
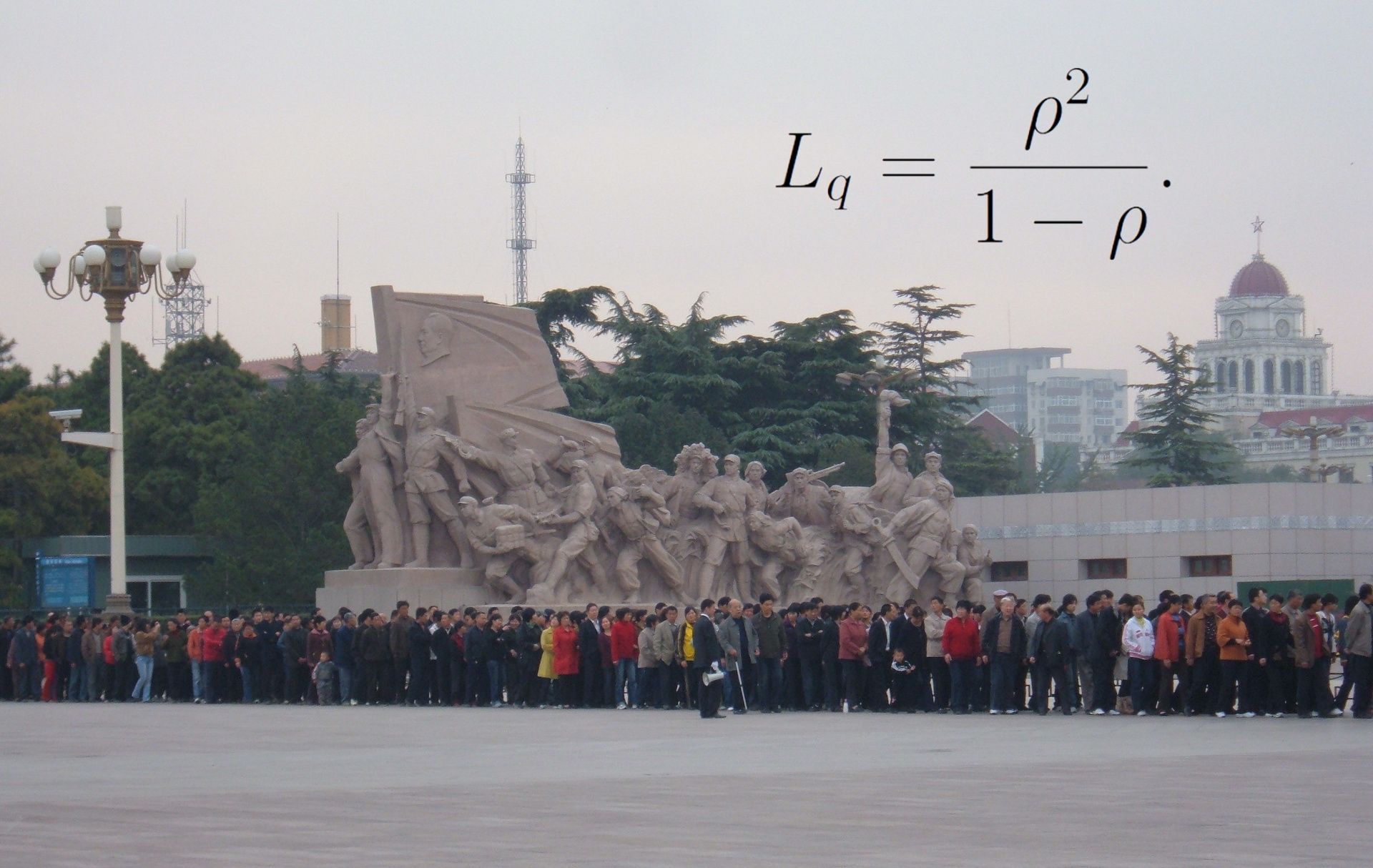
В проекте, над которым я сейчас работаю, применяется распределённая система обработки данных: сначала несколько десятков машин одновременно производят некоторые сообщения, затем эти сообщения отправляются в очередь, из очереди три потока извлекают сообщения и после финальной обработки выкладывают данные в базу Redis. При этом имеется требование: от «зарождения» события в машине, производящей сообщение, до выкладывания обработанных данных в базу должно проходить не более четырёх секунд в 90% случаев.
В какой-то момент стало очевидно, что мы это требование не выполняем, несмотря на затрачиваемые усилия. Несколько произведённых измерений и маленький экскурс в теорию очередей привели меня к выводам, которые я бы хотел донести до себя самого несколько месяцев назад, когда проект только начинался. Отправить письмо в прошлое я не могу, но могу написать заметку, которая, возможно, избавит от неприятностей тех, кто только задумывается над тем, чтобы применять очереди в собственной системе.
Я начал с того, что измерил время, которое сообщение проводит на разных стадиях обработки, и получил примерно такой результат (в секундах):
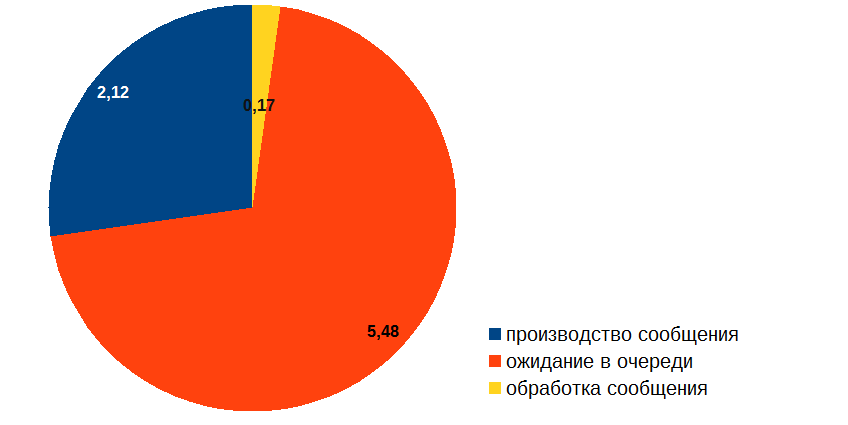
Таким образом, невзирая на то, что обработка сообщения занимает довольно мало времени, больше всего сообщение простаивает в очереди. Как такое может быть? И главное: как с этим бороться? Ведь если бы картинка выше была результатом профайлинга обычного кода, то всё было бы очевидно: надо оптимизировать «красную» процедуру. Но вся беда в том, что в нашем случае в «красной» зоне ничего не происходит, сообщение просто ждёт в очереди! Ясно, что оптимизировать надо обработку сообщения («жёлтую» часть диаграммы), но возникают вопросы: каким образом эта оптимизация может повлиять на длину очереди и где гарантии, что мы вообще сможем добиться желаемого результата?
Я помнил, что вероятностными оценками времени ожидания в очереди занимается теория очередей (подраздел исследования операций). В своё время в университете, впрочем, мы это не проходили, поэтому на некоторое время мне предстояло погрузиться в Википедию, PlanetMath и онлайн-лекции, откуда на меня как из рога изобилия посыпались сведения о нотации Кендалла, законе Литтла, формулах Эрланга, и т. д., и т. п.
Аналитические результаты теории очередей изобилуют довольно серьёзной математикой, основная часть этих результатов была получена в XX веке. Изучать всё это — занятие хотя и увлекательное, но довольно долгое и кропотливое. Не могу сказать, что я смог хоть сколько-нибудь глубоко туда погрузиться.
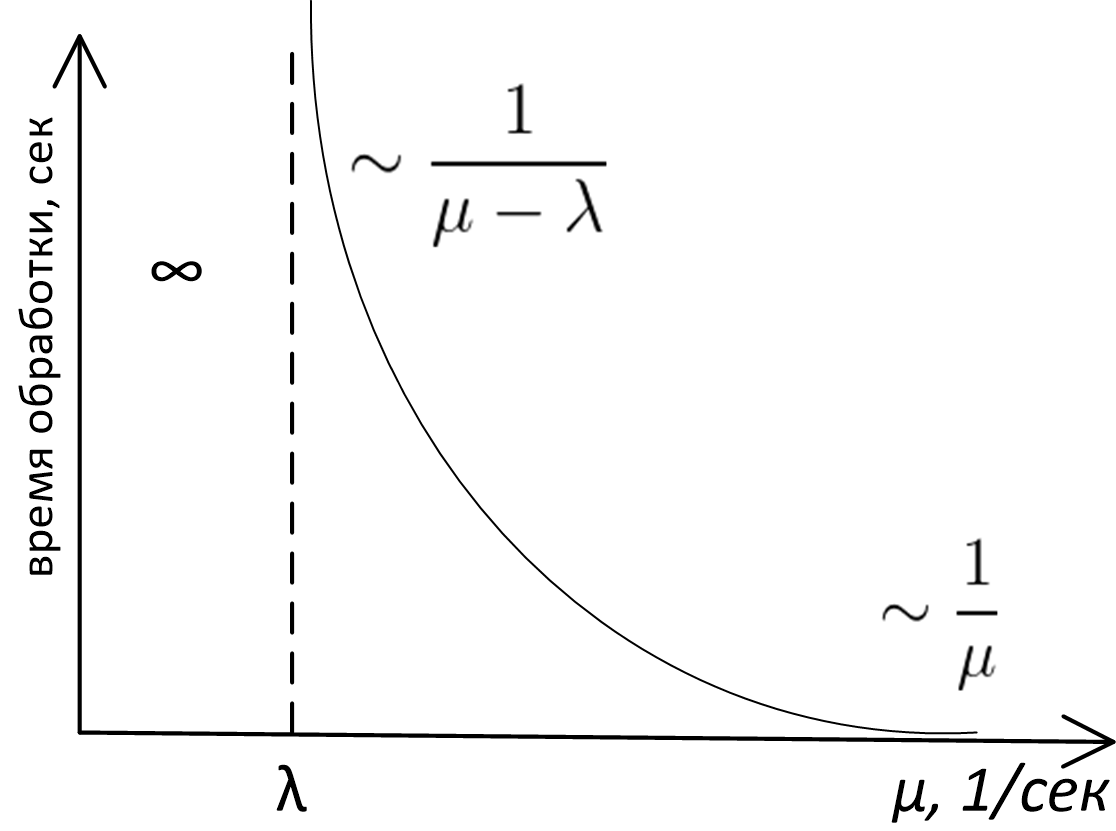
И тем не менее, пробежавшись всего лишь «по верхам» теории очередей, я обнаружил, что основные выводы, которые можно применить на практике в нашем случае, лежат на поверхности, требуют для своего обоснования только лишь здравый смысл и могут быть изображены на графике зависимости времени обработки в системе с очередью от пропускной способности сервера, вот он:
Здесь
- — пропускная способность сервера (в сообщениях за секунду)
- — средняя частота поступления запросов (в сообщениях за секунду)
- По оси ординат отложено среднее время обработки сообщения.
Точный аналитический вид этого графика является предметом изучения теории очередей, и для очередей M/M/1, M/D/1, M/D/c и т. д. (если не знаете, что это такое — см. нотация Кендалла) эта кривая описывается совершенно различными формулами. Тем не менее, какой бы моделью ни описывалась очередь, внешний вид и асимптотическое поведение этой функции будет одинаковым. Доказать это можно простыми рассуждениями, что мы и проделаем.
Во-первых, посмотрим на левую часть графика. Совершенно очевидно, что система не будет стабильной, если (пропускная способность) меньше (частоты поступления): сообщения на обработку приходят с большей частотой, чем мы их можем обработать, очередь неограниченно растёт, а у нас возникают серьёзные неприятности. В общем, случай — аварийный всегда.
Тот факт, что в правой части график асимптотически стремится к , тоже довольно прост и для своего доказательства глубокого анализа не требует. Если сервер работает очень быстро, то мы практически не ждём в очереди, и общее время, которое мы проводим в системе, равно времени, которое сервер затрачивает на обработку сообщения, а это как раз .
Не сразу очевидным может показаться лишь тот факт, что при приближении к с правой стороны время ожидания в очереди растёт до бесконечности. В самом деле: если , то это значит, что средняя скорость обработки сообщений равна средней скорости поступления сообщений, и интуитивно кажется, что при таком раскладе система должна справляться. Почему же график зависимости времени от производительности сервера в точке вылетает в бесконечность, а не ведёт себя как-нибудь так:

Но и этот факт можно установить, не прибегая к серьёзному математическому анализу! Для этого достаточно понять, что сервер, обрабатывая сообщения, может находиться в двух состояниях: 1) он занят работой 2) он простаивает, потому что обработал все задачи, а новые в очередь ещё не поступили.
Задания в очередь приходят неравномерно, где «погуще, где пореже»: количество событий в единицу времени является случайной величиной, описываемой так называемым распределением Пуассона. Если задания в какой-то интервал времени шли редко и сервер простаивал, то время, в течение которого он простаивал, он не может «сберечь» для того, чтобы использовать его для обработки будущих сообщений.
Поэтому за счёт периодов простоя сервера средняя скорость выхода событий из системы будет всегда меньше пиковой пропускной способности сервера.
В свою очередь, если средняя скорость выхода меньше средней скорости входа, то это и приводит к бесконечному удлинению среднего времени ожидания в очереди. Для очередей с пуассоновским распределением событий на входе и постоянным либо экспоненциальным временем обработки величина ожидания около точки насыщения пропорциональна
Выводы
Итак, разглядывая наш график, мы приходим к следующим выводам.
- Время обработки сообщения в системе с очередью есть функция пропускной способности сервера и средней частоты поступления сообщений , и даже проще: это функция отношения этих величин .
- Проектируя систему с очередью, нужно оценить среднюю частоту прибытия сообщений и заложить пропускную способность сервера .
- Всякая система с очередью в зависимости от соотношения и может находиться в одном из трёх режимов:
- Аварийный режим — . Очередь и время обработки в системе неограниченно растут.
- Режим, близкий к насыщению: , но ненамного. В этой ситуации небольшие изменения пропускной способности сервера очень сильно влияют на параметры производительности системы, как в ту, так и в другую сторону. Нужно оптимизировать сервер! При этом даже небольшая оптимизация может оказаться очень благотворной для всей системы. Оценки скоростей поступления сообщений и пропускной способности нашего сервиса показали, что наша система работала как раз около «точки насыщения».
- Режим «почти без ожидания в очереди»: . Общее время нахождения в системе примерно равно времени, которое сервер тратит на обработку. Необходимость оптимизации сервера определяется уже внешними факторами, такими как вклад подсистемы с очередью в общее время обработки.
Разобравшись с этими вопросами, я приступил к оптимизации обработчика событий. Вот какой расклад получился в итоге:
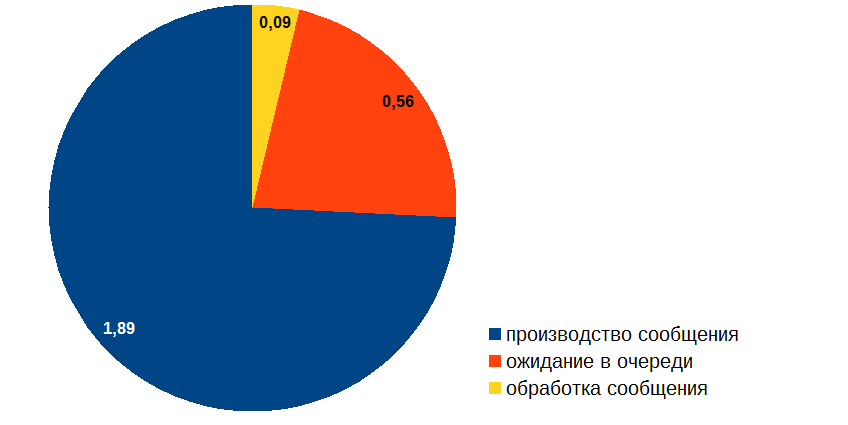
ОК, вот теперь можно и время производства сообщения подоптимизировать!
Также рекомендую прочесть: Принципы и приёмы обработки очередей.
Комментарии (36)

zenkz
07.07.2017 22:12+7Спасибо за статью, но очень много теории и очень мало практических советов.
Вопрос №1 — Что вы изменили в обработчике, чтобы он стал работать быстрее?
Вопрос №2 — Если у вас 3 потока обрабатывают сообщения и не справляются, то почему-бы не добавить ещё потоков? (Само-собой если не помогла оптимизация обработки)?
Другой вариант решения — подключать обработчики по мере наполения очереди. Т.е. приходит мало сообщений — работает 1 обработчик. Как только в очереди скопилось n-сообщений, включается ещё один поток и т.д. Как только очередь отчистилась, то потоки отключаются по-одному до достижения оптимальной загрузки. Недостаток этого решения — могут возникнуть блокировки на извлечении сообщений из очереди. Решение — очереди для каждого потока + балансировщик.
Отсюда приходим к более продвинутому решению: сообщения сначала попадают в очередь балансировщика, который контролирует количество запущенных потоков обработки и перенаправляет сообщения в их очереди. У каждого потока — своя очередь. При опустошении очереди и неполучении новых в течении определённого времени балансировщик отключает поток. При заполнении потоков существующих обработчиков балансировщик создаёт новый. Балансировщик в данной системе должен быть максимально легковесным, чтобы не добавлять задержки в обработку. В идеале он должен быть прозрачным для случая, когда задействована только одна очередь обработки.Ghool
07.07.2017 22:28+2Точно!
Как в магазинах: если вы ждёте в очереди больше 5 минут, лучше звоните солу"

16tomatotonns
08.07.2017 00:39+2В многопоточных штуках, остаётся привязка к количеству физических/виртуальных ядер среды. Если наплодить 100 000 000 потоков, то уже сами таски окажутся в очереди между ядрами процессора. Когда-то делал сервер логирования, который был должен пережёвывать 100-500к логирующих сообщений в секунду, с учётом того что буфер входящих UDP-сообщений всего 64кб на всё про всё. Вот там, правда, я непрерывно перегонял сообщения из буфера сокета в буфер языковой структуры, для дальнейшей обработки, и пытался скомпенсировать скорость обработки количеством потоков. Но при кол-ве потоков более «N ядер — 1» (один — на поток приёма-записи в очередь), скорость всей системы снижается, ибо издержки на обслуживание каждого потока.

zaitsevyan
08.07.2017 16:12+1Нам как-то в универе показывали интересный эксперимент: сделали небольшой обработчик данных-числодробилку. Распаралелили её на потоки и замеряли скорость выполнения всей задачи. Все шло как ожидалось: эффективность прии потоки=число ядер, при превышении начинается очеень маленькая просадка но не критично. Где-то при 128 потоках (при 8 ядрах) началась существенная просадка. А вот при 1000+ потоках, скорость снова начала повышаться и время было меньше чем при оптимальных 8 потоках. А все из-за того, что такое количество потоков «перегружало» системный планировщик операционной системы, а в целом, на нашу задачу начало отводится больше процессорного времени, чем при 8 потоках :) (Но, результат не совсем стабильный + сама система начинает тормозить, так как реже выполняются системные процесы + зависит от железа/кешей.) Ну и вообще, из этого всего был еще один итог: в современных ОС и железе, время на переключения контекста намного меньше, чем когда об этом писали книжки :)
evocatus
09.07.2017 20:38+1Если что, в Linux можно гораздо эффективнее получать данные из сетевого сокета засчёт кольцевого буфера в ядре, который затем mmap'ится в user space.
Читать https://www.kernel.org/doc/Documentation/networking/packet_mmap.txt

IvanPonomarev
08.07.2017 02:07+1Вопрос №1: За счёт кэширования срезал ненужные обращения к БД (там не только Redis, но и реляционка у нас и было что подоптимизировать).
Вопрос №2: Даа, всё это можно, но там потоки начнут лочить друг у друга запись в БД и их увеличение не приводит к увеличению пропускной способности сервиса. В своё время решили остановиться на трёх, хотя эксперименты с увеличением обработчиков ещё можно было бы провести. Идея с «балансировщиком» хороша лишь до некоторой степени: вы про закон Амдала и его обощение — Universal Scalability Law слышали? Распараллеливание обработчиков нельзя делать бесконечно: начиная с какого-то момента оно становится бесполезным, а потом в какой-то момент и вредным, т. е. есть оптимальное число распараллеливания, за которое переступать нельзя.
masterspline
08.07.2017 15:44+3> Отсюда приходим к более продвинутому решению: сообщения сначала попадают в очередь балансировщика, который контролирует количество запущенных потоков обработки и перенаправляет сообщения в их очереди.
Есть другой способ. Называется Work Stealing (очень модная методика, сейчас все так делают). Заводится очередь с подочередями на каждое ядро процессора. Обработчиков не больше, чем ядер (если они не спят на блокирующих системных вызовах). Каждый обработчик берет задачи из своей подочереди, но когда там пусто он (кричит «свободная касса») присваивает задания из чужой очереди. Это уменьшает расходы на блокировки (атомарный xchg данных которые уже в твоем кеше не сильно накладнее, чем обычный) и обмен данными между кешами процессора (пока не закончены задания в своей очереди, чужая не интересует). Когда обработчик прошвырнулся по чужим очередям и даже там ничего не нашел, он уходит в спячку на какое-то время. Если за это время его не разбудят — он самоликвидируется (возможно, за исключение минимального лимита обработчиков, чтобы при появлении нового задания в очереди достаточно было один разбудить, а не создавать новый). Новые обработчики добавляются при постановке задач в очередь. Сначала делается попытка разбудить уже существующий, если такого нет, то создается новый (если еще не превышен лимит обработчиков).
В такой схеме есть недостаток, по сравнению с твоим решением — очередность выполнения. В твоем подходе задачи начинают выполняться в порядке поступления в глобальную очередь (хотя с завершение возможна такая ситуация: первый взял задачу и его сняли с выполнения, а второй взял и выполнил по очереди 2-11 задачи). Тут каждая очередь независима и задачи становятся на выполнение по порядку только в пределах очереди (т.е. 1-я задача в 3-й очереди будет поставлена на обработку до 15-й в той же очереди, но за это время в другой очереди могут быть задачи поставленные в нее еще до 1-й задачи в 3-й очереди, которые так и будут ждать).
Если такое поведение неприемлемо в твоей задаче, то это решение не подходит. Однако, в многопоточке есть одно важное правило — нужно избегать разделяемых объектов, доступных на запись (запись не масштабируется на много CPU). Т.е. глобальная очередь будет работать медленно (каждая запись — это миграция строки кеша на другое ядро, возможно, в другом процессорном сокете и инвалидация этой строки во всех других кешах, за это время можно несколько раз сделать другую невероятно медленную операцию — целочисленное деление).zenkz
10.07.2017 19:21Спасибо за комментарий. Всегда интересно узнать об архитектурных решениях, с которыми раньше не сталкивался. Именно по архитектуре приложений очень тяжело найти годные статьи с примерами из жизни, а такие комментарии спасают и помогают повысить знания — хочу стать архитектором приложений в будущем.
По поводу комментария про объекты на запись — это очень важный момент. Пример из жизни: сервер запускал тяжёлое задание по планировщику и выполнял его несколько часов с интенсивной работой с базой данных. Когда время стало выходить за рамки разумного, то решили оптимизировать это с минимальной кровью. Так вот, замена жёстких дисков на SSD на сервере базы данных дала прирост производительности в 4 раза. Так что иногда вместо оптимизации программного обеспечения можно найти простой и дешёвый способ аппаратной оптимизации.
myemuk
08.07.2017 02:07А если этот процесс автоматизировать не пробовали? К примеру количество воркеров 8. Ну а если очередь разрослась, то менеджер воркеров это заметит и увеличит их количество. Как увилечивать — это уже отдельная статья: процесс, контейнер или хост, — не важно. При уменьшении очереди, убивать воркеров (после окончании обработки сообщения, естественно).
IvanPonomarev
08.07.2017 02:09Выше высказывали эту мысль. Как в кассах супермаркета. Я согласен, это имеет смысл, когда воркер обходится небесплатно. В нашем случае — надо найти оптимальное количество воркеров, дающее максимальную пропускную способность (ограниченную вышеупомянутым universal scalability law).
DenomikoN
08.07.2017 02:09+1Очевидно LIFO это не очередь.

Videoman
09.07.2017 00:47+1Если принять что LIFO тут не нужен, все-таки, хотелось бы не согласиться с вашим утверждением. На всякий случай, для справки: с точки зрения абстракции структур данных LIFO — это самая настоящая очередь. Свойства примитивов, в теории, рассматриваются именно в таком порядке: очередь с приоритетами, потом из этой структуры выводится LIFO и FIFO (подчеркиваю, эффективность реализации рассматривается отдельно от иерархии абстрактных структур данных).
Nikolay_Ch
08.07.2017 02:10Очень плохо видно, сколько конкретно секунд занимает то или иное действие (круговые диаграммы большие. а текст мелкий). Но я не совсем понимаю, почему, оптимизируя время простоя в очереди у Вас изменилось время генерации события и его обработки?
И еще — математики Вы много написали, но непонятно — в чем она Вам помогла? Разобраться с задержками при обработке сообщений можно было и без нее.IvanPonomarev
08.07.2017 02:15+2Что вы, я в этой заметке, можно сказать, вообще без математики обошёлся — если посмотреть, сколько её в теории очередей. В чём помогла: помогла тем, что стало абсолютно ясно происходящее в системе. Вот, вроде бы, быстрый сервер, вроде его пропускная способность адекватна поступающему потоку. Но ожидание в очереди велико. Можем ли мы что-то сделать? Оказалось — ещё как можем, т. к. мы находимся около точки насыщения.
koronabora
08.07.2017 02:15Странно но я когда начал читать подумал что мысль о балансе между производителями заданий и обработчиками должна возникать сама собой. Она довольно инуитивна. Я понимаю это так: соотношение количества обработчиков и генераторов должно быть таким, чтобы на тестируемом интервале времени с нужной точностью достигалось одинаковое количество обработанных и сгенерированных заданий. А лучше чтобы обработчиков было несколько больше. Вот и вся идея. Если генератор дает в секунду, в среднем, 2 задания, и этих генераторов — 2, то обработчиков со скоростью 1 в секунду сделаем 5 или 6, чтобы точно покрывать входящий поток заданий.
Расскажите, где я не прав?IvanPonomarev
08.07.2017 02:20+4Да вот и я так же думал, а оказалось, что ошибался! Про то и статья. Видимо, всё-таки недостаточно ясно изложил.
Оказывается, что на заданном интервале времени количество обрабатываемых заданий должно быть существенно больше количества генерируемых. Тогда будет хорошо.
Если же, как Вы пишете, имеет место «одинаковое количество обработанных и сгенерированных, или несколько больше» — то будет иметь место близость к точке насыщения и система пойдёт вразнос, что мы и наблюдали. Это простое, но контринтуитивное следствие теории очередей. Вот чего я хотел бы знать раньше!zerg59
08.07.2017 03:55Вполне интуитивно все. Чем больше вариация (разброс) темпа генерации заданий тем выше требования к обработчику при одинаковом среднем темпе. В определённых условиях надо ориентироваться на пиковые значения. Пример: туалет в театре. Если вы сделаете из расчёта на среднее — то будет плохо. Ибо народ пойдёт туда только в антракте а не равномерно в течение дня.
masterspline
08.07.2017 16:14> существенно больше
Вот это мне до сих пор остается непонятным. Как уже выше сказали, сильно влияет разброс темпа генерации. Если в среднем система за час обрабатывает чуть больше, чем генерирует за тот же час, но при этом генерация происходит импульсно, в течение 1 минуты, а затем тишина, то последнее сгенерированное задание будет обработано в конце часа. Таким образом, если лимит на ожидание в очереди — 100 секунд, то система должна быть рассчитана на обработку того количества задач, которые могут сгенерироваться за 100 секунд в пике нагрузки. В таком случае просто не будет такого 100 секундного интервала, когда система не успеет обработать все задачи, которые сгенерированы за это время.
В случае сильно неравномерной скорости генерации многие обработчики будут простаивать, поэтому полезно иметь возможность динамически добавлять обработчиков в пике нагрузки и, если есть возможность, ограничивать скорость генерации заданий.
P.S. Многие вещи стали мне понятны после прочтения статьи и комментариев. Плюсик статье поставил.
koronabora
09.07.2017 11:40ИМХО, система на бумаге — это одно, а в реальной операционной системе у нас слишком много потоков заставят планировщик «захлебнуться». Отсюда вытекает следующая моя мысль:
в реальных системах количество ядер ограничено и, поэтому, с некоторого момента, необходимо закидывать обработчики и генераторы по несколько штук в один поток (свой для генераторов и свой для обработчиков). Иначе ресурсы системы будут заняты не работой, а обслуживанием потоков. Грубо говоря, у нас 32 ядра. Делаем по 15 потоков генераторов и по 25 обработчиков, далее все генераторы равномерно распределяем по этим потокам, аналогично с обработчиками. Да, некоторые будут блокировать друг друга, но все равно, при 50 реально работающих потоков аналогично будет проходить блокировка, но уже на уровне ОС.
alexeykuzmin0
10.07.2017 16:53Думаю, это удобно понимать на примере канализации. Несмотря на то, что средний объем трафика одного конкретного унитаза очень маленький, мы делаем от него широкую трубу, чтобы лучше пропускать пики.
corr256
08.07.2017 09:41-4погрузиться в Википедию, PlanetMath и онлайн-лекции, откуда на меня как из рога изобилия посыпались сведения о нотации Кендалла, законе Литтла, формулах Эрланга, и т. д., и т. п.
И это вместо того, чтобы сразу писать нормальный код? Чего только не сделаешь, лишь бы ничего не делать.

funca
08.07.2017 10:53+11Режим, близкий к насыщению: ?>?, но ненамного. В этой ситуации небольшие изменения пропускной способности сервера очень сильно влияют на параметры производительности системы, как в ту, так и в другую сторону.
Не об это-ли постоянно спотыкаются проекты, использующие гибкие методологии разработки типа Scrum и Kanban? Я имею ввиду то, что в них так же используются очереди задач: бэклог, спринты.
Если я правильно понял тезис, попытке задать нагрузку на команду в режиме близком к насыщению, проект автоматически попадает в зону риска, что задачи будут находиться в очереди вечность. И даже незначительные улучшения в «пропускной способности» разработчиков (например за счет овертаймов) будут оказывать сильное влияние на производительность команды и положительно сказываться на ситуации в целом.
dennybaa
08.07.2017 11:31Интересная статья спасибо! Математика) и действительно! Количество обратываемых сообщений должно быть намного больше в нормально настроенной системе. Никогда об этом не думал, а так оно и есть… Однако это ли Вам помогло найти ботлнек!?
На мой взгляд, мониторинг подсистем, хотя бы с визуализацей загружености. Например для БД: диск IO, количество блокировок БД, топ тяжёлых запросов и их медиана в зависимости от количества воркеров (одновременно выполняемых задач), показали бы картину без математики. Если вы наращиваете воркеров, а медиана времени выполнения тяжёлых запросов растет, то сколько бы их не добавлять и как не прокачивать app сервера — это не поможет, затык в БД. А значит надо, что-то соптимизировать, что и было сделано — кэширование ненужных запросов к БД.
le1ic
08.07.2017 17:56+2Все проще — им нужно было просто длину очереди мониторить и все стало бы очевидно. Вообще не понимаю при чем здесь математика, и зачем в нее нужно было так погружаться, чтобы понять очевидные вещи.
Очередь — это бассейн из которого вода вытекает через трубу фиксированной производительности, а втекает как попало.
petropavel
09.07.2017 11:05+1Помогло, как я понял. Там не совсем bottlenect, фишка в том, что обычно надо оптимизировать тот этап, который в профиле занимает больше всего времени. У них обработка занимает очень мало времени, а больше всего — ожидание. И что делать, непонятно, ожидание же ускорить не получится. А теория очередей дает ответ — надо оптимизировать именно обработку (что совершенно контринтуитивно для опытных оптимизаторов с профайлерами наперевес) и это резко уменьшит время ожидания. Что и произошло.

Norgorn
08.07.2017 12:13+2Кажется, что задача просто изначально сформулирована несколько неполностью, отсюда и проблемы. По сути, в случае, когда внезапно приходит большая пачка сообщений, 90% этой пачки должны быть обработаны за 4 секунды. В этом случае средняя скорость обработки и средняя скорость поступления сообщений не играют никакой роли, не важно, что после пачки будет пусто, её вот прямо сейчас надо обрабатывать. Усреднение только мешает и сбивает с толку.
Отсюда можно разбить задачу на две:
— Обрабатывать текущий постоянный поток (если он вообще есть).
— Обрабатывать пики.
И можно даже ввести некоторый критерий применимости теории очередей:
Если пиковая нагрузка не превышает среднюю на X процентов, можно не пытаться обрабатывать пики отдельно и просто добавить мощности в потоковый обработчик. Но, если пиковая нагрузка значительно выше средней, внезапные горы сообщений обрабатывать нужно отдельно и теория очередей в указанном изложении (не сомневаюсь, атм про пики тоже есть) не поможет.
Это все можно математически формализовать, я просто хотел показать, что случай может несколько отличаться, от того, как он представлен.
Что не делает статью плохой, наоборот, она, по-моему, прекрасна, и формализм, на самом деле, радует, ибо дает понятные и обоснованные метрики, а не «ну нам показалось».funca
08.07.2017 12:47Кажется, что задача просто изначально сформулирована несколько неполностью, отсюда и проблемы… когда внезапно приходит большая пачка сообщений, 90% этой пачки должны быть обработаны за 4 секунды. В этом случае средняя скорость обработки и средняя скорость поступления сообщений не играют никакой роли, не важно, что после пачки будет пусто, её вот прямо сейчас надо обрабатывать. Усреднение только мешает и сбивает с толку.
Хорошая мысль, но боюсь, она еще больше сбивает с толку: http://xkcd.ru/605/ :)

AC130
08.07.2017 13:12+3Статья интересная, но хотелось бы упомянуть пару нюансов. Правило что при \lambda=\mu система сваливается в бесконечную очередь за конечное время верно только для случайных систем. Если у вас система детерминированная (D/D/1), то она легко рассчитывается аналитически и работает даже с очередью конечной длины в режиме насыщения. Многие формулы в ТМО выводятся для систем вида M/M, т.е. пуассоновских потоков. Если у вас есть логи, можно проверить верно ли это распределение для вашей системы. Если у вас система очень похожа на детерминированную (сообщения приходят через одинаковые периоды времени + небольшое дрожание), то возможно что она вполне будет работать в режиме насыщения. Более того, в ТМО как правило рассматривают системы без обратной связи, т.е. сервер не может влиять на источники событий. В вашем же случае это видится вполне возможным: когда размер очереди на сервере превышает определённый порог, посылать источникам сообщения обратную связь с просьбой замедлиться.
IvanPonomarev
08.07.2017 18:24+1Спасибо за квалифицированный комментарий!
Да, я знаю, что D/D/1 не вылетает в бесконечность при $\lambda=\mu$, но в статье про это не написал: мне кажется, что детерминированный источник это скорее абстракция) И это точно не наш случай: я, к сожалению, не могу тут рассказать конкретику, но источник событий у нас — самый что ни на есть классический пуассоновский. Мы должны улавливать внешние по отношению к системе события, и на их частоту мы влиять никак не можем.

Shrizt
11.07.2017 18:40Плохо что автор не работал на производстве и не знает того что было придумано еще в 20м веке (да, я это сказал, еще в 20м веке! :) )
https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%BE%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%B8%D0%B9
joger
Я сейчас скажу наверное ужасно глупую вещь, но вы знаете разницу между LIFO и FIFO? у вас уже есть redis, берёте Lists и вперёд. И будет вам выравнивание
TimsTims
Тут дело ведь не в fifo lifo, а в неоптимальном алгоритме. Насколько я понял, сервер после каждой обработки слишком долго ждал получения нового задания, и автор это переделал: оптимизировал обработчики событий. Так-что хоть и графики показывали, что «задание ждёт», на самом деле, это «сервер ждёт получения задания». А уж в каком порядке FIFO/LIFO их выдавать — разницы никакой.
IvanPonomarev
Нет-нет! В нашем случае именно что задания долго ждали в очереди (красный цвет на круговых диаграммах), как раз из-за того, что пропускная способность сервера была лишь немного выше частоты поступления заданий. Поэтому оптимизация алгоритма работы сервера поменяла картину кардинально.
Да, у нас Redis и для очереди мы как раз используем Redis list. Впрочем, к смыслу статьи это отношения не имеет, т. к. это могло быть что угодно: ApacheMQ, Rabbit, Kafka или самописный linked list — всё это подчиняется общим законам ))
Мысль с LIFO я вообще не понял. LIFO — это не очередь, а стек всё-таки. И я не понял, при чём тут LIFO.
martin_wanderer
Простите, я правильно понял, что оптимизация собственно обработки сообщения ( даже небольшая ) привела к радикальному уменьшению времени простоя?
IvanPonomarev
Да, правильно. К радикальному уменьшению времени ожидания в очереди.