
Стандартный план любого хакатона v

В эти выходные пройдет хакатон по машинному обучению, организатором которого является компания Microsoft. У участников хакатона будет 2 дня для того, чтобы крепко не выспаться и сделать мир лучше.
Повествование в этой статье будет проходить в такой же стремительной манере, в какой, как я полагаю, для большинства участников и пройдет хакатон. Никакой воды (если вы не знакомы с Azure ML, то «воду» или какой-то ознакомительный материал лучше все-таки почитать), долгих определений и таких длинных вступлений как это — только то, что вам нужно, чтобы победить на хакатоне.
1)Захватите найдите кофемашину.
2) У вас всего 2 дня, поэтому не надогородить огород сложных моделей: они легко переучиваются и их долго делать. Возьмите самое наивное предположение и итеративно усложняйте его. На каждой успешной итерации сохраните набор данных, подаваемых на алгоритм машинного обучения, и полученную в результате обучения модель. Это делается с помощью пунктов меню «Save as Dataset», «Save Model» в контекстном меню Azure ML Studio (это web IDE). Таким образом, у вас будут пары dataset–trained_model на каждую из итераций.
Создайте уже Workspace! Откройте manage.windowsazure.com, выберите Azure ML и создайте быстрей Workspace. Один на всю команду, а не каждому свой персональный! Соберите у всех участников email’ы и расширьте Workspace между ними.

Внесите Ваш вклад в глобальное потепление
Ниже показано, как выглядит простейший граф обучения в Azure ML.
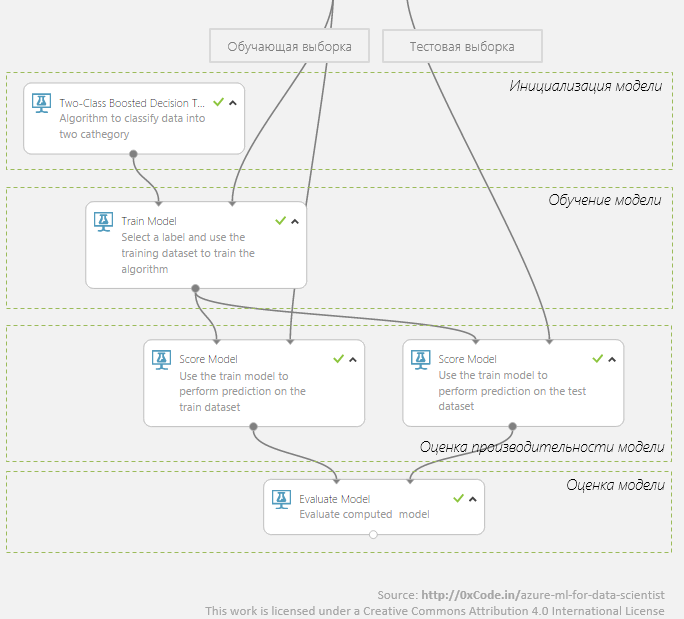
Но это не то! Так вы будете делать дома: запускать, пить чай, уходить гулять, приходить, смотреть что получилось, думать, чесать плечо, снова запускать, пить чай… На хакатоне на это времени нет!
Проверьте сразу все алгоритмы, которые могут подойти. Именно «все» — это же Azure, а не ваш домашний ноутбук! Датацентры Azure будут греть атмосферу западного побережья США, но процесс обучения моделей выполнят! Вот пример такого, как это должно выглядеть на 5-ти алгоритмах двухклассовой классификации.

Сравнение моделей, обученных на алгоритме логистической регрессии (синяя кривая) и методе опорных векторов (красная кривая):

Cross Validation
Включите уже кросс-валидацию! И включите ее правильно: с validation dataset, с fold’ами, c указанием метрики, которую хотите максимизировать (т.е. так, как показано на иллюстрации с кросс-валидацией).
Включив кросс-валидацию, вы узнаете, какой потенциально возможный лучший результат может показать алгоритм машинного обучения на ваших данных, и поймете насколько этот алгоритм стабильно работает (чем меньше величина стандартного отклонения, тем более стабильный результат показывает алгоритм).
Результаты для каждого fold'а:

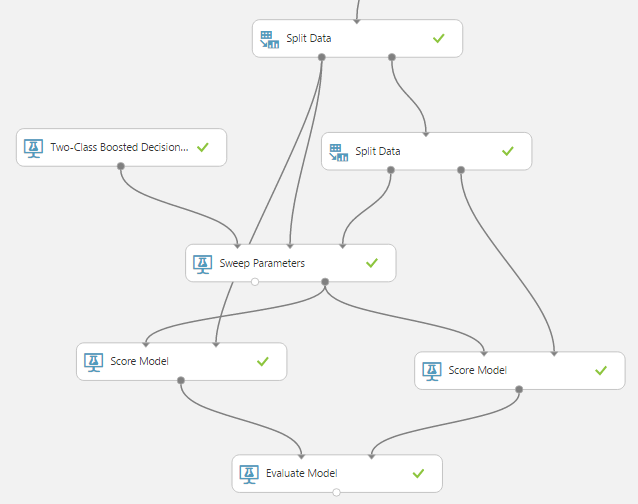
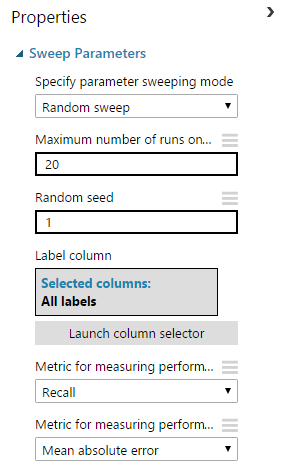
Sweep Parameters
Ключевое влияние на производительность (performance) модели оказывают параметры алгоритма машинного обучения. Так для нейронной сети это количество скрытых слоев нейронов, начальные веса, для дерева решений – количество деревьев, количество листьев на дерево.
Перебором вручную нескольких параметров для 4-ех алгоритмов классификации, в условиях бьющего фонтана новых идей, вы будете заниматься до нового года (а может и во время). Займитесь в новый год чем-то другим! А на хакатоне используйте встроенный модуль Sweep Parameters.
Настройки модулей:

Fair Data Split
Разделите тестовый и тренировочные наборы (модуль Split). В зависимости от объема располагаемых данных в data science принято оставлять в тестовом наборе от 10% до 30% данных. Незанимайтесь самообманом учите модель на тестовом наборе, не используйте его для проверки результатов кросс-валидации. Тестовый dataset вам нужен только для одного – проверка финальной модели.
Ускорьте обучение
Чем быстрее по времени ваша модель учиться, тем больше гипотез вы успеете проверить. Используйте модули из раздела Feature Selection, чтобы не только уменьшить время обучения, но получить наиболее релевантные предикторы и обобщить модель (сделать ее производительность на реальных данных лучше).
Так, используя модуль filter-based feature selection в задаче определения тональности твитов, я уменьшил количество предикторов с 160К до 20К.
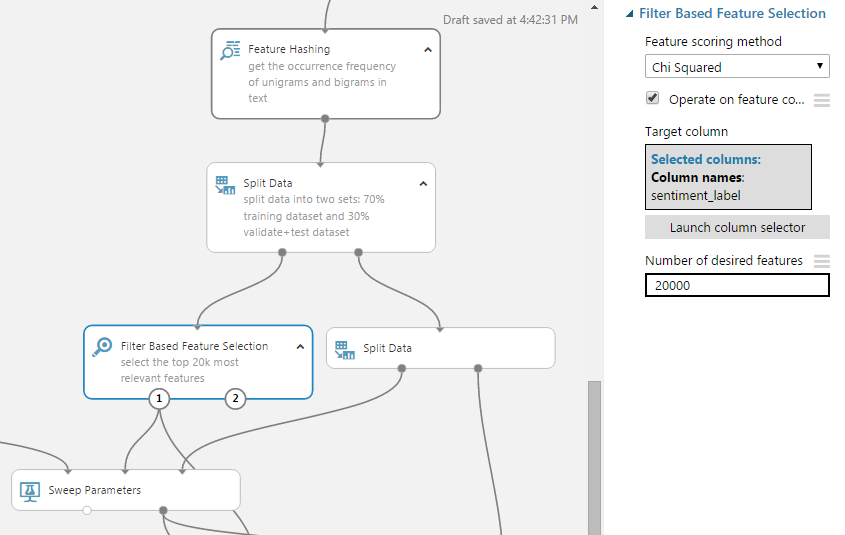
Результат — см. количество предикторов (columns) до и после фильтрации:


А модуль fisher linear discriminant помог мне уменьшить Iris Dataset c матрицы 4xN до 2xN, где N – количество наблюдений.
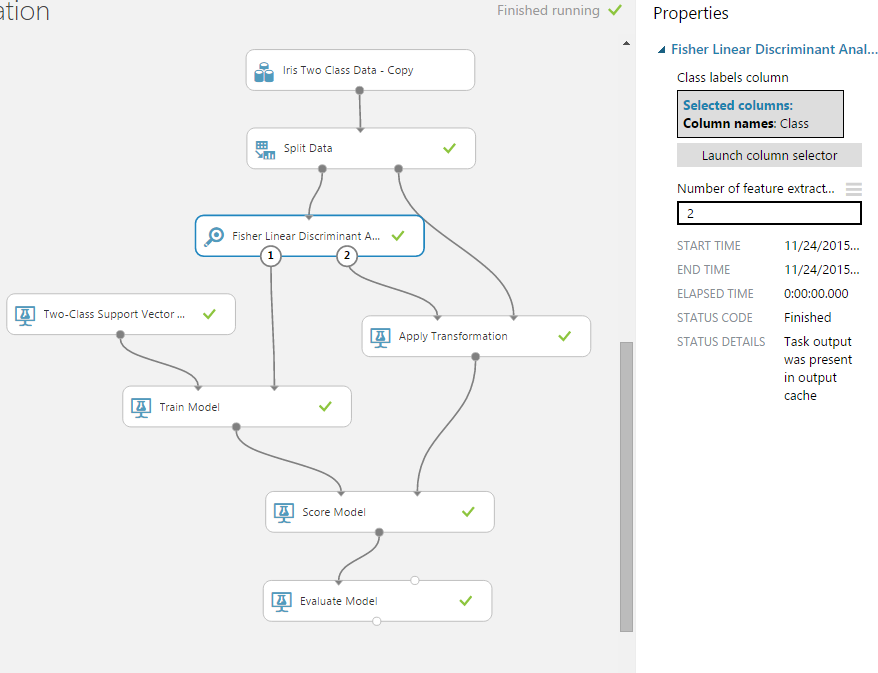
Результат — см. количество предикторов (columns) до и после фильтрации:


Ускорьте обучение. Часть 2
Azure ML может выполнять ваши R/Python-скрипты. Так из коробки есть поддержка ~400 R-пакетов, экспорт в Python Notebooks и это только начало.
Но(!) не пишите R/Python-скрипты просто потому, что вам лень разбираться какой встроенные в Azure ML модуль делает тоже самое. Встроенные модули:
Не умоляя ваше программистского таланта, замечу, что ваш чудесно написанный python-скрипт, так выполниться вряд ли сможет, т.к. для Azure ML такой скрипт — черный ящик.
Feature Engineering
Поймите Ваши данные! Для этого в Azure ML есть как инструменты по визуализации, так и возможность использовать ggplot2. Кроме того не пренебрегайте модулем описательной статистики «Descriptive Statistics», который на любом этапе работы с экспериментом вам может рассказать многое о данных.
Pre-processing
Разметьте данные правильно – используйте модуль Metadata Editor.
Модуль Clean Missing Data вам поможет справиться с пропущенными данными (удалить их, заменить на значение по умолчанию, медиану или моду).
Обнаружить выбросы поможет раздел Anomaly Detection и просто визуализация.
Нормализуйте (хотя бы попытайтесь) все числовые данные, чье распределение отличается от нормального, с помощью модуля Normalize. C помощью того же модуля шкалируйте (scale) все числовые данные, чьи абсолютные значения велики.
Джедайские техники
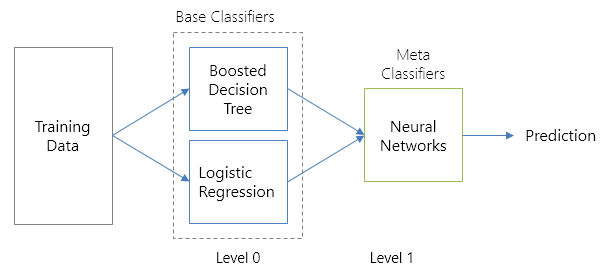
Джедайские техники: Boosting и Stacking
Сразу к терминологии:
Boosting (бустинг) – подход, в котором результат является взвешенной / рассчитанной по эмпирической формуле оценкой нескольких различных моделей.
Stacking (стэкинг) – подход похожий на бустинг: вы также имеет несколько моделей, обученных на данных, но у вас уже нет никакой эмпирической формулы – вы на основе оценок изначальных моделей строите метамодель.
Это очень крутые техники, которые во всю используют data scientist’ы 80-го уровня с kaggle. Встроенных модулей, реализующих бустинг или стэкинг (или просто bagging), в Azure ML нет. Их реализация не сильно сложна, но имеет свои длинный список тонкостей.
Вот как у меня выглядит применение стэкинга для создания метамодели, обученной с помощью нейросети на классификаторах Boosted Decision Tree и логистической регрессии.
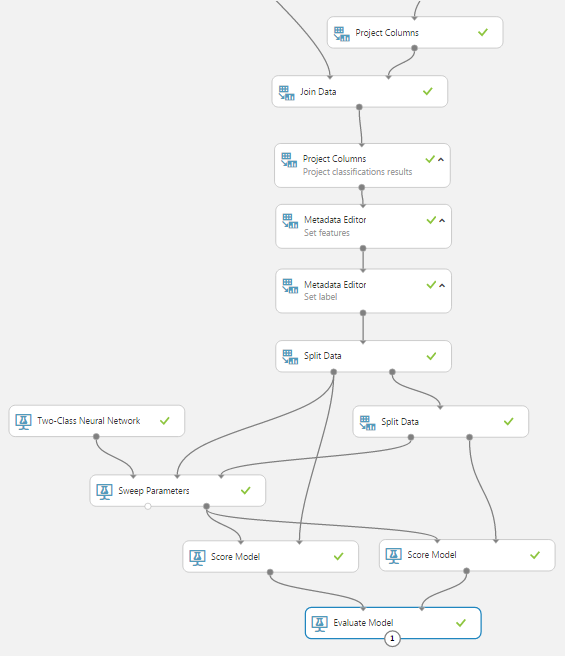
Принципиальная схема, реализованного стэкинга:
Уровень 1:

Уровень 2:
Реализация boosting- и stacking-подходов в Azure ML — тема отдельной интересной статьи, которую не получится раскрыть в рамках этой статьи. Но(!) во второй день хакатона вы сможете меня найти (нижний справа на странице докладчиков хакатона; буду выглядеть также плохо, как и на фото), и я обязательно покажу, как добавить stacking к вашей модели и возможно улучшить ее производительность на важные для таких мероприятий пару-тройку-пятерку процентов.
Джедайские техники: Hadoop/HBase/Spark-кластер
Я не шучу: вам нужен кластер! Но не спешите покупать железки и начинать развертывать/администрировать всю богатую на программные продукты экосистему Hadoop. Это долго, дорого и… хорошо. А нам нужно быстро и хорошо, т.е. HDInsight.
Azure HDInsight – облачный сервис, предоставляющий кластер Hadoop/HBase/Spark по требованию. Прохождение мастера создания кластера занимает 2 минуты, само создание кластера идет в Azure1 кружку кофе ~10 минут.
Но самое вкусное то, что HBase (если совсем точно, то Hive-запросы) поддерживается как один из источников данных в Azure ML. Так что если данных много и по ним нужно делать сложные запросы, то не раздумывая развертывайте HBase-кластер в Azure и загружайте данные в Azure ML напрямую оттуда.
Джедайские техники: Data Science VM
Воспользуйтесь одним из образов виртуальной машины, доступных в Azure VM – образом «Data Science VM» с предустановленным Revolution R Open, Anaconda Python, Power BI и многим другим.
Не ограничивайте себя любимого: возьмите виртуалку с нужным объемом памяти (доступно до 448 Гб RAM), количеством ядер (доступно до 32-ядрами), и, если нужно, SSD-диском. В общем создайте себе удобные условия работы.
Участвуйте не ради призов
Хакатон – то, мероприятия на которое стоит ходить ради атмосферы, ради общения с единомышленниками, знакомств с экспертами, халявного кофе и, если на улице холодно, а жить негде. Общайтесь, обменивайтесь опытом! (Все равно победит самый хитрый.)
Кстати про общение, завтра пройдет Moscow Data Science Meetup – наиотличнейшее мероприятие в наиприятнейшем формате для data scientist’ов и тех, кому эта область интересна.
В эти выходные пройдет хакатон по машинному обучению, организатором которого является компания Microsoft. У участников хакатона будет 2 дня для того, чтобы крепко не выспаться и сделать мир лучше.
Повествование в этой статье будет проходить в такой же стремительной манере, в какой, как я полагаю, для большинства участников и пройдет хакатон. Никакой воды (если вы не знакомы с Azure ML, то «воду» или какой-то ознакомительный материал лучше все-таки почитать), долгих определений и таких длинных вступлений как это — только то, что вам нужно, чтобы победить на хакатоне.
Keep it simple
1)
2) У вас всего 2 дня, поэтому не надо
О структуре статьи
Это более или менее стандартный workflow обучения с учителем. Я начну c самого вкусного – с сердца этого процесса – обучения модели (Train model), постепенно двигаясь к этапу предварительной обработки данных (Pre-processing data).

Collaboration
Создайте уже Workspace! Откройте manage.windowsazure.com, выберите Azure ML и создайте быстрей Workspace. Один на всю команду, а не каждому свой персональный! Соберите у всех участников email’ы и расширьте Workspace между ними.
Внесите Ваш вклад в глобальное потепление
Ниже показано, как выглядит простейший граф обучения в Azure ML.
Но это не то! Так вы будете делать дома: запускать, пить чай, уходить гулять, приходить, смотреть что получилось, думать, чесать плечо, снова запускать, пить чай… На хакатоне на это времени нет!
Проверьте сразу все алгоритмы, которые могут подойти. Именно «все» — это же Azure, а не ваш домашний ноутбук! Датацентры Azure будут греть атмосферу западного побережья США, но процесс обучения моделей выполнят! Вот пример такого, как это должно выглядеть на 5-ти алгоритмах двухклассовой классификации.
Сравнение моделей, обученных на алгоритме логистической регрессии (синяя кривая) и методе опорных векторов (красная кривая):
Cross Validation
Включите уже кросс-валидацию! И включите ее правильно: с validation dataset, с fold’ами, c указанием метрики, которую хотите максимизировать (т.е. так, как показано на иллюстрации с кросс-валидацией).
Включив кросс-валидацию, вы узнаете, какой потенциально возможный лучший результат может показать алгоритм машинного обучения на ваших данных, и поймете насколько этот алгоритм стабильно работает (чем меньше величина стандартного отклонения, тем более стабильный результат показывает алгоритм).
Результаты для каждого fold'а:
Sweep Parameters
Ключевое влияние на производительность (performance) модели оказывают параметры алгоритма машинного обучения. Так для нейронной сети это количество скрытых слоев нейронов, начальные веса, для дерева решений – количество деревьев, количество листьев на дерево.
Перебором вручную нескольких параметров для 4-ех алгоритмов классификации, в условиях бьющего фонтана новых идей, вы будете заниматься до нового года (а может и во время). Займитесь в новый год чем-то другим! А на хакатоне используйте встроенный модуль Sweep Parameters.
Настройки модулей:
Fair Data Split
Разделите тестовый и тренировочные наборы (модуль Split). В зависимости от объема располагаемых данных в data science принято оставлять в тестовом наборе от 10% до 30% данных. Не
Ускорьте обучение
Чем быстрее по времени ваша модель учиться, тем больше гипотез вы успеете проверить. Используйте модули из раздела Feature Selection, чтобы не только уменьшить время обучения, но получить наиболее релевантные предикторы и обобщить модель (сделать ее производительность на реальных данных лучше).
Так, используя модуль filter-based feature selection в задаче определения тональности твитов, я уменьшил количество предикторов с 160К до 20К.
Результат — см. количество предикторов (columns) до и после фильтрации:
А модуль fisher linear discriminant помог мне уменьшить Iris Dataset c матрицы 4xN до 2xN, где N – количество наблюдений.
Результат — см. количество предикторов (columns) до и после фильтрации:
Ускорьте обучение. Часть 2
Azure ML может выполнять ваши R/Python-скрипты. Так из коробки есть поддержка ~400 R-пакетов, экспорт в Python Notebooks и это только начало.
Но(!) не пишите R/Python-скрипты просто потому, что вам лень разбираться какой встроенные в Azure ML модуль делает тоже самое. Встроенные модули:
- оптимизированы под Azure ML (скорее всего большинство из них написано на С++, что звучит, как «это быстро»);
- работа внутри них потенциально распараллеливается и выполняется распределено (т.к. заранее известно какие модули выполняют параллельные по данным задачи, а какие нет);
- алгоритмы машинного обучения, реализованные во встроенных модулях, также потенциально могут быть LSML-историей (выполняться распределено на кластере).
Не умоляя ваше программистского таланта, замечу, что ваш чудесно написанный python-скрипт, так выполниться вряд ли сможет, т.к. для Azure ML такой скрипт — черный ящик.
Feature Engineering
Поймите Ваши данные! Для этого в Azure ML есть как инструменты по визуализации, так и возможность использовать ggplot2. Кроме того не пренебрегайте модулем описательной статистики «Descriptive Statistics», который на любом этапе работы с экспериментом вам может рассказать многое о данных.
Pre-processing
Разметьте данные правильно – используйте модуль Metadata Editor.
Модуль Clean Missing Data вам поможет справиться с пропущенными данными (удалить их, заменить на значение по умолчанию, медиану или моду).
Обнаружить выбросы поможет раздел Anomaly Detection и просто визуализация.
Нормализуйте (хотя бы попытайтесь) все числовые данные, чье распределение отличается от нормального, с помощью модуля Normalize. C помощью того же модуля шкалируйте (scale) все числовые данные, чьи абсолютные значения велики.
Джедайские техники
Джедайские техники: Boosting и Stacking
Сразу к терминологии:
Boosting (бустинг) – подход, в котором результат является взвешенной / рассчитанной по эмпирической формуле оценкой нескольких различных моделей.
Stacking (стэкинг) – подход похожий на бустинг: вы также имеет несколько моделей, обученных на данных, но у вас уже нет никакой эмпирической формулы – вы на основе оценок изначальных моделей строите метамодель.
Это очень крутые техники, которые во всю используют data scientist’ы 80-го уровня с kaggle. Встроенных модулей, реализующих бустинг или стэкинг (или просто bagging), в Azure ML нет. Их реализация не сильно сложна, но имеет свои длинный список тонкостей.
Вот как у меня выглядит применение стэкинга для создания метамодели, обученной с помощью нейросети на классификаторах Boosted Decision Tree и логистической регрессии.
Принципиальная схема, реализованного стэкинга:
Уровень 1:
Уровень 2:
Реализация boosting- и stacking-подходов в Azure ML — тема отдельной интересной статьи, которую не получится раскрыть в рамках этой статьи. Но(!) во второй день хакатона вы сможете меня найти (нижний справа на странице докладчиков хакатона; буду выглядеть также плохо, как и на фото), и я обязательно покажу, как добавить stacking к вашей модели и возможно улучшить ее производительность на важные для таких мероприятий пару-тройку-пятерку процентов.
Джедайские техники: Hadoop/HBase/Spark-кластер
Я не шучу: вам нужен кластер! Но не спешите покупать железки и начинать развертывать/администрировать всю богатую на программные продукты экосистему Hadoop. Это долго, дорого и… хорошо. А нам нужно быстро и хорошо, т.е. HDInsight.
Azure HDInsight – облачный сервис, предоставляющий кластер Hadoop/HBase/Spark по требованию. Прохождение мастера создания кластера занимает 2 минуты, само создание кластера идет в Azure
Но самое вкусное то, что HBase (если совсем точно, то Hive-запросы) поддерживается как один из источников данных в Azure ML. Так что если данных много и по ним нужно делать сложные запросы, то не раздумывая развертывайте HBase-кластер в Azure и загружайте данные в Azure ML напрямую оттуда.
Джедайские техники: Data Science VM
Воспользуйтесь одним из образов виртуальной машины, доступных в Azure VM – образом «Data Science VM» с предустановленным Revolution R Open, Anaconda Python, Power BI и многим другим.
Не ограничивайте себя любимого: возьмите виртуалку с нужным объемом памяти (доступно до 448 Гб RAM), количеством ядер (доступно до 32-ядрами), и, если нужно, SSD-диском. В общем создайте себе удобные условия работы.
Подглядывайте через плечо. Стройте заговоры. Найдите нефть!
Участвуйте не ради призов
Хакатон – то, мероприятия на которое стоит ходить ради атмосферы, ради общения с единомышленниками, знакомств с экспертами, халявного кофе и, если на улице холодно, а жить негде. Общайтесь, обменивайтесь опытом! (Все равно победит самый хитрый.)
Кстати про общение, завтра пройдет Moscow Data Science Meetup – наиотличнейшее мероприятие в наиприятнейшем формате для data scientist’ов и тех, кому эта область интересна.
Комментарии (4)

Alexey_mosc
30.11.2015 11:59Статья помогла. Мы вместе с goodok впервые работали с Azure ML и взяли первое место благодаря не переобученной staking модели.

monah_tuk