

Нужно построить больше GPU
Deep Learning – одно из наиболее интенсивно развивающихся направлений в области машинного обучения. Успехи исследований в области глубокого (глубинного) обучения вызывают за собой рост количества ML/DL-фреймворков (в т.ч. и от Google, Microsoft, Facebook), имплементирующих данные алгоритмы. За все возрастающей вычислительной сложностью DL-алгоритмов, и, как следствие, за увеличивающейся сложностью DL-фреймворков уже давно не угоняются аппаратные мощности ни настольных, ни даже серверных CPUs.
Выход нашли, и он простой (кажется таким) – использовать для такого типа compute-intensive-задач расчеты на GPU/FPGA. Но и тут проблема: можно, конечно, для этих целей использовать видеокарту любимого ноутбука, но какой
Подходов к владению высокопроизводительными GPU минимум два: купить (on-premises) и арендовать (on-demand). Как накопить и купить – тема не этой статьи. В этой — мы рассмотрим, какие предложения есть по аренде инстансов VM c высокопроизводительными GPU у облачных провайдеров Amazon Web Service и Windows Azure.
1. GPU in Azure
В начале августа 2016 года было объявлено о начале закрытого тестирования (private preview) инстансов виртуальных машин, оборудованных картами NVidia Tesla [1]. Эта возможность предоставляется в рамках сервиса Azure VM – IaaS-сервис предоставляющий виртуальные машины по требованию (аналог Amazon EC2).
C точки зрения доступа приложения к графическому процессора архитектура сервиса выглядит так:
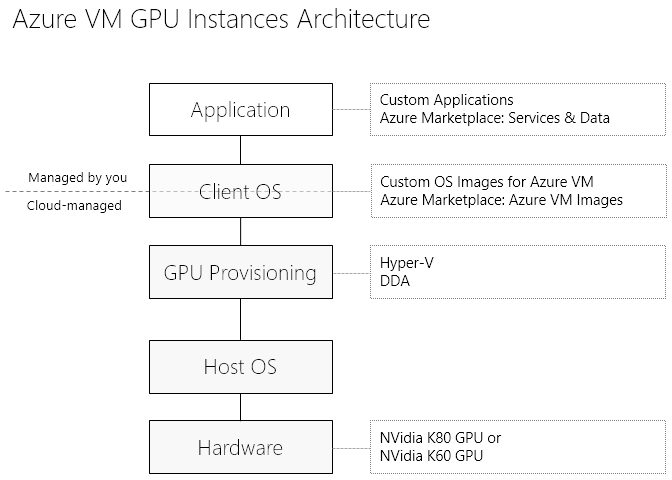
Расчеты на GPU доступны на виртуальных машинах серии N, которые, в свою очередь, делятся на 2 категории:
- NC Series (computer-focused): GPU, нацеленные на вычисления;
- NV Series (visualization-focused): GPU, нацеленные на графические расчеты.
1.1. NC Series VMs
Графические процессоры, предназначенные для compute-intensive нагрузки с использование CUDA/OpenCL. Графическими платами для них служат NVidia Tesla K80: 4992 CUDA ядра, >2.91/8.93 Tflops c двойной/одинарной точностью). Доступ к картам осуществляется с использованием технологии DDA (discrete device assignment), которая приближает производительность GPU при использовании через VM к bare-metal-производительности карты.
Как несложно догадаться, VM серии NC предназначены для ML/DL-задач.
В Azure доступны следующие конфигурации VM, оборудованных Tesla K80.
| NC6 |
NC12 |
NC24 |
|
| Cores |
6 (E5-2690v3) |
12 (E5-2690v3) |
24 (E5-2690v3) |
| GPU |
1 x K80 GPU (1/2 Physical Card) |
2 x K80 GPU (1 Physical Card) |
4 x K80 GPU (2 Physical Cards) |
| Memory |
56 GB |
112 GB |
224 GB |
| Disk |
380 GB SSD |
680 GB SSD |
1.44 TB SSD |
1.2. NV Series VMs
Виртуальные машины серии NV предназначены для визуализации. На данных VM стоят GPU Tesla M60 (4086 CUDA ядер, 36 потоков по 1080p H.264). Эти карты подойдут для задач (де)кодирования, рендеринга, 3D-моделирования.
Заявлено о доступности экземпляров VM со следующими конфигурациями:
| NV6 |
NV12 |
NV24 |
|
| Cores |
6 (E5-2690v3) |
12 (E5-2690v3) |
24 (E5-2690v3) |
| GPU |
1 x M60 GPU (1/2 Physical Card) |
2 x M60 GPU (1 Physical Card) |
4 x M60 GPU (2 Physical Cards) |
| Memory |
56 GB |
112 GB |
224 GB |
| Disk |
380 GB SSD |
680 GB SSD |
1.44 TB SSD |
1.3. Цены
Цены на N-Series Azure VM выглядят следующим образом (октябрь 2016) [5]:
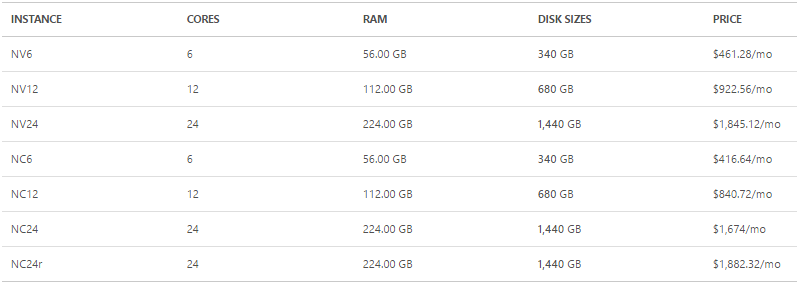
Но пусть Ваше любопытство эти 4-ехзначные числа не уменьшают: как всегда, в облаке мы платим за использование ресурсов. Для IaaS-сервисов, каковым сервис Azure VM является, это стоит понимать, как почасовая тарификация. Кроме того, в Microsoft Azure есть много способов получить золото вычислительные ресурсы совершенно бесплатно.
Это распространяется на новые учетные записи в Azure, на студентов, на стартапы, если вы ищете лекарство от рака исследователь, или если Вы/компания, в которой Вы работаете, обладатель MSDN-подписки.
2. Amazon EC2 GPU Instances (+опасное сравнение)
Облачный провайдер Amazon Web Services (AWS) начал предоставлять инстансы VM с графическими процессорами еще в 2010 году.
Еще в начале сентября (2016) GPU-инстансы AWS были представлены только семейством G2.
Конфигурации виртуальных машин семейства G2:
| Model | GPUs | vCPU | Mem (GiB) | SSD Storage (GB) | Price, per hour/month |
| g2.2xlarge | 1 | 8 | 15 | 1 x 60 | 0.65/468 |
| g2.8xlarge | 4 | 32 | 60 | 2 x 120 | 2.6/1872 |
Инстансы G2 комплектуются графическими процессорами NVidia GRID K520 с 1556 CUDA-ядрами, поддержкой 4-ех видеопотоков 1080p H.264. Заявлено о поддержке CUDA/OpenCL. Также имеется поддержка технологии HVM (hardware virtual machine), которая по аналогии с DDA в Azure VM, минимизирует издержки, связанные с виртуализацией, позволяя на гостевой VM получать производительность GPU, близкую к bare-metal-производительности.
Пока я писал статью буквально месяц назад (конец сентября 2016) AWS анонсировали P2-инстансы, содержащие более современные графические карты.
Инстансы семейство P2 могут включать в себя до 8-ми карт NVIDIA Tesla K80. Заявлено о поддержке CUDA 7.5, OpenCL 1.2. Инстансы p2.8xlarge и p2.16xlarge поддерживают высокоскоростное GPU-to-GPU соединение, а для локальной сети доступно соединение до 20 Gbps по технологии ENA (Elastic Network Adapter – высокоскоростной сетевой интерфейс для Amazon EC2).
| Instance Name | GPU Cores | vCPU Cores | Memory, Gb | CUDA Cores | GPU Memory | Network, Gbps |
| p2.xlarge | 1 | 4 | 61 | 2496 | 12 | High |
| p2.8xlarge | 8 | 32 | 488 | 19968 | 96 | 10 |
| p2.16xlarge | 16 | 64 | 732 | 39936 | 192 | 20 |
Для сравнения* возьмем самый производительный (NC24) и самый бюджетный (NC6) инстансы в Azure VM и, ближайшие по производительности к ажуровским, инстансы в Amazon EC2.
| Instance Family | GPU Model | GPU Cores | vCPU Core | RAM, Gb | Network, Gbps | CUDA/OpenCL | Status | Price, $/mo | Price, $ per GPU/mo |
| Amazon p2.xlarge | K80 | 1 | 4 | 61 | High | 7.5/1.2 | GA | 648 | 648 |
| Azure NC6 | K80 | 1 | 6 | 56 | 10 (?) | +/+ | Private preview | 461 | 461 |
| Amazon p2.8xlarge | K80 | 8 | 32 | 488 | 10 | 7.5/1.2 | GA | 5184 | 648 |
| Azure NC24 | K80 | 8 | 24 | 224 | 10 (?) | +/+ | Private preview | 1882 | 235 |
Заключение
AWS долго «мучали» data-science-сообщество довольно слабенькими и вместе с тем дорогими GPU-инстансами семейства G2. Но конкуренция на рынке облачных провайдеров сделала свое дело – месяц назад появились GPU-инстансы семейства P2, и выглядят они очень достойно.
Microsoft Azure также долго мучали коммьюнити вообще отсутствием GPU-инстансов (эта была одна из самых ожидаемых возможностей платформы Azure). На текущий момент GPU-инстансы в Azure выглядят крайне неплохо, хотя и не достает технических подробностей. Рreview-статус этой возможности –
Вообще Microsoft буквально за год-два серьезно обросла различными AI-технологиями / фреймворками/ инструментами, и в том числе (может — в первую очередь) для разработчиков и data scientist’ов. Насколько это все серьезно и удобно можно оценить самостоятельно, посмотрев записи с прошедшего в конце сентября Microsoft ML & DS Summit [6].
Кроме того, ровно через неделю – 1 ноября – пройдет конференция Microsoft DevCon School, один из треков которой полностью посвящен машинному обучению. И рассказывать там будут не исключительно про проприетарные технологии MS, а про привычные и «свободные» Python, R, Apache Spark.
Список источников
- NVIDIA GPUs in Azure: регистрация в preview-программе.
- Leveraging NVIDIA GPUs in Azure. Вебкаст на Channel 9.
- Linux GPU Instances: документация.
- Анонс P2-инстансов в AWS, 29 сентября 2016.
- Цены на Azure Virtual Machines (в т.ч. Azure VM GPU).
- Конференция Microsoft Machine Learning & Data Science Summit.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (18)

gooddaytoday
25.10.2016 12:30+1На этом фоне любопытно наблюдать за акциями NVIDEA. Они за год поднялись всего-то на 100 с небольшим процентов (до этого лет 10 находились на одной средней планке): https://www.google.com/finance?cid=662925
Но мы то с вами понимаем, что это ралли только началось ;)yul
25.10.2016 14:21Хм, на 5-летнем графике с $20 в середине 2015 до почти $70, это уже порядка 250%. В общем, ожидаемо, практически подмяли игровой рынок под себя, да и облака тоже. Хотя в приставках пока AMD/ATi, но если в следующем поколении поставят nVidia… Где бы их акции прикупить ;)
gooddaytoday
25.10.2016 16:58+1В любом брокере. Можно даже с левериджем, благо скачки позволяют.
Плюсом:
1. Nintendo выпустила новую приставку формата iPad+джойстик и там будет Nvidea.
2. У них итак 70% рынка,
3. У AMD нет ни p/e, ни дивидендов, Nvidea — есть.

ivan2kh
25.10.2016 20:50Виртуальные машины с GPU есть у всех основных игроков: Google, Azure, AWS. Напишите тогда success story, как простому смертному купить эти виртуалки (хотя бы за пару недель), потому что моя история пока напоминает известный фильм про Бразилию. Чего они так боятся?
yul
26.10.2016 14:27Ну, я недавно брал на амазоне попробовать, просто пришлось создать тикет, чтобы увеличили лимит на количество инстансов этого типа (по умолчанию 0), с указанием цели использования и планируемых сроков. Разрешили в тот же день, больше проблем не было. Немного странно, да. Скорее всего, машин пока не слишком много и они перестраховываются с планированием.
senya_z
25.10.2016 21:16Когда я последний раз слышал про виртуальные машины с GPU, Амазон их продавал с условием, что клиент выкупает всю физическую машину, где виртуалки хостятся и видеокарты установлены. Связано это было с невозможностью виртуализировать GPU из-за его DMA, что не позволяло гарантировать другим тенантам того, что в область физической памяти, выделенной лично им, не сможет добраться код, выполняемый на GPU. Это уже как-то решили? Или все так же надо выкупать хост?
yul
26.10.2016 14:28У меня такого не было, поднимается обычный виртуальный инстанс с почасовой оплатой, по крайней мере с windows. В немецком дата-центре что-то порядка $0.9/час за g2.2xlarge
senya_z
26.10.2016 19:50тут скорее вопрос в том, мог ли кто-то еще в это же время использовать инстансы, поднятые на том же хосте. то есть, выкуплен ли хост целиком за эти 90 центов в час.

markhor
26.10.2016 09:30Очень полезная презентация про подбор ресурсов для глубокого обучения, которая совпадает с моим мнением и которую только что опробовали на практике: http://www.slideshare.net/PetteriTeikariPhD/deep-learning-workstation
Резюме: в топку облака, Titan X 2016 рулит своим Паскалем и ценой, SuperMicro подходит идеально.
yul
26.10.2016 14:45Что-то непонятное у вас с ценами на амазоне. p2.xlarge в N.Virginia стоит $499/месяц при резерве на год, цена по требованию — $0.9/час ($648/месяц), ну и там разные варианты предоплаты есть, а с виндой так еще дороже, откуда $306 в таблице? p2 у вас выходит дешевле, чем g2 ($468/mo)…

codezombie
26.10.2016 18:51Математика простая: беру цену за час из прайса AWS/Azure и умножаю на 720 (приблизительное число часов в месяц).
Дальше считаю по максимально общему сценарию: спотовая цена ввиду слабой предсказуемости не рассматривается; поправки, на историю, что GPU-инстанс возьмут на год вперед, также не делаю.yul
26.10.2016 22:08Ну и как у вас так получилось $306/месяц за p2.xlarge при цене $0.9/час?
codezombie
26.10.2016 23:35Судя по тому, что ошибка повторяется для всех p2-инстансов и только для AWS, Amazon изменила цены. Поправил. Спасибо, что заметили.
gaploid
Вы сравниваете Vcpu у Амазона( гипертредовые ядра) и физические ядра у Azure.
Labunsky
Azure не особо распространяется, что именно там за ядра, да и производительность их довольно скромна, так что вполне корректное сравнение
gaploid
Ну так знайте в Azure логические ядра, а в Amazon виртуальные(гипертрединговые) ну или shared.
Labunsky
Я в курсе, спасибо. А что это за логические ядра, какие они — кто-нибудь знает?
И в чем преимущество, если производительность этих логических ядер а) низкая; б) плывет от инстанса к инстансу?