
Наиболее распространённый способ обеспечить надежное хранение данных — это периодически создавать их резервные копии. Современные сервисы удаленного резервного копирования позволяют хранить резервные копии на облачном сервере и иметь к ним доступ из любой точки планеты.
Передача данных на расстояния в тысячи километров занимает несколько сотен миллисекунд, а часть пакетов просто не доходит до адресата — теряется по пути. Задержки и потери пакетов губительно сказываются на производительности транспортного протокола TCP, который обычно используется в сети Интернет. К примеру, вы находитесь в Москве и хотите создать резервную копию файла размером 3ГБ. Передача этого файла на сервер, который находится в пределах города, займет 10-15 минут. Теперь, если вы захотите восстановить этот файл, находясь вдали от дома, скажем в Китае, передача этого же файла по сети с задержкой порядка сотен миллисекунд займет уже несколько часов.

В этой статье мы рассмотрим способы оптимизации передачи резервных копий в сети интернет и расскажем о концепции протокола удаленного резервного копирования, который позволит получить прирост производительности при работе в сетях с большими задержками и потерями пакетов. Данная статья основана на исследованиях, выполненных в рамках магистерской работы студента Академического университета РАН под руководством инженеров компании Acronis.
Давайте рассмотрим существующие способы решения нашей проблемы. Во-первых, это использование сетей передачи и дистрибуции контента (CDN). При этом данные размещаются на нескольких территориально распределенных серверах, что сокращает сетевои? маршрут от сервера к клиенту и делает процедуру обмена данными более быстрои?. Однако при создании резервных копий основной поток данных идет от клиента к серверу. Кроме того, существуют законодательные и корпоративные ограничения на физическое местоположение данных.
Следующий подход — это использование WAN оптимизаторов. WAN оптимизаторы – чаще всего аппаратные решения, которые устраняют или ослабляют основные причины низкои? эффективности работы приложении? в глобальнои? сети. Для этого они используют такие механизмы, как компрессия данных, кеширование и оптимизация работы прикладных протоколов. Существующие решения подобного рода в большинстве случаев требуют дополнительного аппаратного обеспечения, не учитывают мобильность клиента, а также не заточены для работы с прикладными протоколами удаленного резервного копирования.
Таким образом, существующие методы, работающие на уровне транспортных протоколов и ниже, не подходят для нашей задачи. Оптимальным решением может стать разработка прикладного протокола удаленного резервного копирования, который сможет учитывать особенности передачи данных по сети. Разработкой именно такого прикладного протокола мы и займемся.
Любой прикладной протокол пользуется услугами транспортного уровня для доставки данных, поэтому целесообразно начать с выбора наиболее подходящего транспортного протокола. Давайте для начала разберемся с причинами низкой производительности транспортного протокола TCP. Передача данных в этом протоколе управляется механизмом скользящего окна. Окно имеет принципиальное значение: оно определяет число сегментов, которые могут быть посланы без получения подтверждения. Регулирование величины этого окна имеет двоякую цель: максимально полно использовать пропускную способность соединения с однои? стороны и не допустить перегрузок сети – с другои?. Таким образом, можно сделать вывод о том, что причинои? недогрузки канала при наличии задержек и потерь является неоптимальное управление размером скользящего окна передатчика. Механизмы управления окном перегрузок TCP достаточно сложны, а детали их различаются для разных версии? протокола. Совершенствование управления окном TCP является областью активных исследовании?. Большинство предлагаемых расширении? TCP (Scalabale TCP, High Speed TCP, Fast TCP и т.д.) пытаются сделать управление окном менее консервативным с целью повышения производительности приложении?. Однако их существенный минус состоит в том, что они имеют реализацию на ограниченном числе платформ, а также требуют модификации ядра операционной системы клиента и сервера.
Рассматривая транспортные протоколы, которые могли бы показать хорошую производительность в сетях с задержками и потерями пакетов, особенное внимание следует уделить протоколу UDT. Протокол UDT ? это основанныи? на UDP протокол передачи данных для высокоскоростных сетеи?. Функциональные возможности протокола UDT аналогичны протоколу TCP: является дуплексным протоколом передачи потока данных с предварительной установкои? соединения, гарантирует доставку и предоставляет механизмы управления потоком. Большим плюсом протокола является его работа на уровне приложении?, что избавляет от необходимости внедрения изменении? в ядро операционной системы.
Для сравнения производительности TCP и UDT мы собрали тестовый стенд, который состоял из клиента, сервера и эмулятора сети. В задачи клиента и сервера входит нагрузка сети непрерывным трафиком с заданными параметрами (для этого мы использовали утилиту iperf). Эмулятор сети позволяет изменять необходимые характеристики сети между клиентом и сервером (утилита tc из пакета iproute2).
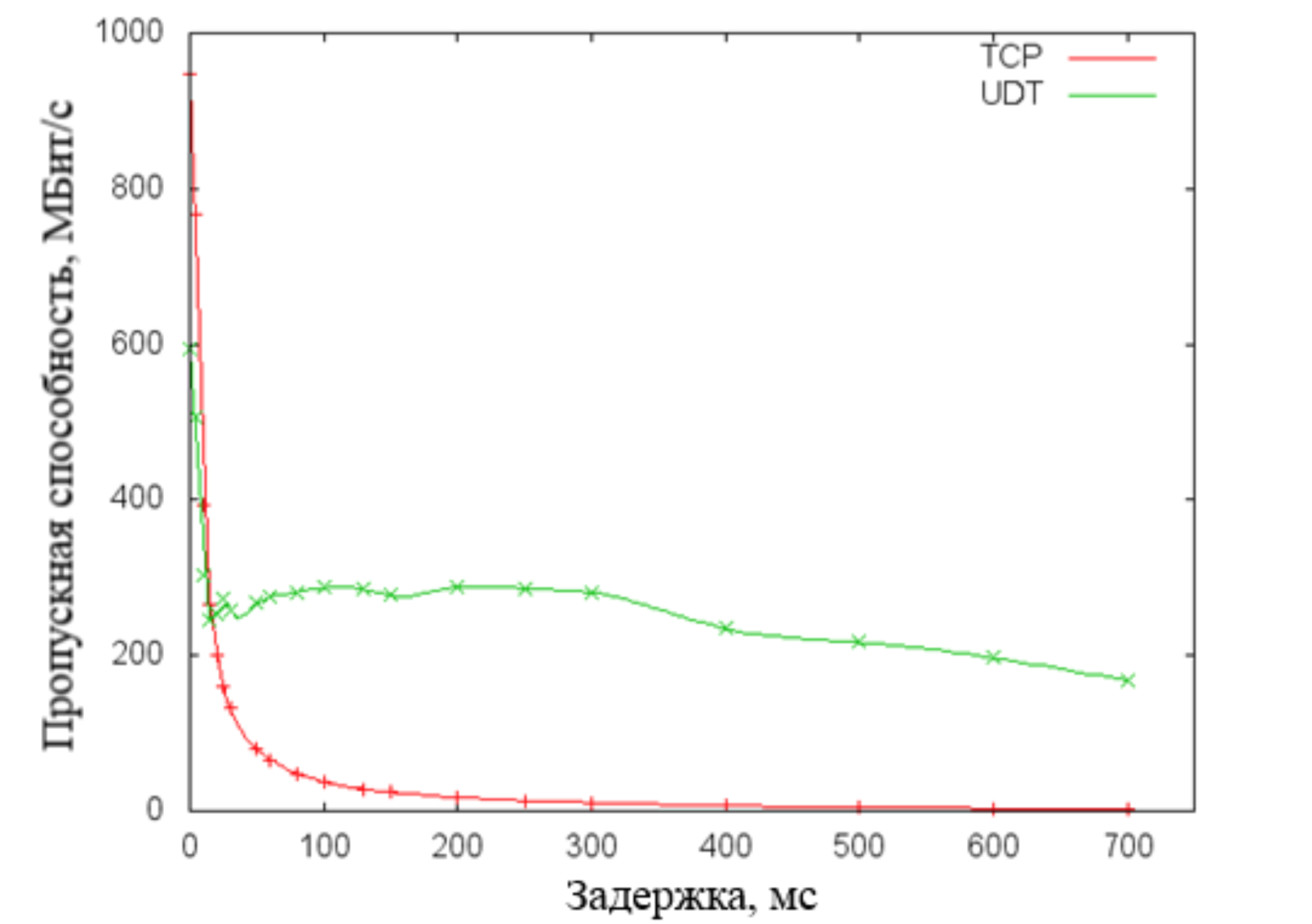
На рисунке ниже изображен график, на котором видно, что производительность протокола UDT гораздо медленнее падает с увеличением задержек в сети передачи. Однако следует отметить тот факт, что многие проваи?деры сети Интернет зачастую ограничивают UDP трафик при балансировке нагрузок на сетевое оборудование. Таким образом, в сети Интернет протокол UDT (реализован поверх UDP) рискует лишиться всех своих преимуществ. Именно поэтому данныи? протокол не является эффективным и универсальным решением нашеи? задачи.
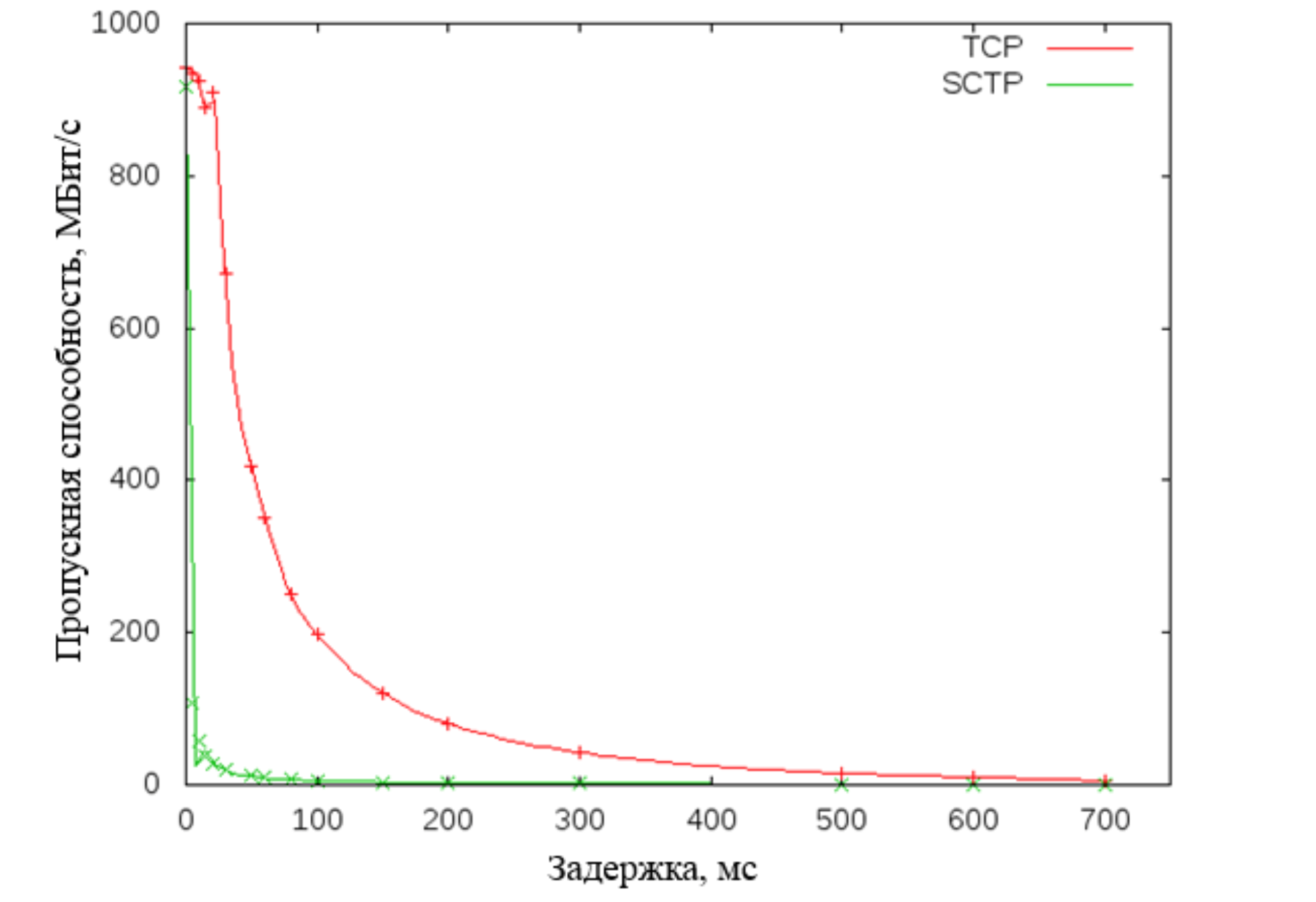
Далее мы рассмотрели транспортный протокол SCTP. Этот протокол использует TCP-подобные алгоритмы изменения скользящего окна, но имеет ряд дополнительных преимуществ: улучшенная система контроля ошибок, многопоточность, поиск пути с мониторингом. Однако испытания на стенде показали его низкую производительность при работе в сетях с задержками.
В итоге в качестве транспорта мы решили выбрать протокол TCP с применением ряда оптимизаций на прикладном уровне. Один из возможных способов оптимизации производительности TCP протокола при работе в сетях с задержками и потерями — это подбор оптимального размера окна (рисунки а, б)

Подход с автоматической настрои?кой размера окна на уровне ядра ОС является весьма эффективным и поэтому встроен в большинство современных ОС. Однако это не позволяет добиться полнои? утилизации канала в сетях с задержками, что подтверждают проведенные испытания на тестовом стенде. Объясняется это тем, что автоматическая настрои?ка размера окна происходит в строго ограниченном интервале, которыи? определен в конфигурации ОС. Таким образом, в канале с большои? емкостью окно не достигает своего оптимального размера.
Второй способ оптимизации — это создание нескольких параллельных соединении? (рисунок в). Пусть W ? это размер окна одиночного соединения, которыи? позволит утилизировать всю доступную пропускную способность P. Пропускная способность поровну делится между всеми активными TCP соединениями. Пусть их будет N, значит доступная пропускная способность для каждого параллельного соединения — P / N и, соответственно, оптимальныи? размер окна ? W / N (т.к. W = P * RTT). Значит, можно подобрать такое N, что фиксированный размер окна каждого параллельного соединения станет оптимальным для его пропускной способности. Тогда каждое соединение будет полностью утилизировать выделенную ему пропускную способность. Это в итоге приведет к росту производительности всеи? системы в целом.
Создание нескольких соединений также уменьшает негативное влияние потерь пакетов на производительность транспорта. При обнаружении потери пакета TCP протокол мультипликативно уменьшает размер окна. Потеря пакета в одном из соединении? приведет к уменьшению только его собственного окна (W / N), а не окна W в случае одного соединения. В итоге система сможет быстрее восстановить максимальное значение пропускнои? способности.
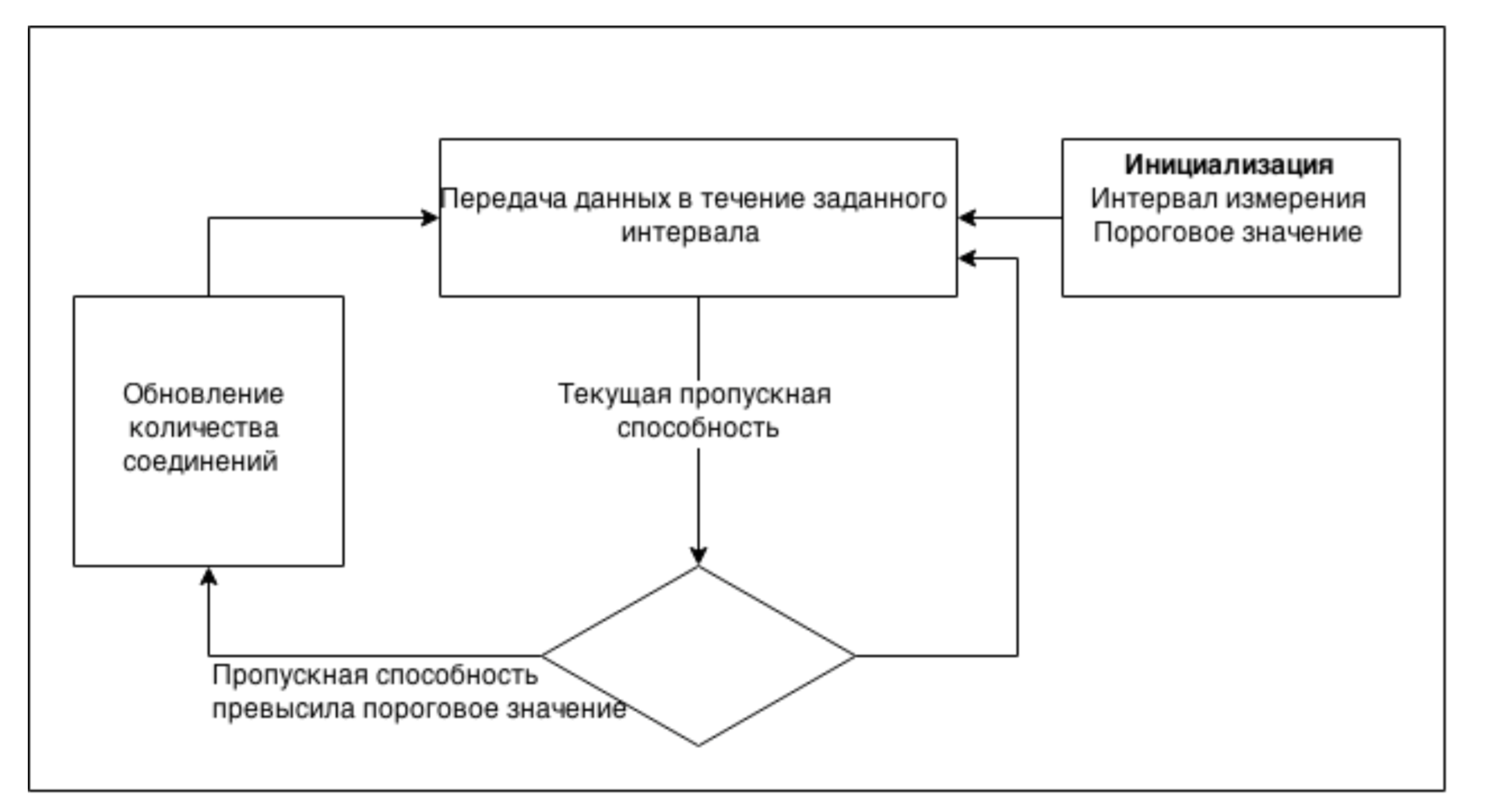
Главная проблема данного подхода состоит в оптимальном выборе количества соединении?: недостаточное количество недогрузит сеть, а переизбыток может вызвать перегрузки. Основнои? задачеи? нашего прикладного протокола является передача больших объемов данных. Это дает возможность использовать информацию о передаче этих данных для оценки текущеи? пропускнои? способности канала. Поэтому для определения оптимального числа соединении? было решено использовать следующии? подход: число активных параллельных соединении? определяется динамически и адаптируется под текущее состояние сети. Изначально система инициализируется интервалом измерения пропускнои? способности, а также пороговым значением. Далее происходит передача данных параллельно по всем активным соединениям. Каждыи? интервал измерения происходит оценка пропускнои? способности на основе переданных данных. Текущее значение сравнивается с максимальным и на основании порогового значения принимается решение об аддитивном увеличении или уменьшении числа соединении?. Затем происходит обновление максимального значения и процесс повторяется заново. Таким образом, число соединении? постепенно установится в области оптимального значения, что позволит добиться максимальной утилизации канала.
Теперь давайте представим, что вы хотите создать резервную копию операционной системы вашего рабочего компьютера. Логично сделать вывод о том, что сервер хранения с большой долей вероятности уже имеет какие-то отдельные блоки ваших данных, которые попали туда от других клиентов с такой же операционной системой. Очевидно, что сокращение количества передаваемых данных может послужить отличной оптимизацией прикладного протокола резервного копирования. Для этого в наш протокол мы добавили поддержку механизма дедупликации данных. Его суть состоит следующем: делим данные клиента на маленькие сегменты (наш протокол предоставляет лишь интерфейс для отправки готовых сегментов, методы эффективного разбиения данных являются большой отдельной темой); вычисляем хеш значение каждого сегмента и отправляем запрос его наличия на сервер; передаем по сети только уникальные сегменты.
Подведем небольшой итог и кратко опишем модель взаимодействия клиента и сервера, которую реализует наш прикладной протокол. Клиентская часть протокола предоставляет пользователю POSIX-подобныи? интерфеи?с взаимодействия с фаи?лами на сервере. Процедура удаленного резервного копирования начинается с открытия необходимого фаи?ла на сервере. При этом клиент инициирует запрос начала сессии, в котором указывает название и атрибуты открытия фаи?ла, а также желаемые параметры сессии. Сервер создает все необходимые ресурсы для обработки запросов клиента и отвечает сообщением, в котором указывает результат запроса и параметры установленной сессии (идентификатор сессии, размер блока дедупликации, тип хеш функции).
После создания сессии клиент начинает запись блоков данных в соответствующий фаи?л. Для каждого блока клиент вычисляет значение заданнои? хеш-функции и отправляет серверу запрос на наличие блока. Получив данныи? запрос, сервер проверяет наличие блока в собственном кэше дедупликации:
Для того, чтобы гарантировать запись каждого блока данных в область хранения, на прикладном уровне реализован асинхронныи? механизм подтверждения каждого блока. Сессия заканчивается закрытием фаи?ла и отправкои? на сервер запроса завершения сессии. Сервер отвечает сообщением, в котором возвращает информацию об успешности проведеннои? операции. Отметим также, что в задачи клиента входит наблюдение и контроль локальных ресурсов памяти, а также контроль перегрузок сервера (на основании полученных подтверждений).
Для того, чтобы проверить характеристики полученного решения мы приступили к реализации прототипов клиента и сервера. Архитектура сетевого слоя клиента и сервера основана на событиях, которые обрабатываются в одном потоке (смотрите рисунок).
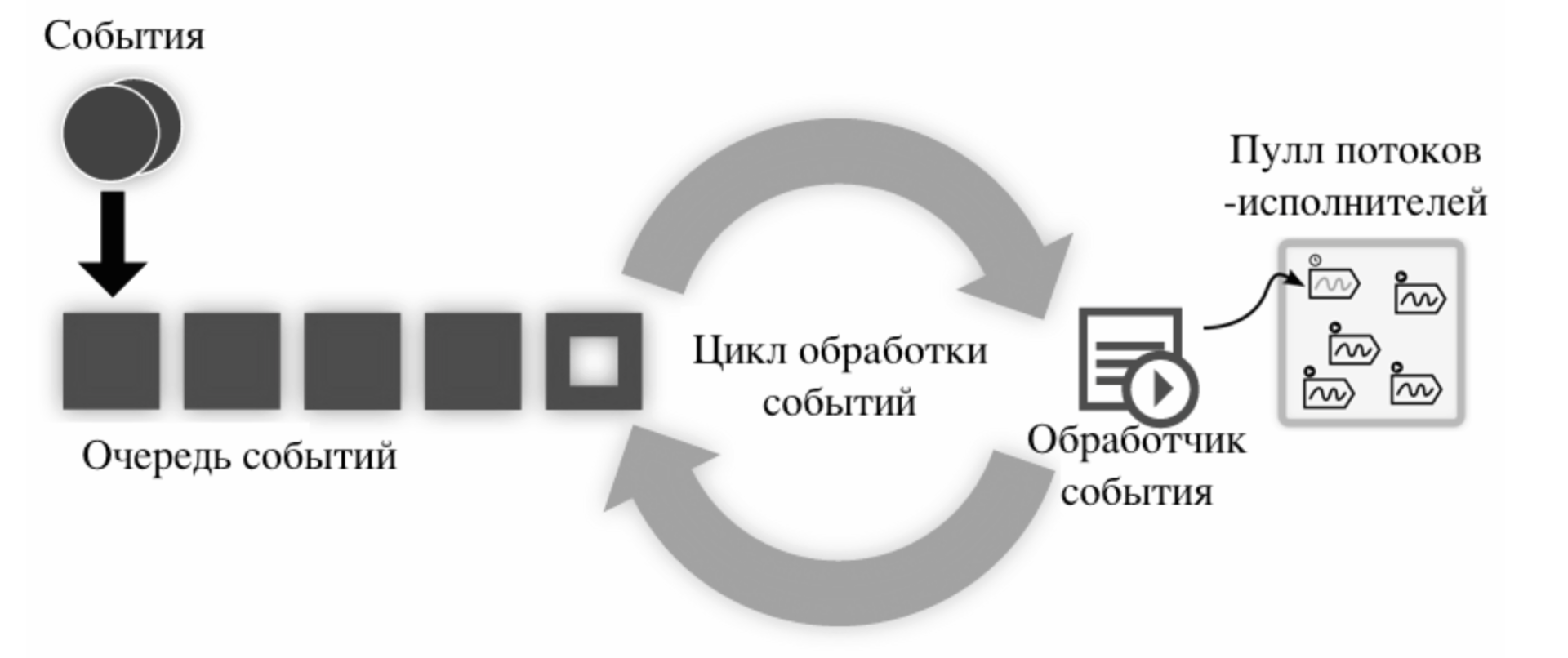
Для взаимодействия с сетью используются асинхронные неблокирующие механизмы ввода-вывода. Основои? архитектуры является главныи? цикл обработки, которыи? последовательно обслуживает очередь событии? (прием/передача данных, обработка нового соединения и.т.д). При регистрации события задается обработчик, которыи? должен быть вызван при наступлении события. Чтобы не блокировать цикл обработки, обработчик делегирует пулу потоков все трудоемкие задачи. Для реализации этой архитектуры была выбрана кроссплатформенная библиотека libevent.
Серверная логика также включает в себя:
На стороне клиента дополнительно присутствуют:
Для проверки производительности полученнои? реализации было проведено тестирование на стенде. Для каждого значения задержки производилась непрерывная передача случайных блоков данных размером 8 КБаи?т в течение 1 минуты. Встроенная в протокол дедупликация была отключена.
На этом графике мы видим зависимость пропускнои? способности от задержек для разных протоколов удаленного резервного копирования. «Было» — это протокол с использованием одного TCP соединения. «Стало» — это протокол с динамическим управлением количеством TCP соединений. Цифрами обозначено число активных соединении?.
В данной статье мы попытались найти подходы и механизмы для борьбы с проблемой низкой производительности протокола удаленного резервного копирования в сетях с большими задержками и потерями. Динамическая оптимизация числа соединении?, реализованная на клиенте, позволяет получить существенный прирост пропускнои? способности при больших задержках в сети. Реализованный механизм дедупликации позволяет сократить объем передаваемого трафика, а значит улучшить общую производительность системы. Однако для полного анализа эффективности дедупликации, требуется произвести тестирование с использованием больших объемов реальных данных и сложных алгоритмов кеширования не сервере, что выходит за рамки даннои? статьи и магистерского исследования.
Передача данных на расстояния в тысячи километров занимает несколько сотен миллисекунд, а часть пакетов просто не доходит до адресата — теряется по пути. Задержки и потери пакетов губительно сказываются на производительности транспортного протокола TCP, который обычно используется в сети Интернет. К примеру, вы находитесь в Москве и хотите создать резервную копию файла размером 3ГБ. Передача этого файла на сервер, который находится в пределах города, займет 10-15 минут. Теперь, если вы захотите восстановить этот файл, находясь вдали от дома, скажем в Китае, передача этого же файла по сети с задержкой порядка сотен миллисекунд займет уже несколько часов.
В этой статье мы рассмотрим способы оптимизации передачи резервных копий в сети интернет и расскажем о концепции протокола удаленного резервного копирования, который позволит получить прирост производительности при работе в сетях с большими задержками и потерями пакетов. Данная статья основана на исследованиях, выполненных в рамках магистерской работы студента Академического университета РАН под руководством инженеров компании Acronis.
Давайте рассмотрим существующие способы решения нашей проблемы. Во-первых, это использование сетей передачи и дистрибуции контента (CDN). При этом данные размещаются на нескольких территориально распределенных серверах, что сокращает сетевои? маршрут от сервера к клиенту и делает процедуру обмена данными более быстрои?. Однако при создании резервных копий основной поток данных идет от клиента к серверу. Кроме того, существуют законодательные и корпоративные ограничения на физическое местоположение данных.
Следующий подход — это использование WAN оптимизаторов. WAN оптимизаторы – чаще всего аппаратные решения, которые устраняют или ослабляют основные причины низкои? эффективности работы приложении? в глобальнои? сети. Для этого они используют такие механизмы, как компрессия данных, кеширование и оптимизация работы прикладных протоколов. Существующие решения подобного рода в большинстве случаев требуют дополнительного аппаратного обеспечения, не учитывают мобильность клиента, а также не заточены для работы с прикладными протоколами удаленного резервного копирования.
Таким образом, существующие методы, работающие на уровне транспортных протоколов и ниже, не подходят для нашей задачи. Оптимальным решением может стать разработка прикладного протокола удаленного резервного копирования, который сможет учитывать особенности передачи данных по сети. Разработкой именно такого прикладного протокола мы и займемся.
Любой прикладной протокол пользуется услугами транспортного уровня для доставки данных, поэтому целесообразно начать с выбора наиболее подходящего транспортного протокола. Давайте для начала разберемся с причинами низкой производительности транспортного протокола TCP. Передача данных в этом протоколе управляется механизмом скользящего окна. Окно имеет принципиальное значение: оно определяет число сегментов, которые могут быть посланы без получения подтверждения. Регулирование величины этого окна имеет двоякую цель: максимально полно использовать пропускную способность соединения с однои? стороны и не допустить перегрузок сети – с другои?. Таким образом, можно сделать вывод о том, что причинои? недогрузки канала при наличии задержек и потерь является неоптимальное управление размером скользящего окна передатчика. Механизмы управления окном перегрузок TCP достаточно сложны, а детали их различаются для разных версии? протокола. Совершенствование управления окном TCP является областью активных исследовании?. Большинство предлагаемых расширении? TCP (Scalabale TCP, High Speed TCP, Fast TCP и т.д.) пытаются сделать управление окном менее консервативным с целью повышения производительности приложении?. Однако их существенный минус состоит в том, что они имеют реализацию на ограниченном числе платформ, а также требуют модификации ядра операционной системы клиента и сервера.
Рассматривая транспортные протоколы, которые могли бы показать хорошую производительность в сетях с задержками и потерями пакетов, особенное внимание следует уделить протоколу UDT. Протокол UDT ? это основанныи? на UDP протокол передачи данных для высокоскоростных сетеи?. Функциональные возможности протокола UDT аналогичны протоколу TCP: является дуплексным протоколом передачи потока данных с предварительной установкои? соединения, гарантирует доставку и предоставляет механизмы управления потоком. Большим плюсом протокола является его работа на уровне приложении?, что избавляет от необходимости внедрения изменении? в ядро операционной системы.
Для сравнения производительности TCP и UDT мы собрали тестовый стенд, который состоял из клиента, сервера и эмулятора сети. В задачи клиента и сервера входит нагрузка сети непрерывным трафиком с заданными параметрами (для этого мы использовали утилиту iperf). Эмулятор сети позволяет изменять необходимые характеристики сети между клиентом и сервером (утилита tc из пакета iproute2).
На рисунке ниже изображен график, на котором видно, что производительность протокола UDT гораздо медленнее падает с увеличением задержек в сети передачи. Однако следует отметить тот факт, что многие проваи?деры сети Интернет зачастую ограничивают UDP трафик при балансировке нагрузок на сетевое оборудование. Таким образом, в сети Интернет протокол UDT (реализован поверх UDP) рискует лишиться всех своих преимуществ. Именно поэтому данныи? протокол не является эффективным и универсальным решением нашеи? задачи.
Далее мы рассмотрели транспортный протокол SCTP. Этот протокол использует TCP-подобные алгоритмы изменения скользящего окна, но имеет ряд дополнительных преимуществ: улучшенная система контроля ошибок, многопоточность, поиск пути с мониторингом. Однако испытания на стенде показали его низкую производительность при работе в сетях с задержками.
В итоге в качестве транспорта мы решили выбрать протокол TCP с применением ряда оптимизаций на прикладном уровне. Один из возможных способов оптимизации производительности TCP протокола при работе в сетях с задержками и потерями — это подбор оптимального размера окна (рисунки а, б)
Подход с автоматической настрои?кой размера окна на уровне ядра ОС является весьма эффективным и поэтому встроен в большинство современных ОС. Однако это не позволяет добиться полнои? утилизации канала в сетях с задержками, что подтверждают проведенные испытания на тестовом стенде. Объясняется это тем, что автоматическая настрои?ка размера окна происходит в строго ограниченном интервале, которыи? определен в конфигурации ОС. Таким образом, в канале с большои? емкостью окно не достигает своего оптимального размера.
Второй способ оптимизации — это создание нескольких параллельных соединении? (рисунок в). Пусть W ? это размер окна одиночного соединения, которыи? позволит утилизировать всю доступную пропускную способность P. Пропускная способность поровну делится между всеми активными TCP соединениями. Пусть их будет N, значит доступная пропускная способность для каждого параллельного соединения — P / N и, соответственно, оптимальныи? размер окна ? W / N (т.к. W = P * RTT). Значит, можно подобрать такое N, что фиксированный размер окна каждого параллельного соединения станет оптимальным для его пропускной способности. Тогда каждое соединение будет полностью утилизировать выделенную ему пропускную способность. Это в итоге приведет к росту производительности всеи? системы в целом.
Создание нескольких соединений также уменьшает негативное влияние потерь пакетов на производительность транспорта. При обнаружении потери пакета TCP протокол мультипликативно уменьшает размер окна. Потеря пакета в одном из соединении? приведет к уменьшению только его собственного окна (W / N), а не окна W в случае одного соединения. В итоге система сможет быстрее восстановить максимальное значение пропускнои? способности.
Главная проблема данного подхода состоит в оптимальном выборе количества соединении?: недостаточное количество недогрузит сеть, а переизбыток может вызвать перегрузки. Основнои? задачеи? нашего прикладного протокола является передача больших объемов данных. Это дает возможность использовать информацию о передаче этих данных для оценки текущеи? пропускнои? способности канала. Поэтому для определения оптимального числа соединении? было решено использовать следующии? подход: число активных параллельных соединении? определяется динамически и адаптируется под текущее состояние сети. Изначально система инициализируется интервалом измерения пропускнои? способности, а также пороговым значением. Далее происходит передача данных параллельно по всем активным соединениям. Каждыи? интервал измерения происходит оценка пропускнои? способности на основе переданных данных. Текущее значение сравнивается с максимальным и на основании порогового значения принимается решение об аддитивном увеличении или уменьшении числа соединении?. Затем происходит обновление максимального значения и процесс повторяется заново. Таким образом, число соединении? постепенно установится в области оптимального значения, что позволит добиться максимальной утилизации канала.
Теперь давайте представим, что вы хотите создать резервную копию операционной системы вашего рабочего компьютера. Логично сделать вывод о том, что сервер хранения с большой долей вероятности уже имеет какие-то отдельные блоки ваших данных, которые попали туда от других клиентов с такой же операционной системой. Очевидно, что сокращение количества передаваемых данных может послужить отличной оптимизацией прикладного протокола резервного копирования. Для этого в наш протокол мы добавили поддержку механизма дедупликации данных. Его суть состоит следующем: делим данные клиента на маленькие сегменты (наш протокол предоставляет лишь интерфейс для отправки готовых сегментов, методы эффективного разбиения данных являются большой отдельной темой); вычисляем хеш значение каждого сегмента и отправляем запрос его наличия на сервер; передаем по сети только уникальные сегменты.
Подведем небольшой итог и кратко опишем модель взаимодействия клиента и сервера, которую реализует наш прикладной протокол. Клиентская часть протокола предоставляет пользователю POSIX-подобныи? интерфеи?с взаимодействия с фаи?лами на сервере. Процедура удаленного резервного копирования начинается с открытия необходимого фаи?ла на сервере. При этом клиент инициирует запрос начала сессии, в котором указывает название и атрибуты открытия фаи?ла, а также желаемые параметры сессии. Сервер создает все необходимые ресурсы для обработки запросов клиента и отвечает сообщением, в котором указывает результат запроса и параметры установленной сессии (идентификатор сессии, размер блока дедупликации, тип хеш функции).
После создания сессии клиент начинает запись блоков данных в соответствующий фаи?л. Для каждого блока клиент вычисляет значение заданнои? хеш-функции и отправляет серверу запрос на наличие блока. Получив данныи? запрос, сервер проверяет наличие блока в собственном кэше дедупликации:
- Совпадение наи?дено: сервер производит запись нужного блока в область хранения и отправляет клиенту подтверждение.
- Совпадение не наи?дено: сервер отвечает сообщением, которым просит клиента начать передачу нужного блока. Получив блок, сервер отвечает подтверждением.
Для того, чтобы гарантировать запись каждого блока данных в область хранения, на прикладном уровне реализован асинхронныи? механизм подтверждения каждого блока. Сессия заканчивается закрытием фаи?ла и отправкои? на сервер запроса завершения сессии. Сервер отвечает сообщением, в котором возвращает информацию об успешности проведеннои? операции. Отметим также, что в задачи клиента входит наблюдение и контроль локальных ресурсов памяти, а также контроль перегрузок сервера (на основании полученных подтверждений).
Для того, чтобы проверить характеристики полученного решения мы приступили к реализации прототипов клиента и сервера. Архитектура сетевого слоя клиента и сервера основана на событиях, которые обрабатываются в одном потоке (смотрите рисунок).
Для взаимодействия с сетью используются асинхронные неблокирующие механизмы ввода-вывода. Основои? архитектуры является главныи? цикл обработки, которыи? последовательно обслуживает очередь событии? (прием/передача данных, обработка нового соединения и.т.д). При регистрации события задается обработчик, которыи? должен быть вызван при наступлении события. Чтобы не блокировать цикл обработки, обработчик делегирует пулу потоков все трудоемкие задачи. Для реализации этой архитектуры была выбрана кроссплатформенная библиотека libevent.
Серверная логика также включает в себя:
- Менеджер сессий, который занимается корректной установкой и завершением сессий.
- Блок дедупликации для кэширования данных и обработки запросов от клиента на существование блока.
- Менеджер данных для записи блоков в постоянное хранилище.
На стороне клиента дополнительно присутствуют:
- Оценщик текущеи? пропускнои? способности. Позволяет в заданные интервалы времени производить оценку текущеи? пропускнои? способности. Для этого он получает информацию о подтверждениях сервера и следит за состоянием буферов отправки всех соединении?.
- Оптимизатор числа соединении?. Этот блок реализует логику оптимизации числа соединении?, описанную ранее. Также данныи? блок решает задачу исключения влияния случаи?ных колебании? пропускнои? способности.
- Балансировщик исходящего трафика. Необходим для равномерного распределения данных по всем активным соединениям.
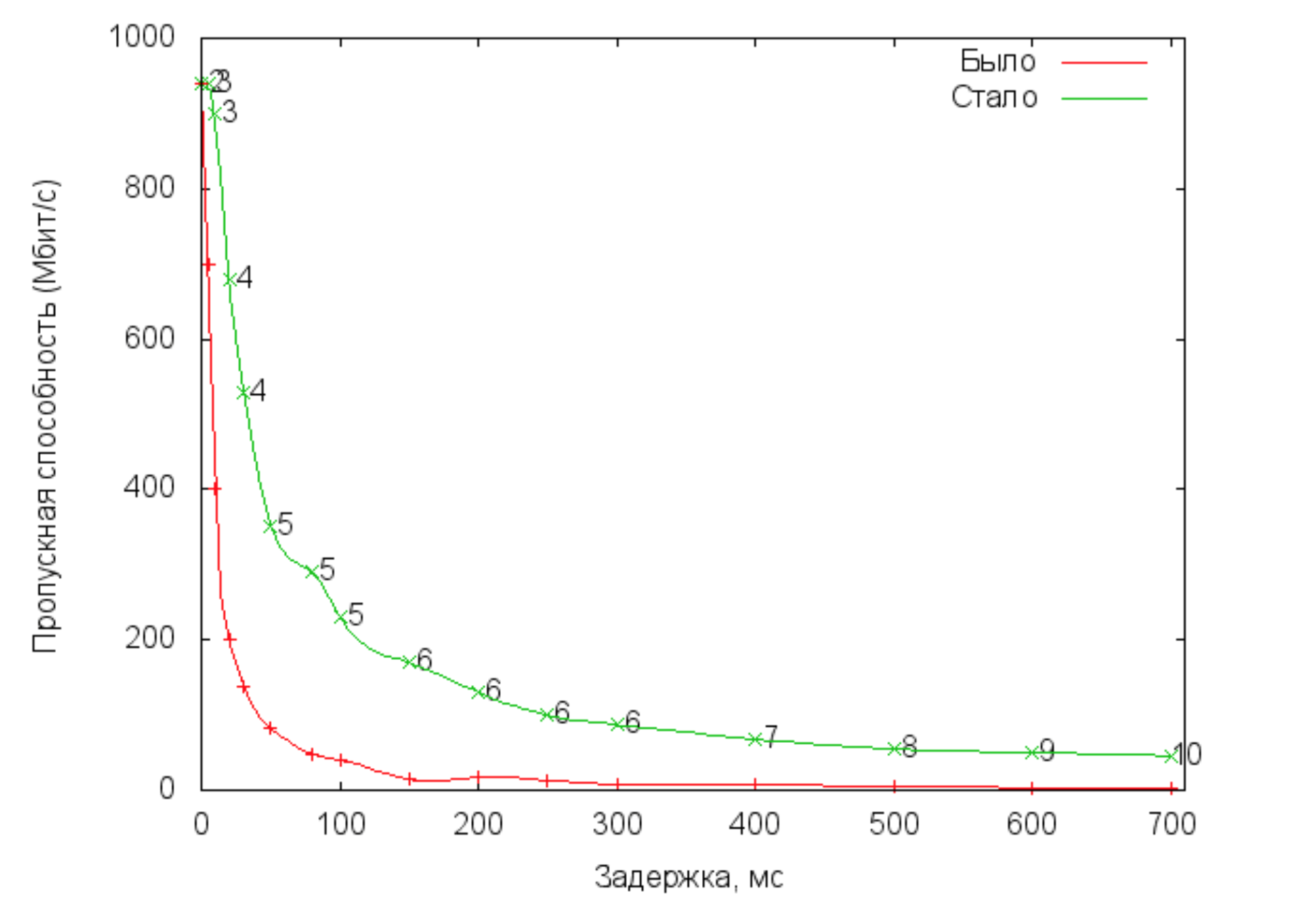
Для проверки производительности полученнои? реализации было проведено тестирование на стенде. Для каждого значения задержки производилась непрерывная передача случайных блоков данных размером 8 КБаи?т в течение 1 минуты. Встроенная в протокол дедупликация была отключена.
На этом графике мы видим зависимость пропускнои? способности от задержек для разных протоколов удаленного резервного копирования. «Было» — это протокол с использованием одного TCP соединения. «Стало» — это протокол с динамическим управлением количеством TCP соединений. Цифрами обозначено число активных соединении?.
Заключение
В данной статье мы попытались найти подходы и механизмы для борьбы с проблемой низкой производительности протокола удаленного резервного копирования в сетях с большими задержками и потерями. Динамическая оптимизация числа соединении?, реализованная на клиенте, позволяет получить существенный прирост пропускнои? способности при больших задержках в сети. Реализованный механизм дедупликации позволяет сократить объем передаваемого трафика, а значит улучшить общую производительность системы. Однако для полного анализа эффективности дедупликации, требуется произвести тестирование с использованием больших объемов реальных данных и сложных алгоритмов кеширования не сервере, что выходит за рамки даннои? статьи и магистерского исследования.
Kolyuchkin
Спасибо за статью) Идея интересная, а код можно посмотреть? А то без кода сложно оценить ценность теоретических изысканий. И меня сильно интересует и смущает эффективность режима дедубликации на практике: 1) пусть с сети мы нагрузку снимаем, но на файловую систему она и переходит (запись на диски кучи разрозненных блоков, плохо поддающихся оптимизации — либо нужна специализированная ФС); 2) как и где осуществляется индексация блоков данных, что если таблица индексации увеличится до размеров, когда ее частично засвопит ОС? Вопросов много, поэтому и тема и статья интересны — еще раз спасибо Вам)
karama
Спасибо за вопросы.
Код нельзя выложить в открытый доступ. Все описанное в статье было честно, эффективно реализовано и результаты (графики) получены для описанных в статье экспериментов. Поэтому в статье описаны не только теоритические выкладки. Теория скорее объясняет в нашем случае результаты практических экспериментов.
Другие вопросы, которые вы задали, выходят за рамки статьи. Сеть за них, так скажем, не отвечает. Но немного отвечу.
1) ФС всегда пишут сначала в память (RAM). Далее блоки, которые нужно записать на диск собираются в «пакеты» и оптимизированно (последовательно) записываются на диск. То есть запись, как правило, не по одному блоку со случайным доступом к диску. Конечно сервер может быть перегружен от данных клиентов. Тогда в действие вступает дополнительный сетевой протокол, ответственность которого — лимитировать скорость отправки данных клиентами/отказать некоторым клиентам в обслуживании/перераспределить нагрузку (например, на другой шард). Вариантов много. Цель статьи — повысить максимальную пропускную способность протокола, а дальше ее можно динамически менять в своем диапазоне.
2) Обычно индексы стараются полностью хранить в памяти. Индекс может быть распределенным (шардированным), чтобы памяти многих машин хватило для хранения индекса. Также можно использовать пространственную локальность (prefetch индекса с диска), либо временную локальность (вытеснять давно не использованные блоки из индекса) — тогда индекс становится кешом со всеми вытекающими методиками связанными с кешами.
phprus
Скажите, пожалуйста, какую реализацию UDT Вы использовали, существующую или написанную самостоятельно?
karama
На этом этапе работы мы проводили тестирование уже существующих решений, поэтому использовали готовую реализацию протокола UDT
phprus
Существующую, это какую?
Если udt.sourceforge.net, то эта реализация достаточно требовательна к CPU. Это надо учитывать, чтобы не получить искаженные результаты.
karama
Спасибо за комментарий
Даже эта реализация в первом приближении показала неплохую производительность в сетях с большими задержками. Но по причинам, описанным в статье, протокол UDT для нашей задачи не подошел. Поэтому рассмотрение других реализаций, а тем более написание собственной было не целесообразно.