
Если трезво смотреть на мир, то транспортная сеть состоит из кучи «костылей», чего только стоят такие технологии как nat (во всех его видах) или virtual links в ospf. Прочитав драфт rfc , посвященный EnIP, я понял, что это очередной костыль. Но честно говоря идея мне понравилась. Ну, начнем.
Не буду говорить как тяжело сейчас живется и как мало у нас IPv4 адресов (это все и так уже слышали), а перейду непосредственно к технологии.
Итак, что же такое EnIP. На первый взгляд разработчики взяли два IPv4 адреса и склеили их в один, получив при этом 64 битый адрес вида 192.0.0.1.10.0.0.1. Казалось бы адресное пространство увеличилось более чем в 4 миллиарда: с 2^32 до 2^64, теперь провайдерам не надо переходить на IPv6, IANA может снова раздавать адреса пачками направо и на лево. Но давайте разберемся на сколько реально увеличится адресное пространство. Для этого приведу пару фраз из rfc:
Because it is IPv4, it maximizes backward compatibility while increasing address space by a factor of 17.9 million.
This could allow the reassignment of small segments of unused address blocks in /8 networks to registries with chronic shortages of IP addresses
У нас есть три распределенных блока адресов, который можно перераспределить, не потеряв обратную совместимость между IPv4 и EnIP– это приватные диапазоны 10.0.0.0/8, 172.16.0.0/12 и 192.168.0.0/16. Делаем не сложные подсчеты (2^32*2^24)+(2^32*2^20)+(2^32+2^16) и убеждаемся, что количество маршрутизируемых в интернете адресов увеличится в 17,9 миллионов раз. Конечно, стоит упомянуть, что помимо префикса из приватного адресного пространства 10.0.0.0/8,172.16.0.0/12 и 192.168.0.0/16, необходимо иметь (или получить) хотя бы один глобально маршрутизируемый префикс, иначе ничего не заработает.
Примечание: есть еще префикс 240.0.0.0/4, но он до сих пор не распределен, а в драфте RFC говорится о перераспределении. Может быть когда драфт данного rfc обретет статус официального документа, что то поменяется, но я очень в этом сомневаюсь.
Итак, подведем маленький итог. Что же на самом деле сделали разработчики. Они взяли адреса приватных диапазонов и предложили приделать их ко всем глобально маршрутизируемым префиксам, тем самым увеличив количество доступных для маршрутизации в интернете (так сказать белых) адресов.
Но тогда возникает здравая мысль-как без модернизации стандартного IPv4 заголовка реализовать идею разработчиков, ведь под адреса в IPv4 заголовке выделено 64 бита ( 32 на source IP и 32 на destination IP):
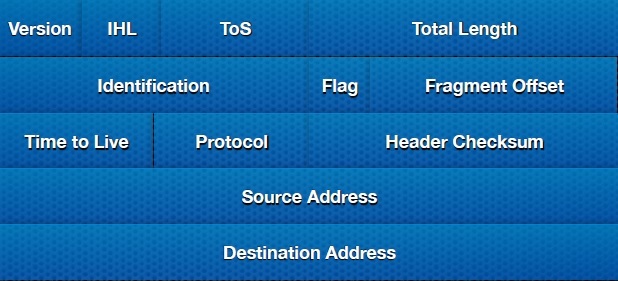
Если мы изменим заголовок — то получим не IPv4, а что то новое и неизвестное. В такой ситуации проще сразу перейти на IPv6. Но разработчики нашли выход, который помимо того, что не требует внесения изменения в IP заголовок, еще и не требует больших вложений со стороны провайдеров (необходимо лишь произвести апгрейд софта).
Надеюсь, что все знают, что заголовок IPv4 может быть дополнен несколькими полями опций. В EnIP к 20 байтам основного заголовка добавляется поле опций, длинной 12 байт, таким образом получаем такой заголовок длинной 32 байта:

Как указано на рисунке поле опций включает два поля под адреса, называемые Extended Source Address и Extended Destination Address. Думаю вы уже поняли основную идею — хоть адрес и представлен в виде одного 64-битного адреса, на самом деле таковым не является и размещается в заголовке в двух полях — поле адреса в заголовке и поле расширенного адреса в опциях. Перейдем непосредственно к механизму работы данной технологии.
Для наглядности будем использовать следующую топологию:

Условно можно разделить сеть на две зоны: одна зона, где для маршрутизации используется префикс из приватного диапазона 10.0.0.0/8 ( от EIP1 до N1, от N2 до EIP2) и зона, где используется глобальный уникальный префикс ( от N1 до N2).
Теперь разберем, как будут меняться значения полей в IP заголовке при передаче от узла к узлу.
Узел EIP1 получает от DNS сервера адрес узла EIP2 вида 65.127.221.2.10.3.3.2. (о нюансах работы DNS в данной технологии мы поговорим ниже). Далее узел EIP1 разбивает полученный адрес на два адреса: адрес сайта (site address) 65.127.221.2 (он должен быть глобально маршрутизируемым) и адрес хоста (host address) 10.3.3.2. Составляя пакет, узел EIP1 помешает адрес сайта (65.127.221.2) в поле адреса назначения в заголовке, адрес хоста (10.3.3.2) в поле расширенного адреса назначения в опциях, а так же свой адрес в поле адреса источника в заголовке (10.1.1.2), как показано на иллюстрации ниже:
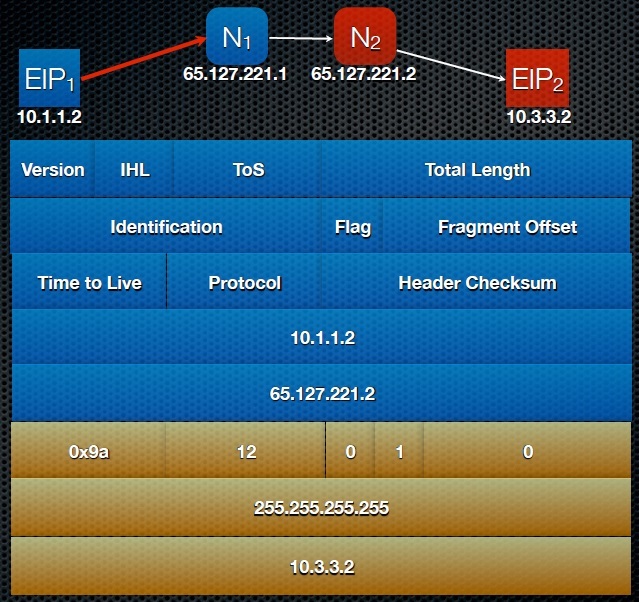
Как видно из иллюстрации, extended source address (расширенный адрес источника пакета) не задан. Дело в том, что EIP1 не знает данного адреса (подобно технологии NAT – узел не знает своего глобального уникального адреса), поэтому и подставляет вместо адреса все единицы (255.255.255.255), как это регламентирует RFC:
The Enhanced Source Address in the EnIP header is set to all ones since an EnIP source address is not currently present
Стоит так же обратить внимание на поля флагов ESP и EDP в поле опций. Поднятый флаг в ESP говорит о наличии Enhanced Source Address, а EDP – о наличии Extended Destination Address.
В представленном выше заголовке в поле опций отсутствует расширенный адрес исходящего узла, поэтому флаг ESP выставлен в 0.
Далее пакет с указанным выше заголовком попадает к узлу N1. N1 производит анализ полей заголовка и опций, переносит адрес хоста 10.1.1.2 из заголовка в опции, а вместо Source Address в заголовок вписывает свой глобально маршрутизируемый IPv4 адрес, так же меняет значения флага ESP на 1, так как теперь заданы оба расширенных адреса; пересчитывает контрольную сумму и отправляет пакет в соответствующий интерфейс (поля, которые изменяются выделены зеленым цветом):

Почему нам необходимо поменять исходящий адрес? Дело в том, что согласно rfc, если в открытом интернете маршрутизатор получит пакет с приватным исходящим адресом или приватным адресом назначения, он должен отбросить этот пакет. То есть имя приватный адрес, пакет просто не будет отправлен в глобальную сеть. Мы этого не хотим, поэтому маршрутизатор меняет приватный адрес на глобально маршрутизируемый
Теперь пакет имеет в заголовке глобально маршрутизируемый адрес назначения и источника в заголовке, что позволит ему беспрепятственно передаваться в интернете, а в опциях сохранена информация о конечных адресах хостов.
Приняв пакет, узел N2 тоже производит анализ заголовка. Так как узел N2 видит, что пакет предназначен ему, он начинает анализировать опции, перемещает адрес хоста (10.3.3.2) из опций в поле адрес назначения заголовка, а поле расширенного адреса в опциях обнуляет (так как теперь в этом поле нет смысла). Так как в заголовок были внесены изменения, N2 должен произвести пересчет контрольной суммы заголовка, а так как в поле extended destination address теперь нет адреса, то N2 также должен сбросить значение флага EDP.
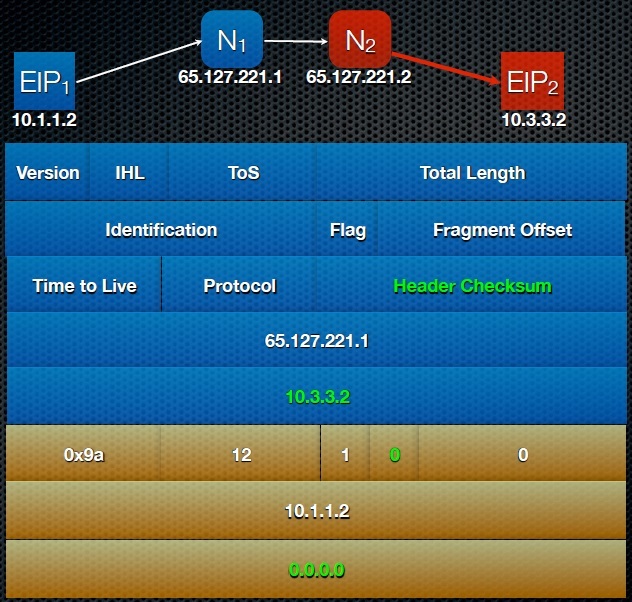
Узел EIP2, приняв пакет, видит что данный пакет получен с адреса 65.127.221.1.10.1.1.2 ( адрес сайта 65.127.221.1, адрес узла 10.1.1.2. Зная этот адрес, EIP2 может отправить ответное сообщение узлу EIP1.
Теперь перейдем к еще одному важному звену технологии EnIP – DNS сервер. Для работы описанной технологии необходим DNS сервер, умеющий работать с AAAA записями. По сути нам нужен IPv6 DNS-сервер.
Хост EIP1 делает запрос на определение IP адреса, какого то сайта, к примеру mysite.ru. Данный процесс проиллюстрирован ниже:
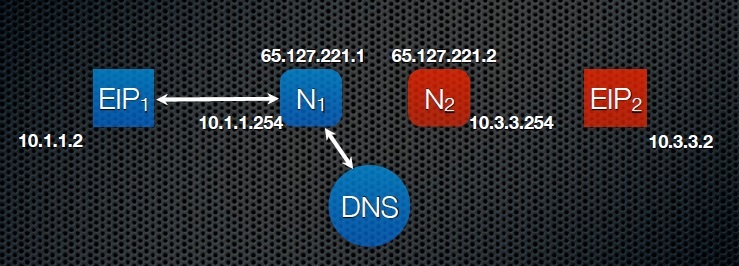
DNS сервер находит в свое базе данных запрошенный адрес сайта mysite.ru и предоставляет информацию в виде… IPv6 адреса. Зачем нам IPv6 префикс?? Для начала надо вспомнить, какие адреса IPv6 зарезервированы. Все вспоминать не будем, нам нужен префикс 2001:0101::, который был зарезервирован для экспериментального применения.
Теперь вернемся к полученной от DNS сервера информации. В ответ на наш запрос, мы получили вот такой IPv6 префикс: 2001:0101:417F:DD02:0A03:0302::0. Но зачем он нам? Ответить на этот вопрос мы сможем, если переведем полученный префикс из шестнадцатеричной системы в десятичную:
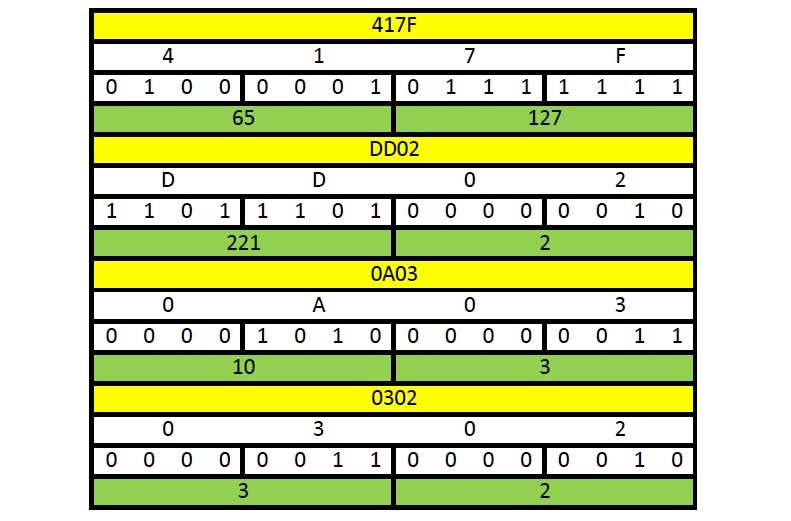
Оказывается 417F:DD02:0A03:0302 после перевода из шестнадцатеричной системы в десятичную отображаются как 65.127.221.2.10.3.3.2. Выбраны именно эти группы префикса, так как первые две группы это зарезервированный префикс 2001:0101::, а группы 7 и 8 всегда равны нулям.
Узел EIP1 проделывает показанную выше операцию и получает необходимый для передачи сообщения адрес.
На этом думаю можно закончить с кратким обзором технологии. Если остались вопросы задавайте, попробую на них ответить.
Информация взята из RFC по ссылке в начале статьи. Иллюстрации взяты из презентации по ссылке .
Комментарии (42)

Bormoglotx
12.01.2016 21:29В каком смысле сломает? Имеете ввиду nat? Если да, то кто сидел за ним, так и будет сидеть.

click0
12.01.2016 21:49+1У многих аппаратных решений до сих пор нет полной поддержки IPv6, а вы тут предлагаете очередной костыль для IPv4.
Bormoglotx
12.01.2016 22:11+2Половина транспорта — костыли. Но приходится с ними работать. Ну а о поддержке ipv6 — парк оборудования, с которым я работаю полностью его поддерживает, честно говоря давно не встречал оборудование, не поддерживающее ipv6 — во всяком случае на оборудовании операторского класса такой беды не наблюдал.

DoMoVoY
12.01.2016 22:19+5Не взлетит. Индустрия давно движется к dualstack. Для этого есть NAT44 + Native IPv6. Вряд ли эту отлаженную схему будут менять. 90% сервисов в ближайшие 10-20 лет мигрируют на IPv6, а IPv4 останется для совместимости старого софта.
khim
12.01.2016 23:04+1Оглянитесь по сторонам: много вы видите сетей на базе IPX? А ведь лет 20 назад их было чуть ли не 90%.
Так и с IPv4. IPv4 вымрет — и довольно быстро. И примерно даже понятно когда.
После того, как пользователей с поддержкой IPv6 станет больше, чем пользователей без оной поддержки вложение станет элементарно невыгодно вкладывать деньги в поддержку IPv4 пользователей.
Какое-то время будет казаться, что «всё отлично, ведь web-сайты работают», чего ещё нужно? Но появится какой-нибудь очередной WhatsApp без поддержки IPv4 — и всё кончится.
Конечно предсказать заранее какой именно сервис запустит лавину нельзя, но так ли это важно в долгосрочной перспективе?DoMoVoY
12.01.2016 23:13Ситуация с ipv4 и ipx разная. ОС NetWare не выдержал конкуренции, да и устройств на этой ОС было на несколько порядков меньше чем сейчас IPv4. Останется множество телефонов, камер и других устройств, которые не получат обновление ПО с поддержкой IPv6 и оператор связи не сможет отказать такому клиенту лишь по причине «мы используем только IPv6». Трафик уйдет на новую версию — освободятся мощности для NAT — они и будут поддерживать совместимость без дополнительных вложений.
khim
12.01.2016 23:26+1А зачем ему отказывать? Достаточно выкатить ценник подольше. Что, во многих случаях, произойдёт автоматом. Какой смысл провайдеру за свой счёт кому-то предоставлять сервис?
4G, скажем, требует IPv6, а стоимость килобайта там будет элементарно ниже. То же самое и в других случаях. А дальше — спираль начнёт сжиматься: поддержка «освободившихся мощностей для NAT'а» будет ложиться на всё меньшее число абонентов, что в свою очередь, заредёт цены ещё выше.
Не нравится пример с IPX — вспомните про модемные пулы. Принцип тот же: вначале «старая» технология становится «слегка дороже», потом ещё, а потом неожиданно и резко она становится вдруг «сильно дороже», после чего умирает.
Конечно речь тут идёт о годах, а не днях. Но очень сильно сомневаюсь что о десятилетиях. Скорее речь может идти о десятилетии — одном.
Подавляющее большинство устройств может быть поддержано «прозрачным proxy» на домашнем роутере — вот такой вариант, вполне возможно, будет жить ещё долго.

Just_Wah
13.01.2016 15:23сложно согласиться. Между IPX и IP разница несколько иная, чем между IPv4 и IPv6. И сейчас хватает ПО, которое работает только на IPv6. Тот же DirectAccess, например. Что никак не мешает механизму инкапсуляции. Так что, как мне кажется, ПО тут роли особой не сыграет. Например, в службах кластера Hyper-V при трансляции содержимого оперативной памяти с ноды на ноду даже IP протокол не используется в качестве функционального.
khim
13.01.2016 17:08Вся история перехода и с IPX на IPv4 и с IPv4 на Ipv6 описывается пресловутым закона Меткалфа.
Для одной IPX-сети Меткалфа действует, спору нет — но IPX-сети ограничены размером, автоматической маршрутизации нет, весь шарик ими не покроешь. Потому куча отдельных IPX-сетей очень быстро стали менее «полезны» чем одна, единая TCP/IP сеть.
Пока у IPv4 сетей были резервы (IP-адресов хватало) ни у какой другой технологии (EnIP, IPv6 или чего-нибудь ещё) шансов не было. Однако появление многослойных NAT'ов хотя и дало резервы для расширения сетей, но оный закон «сломало», причём кардинально. Исчерпание IP-адресов же фактически развите в смысле «полезности» заморозило вообще. Ни о какой «сети» в современном Интернете речи не идёт. Куча сервисов фактически перешла на топологию «звезда» — и «не от хорошей жизни».
IPv6 же, хотя и начал развиваться сильно позже, развивается примерно теми же темпами, что и IPv4 поначалу. Закон Меткалфа действует, хотя много организаций прилагают усилия, чтобы его ограничить. Когда IPv6 сеть станет «полезнее», чем IPv4 сеть, то она довольно быстро убьёт старую.
Но для того, чтобы это случилось нужно не просто ПО, которое работает поверх IPv6, а такое ПО, которое будет эффективнее работать при прямом соединении, а не при работе через сервера. DirectAccess — это круто, конечно, не только там никакой сети нет, фактически речь идёт о соединении точка-точка (хотя и поверх Интернета). Нужно ПО где будут устанавливаться прямые соединяние между клиентами (для тех или иных нужд). Только такое ПО сможет «проявить» закон Меткалфа и «убить» IPv4. Претендентов — вагон, но ясно, что 99% из них умрут. Но в то, что умрут все — я не верю.Just_Wah
13.01.2016 18:21если совсем формально подходить, то ПО работает на 4 уровне модели DOD и ему глубоко все равно, как будет доставлена информация до другого ПО на другом участнике сети. Главное, чтобы они нашли друг друга. Другими словами, у ПО есть функциональные требования и не функциональные требования. И отнести IP протокол к функциональным, на мой взгляд, никак нельзя. Это лишь средство транспорта. Т.е. все фишки IPv6 касаются лишь стороны соединения и функционирования соединения. Накладные расходы, которые уменьшает IPv6 и дополнительный функционал вполне реализуем и на IPv4.
И я, если честно, не уловил почему IPX не маршрутизируемый протокол? Создавайте подсети и настраивайте маршруты. Все будет бегать. По чуть иным условиям, но концепция точно такая же. Что же до ограничений размером, то это субъективно. Зависит не от размера шарика, а от количества потребителей. Когда-то и IPv4 казался неисчерпаемым. IPv6 хоть и имеет совершенно иные способности к масштабированию, тоже не бесконечен.khim
13.01.2016 23:47+1И я, если честно, не уловил почему IPX не маршрутизируемый протокол?
Потому что таким уж он сделан.
Создавайте подсети и настраивайте маршруты.
Серьёзно? Как аналог BGP для IPX называется не подскажите?
Да, на базе IPX можно было бы сделать вполне современный протокол. Но… не сделали. Эту нишу занял IP.
Т.е. все фишки IPv6 касаются лишь стороны соединения и функционирования соединения. Накладные расходы, которые уменьшает IPv6 и дополнительный функционал вполне реализуем и на IPv4.
Не реаализуются. Смысл закона Меткалфа — в том, что ценность сети зависит не от количества участников, а от количества потенциально возможных связей между ними, а это — квадрат количества участников. IPv4 интернет сейчас устроен как «ядро», мощность которого растёт как положено, квадратично (сервара) и «периферию» (оконечное оборудование), которое соединяется только с ядром.Just_Wah
14.01.2016 10:16+1мне кажется, вы не совсем понимаете разницу между маршрутизируемым протоколом, которым является IPX (и тот же IP) и протоколом маршрутизации, которых великое множество. Последний раз с IPX я работал в 95 году, поэтому вряд ли могу что-либо сообщить о нем, т.к. в 96 году все стремительно перешли на IP.
khim
14.01.2016 16:25+2Мне кажется это вы не понимаете разницы между теорией и практикой. В теории свойства протокола могут влиять на что-то сами по себе, безотносительно к окружающей обстановке. На практите, увы и ах, но «короля играет свита».
IPX — более новый и потому более прогрессивный протокол. В частности адреса там 80-битные, так если бы, вдруг, в 90е годы выиграл IPX, то никакого болезненного перехода на IPXv6 бы не потребовалось.
Однако, увы и ах, к моменту, когда IP и IPX сети схлестнулись IP-сети были уже региональными и BGP был уже третьей инкарнацией соответствующих инженерных наработок (после GGP и EGP), а IPX сети застряли на RIP и EIGRP с NLSP. Это позволяло поддерживать локалки довольно-таки приличного размера, но на региональные сети (и тем более на глобальные) не тянуло.
Эксперимент с объединением сетей оказался слишком удачным и ни у IPXа, ни у пресловутых OSI протоколов не осталось времени. От последних осталась идиотская OSI модель?), а IPX… IPX попросту сгинул.
??????
?) Строго говоря ничего идиотского в OSI модели нет. Идиотским является её использование. Когда выяснилось что денег спалили дофига и больше, а практического применения у этого чуда нет кому-то пришла в голову «спасительная» мысль: а пусть то, что мы породили будет не описанием мертворождённого высера, а как бы типа «описание всех сетей вообще». Попасть под обвинения о растрате никому не захотелось и OSI модель ретроспективно сделали описанием всех сетей вообще. С тех пор мы с этим идиотизмом и мучаемся. Это всё равно как взять чертежи и термины от танка и применять их при работе с самолётами. И делать вид, что у самолётов тоже есть гусеницы и трансмиссия.Just_Wah
14.01.2016 18:16-1Простите, а что в OSI модели идиотского? Обычная абстракция. Впрочем, т.к. вы не различаете маршрутизирумые протоколы (т.е. протоколы с возможностью организации сегментов) и протоколы маршрутизации (т.е. протоколы, призванные строить маршруты между уже созданными сегментами) то у вас есть определенные пробелы в сетевых знаниях.
khim
14.01.2016 18:46Простите, а что в OSI модели идиотского?
Как я уже сказал: идиотизм заключается не в OSI модели, как таковой (для описания OSI протоколов она подходит как нельзя лучше), а к попыткам прикрутить её к TCP/IP. В котором, на минуточку, уровней не 7, а 4. Да и «разделение обязанностей» между ними совсем не такое как в OSI. Если вы начнёте устраивать разные виды инкапсуляции, то уровней может и 10 оказаться, только вот беда: к 7 уровням OSI модели это всё равно всё не будет иметь никакого отношения.
у вас есть определенные пробелы в сетевых знаниях.
Ну тут как бы вопрос о том, чего вы хотите.
Если вы под сетевыми знаниями понимаете «умение складывать „умные“ слова в „умные“ фразы не понимая что за всем этим стоит» — то да, в этих знаниях у меня пробелы. Если вы понимаете под этим «умение проектировать и создавать системы, которыми будут пользоваться миллионы (а то и миллиарды) пользователей» — то тут дело другое. Тут мне есть что сказать.
Выбор — за вами, как всегда.

ayurtaykin
12.01.2016 22:34+2Забавная технология, но мне кажется что по производительности на маршрутизаторах будет тоже самое что NAT (а вероятно и гораздо медленнее).
И я так понимаю «проблему клиента» оно не решает, без апгрейда клиентских устройств они не смогут подключиться к такому URL который резолвится в IPv6 адрес — а значит никто не будет так хоститься ибо это убыточно.
Проще уже дождаться IPv6.khim
12.01.2016 23:14+3Оно другой проблемы не решает: все эти пакеты пойдут на всех роутерах через софт. Замедление — катастрофическое. То есть для практического использования не одним-двумя пользователями для соединения двух офисов, а для всего интернета — нужно менять всё оборудование. Если менять оборудование — можно порейти на IPv6. Так спрашивается: нафига козе баян?
Ovsiannikov
13.01.2016 03:52не, софт надо менять только в 4-5 местах, причём 2 из этих мест сами хосты.
khim
13.01.2016 04:13+3Надо менять не софт. Надо менять железо. IP пакеты был опций CISCO обрабатывает в «железе» (hardware switching). IP пакеты с опциями отправляются в Cisco IOS, где обрабатываются программно. Разница в скорости — хороше если на порядок (а не на два).
Что это значит? Если хотите обработать сколько-нибудь осмысленный процент траффика в режиме EnIP — извольте заменить всё оборудование на всех магистралях. Но, позвольте, если мы закатали рукава и уже меняем всё оборудование — почему сразу IPv6 не внедрить?Bormoglotx
13.01.2016 12:57+1Вообще, разработчики позиционируют данную технологию, как решение проблем с катастрофической нехваткой IP адресов для мобильных девайсов, особенно в свете того, что технология 4G вообще не предусматривает CS-Core, и все соединение должно устанавливаться через IMS. Это значит, что каждый телефон должен иметь поддержку SIP и передачу данных в сетях 4G. Внедрить в телефон поддержку EnIP не думаю что сложно, как и обновить софт на некоторых железках.
То что IP пакеты с опциями попадают на CPU а не обрабатываются на ASIC конечно плачевно, но где-то в описании EnIP я натыкался на стоки кода, которые позволяют транзитным маршрутизаторам игнорировать поле опций, если оно имеет код 26. ASIC — по сути компьютер на чипе, и думаю реализовать на них такую функцию можно (могу ошибаться, поправьте если что).
Есть еще один вариант избежать обработки опций транзитными маршрутизаторами — MPLS. Навешиваем метку, FEC — адрес маршрутизатора, который должен произвести замену адресов. Что бы метка не была снята до попадания на узел, который должен произвести смену адреса назначения, можно использовать explicit nul label.
khim
13.01.2016 16:18+1ASIC — по сути компьютер на чипе, и думаю реализовать на них такую функцию можно (могу ошибаться, поправьте если что).
ASIC — это таки ASIC. Вы можете добавить туда любую функциональность, в том числе ту, о которой говорите вы — но после этого извольте «испечь» новую микросхему. Обновление возможно только с заменой железки.
Можно делать что угодно, но всё упирается в ту же дилемму: без замены «железа» это всё работать не будет, а если «железо» всё равно менять, то неясно чем все эти схемы лучше простого IPv6 без извращений.Bormoglotx
13.01.2016 16:36ASIC — это таки ASIC. Вы можете добавить туда любую функциональность, в том числе ту, о которой говорите вы — но после этого извольте «испечь» новую микросхему. Обновление возможно только с заменой железки.
Вообще то я и имел ввиду, что это возможно, но как вы и сказали, потребует замены железа (в данном случае линейных плат маршрутизаторов)
Но при использовании MPLS транзитные маршрутизаторы на смотрят внутрь IP заголовка, а производят коммутацию на основании меток согласно LFIB. В самом худшем случае можно использовать стек меток, подобно технологии 6PE.khim
13.01.2016 16:52Но при использовании MPLS транзитные маршрутизаторы на смотрят внутрь IP заголовка, а производят коммутацию на основании меток согласно LFIB. В самом худшем случае можно использовать стек меток, подобно технологии 6PE.
Как это всё использовать в уже существующей сети?
Очередная байка про сову, мышей и ёжиков, блин… Кто, как и почему будет это чудо внедрять? Какую задачу они будут решать? Почему они не смогут просто использовать IPv6?Bormoglotx
13.01.2016 17:11Подождите, я вас заставляю использовать эту технологию??? Давайте проанализируем текст статьи и посмотрим, о чем же я писал: есть технология, которая имеет право на жизнь, и я ее и описал.
Я предложил возможное решение озвученной вами проблемы — как оставить производительность транзитных узлов на прежнем уровне.
Но вам и это не понравилось. Вы начинаете о каких то мышах и ежиках говорить и задаете вопросы, ответы на которые очевидны. Но я на них отвечу:
Кто, как и почему будет это чудо внедрять? — когда мне скажут внедрить эту технологию, я это сделаю, хотя понимаю что это «гремучий костыль».
Какую задачу они будут решать? — решать задачу отсутствия белых IPv4 адресов в период, когда IP адрес уже в приделали к пылесосу и кофеварке.
Почему они не смогут просто использовать IPv6? — есть несколько подходов для миграции с IPv4 на IPv6. Самый оптимальный (на мой взгляд) — dual stack с плавным уменьшением сервисов на IPv4. Но для этого нужны люди, которые будут заниматься внедрением данной технологии, пока остальные будут устранять эксплуатировать IPv4 сервисы и устранять аварии. То есть снова все упирается в деньги. А сразу взять и перейти на IPv6 — нереально. Поэтому мы и будем дальше топтаться на IPv4, придумывая все более изощренные технологии, не дающие умереть этому протоколу.khim
13.01.2016 17:49+1В этой ветке мы, собственно, обсуждаем не саму технологию, а не, софт надо менять только в 4-5 местах, причём 2 из этих мест сами хосты.
К самой технологии вопросов нет: как оно работает — понятно, непонятно "зачем?". Какой в ней смысл. Когда от неё может быть больше толку, чем от какого-нибудь Teredo?
А сразу взять и перейти на IPv6 — нереально. Поэтому мы и будем дальше топтаться на IPv4, придумывая все более изощренные технологии, не дающие умереть этому протоколу.
Проблема в том, что то, что вы тут придумали — это не IPv4. Адреса 8-байтовые, то есть клиенты IPv4 работать не будут.
Это новый протокол, который абсолютно бессмысленен в малых сетях (там хватает «серых» IPv4 адресов, никакой нехватки адресов у них нет) и столь же бессмысленен в больших («большие» существующие роутеры использовать нельзя, нужно закупать новое оборудование). А какое у него есть преимущество над IPv6 — мне неясно.
Вся статья, собственно, очердная иллюстрация базовой правды о сетях номер три. Вернее её первого предложения. Но мне кажется, что кто-то забыл про второе и третье…Bormoglotx
13.01.2016 17:54-1Правда в том, что до триумфа ipv6 мы с вами наверное не доживем, а так и будем изобретать такие технологии.
Bormoglotx
13.01.2016 18:14-1К тому-же вынужден канстатировать, что вы не поняли принцип работы данной технологии. Прочитайте еще раз, или обратитесь к rfc.
Спасибо за внимание
Ovsiannikov
13.01.2016 03:55по идее, оно легче чем NAT, т.к. не надо таблицу соединений в памяти держать.
khim
13.01.2016 04:19+1«В теории — теория и практика одинаковы, однако на практике это не так».
То есть где-нибудь «в далёкой-далёкой галактике» EnIP и будет легче, чем NAT. Но не в нашей вселенной. По одной простой причине: таблицы для NAT'а в роутерах уже есть и работа с ними происходит аппаратно. CPU в этом процессе не участвует. А вот обработка пакетов с IP опциями — происходит программно. Всё. Приехали. Закрыли тему.

ValdikSS
13.01.2016 02:27Ну все, наконец-то можно будет достойно отвечать «NAT — не Firewall», ссылаясь на этот стандарт.
Ovsiannikov
13.01.2016 03:32итак, нам в типичном случае нужно обновить:
1. сетевой стек на компьютере пользователя. (чтоб писал все эти опции)
2. прошивку на домашнем рутере (чтоб не поломал всё нафиг)
3. BRAS у провайдера интернет (чтоб заголовки програмно переписывал)
4. Балансировщик в датацентре у провайдера услуг (чтоб тоже заголовки програмно переписывал)
5. сетевой стек на сервере у провайдера услуг (чтоб писал все эти опции в ответный пакет)
…
вопрос автору статьи: я уверен есть реализация драфта в опенсорсе,
у вас хватило терпения настроить стенд со всеми участниками процесса и проверить как оно работает с разными программами?
не совсем понятно как будут работать существующие приложения, которые писались под 4х октетный адрес.
кто, какая программная сущность будет дописывать опции и знать как поля заполнять?Bormoglotx
13.01.2016 13:28+1Стенд собирали (на виртуалках), браузер работал, поднятый сайт открывался (правда не было DNS сервера и открывали сайт по EnIP).
Как будут работать приложения, заточенные под IPv4 особо протестировать не получилось. Но точно работают SSH, SSL, HTTP. Точно не работает IPSec.
Опции в IPv4 используются и сейчас, поэтому проблем с добавлением опций не должно быть. Правда придется обновлять софт (в Linux уже есть поддержка данной технологии, версию ядра не помню к сожалению).khim
13.01.2016 16:31в Linux уже есть поддержка данной технологии, версию ядра не помню к сожалению
Эк вы красиво завернули. Patch для древнего ядра, валяющийся и не обновляющийся год — это не называется «в Linux уже есть поддержка данной технологии», уж извините.
Типичный пример: функциональность IFS (Inherited File System) из старого древнего дистрибутива Stackware 1994 года выпуска была-таки добавлена в ядро. В 2014м году! Разумеется это был уже совсем-совсем другой код. Переписанный раз… много.
А сколько всего просто осталось никому не нужными patch'ами валяющимися на просторах archive.org?
Нет в Linux никакого EnIP и, скорее всего, никогда не будет, не нужно обманывать.Bormoglotx
13.01.2016 16:47Не буду переубеждать, но и не стоит говорить, что человек врет, если не владеете полной информацией.
Вот ссылка https://github.com/EnIP/enhancedip/tree/master/v1.1 скачивайте и пробуйте.
Если вы имели ввиду, что официально нет, то наверно вы правы — официальной версии я не видел.khim
13.01.2016 17:33+1Я имею в виду, что в Linux — даже в самой последней версии 4.4, вышедшей несколько дней назад.
То, что у кого где-то под столом есть какие-то патчи, не обновляющиеся уже год не делает технологию доступной в Linux'е!Bormoglotx
13.01.2016 17:41+1Да, согласен софт не обновлялся, но хотя бы он есть. Отвечая на ваш комментарий, я имел ввиду, что пока что попробовать эту технологию можно в Линукс, если есть желание, про остальные системы не знаю. Давайте не будем спорить по пустякам, как говорится, давайте жить дружно:)
khim
13.01.2016 17:53+1С такой поправкой — ответ принимается. Да, попробовать можно.
Просто такое ощущение что кто-то студенческую лабораторную работу с соотвествующей кафедры пытается представить как-то что-то реальное и серьёзное. Что, мягко говоря, вызывает недоумение.
Как студенческая работа — так очень даже неплохо, но рассматривать это всерьёз??? Странно это, как-то. Если бы эти все изыски были предствалены в стиле как я провёл лето, то у меня вопросов не было бы.

Imple
13.01.2016 07:24есть еще префикс 224.0.0.0/4, но он до сих пор не распределен
Ничего не путаете? Может быть имеется в виду 240/4?
Bormoglotx
13.01.2016 07:45Спасибо внимательном читателю. Естественно 240 — автозамена видимо была при наборе, а я не заметил. Поправил
mwizard
И все это добро сломает 10.0.0.0/8?