
 Если стационарный компьютер или ноутбук ориентирован на новые и требовательные видеоигры, а также работу с системами автоматизированного проектирования и другими специализированными приложениями, то в нём чаще всего установлен видеоускоритель либо компании Nvidia, либо AMD. Текущее поколение видеоускорителей представлено девятисотой серией GeForce и трёхсотой серией чипов Radeon. Обе постепенно заполняются моделями разной направленности: Nvidia начала делать это осенью 2014 года, AMD — в прошлом июне.
Если стационарный компьютер или ноутбук ориентирован на новые и требовательные видеоигры, а также работу с системами автоматизированного проектирования и другими специализированными приложениями, то в нём чаще всего установлен видеоускоритель либо компании Nvidia, либо AMD. Текущее поколение видеоускорителей представлено девятисотой серией GeForce и трёхсотой серией чипов Radeon. Обе постепенно заполняются моделями разной направленности: Nvidia начала делать это осенью 2014 года, AMD — в прошлом июне.Новая линейка появится в 2016 году. Производители предоставляют скудную информацию о новых продуктах. Возможно, они опасаются эффекта Осборна: рассказ о более совершенном последователе состарит текущую модель в общественном восприятии, что негативно отразится на продажах последней. А ещё разработчики и сами могут не знать, как будет выглядеть конечный продукт на прилавке. Но какая-то информация есть уже сейчас.
Новое поколение можно характеризовать использованием HBM2 (High Bandwidth Memory 2) и уменьшением техпроцесса производства. AMD и Nvidia переходят с 28 нм на 14 и 16 нм FinFET, соответственно. Оба нововведения призваны увеличить производительность на ватт в 2 раза.
High Bandwidth Memory или HBM — это технология памяти, которая была разработана AMD и Hynix. До появления HBM в видеокартах использовалась память GDDR5. Для получения дополнительной пропускной способности приходилось добавлять чипы и каналы, которые отъедали пространство на плате и энергию. Обычное ускорение частоты работы микросхем памяти затормозилось, поскольку повышение частоты означает быстрый рост тепловыделения. Решением проблем призвано стать то, чем производители занимались последние пару десятилетий для уменьшения стоимости и энергопотребления и увеличения производительности: интеграция. К примеру, центральные процессоры включили в свой состав множество элементов, от математических сопроцессоров до контроллеров памяти. В каждом случае были свои плюсы.

HBM предполагает сближение памяти и чипа видеоускорителя в одной структуре. Но процессы производства слишком отличаются, чтобы реализовать подобное в одном кристалле. Поэтому используется конструкция из трёх элементов: главного чипа (в данном случае GPU, видеоускорителя), столбиков памяти и интерпозера. Интерпозер — обычный кремниевый чип, производимый по относительно старому процессу. Роль интерпозера полностью пассивна. У него нет активных элементов, поскольку его основной задачей является электрическое соединение дорожек между памятью и процессором.
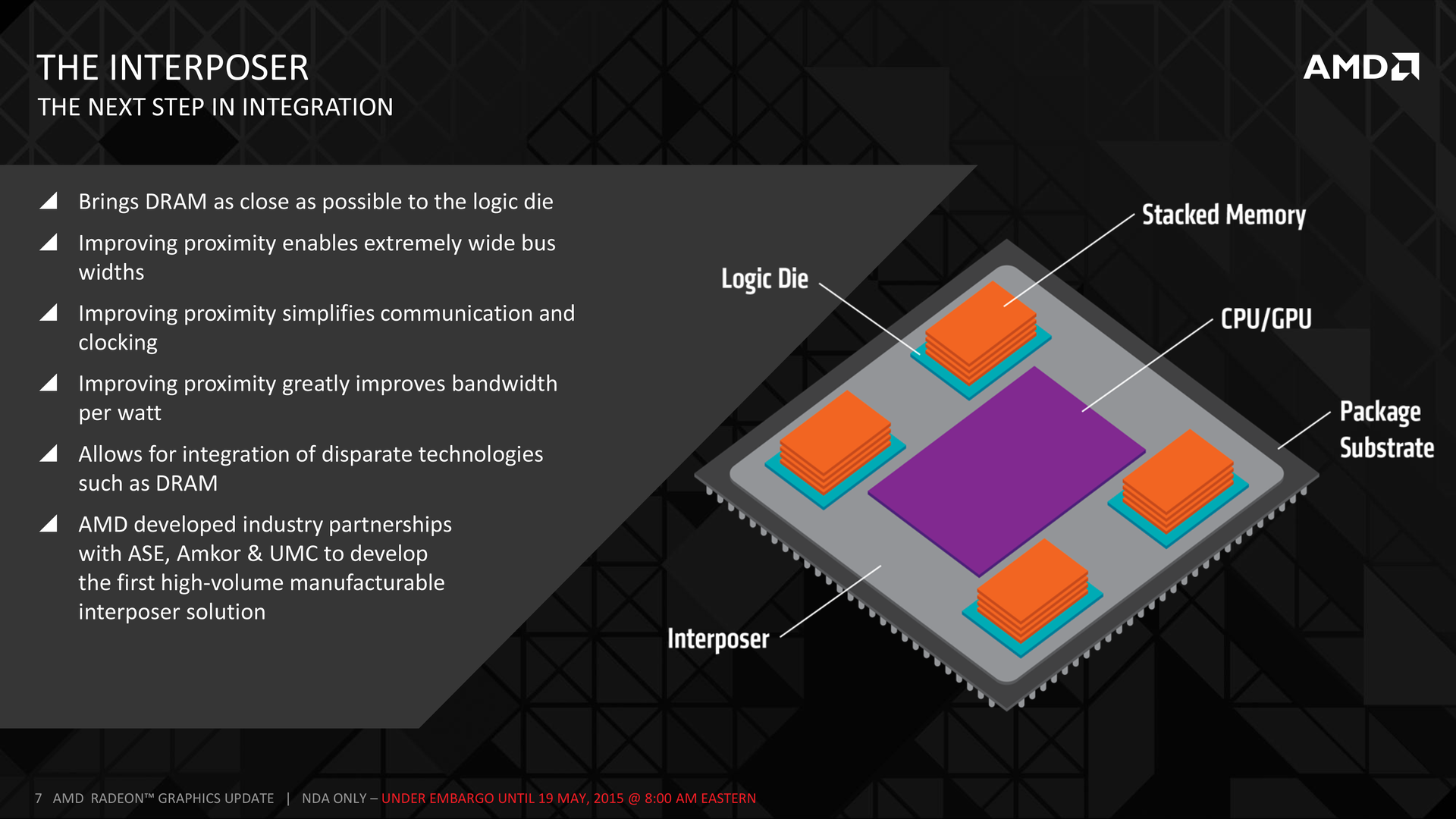
Главный чип и столбики памяти стоят на интерпозере. Поскольку это кремниевый чип, он может соединять куда больше элементов, чем обычная плата. Именно интерпозер является ключевой деталью High Bandwidth Memory. Под интерпозером расположены другие традиционные элементы, но их задачей является обмен с шиной PCI Express, вывод на мониторы и другие интерфейсы. Всё общение между видеопроцессором и памятью происходит с помощью интерпозера.

Частота работы памяти невысока (1 ГГц вместо 6), но это компенсируется очень широким соединением: 1024 бит шины на каждую из четырёх стопок. У GDDR5 шина памяти достигает 512 бит ширины, что в восемь раз меньше 4096 бит HBM. В результате уже в первом поколении HBM получается продемонстрировать преимущество пропускной способности (512 ГБ/с).
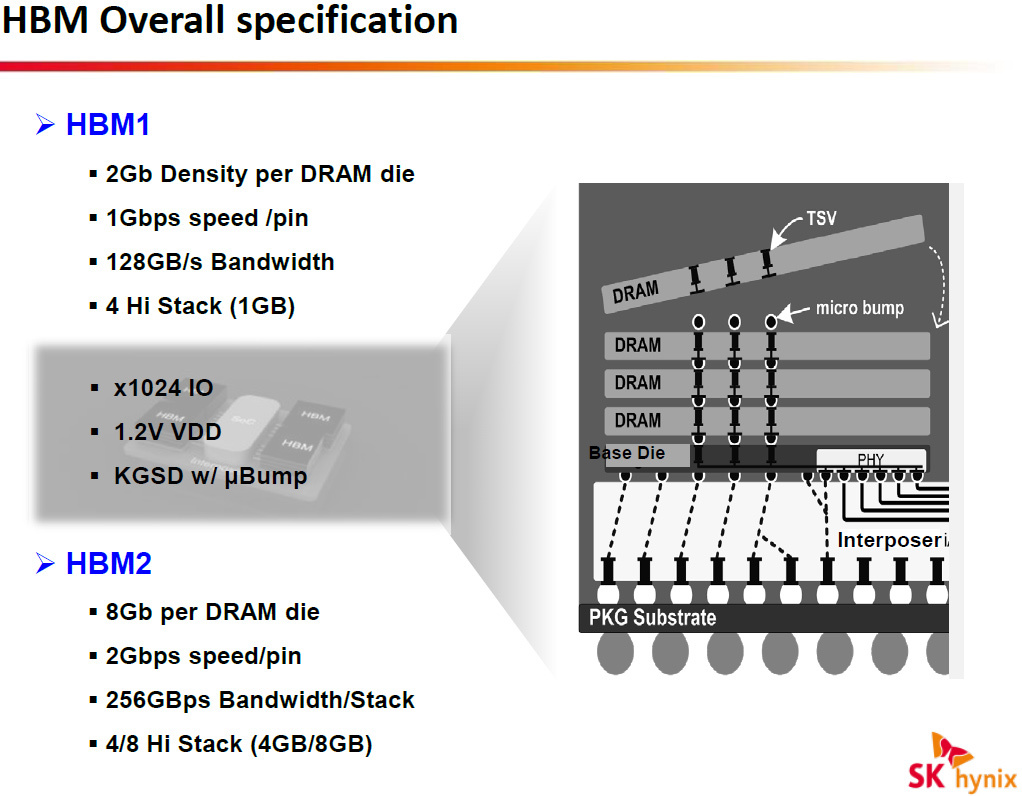
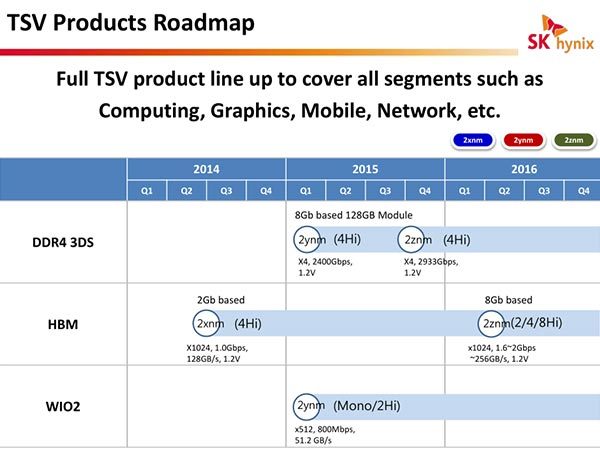
Планы Hynix по производству HBM2.
Первое поколение HBM уже используется в нескольких продуктах трёхсотой серии Radeon. Второе поколение HBM появится как в продуктах AMD, так и Nvidia. Некоторые источники считают, что факт владения HBM даст AMD приоритет доступа к HBM2. В ней скорость обмена возрастёт с 128 ГБ/с до 256 ГБ/с на каждую из стопок, а объём памяти слоя вырастет в четыре раза. Первый HBM предусматривает 4 слоя памяти в стопке, во втором будут доступны конфигурации с 4 и 8 слоями.
Следующая микроархитектура Nvidia носит название Pascal. Её основными характеристиками являются 16-нм техпроцесс FinFET+ от компании TSMC и до 16 ГБ памяти HBM2. Это даёт возможность предположить, что будет использоваться конфигурация с 4 слоями HBM2. Также доступна информация, что разработка следующего видеопроцессора Nvidia ставит целью достижение 1 ТБ/с скорости обмена данными с видеопамятью. Это в два раза больше, чем может предложить текущая Fury X.
Карты на основе Pascal впервые будут использовать NVLink, высокоскоростную шину между центральным и графическим процессорами или между графическими процессорами. Скорость NVLink значительно выше, чем у PCI Express.
Продукты Pascal начнут выходить где-то в 2016 году. (Будет интересно увидеть маркетинг модели GTX 1080 и разъяснения, что она отлично подходит для разрешений 4К.) Кое-что уже существует. На днях Nvidia представила автомобильный компьютер Drive PX 2, ядром которого являются два процессора Tegra и два неких чипа микроархитектуры Pascal. Drive PX 2 — это мощная дробилка чисел для испытания технологий робоавтомобилей, и имя Pascal упоминается в анонсе вскользь.
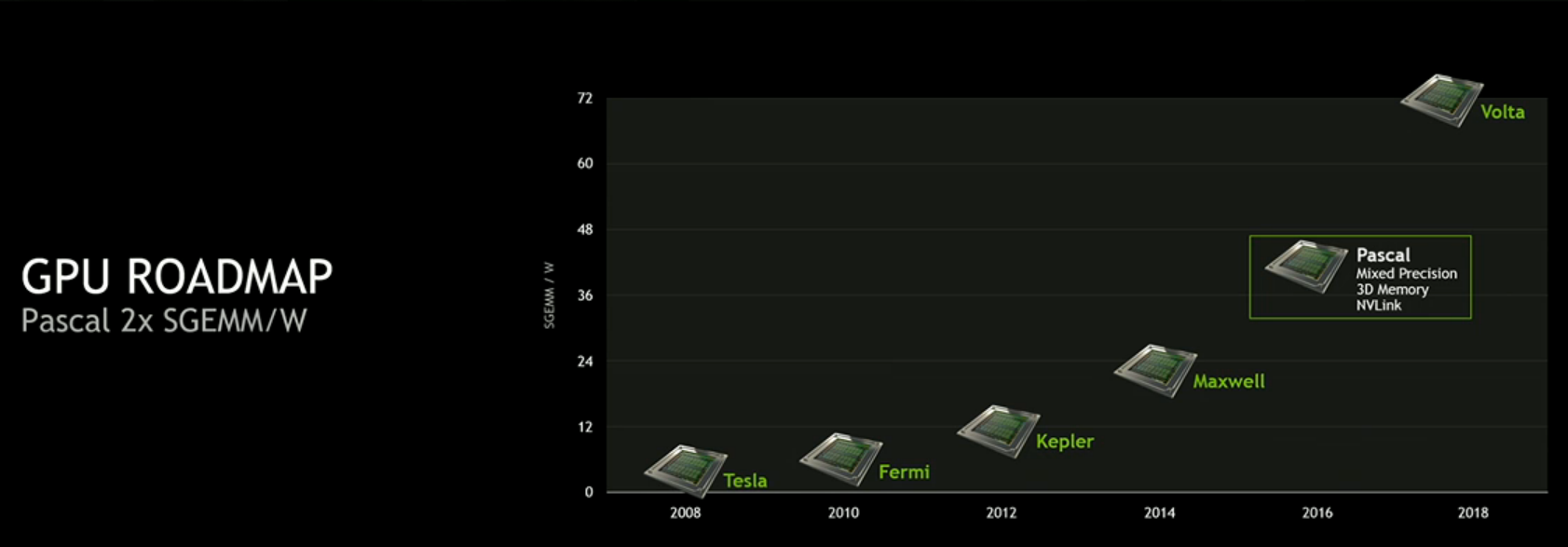
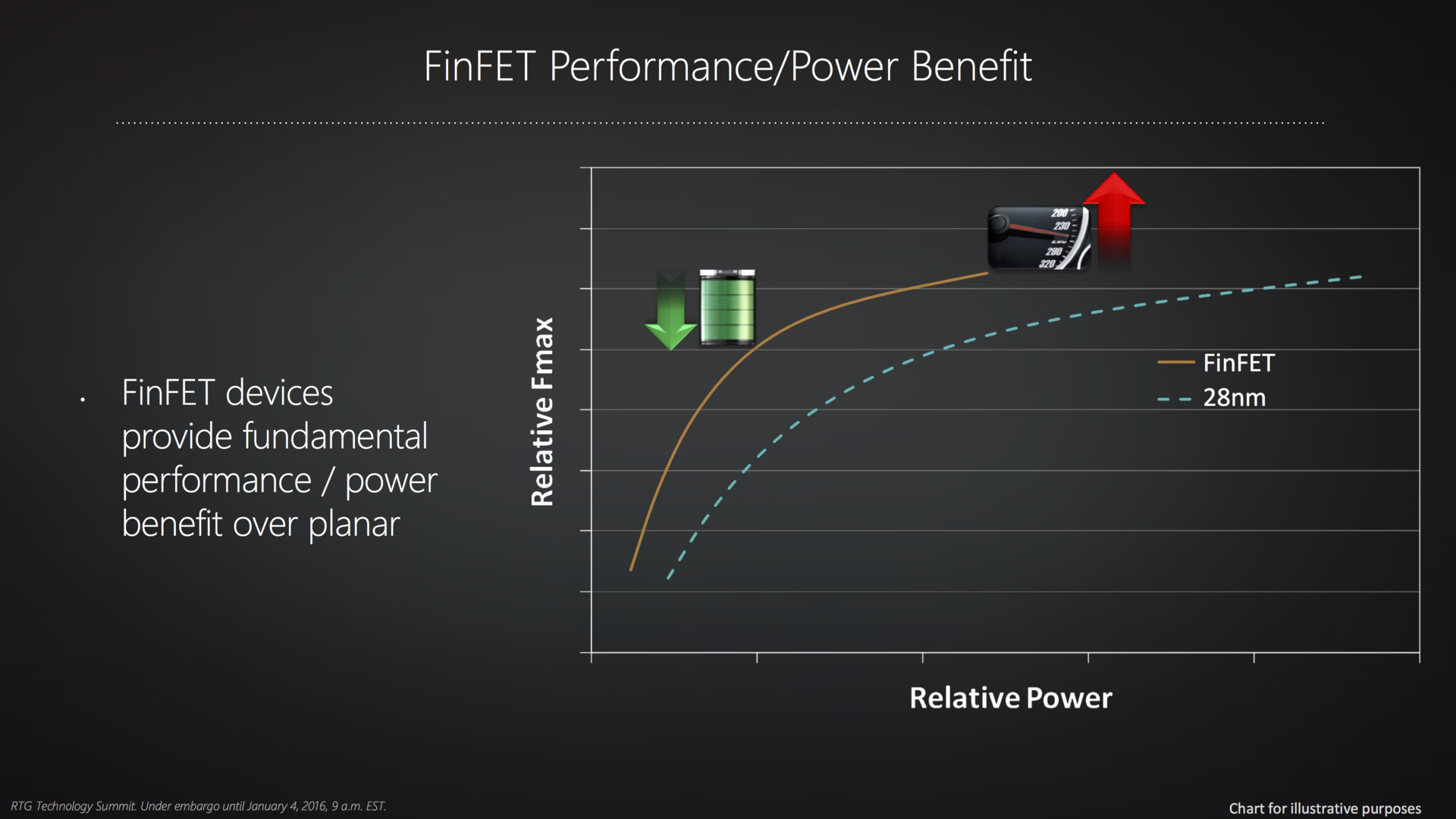
Новая микроархитектура AMD носит название Polaris. Порция данных о ней появилась 4 января. В Polaris предусмотрена поддержка HDMI 2.0a (вывод до 4K 60 FPS), DisplayPort 1.3 (вывод до 8K 60 FPS), энкодинга и декодинга 4K h.265 (HEVC). AMD будет использовать 14 нм техпроцесс FinFET. Относительно 28-нм техпроцесса будут достигнуты лучшие скорости, меньшие токи утечки, меньшее варьирование показателей элементов.

AMD найдёт идеальную точку для улучшения энергоэффективности, обеспечивая прирост производительности за счёт архитектурных изменений. Как показывает график ниже, новый техпроцесс даёт хорошее уменьшение энергопотребления при той же частоте, но не настолько крупное пространство для увеличения производительности. AMD делает акцент на производительности на ватт, а не собственно производительности. Это позволит достичь консольный уровень графики даже в компактных ноутбуках.
Впрочем, это не означает, что Polaris не продолжит рост производительности. Просто для достижения новых показателей будут задействованы изменения в архитектуре, а не тупой рост частот. AMD выдала мало информации, но из предоставленного следует, что были переработаны многие блоки графических чипов. Polaris — это четвёртое поколение Graphics Core Next, поэтому архитектура наследует те же принципы. Каждый вычислительный блок содержит 4 блока SIMD, которые в свою очередь содержат блоки векторных вычислений.

Неизвестно, продолжат ли «зелёные» использовать GDDR5 в бюджетных продуктах. Micron сделала несколько объявлений о технологии GDDR5X, которая сулит скорость примерно в два раза больше GDDR5. Впрочем, GGDR5X является проприетарной технологией Micron, и поставки возможны ближе к концу 2016 года.
В свою очередь «красные» уже заявляют, что GDDR5 останется в продуктах, которые ориентированы на низкое энергопотребление или среднюю производительность. Какие конкретно модели будут содержать «старый» тип памяти, AMD пока не говорит.
AMD продемонстрировала прототип подобного недорогого видеоускорителя микроархитектуры Polaris с памятью GDDR5 вместо HBM. Его сравнили с неназванным образцом GTX 950. Регистрировалось энергопотребление в Star Wars Battlefront в разрешении 1920?1080. Трудно сделать какие-либо выводы в этом тесте, где фреймрейт был ограничен 60 к/с, но карта на Polaris потребляла на почти 40 % меньше энергии: в районе 85 ватт против 140.

На второй минуте говорящие головы сменяются демонстрацией этого теста.
На данный момент AMD указывает на середину 2016 года как на сроки выхода Polaris-видеокарт.
По материалам ExtremeTech (1, 2, 3, 4) и Ars Technica.
Комментарии (20)
kriz10
06.01.2016 20:34+4А что за платка такая на главном фото?

a5b
06.01.2016 21:39+3Нечто вроде FUJITSU-SIEMENS D2463-A11 DVI EXTENSION ADAPTER FH PCI-E
Еще бывает сходная D2823-A11 — с одним чипом — www.ckommer.de/ebay/FSC-5730-5731/DVI-FSC-D2823-A11-GS1.JPG
ru.gecid.com/mboard/fujitsu-siemens_d2841-a11/?s=all
… материнская плата Fujitsu-Siemens D2841-A11 может комплектоваться специальным DVI-D адаптером D2823-A11, которой позволит подключить современный цифровой монитор. Данный DVI-D адаптер устанавливается в слот для видеокарт PCI Express x16 и позволяет получить еще один выход на монитор, причем цифровой… адаптер DVI-D D2823-A11 поддерживается всеми платами Fujitsu-Siemens, которые основанны на чипсетах Intel Q43 Express и Intel Q45 Express
Вероятно, данный южный мост умеет переключать часть пинов из PCIe в DVI-D режим — www.intel.com/content/dam/www/public/us/en/documents/datasheets/4-chipset-family-datasheet.pdf
1.2.4 Multiplexed PCI Express* Graphics Interface and Intel®
sDVO/DVI/HDMI/DP Interface
For the 82Q45, 82Q43, 82B43, 82G45, 82G43, and 82G41 GMCHs, the PCI Express
Interface is multiplexed with the SDVO and HDMI/DVI interfaces.…
The GMCH supports two multiplexed SDVO ports that each drive pixel clocks up to
270 MHz. The GMCH can make use of these digital display channels via an Advanced
Digital Display card (ADD2) or Media Expansion card.
Продолжение https://en.wikipedia.org/wiki/Serial_Digital_Video_Out
Taciturn
06.01.2016 23:18+3На других фотографиях этой платы можно прочесть маркировку чипа — это PI3VDP411LS — www.pericom.com/products/display-interface/part/PI3VDP411LS — мост DisplayPort в DVI/HDMI.
kriz10
07.01.2016 21:35+1Спасибо за ответ! Теперь понятно!
a5b
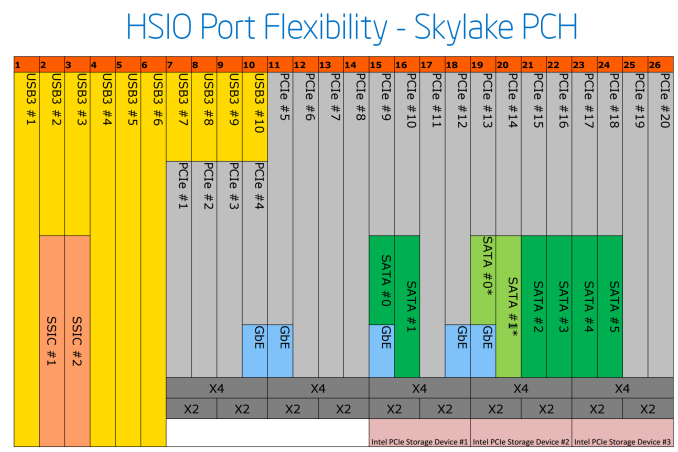
07.01.2016 22:22+1У современных чипсетов (Z170) еще хуже — больше мультиплексирования групп выводов между USB3 / PCIe / GbE / SATA:
www.anandtech.com/show/9485/intel-skylake-z170-motherboards-asrock-asus-gigabyte-msi-ecs-evga-supermicro
images.anandtech.com/doci/9485/PCH%20Allocation_575px.png
Вероятно, используется нечто вроде Multi-Protocol PHY / Multi-Standard SerDes (списки DR для GF, SMIC, TSMC, UMC; Synopsys, Cadence; конечно же высокие скорости лишь на 28 и более тонких техпроцессах): www.intel.com/content/dam/www/public/us/en/documents/white-papers/phy-interface-pci-express-sata-usb30-architectures.pdf
There may be PIPE implementations that support multiples of the above configurations.… A PHY that supports multiple rates in either PCI Express Mode or SATA Mode must support configurations across all supported rates..
(Есть скептики по поводу подобных Multiprotocol-PHY IP — www.semiwiki.com/forum/content/3240-does-multiprotocol-phy-ip-really-boost-ttm.html)

{kind=link}
{kind=link}

potan
07.01.2016 20:48А технологию со столбиками памяти для встраиваемых однокристалок не хотят применять? Для любительских устройств возможность в каджую пуговицу запихнуть полноценную версию ОС была бы очень приятной.
furtaev
Осталось создать такие игры, которым будет нужно 16 Гб видеопамяти. А вот с этим (производством качественных игр) в последнее время дела гораздо хуже, чем с законом Мура.
Undiabler
Вот как раз с этим (привет размыленым тестурам из фолаута 4 в 2к) проблем не будет никаких. Будет больше ресурсов — разработчики будут писать менее оптимизированный код. Посмотрите что стало с гугл хромом когда ram стал доступен обычному пользователю в больших количествах. То же будет и с видеопамятью)
anloop
Создать-то говнокодерам — не проблема. Вопрос в другом: а под что будут использоваться эти ресурсы? Смотрю на свежие AC:S\JC3 — куда там 4 Гб видеопамяти? На мутные текстуры? На посредственные эффекты?
neomedved
Проблема в том, что мыльные текстуры занимают 4гб, оставаясь при этом мыльными. На чёткие памяти не хватает.
zorge_van_daar
Ой-ой, только не надо про говнокодинг) Мы не сайтики в Индии на PHP собираем. Мыльцо это как раз про слабое железо и старые консоли. То самое мыльцо это попытка выжать нормальную картинку там, где должны быть ступеньки пикселей. Это мыльцо — несколько поколений развития математических алгоритмов и их реализации с заточкой на определенные ограничения железа. Дайте железа и получите фотореалистичную картинку. И физики на сдачу.
Aclz
Если это супер-алгоритмы в седьмом колене, то откуда 4 Гб?? У меня уже лет 15 валяется демка farbrausch, графика там, конечно, ещё тех годов (уровня Quake 1-2), но 5-минутная exe-демка с анимацией, шейдерами и саундтреком запихана в 64 Кб! Такой бы подход да к современным поделиям…
Если кто не видел и не побоится запустить: https://www.dropbox.com/s/e3kr7k9y07bclhf/FR08V101.EXE?dl=0
zorge_van_daar
Попрошу не путать случаи. Мыльцо — это вынужденная мера, для того, что бы запихнуть игру в приставку 7 поколения (xbox 360, ps3). У них что-то вроде 512 мб памяти всего (оперативная и видео). Ни о каких 4 гб видеопамяти там и не шло речи. Вот для того, что бы получить современную картинку на полугигабайте, и нужно экономить на всем что есть, в т.ч. и текстурах высокого разрешения. А как сэкономить на текстурах и получить хорошую картинку? Все просто — возьми маленькую текстуру и замыль.
А то, что на ПК (которые обзаводятся новым железом) выпускают игры под консоли десятилетней старости, так это — претензии маркетологам. Гта 5 выпустили на ПК. Год пришлось доделывать — зато картинка. А год доделки это деньги, а ради кого — ради ПК-шников, которые все спиратят? Таки дела.
А по поводу демок — вам по демке не ходить, на демку не охотиться. В демке контент по большей части генерируется, а значит он достаточно скучный. Просто в 64 кб нельзя запихнуть интересный мир. Против математики не попрешь — хочешь все интересно и красиво — давай информацию, дашь мало информации — тебе сгенерируют простые или однотипные объекты в игре. Талант демосцены — создать вау там, где если разобраться, ничего нет. А написать хорошие алгоритмы генерации — тут скорее мастерство, нежели талант. Кстати, мыльцо это тоже алгоритм генерации вау картинки из малого количества информации, так, что мыльцо намного ближе к демосцене, чем вы думаете.
Alexsey
Далеко за примером ходить не надо — VR. Если технология действительно пойдет в массы то увеличение разрешения и, соответственно, требуемой видеопамяти не заставит себя долго ждать.
esc
Да увеличение разрешения уже давно не кушает основную часть памяти. Экран в 4К весит 8 847 360 * 4 = 35.3 МБ. Даже если буфферов экрана будет десяток, это будет всего лишь 353МБ памяти.
SpaceEngineer
Буферы-то должны быть хотя бы half float, так что умножайте на два. Обычно сейчас используется deferred rendering, а там кроме цвета нужно хранить нормали, глубину, индекс матрериала и другое. Типичный G-буфер это 4 RGBA буфера. Умножайте на два, если это VR. Плюс вспомогательные буферы для всяких эффектов.
На подходе «настоящее 3D» — голограммы и воксельные дисплеи. Они как раз сейчас утыкаются в ограниченную производительность железа и пропускную способность каналов вывода изображения. Поэтому в прототипах нам показывают тупо вращающиеся кубики.
Что ещё требует безумной вычислительной мощи? Конечно же, нейросети и ИИ. К тому моменту, как станут понятны принципы работа мозга (уже в конкретных деталях), железо как раз поспеет, чтобы эмулировать его.
esc
А вы цифрами оперируйте, посчитайте сколько те буфферы, что вы привели будут весить на примере, скажем oculus rift. И, кстати, зачем для vr множить на 2? Для каждого глаза ведь 2 отдельных кадра, дублировать надо только экранные буфферы, остальное считается как новый кадр.
Мы обсуждаем 16ГБ в современной видеокарте. При чем тут воксели, голограммы и ИИ?
В современной карте эту память съедят в основном текстуры (и подобные данные).
SpaceEngineer
При том, что что-то из этого может стать реальностью в ближайшие 10 лет. Воксели уже нужны, на 3D текстурах можно делать крутые вещи (по сути полноценный рейтрейсинг), но жрут памяти они огого. Вендоры даже придумывают всякие хитрые способы их сжимать. Например, в эти 16 Гб влезает всего лишь одна 3D текстура размером 1024*1024*1024 (float RGBA).
esc
Вы серьезно? Обсуждаем текущий объем видеопамяти говоря о технологиях, которые появятся в течение 10 лет?
Будут воксели, под них и будут делать видеокарты хоть со 128ГБ на борту. А то, что делают сейчас надо освоить теми технологиями что есть сейчас.