
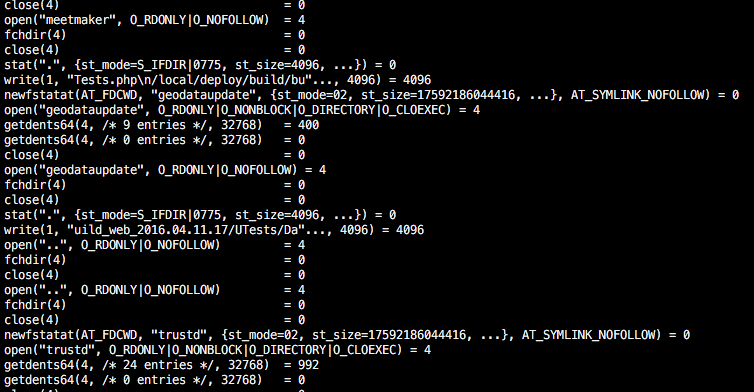
 Для одной внутренней утилиты мне понадобилось написать сканирование изменений в директории, по аналогии с утилитой find, и я столкнулся с неожиданной вещью: стандартный Open()+Readdir()+Close() в go очень медленным по сравнению с тем, как работает linux'овая утилита find. На картинке можно видеть strace этой утилиты. Можно видеть, что она делает какие-то очень странные системные вызовы, и в этих системных вызовах мы и попытаемся разобраться и написать аналог find на go, который будет работать только под Linux, но зато со сравнимой скоростью.
Для одной внутренней утилиты мне понадобилось написать сканирование изменений в директории, по аналогии с утилитой find, и я столкнулся с неожиданной вещью: стандартный Open()+Readdir()+Close() в go очень медленным по сравнению с тем, как работает linux'овая утилита find. На картинке можно видеть strace этой утилиты. Можно видеть, что она делает какие-то очень странные системные вызовы, и в этих системных вызовах мы и попытаемся разобраться и написать аналог find на go, который будет работать только под Linux, но зато со сравнимой скоростью.Наивная реализация
Давайте для начала напишем «наивную» реализацию find, которая будет для простоты рекурсивно выводить список файлов в директории.
package main
import (...)
func readdir(dir string) {
dh, err := os.Open(dir)
defer dh.Close()
for {
fis, err := dh.Readdir(10)
if err == io.EOF {
break
}
for _, fi := range fis {
fmt.Printf("%s/%s\n", dir, fi.Name())
if fi.IsDir() {
readdir(dir + "/" + fi.Name())
}
}
}
}
func main() {
readdir(os.Args[1])
}
(полный код, с импортами и обработкой ошибок)
Если мы запустим этот код, то он, безусловно, будет работать, но wall time и rusage будут примерно в 3 раза больше, чем у find (разница в один файл объясняется тем, что мы не печатаем саму запрошенную директорию, в отличие от find):
$ time find /path/to/dir | wc -l
169561
real 0m0.333s
user 0m0.104s
sys 0m0.272s
$ time GOGC=300 ./find-simple /path/to/dir | wc -l
169560
real 0m1.160s
user 0m0.540s
sys 0m0.944s
Заметим, что system time уж очень большой, и добавим буферизацию вывода:
@@ -7,5 +7,7 @@ import (
+var bufout = bufio.NewWriter(os.Stdout)
func readdir(dir string) {
@@ -28,3 +30,7 @@ func readdir(dir string) {
for _, fi := range fis {
- fmt.Printf("%s/%s\n", dir, fi.Name())
+ bufout.WriteString(dir)
+ bufout.WriteByte('/')
+ bufout.WriteString(fi.Name())
+ bufout.WriteByte('\n')
if fi.IsDir() {
@@ -44,2 +50,3 @@ func main() {
readdir(dir)
+ bufout.Flush()
}
(полная версия)
Результаты будут уже намного лучше, но всё равно далеки от идеала:
$ time GOGC=300 ./find-simple-bufio /path/to/dir | wc -l
169560
real 0m0.796s
user 0m0.352s
sys 0m0.616s
Для примера, вот результат для такой же программы на PHP:
$ php ~/find-ob.php /path/to/dir | wc -l
169560
real 0m0.777s
user 0m0.276s
sys 0m0.500s
Программа на PHP даже немного быстрее и потребляет измеримо меньше ресурсов! Это явно не то, что хотелось бы получить от компилируемого языка…
Изучаем системные вызовы Linux
Если вглядеться в strace от find, можно заметить, что он делает getdents64 и почти не делает stat! Но при этом утилита каким-то образом знает, какие имена соответствуют директориям. Посмотрим, что это за вызов getdents64 такой:
SYNOPSIS
int getdents(unsigned int fd, struct linux_dirent *dirp,
unsigned int count);
DESCRIPTION
This is not the function you are interested in. Look at readdir(3) for the POSIX conforming C library interface. This page documents the bare kernel system call interface. The system call getdents() reads several linux_dirent structures from the directory referred to by the open file descriptor fd into the buffer pointed to by dirp. The argument count is specifies the size of that buffer.
The linux_dirent structure is declared as follows:
struct linux_dirent {
...
char d_name[];
char pad; // Zero padding byte */
char d_type; // File type (only since Linux 2.6.4
}
Это именно то, что нам нужно! Что интересно, на BSD-системах при чтении директории тоже доступно поле с типом файла (d_type), для некоторых файловых систем. Нас всячески отговаривают использовать этот системный вызов, но ту же утилиту find это ни капельки не смущает.
Как оказалось, «под капотом» стандартная библиотека go тоже зовет getdents(2), так что нам остается только «выдрать» код, который это делает и очистить его от всего лишнего:
package main
import (...)
var bufout = bufio.NewWriter(os.Stdout)
func readdir(dir string, file string, dirfd int, pathbuf []byte) {
origbuf := make([]byte, 4096) // буфер, куда будет читать getdents
dh, err := syscall.Openat(dirfd, file, syscall.O_RDONLY, 0777) // открываем файл директории по относительному пути
origpathbuf := pathbuf[0:0] // нам передают буфер для хранения пути файла, сбрасываем его
for {
n, errno := syscall.ReadDirent(dh, origbuf) // вызываем getdents
if n <= 0 {
break // EOF
}
buf := origbuf[0:n] // нам вернули число прочитанных байт, это нужно использовать :)
for len(buf) > 0 {
// следующий код выдран из кода ParseDirent:
dirent := (*syscall.Dirent)(unsafe.Pointer(&buf[0]))
buf = buf[dirent.Reclen:]
if dirent.Ino == 0 { // File absent in directory.
continue
}
bytes := (*[10000]byte)(unsafe.Pointer(&dirent.Name[0]))
name := bytes[0:clen(bytes[:])] // функция clen() возвращает длину сишной строки
if len(name) == 1 && name[0] == '.' || len(name) == 2 && name[0] == '.' && name[1] == '.' {
continue
}
// пишем полный путь в буфер с конечным именем файла,
// чтобы не выделять память для маленьких кусочков
pathbuf = append(pathbuf, dir...)
pathbuf = append(pathbuf, '/')
pathbuf = append(pathbuf, file...)
dirlen := len(pathbuf)
pathbuf = append(pathbuf, '/')
pathbuf = append(pathbuf, name...)
pathbuf = append(pathbuf, '\n')
bufout.Write(pathbuf)
// только в случае, если это директория, создаем string
if dirent.Type == syscall.DT_DIR {
readdir(string(pathbuf[0:dirlen]), string(name), dh, origpathbuf)
}
pathbuf = origpathbuf[0:0]
}
buf = origbuf[0:0]
}
syscall.Close(dh)
}
func main() {
dir := os.Args[1]
parentDir := filepath.Dir(dir)
dh, err := os.Open(parentDir)
pathbuf := make([]byte, 16 * 1024)
readdir(parentDir, filepath.Base(dir), int(dh.Fd()), pathbuf)
bufout.Flush()
}
(полный исходный код программы, с обработкой ошибок и функцией clen)
Результаты
Со всеми оптимизациями и использованием системного вызова getdents удалось уменьшить потребление ресурсов до такой степени, что оно работает быстрее, чем find:
$ time GOGC=300 ./find-simple /path/to/dir | wc -l
169560
real 0m1.160s
user 0m0.540s
sys 0m0.944s
$ time GOGC=300 ./find-optimized /path/to/dir | wc -l
169560
real 0m0.200s
user 0m0.060s
sys 0m0.160s
$ time find /path/to/dir | wc -l
169561
real 0m0.333s
user 0m0.104s
sys 0m0.272s
Потребление ресурсов и общее время работы меньше в полтора раза, чем у find. Основные причины для этого состоят в том, что find выдает сортированый список файлов, а также принимает условия для фильтрации списка.
Очевидно, что просто получение списка файлов и вывод его на экран не представляют особой ценности, но такой способ позволяет ускорить многие программы на go, которые, к примеру, предоставляют альтернативу grep за счёт уменьшения накладных расходов на чтение списка файлов из директории.
Ссылки:
Комментарии (24)

Stronix
11.04.2016 20:39-2Таким образом вы лишаетесь кроссплатформенности. А как насчёт быстродействия Walk?

youROCK
11.04.2016 21:03+1Walk использует Readdirnames, так что производительность особо не отличается.
youROCK
11.04.2016 21:04+3На других платформах можно использовать generic-код, это ничему не противоречит
galaxy
11.04.2016 20:55+3Нас всячески отговаривают использовать этот системный вызов, но ту же утилиту find это ни капельки не смущает.
Удивительно, не правда ли? Учитывая, что getdents — нынче единственный системный вызов для чтения директорииyouROCK
11.04.2016 21:05Дело в том, что find явно не просто зовет readdir, ибо «знает», какие файлы являются директориями, не делая stat
mbait
12.04.2016 06:45сканирование изменений в директории
по аналогии с утилитой find
find(1) умеет сканировать изменения, или я не так понял?youROCK
12.04.2016 09:47Не умеет, разве что с фильтром по mtime можно получить нечто похожее. Я имел в виду, что на основе списка файлов можно определять изменения, если где-то хранить предыдущее состояние, как это делает git, например
mbait
12.04.2016 20:04Если речь идёт о периодическом сканировании, скажем, раз в день, то непонятно, зачем делать быстрее, чем
find. Если нужно непрерывно это делать, но полное сканирование это очень плохой подход — медленный и нагружает диск и ядро. Смотритеinotify(7)и другие подобные инструменты.
Но сама тема разбора программ из coreutils однозначно интересна. Я когда-то разбирал
sort(1), чтобы посмотреть, как она делает сортировку по кускам.

stalkerg
12.04.2016 10:48Предупреждаю т.к. недавно наткнулся: в любимой под Linux файловой системе XFS это работать не будет, без спец настройки ФС. :(
В итоге кусок кода на stat переводил обратно (но там время обхода не кретично).youROCK
12.04.2016 10:54В документации об этом написано, и в этом случае должен возвращаться DT_UNKNOWN. В полном коде примера есть кусок, который делает stat(), когда получает такое значение
nikitadanilov
12.04.2016 12:55+1Oдно ограничение вашего кода (и исходного и модифицированного), которого нет у find(1), это невозможность работать с деревом, в котором длина путей превышает MAXPATHLEN. Поэтому find делает fchdir в директорию и из нее. Ну и при DT_UNKNOWN делать stat. У find есть еще одна оптимизация: от смотрит на nlink *родительской* директории. Это число на 1 больше числа поддиректорий (из-за dotdot). Поэтому если nlink == 1, то поддиректорий гарантировано нет (это самый распространенный случай — большинство директорий листьевые) и делать stat в случае DT_UNKNOWN не нужно.
youROCK
12.04.2016 13:02Кстати говоря, ограничения на MAXPATHLEN не должно быть, если не требуется делать Stat (т.е. на семейсте файловых систем ext, например). Я использую openat, а имя директории передаю только для того, чтобы напечатать его на экран.
В целом, я не буду спорить, что код (причём полная версия, а не та, что в статье) обрабатывает DT_UNKNOWN весьма неоптимально, и я даже перепутал Stat() с Lstat(), когда это делал.
Про значение nlink для директорий никогда не задумывался, спасибо! Впрочем, если вы не собираетесь получать DT_UNKNOWN (т.е. если ваши ФС это ext* или btrfs), то эта оптимизация не нужна :).nikitadanilov
12.04.2016 13:12Кстати, ext* может быть создана без флага filetype (mkfs -O ^filetype). Этом случае всегда возвращается DT_UNKNOWN.
youROCK
12.04.2016 13:33Проверил на файловой системе ext3, создал директорию, на которую stat(2) ругается с ENAMETOOLONG, и конечная версия утилиты распечатала дерево целиком, и результат не отличается от find.

Woodroof
12.04.2016 20:32Есть ещё fts, и там тоже есть флаг FTS_NOSTAT, чтобы не делать stat при проходе по иерархии.

snizovtsev
Я использую fzf — find и grep/ag в одном флаконе с интеграцией в vim и кучей плюшек. Тоже написано на Go и работает очень быстро.