительность в реальных проектах. Если вам всё ещё мало доказательств, то взгляните на это:


Сверху — шум на основе случайных данных из Safari, снизу — из V8. Картинки сгенерированы в браузере с помощью этого кода:
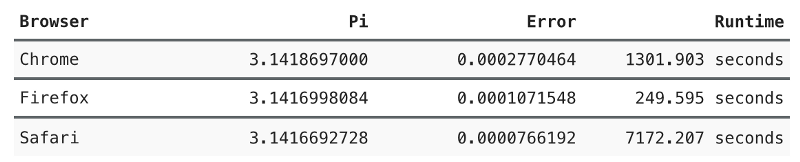
Вычисление числа ? с помощью алгоритма Монте-Карло, 1010 итераций. Код.
Надеюсь, вы теперь согласитесь, что с Math.random() пора что-то делать. Вопрос — что именно. Корректировка одной строки позволит улучшить объединение битов, но я вообще не вижу смысла держаться за MWC1616. Есть варианты получше.
Я не собираюсь устраивать здесь детальное сравнение множества существующих методов генерирования псевдослучайных чисел. Но хотя бы формализую критерии, которым должны удовлетворять подходящие генераторы:
- Большое пространство состояний и большое начальное число (seed) — в идеале, не менее 1024 бит. Это будет верхней границей для других параметров качества генератора. В 99,9% случаев пространства состояний размером 21024 будет достаточно, при обеспечении хорошего уровня безопасности.
- Скорость. Возьмём на уровне лучших современных реализаций — 25 млн чисел в секунду на моём компьютере.
- Эффективность использования памяти. Вероятно, для генератора с 1024 битами состояния в пользовательском пространстве JavaScript понадобится не менее 256 байт (мы можем использовать только 32 бита на каждое 64-битное число). Если это нереализуемо, то можно воспользоваться обходными путями, но будем считать, что это возможно.
- Очень длинный период. Генератор полного цикла — вещь хорошая, но и периода длиной больше 250 будет вполне достаточно, чтобы избежать цикличности. А при 2100 мы можем безопасно использовать 250 и продолжать притворяться, что у нас истинно случайная последовательность.
- Прохождение практических тестов на случайность. Как минимум — TestU01. Он строже, чем Dieharder. Дополнительные баллы даются за прохождение BigCrush и хорошую равнораспределённость. Про тесты NIST или rngtest ничего сказать не могу, но их тоже надо бы использовать.
Существует много PRNG, удовлетворяющих этим требованиям или перекрывающих их. Генераторы xorshift (тоже разработанные Марсальей) имеют высокую производительность и показывают отличные результаты на статистических тестах. Один из вариантов, под названием xorgens4096, был реализован на JavaScript. Он обладает пространством состояний 4096 бит, длиной цикла около 24096 и работает в Chrome на моей машине быстрее, чем MWC1616. Кроме того, не проваливает систематически BigCrush.
Недавно было показано, что умножение выходных данных xorshift-генератора на константу является достаточно нелинейной трансформацией, поэтому генератор не пройдёт BigCrush. Этот класс генераторов называется xorshift*. Они работают очень быстро, эффективно используют память и легко реализуемы. Генератор xorshift1024* удовлетворяет всем нашим требованиям, некоторым даже с избытком. Xorshift64* потребляет столько же памяти, у него длиннее цикл, работает быстрее MWC1616. Для нового семейства гибридных линейно-нелинейных генераторов — PCG — заявлены такие же характеристики производительности и качества.
В общем, есть из чего выбрать. Безопаснее всего, наверное, стандартный вихрь Мерсенна. Его наиболее популярным вариантом является MT19937, представленный в конце 1990-х. С тех пор он стал стандартным генератором в десятках продуктов. Вещь неидеальная, но зато хорошо протестированная и тщательно проанализированная. С ним легко разобраться, неплохо ведёт себя в практических тестах. Длина цикла составляет аж 219937 – 1, у него внушительные 2 Кб пространства состояний и его критикуют за большое потребление памяти и не слишком высокую производительность. Есть и реализация на JavaScript. Я не сравнивал его производительность с Math.random() в Chrome на своём компьютере.
Короче, я полностью согласен с комментарием Дина Мак-Нами шестилетней давности и рекомендую использовать вихрь Мерсенна. Его могут без опаски применять те разработчики, которые не слишком хорошо представляют себе устройство генераторов псевдослучайных чисел. Если хотите — используйте более экзотические альтернативы. Но только избавьтесь от MWC1616, прошу вас!
Итоги
Это был длинный пост. Давайте подведём краткие итоги:
- В движке V8 функция Math.random() использует алгоритм MWC1616. Если вы используете только самые важные 16 бит, то у этого алгоритма очень короткая и эффективная длина цикла (меньше 230). Показывает низкие результаты при прохождении практических тестов на качество. Во многих специфических случаях будет небезопасным притворяться, что данные получаются истинно случайными. Остерегайтесь использовать этот алгоритм для любых ответственных задач.
- Если у вас нет возможности тщательно выбрать некриптографическую альтернативу, то лучше применять криптографически безопасные PRNG. Безопаснее всего (в том числе для криптографических задач) — urandom. В браузере можно использовать crypto.getRandomValues().
- Есть много других некриптографических генераторов псевдослучайных чисел, которые работают быстрее и с лучшим качеством, чем MWC1616. В V8 следует внедрить любой из них. Наиболее популярный и, вероятно, самый безопасный кандидат — вихрь Мерсенна (MT19937).
Напоследок замечу, что используемый Mozilla LCG-генератор из Java-пакета util.Random не сильно лучше, чем MWC1616. Так что есть смысл обновить генератор и в SpiderMonkey.
В то же время браузеры остаются тёмным и опасным местом. Берегите себя!
Goodkat
Может быть, это закладка NSA в Chrome :)
IRainman
Скорее всего это какое то древнее наследие :)
P.S. в DC++, например, тоже свой генератор используется, но тут всё гораздо суровее и интереснее:
bejibx
Чудесный TODO:
// TODO oa?aou iaae?aneea ?enea!!!)
flexoid
// TODO убрать магические числа!!!
IRainman
Дооо ) на самом деле там имелось ввиду, что необходимо обосновать использование именно таких значений N и M ибо они влияют на вероятность появления коллизий.
P.S. flexoid благодарю
YoungSkipper
Тут вполне я думаю применима Бритва Хэнлона:
chill84
В следующих версиях починили
http://v8project.blogspot.ru/2015/12/theres-mathrandom-and-then-theres.html
Apathetic
О том, что Math.random() в V8 ужасающего качества, было известно всегда. Начиная с версии 4.9.41.0 используется другой алгоритм. Описание и наглядное сравнение: v8project.blogspot.ru/2015/12/theres-mathrandom-and-then-theres.html
ProRunner
Так эта самая переведенная статья и послужила причиной смены алгоритма:
Apathetic
И было бы неплохо в конкретно этом переводе, опубликованном уже после внедрения нового алгоритма, об этом упомянуть.
michael_vostrikov
Вероятность «раз в миллион лет» говорит о том, что за миллион лет событие скорее всего произойдет хотя бы один раз. Но она ничего не говорит о том, в какой день это событие произойдет. Оно может произойти в любой день, например, в первый.
Prototik
Событие может и вообще не произойти, а может и 20000 раз произойти за «миллион лет». Случайность штука интересная.
RZK333
пример эксплуатации старого Math.random().
jonasnick.github.io/blog/2015/07/08/exploiting-csgojackpots-weak-rng
SirEdvin
А почему бы не добавлять какой-то идентификатор объекта, который сделал запрос к идентификатору запроса? Тогда бы и коллизий не было.
AlexanderG
По сути получается то же самое, что и увеличение длины генерируемой последовательности.
SirEdvin
Уменьшается вероятность коллизии. Так вам нужно уникальный в рамках всей системы, а так в рамках одного пользователя.
AlexanderG
То есть по сути попытаться компенсировать низкое качество генератора добавлением лишнего источника энтропии. Точно так же можно добавлять системное время, например. Решить проблему это может помочь, колиизий станет меньше, но сам по себе генератор всё равно останется низкокачественным, к чему, кажется, и должна привлечь внимание статья.
Sirion
Вы просили не критиковать код, но всё же я не могу удержаться от вопроса: почему не ALPHABET.charAt(rand)? Или не ALPHABET[rand]? Есть какие-то неизвестные мне нюансы?
Riketta
Это слегка перевод
Sirion
Упс, не заметил. Пардон.
eme
Если интересна разница, то она есть:
var str = '12345';
str.charAt(10) == '';
str[10] == undefined;
Sirion
Меня интересовало, какие «фишки» есть у substring(rand, rand+1) по сравнению с приведёнными мной вариантами. С квадратными скобками я немного погорячился, но разве charAt(rand) не полный аналог?
RumataEstora
>… пространство имеет размер 64^22 ? 2^132
Каким образом левая часть выражения приближенно равна правой части?
mitasovr
Спасибо!
Это перевод, в оригинале «64?? or ~2???»
vics001
Имелось в виду, они просто равны.
sabio
Вот ещё недавно попалось на глаза: www.pcg-random.org
Очень быстрый, требует мало памяти, статистические тесты проходит «на отлично».
Также он обладает «k-размерной эквидистрибутивностью». Вот, например, с его помощью «генерируют» тексты Шекспира: www.pcg-random.org/party-tricks.html
grossws
barabanus
Я вот думаю, ну почему так долго развиваются инструкции процессора в сторону векторных вычислений (MMX, SSE, AVX, AVX2 и т.д.), но до сих пор не сделали инструкцию в один цикл, дающую абсолютно случайное число на аппаратном уровне? Или, например, регистр со случайным числом, которое меняется каждый цикл процессора. Хорошие псевдослучайные числа стоят очень дорого, если применять обычный конвейер вычислений, при этом запрос на быстрые случайные числа велик.
xytop
en.wikipedia.org/wiki/RdRand
barabanus
Это то, что нужно! В таком случае было бы хорошо, если бы стандартные библиотеки перестроились на использование именно этой инструкции. Для задач, в которых не важна конкретная реализация алгоритма случайных чисел.
lumag
Плохая идея. Как дополнительный источник энтропии RdRand/PadLock/прочие HwRng можно использовать, но как единственный — нет.
lumag
Потому что потом никто не будет уверен в надежности этих случайных чисел. Например пост Theodore Ts'o.
barabanus
А никто и не будет использовать генераторы псевдослучайных чисел из стандартных библиотек для криптографических задач.
mynameisdaniil
К слову, такой шум генерирует Фаерфокс №43:
23rd
А такой в Edge. Скорость тоже хорошая.
vics001
У меня немного вопросы, еще к самому способу решения задачи:
1) Почему нельзя взять например nanoTime — счетчик и прибавить 8 бит какого-то случайного rpng. Вероятность совпадения будет гораздо ниже, потому что вероятность «дней рождения» велика за счет общности задачи. С другой же стороны всегда можно сказать, что пиковая пропускная способность в 1 секунду не превышает некоторого числа.
2) Почему использовалась функция Math.random() — double, а не Math.random(255) возвращающая один бит (не уверен на счет JS).
KReal
А почему не GUID / UUID?
xytop
Они по такому же принципу создаются