

R, один из популярнейших языков программирования среди data scientist'ов, получает все большую и большую поддержку как среди opensource-сообщества, так и среди частных компаний, которые традиционно являлись разработчиками проприетарных продуктов. Среди таких компаний – Microsoft, чья интенсивно увеличивающая поддержка языка R в своих продуктах/сервисах, привлекла к себе и мое внимание.
Одним из «локомотивов» интеграции R с продуктами Майкрософт является облачная платформа Microsoft Azure. Кроме того, появился отличный повод повнимательнее взглянуть на связку R + Azure – это проходящий в эти выходные (21-22 мая) хакатон по машинному обучению, организованный Microsoft.
Хакатон – мероприятие, где
R же прекрасно подходит для создания прототипов, для копания (mining) в данных, для быстрой проверки своих гипотез – то есть
всего того, что нам нужно на такого типа соревнованиях! Ниже я расскажу, как использовать всю мощь R в Azure – от создания прототипа до публикации готовой модели в Azure Machine Learning.
0. Microsoft love R
Сразу определимся со списком продуктов/сервисов Microsoft, которые нам позволят работать с R:
- Microsoft R Server / R Server для Azure HDInsight
- Data Science VM
- Azure Machine Learning
- SQL Server R Services
- Power BI
- R Tools for Visual Studio
И (о радость!) продукты 1-3 нам доступны в Azure по модели IaaS/PaaS. Рассмотрим их по очереди.
1. Microsoft R Server (+ для Azure HDInsight)
После покупки в прошлом году небезызвестной Revolution Analytics, Revolution R Open (RRO) и Revolution R Enterprise (RRE) были переименованы в Microsoft R Open (MRO) и Microsoft R Server, соответственно. Сейчас Microsoft R Server – хорошо сложенная экосистема, состоящая как из opensource-продуктов, так и проприетарных модулей Revolution Analytics.
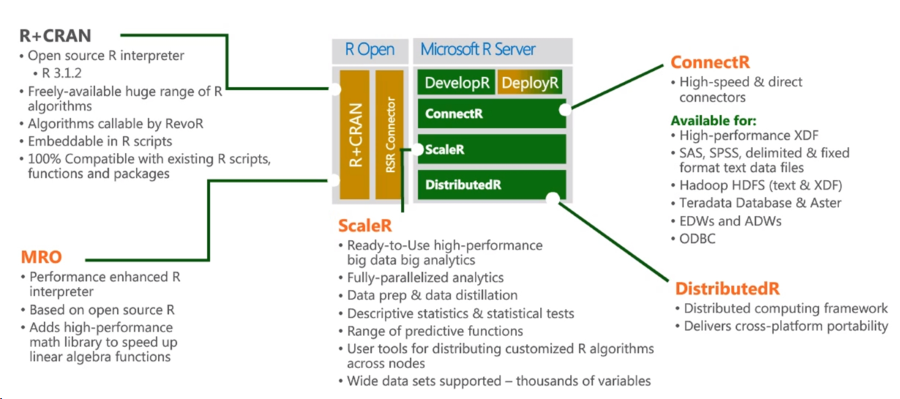
Источник
Центральное место занимает R+CRAN, гарантируется 100%-ая совместимость как с языком R, так и совместимость с существующими пакетами. Еще один центральный компонент R Server – Microsoft R Open, представляющий собой среду выполнения с улучшенными показателями скорости работы с матрицами, математическими функциями, улучшенную поддержку многопоточности.
Модуль ConnectR позволяет получать доступ к данным, хранящимся в Hadoop, Teradata Database и др.
R Server для Azure HDInsight добавляет ко всему возможность выполнять R-скрипты непосредственно на Spark-кластере в облаке Azure. Таким образом, решена проблема того, что данные не помещаются в RAM машины, локально, по отношению которой, исполняется R-скрипт. Инструкция прилагается.
Сам же Azure HDInsight – облачный сервис, предоставляющий Hadoop/Spark-кластер по требованию. Так как это сервис, то из задач администрирования стоит только развертывание и удаления кластера. Все! Ни секунды потраченного времени на конфигурацию кластера, установку обновлений, настройку доступов и т.п.
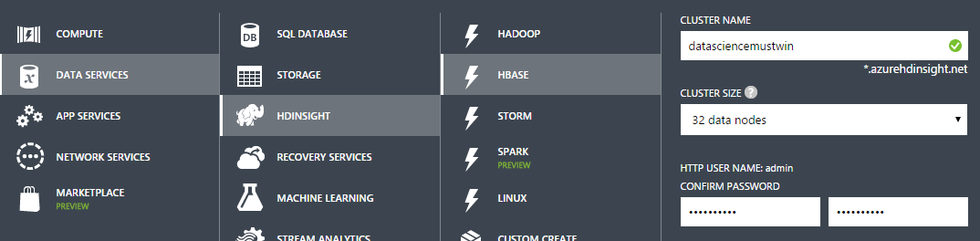
Для создания Spark-кластера нам на выбор нужно нажать либо 3 кнопки (изображение выше), либо выполнить следующий несложный PowerShell-скрипт [источник]:
Login-AzureRmAccount
# Set these variables
$clusterName = $containerName # As a best practice, have the same name for the cluster and container
$clusterNodes = 8 # The number of nodes in the HDInsight cluster
$credentials = Get-Credential -Message "Enter Cluster user credentials" -UserName "admin"
$sshCredentials = Get-Credential -Message "Enter SSH user credentials"
# The location of the HDInsight cluster. It must be in the same data center as the Storage account.
$location = Get-AzureRmStorageAccount -ResourceGroupName $resourceGroupName `
-StorageAccountName $storageAccountName | %{$_.Location}
# Create a new HDInsight cluster
New-AzureRmHDInsightCluster -ClusterName $clusterName `
-ResourceGroupName $resourceGroupName -HttpCredential $credentials `
-Location $location -DefaultStorageAccountName "$storageAccountName.blob.core.windows.net" `
-DefaultStorageAccountKey $storageAccountKey -DefaultStorageContainer $containerName `
-ClusterSizeInNodes $clusterNodes -ClusterType Hadoop `
-OSType Linux -Version "3.3" -SshCredential $sshCredentials
Remove-AzureRmHDInsightCluster -ClusterName <Cluster Name>
2. Data Science VM
Если вам вдруг захотелось: 32x CPU, 448Gb RAM, ~0.5 TB SSD с предустановленными и сконфигурированными:
- Microsoft R Server Developer Edition,
- Anaconda Python distribution,
- Jupyter Notebooks для Python и R,
- Visual Studio Community Edition с Python и R Tools,
- Power BI desktop,
- SQL Server Express edition.
Если Вы собирайтесь писать на R, Python, C# и использовать SQL. А потом еще решили, что вам не помешает xgboost, Vowpal Wabbit, CNTK (open source deep learning library от Microsoft Research). Тогда Data Science Virtual Machine то, что вам нужно — там предуставновлены и готовы к работе все перечисленные выше продукты и не только. Развертывание несложное, но и для него есть инструкция.
3. Azure Machine Learning
Azure Machine Learning (Azure ML) – облачный сервис для выполнения задач, связанных с машинным обучением. Почти наверняка Azure ML будет центральным сервисом, которым вы будете пользоваться, в случае, если захотите обучить модель, в облаке Azure.
Подробный рассказ про Azure ML не входит в цели данного поста, в тем более, что о сервисе уже достаточно написано: Azure ML для Data Scientist’ов, Best Practices обучения модели в Azure ML. Сконцентрируемся на следующей задаче: организация командной работы с максимально безболезненным переносом R-скриптов с локального компьютера в Azure ML Studio.
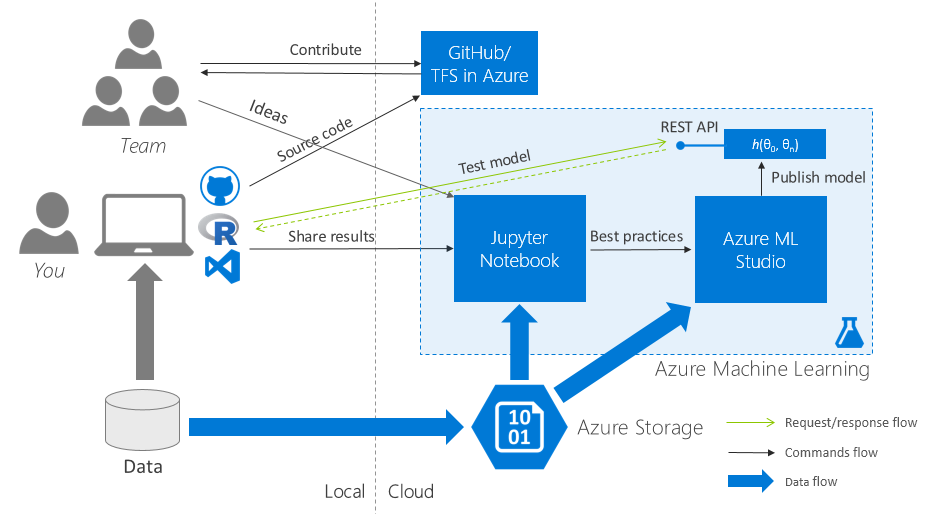
3.1. Начальные требования
Для задуманного понадобятся следующие бесплатные программные продукты:
- Для консерваторов: R (runtime), R Studio (IDE).
- Для демократов: R (runtime), Microsoft R Open (runtime), Visual Studio Community 2015 (IDE), R Tools для Visual Studio (IDE extension).
Для работы в Azure понадобится активная подписка Microsoft Azure.
3.2. Начало работы: collaboration everything
Один workspace в Azure ML на всех
Создаем один(!) на всю команду workspace в Azure ML и расшариваем его между всеми участниками команды.
Один репозиторий кода на всех
Создаем один облачный Team Project (TFS в Azure) / репозиторий в GitHub и также расшариваем его на всю команду.
Думаю, очевидно, что теперь часть команды, работающая над одной задачей хакатона, делает коммиты в один репозиторий, коммитит фичи в бранчи, бранчи мержит в мастер – в общем идет нормальная командная работа над кодом.
Один набор начальных данных на всех
Зайдите в Azure ML Studio (web IDE), перейдите на вкладку «Datasets» и загрузите набор изначальных данных в облако. Сгенерируйте код доступа (Data Access Code) и разошлите его команде.
Так выглядит интерфейс загрузки данных в Azure ML Studio:
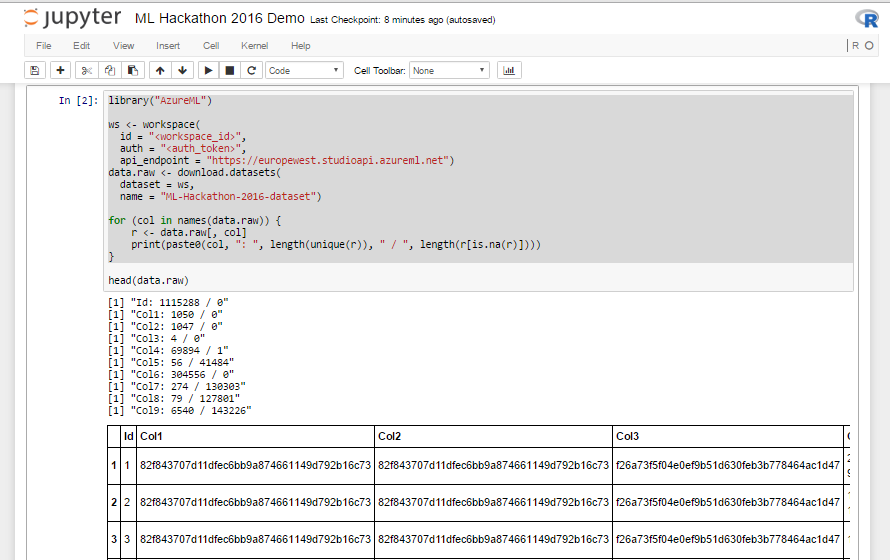
Листинг 1. R-скрипт для загрузки данных
library("AzureML")
ws <- workspace(
id = "<workspace_id>",
auth = "<auth_token>",
api_endpoint = "https://europewest.studioapi.azureml.net")
data.raw <- download.datasets(
dataset = ws,
name = "ML-Hackathon-2016-dataset")
3.3. Jupyter Notebook: выполнение R-скриптов в облаке и визуализация результатов
После того, как дата, код и проект в Azure ML оказались в общем для всей команды доступе, пора научиться делиться визуальными результатами исследования.
Традиционно для этой задачи data science community любит использовать Jupyter Notebook – клиент-серверное веб-приложение, позволяющее разработчику объединить в рамках единого документа: код (R, Python), результаты его выполнения (в т.ч. графики) и rich-text-пояснения к нему.
Создадим в Azure ML документы Jupyter Notebook:
- Создаем отдельный документ Jupyter Notebook на участника.
- Заливаем единый расшаренный начальный набор данных из Azure ML (код из листинга 1). Код работает и при запуске из локальной R Studio, поэтому ничего нового для Jupyter Notebook писать не надо – просто берем и копируем код из R Studio.
- Делимся ссылкой на документ Jupyter Notebook с командой,
кидаемся каобсуждаем, дополняем непосредственно в Jupyter Notebook.
В результате на каждую задачу хакатона должны получиться несколько Jupyter Notebook документов:
- содержащих R-скрипты и результаты их выполнения;
- над которыми пофантазировала-подумала вся команда;
- с полным flow: от загрузки данных до результата применения алгоритма машинного обучения.
Вот так это выглядит у меня:
3.4. Prototype to Production
На этом этапе у нас есть несколько исследований, по которым получен приемлемый результат и соответствующие этим исследованиям:
- в GitHub/Team Project: бранчи с R-скриптами;
- в Jupyter Notebook: несколько документом с обсужденными в команде результатами того, что получилось.
Следующий шаг – создание в Azure ML Studio экспериментов (вкладка «Experiments») – далее AzureML-экспериментов.
На этом этапе необходимо придерживаться следующих best practices при переносе R-кода в AzureML-эксперимент:
Модули:
- По возможности не используйте встроенный модуль «Execute R script» как контейнер для выполнения R кода: у него нет поддержки версионности (сделанные внутри модуля изменения кода нельзя откатить), модуль в совокупности с R кодом не может быть переиспользован в рамках другого эксперимента.
- Используйте возможность загружать пользовательские R-пакеты (Custom R Module) в Azure ML (о процессе загрузки ниже). Custom R Module имеют уникальное имя, описание модуля, модуль можно переиспользовать в рамках различных AzureML-экспериментов.
R-скрипты:
- Организуйте R-скрипты внутри R-модулей как набор функций с одной точкой входа.
- Переносите в Azure ML в виде R-кода только тот функционал, который невозможно/сложно воспроизвести с помощью встроенных модулей Azure ML Studio.
- R-код в модулях выполняется со следующими ограничениями: отсутствует доступ к persistence-хранилищу и сетевому соединению.
В соответствии с правилами выше перенесем наш R-код в AzureML-эксперимент. Для нам необходим zip-архив, состоящий из 2-ух файлов:
- .R-файл, содержащий код, который мы собираемся перенести в облако.
Пример с поиском/фильтрацией выбросов в данныхPreprocessingData <- function(dataset1, dataset2, swap = F, color = "red") {
# do something
# ...
# detecting outliners
range <- GetOutlinersRange(dataset1$TransAmount)
ds <- dataset1[dataset1$TransAmount >= range[["Lower"]] &
dataset1$TransAmount < range[["Upper"]], ]
return(ds)
}
# outlines detection for normal distributed values
GetOutlinersRange <- function(values, na.rm = F) {
# interquartile range: IQ = Q3 - Q1
Q1 = quantile(values, probs = c(0.25), na.rm = na.rm)
Q3 = quantile(values, probs = c(0.75), na.rm = na.rm)
IQ = Q3 - Q1
# outliners interval: [Q1 - 1.5IQR, Q3 + 1.5IQR]
range <- c(Q1 - 1.5*IQ, Q3 + 1.5*IQ)
names(range) <- c("Lower", "Upper")
return(range)
}
- Xml-файл, содержащий определение/метаданные нашей R-функции.
Пример (раздел Arguments просто для «широты» примера)<Module name="Preprocessing dataset">
<Owner>Dmitry Petukhov</Owner>
<Description>Preprocessing dataset for ML Hackathon Demo.</Description>
<!-- Specify the base language, script file and R function to use for this module. -->
<Language name="R" entryPoint="PreprocessingData " sourceFile="PreprocessingData.R" />
<!-- Define module input and output ports -->
<Ports>
<Input id="dataset1" name="Dataset 1" type="DataTable">
<Description>Transactions Log</Description>
</Input>
<Input id="dataset2" name="Dataset 2" type="DataTable">
<Description>MCC List</Description>
</Input>
<Output id="dataset" name="Dataset" type="DataTable">
<Description>Processed dataset</Description>
</Output>
<Output id="deviceOutput" name="View Port" type="Visualization">
<Description>View the R console graphics device output.</Description>
</Output>
</Ports>
<!-- Define module parameters -->
<Arguments>
<Arg id="swap" name="Swap" type="bool" >
<Description>Swap input datasets.</Description>
</Arg>
<Arg id="color" name="Color" type="DropDown">
<Properties default="red">
<Item id="red" name="Red Value"/>
<Item id="green" name="Green Value"/>
<Item id="blue" name="Blue Value"/>
</Properties>
<Description>Select a color.</Description>
</Arg>
</Arguments>
</Module>
Загрузим полученный архив через Azure ML Studio. И выполним эксперимент, убедившись, что скрипт отработал и мы обучили модель.
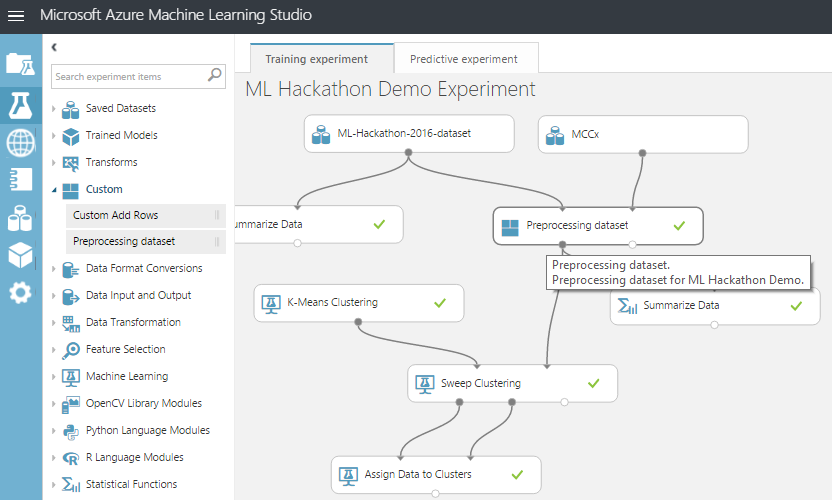
Теперь можно улучшить существующий модуль, загрузить новый, устроить соревнование между ними – в общем пользоваться благами инкапсуляции и модульной структуры.
Заключение
По моему мнению R экстремально эффективен в прототипировании, и от этого он прекрасно себя зарекомендовал на различного типа data science хакатонах. В то же время между прототипом и продуктом существует труднопреодолимая пропасть в таких вещах как масштабируемость, доступность, надежность.
Используя инструментарий Azure для R, мы довольно долго можем балансировать на грани между гибкостью R и надежностью + другими бенефитами, которые нам дает Azure ML.
И еще…
Приходите на хакатон по Azure Machine Learning (о нем я писал в начале) и попробуйте все это сами, пообщайтесь с экспертами и единомышленниками
Кроме того, для тех кому будет мало офлайн общения, приглашаю в теплый ламповый slack-чат, где участники хакатона смогут задавать вопросы, делится с друг другом опытом, а после хакатона рассказать о своем ML-решении и продолжать поддерживать профессиональные связи.
Стучитесь ко мне за инвайтом в slack через личные сообщения в Хабре или по любому из контактов, который найдете в моем блоге (ссылку ставить не буду – через профиль на Хабре найти его не составит труда).
Комментарии (5)

Sorokinv
19.05.2016 16:11У Вас свободный аккаунт (Free) или другой (стандартный, нестандартный)? На свободном (free) аккаунте доступа к генерации кода доступа к DataSet нет, по крайней мере у меня (Generate Data Access Code). Так же нет Custom вкладки на панели в AzureML. Каковы требования к аккаунту для такой работы?

codezombie
19.05.2016 16:26Я на Standart Layer в Azure ML сижу. Список отличий слоев можно найти на https://azure.microsoft.com/en-us/pricing/details/machine-learning/. Вроде про функции, о которых вы говорите, речи там не идет, но я не исключаю, что ограничения с которыми вы столкнулиcь, именно из-за типа layer.
Sorokinv
19.05.2016 16:41+1Спасибо за ответ, обязательно гляну.
Но я вроде бы уже разобрался методом проб и ошибок за время модерации вопроса. Данная возможность не предоставляется для наборов типа dataset, в том числе и выгрузка в Jupyter notebook (но предоставляется для типов типа csv, tsv и др, как запутанно описано в описании библиотеки AzureML). Я после задумчивых чтений сообщений об ошибках в Jupyter Notebook для функции download.datasets (AzureML) решил попробовать перегрузить одну таблицу в csv формат. И для этой таблицы в csv формате всё недостающее появилось, в том числе выгрузки в notebook, генерация кода доступа и другие плюшки. Так что проблема была в форматах хранения данных, с которыми ты хочешь работать внешними приложениями.
Thanks, отличия по уровням гляну.
ZogG
Извините за вопрос не совмем по теме, но может кто знает, что за фонт на первой картинке?
codezombie
Ответил в личку