

Вы знаете, что «нобелевку» по научной фантастике получил китайский автор Лю Цысинь (Liu Cixin, ???) с произведением The Three-Body Problem ( ??). На эту книгу обратили внимание Барак Обама (пруф) и Марк Цукерберг (пруф).

Ольга Браатхен по своей инициативе перевела книгу на русский (вот тут можно качнуть fb2), за что ей большое спасибо.
Еще один кандидат на «нобелевку» в 2016 — это Нил Стивенсон (написавший «Лавину» и «Криптономикон») с произведением Seveneves (качнуть на английском можно тут, жаль, что на русский никто не взялся переводить).
Разработчики компании EDISON создали программу Управления доступом к электронным документам, о чем я писал пару лет назад, а сегодня речь пойдет об SDK для внедрения поддержки электронных книг в формате FB2.
Введение
Применение информационных технологий в библиотечной сфере привело к появлению интернет-сервисов, предоставляющих читателям удаленный доступ к богатому набору художественной, научной и технической литературы. Такие сервисы выводят библиотечное дело на новый уровень. Библиотеки могут объединяться в единую сеть, формируя огромную географически распределенную базу оцифрованного контента, а предоставление библиотечных услуг в интернет расширяет целевую аудиторию и дает дополнительный доход. Ключевые пользователи также получают преимущества: не нужно тратить время на поездку в библиотеку, брать книги в личное пользование и заботиться о своевременной сдаче; возможен доступ к редкой литературе, отсутствующей в конкретном населенном пункте. Правообладатели могут получать роялти, предоставляя контент на взаимовыгодных условиях.
Особое внимание в библиотечных сервисах отводится соблюдению авторских прав и защите от копирования. На транспортном уровне используются проприетарные форматы, а программное обеспечение на стороне клиента не должно сохранять полученный контент на диске.
Основная часть контента формируется путем ручной оцифровки физических носителей с применением сканеров и последующим распознаванием текста для обеспечения возможности поиска, но это не единственный источник. Существует множество цифровых форматов, предназначенных для хранения электронных книг, и уже оцифрованных книг в данных форматах тоже не мало. Соответственно, нужна поддержка различных электронных форматов в библиотечных сервисах. Расскажу о разработке SDK (инструментария разработчика) для внедрения поддержки электронных книг в формате Fiction Book в один из сервисов.
Задача
Сервис доставки контента предоставляет пользователям постраничный доступ к литературе в удаленном хранилище. Доступ к каждой странице фиксируется и тарифицируется. В сервисе реализован полнотекстовый поиск, результаты которого подсвечиваются полупрозрачными прямоугольниками. Трафик между сервером и клиентом защищен и представляет собой проприетарный бинарный формат.
Перед программистами EDISON стояла задача создать SDK, предоставляющую конечному разработчику набор готовых к использованию функций, способствующих упрощению процедуры внедрения поддержки электронных книг в формате FB2, а также использованию общей кодовой базы при построении серверной и клиентской части решения.
Исходя из функциональных возможностей сервиса, требования к набору функций SDK были определены заранее:
- получение библиографической информации;
- получение количества страниц электронной книги;
- получение результатов полнотекстового поиска со ссылками на соответствующие страницы;
- получение координат прямоугольников для подсветки результатов полнотекстового поиска;
- получение контента произвольной страницы в бинарном формате и рендеринг страницы.
Реализация и технологии: С++ / Qt
Решение
Электронная книга в FB2 — одностраничный документ. В формате не предусмотрено информации как должен выглядеть документ. В первую очередь, предстояло решить проблему с разбиением FB2-документа на страницы, не дублируя при этом содержимое документа. В результате был спроектирован формат индексного файла, который хранит мета-данные об исходном FB2-документе, полученные в результате парсинга оригинального документа, рендеринга и разбиения документа на страницы.
Индексный файл содержит местонахождение фрагментов XML документа в виде смещения от начала документа и длины фрагмента в количестве знаков, а также XML-префикс.
Структура индексного файла включает три раздела:
- description — фрагмент с описанием документа;
- binary — фрагменты с картинками в оригинальном документе;
- page — фрагменты документа, где начинаются и заканчиваются страницы, полученные в результате рендеринга с заданными параметрами размера страницы, отступов и шрифта.
Информация о местонахождении фрагмента XML-документа позволяет вычитать нужный кусок информации из оригинального документа без необходимости его парсинга, XML-префикс позволяет построить миниатюрный XML-документ, содержащий разметку только нужной страницы, распарсить ее и тут же отрендерить нужную страницу по запросу пользователя.
Пример индексного файла с разбиением документа на страницы.
<document>
<description>
<fragment>
<offset>418</offset>
<length>5230</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink">]]></prefix>
</fragment>
</description>
<binary id="cover.jpg" >
<fragment>
<offset>43034</offset>
<length>48151</length>
</fragment>
</binary>
<page number="1" >
<fragment>
<offset>5657</offset>
<length>1779</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body>]]></prefix>
</fragment>
</page>
<page number="2" >
<fragment>
<offset>7436</offset>
<length>2366</length>
<prefix><![CDATA[<FictionBook xmlns="http://www.gribuser.ru/xml/fictionbook/2.0" xmlns:xlink="http://www.w3.org/1999/xlink"><body><section><section><p>]]></prefix>
</fragment>
</page>
</document>Когда появилось представление об алгоритме разбиения документа на страницы, мы приступили к его реализации. Для формирования индекса был выбран метод потокового парсинга оригинального документа с использованием стандартных классов библиотеки Qt, благодаря возможности последовательного чтения XML-файла и сохранения информации о смещении в файле в количестве знаков, посредством метода QXmlStreamReader::characterOffset.
В процессе парсинга FB2-документа по мере продвижения от тега к тегу, параграфы документа разбираются на наборы слов, которые затем снова собираются в строки. В соответствии с файлом настроек каждой строке задается максимальная ширина с учетом заданной ширины полей страницы и отступа для параграфов. Для строк также задается межстрочный интервал, указанный в файле настроек. В зависимости от тегов XML-документа задаются параметры шрифта, размер, начертание и выравнивание. Для заголовков и подзаголовков задается выравнивание по центру, для эпиграфов — выравнивание по правому краю, по умолчанию — выравнивание по левому краю. По мере добавления слов в строку длина строки пересчитывается путем сложения длины всех добавленных слов. Если длина строки превышает заданную ширину страницы, то строка добавляется к объекту страницы; слово, которое не влезло в строку, добавляется в очередную строку. По мере добавления строк к странице, пересчитывается высота всех строк с учетом межстрочного интервала. При внедрении картинок за высоту строки пришлось считать максимальную высоту объекта, добавленного к строке. Если высота всех добавленных строк превышает заданную высоту страницы с учетом отступов, в индексный файл добавляется очередной фрагмент. Описанный алгоритм применяется как при разбиении FB2-документа на страницы, так и при произвольном доступе к странице по средством использования индексного файла.
Так как метод QXmlStreamReader::characterOffset возвращает смещение в количестве знаков, а не в байтах, то при произвольном доступе к страницам документа пришлось вычитывать начало оригинального файла, и только затем вычитывать интересующую часть документа, так как документ может содержать кириллицу и латиницу, и использование одного лишь смещения по файлу в байтах, используя метод seek, неизбежно привело бы к ошибкам.
QString Document::documentFragment(uint offset, uint length)
{
QString fragment;
QFile file(m_fileName);
if (!file.open(QIODevice::ReadOnly))
{
m_error = IOError;
return fragment;
}
QTextStream fileStream(&file);
fileStream.setCodec("UTF-8");
fileStream.setAutoDetectUnicode(true);
fileStream.seek(0);
fileStream.read(offset);
fragment = fileStream.read(length);
file.close();
if ((uint) fragment.size() < length)
{
m_error = IOError;
fragment = QString();
return fragment;
}
return fragment;
}Несмотря на это, потери в производительности нет, доступ к последней странице документа осуществляется так же быстро, как и к первой странице, и занимает менее секунды. Дело в том, что средний объем книги без картинок в формате FB2 редко превышает 10 Мб.
Разбиение 7 Мб файла на 998 страниц и подготовка индекса занимают около 10 секунд. Разбиение 9 Мб файла на 1576 страниц занимает около 15 секунд. В среднем за одну секунду рендерится порядка 100 страниц. При наличии индекса документ открывается за 50 миллисекунд.
Далее предстояло решить задачу полнотекстового поиска с привязкой к страницам документа. И тут для обеспечения быстродействия всё-таки пришлось дублировать содержимое документа, но уже без XML-разметки, а в виде обычного текстового файла. В текстовый индекс вставляются маркеры начала и окончания страницы в виде нулевого байта. Для привязки результатов поиска к страницам и хранения координат прямоугольников, понадобилось организовать два вспомогательных индекса в бинарном формате. Вспомогательный индекс для привязки результатов поиска к страницам хранит номер страницы, порядковый номер начального и конечного байта маркера страницы в текстовом индексе.
Полнотекстовый поиск осуществлялся с помощью библиотеки, предоставленной заказчиком, которая возвращает все словоформы по заданному слову. Поисковый запрос разбивается на набор слов, затем по каждому слову находятся все словоформы, затем по сформированному массиву найденных словоформ осуществляется поиск в текстовом индексе. С помощью вспомогательного индекса и маркеров начала/окончания страницы в текстовом индексе определяются номера страниц, к которым принадлежат результаты поиска. Вспомогательный индекс с координатами прямоугольников формируется лишь при запросе страницы. На каждую страницу формируется отдельный индексный файл. В процессе получения координат прямоугольников задействован все тот же алгоритм разбиения оригинального документа на страницы благодаря разбиению строк на слова и вычислению границ каждого слова, а индекс служит для того, чтобы не вызывать этот алгоритм повторно при переходе на ту же страницу.
Создание индексов для полнотекстового поиска занимает уже около минуты на документах объемом около 10 Мб. Поиск же, при наличии индексов, работает около одной секунды на документе с 1576 страницами.
Очередным сюрпризом было отображение полупрозрачных прямоугольников над найденными фрагментами текста. Так как изначально математика по расчету границ слов была в пикселях, это вызвало неточности в несколько пикселей при масштабировании страниц документа. Решение было найдено: пришлось всего лишь перевести все вычисления в дюймы с учетом DPI-устройства вывода, используя при этом значения с плавающей точкой вместо целочисленных, исправив при этом существенную часть кода.
m_dpiX = (qreal) QApplication::desktop()->physicalDpiX();
m_dpiY = (qreal) QApplication::desktop()->physicalDpiY();
QFontMetricsF fm(m_font);
m_rect = fm.boundingRect(m_text);
m_textDescent = fm.descent() / m_dpiY;
qreal width = m_rect.width() / m_dpiX;
qreal height = m_rect.height() / m_dpiY;
m_rect.setSize(QSizeF(width, height)); На финишной прямой оставалось решить вопрос с сериализацией представления страницы, включая набор прямоугольников, в бинарный формат и обратного чтения из него для передачи содержимого страницы на клиента и последующего рендеринга посредством все той же SDK. Тут оказалось все достаточно просто: на помощь пришел стандартный класс библиотеки QT, QDataStream.
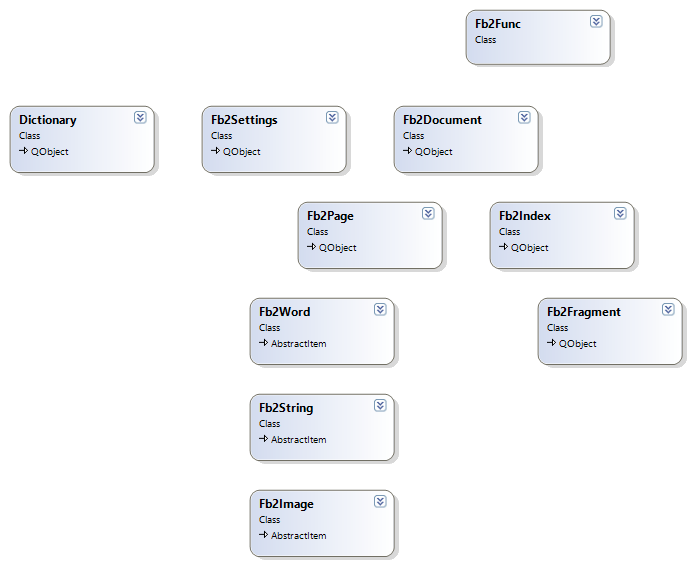
В процессе декомпозиции при решении задачи были выделены следующие классы.
- Fb2Document — документ FB2, основной класс, инкапсулирует логику парсинга документа, разбиения на страницы, формирования индекса, предоставления доступа к произвольной странице с использованием сформированного индекса, а также полнотекстовый поиск.
- Fb2Page — страница FB2-документа, инкапсулирует логику заполнения страницы набором строк документа и рендеринга страницы, определение признака окончания страницы. Предоставляет интерфейс для задания размера страницы в дюймах по ширине и высоте, а также отступы от краев страницы.
- Fb2Word — слово, инкапсулирует логику вычисления границ слова в дюймах на канве документа, в соответствии с заданными параметрами шрифта, сериализацию слов страницы документа в бинарный формат, чтение слов из бинарного формата.
- Fb2String — строка из набора слов (Fb2Word), инкапсулирует логику заполнения строк списком слов, определение признака окончания строки, выравнивание строки по левому, правому краю и по центру, учет межстрочного интервала заданного в файле настроек, сериалиазацию строк страницы документа в бинарный формат, чтение из строк из бинарного формата.
- Fb2Image — изображение, инкапсулирует логику рендеринга картинок документа, сериализацию картинок в бинарный формат, чтение картинок из бинарного формата.
- Fb2Index — индекс, инкапсулирует логику формирования индексного файла и чтение из него.
- Fb2Fragment — фрагмент FB2-документа, представляет собой основную структуру индексного файла.
- Fb2Settings — файл настроек, инкапсулирует логику работы с файлом настроек чтение/запись.
- Fb2Func — класс обертка, предоставляет набор функций SDK в соответствии с интерфейсом, заданным при постановке задачи.
- Dictionary — класс обертка над морфологическим словарем.
Методы всех классов SDK были покрыты модульными тестами, чтобы гарантировать корректность разбиения FB2-документа на страницы, а также что пользователь в клиентской программе увидит ровно ту же картинку при запросе страницы, что будет изначально отрендерена на стороне сервера при подготовке индексного файла.
В результате конечная цель была достигнута. Преимущество разработки SDK по сравнению с коробочным решением заключается в гибкости. Все самое сложное скрыто за вызовом простых функций, а разработчик, использующий SDK может самостоятельно принимать решения, как ее использовать: например, строить ли индексы заранее для обеспечения быстродействия функций системы и более комфортной работы пользователей или строить индексы по первому обращению к документу и первому поисковому запросу и удалять их при редком использовании для экономии дискового пространства.
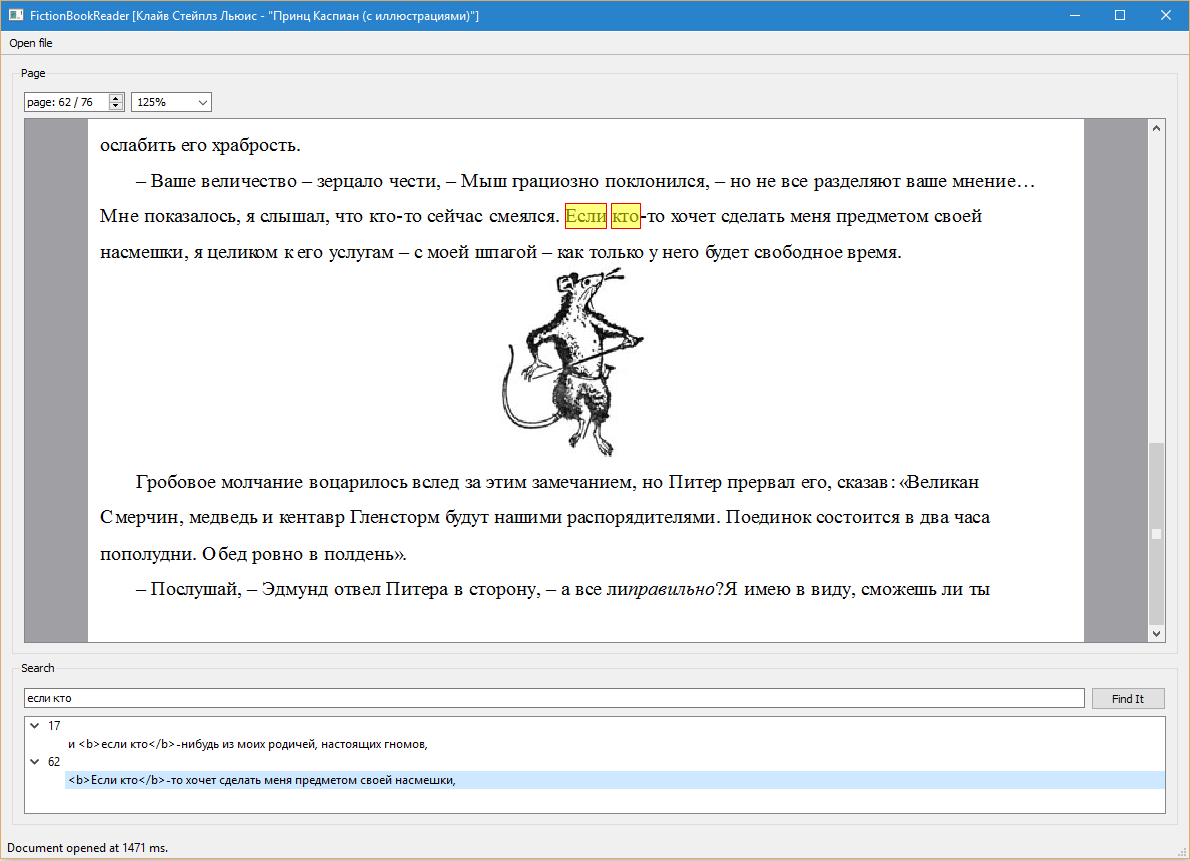
Для демонстрации работоспособности SDK заказчику, на ее основе было реализовано два Desktop-приложения. FictionBookReader предоставляет функционал примитивного ридера FB2-документов с возможностью постраничного просмотра и полнотекстового поиска с подсветкой результатов поиска.
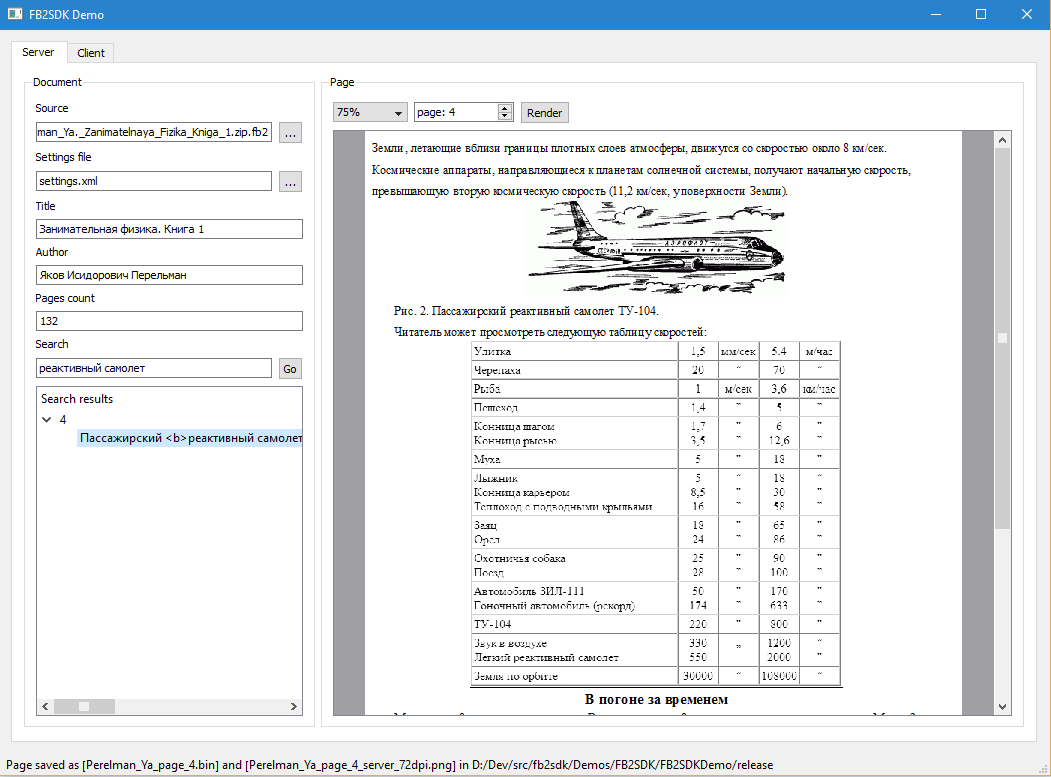
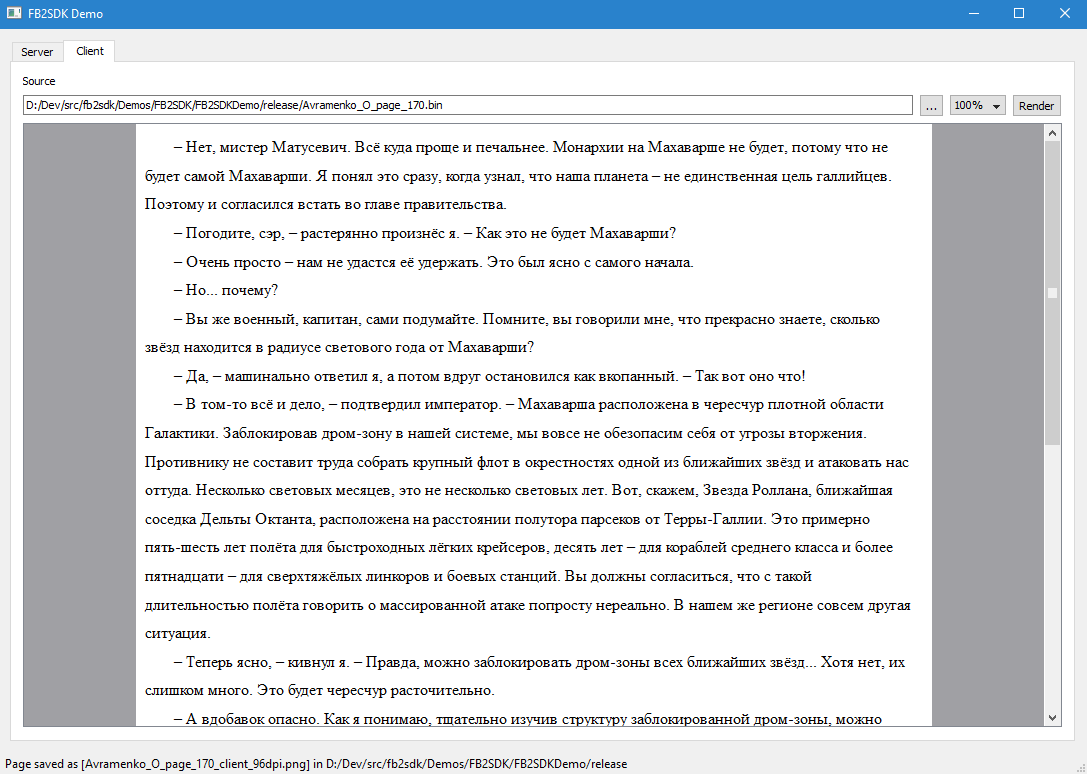
FB2SDK Demo наглядно показывает функционал серверной и клиентской части SDK. Функционал серверной части выделен во вкладку Server, которая демонстрирует парсинг документа и формирование многостраничного индекса, а также формирование файлов с прямоугольниками и полнотекстового индекса. Функционал клиентской части выделен во вкладку Client, которая демонстрирует рендеринг страницы документа по сформированному бинарному файлу.

Больше проектов:
Как за 5233 человеко-часа создать софт для микротомографа
Управление доступом к электронным документам. От DefView до Vivaldi
Разработка простого плагина для JIRA для работы с базой данных
В помощь DevOps: сборщик прошивок для сетевых устройств на Debian за 1008 часов
Автообновление службы Windows через AWS для бедных
Комментарии (37)


MagisterLudi
12.05.2016 13:36«В окрестностях тройной звёздной системы Альфа Центавра обнаруживается продвинутая цивилизация Трисоляриса, намного обгоняющая земную по уровню технического развития, но из-за особенностей расположения и взаимодействия с системой своих светил, готовая в любой момент погибнуть в гравитационном коллапсе. Само развитие внеземной цивилизации носило хаотичный характер, прерываясь и вновь возобновляясь под воздействием гравитационных перепадов. В сигнале с Земли тоталитарная власть Трисоляриса увидела шанс к спасению и сразу же отправила к планете военный флот, который прибудет к Земле через 450 лет. Вместе с тем, технологии Трисоляриса позволяют отправить на Землю сверхскоростные спутники-шпионы, которые прибыв на планету, начинают тормозить земной прогресс, и воспользовавшись многополярностью взглядов и мнений относительно предстоящего контакта, создают секту учёных, которая по сути выступает «пятой колонной».»

DmitryKoterov
13.05.2016 01:35Насчет ссылки на fb2 на vk.com: с iphone она открывается как простая html-страница, и «открыть с помощью» для нее не работает (например, в приложение ShortBook не отправить, а через компьютер это уже делать лень). Но есть решение: ставим бесплатное приложение «Browser and File Manager for Documents» из app store, и оно уже умеет скачивать ссылку. После чего можно из этого приложения отправить, куда угодно.
Hayate
Про проблему трёх тел — это отлично.
А как там с литературным качеством перевода?
vconst
Чувствую, пора написать статью об этой книге, в переводе которой я участвовал. Вечером займусь, если ничто не отвлечет
Чтобы два раза не вставать: fb2 — это старый, кривой и глючный формат, вызывающий проблемы как у книгоделов, так и у читателей, нормального софта для работы с ним почти нет, поддержка отсутствует. Зачем вообще надо было его выбирать для демонстрации технологии?
MagisterLudi
Да, будет здорово, напишите обязательно.
Мне интересно.
ChALkeRx
А у нас всё такое (анекдот про верблюдов помните?) — fb2, xmpp, http, tcp, html, x11, c/c++, много чего ещё.
Но для части из этого адекватной замены либо вообще нет, либо есть, но полностью перейти пока ещё нельзя.
Что конкретно бы вы предложили вместо fb2 в данный момент?
vconst
Я бы предложил epub. Этот формат получил очень широкое распространение, а широкое распространение — означает широкую поддержку, вплоть до InDesing и других программ, даже GoogleDoc умеет экспортировать в epub из своих документов. Он очень хорошо задокументирован, постоянно развивается и поддерживается в куче самых разных API, без костылей
Вдобавок, у него больше возможностей по отображению контента и настройках. В fb2 есть несколько жестко зашитых стилей, которые почти невозможно изменять, разные программ-читалки по своему реализуют настройки отображения и все это очень плохо совместимо. А epub — это контейнер в котором заархивирован обычный сайт на привычном html и css, поддерживается динамический контент и в планах добавить даже полноценную поддержку JS
Инсайдерская информация с флибусты: там есть два лагеря библиотекарей, которые порой сцепляются насмерть в спорах «зачем нам fb2», но все заканчивается на том, что поддержка fb2 — историческая, тянется еще с долибрусековских времен, и что бы поменять дефолтный формат в библиотеке — надо очень серьезно переколбашивать ее движок. а этим никто заниматься не будет — у народа еле хватает времени на исправление текущих багов, ибо там все на волонтерско-добровольных началах и в свободное время
webkumo
А я бы не предлагал.
плюсы fb2 к epub:
— простой текстовый формат (грубо говоря — можно открыть и читать в блокноте)
— нет и хрен встроишь DRM
— очень широкое распространение читалок (намного шире)
минусы epub:
— получил распространение из под крыла Apple (для некоторых это плюс)
— более жёсткие требования к читалкам
— попытка прибить стили гвоздями (очень на любителя функционал)
— (спёр с вики) «Трудности автоматической конвертации в другие форматы»
— (спёр с вики) «Серьёзная фрагментация»
В общем «чукча не писатель, чукча читатель» — я как пользователь не вижу минусов формата.
Но да, согласен, формат не подходит для некоторых видов публикаций (те же научные статьи — там лучше делать не сноски, а ссылки, чего сам формат fb2 не даёт)… впрочем сомневаюсь, что узги его опережает.
vconst
Вы все перепутали. И fb2 и epub — это разновидности XML, а не «простой текстовый формат», разница только в том, что epub — это заархивированный html. В bf2 стили прибиты гвоздями разработчиком формата и вообще ограничены по количеству и функционалу, например: нельзя сделать эпиграфу выравнивание по левому краю, без костылей, которые свои в каждой читалке и тп. В epub — обычный CSS, который настраивается и переопределяется штатными и всем понятными средствами. А распространен fb2 только на территории бывшего СССР, за этими границами он вообще никому не известен и ничем не поддерживается, соответственно — и не развивается
webkumo
fb2 — простой текстовый (xml-совместимый) формат.
epub — бинарный zip-архив с xml + html/css/картинки/pdf/хрен знает что ещё.
Т.е. вот взять и открыть в редакторе epub уже не получится (нужно сперва разархивировать и разобраться в каком файле прячется само произведение, при этом оно может быть закрыто DRM или вообще лежать в pdf).
Насчёт распространённости за пределами exUSSR я не знаю, говорить не буду (а у вас откуда дровишки?).
Ну а по поводу стилизаций я уже высказался — мне интересно читать (художественную литературу, да), а не смотреть на войну стилей. На второе я насмотрелся в конце 90х начале 2000х в интернете.
vconst
О распространенность форматов легко судить по иностранным интернет-магазинам книг, практически повсеместно mobi и epub, и по тому — в какие форматы есть возможность экспорта из распространенных программ верстки и работы с текстом, даже GoogleDocs недавно научится делать экспорт в epub, без промежуточных форматов типа fb2
Недостатки fb2 еще и в том, что очень мало программ, которые полноценно работают с этим форматом (Calibre не в их числе), и это сдерживает развитие электронного издательства, как отрасли
Необходимость открывать электронные книги «как текст» мне кажется весьма сомнительной, за многолетнюю практику чтения электронных книг мне это почти не приходилось делать, только когда сам делал электронную книгу из бумажных сканов (один раз) — а этим занимается ничтожный процент от всей массы электронных читателей. Узок круг электронных книгоделов…
webkumo
«легко судить по иностранным интернет-магазинам книг» о том, какой формат DRM-пригодный. Google Play использует DRM везде, где только может (чтоб им пусто было). Насчёт других сторов — не в курсе. Для справки — fb2 не поддерживает DRM ни в каком виде.
«в какие форматы есть возможность экспорта из распространенных программ верстки и работы с текстом» — хм… сомнительный довод… впрочем я сферы вёрстки бумажных книг не касался, но там же вроде вообще проприетарщина правит бал? А она штука не предсказуемая… да и издатели имеют несколько отличные цели от целей читателей (а я, повторюсь, смотрю в первую очередь с точки зрения читателя).
А я вот не знаю никакой Calibre… Зато знаю множество ридеров/вьеров полностью поддерживающих fb2 и способных глотать 2х-мегабайтные архивы (т.е. сам fb2 как-бы больше 4х Мб получается). А вот у epub-а с этим как-то посложнее, насколько я понял из отзывов… Но в любом случае всё же упирается в спрос — будет спрос, будут редакторы… но откуда будет спрос, если профессионалам формат не очень интересен (нет DRM… это ж для западных издателей вообще конец света!.. а наши ничего так — работают… хотя тоже были бы рады всё заDRMить, да исторически не сложилось), а у любителей не там много денег.
Ну почему же сомнительной? Я вот ещё помню, как книги в txt читал… Согласен, что по текущим временам — это может быть неактуальным… Но вот например для личного каталога — я эти скачанные файлы правил (к сожалению наполнение мета-информацией книг даже в пределах одной серии иногда хромает — то автор без отчества, то серия не проставлена в первой книге, то ещё что-нибудь… а каталогизатор потом считает их разными инстансами) в простом текстовом редакторе… (ну ладно-ладно, не в простом… в IDEA с xml работать комфортней)
xaizek
Поддерживаю, проблема epub в том, что то, что он использует, было сделано вообще для другого и описывает как текст должен отображаться, а настоящий формат для электронных книг должен описывать структуру! По аналогичным причинам pdf тоже плохо подходит. Так что fb2 ближе их обоих к идеалу, дополню почему:
Self_Perfection
epub зло. Подробно в http://gribuser.livejournal.com/1434.html но если коротко, то fb2 семантический, а epub про презентацию. Но невозможно читалки научить поддерживать всё многообразие html
Практический пример: я сейчас читаю hpmor в epub, главы внутри разделены на секции, предполагается, что секции должны быть отделены друг от друга горизонтальной линией. Но FBReader эту горизонтальную линию не отображает. И это сбивает с толку, т.к. автор, предполагая, что оформлением книги донесена информация, что началась новая сцена, не поясняет текстом, что теперь действие происходит в другом месте или спустя некоторое время.
Удобный формат в ядре своём должен быть семантическим.
vconst
Статья в ЖЖ написана создателем формата fb2, четыре года назад и весьма предвзята. Развития fb2 нет и не предвидится, fb3 хронически «в ближайших планах».
Что касается поддержки и реализации fb2, то программ грамотно работающих с этим форматом — по пальцам одной руки пересчитать и еще лишние останутся, если что — то Calibre с ним работает ужасно.
Что касается удобства epub — то фактически это обычный сайт в архиве, мало кто недоволен html и css настолько, что бы говорить «это все вообще никуда не годится и нигде правильно не реализуется»
gimntut
Насколько я помню, автор fb2 высказался про fb3 следующим образом (не дословно): «fb3 уже придуман и называется он xhtml».
Другими словами, xhtml обладает и строгостью и гибкостью необходимой для электронной книги.
Только нет ни приложений, ни книг в формате xhtml.
knutov
епаб — это конечный формат. фб2 — это промежуточный исходник, из которого делается любой конечный формат под любой девайс и разрешение. Почему-то все это забывают.
Во времена наладонников благодаря чудесным читалкам у многих сложилось восприятие фб2 как конечного формата (и для некоторых платформ/читалок это может быть так), но это ошибочное восприятие.
alexxisr
согласен. Я например fb2 маленьким скриптом перегоняю в latex и делаю красивую и удобную pdf под мою читалку, с теми шрифтами и оформлением, которые нравятся мне, а не какому-то там издателю.
Stiver
Полезная вещь, не поделитесь вашим скриптом с общественностью?
MagisterLudi
Разработчики ответили:
«Мы — профессионалы, это как наемники. Заказчик сказал 7 красных перпендикулярных линий — мы сделали. Плакали, кололись, но жрали
кактус. Получили огромный опыт и позитивные отзывы.»
vconst
Логично, я так и предполагал. Возможно стоило обсудить с заказчиком целесообразность в выборе формата, но это уже «после драки кулаками». Есть у меня нехорошая мысль, что fb2 заказчику нужен только потому, что есть десятки гигабайт уже готовых файлов, валяющихся на торрентах со сборками архивов либрусека и флибусты, но это его личное дело…
Andreyc4d
7 красных перпендикулярных линий зеленого цвета… Ммм… и 3 прозрачного цвета.
knutov
А у fb2 есть какие-то альтернативы?
Там же по задумке было — делаем книгу один раз в фб2, рендерим из фб2 под любой девайс и любой формат. Доживших до наших дней альтернатив я не знаю ни одной.
vconst
Весь мир пользуется другими форматами и пока электронное издание только развивается, экспорт в epub можно сделать из всех распространенных программ для работы с текстом и версткой
knutov
Но как будет выглядеть результат этого экспорта…
Весь смысл фб2 изначально был именно в том, что у нас есть исходник с разметкой в фб2, есть правила как это должно выглядеть на конкретном девайсе с конкретным разрешением, и дальше из фб2 по правилам рендерится под девайс и его формат.
vconst
Смысл в fb2 — был лет десять назад, с тех пор много что изменилось, кроме самого формата fb2
___
2 Автор топика: прошу прощения за этот fb2-диспут не по теме…
knutov
Есть же fb3 )
vconst
И где он есть, кроме викпедии и ЖЖ автора формата?
dzikar
Не вижу разницы epab и fb2. То и то использует разметку. Маркетинг разве что.
webkumo
Я ведь правильно понял, перевод книжки был под авторством нескольких людей?
А почему площадкой для распространения был выбран вконтакт (по крайней мере автор статьи ссылается только на вконтакт, если это не так, то приведите, пожалуйста, ссылочки на другие источники)?
PS просто привык периодически что-то искать на samlib.ru (портал для авторов, распространяющих свои произведения бесплатно, там бывают и авторские произведения и переводы), но такой книги я там вроде не видел…
vconst
Перевод был сделан одним человеком, остальные помогали редактировать. Книгу можно найти на флибусте, перевод был сделан именно для этой библиотеки
Я написал статью о переводе и послал ее в песочницу гиктаймс, подождем пока модераторы ее пропустят туда
rvt
Насчет старого и кривоватого согласен. А вот софта для него полно. И мобильного и стационарного.
Arhont375
Качественный перевод, рекомендую.
Hayate
Начал читать, текст читается хорошо, боялся что будет что-то вроде Артура Кларка. Впрочем у Кларка не с переводчиком проблема.
Hayate
Пока что что-то вроде объединения «За миллиард лет до конца света» и «Один день Ивана Денисовича». И очень интересно. Ещё бы спойлера в комментах не было бы.
Hayate
Я только не понял, почему адвентисты не были предупреждены о спецоперации.