
Занимаясь разработкой приложений под ОС Android возникают интересные идеи, которые хочется попробовать, либо есть какой-то набор теоретических знаний и их хочется применить на практике, из совокупности этих факторов и возникла идея описываемого проекта.
Существует много статей о распознавании текста, о компьютерном зрении и об отдельных алгоритмах распознавания. В этой же публикации демонстрируется попытка реализации задачи, связанной с нахождением ключевого слова на изображении текста, что может позволить, например, найти необходимое место для чтения какого-либо текста в DjVu без распознавания самого текста.
Пример реализации представлен в виде Android приложения, а исходным изображением является скриншот текста, с введенным ключевым словом, для решения задачи применяются различные алгоритмы обработки и распознавания изображений.
Допустим у нас есть изображение какого-то текста, это может быть фотография, сканированное изображение или скриншот, и на этом изображении необходимо отыскать какую-то фразу или слово в максимально короткий срок, чтобы быстро извлечь необходимую часть информации, здесь на помощь нам приходят алгоритмы обработки изображений и распознавания.
Подробно этапы создания Android приложения здесь описаны не будут, как и не будет представлено подробное теоретическое описание алгоритмов. При минимальном тестовом интерфейсе приложения основными целями нижеописанного являются:
Для получения исследуемого изображения создаем Activity, в которой будет всего три элемента:
1. EditText — для ввода ключевого слова;
2. TextView — для отображения текста, в котором необходимо найти это слово;
3. Кнопка создания скриншота и перехода на другой экран.
! Весь код носит исключительно демонстративный характер и не является правильной инструкцией к действию.
Примерно так это будет выглядеть:

Для поиска, например, введем слово «dreams»:

Таким образом мы получаем одиночное ключевое слово, после которого ниже следует текст. Стоит обратить внимание на то, что ключевое слово и сам текст имеют разный размер шрифта (для усложнения задачи, скажем так).
Нажимаем на кнопку и получаем скриншот области с ключевым словом и текстом.
Полученный скриншот открывается в новой Activity, где в NavigationDrawer собраны функции последовательных действий. В реальном приложении некоторые из операций могут быть объединены в одну для исключения лишних проходов по изображению.
Для начала нужно выполнить перевод полученного цветного изображения в полутоновое.
Для перевода используется схема RGB to YUV.
В нашем случае необходима лишь интенсивность (яркость), а получить её можно по форумуле:
Y = 0.299*R + 0.587*G + 0.114*B, где R,G,B красный, зеленый и синий каналы соответственно.
Для работы с цветами, как ни странно, полезен класс Color и, в частности, его статические методы red, green и blue, в которых реализованы операции с побитовыми сдвигами для выделения нужного цветового канала из интового значения цвета пикселя.
Пример кода, для перевода цветного пикселя в яркость:
Выполнять сегментацию на полутоновом изображении не на много легче, чем на цветном, поэтому следующим шагом необходимо полутоновое изображение перевести в бинарное (значения яркостей пикселей имеют лишь два значения 0 и 1).
В данной задаче для бинаризации достаточно элементарного порогового метода, с порогом по умолчанию 128.
В дальнейшем для корректировки результатов порог можно подобрать экспериментальным путем (в приложении реализована возможность задания порога пользователем).
Для получения бинарного значения яркости выполняется проверка полученной ранее полутоновой яркости:
Где threshold — порог, Color.WHITE и Color.BLACK — константы для удобства, чтобы не путаться с 0 и 1.
После проделанного перевода в полутоновое и дальнейшей бинаризации получаем следующий результат:

Так как эти два способа обработки изображения очень близки, они объединены в один метод.
Для нахождения ключевого слова необходимо после бинаризации выполнить несколько этапов сегментации, которые заключаются в поиске строк в тексте, поиске слов в строках и отнесение найденных слов к словам претендентам по количеству букв (для сужения круга слов для распознавания).
Для определения строк текста необходимо найти части гистограммы с количеством черных пикселей больше нуля, которые находятся между частями гистограммы с нулевым количеством пикселей. Для этого составляется гистограмма количества черных пикселей в каждой однопиксельной строке изображения, после чего она обрабатывается для получения координат строк по вертикали (по сути номера строк в гистограмме). Зная эту координату и общие размеры изображения, можно выделить область, содержащую строку со словами.
«Inline» гистограмма для наглядности (слева) выглядит, например, так:

Для удобства отображения гистограмма нормализуется.
Когда известно расположение строк на изображении, можно переходить к поиску слов.
Для того, чтобы понять, где слова а где просто соседние символы, необходимо определиться, какие расстояния между символами считать расстояниями между словами, а какие расстояниями между символами внутри одного слова. Здесь на помощь приходит метод мод, а точнее его адаптированный вариант, потому что чаще всего этот метод встречается в бинаризации, но его суть можно применить и в данной ситуации.
Для начала как и для строк, аналогичным образом строим гистограмму внутри строки (по сути была вертикальная, теперь горизонтальная), она необходима, чтобы понять, где символы, а где белые промежутки.
Пример получения такой гистограммы ниже и аналогичен предыдущему.
Обрабатывая эту гистограмму можно получить новую гистограмму — промежутков между черными пикселями, т.е., первая градация её будет количеством «пробелов» шириной 1 пиксель, вторая градация количество «пробелов» шириной 2 пикселя и так далее.
Получится примерно что-то такое:

Исходя из логики метода мод мы находим два ярко выраженных пика (на изображении выше они очевидны), и всё что находится около одного пика — расстояния между символами внутри слова, около второго — расстояния между словами.
Имея такую информацию о «пробелах» и гистограмму строки можно выделить участки изображения, где находятся слова, а также посчитать сколько символов содержится в этих словах.
Полный код данного процесса смотри в исходниках.
Для визуальной оценки работы вышеизложенной совокупности алгоритмов слова в тексте окрашиваются в чередующееся цвета, а слова претенденты (напомню, те, у которых количество символов совпадает с количеством символом в ключевом слове) остаются черного цвета:
И так, на данном этапе есть кусочки изображений (точнее координаты этих кусочков), которые содержат ключевое слово и слова претенденты на основании количества символов, можно попробовать найти среди претендентов ключевое слово.
Обращаю внимание, что здесь под распознаванием подразумевается распознавание ключевого слова среди претендентов, при этом о распознавании из каких именно символов они состоят речи не идет.
Для распознавания подбирается набор информативных признаков: это может быть количество концевых точек, узловых точек, а также количество пикселей с 3, 4 и 5 черными пикселями-соседями, и другие. Опытным путем установлено, что большое количество признаков теряет смысл, так как они «перекрывают» друг друга.
На данном этапе остановимся на количестве концевых точек, с учетом их расположения (в верхней и нижней части изображения — для каждой части признаки считаются отдельно).
Для каждого слова выполняется подсчет количества признаков, после чего происходит поиск по методу ближайших соседей на основании евклидова расстояния.
Обо всех характерных числах типа A4, A8 и т.д. можно найти информацию дополнительно.
Учитывая повторяемость слов и погрешности, в результате можно получить 2-3 ближайших соседа, среди которых будет найдено ключевое слово (на рисунке выделены красным).

Также на рисунке видно, что среди красных слов есть искомое слово «dreams».
Для улучшения качества распознавания можно попробовать подобрать другой порог бинаризации, а также выбрать другие информативные признаки, добавив к ним, например, зонды.
Поставленных целей удалось достичь, были опробованы некоторые методы обработки и распознавания изображений, при этом их реализация под Android не накладывает никаких дополнительных сложностей, просто нужно учитывать расход памяти и не хранить одновременно несколько больших Bitmap.
Надеюсь, информация окажется полезной для начинающих свой путь в решении задач по работе с изображениями под Android.
Описание всех используемых алгоритмов, подсчет характерных чисел и т.п. можно с легкостью найти в открытом доступе как на habrahabr, так и в многочисленных учебниках и онлайн ресурсах.
Полностью проект доступен на GitHub
P.S.: Приведенная реализация алгоритмов не оптимальная, и требует дальнейшей проработки и оптимизации, служит лишь минимально необходимым примером для ознакомления, визуализации и оценки работы вышеописанных методов на Android.
Существует много статей о распознавании текста, о компьютерном зрении и об отдельных алгоритмах распознавания. В этой же публикации демонстрируется попытка реализации задачи, связанной с нахождением ключевого слова на изображении текста, что может позволить, например, найти необходимое место для чтения какого-либо текста в DjVu без распознавания самого текста.
Пример реализации представлен в виде Android приложения, а исходным изображением является скриншот текста, с введенным ключевым словом, для решения задачи применяются различные алгоритмы обработки и распознавания изображений.
Задача
Допустим у нас есть изображение какого-то текста, это может быть фотография, сканированное изображение или скриншот, и на этом изображении необходимо отыскать какую-то фразу или слово в максимально короткий срок, чтобы быстро извлечь необходимую часть информации, здесь на помощь нам приходят алгоритмы обработки изображений и распознавания.
Подробно этапы создания Android приложения здесь описаны не будут, как и не будет представлено подробное теоретическое описание алгоритмов. При минимальном тестовом интерфейсе приложения основными целями нижеописанного являются:
- Ознакомление с некоторыми методами обработки изображений и распознавания образов;
- Ознакомление с возможностями и сложностью реализации этих методов для Android.
Получение изображения
Для получения исследуемого изображения создаем Activity, в которой будет всего три элемента:
1. EditText — для ввода ключевого слова;
2. TextView — для отображения текста, в котором необходимо найти это слово;
3. Кнопка создания скриншота и перехода на другой экран.
! Весь код носит исключительно демонстративный характер и не является правильной инструкцией к действию.
XML код для 1 и 2 пунктов
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:id="@+id/main_content_layout"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#ddd"
android:orientation="vertical"
android:paddingBottom="@dimen/activity_vertical_margin"
android:paddingLeft="@dimen/activity_horizontal_margin"
android:paddingRight="@dimen/activity_horizontal_margin"
android:paddingTop="@dimen/activity_vertical_margin"
app:layout_behavior="@string/appbar_scrolling_view_behavior"
tools:context=".MainActivity"
tools:showIn="@layout/activity_main">
<EditText
android:layout_width="fill_parent"
android:layout_height="40dp"
android:singleLine="true"
android:textColor="#000" />
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/main_text"
android:textColor="#000"
android:ellipsize="end"/>
</LinearLayout>
Layout с кнопкой, который включает ссылку на вышеприведенный layout
<?xml version="1.0" encoding="utf-8"?>
<android.support.design.widget.CoordinatorLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:fitsSystemWindows="true"
tools:context=".MainActivity">
<android.support.design.widget.AppBarLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:theme="@style/AppTheme.AppBarOverlay">
<android.support.v7.widget.Toolbar
android:id="@+id/toolbar"
android:layout_width="match_parent"
android:layout_height="?attr/actionBarSize"
android:background="?attr/colorPrimary"
app:popupTheme="@style/AppTheme.PopupOverlay" />
</android.support.design.widget.AppBarLayout>
<include layout="@layout/content_main" />
<android.support.design.widget.FloatingActionButton
android:id="@+id/fab"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="bottom|end"
android:layout_margin="@dimen/fab_margin"
android:src="@android:drawable/ic_menu_camera" />
</android.support.design.widget.CoordinatorLayout>
Примерно так это будет выглядеть:
Для поиска, например, введем слово «dreams»:
Таким образом мы получаем одиночное ключевое слово, после которого ниже следует текст. Стоит обратить внимание на то, что ключевое слово и сам текст имеют разный размер шрифта (для усложнения задачи, скажем так).
Нажимаем на кнопку и получаем скриншот области с ключевым словом и текстом.
Метод для получения скриншота, вызываемый по нажатию на кнопку
private void takeScreenshot() {
//Для уникальности файлов используется текущее время
Date now = new Date();
//Форматирование даты/времени по образцу
android.text.format.DateFormat.format("yyyy-MM-dd_hh:mm:ss", now);
try {
//Получение пути для сохранения изображений и подготавливаем файл
String path = Environment.getExternalStorageDirectory().toString() + "/" + now + ".jpg";
File imageFile = new File(path);
//Нахождение части layout'a, в которой находится ключевое слово и текст
View v1 = findViewById(R.id.main_content_layout);
//Получение изображения
v1.setDrawingCacheEnabled(true);
Bitmap bitmap = Bitmap.createBitmap(v1.getDrawingCache());
v1.setDrawingCacheEnabled(false);
//Сохранение изображения в файл
FileOutputStream outputStream = new FileOutputStream(imageFile);
int quality = 100;
bitmap.compress(Bitmap.CompressFormat.PNG, quality, outputStream);
outputStream.flush();
outputStream.close();
//Переход к следующей Activity
openScreenshotActivity(now);
} catch (Throwable e) {
e.printStackTrace();
}
}
Полученный скриншот открывается в новой Activity, где в NavigationDrawer собраны функции последовательных действий. В реальном приложении некоторые из операций могут быть объединены в одну для исключения лишних проходов по изображению.
Предварительная обработка полученного изображения
Для начала нужно выполнить перевод полученного цветного изображения в полутоновое.
Перевод изображения из цветного в полутоновое
Для перевода используется схема RGB to YUV.
В нашем случае необходима лишь интенсивность (яркость), а получить её можно по форумуле:
Y = 0.299*R + 0.587*G + 0.114*B, где R,G,B красный, зеленый и синий каналы соответственно.
Для работы с цветами, как ни странно, полезен класс Color и, в частности, его статические методы red, green и blue, в которых реализованы операции с побитовыми сдвигами для выделения нужного цветового канала из интового значения цвета пикселя.
Пример кода, для перевода цветного пикселя в яркость:
//Цикл обхода матрицы цветных пикселей pixels (size = количество пикселей = width*height изображения)
for (int i = 0; i < size; i++) {
int color = pixels[i];
//получаем значение красного канала
int r = Color.red(color);
//получаем значение зеленого канала
int g = Color.green(color);
//получаем значение синего канала
int b = Color.blue(color);
//вычисляем полутоновую яркость по формуле перехода RGB to YUV
double luminance = (0.299 * r + 0.0f + 0.587 * g + 0.0f + 0.114 * b + 0.0f);
}
Выполнять сегментацию на полутоновом изображении не на много легче, чем на цветном, поэтому следующим шагом необходимо полутоновое изображение перевести в бинарное (значения яркостей пикселей имеют лишь два значения 0 и 1).
Бинаризация полутонового изображения
В данной задаче для бинаризации достаточно элементарного порогового метода, с порогом по умолчанию 128.
В дальнейшем для корректировки результатов порог можно подобрать экспериментальным путем (в приложении реализована возможность задания порога пользователем).
Для получения бинарного значения яркости выполняется проверка полученной ранее полутоновой яркости:
pixels[i] = luminance > threshold ? Color.WHITE : Color.BLACK;
Где threshold — порог, Color.WHITE и Color.BLACK — константы для удобства, чтобы не путаться с 0 и 1.
После проделанного перевода в полутоновое и дальнейшей бинаризации получаем следующий результат:
Так как эти два способа обработки изображения очень близки, они объединены в один метод.
Пример метода, осуществляющего перевод в полутоновое и бинаризацию изображения
/**
* imagePath - путь к изображению
* threshold - порог бинаризации
*/
public void binarizeByThreshold(String imagePath, int threshold) {
//Открываем изображение по его пути
Bitmap bitmap = BitmapFactory.decodeFile(imagePath);
//Получаем размеры изображения
int width = bitmap.getWidth();
int height = bitmap.getHeight();
int size = width * height;
//Получаем матрицу пикселей изображения
int[] pixels = new int[size];
bitmap.getPixels(pixels, 0, width, 0, 0, width, height);
bitmap.recycle();
//Проходим по всем пикселям в матрице, выполняя перевод в полутоновое изображение и бинаризацию по порогу
for (int i = 0; i < size; i++) {
int color = pixels[i];
int r = Color.red(color);
int g = Color.green(color);
int b = Color.blue(color);
double luminance = (0.299 * r + 0.0f + 0.587 * g + 0.0f + 0.114 * b + 0.0f);
pixels[i] = luminance > threshold ? Color.WHITE : Color.BLACK;
}
Utils.saveBitmap(imagePath, width, height, pixels);
}
Сегментация
Для нахождения ключевого слова необходимо после бинаризации выполнить несколько этапов сегментации, которые заключаются в поиске строк в тексте, поиске слов в строках и отнесение найденных слов к словам претендентам по количеству букв (для сужения круга слов для распознавания).
Сегментация строк
Для определения строк текста необходимо найти части гистограммы с количеством черных пикселей больше нуля, которые находятся между частями гистограммы с нулевым количеством пикселей. Для этого составляется гистограмма количества черных пикселей в каждой однопиксельной строке изображения, после чего она обрабатывается для получения координат строк по вертикали (по сути номера строк в гистограмме). Зная эту координату и общие размеры изображения, можно выделить область, содержащую строку со словами.
«Inline» гистограмма для наглядности (слева) выглядит, например, так:
Метод для получения гистограммы строк
public ArrayList<GystMember> getRowsGystogram(String imagePath) {
//Открытие изображения, получение его размеров и матрицы пикселей
Bitmap bitmap = BitmapFactory.decodeFile(imagePath);
int width = bitmap.getWidth();
int height = bitmap.getHeight();
int size = width * height;
int[] pixels = new int[size];
bitmap.getPixels(pixels, 0, width, 0, 0, width, height);
bitmap.recycle();
ArrayList<GystMember> gystogram = new ArrayList<>();
//Получение гистограммы
for (int x = 0; x < height; x++) {
gystogram.add(new GystMember(x));
for (int y = 0; y < width; y++) {
int color = pixels[y + x * width];
if (color == Color.BLACK) {
gystogram.get(x).add();
}
}
}
return gystogram;
}
/*Класс, который здесь и в дальнейшем используется для удобства составления гистограмм в виде коллекции*/
public class GystMember implements Serializable {
public int grayValue;
public int count;
public GystMember(int grayValue) {
this.grayValue = grayValue;
this.count = 0;
}
public void add() {
count++;
}
}
Для удобства отображения гистограмма нормализуется.
Пример нормализации гистограммы в onDraw кастомной View
if (mGystogram != null) {
float max = Integer.MIN_VALUE;
for (GystMember gystMember : mGystogram) {
if (gystMember.count > max) {
max = gystMember.count;
}
}
int pixelSize = getWidth();
int coef = (int) (max / pixelSize);
if (coef == 0){
coef = 1;
}
int y = 0;
for (GystMember gystMember : mGystogram) {
int value = gystMember.count;
canvas.drawLine(0, y, value / coef, y, mPaint);
y++;
}
}
Когда известно расположение строк на изображении, можно переходить к поиску слов.
Сегментация слов
Для того, чтобы понять, где слова а где просто соседние символы, необходимо определиться, какие расстояния между символами считать расстояниями между словами, а какие расстояниями между символами внутри одного слова. Здесь на помощь приходит метод мод, а точнее его адаптированный вариант, потому что чаще всего этот метод встречается в бинаризации, но его суть можно применить и в данной ситуации.
Для начала как и для строк, аналогичным образом строим гистограмму внутри строки (по сути была вертикальная, теперь горизонтальная), она необходима, чтобы понять, где символы, а где белые промежутки.
Пример получения такой гистограммы ниже и аналогичен предыдущему.
Обрабатывая эту гистограмму можно получить новую гистограмму — промежутков между черными пикселями, т.е., первая градация её будет количеством «пробелов» шириной 1 пиксель, вторая градация количество «пробелов» шириной 2 пикселя и так далее.
Пример получения гистограммы промежутков
public ArrayList<GystMember> getSpacesInRowsGystogram(String imagePath, ArrayList<GystMember> rowsGystogram) {
//Загрузка изображения, получение его размеров и матрицы пикселей
Bitmap bitmap = BitmapFactory.decodeFile(imagePath);
int width = bitmap.getWidth();
int height = bitmap.getHeight();
int size = width * height;
int[] pixels = new int[size];
bitmap.getPixels(pixels, 0, width, 0, 0, width, height);
bitmap.recycle();
//Для гистограммы используется тот же GystMember, только немного менять суть параметров.
ArrayList<GystMember> oneRowGystogram = new ArrayList<>();
ArrayList<Integer> spaces = new ArrayList<>();
ArrayList<GystMember> spacesInRowsGystogram = new ArrayList<>();
int yStart = 0, yEnd = 0, yIter = -1;
boolean inLine = false;
//Последовательный обход строк
for (GystMember gystMember : rowsGystogram) {
yIter++;
//Если встречаем черные пиксели (имеется в виду в гистограмме), то "начинаем строку"
if (gystMember.count > 0 && !inLine) {
inLine = true;
yStart = yIter;
} else if (gystMember.count == 0 && inLine) { //Когда встречаем пустую градацию (нет черных пикселей), "заканчиваем строку"
inLine = false;
yEnd = yIter;
//Строим гистограмму внутри строки, аналогично гистограмме строк
for (int x = 0; x < width; x++) {
GystMember member = new GystMember(x);
for (int y = yStart; y < yEnd; y++) {
int color = pixels[x + y * width];
if (color == Color.BLACK) {
member.add();
}
}
oneRowGystogram.add(member);
}
int xStart = 0, xEnd = 0, xIter = -1;
boolean inRow = false;
//Горизонтальный обход одной строки
for (GystMember oneRowMember : oneRowGystogram) {
xIter++;
//Поиск символов аналогичен поиску строк
if (oneRowMember.count == 0 && !inRow) {
inRow = true;
xStart = xIter;
} else if ((oneRowMember.count > 0 || xIter == oneRowGystogram.size()-1) && inRow) {
inRow = false;
xEnd = xIter;
//Вычисляем количество пикселей между соседними символами и добавляем в список промежутков
int xValue = xEnd - xStart;
spaces.add(xValue);
}
}
}
}
//Сортируем промежутки и собираем гистограмму промежутков
Collections.sort(spaces);
int lastSpace = -1;
GystMember gystMember = null;
for (Integer space : spaces) {
if (space > lastSpace) {
if (gystMember != null) {
spacesInRowsGystogram.add(gystMember);
}
gystMember = new GystMember(space);
}
gystMember.add();
lastSpace = space;
}
return spacesInRowsGystogram;
}
Получится примерно что-то такое:
Исходя из логики метода мод мы находим два ярко выраженных пика (на изображении выше они очевидны), и всё что находится около одного пика — расстояния между символами внутри слова, около второго — расстояния между словами.
Имея такую информацию о «пробелах» и гистограмму строки можно выделить участки изображения, где находятся слова, а также посчитать сколько символов содержится в этих словах.
Полный код данного процесса смотри в исходниках.
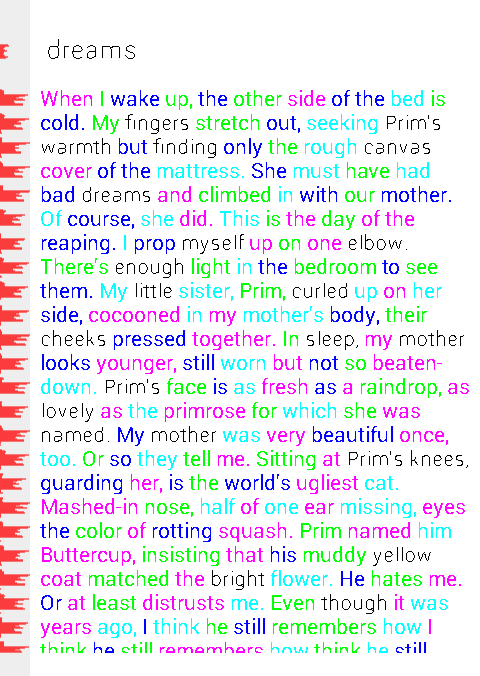
Для визуальной оценки работы вышеизложенной совокупности алгоритмов слова в тексте окрашиваются в чередующееся цвета, а слова претенденты (напомню, те, у которых количество символов совпадает с количеством символом в ключевом слове) остаются черного цвета:
И так, на данном этапе есть кусочки изображений (точнее координаты этих кусочков), которые содержат ключевое слово и слова претенденты на основании количества символов, можно попробовать найти среди претендентов ключевое слово.
Распознавание
Обращаю внимание, что здесь под распознаванием подразумевается распознавание ключевого слова среди претендентов, при этом о распознавании из каких именно символов они состоят речи не идет.
Для распознавания подбирается набор информативных признаков: это может быть количество концевых точек, узловых точек, а также количество пикселей с 3, 4 и 5 черными пикселями-соседями, и другие. Опытным путем установлено, что большое количество признаков теряет смысл, так как они «перекрывают» друг друга.
На данном этапе остановимся на количестве концевых точек, с учетом их расположения (в верхней и нижней части изображения — для каждой части признаки считаются отдельно).
Для каждого слова выполняется подсчет количества признаков, после чего происходит поиск по методу ближайших соседей на основании евклидова расстояния.
Пример формирования структуры с подсчитанными признаками
private void generateRecognizeMembers() {
mRecognizeMembers.clear();
for (PartImageMember pretendent : mPretendents) {
RecognizeMember recognizeMember = new RecognizeMember(pretendent);
int pretendentWidth = pretendent.endX - pretendent.startX;
int pretendentHeight = pretendent.endY - pretendent.startY;
int[][] workPixels = new int[pretendentWidth][pretendentHeight];
//Получение матрицы претендента из большой матрицы всего изображения
for (int pY = pretendent.startY, py1 = 0; pY < pretendent.endY; pY++, py1++)
for (int pX = pretendent.startX, px1 = 0; pX < pretendent.endX; pX++, px1++) {
workPixels[px1][py1] = mImagePixels[pX + pY * mImageWidth];
}
int half = pretendentHeight / 2;
//Обход сверху вниз
for (int ly = 0; ly < pretendentHeight; ly++) {
//Обход слева направо
for (int lx = 0; lx < pretendentWidth; lx++) {
int currentColor = workPixels[lx][ly];
//При вычислении характерных чисел нас интересуют только пиксели объекта.
if (currentColor != Color.WHITE) {
//Заполнение 3х3 матрицы соседей каждого пикселя
int[][] pixelNeibours = Utils.fill3x3Matrix(pretendentWidth, pretendentHeight, workPixels, ly, lx);
int[] pixelsLine = Utils.getLineFromMatrixByCircle(pixelNeibours);
//Подсчет характерных чисел для определения того, является ли пиксель концевым
int A4 = getA4(pixelsLine);
int A8 = getA8(pixelsLine);
int B8 = getB8(pixelsLine);
int C8 = getC8(pixelsLine);
int Nc4 = A4 - C8;
int CN = A8 - B8;
recognizeMember.A4.add(A4);
recognizeMember.A8.add(A8);
recognizeMember.Cn.add(CN);
//При выполнении этих условий пиксель считается концевым
if (A8 == 1 && Nc4 == 1 && CN == 1) {
if (ly < half) {
recognizeMember.endsCount++;
} else {
recognizeMember.endsCount2++;
}
}
}
}
}
mRecognizeMembers.add(recognizeMember);
}
}
private int getA4(int[] pixelsLine) {
int result = 0;
for (int k = 1; k < 5; k++) {
result += pixelsLine[2 * k - 2];
}
return result;
}
private int getA8(int[] pixelsLine) {
int result = 0;
for (int k = 1; k < 9; k++) {
result += pixelsLine[k - 1];
}
return result;
}
private int getB8(int[] pixelsLine) {
int result = 0;
for (int k = 1; k < 9; k++) {
result += pixelsLine[k - 1] * pixelsLine[k];
}
return result;
}
private int getC8(int[] pixelsLine) {
int result = 0;
for (int k = 1; k < 5; k++) {
result += pixelsLine[2 * k - 2] * pixelsLine[2 * k - 1] * pixelsLine[2 * k];
}
return result;
}
Обо всех характерных числах типа A4, A8 и т.д. можно найти информацию дополнительно.
Код непосредственно распознавания на основе евклидова расстояния
private void recognize() {
//Подсчет характерных чисел (описан выше)
generateRecognizeMembers();
mResultPartImageMembers.clear();
ArrayList<Double> keys = new ArrayList<>();
//Составление результатов на основании расстояний
RecognizeMember firstMember = mRecognizeMembers.get(0);
mRecognizeMembers.remove(firstMember);
for (RecognizeMember recognizeMember : mRecognizeMembers) {
if (recognizeMember.getPretendent() != firstMember.getPretendent()) {
double keyR = firstMember.equalsR(recognizeMember);
recognizeMember.R = keyR;
keys.add(keyR);
}
}
//Сортировка полученных результатов
Collections.sort(mRecognizeMembers, new Comparator<RecognizeMember>() {
@Override
public int compare(RecognizeMember lhs, RecognizeMember rhs) {
return (int) Math.round(lhs.R - rhs.R);
}
});
//Приведение результатов к виду ответа, учитывая повторяемость (все повторы включаются) и два первых соседа
double firstKey = -1;
double secondKey = -1;
for (RecognizeMember member : mRecognizeMembers) {
double key = member.R;
if (firstKey == -1) {
firstKey = key;
mResultPartImageMembers.add(member.getPretendent());
} else if (key == firstKey) {
mResultPartImageMembers.add(member.getPretendent());
} else if (secondKey == -1) {
secondKey = key;
mResultPartImageMembers.add(member.getPretendent());
} else if (secondKey == key) {
mResultPartImageMembers.add(member.getPretendent());
}
}
}
<...>
//Вычисление евклидово расстояния для количества концевых точек в верхней и нижней(2) части изображения
public double equalsR(RecognizeMember o) {
return Math.sqrt(Math.pow(this.endsCount - o.endsCount, 2)
+ Math.pow(this.endsCount2 - o.endsCount2, 2));
}
<...>
Учитывая повторяемость слов и погрешности, в результате можно получить 2-3 ближайших соседа, среди которых будет найдено ключевое слово (на рисунке выделены красным).
Также на рисунке видно, что среди красных слов есть искомое слово «dreams».
Для улучшения качества распознавания можно попробовать подобрать другой порог бинаризации, а также выбрать другие информативные признаки, добавив к ним, например, зонды.
Заключение
Поставленных целей удалось достичь, были опробованы некоторые методы обработки и распознавания изображений, при этом их реализация под Android не накладывает никаких дополнительных сложностей, просто нужно учитывать расход памяти и не хранить одновременно несколько больших Bitmap.
Надеюсь, информация окажется полезной для начинающих свой путь в решении задач по работе с изображениями под Android.
Описание всех используемых алгоритмов, подсчет характерных чисел и т.п. можно с легкостью найти в открытом доступе как на habrahabr, так и в многочисленных учебниках и онлайн ресурсах.
Полностью проект доступен на GitHub
P.S.: Приведенная реализация алгоритмов не оптимальная, и требует дальнейшей проработки и оптимизации, служит лишь минимально необходимым примером для ознакомления, визуализации и оценки работы вышеописанных методов на Android.
m03r
Поздравляем! Вы изобрели tesseract
kstep
Ну не совсем, как я понял. Здесь всё же решена более простая задача: фактически сравнение кусочков изображений с одним эталонным изображением, без разбора на конкретные символы и их распознавания.