

Фото: Известия
В этом посте кратко рассматривается поведение и преимущества структур данных в РНР 7. В конце также представлен список ответов на ваши возможные вопросы.
GitHub: https://github.com/php-ds
Область имён: Ds\
Интерфейсы:
Collection, Sequence, HashableКлассы:
Vector, Deque, Stack, Queue, PriorityQueue, Map, SetВ PHP есть одна структура данных, которая управляет всеми остальными. Это
array — комплексная, гибкая, ничего не умеющая гибридная структура, поведение которой сродни комбинации list и linked map. Эту структуру мы используем повсеместно, что связано с прагматичностью РНР: «используя средства здраво и реалистично, исходя из практических, а не теоретических соображений». Array выполняет свою работу, даже если вы не изучали информатику. Но гибкость, к сожалению, увеличивает сложность.Недавний релиз РНР 7 сильно взволновал РНР-сообщество. Все жаждали попробовать новые возможности и самостоятельно убедиться в двукратном приросте производительности. Хотя одной из причин увеличения скорости стала именно переработка
array, но всё же эта структура по-прежнему «оптимизирована для всего и для ничего» и обладает потенциалом для улучшения.Что касается структур SPL, то… к сожалению, они ужасны. До выхода РНР 7 они давали некоторые преимущества, но теперь толку от них никакого. Вы спросите, почему бы их не улучшить? Это можно было бы сделать, но я считаю, что их архитектура и реализация столь неудачны, что целесообразнее заменить их чем-нибудь совершенно новым.
Collection
Это основной интерфейс, применение которого охватывает такую функциональность, как
foreach, echo, count, print_r, var_dump, serialize, json_encode и clone. Sequence
Sequence описывает поведение значений, расположенных в виде одномерной линейной последовательности. В некоторых языках это называется List. Sequence аналогичен array, который использует инкрементальные целочисленные ключи, за исключением ряда отличий:- Значения всегда индексируются по порядку [0, 1, 2, …, размер – 1].
- Удаление или вставка одного значения изменяет позиции всех следующих за ним значений.
- Доступ к значениям возможен только в рамках индекса диапазона [0, размер – 1].
Применение:
- В случаях, когда вы бы хотели использовать
arrayв качестве списка (без учёта ключей). - Это более эффективная альтернатива для
SplDoublyLinkedListиSplFixedArray.
Vector
Это последовательность (
sequence) значений в непрерывном буфере, который автоматически увеличивается и уменьшается. Vector — одна из наиболее эффективных структур-последовательностей, поскольку индекс значений напрямую сопоставляется с индексом в буфере, а фактор роста не зависит от конкретного множителя или степени. Преимущества:
- Очень низкое потребление памяти.
- Очень быстрое итерирование.
- Временная сложность
get,set,pushиpopравна О(1).
Недостатки:
- Временная сложность
insert,remove,shiftиunshiftравна О(n).
Интересный факт:
Vector — наиболее часто используемая структура данных в Photoshop.Deque
Название произносится как «дэк» и является аббревиатурой от double-ended queue (двусторонняя очередь). Это последовательность значений в непрерывном буфере, который автоматически увеличивается и уменьшается. Внутри РНР
deque используется с помощью Ds\Queue.Для отслеживания начала (head) и окончания (head) последовательности используются два указателя. Они могут перемещаться по буферу циклически, поэтому нет нужды перемещать значения, чтобы вставить новое. Благодаря этому свойству shift и
unshift работают гораздо быстрее того же Vector.Использование индекса для доступа к значениям требует преобразования позиции в индексе в соответствующее значение в буфере: ((начало + позиций) % ёмкость).
Преимущества:
- Низкое потребление памяти.
- Временная сложность
get,set,push,shiftиunshiftравна О(1).
Недостатки:
- Временная сложность
insertиremoveравна О(n). - Ёмкость буфера должна равняться 2n.
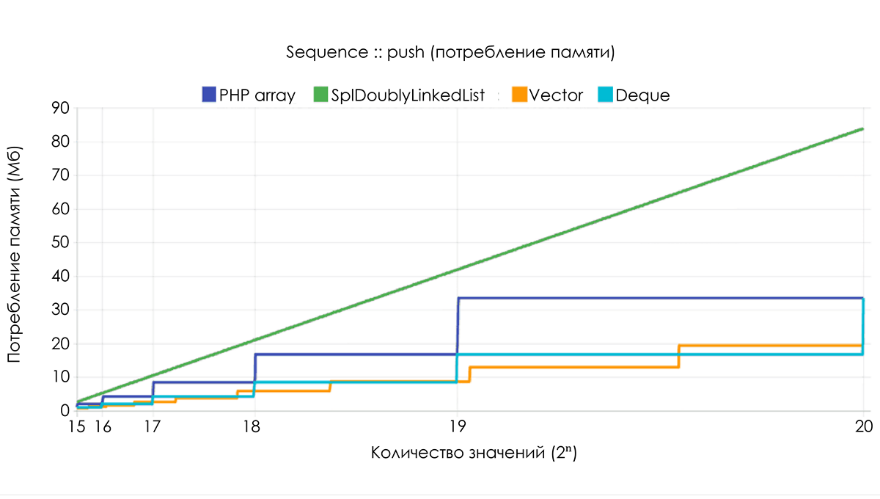
Ниже приведены результаты бенчмарка, демонстрирующие время выполнения
push и объём используемой памяти при случайной выборке из 2n целочисленных значений. Высокую скорость продемонстрировали array, Ds\Vector и Ds\Deque, а SplDoublyLinkedList оказался более чем вдвое медленнее.В случае с
SplDoublyLinkedList осуществляется индивидуальное выделение памяти для каждого значения, что приводит к линейному росту потребления. С учётом поддержания ёмкости буфера 2n, фактор роста у array и Ds\Deque равен 2. У Ds\Vector фактор роста равен 1,5, поэтому процедура выделения памяти происходит чаще, но зато общее потребление ниже.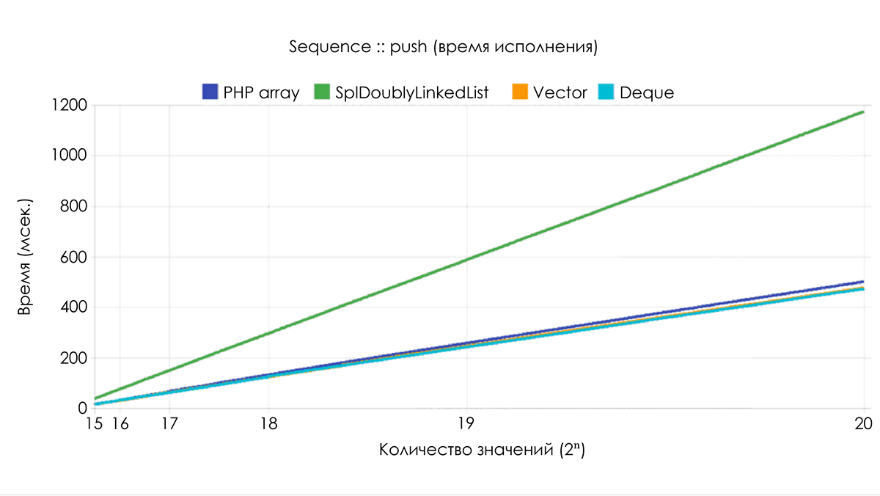
Следующий бенчмарк показывает, сколько времени занимает выполнение
unshift для одного значения в последовательности из 2n значений. При этом не учитывалось время, затраченное на выбор образца. Временная сложность array_unshift равна О(n). Увеличение размера образца вдвое настолько же увеличивает и время выполнения, потому что приходится обновлять все числовые индексы в диапазоне [1, размер – 1].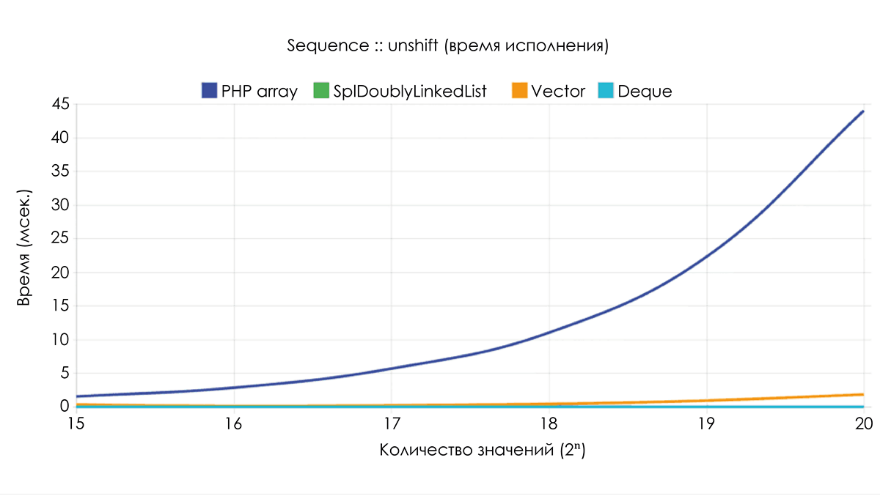
Временная сложность
Ds\Vector::unshift тоже равна О(n). Откуда такая скорость? Дело в том, что array хранит в корзине (bucket) каждое значение вместе с его ключом и хэшем. Если индекс является цифровым, то нам нужно проверить каждую корзину и обновить хэш. При этом array_unshift фактически создаёт совершенно новый массив, который заменяет старый по мере копирования значений.В
Vector индекс значений напрямую сопоставляется с индексом в буфере, поэтому нам достаточно лишь переместить вправо на одну позицию каждое значение в диапазоне [1, размер – 1]. Это осуществляется с помощью единичной операции memmove.Ds\Deque и SplDoublyLinkedList работают очень быстро — О(1), потому что время выполнения unshift не зависит от размера образца.Третий бенчмарк демонстрирует потребление памяти при выполнении 2n операций
pop, то есть от 2n до 0. Любопытно, что array всегда придерживается уже выделенной памяти, даже если её объём значительно уменьшается. Ds\Vector и Ds\Deque начинают потреблять вдвое меньше памяти, если их размер падает ниже 25% от текущей ёмкости. А SplDoublyLinkedList освобождает память, занимаемую каждым значением, поэтому потребление снижается линейно.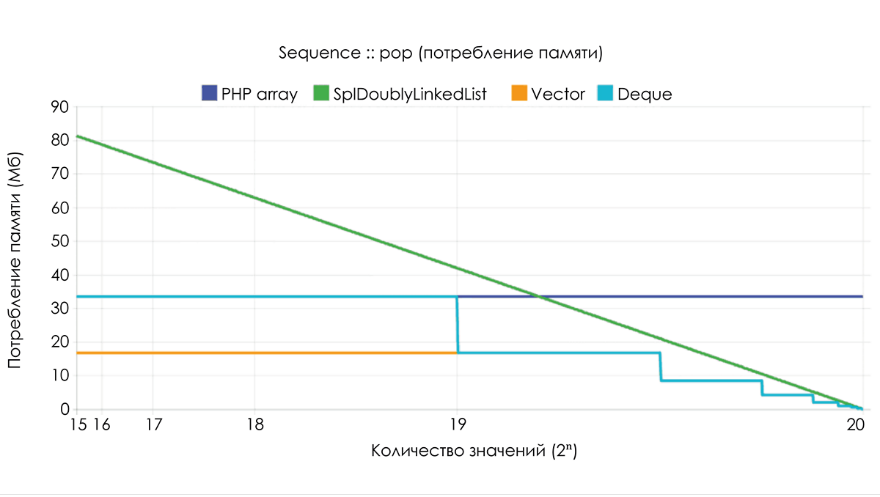
Stack
Stack — это LIFO-коллекция («получен последним, обработан первым»), предоставляющая доступ только к верхнему значению из всех содержащихся в структуре. Итерирование осуществляется деструктивно: в первую очередь обрабатывается то значение, которое было получено последним. Как патроны в магазине:
https://upload.wikimedia.org/wikipedia/commons/6/6c/Single_row_box_magazine.svg
{kind=link}
Функционирование
Ds\Stack обеспечивается с помощью Ds\Vector. SplStack расширяется с помощью SplDoublyLinkedList, поэтому с точки зрения производительности картина будет аналогична сравнению Ds\Vector с SplDoublyLinkedList, как в предыдущих бенчмарках. А ниже вы можете видеть, сколько времени тратится на выполнение 2n операций pop, то есть при размере от 2n до 0.
Queue
Queue — это FIFO-коллекция («получен первым, обработан первым»), предоставляющая доступ только к первому значению из всех содержащихся в структуре. Итерирование осуществляется деструктивно, в порядке живой очереди.
Функционирование
Ds\Queue обеспечивается с помощью Ds\Deque. SplDoublyLinkedList расширяет с помощью SplQueue, поэтому с точки зрения производительности картина будет аналогична сравнению Ds\Deque с SplDoublyLinkedList, как в предыдущих бенчмарках.PriorityQueue
Очень похожа на
Queue. Каждому значению в очереди назначают определённый приоритет, и первым из них всегда будет значение с наивысшим приоритетом. Итерирование осуществляется деструктивно, аналогично последовательным pop-операциям, пока очередь не опустеет. PriorityQueue реализована с помощью max heap.Значения с одинаковым приоритетом обрабатываются в порядке живой очереди, аналогично
Queue. Однако SplPriorityQueue удаляет значения в произвольном порядке.Ниже приведены результаты бенчмарка, демонстрирующие время выполнения
push и объём используемой памяти при случайной выборке из 2n целочисленных значений, имеющих случайные значения приоритетов. Этот набор значений использовался во всех бенчмарках, при этом в случае с Queue также генерировались случайные приоритеты.Пожалуй, это наиболее важный бенчмарк.
Ds\PriorityQueue более чем вдвое быстрее SplPriorityQueue, при этом расходует лишь 5% от его объёма памяти. То есть эффективность потребления памяти у него в 20 раз выше.Как это достигнуто? Ведь
SplPriorityQueue использует те же самые внутренние структуры. Всё дело в приоритетах. SplPriorityQueue может использовать в качестве приоритетов любые типы значений, в результате размер каждой пары значение — приоритет может достигать 32 байт, в то время как Ds\PriorityQueue поддерживает только целочисленные приоритеты, поэтому размер пары не превышает 24 байт. Но всё же это совершенно не объясняет столь разительную разницу в бенчмарках.Если вы посмотрите на исходный код
SplPriorityQueue::insert, то увидите, что для хранения пары в памяти размещается массив. А поскольку минимальная ёмкость массива равна 8, то в результате каждая пара требует zval + HashTable + 8 * (корзина + хэш) + 2 * zend_string + (8 + 16) строк байтов = 16 + 56 + 36 * 8 + 2 * 24 + 8 + 16 = 432 байта (64 бита).Какой тогда смысл в использовании массива?
SplPriorityQueue использует ту же внутреннюю структуру, что и SplMaxHeap. А это означает, что в качестве значения должен выступать zval. Очевидным (хотя и неэффективным) способом создания zval-пары является использование массива самим zval.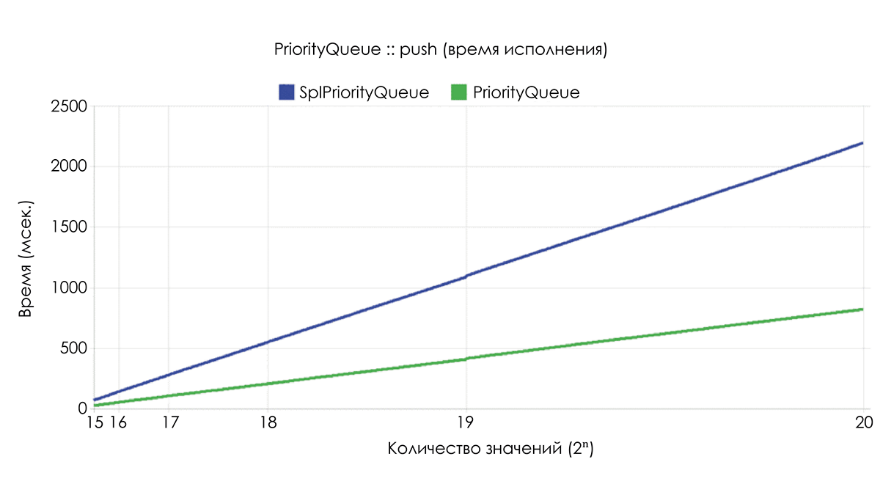

Hashable
Это интерфейс, позволяющий использовать объекты в качестве ключей. Он служит альтернативой
spl_object_hash. Хэш объекта создаётся на основе его ссылки (handle), то есть два объекта, согласно неявному определению считающиеся равными, не будут рассматриваться как эквивалентные, поскольку не являются одним и тем же экземпляром.В
Hashable используются только два метода: hash и equals. Во многих языках эта функциональность поддерживается нативно. Например, в Java — hashCode и equals, в Python — __hash__ и __eq__. Возможность внедрения этой функциональности в РНР также обсуждалась, но в результате от неё решили отказаться.Если
Hashable не задействуется ключом объекта, то все структуры, использующие этот интерфейс, — Map и Set — обращаются к spl_object_hash. Map
Это последовательная коллекция пар ключ — значение, использование которой в этом контексте почти аналогично
array. Ключи могут быть любых типов, главное, чтобы они были уникальными. Если в map уже есть такой ключ, то его значение заменяется.Данные сохраняются в порядке добавления, как и в
array.Преимущества:
- Производительность и эффективность потребления памяти почти такие же, как у
array. - При уменьшении размера автоматически освобождает память.
- Ключи и значения могут быть любого типа, в том числе могут быть и объектами.
- Использует интерфейс
Hashable. - Временная сложность
put,get,removeиcontainsKeyсоставляет O(1).
Недостатки:
- Если в качестве ключей используются объекты, то
mapнельзя преобразовать вarray. - Не может обращаться к значениям по индексу (позиции).
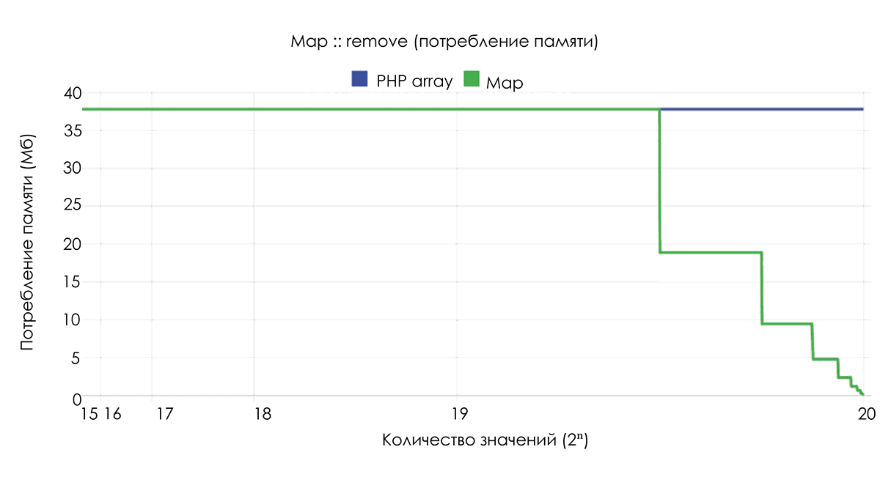
По производительности и потреблению памяти
map находится примерно между array и Ds\Map. Однако array не меняет объём занимаемой памяти, а Ds\Map начинает потреблять меньше памяти, если его размер падает ниже 25% от текущей ёмкости.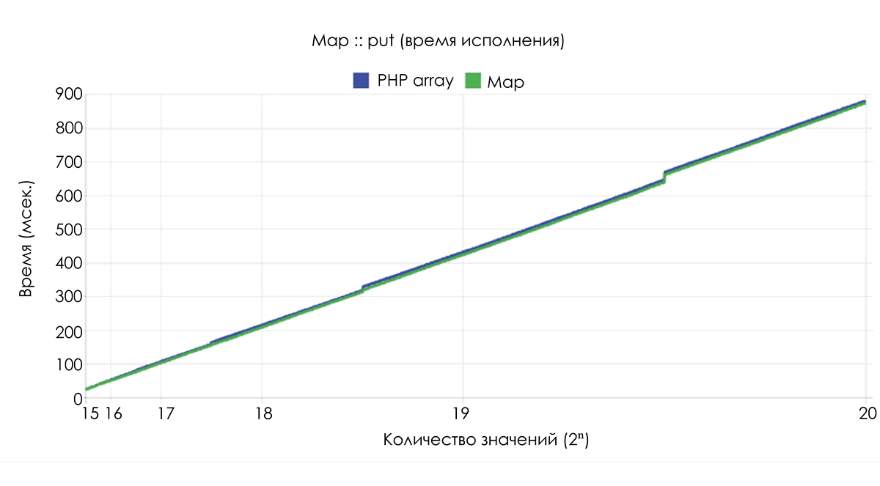
Set
Это коллекция уникальных значений. Согласно руководству, если при реализации не определять порядок размещения значений, то они будут храниться беспорядочно. Приведу пример из Java: у интерфейса
java.util.Set есть две основные реализации — HashSet и TreeSet. В первом случае на добавление и удаление тратится О(1) времени, а во втором — O(log n), зато данные сортируются.Set использует ту же внутреннюю структуру, что и Map, в основе которой лежит внутренняя структура array. Поэтому Set можно в любое время отсортировать в течение O(n * log(n)), так же как и Map с array.Преимущества:
- Временная сложность
add,removeи contains равна O(1). - Использует интерфейс
Hashable. - Поддерживает значения любого типа (
SplObjectStorageподдерживает только объекты). - Побитовая эквивалентность для
intersection,difference,unionиexclusive or.
Недостатки:
- Не поддерживает
push,pop,insert,shiftиunshift. - Если до индекса удалялись значения, то временная сложность
getравна O(n), в противном случае — O(1).
Ниже отражён график продолжительности добавления 2? новых экземпляров
stdClass. Как видите, Ds\Set чуть быстрее SplObjectStorage, при этом потребляет вдвое меньше памяти.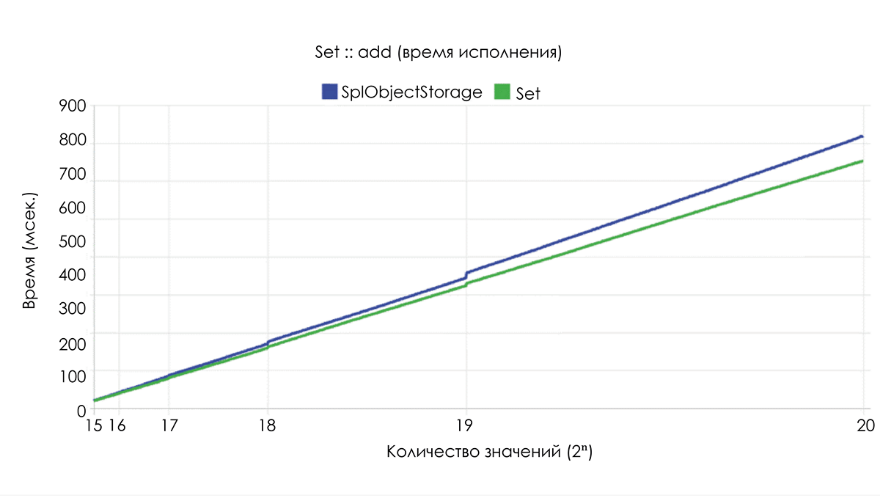

Обычно для создания массива уникальных значений используется
array_unique, создающий новый array, содержащий только уникальные значения. Важно помнить, что значения в массиве не индексированы, поэтому временная сложность линейного поиска in_array равна O(n). array_unique работает со значениями, а не с ключами, поэтому каждая проверка на принадлежность представляет собой процедуру линейного поиска. В результате общая временная сложность равна O(n?), а сложность по памяти (memory complexity) — O(n).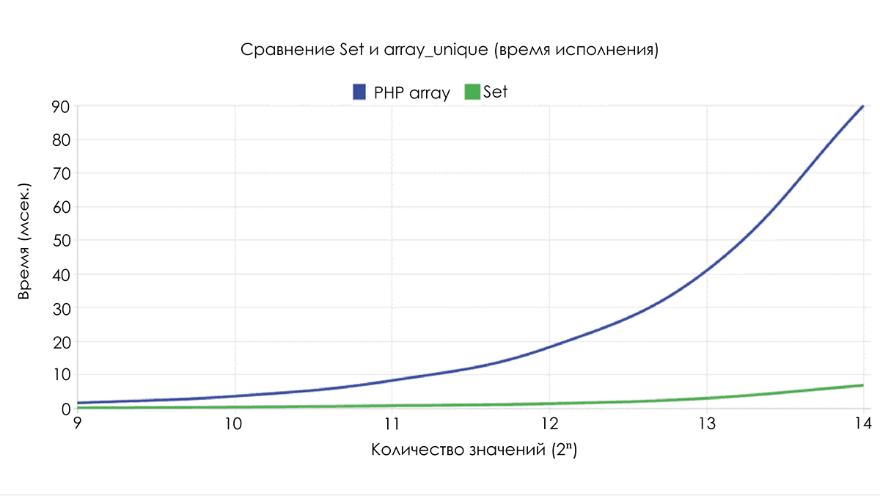
Ответы на вопросы
Проводились ли тесты?
На данный момент проведено ~2600 тестов. Возможно, некоторые из них были избыточны, но я предпочту случайно дважды что-то протестировать, чем не сделать этого совсем.
Документация? API?
На момент написания этой публикации работа над документацией ещё не закончена, но вы получите её с первым стабильным релизом. А пока можете изучить некоторые хорошо задокументированные файлы заглушки.
Можно посмотреть конфигурацию бенчмарков? Есть ли другие результаты?
Полный список бенчмарков доступен в отдельном репозитории: php-ds/benchmarks.
Все прогоны выполнялись на стандартной сборке PHP 7.0.3 на Macbook Pro 2015. Для разных версий и платформ результаты будут отличаться.
Почему
Stack, Queue, Set and Map не являются интерфейсами?Я не верю, что стоит создавать дополнительные реализации какого-то из них. Три интерфейса и семь классов обеспечивают хороший баланс между практичностью и специализацией.
В каких случаях лучше использовать
Deque, а не Vector?Если вы уверены в том, что не будете использовать shift и unshift, то применяйте
Vector. Также можете воспользоваться Sequence в качестве typehint.Почему все классы являются финальными (final)?
Архитектура API php-ds заставляет использовать принцип composition over inheritance. SPL-структуры служат хорошим примером неправильного использования наследования. Например,
SplDoublyLinkedList расширяется с помощью SplStack, поддерживающим случайный доступ по индексу, а также shift и unshift, так что технически это уже не стек.В Java Collections Framework также есть несколько интересных случаев, когда наследование становится причиной неопределённости. Скажем,
ArrayDeque использует три метода добавления значений: add, addLast и push. Дело в том, что ArrayDeque реализует Deque и Queue и поэтому должен реализовать addLast and push. Но когда три разных метода делают одно и то же, это может приводить к ошибкам и несовместимости.java.util.Vector расширяется с помощью старого java.util.Stack, и считается, что интерфейс Deque и его реализации обеспечивают более полный и логичный набор операций стековой памяти (LIFO stack). Однако интерфейс Deque включает в себя такие методы, как addFirst и remove(x), которые не должны быть частью стекового API. То, что эти структуры не расширяют друг друга, ещё не означает, что нам нельзя это делать.Это справедливое замечание, но я всё ещё верю, что составная архитектура больше подходит для структур данных. Как и
array, они создавались самодостаточными. Вы же не можете расширять array, поэтому вокруг него мы создаём свои собственные API, используя для этого внутреннюю возможность хранения реальных данных в array. А наследование лишь повлечёт за собой ненужное внутреннее усложнение.Почему в глобальном пространстве имён присутствует класс
ds?Он обеспечивает альтернативный синтаксис построения:

Почему нет связного списка?
На самом деле он был —
LinkedList. Но потом я понял, что он ни при каких условиях не сможет конкурировать с Vector или Deque, поэтому решил его убрать. Есть две главные причины его поддерживать: избыточное распределение памяти (allocation overhead) и локальность ссылок (locality of reference).Связный список также должен выделять или освобождать node при любом добавлении или исключении значения. У
node есть два указателя (в случае с двунаправленным связным списком) для ссылок на предыдущий и следующий node. В то же время
Vector и Deque заранее выделяют буфер, поэтому можно реже выполнять процедуру выделения и освобождения. Также им не требуются дополнительные указатели, чтобы знать, какое значение идёт до или после, что позволяет экономить ресурсы.Можно ли за счёт отсутствия буфера снизить максимальное потребление памяти связным списком?
Можно, но только если коллекция очень маленькая. Верхняя граница потребления памяти
Vector’ом определяется по формуле (1,5 * (размер – 1)) * zval, а минимальная — 10 * zval. Двунаправленный связный список будет потреблять (размер * (zval + 8 + 8)). Так что связный список выгоднее Vector’а, только если его размер меньше 6.Ладно… связный список использует больше памяти. Но почему он такой медленный?
У узлов связного списка плохая пространственная локальность. Это означает, что расположенные рядом узлы могут находиться в физической памяти далеко друг от друга. И при прохождении по связному списку приходится метаться по памяти вместо того, чтобы использовать кэш процессора. С этой точки зрения
Vector и Deque обладают большим преимуществом: их значения располагаются в физической памяти друг за другом.«В основе низкой производительности лежит разобщённость структур данных. Особенно избегайте связных списков».
«Трудно найти что-то, ещё хуже влияющее на производительность современных процессоров, чем использование связных списков».
Chandler Carruth (CppCon 2014)
PHP — это язык для веб-разработки, и производительность тут неважна.
Производительность не должна быть на первом месте. Ваш код должен быть консистентным, удобным в обслуживании, устойчивым, предсказуемым, безопасным и лёгким для понимания. Но нельзя сказать, что производительность «неважна». Мы тратим много времени, стараясь уменьшить потребление ресурсов, прогоняем фреймворки через бенчмарки и делаем бессмысленные микрооптимизации:
- Что быстрее, print или echo?
- Тернарный оператор в PHP: быстрый или нет?
- Бенчмарк PHP: вносим ясность
- Опровержение мифа о производительности одинарных кавычек
Мы приложили все силы к тому, чтобы обеспечить двукратный рост производительности в PHP 7. Пожалуй, это одно из важнейших преимуществ перехода с PHP 5.
Эффективный код снижает нагрузку на серверы, уменьшает время отклика наших API и веб-страниц, увеличивает скорость работы наших инструментов для разработки. Производительность важна, но большее значение имеет удобство поддержки кода.
Обсуждение: Twitter, Reddit, Room 11
Репозиторий: github.com/php-ds
Бенчмарки: github.com/php-ds/benchmarks