
Какие-то приложения на большие таблицы не рассчитаны и «зависают» при попытке открыть на просмотр/редактирование таблицу с миллионами записей. Иные отказываются от использования грида с вертикальной полосой прокрутки в пользу постраничного отображения или предлагают пользователю лишь иллюзию, что при помощи полосы прокрутки можно быстро перейти к нужной (хотя бы к самой последней) записи.
Мы расскажем об одном из возможных методов реализации табличного элемента управления, обладающего свойствами Log(N)-быстрого 1) первоначального отображения 2) прокрутки на всём диапазоне записей 3) перехода к записи с заданным уникальным ключом. Всё это — при двух ограничениях: 1) записи могут быть отсортированы только по индексированному набору полей и 2) collation-правила базы данных должны быть известны алгоритму.
Изложенные в статье принципы были реализованы автором в проекте с его участием на языке Java.
Основной принцип
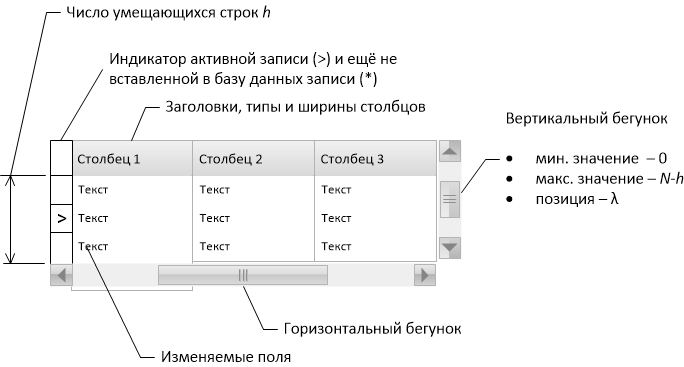
Двумя ключевыми функциональными возможностями табличного элемента управления (грида) являются
- прокрутка — отображение записей, соответствующих положению бегунка полосы прокрутки,
- переход к записи, заданной по комбинации ключевых полей.
Сперва рассмотрим простейшие подходы к их реализации и покажем, почему они непригодны в случае большого числа записей.
Наиболее прямолинейный подход заключается в считывании в оперативную память всех записей (или хотя бы их первичных ключей), после чего прокрутка осуществляется выборкой сегмента массива, а позиционирование — поиском записи в массиве. Но при большом количестве записей, во-первых, слишком много времени занимает процесс изначальной загрузки массива и, как следствие, задерживается отображение грида на экране, а во-вторых, оперативную память начинают занимать данные таблицы, что снижает общее быстродействие.
Другой подход заключается в «перекладывании» вычислений на СУБД: выборку записей для отображения в окне прокрутки осуществлять при помощи конструкций вида select… limit… offset ..., позиционирование — сводить к select… и count(*). Однако и offset, и count(*) связаны с перебором записей внутри сервера, они имеют в общем случае скорость выполнения O(N), и потому неэффективны при большом числе записей. Частый их вызов приводит к перегрузке сервера БД.
Итак, нам нужно реализовать систему, которая не требовала бы полной закачки данных в память и при этом не перегружала бы сервер неэффективно выполняющимися запросами. Для этого поймём, какие запросы являются эффективными, а какие — нет.
При условии, что по полю k построен индекс, быстрыми являются следующие запросы (они используют index lookup и выполняются за время Log(N)):
- Запрос A. Найти первую и последнюю запись в наборе данныx:
select ... order by k [desc] limit 1 - Запрос B. Найти h первых записей с ключом, большим или равным данному значению K:
select ... order by k where k >= K limit h
Не являются быстрыми следующие запросы:
- Запрос C Подсчитать общее количество записей в наборе данных:
select count(*) ... - Запрос D. Подсчитать число записей, предшествующих записи с ключом, большим или равным данному:
select count(*) ... where key < K
where k1 >= K1 and (k1 > K1 or (k2 >= K_2 and (k2 > K2 or ...)))«Угадывание» зависимости первичного ключа от номера записи
На время представим себе, что первичный ключ нашей таблицы имеет всего одно целочисленное поле (далее мы снимем это ограничение).
Пусть каждому положению бегунка полосы прокрутки соответствует целое число от 0 до
(Заметим, что запрос D, вызываемый с параметром k, как раз возвращает значение
Естественно, функция
Пусть мы выполнили запрос
select min(k), max(k), count(*) from fooмонотонно растёт,
- при увеличении
на единицу,
увеличивается на единицу или не увеличивается, поэтому график функции
, кроме точки
, целиком лежит в параллелограмме
,
,
,
,
- общее число возможных функций
записей по
значениям ключа (позиции первой и последней записи фиксированы), т. е.
- число возможных функций
Таким образом, если каждый из возможных вариантов считать равновероятным, то вероятность того, что для заданного значения
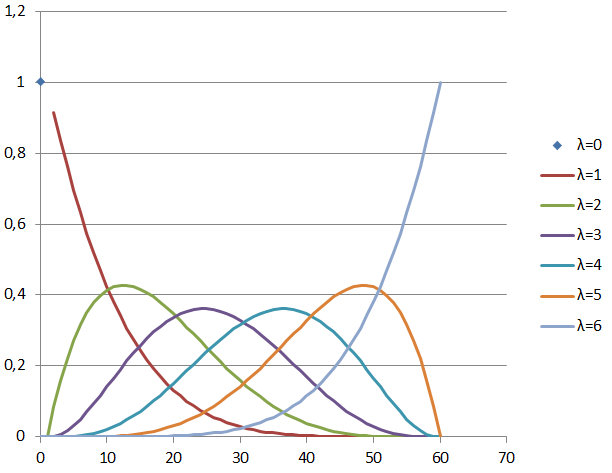
Свойства гипергеометрического распределения хорошо известны. В случае
Дисперсия значения
Расчёт значений по вышеприведённым формулам для
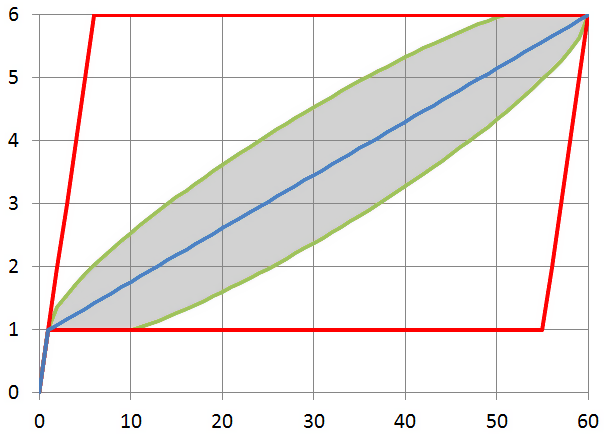
Итак, ломаная, построенная между точками
Если теперь для какого-то
Если ключевых полей несколько и типы данных не INT
На практике дело не ограничивается единственным целочисленным полем для сортировки набора данных. Во-первых, тип данных может быть другим: строка, дата и прочее. Во-вторых, сортируемых полей может быть несколько. Это затруднение устраняется, если мы умеем вычислять
- функцию-нумератор
, переводящую набор значений полей произвольных типов в натуральное число,
- обратную ей функцию
, переводящую натуральное число обратно в набор значений полей,
.
Функция-нумератор должна обладать тем свойством, что если набор
Говоря языком математики, биекция
Для представления значений
При наличии обратимой функции-нумератора
- прокрутка грида сводится к вычислению значений ключевых полей
, где
первых записей, больших или равных
,
- позиционирование сводится к считыванию
.
Схема взаимодействия процедур
На этом этапе мы можем отвлечься от математики и разобраться собственно с алгоритмической частью. Общая схема взаимодействия процедур системы показана на рисунке ниже. Использована «приблизительная UML Activity» нотация, при этом сплошной стрелкой показана последовательность выполнения процедур, а пунктирной стрелкой — асинхронный вызов в отдельном потоке выполнения:
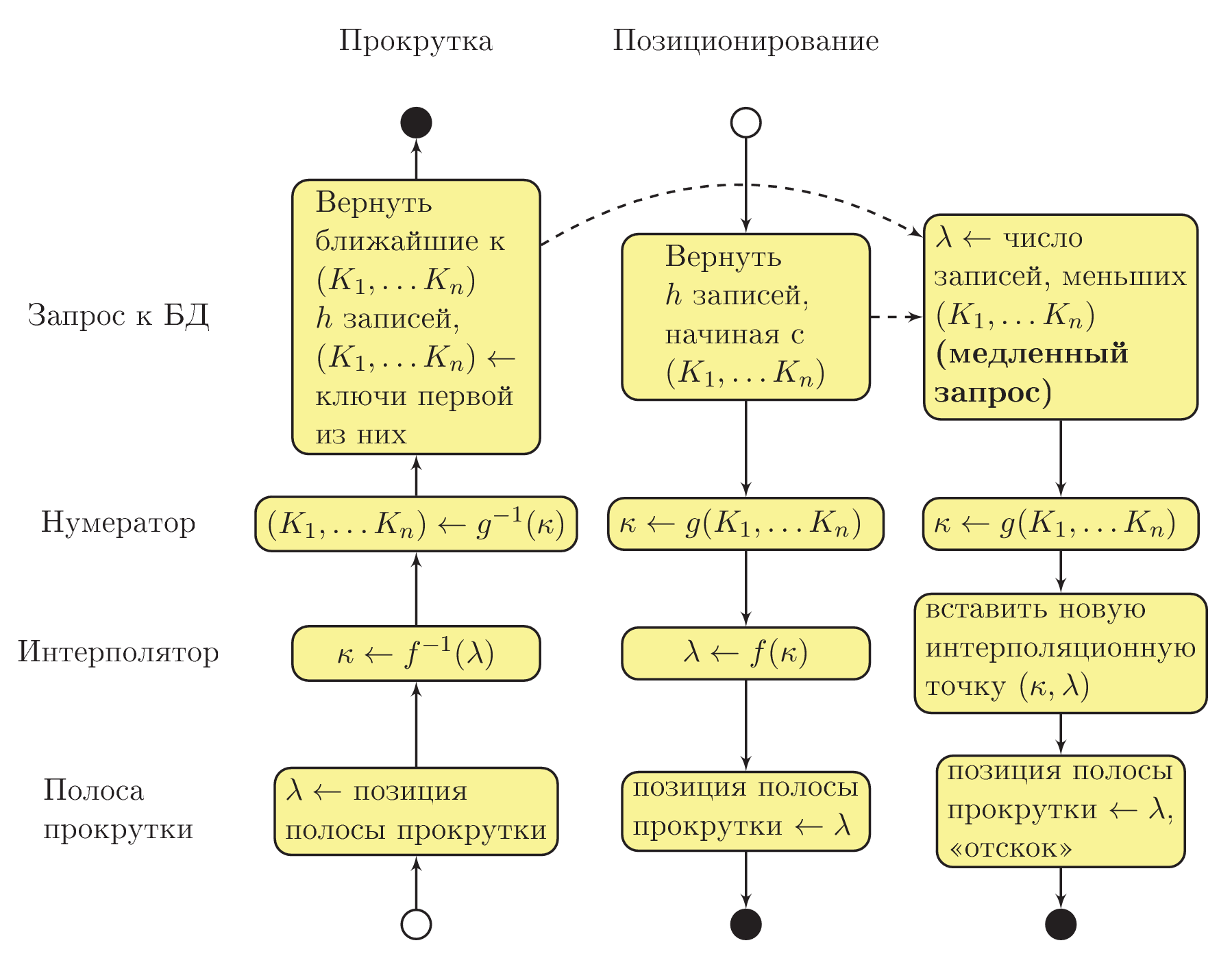
Допустим, что пользователь изменил положение бегунка вертикальной полосы прокрутки (см. в левый нижний угол диаграммы). Интерполятор вычисляет значение номера комбинации значений ключевых полей (
Здесь важно понимать, что на данном этапе в полях
Если пользователь отпустил полосу прокрутки и какое-то время не трогал её, асинхронно (в отдельном потоке выполнения) запускается запрос D, определяющий порядковый номер записи, а значит, и точное положение полосы прокрутки, которое соответствует тому, что отображено пользователю. Когда запрос будет завершён, на основе полученных данных будет пополнена интерполяционная таблица. Если к этому моменту пользователь не начал снова прокручивать таблицу, вертикальный бегунок «отскочит» на новое, уточнённое положение.
При переходе к записи последовательность вызовов процедур происходит в обратную сторону. Т. к. значения ключевых полей уже известны, для пользователя запросом B сразу извлекаются данные из базы. Нумератор вычисляет
Чем больше пользователь будет «бродить» по данным вертикальным бегунком, тем больше точек будет собираться в интерполяционной таблице и тем меньше будут «отскоки». Практика показывает, что достаточно всего 4-5 удачных точек в интерполяционной таблице, чтобы «отскоки» стали очень малы.
Экземпляр класса-интерполятора должен хранить в себе промежуточные точки монотонно растущей функции между множеством 32-битных целых чисел (номеров записей в таблице) и множеством объектов типа BigInteger (порядковых номеров комбинаций значений ключевых полей).
Сразу же после инициализации грида необходимо в отдельном потоке выполнения запросить общее количество записей в таблице, чтобы получить корректное значение
Интерполятор должен уметь за быстрое по количеству интерполяционных точек время вычислять значение как в одну, так и в другую сторону. Однако заметим, что чаще требуется вычислять значение порядкового номера комбинации по номеру записи: такие вычисления производятся много раз за секунду в процессе прокрутки грида пользователем. Поэтому за основу реализации модуля интерполятора удобно взять словарь на основе бинарного дерева, ключами которого являются номера записей, а значениями — порядковые номера комбинаций (класс TreeMap<Integer, BigInteger> в языке Java).
Ясно, что по заданному номеру
При пополнении словаря интерполяционными точками необходимо следить за тем, чтобы интерполируемая функция оставалась монотонной. Так как другие пользователи могут удалять и добавлять записи в просматриваемую таблицу, актуальность известных словарю интерполяционных точек может утратиться, а вновь добавляемая точка может нарушить монотонность. Поэтому метод добавления новой интерполяционной точки должен проверять, что «точке слева» от только что добавленной соответствует меньшее, а «точке справа» — большее значение. Если оказывается, что это не так, следует исходить из предположения, что последняя добавленная точка соответствует актуальному положению вещей, а некоторые из старых точек утратили свою актуальность. По отношению к вновь добавленной точке следует удалять все точки слева, содержащие большее значение, и все точки справа, содержащие меньшее значение. Процесс «срезания выбивающейся точки» показан на рисунке:
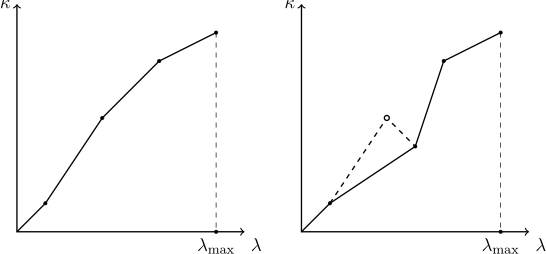
Также интерполятор должен содержать в себе механизм, в целях экономии памяти защищающий словарь от переполнения излишними точками, и отбрасывающий наименее существенные из них (как мы помним, не имеет смысла хранить все точки подряд — достаточно только через одну).
Заключение к первой части
Итак, мы разобрались, как в целом устроена наша система: основными её частями являются интерполятор и нумератор, а также полностью обсудили реализацию интерполятора. Чтобы завершить решение задачи, необходимо теперь реализовать нумератор — биекцию
Этому посвящена вторая часть статьи.
Ещё я готовлю научную публикацию, и вы можете также ознакомиться с препринтом научной версии этой статьи на arxiv.org.
Комментарии (21)

aionin
14.03.2016 12:27"Диссертабельно".
Много математики. Действительно, сегодня мало кто так глубоко задумывается над эффективностью зачастую готовых элементов интерфейса.
IvanPonomarev
14.03.2016 16:12Ну, диссертацию я давно уж защитил, поэтому никуда не спешу — важна суть) На очереди вторая часть: там будет про преобразование строковых значений в числа с учётом collation-правил.

Rupper
14.03.2016 14:18Я правильно понимаю, что вы еще неявно предполагаете, что выполнение запроса практически бесплатно? Имею ввиду что несколько раз выполнить запрос не отличается от выполнить запрос один раз и зачитать все данные.
IvanPonomarev
14.03.2016 17:53Уточните, что для вас значит "зачитать все данные". Вообще все данные из таблицы? Я об этом пишу в самом начале статьи. Подход "зачитать всё" годится лишь до тех пор, пока записей достаточно мало, чтобы это можно было сделать за малое время. В противном случае требуется слишком много времени при каждом открытии таблицы (хранить в памяти долго мы данные тоже не можем: таблицу ведь редактируют другие пользователи, надо всё время выдавать свежее состояние данных).
"Запрос B" действительно почти "бесплатен". И если записей очень много, то пользователь при одном сеансе "браузинга" таблицы в любом случае увидит лишь их малую часть (и запросить придётся лишь их малую часть).

scumware
15.03.2016 13:02Делал нечто подобное в реальном проекте (ушло в продакшен).
У меня первый запрос считал кол-во результирующих записей, при скроллинге ListView заполнялся пустыми строками, и через таймаут (в районе полусекунды) отдельный поток подтягивал данные.
Однако я не считаю хорошей идеей показывать много записей на экране: пользователю это не нужно. Ему нужно знать примерное кол-во записей результирующей выборки, а так же возможность пролистать вниз (до первого элемента), в середину (посмотреть набор записей из середины выборки), и в начало выборки. Вот эти кейсы и надо реализовывать.IvanPonomarev
15.03.2016 15:06через таймаут (в районе полусекунды) отдельный поток подтягивал данные.
Вы применяли явный запрос к СУБД вида "выдать данные, начиная с N-й записи" или интерполяцию?scumware
15.03.2016 19:47Выдать данные начиная с N-й записи, лимитированной L'ным кол-вом строк. При этом стандартного функционала виндового ScrollBar'а мне было достаточно, и высчитывать самостоятельно индекс начала выборки мне не приходилось.

Holms
15.03.2016 20:39Когда была такая проблема решил с использованием ODBC курсора, для любого запроса он может двигаться вперед/назад по записям. Как такое сделать через ADO.NET так и не нашел.
Если у вас получиться сделать что-то подобное которое можно будет использовать для HTML/JS таблиц (либо через WebSocket, либо через AJAX запросы), то я готов даже купить лицензию за такое.scumware
15.03.2016 21:03Самостоятельно реализовать курсор. В частном случае это не очень сложно, а в общем эта задача не имеет приемлемого решения.
К тому же если данные приходят, например, из хранимки, то ODBC'шный курсор ничем не поможет: если это серверный курсор, то вы сожрёте всю память на сервере, а если клиентский, то на клиенте (но перед этим вы сожрёте всю всю ширину сетевого канала).
IvanPonomarev
16.03.2016 14:42Мы всё это это делаем в рамках проекта разработки своей OpenSource платформы (https://share.curs.ru/wiki). В конце марта должен появиться билд с гридом для веб-интерфейса. Но там всё сильно завязано на серверную часть: есть у нас и реализованные нами курсоры. Поэтому как-то отделить в компоненту вряд ли получится)
Holms
16.03.2016 02:32мне в принципе все равно как реализовать, текущая версия это десктопная программа которая работает без проблем с ODBC курсором.
У нас много таблиц у которых виртуальный скролл, без страниц, пользователь может просто нажать Page Down или Arrow Down и прокрутить все 10 миллионов записей если надо. Запросы очень сложные и полагаться на первичные ключ никак не получится.
Теперь пришло время все это показывать в Вебе, вот и думаем как имитировать то-же поведение таблиц.IvanPonomarev
16.03.2016 14:46Хм, хм, у вас "очень сложные запросы", и при этом они быстро возвращают 10 млн. записей? Позвольте усомниться: тут должны быть или запросы не очень сложные, или работают они не быстро, или записей не 10 млн. :-)) В предложенном мною методе довольно жёсткое ограничение: сортироваться можно только по индексированному набору полей. Иначе на миллионах записей возникает тормоз. Поэтому функциональности "сортировка столбца грида по щелчку на заголовок" при таком подходе нет и не будет… только выбор из списка заранее предложенных сортировок
scumware
17.03.2016 02:16Поэтому функциональности «сортировка столбца грида по щелчку на заголовок» при таком подходе нет и не будет… только выбор из списка заранее предложенных сортировок
Странное решение.
Вы вполне можете сортировать при щелчке по заголовку, но не по всем полям. Я, кстати, именно так и сделал.IvanPonomarev
17.03.2016 23:00Окэй, допустим, у таблицы есть два составных индекса: по полям A, B, C и по полям A, D, E. Пользователь щёлкнул по столбцу A. Как будем сортировать?
scumware
18.03.2016 05:01Никак: просто не меняем порядок сортировки при щелчке по заголовкам полей, для которых сортировка не разрешена явным образом.
Кстати, пользователи плохо воспринимают сложные сортировки. Даже начинающие программисты, до этого не сталкивавшиеся с SQL, с трудом понимают что значит order by A, B, C — они просто не понимают: мы тут по A сортируем, по B, или по C?
И, кстати, не все знаю что такое составной индекс, и зачем он нужен. Пользователи вашей библиотеки могут даже не догадываться об их существовании.
auine
По пойму вы слишком преувеличиваете проблему пытаясь обосновать свою работу :) Никто не показывает таблицу с миллионами записей, банальный лимит и пагинация, то ли на основе страниц, то ли на бесконечном скроле, и проблема решена.
И кстате ваш же подход давно упакован в не один велосипед.
IvanPonomarev
Не говорите "никто", всех вы знать не можете :-) Меня лично вдохновил классический интерфейс Microsoft Navision версии до 2009, который прекрасно справлялся с этой задачей по-видимому похожими методами. Мы создаём платформу для бизнес-решений, а бизнес-программисту надо дать простой универсальный инструмент, отвечающий на запрос "В этом месте формы я хочу грид для таблицы. В таблице может быть 5 записей, а может — 5 миллионов, ничего не хочу знать, меня волнуют бизнес-процессы, а не техническая сторона".
На новизну идеи с интерполяцией я также не претендую. Однако мне пока что не удалось разыскать в интернете работу, которая бы увязывала интерполяцию "ключ-номер записи" с гипергеометрическим распределением и тем самым давала бы точную оценку среднеквадратичной погрешности, так что в этой части, возможно, есть и новизна.
AndreyDmitriev
Делал примерно такое лет десять назад (на эзотерическом LabVIEW). Задача стояла именно такая — отображать таблицу с сотнями тысяч записей с возможностью скроллинга. "Прямая" загрузка таблицы в многоколонный листбокс приводила к диким тормозам и бешеному расходу памяти. Вместо это собственный нативный скролл у таблицы был выключен, к ней был бесшовно приставлен собственный скролл бар, при перемещении которого делалась выборка из базы и показывались лишь "видимые" строки. Пришлось немного повозиться с "балансировкой" нагрузки, если пользователь дёргал скролл туда-сюда, чтобы не перегружать базу запросами (часть изменённых значений незаметно для пользователя пропускались, если следовали слишком часто). Кроме того, добавили "упреждающее" чтение, на тот случай, если пользователь "примерно" выставляет скролл, думает некоторое время, а затем "доводит" его до нужного значения, щёлкая по крайним стрелочкам, в промежутки ну или нажимая клавиши на клавиатуре — тут ему в таблицу выгоняются "кешированные" значения, полученные во время "простоя" без запросов к базе. Ну и с динамическим изменением размера формы пришлось чуть повозиться (когда пользователь разворачивает приложение на весь экран — в таблице больше записей помещается, ну и скролл надо синхронно с таблицей ресайзить и позиционировать). На всё про всё недели полторы потратил, пока оно не заработало "гладко". В интерполяцию особо не упирался — если пользователь перемещал скролл, скажем, в позицию 357650, то из базы это значение и выбиралось. Понятно, что небольшое смещение скролл-бара, скажем на несколько пикселей, легко приводит к скроллингу нескольких тысяч записей. С другой стороны в моём случае пользователь редко когда пользовался скроллбаром для вот такой "сплошной" навигации — как правило он сначала фильтрует базу по какому-либо полю (при этом в выборку попадает от силы несколько сот записей), и лишь затем пользуется скролл баром, чтобы найти конкретную запись.
На современном этапе развития средств разработки я б первым делом проверил, нет ли такой функциональности "из коробки".
IvanPonomarev
Означает ли это, что у вас первичный ключ состоял только из одного числового поля?
AndreyDmitriev
Да, именно так. Впрочем я выше неточно выразился — при перемещении скроллбара в позицию N я устанавливаю курсор в рекордсете в эту самую позицию и начинаю получать через fetch данные, заполняя видимую часть таблицы. Если пользователь хочет отфильтровать базу по какому-то праметру, то выполняется SELECT * FROM bla bla WHERE bla bla, затем я опрашиваю recordset — он мне отдаёт количество записей в фильтрованной выдаче, на основе этого количества я пересчитываю скроллбар (ну чтобы движок по высоте соответствовал количеству записей и инкремент был правильный), дальше ставлю курсор на запись в соответствии с новым положением скроллбара, если его юзер подёргал, ну и fetch рекордсета начиная с новой позиции. Это не самый оптимальный способ, но для моей задачи он оказался более чем достаточен.
IvanPonomarev
Я понял. Да, на самом деле некоторое загрубление допустимо, тут зависит от конкретной задачи, конечно.
У нас ключ может быть составным и включать в себя в том числе и строки (о чём поведу речь во второй части статьи)