
Как часто, имея массив текстов (любой тематики) мы хотим увидеть тематическую выжимку? Какие темы обсуждаются? Какие наиболее популярные? Как было бы здорово ввести поисковые слова и получить тренды вокруг них!

Система умеет:
Все перечисленные функции доступны через API, которым легко воспользоваться, подключившись к одному из тарифных планов (есть бесплатный триал на месяц!).
Мы проиндексировали соц. медиа (твиттер, facebook, вконтакте) в начале осени 2015 года и сделали скриншоты системы для визуальной оценки.
Консьюмерский сегмент: Магнит.

Yota:
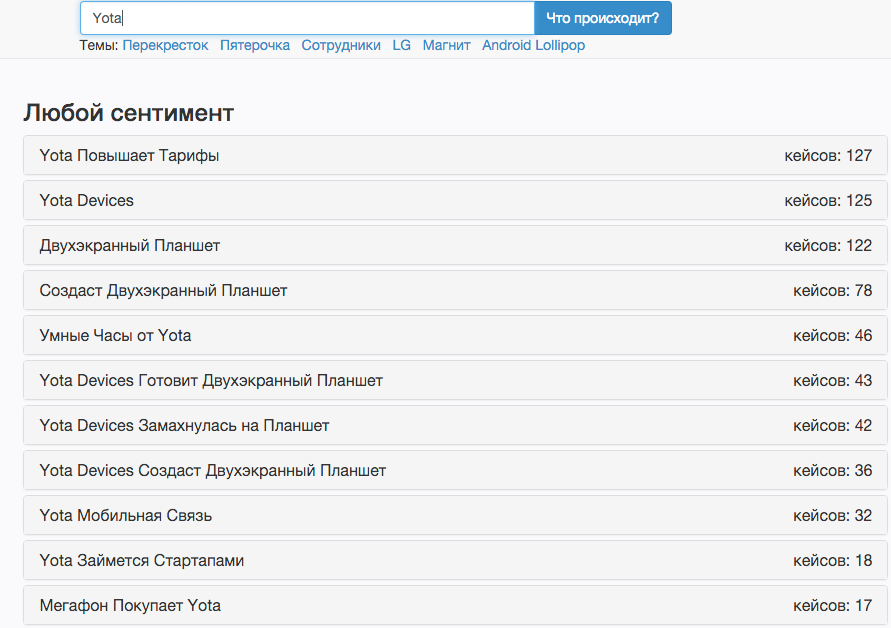
Политика: выступление Путина в ООН.

Так выглядит тема изнутри:

На предыдущем скриншоте представлено содержимое темы “ООН 2015”, включающее 7 новостей.
Как видно из скриншотов, система представляет из себя полноценную поисковую систему (с поддержкой русской морфологии) и является удобным инструментом для быстрой навигации по массивам информации. У нас нет ограничений по поддерживаемым тематикам и типу данных — соц. медиа, новостные ленты либо Ваши корпоративные документы. Все описанные функции доступны как в виде SAAS продукта с пользовательским интерфейсом, так и в составе Insider API, который можно встроить в Ваши существующие системы и мобильные приложения.
Принцип применения API:
1. Загрузить данные (посты, статьи) в систему.
В одном запросе можно переслать до 50 текстов. В ответ API отвечает кодом 200, если всё прошло успешно.
Обратите внимание на параметр id: по значению этого параметра мы получим привязку данного поста к определенной теме / тренду на следующем шаге.
2. Получить тренды: либо по документам в целом, либо в привязке к ключевым словам.
В ответ API генерирует тренды.
Значение score отображает релевантность данной тематики запросу пользователя.
На шаге два можно передать и некоторое ключевое слово, вокруг которого будут построены темы / тренды.
Insider API доступен здесь: market.mashape.com/dmitrykey/insiderapi
Помимо трендов, другими удобными фичами являются:
Система умеет:
- Получать массив данных и сохранять их под Вашим пользователем.
- Строить список тем с группировкой документов по темам.
- Делать realtime поиск по документам и строить темы по найденной выборке.
Все перечисленные функции доступны через API, которым легко воспользоваться, подключившись к одному из тарифных планов (есть бесплатный триал на месяц!).
Мы проиндексировали соц. медиа (твиттер, facebook, вконтакте) в начале осени 2015 года и сделали скриншоты системы для визуальной оценки.
Консьюмерский сегмент: Магнит.
Yota:
Политика: выступление Путина в ООН.
Так выглядит тема изнутри:
На предыдущем скриншоте представлено содержимое темы “ООН 2015”, включающее 7 новостей.
Как видно из скриншотов, система представляет из себя полноценную поисковую систему (с поддержкой русской морфологии) и является удобным инструментом для быстрой навигации по массивам информации. У нас нет ограничений по поддерживаемым тематикам и типу данных — соц. медиа, новостные ленты либо Ваши корпоративные документы. Все описанные функции доступны как в виде SAAS продукта с пользовательским интерфейсом, так и в составе Insider API, который можно встроить в Ваши существующие системы и мобильные приложения.
Принцип применения API:
1. Загрузить данные (посты, статьи) в систему.
End-point: /articles/uploadJson
Тип запроса: POST
[
{
"id": 2134657,
"title": "Оскар",
"description": "Наши дети уже не поймут всех этих приколов про Лео и Оскар. Ушла эпоха. Мы - особое поколение.",
"link": "https://twitter.com/palnom6/status/704979632127418369"
}
]
В одном запросе можно переслать до 50 текстов. В ответ API отвечает кодом 200, если всё прошло успешно.
Обратите внимание на параметр id: по значению этого параметра мы получим привязку данного поста к определенной теме / тренду на следующем шаге.
2. Получить тренды: либо по документам в целом, либо в привязке к ключевым словам.
End-point: /articles/cluster
Тип запроса: POST
{
"query": ""
}
В ответ API генерирует тренды.
[
{
"labels": [
"Оскар"
],
"score": 1.510325122396045,
"docs": [
"2134657",
"2134656",
"2134655",
"2134654"
]
},
{
"labels": [
"Политика"
],
"score": 1.2447816860782057,
"docs": [
"2134653",
"2134652",
"2134651",
"2134650",
"2134649",
"2134648"
]
}
]
Значение score отображает релевантность данной тематики запросу пользователя.
На шаге два можно передать и некоторое ключевое слово, вокруг которого будут построены темы / тренды.
Insider API доступен здесь: market.mashape.com/dmitrykey/insiderapi
Помимо трендов, другими удобными фичами являются:
- Объектная тональность: market.mashape.com/dmitrykey/russiansentimentanalyzer
- Извлечение адресов: market.mashape.com/dmitrykey/streetdetector
- Тональность, если ваши тексты на китайском: market.mashape.com/dmitrykey/fuxiapi
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Поделиться с друзьями
Комментарии (15)

ServPonomarev
18.05.2016 13:22Обязательная регистрация для теста? Ввод данных кредитки для бесплатной месячной подписки — для теста?!
Вам совсем плохо?

vshemarov
18.05.2016 13:52Какие темы обсуждаются?..
Мы проиндексировали соц. медиа (твиттер, facebook, вконтакте) в начале осени 2015 года…
Т.е. сейчас это интересно только тому, кто хочет знать, какие новости обсуждались более полугода назад
DKey
18.05.2016 14:08Чем старше данные, тем меньше вопросов от соответствующих организаций. Для новых данных система тоже работает.
vshemarov
18.05.2016 16:48+1А ФБ ведь в нынешнем АПИ не позволяет поиск. Интересно, как вы получаете свежие данные?
DKey
18.05.2016 20:17Это правда. Остался открытым Graph API, при помощи которого можно загрузить странички-хабы по брендам / политике / спорту и тд с комментариями, лайками и тд. Помимо этого есть scrappers (например: http://scrapy.org/).
zenn
Вот хоть убейте, но каким образом этот рекламный пост относится к разделу разработки? Вы серьезно считаете, что ~1к тексто-символов, размытые 4мя скриншотами и 1 логотипом можно считать за техническую статью?!
Почему эта «пиарщина» не в блоге компании?! Почему не в «я пиарюсь» (кармы нахватает?)?
Каким боком это относится к Data mining? Вы описываете технические аспекты реализации или просто пришли вбросить 4 ссылки на ваш сервис?
П.с. — вы не на мегамозг пишите, будьте добры, либо оформляйте статьи так, как соответствует техническим материалам, или пишите в соответствующие разделы/хабы.
DKey
спасибо за рекомендации. Data mining — например, извлечение адресов из текстов. Какой хаб вы бы порекомендовали?
zenn
Вся принципиальная разница лишь в том, что вы не описываете этот самый процесс (нет никаких технических аспектов, ни алгоритмов, ни ПО, ни программного кода), а просто рекламируете свой сервис. Единственный хаб для данного, кхм, поста — это «Я пиарюсь».
DKey
мне действительно не доступен хаб «Я пиарюсь». Поэтому на посте есть тэг.
DKey
Добавлено описание взаимодействия с end-point'ами.
zenn
Выглядит так, будто вы пытаетесь сдать реферат в институте, а у вас его не принимают и вы пытаетесь добавить «больше воды». Возможно вы невнимательно прочли мой вопрос, а возможно некомпетентны в нем, постараюсь разъяснить. Вы описываете «скриншотами» некий технический комплекс, который по средствам взаимодействия с его API позволяет получить ту или иную релеватную выдачу в зависимости от запроса и данных, введенных пользователем. Так вот, технический интерес представляет как раз таки работа вашего технического комплекса и его организация, но никак не алгоритм взаимодействия с его API по средствам JSON (это пожалуй известно даже новичкам, а детальная информация уже есть на сайте сервиса). Под «работой технического сервиса» понимается набор приложений (баз данных, поискового движка, программного кода который все это связывает) и то как они организованы, чего здесь нет и статья вряд ли может находится в техн. разделе этого ресурса.
DKey
Дело в том, что данная публикация преследует ознакомительную цель с данным продуктом. А относится ли это к разработке — имхо, да. Ведь продукты на основе данного API вполне себе разработка.