
 Так сложилось, что основным языком для работы с микроконтроллерами является C. Многие крупные проекты написаны именно на нем. Но жизнь не стоит на месте. Современные средства разработки уже давно позволяют использовать C++ при разработке ПО для встраиваемых систем. Однако такой подход до сих пор встречается достаточно редко. Не так давно я попробовал использовать С++ при работе над очередным проектом. Об этом опыте я и расскажу в данной статье.
Так сложилось, что основным языком для работы с микроконтроллерами является C. Многие крупные проекты написаны именно на нем. Но жизнь не стоит на месте. Современные средства разработки уже давно позволяют использовать C++ при разработке ПО для встраиваемых систем. Однако такой подход до сих пор встречается достаточно редко. Не так давно я попробовал использовать С++ при работе над очередным проектом. Об этом опыте я и расскажу в данной статье.Вступление
Большая часть моей работы с микроконтроллерами связана именно с C. Сначала это было требованиями заказчика, а потом стало просто привычкой. При этом, когда дело касалось приложений для Windows, то там использовался сначала C++, ну а потом вообще C#.
Вопросов по поводу C или C++ не возникало долгое время. Даже выход очередной версии MDK от Keil с поддержкой C++ для ARM особо меня не смутил. Если посмотреть демо-проекты Keil, то там все написано на C. При этом C++ вынесен в отдельную папку наравне с Blinky-проектом. CMSIS и LPCOpen тоже написан на C. И если “все” используют C, значит есть какие-то причины.
Но многое поменял .Net Micro Framework. Если кто не знает, то это реализация .Net позволяющая писать приложения для микроконтроллеров на C# в Visual Studio. Более подробно с ним можно познакомиться в этих статьях.
Так вот, .Net Micro Framework написан c использованием C++. Впечатлившись этим, я решил попробовать написать очередной проект на С++. Сразу скажу, что однозначных доводов в пользу С++ я в итоге так и не нашел, но некоторые интересные и полезные моменты в таком подходе есть.
В чем разница между проектами на С и С++?
Одно из самых главных отличий между C и C++ — то, что второй является объектно-ориентированным языком. Всем известные инкапсуляция, полиморфизм и наследование являются тут привычным делом. С — это процедурный язык. Тут есть только функции и процедуры, а для логической группировки кода используются модули (пара .h + .c). Но если присмотреться к тому, как C используется в микроконтроллерах, то можно увидеть обычный объектно-ориентированный подход.
Посмотрим на код работы со светодиодами из примера Keil для MCB1000 (Keil_v5\ARM\Boards\Keil\MCB1000\MCB11C14\CAN_Demo):
LED.h:
#ifndef __LED_H
#define __LED_H
/* LED Definitions */
#define LED_NUM 8 /* Number of user LEDs */
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:
#include "LPC11xx.h" /* LPC11xx definitions */
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
/*----------------------------------------------------------------------------
initialize LED Pins
*----------------------------------------------------------------------------*/
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6); /* enable clock for GPIO */
/* configure GPIO as output */
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
/*----------------------------------------------------------------------------
Function that turns on requested LED
*----------------------------------------------------------------------------*/
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
/*----------------------------------------------------------------------------
Function that turns off requested LED
*----------------------------------------------------------------------------*/
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
/*----------------------------------------------------------------------------
Output value to LEDs
*----------------------------------------------------------------------------*/
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Если присмотреться, то можно привести аналогию с ООП. LED представляет собой объект, имеющий одну публичную константу, конструктор, 3 публичных метода и одно приватное поле:
class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED(); //Аналог LED_init
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Несмотря не то, что код написан на C, в нем используется парадигма объектного программирования. Файл .C представляет собой объект, позволяющий инкапсулировать внутри механизмы реализации публичных методов, описанных в .h файле. Вот только наследования тут нет, поэтому и полиморфизма тоже.
Большая часть кода в проектах, которые я встречал, написана в таком же стиле. И если используется ООП подход, то почему бы не использовать язык, полноценно его поддерживающий? При этом при переходе на C++ по большому счету будет меняться только синтаксис, но не принципы разработки.
Рассмотрим другой пример. Пусть у нас есть устройство, которое использует датчик температуры, подключенный по I2C. Но вот вышла новая ревизия устройства и этот же датчик теперь подключен к SPI. Что делать? Нужно же поддерживать и первую и вторую ревизию устройства, значит, код должен гибко учитывать эти изменения. В С для этого можно использовать предопределения #define, чтобы не писать два почти одинаковых файла. Например
#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
и так далее.
В С++ можно эту задачу решить немного элегантнее. Сделать интерфейс
class ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
и сделать 2 реализации
class Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
А затем использовать ту или иную реализацию в зависимости от ревизии:
class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Вроде бы разница не очень большая между кодом на C и C++. Объектно-ориентированный вариант выглядит даже более громоздким. Но он позволяет сделать более гибкое решение.
При использовании С можно выделить два основных решения:
- Использовать #define, как показано выше. Данный вариант не очень хорош тем, что “размывает” ответственность модуля. Получается, что он отвечает за несколько ревизий проекта. Когда таких файлов становится много, поддерживать их становится довольно сложно.
- Сделать 2 модуля, так же как при C++. Тут “размытия” не происходит, но усложняется использование этих модулей. Так как у них нет единого интерфейса, то использование каждого метода из этой пары нужно обрамлять в #ifdef. Это ухудшает читаемость, а следовательно, и поддерживаемость кода. И чем выше по абстракции нужно будет поднимать место разделения, тем более громоздким получится код. При этом нужно еще продумывать названия функций для каждого модуля, чтобы они не пересекались, что тоже чревато ухудшением читаемости кода.
Использование полиморфизма дает более красивый результат. С одной стороны, каждый класс решает четкую атомарную задачу, с другой стороны, код не замусорен и легко читается.
“Разветвление” кода на ревизии все равно придется делать и в первом и во втором случае, но использование полиморфизма позволяет легче переносить место разветвления между слоями программы, при этом не загромождать код лишними #ifdef.
Использование полиморфизма позволяет легко сделать еще более интересное решение.
Допустим вышла новая ревизия, в которой стоят оба датчика температуры.
Тот же код при минимальных изменениях позволяет выбирать вам SPI и I2C реализацию в реальном времени, просто используя метод Init(&temperature).
Пример очень упрощенный, но в реальном проекте я использовал тот же подход, чтобы реализовать один и тот же протокол по верх двух разных физических интерфейсов передачи данных. Это позволило легко вынести выбор интерфейса в настройки устройства.
Однако при всем выше сказанном, разница между использованием С и С++ остается не очень большой. Преимущества С++, связанные с ООП не столь очевидны и являются из разряда “на любителя”. Но у использования С++ в микроконтроллерах есть и достаточно серьезные проблемы.
Чем опасно использование C++?
Вторым важным отличием C от C++ является использование памяти. C язык по большей части статический. Все функции и процедуры имеют фиксированные адреса, а работа с кучей ведется только по необходимости. С++ — язык более динамический. Обычно его использование подразумевает активную работу с выделением и освобождением памяти. Этим то C++ и опасен. В микроконтроллерах очень мало ресурсов, поэтому важен контроль над ними. Бесконтрольное использование оперативной памяти чревато порчей хранящихся там данных и такими ”чудесами” в работе программы, что мало не покажется никому. Многие разработчики сталкивались с такими проблемами.
Если внимательнее посмотреть на примеры выше, то можно отметить, что классы не имеют конструкторов и декструкторов. Это сделано потому, что они никогда не создаются динамически.
При использовании динамической памяти (и при использовании new) всегда вызывается функция malloc, которая выделяет необходимое количество байт из кучи (heap). Даже если вы все продумаете (хотя это очень сложно) и будете контролировать использование памяти, вы можете столкнуться с проблемой ее фрагментации.
Кучу можно представить в виде массива. Для примера выделим под нее 20 байт:

При каждом выделении памяти происходит просмотр всей памяти (слева направо или справа налево — это не так важно) на предмет наличия заданного количества незанятых байт. Причем эти байты должны все располагаться рядом:
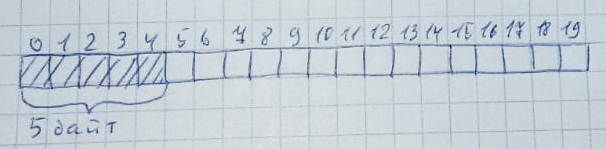
Когда память больше не нужна, она возвращается в исходное состояние:
Очень легко этом может возникнуть ситуация, когда есть достаточное количество свободных байт, но они не располагаются подряд. Пусть будет выделено 10 зон по 2 байта каждая:
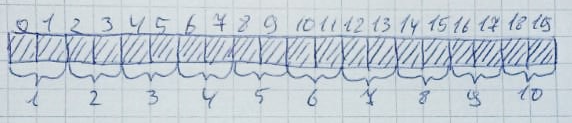
Затем будут освобождены 2,4,6,8,10 зоны:
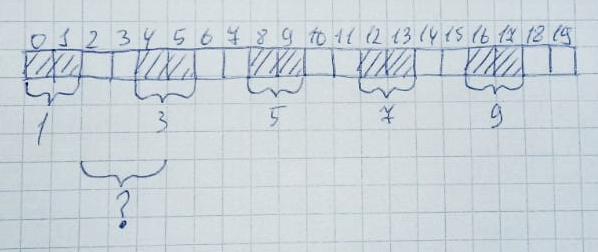
Формально остается свободной половина всей кучи (10 байт). Однако выделить область памяти размером 3 байта все равно не получится, так как в массиве нет 3-х свободных подряд ячеек. Это и называется фрагментацией памяти.
И бороться с этим на системах без виртуализации памяти достаточно сложно. Особенно в больших проектах.
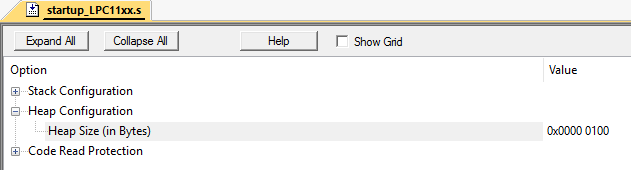
Такую ситуацию можно легко сэмулировать. Я делал это в Keil mVision на микроконтроллере LPC11C24.
Зададим размер кучи в 256 байт:
Пусть у нас есть 2 класса:
#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Как видно, класс bar будет занимать больше памяти чем foo.
В кучу помещается 14 экземпляров класса bar и экземпляр класса foo уже не влезает:
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Если создать всего 7 экземпляров bar, то foo будет тоже нормально создан:
int main(void)
{
foo *f;
bar *b[14];
//b[0] = new bar();
b[1] = new bar();
//b[2] = new bar();
b[3] = new bar();
//b[4] = new bar();
b[5] = new bar();
//b[6] = new bar();
b[7] = new bar();
//b[8] = new bar();
b[9] = new bar();
//b[10] = new bar();
b[11] = new bar();
//b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Однако если сначала создать 14 экземпляров bar, затем удалить 0,2,4,6,8,10 и 12 экземпляры, то для foo выделить память уже не получится из-за фрагментации кучи:
int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Получается, что полноценно С++ использовать нельзя, и это существенный минус. С архитектурной точки зрения С++ хотя и превосходит С, но незначительно. В итоге существенной выгоды переход на С++ не несет (хотя и больших отрицательных моментов тоже нет). Таким образом, из-за небольшой разницы, выбор языка будет оставаться просто личным предпочтением разработчика.
Но для себя я нашел один существенный положительный момент в использовании С++. Дело в том, что при правильном подходе C++ код для микроконтроллеров можно достаточно легко покрыть юнит-тестами в Visual Studio.
Большой плюс C++ — возможность использования Visual Studio.
Лично для меня тема тестирования кода для микроконтроллеров всегда была достаточно сложной. Естественно, код проверялся всевозможными способами, но создание полноценной автоматической системы тестирования всегда требовало огромных затрат, так как нужно было собирать аппаратный стенд и писать для него специальную прошивку. Особенно если речь идет о распределенной IoT системе, состоящей из сотен устройств.
Когда я начал писать проект на С++, мне сразу захотелось попробовать засунуть код в Visual Studio а Keil mVision использовать только для отладки. Во-первых, в Visual Studio очень мощный и удобный редактор кода, во-вторых, в Keil mVision совсем не удобная интеграция с системами контроля версий, а в Visual Studio это все отработано до автоматизма. В-третьих, у меня была надежда, что удастся хотя бы часть кода покрыть юнит-тестами, которые тоже хорошо поддерживаются в Visual Studio. Ну и в-четвертых, это появление Resharper C++ — расширения Visual Studio для работы с С++ кодом, благодаря которому можно заранее избежать многих потенциальных ошибок и следить за стилистикой кода.
Создание проекта в Visual Studio и подключение его к системе контроля версий не вызвало никаких проблем. А вот с юнит-тестами пришлось повозиться.
Классы, абстрагированные от аппаратной части (например, парсеры протокола), достаточно легко поддались тестированию. Но хотелось большего! В своих проектах для работы с периферией я использую заголовочные файлы от Keil. Например, для LPC11C24 это LPC11xx.h. В этих файлах описаны все необходимые регистры в соответствии со стандартом CMSIS. Непосредственно определение конкретного регистра сделано через #define:
#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Оказалось, что если правильно переопределить регистры и сделать пару заглушек, то код, использующий периферию, вполне может быть скомпилирован в VisualStudio. Мало того, если сделать статический класс и указывать его поля как адреса регистров, то получится полноценный эмулятор микроконтроллера, позволяющий полноценно тестировать даже работу с периферией:
#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
И дальше делать так:
#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
Таким образом можно скомпилировать и оттестировать весь код проекта для микроконтроллеров в VisualStudio с минимальными изменениями.
В процессе разработки проекта на С++ я написал более 300 тестов, покрывающих как чисто аппаратные аспекты, так и абстрагированный от аппаратуры код. При этом заранее найдены примерно 20 достаточно серьезных ошибок, которые, из-за размеров проекта, было бы не просто обнаружить без автоматического тестирования.
Выводы
Использовать или не использовать С++ при работе с микроконтроллерами — достаточно сложный вопрос. Выше я показал, что, с одной стороны, архитектурные преимущества от полноценного ООП не так уж и велики, а невозможность полноценной работы с кучей является достаточно большой проблемой. Учитывая эти аспекты, большой разницы между С и С++ для работы с микроконтроллерами нет, выбор между ними вполне может быть обоснован личными предпочтениями разработчика.
Однако мне удалось найти большой положительный момент использования С++ в работе с Visaul Studio. Это позволяет существенно повысить надежность разработки за счет полноценной работы с системами контроля версий, использования полноценных юнит-тестов (в том числе и тестов работы с периферией) и других преимуществ Visual Studio.
Надеюсь, мой опыт будет полезен и кому-то поможет повысить эффективность своей работы.
Комментарии (55)

Atakua
22.02.2016 12:49+5То, что в коде на Си вполне можно использовать ООП — это довольно старый, но почему-то малоизвестный широкой публике факт. Поглядите на ядро Linux — написано на Си, при этом имеет развитые иерархии классов драйверов, абстрактные классы для файловых систем и т.п., есть в наличии аналог dynamic_cast (более опасный)...
С++ не привнёс в идеи ООП существенного. Да и исполнение принципов ООП в нём, надо сказать, слабенькое — что угодно кастуется к чему угодно, вся память на ладони.
Что, по-моему, действительно является шагами вперёд по сравнению с Си, — это следующие три вещи.
- Пространства имён (namespace). В Си приходится придумывать всякие префиксы к функциям, структурам, типам и т.п. В мелких проектах это несложно, но с ростом масштабов это становится тормозом.
- Механизм исключений (exceptions). В embedded-проектах его, как правило, не задействуют (как раз из-за требований по памяти, времени и стеку); этому помогает его необязательность в C++. Но в традиционном программировании возможность разделить обработку ошибок от главной ветки кода очень ускоряет работу.
- Шаблоны (templates). Замена костыльным макросам Си. При отладке разбирать макросы — сущее мучение. С шаблонами при отладке чуть полегче. Хотя любой, кто хоть раз пытался разобраться в выводе ошибки компилятора для шаблонизированного кода (пресловутый template vomit) со мной не согласится :-)

Amomum
22.02.2016 13:37+1Мы в одном проекте попробовали писать объектно на С, но очень быстро устали. Слишком многословно получается. Да и какой смысл писать руками то, что компилятор может делать за тебя?
Да, С++ более запутанный, но все его фишки никто не заставляет применять. Можно спокойно жить в "С с классами".
А уж на GObject'ы мне лично смотреть страшно.
- Пространства имён (namespace). В Си приходится придумывать всякие префиксы к функциям, структурам, типам и т.п. В мелких проектах это несложно, но с ростом масштабов это становится тормозом.
ProLimit
22.02.2016 13:39+1Уже давно использую "C++ с ограничениями" для микроконтроллеров, так как читабельнсть и структурирование кода в разы выше, чем на С. Если проект большой и сложный, то C++ здорово выручает. При этом практически не отличается от C в плане потребления ресурсов. Вот ограничения:
- не используется динамическое выделение памяти и куча вообще. Все место отдано под стэк. Как правило, переменные состояния нужны на все время функционирования программы и прекрасно живут в статике. Если нужно выполнить операцию с большим расходом памяти, это делается объявлением переменных и объектов класса внутри функции. Такой подход автоматически избавляет от необходимости следить за фрагментацией кучи.
- не используются конструкторы и деструкторы, кроме пустых конструкторов прямой инициализации:
SomeClass(int v1, int v2): member1(v1), member2(v2) {}
- они компилятором правильно разворачиваются без доп. кода.
- Если предполагается создать всего один экземпляр класса, то все функции и члены класса — статические. Результат компиляции ничем не отличается от С, но выигрывает синтаксисом.
- Использование интерфейсов и мультинаследования бывает очень удобно, но приводит к расходу памяти (все нужные объекты всех реализаций создаются статически, и потом просто выбирается необходимая реализация). Впрочем, тут можно очень аккуратно использовать malloc — как правило, выбор реализаций интерфейса зависит от настроек и создается один раз при старте системы, удалять его не нужно и дефрагментация не страшна.
Amomum
22.02.2016 14:55+2не используются конструкторы и деструкторы, кроме пустых конструкторов прямой инициализации:
SomeClass(int v1, int v2): member1(v1), member2(v2) {}
А почему? Ведь можно сделать, например, критическую секцию через RAII, из которой невозможно забыть выйти.ProLimit
22.02.2016 17:27Причина в ограниченных ресурсах памяти FLASH и производительности. Конструкторы тянут достаточно много сервисного кода за собой, зато при их отсутсвии код сравним с генерируемым из С.

Falstaff
22.02.2016 18:04Не могли бы вы уточнить, что имеется в виду под сервисным кодом? В самом общем случае конструкторы — это всего лишь функции, которые вызываются при создании объекта. Когда я в своё время рассматривал, какие из возможностей C++ могут подложить свинью во встраиваемом ПО, конструкторы на особом подозрении у меня не были. Понятно, что так получаются неявные вызовы в коде, но это уже другая история.
ProLimit
22.02.2016 22:05Да я особо не разбирался, просто достаточно упомянуть оператор 'new' и размер бинарника увеличивается на 40к. Это сам механизм конструкторов и выделения памяти, даже если сами фукнции пустые.
Falstaff
23.02.2016 03:57+1Думаю, стоит копнуть поглубже — возможно, рост бинарника вызван другими причинами, и вы себя напрасно ограничиваете. Конструкторы ведь никак не зависят от того, динамически создаются объекты или статически — и тут и там код конструкторов один и тот же. Скорее всего, когда вы упоминаете в проекте new, то однократно тянется фрагмент рантайма, связанный с динамическим выделением памяти или, например, с исключениями (если разрешены в проекте).
Если вы используете GCC и Newlib, там есть грабли с резким ростом размера кода при использовании абстрактных классов, и ещё одни грабли — если включены и используются исключения (а оператор new бросает исключение при нехватке памяти). Плюс, конечно, убедиться в том, что компилятору и компоновщику дана отмашка удалять неиспользуемый код.ProLimit
23.02.2016 12:40В общем то new мне не нужен в проекте, поэтому я глубже не копал. Но думаю, вытянуть только часть функционала C++ связанного с конструкторами, и не тянуть исключения и прочее, будет достаточно сложно. Кстати, при создании объекта статически конструкторы не отрабатывают. Тоже нужно разибираться, почему.
Удаление неиспользуемых функций включено.Falstaff
23.02.2016 14:25+1Это, признаться, ужасно странно — с точки зрения языка что вы пишете "MyClass my_class;", что "MyClass* my_class = new MyClass;", должен вызваться один и тот же конструктор. Если для локальных переменных конструктор вызывается а для глобальных — нет, можно посмотреть, вызывает ли стартовый код
__libc_init_array()перед прыжком в main().
Если у вас GCC и исключения вам не нужны, можете их просто запретить (-fno-exceptions), компоновщик тогда не должен потянуть связанный с ними код. Если нужны, попробуйте определить собственную__gnu_cxx::__verbose_terminate_handler(), стандартная из Newlib чудовищно раздута, а всё что ей надо делать — реагировать на непойманное исключение. В нагрузку, если используете абстрактные базовые классы, сделайте своюextern "C" void __cxa_pure_virtual(), с ней та же история. Из стандартной библиотеки торчит довольно много ручек, которые можно покрутить и подёргать.
AlexPublic
23.02.2016 05:05+1Конструкторы к new не имеют никакого отношения. И естественно не увеличивают память и т.п. Это можно очень просто проверить, создав объект с конструктором в виде локальной переменной.
ProLimit
23.02.2016 12:34Да, но они и не рабатают как надо. Выше я написал, что компилятор из всего конструктора выполняет только инициализацию переменных, которые указаны до фигурных скобок. Само тело конструктора не выполняется.
AlexPublic
23.02.2016 15:19Если не работают, то это может означать только то баг компилятора. Кстати, о каком идёт речь?
У меня например всё без проблем работает.

Xop
23.02.2016 16:10+2Если переменные-объекты, для которых не вызываются конструкторы объявлены как глобальные или статические внутри классов или функций, и вы работаете с тулчейном arm-none-eabi-gcc, то вполне возможно вы используете ld-скрипт и startup-код, который не поддерживает вызов конструкторов глобальных переменных. Если вкратце — компилятор кладет список адресов конструкторов в секции .preinit_array и .init_array, поэтому чтобы оно заработало нужно:
1) добавить в ld-скрипт соответствующие секции
.init_array: {
. = ALIGN(4);
init_array_begin = .;
KEEP ((.init_array))
init_array_end = .;
} >rom
2) сделать доступными указатели на начало и конец секции в коде, например так:
typedef void (func_t)();
extern func_t init_array_begin;
extern func_t init_array_end;
3) в startup-коде (обычно это reset-handler) перед вызовом функции main но после обнуления секции .bss и загрузки секции .data добавить что-то вроде:
for( func_t f = &init_array_begin; f != &__init_array_end; ++f )
(f)();
Разумеется то же самое нужно сделать для секции .preinit_array, и если вы хотите, чтобы вызывались деструкторы, то и для .fini_array, только деструкторы вызывать после main. Это если вкратце. А если подробно, то вдумчиво читать документацию про то, как пишутся ld-скрипты, и изучать примеры, например в libopencm3 вся эта инициализация есть, исходники можно на гитхабе посмотреть.
Xop
23.02.2016 16:19+1Дико извиняюсь за предыдущий комментарий, забыл про тег source, а исправить это месиво не успел (
Если переменные-объекты, для которых не вызываются конструкторы объявлены как глобальные или статические внутри классов или функций, и вы работаете с тулчейном arm-none-eabi-gcc, то вполне возможно вы используете ld-скрипт и startup-код, который не поддерживает вызов конструкторов глобальных переменных. Если вкратце — компилятор кладет список адресов конструкторов в секции .preinit_array и .init_array, поэтому чтобы оно заработало нужно:
1) добавить в ld-скрипт соответствующие секции
.init_array: { . = ALIGN(4); __init_array_begin = .; KEEP ((.init_array)) __init_array_end = .; } >rom
2) сделать доступными указатели на начало и конец секции в коде, например так:
typedef void (func_t)(); extern func_t __init_array_begin; extern func_t __init_array_end;
3) в startup-коде (обычно это reset-handler) перед вызовом функции main но после обнуления секции .bss и загрузки секции .data добавить что-то вроде:
for( func_t * f = &__init_array_begin; f != &__init_array_end; ++f ) (*f)();
Разумеется то же самое нужно сделать для секции .preinit_array, и если вы хотите, чтобы вызывались деструкторы, то и для .fini_array, только деструкторы вызывать после main. Это если вкратце. А если подробно, то вдумчиво читать документацию про то, как пишутся ld-скрипты, и изучать примеры, например в libopencm3 вся эта инициализация есть, исходники можно на гитхабе посмотреть.ProLimit
23.02.2016 18:49Спасибо за развернутое объяснение, попробую на практике. ld-скрипты это то что я пропустил из-за их сложности, остановился на первом рабочем примере из того, что удалось найти.
Xop
24.02.2016 11:37Не за что ) кстати, вот еще хороший материал по этой теме: http://electronix.ru/forum/index.php?showtopic=79902
- не используется динамическое выделение памяти и куча вообще. Все место отдано под стэк. Как правило, переменные состояния нужны на все время функционирования программы и прекрасно живут в статике. Если нужно выполнить операцию с большим расходом памяти, это делается объявлением переменных и объектов класса внутри функции. Такой подход автоматически избавляет от необходимости следить за фрагментацией кучи.
GarryC
22.02.2016 13:43+4Статья произвела двойственное впечатление — тема поднята интересная, но совершенно не раскрыта, вместо серьезного обсуждения автор начал объяснять нам механизм фрагментации памяти — тот, кто знал, пропустил, кто не знал — все равно не понял.
Позволю себе несколько дополнений.
Первое — конструкторы и деструкторы именно нужны (особенно конструкторы), независимо от присутствия динамических объектов, поскольку, на мой взгляд, наличие конструкторов есть одно из основных преимуществ в С+ перед С, поскольку не позволяет Вам забыть об инициализации используемого объекта (например, UARTа).
Второе — очень важна инкапсуляция, которая не позволит Вам обращаться к объекту несанкционированными способами (точнее, не позволит легко и непринужденно обращаться, как в С), что в сочетании с развитым аппаратом enum ставит дополнительную преграду ошибкам (у меня был пост на эту тему).
Третье — динамические объекты не так страшны, как Вам представляется, если принять должные меры безопасности — не применять их без надобности, аккуратно освобождать, перекрыть new под часто используемые классы, не использовать STL (без крайней надобности) и т.д.
Четвертое — (и наверное, одно из главных) все эти преимущества не стоят Вам ничего, современные компиляторы настолько умны, что код, порождаемый из весьма сложной иерархии классов, Вас удивит своей простотой и эффективностью, заявляю это со всей ответственностью.
Так что мой личный вывод — несомненно использовать, плюсы однозначно минусы перевешивают, в конце концов методику "на С++ как на С никто не запрещал", начните с нее а потом распробуете и потихоньку перейдете на полный С++.

farcaller
22.02.2016 13:54Real Time C++ — http://www.amazon.co.uk/dp/3642429157 вполне годная книга по С++ применимо ко встраиваемым системам.
olekl
22.02.2016 14:00mbed же на С++. И еще может быть критичным производительность. Для mbed актуально.
А конструкторы кстати вполне в данном случае оправданы и для статических классов. Что бы не забыть инициализацию вызвать и для инкапсуляции опять же.Indemsys
22.02.2016 17:37А что вы называете mbed?
На github проекта mbed я увидел несколько десятков проектов.
Где-то половина на С-и.


veydlin
22.02.2016 14:06А не могли бы вы подробней описать работу в связке Visaul Studio + Keil, было бы интересно почитать.
Ах да, вы не смотрели в сторону SW4STM32? Она тоже поддерживает C++
AlexandrSurkov
22.02.2016 18:02Я планирую написать отдельную статью про то как использую Visual Studio для тестирования кода. А по поводу IDE — это все на любителя. Мне больше нравится Keil mVision, хотя я пробовал и Eclipse и IAR.
eastig
22.02.2016 16:55Keil использует ARM Compiler 5, который поддерживет только подмножество C++11. Вряд ли ситуация улучшится в будущем.
Если нужен C++11 и C++14, то ARM рекомендует использовать ARM Compiler 6, который основан на LLVM/Clang последних версий.
Вот например статья: How C++11/14 can improve readability without affecting performance
Главные проблемы с C++ — это размер исполняемого кода и С++ библиотека, слишком много чего тянет за собой C++. В ARM об этом знают и работают над этим. Правда все зависит от того, насколько C++ востребован у кастомеров.AlexPublic
23.02.2016 05:10Используем обычный gcc. Код на C++14 (с полиморфными лямбдами и т.п.) спокойно компилируется и работает на МК с флешем в 16КБ и оперативкой в 4КБ. Не пойму откуда у людей сложности.
eastig
23.02.2016 14:17А как вы избавились от зависимостей от C++ runtime библиотек?
AlexPublic
23.02.2016 15:21Ни от чего не избавлялись. А зачем? Всё равно же линкуется только непосредственно используемое...
А вот исключения, rtti и threadsafe действительно отключены в настройках компилятора.

5oclock
22.02.2016 18:03+2Может быть помешал недописанный код первого примера на c++, но я так и не понял:
зачем все навороты с виртуальными функциями («подготовка к полиморфизму»), если дальше всё опять сводится к ifdef'ам?AlexandrSurkov
22.02.2016 18:09Вы можете выбрать точку разветвления и поднять ее вплоть до main без особых усилий. Когда у вас маленький проект — это на так важно. А когда огромный — построение связей между частями программы начинает играть осень большую роль.

Costic
22.02.2016 18:031) Не могли бы вы поподробнее рассказать (может быть в виде статьи) «о распределенной IoT системе, состоящей из сотен устройств»? Потому что управление освещением и/или гаражными воротами уже не интересно.
2) Visual Studio отличная среда разработки. Но как я понял, вы используете LPC11C24, для которого изготовитель предлагает и даже настойчиво рекомендует Eclipse. Прокомментируете ваш выбор?
3) Сейчас очень много микроконтроллеров на ядре Cortex-M. Почему вы выбрали (или ваш заказчик) LPC11C24, а не STM или Milandr 1986, особенно в свете модного импортозамещения?AlexandrSurkov
22.02.2016 18:211) Смотрите тут.
2) Я не работаю напрямую с LPC11C24 в Visual Studio. Только тестирую там код. Отлаживаюсь я в Keil mVision — мне он нравится больше всего. Я пробовал и другие IDE — не пошли :) На мой взгляд выбор IDE — это как выбирать машину, кому что нравится.
3) LPC11C24 — это CortexM0. Его взяли потому что он во первых маленький (занимает мало места на плате) а во вторых имеет встроенный CAN. На выбор микроконтроллера импортозамещение никак не влияет. Их еще долго будут импортозамещать :)
AlexPublic
22.02.2016 20:32+1Забавно. Статья про то, что надо использовать C++ на микроконтроллерах (в принципе правильный тезис) от того, кто похоже по сути не умеет программировать на современном C++ (делает это в стиле Java/C#). Показать в качестве аналога сишного ifdef динамический полиморфизм — это же просто жесть. И это при том, что в C++ имеется в наличие один из лучших среди всех языков механизмом статического полиморфизма. Конечно на фоне такого можно рассуждать о перерасходе памяти в C++ в сравнение с C. Хотя на практике при нормальном использование как раз C++ код может быть оптимальнее за счёт использования множества инструментов времени компиляции (включая метапрограммирование).
AlexandrSurkov
22.02.2016 21:13А что вы понимаете под оптимальностью?
AlexPublic
23.02.2016 05:00В данном случае подразумевалась оптимальность кода (минимизация расхода памяти и количества тиков процессора). С этим у C и C++ в большинстве случаев абсолютно одинаково (хорошо, в отличие от того же C#). Ещё бывает оптимальность работы программиста, которая зависит качества абстракций языка. С этим у C всё плохо, а у C++ и C# хорошо. В этом и есть весь смысл C++ — наличие высокоуровневых абстракции без малейшей потери эффективности кода. Ценой же за это является сложность языках.
Xop
23.02.2016 08:32+1Подозреваю, что человек имеет в виду использование шаблонов и метапрограммирования для чего-то такого: easyelectronics.ru/rabota-s-portami-vvoda-vyvoda-mikrokontrollerov-na-si.html
ProLimit
23.02.2016 18:56А разве шалоны не ведут к увеличению объема кода? К примеру у меня есть функция на 10 экранов, которая оперирует матрицами любого размера. Для возможности обращения вида a[i][j] нужно заранее определеить во всех переменных размерность матрицы, и это красиво делается при помощи шаблона. Но когда я вызову эту функцию для матрицы 3X3 и 4x4, разве компилятор не сделает 2 коппии кода фунции? Если задача экономить FLASH память, то очевидно шаблоны не лучшее решение.
Xop
23.02.2016 19:44Это уже вопрос разумности использования, шаблоны — это просто один из инструментов. В вашем примере с матрицами и большой функцией вероятно да, шаблоны могут привести к раздуванию кода. С другой стороны, в статье ссылку на которую я кинул приводятся примеры использования шаблонов для GPIO вместе с ассемблерными листингами того, что получается на выходе, и получается очень компактно.
AlexPublic
23.02.2016 21:41К примеру у меня есть функция на 10 экранов, которая оперирует матрицами любого размера.
Так размер матриц задаётся на стадии компиляции или на стадии исполнения. Если на стадии компиляции, то где он задаётся? Если на стадии исполнения, то как передаётся в функцию?
Для возможности обращения вида a[i][j] нужно заранее определеить во всех переменных размерность матрицы, и это красиво делается при помощи шаблона.
А это вообще непонятно. В принципе в C++ для возможности обращений вида a[i][j] просто переопределяют соответствующий оператор. Причём тут размеры или вообще шаблоны неясно. )

Sun-ami
22.02.2016 20:56Динамическое выделение памяти можно также использовать для создания объектов при инициализации в соответствии с конфигурацией — в этом случае память не нужно освобождать, и фрагментация не возникает. Также использую автоматические временные объекты в стеке. Использую модифицированные шаблоны STL, не использующие динамическую память. Использую свой HAL в виде шаблонов для работы с периферией STM32. Иногда приходится использовать временные объекты, созданные в динамической памяти — в рамках одной функции.

Mirn
22.02.2016 21:25«Использую модифицированные шаблоны STL, не использующие динамическую память. Использую свой HAL в виде шаблонов для работы с периферией STM32. „
эти наработки публично доступны? можно глянуть?Sun-ami
23.02.2016 00:22Нет, эти наработки принадлежат компании. Но подобный HAL для AVR и STM32 есть в публичном доступе, и подобные модификации STL — по-моему тоже.
golf2109
23.02.2016 18:56также очень интерестно взглянуть на модифицированный HAL и его возможность связи с CubeMX

den_po
24.02.2016 11:50Могу посоветовать взглянуть на эти библиотеки:
github.com/andysworkshop/stm32plus
github.com/JorgeAparicio/libstm32pp
github.com/RickKimball/fabooh
github.com/pfalcon/PeripheralTemplateLibrary
Особенно впечатляюще выглядит первая, хоть она и является (являлась) обёрткой над STM32 Standard Peripherals Library

BelerafonL
23.02.2016 00:30+1Еще надо упомянуть про некоторую проблему с "красивым" встраиванием обработчиков прерываний в проект на С++. Для микроконтроллера прерывание — это переход на выполнение кода с определенного адреса, сохранив перед этим контекст. Что нативно делается вызовом Си-функции. На Си++ метод класса — это не просто функция. При вызове метода класса метод должен знать, от какого именно он класса, т.е. помимо адреса функции должен передаваться адрес класса (вернее адрес+смещение метода, или как там это внутри у компиляторов делается). Поэтому обработчик прерывания нельзя вот так просто повесить на метод какого-то класса, скажем, метод драйвера SPI ЦАПа. Придется либо пользоваться "нестандартными" расширениями компилятора, который после использования специальных директив позволит так делать для статических классов, либо делать Сишную функцию обработки прерывания, засовывать внутрь файла с реализацией класса, прописывать области видимости, extern'ы и прочий уменьшающий красивость код.
После этого появляется проблема с переносимостью кода с компилятора на компилятор, с микроконтроллера на микроконтроллер. Если Си "поддерживают все", то с реализацией тонкостей Си++ могут быть проблемы и нюансы.
Есть вопросы с подсветкой кода. Не все среды разработки под МК уверенно парсят Си++ код и позволяют на ходу подсвечивать ошибки, подсказывать члены класса, переходить по объявлению переменной и т.п. На Си обычно работает у всех без вопросов.
Однако есть определенные плюсы в применении Си++ компилятора даже ведя проект "на Си", без использования классов. Например, Си может позволить вызвать функцию и передать в неё не то число аргументов, может позволить присвоить указатели на функции опять же не глядя на кол-во аргументов, может не напомнить о возвращаемом функцией значении и т.п. По опыту работы с микроконтроллерами Texas Intruments ядра C28 Компилятор Си++ оказался более интересен в плане нахождения ошибок и нестыковок в коде.AlexPublic
23.02.2016 05:18Поэтому обработчик прерывания нельзя вот так просто повесить на метод какого-то класса
Хы, ну это же совсем древняя проблема, с кучей давно известных решений. Ведь в том же программирование скажем под Windows тоже нельзя передать функциональный объект в качестве оконной функции и т.п. Однако никто не страдает от этого при написание GUI библиотек под Windows. )))
Есть вопросы с подсветкой кода. Не все среды разработки под МК уверенно парсят Си++ код и позволяют на ходу подсвечивать ошибки, подсказывать члены класса, переходить по объявлению переменной и т.п. На Си обычно работает у всех без вопросов.
Только главный нюанс в том, что все эти среды разработки под МК являются жутким убожеством по уровню возможностей редактирования кода (навигация, автодополнения, рефакторинг и т.п.) в сравнение с ведущими IDE. Не пойму даже как можно пользоваться этими блокнотами-переростками.BelerafonL
23.02.2016 10:34с кучей давно известных решений
Решений куча, не спорю, но красота кода по сравнению с Си чуть портится.
Не пойму даже как можно пользоваться этими блокнотами-переростками.
Стараюсь, конечно, пользоваться эклипс для повседневной работы, но иногда нужно бывает что-то перенести в старый проект на другой IDE, бывает, что заказчики, покупающие софт в исходных кодах, говорят "а мы хотим вот в этой IDE, у нас она лицензионная и все привыкли". Ну это всё лирика, конечно.
QuaziKing
25.02.2016 11:22Я использую C++ в МК возможности только для изоляции кода. Т.е. классы у меня есть, но все методы и переменные у него static. По сути это C но с изоляцией. Все остальное я делать не хочу, т.к. память это весьма критичный ресурс и я должен его контролировать очень жестко. + к тому, ООП это не просто классы, это виртуальные методы. А это уже не только память под VMT (хотя и статическая) но и быстродействие. Причем не контролируемое (точнее менее контролируемое). Поэтому я просто не даю себе возможности потерять контроль над процессом исполнения программы.
З.Ы. Все сказанное исключительно ИМХО
thatsme
А Вы пробовали в C++ вообще не использовать явное выделение памяти в куче? Понятно, что использование контейнеров и умных указателей будет кушать больше памяти. Просто интересно, насколько это вообще прогодно для микроконтроллеров. Хотя кажется, что там где есть 512МБ ОЗУ, уже можно практически не беспокоутся…
Amomum
Я, собственно, так и делаю. Динамическое выделение памяти не нужно. Практически всегда можно оценить верхний предел используемой памяти и выделить его статически или на стеке. На крайняк есть alloca. Ну, или можно свой менеджер памяти написать, без фрагментации.
Да, почти все стандартные контейнеры нельзя использовать — ну и ладно. Зато есть шаблоны, RAII, интерфейсы, std::fill вместо memset'a и std::copy вместо memcpy.
Если бы Кейл полноценно поддерживал С+11 (а он уже почти, только компиляция на лету все еще ругается), то были бы еще весьма удобные вещи вроде std::array, auto и std::function. Но многое можно и самому написать в упрощенном виде или в Бусте взять.
Из минусов:
В основном это минусы Кейла как среды разработки, а не С++.
Atakua
Соглашусь с Вами — для большого класса задач (даже вне области embedded) сущности определены на начало работы системы, и их динамическое порождение/уничтожение излишне.
В нашем проекте все места, где допустимо использование динамической памяти, уже давно известны. Как правило, парные malloc/free при этом содержатся в пределах одной функции. Любой код-ревью, содержащий malloc, вызывает тяжёлый взгляд и долгое обсуждение. А если к нему не идёт free...
AlexandrSurkov
Я его и не выделяю. У меня все классы либо статические сами по себе либо статически объявлены в стеке. Для микроконтроллера и 2 МБ ОЗУ это уже роскошь на мой взгляд. Хотя все зависит от задачи.