
Если вы когда-нибудь задумывались о доверии и надежде, то скорее всего, не испытывали этого ни к чему так же сильно, как к системам управления базами данных. Ну и действительно, это же База Данных! В названии содержится весь смысл — место, где хранятся данные, основная задача ХРАНИТЬ. И что самое печальное, как всегда, однажды, эти убеждения разбиваются об останки такой одной умершей БД на 'проде'.
И что же делать? — спросите вы. Не деплоить на сервера ничего, — отвечаем мы. Ничего, что не умеет само себя чинить, хотя бы временно, однако надежно и быстро!
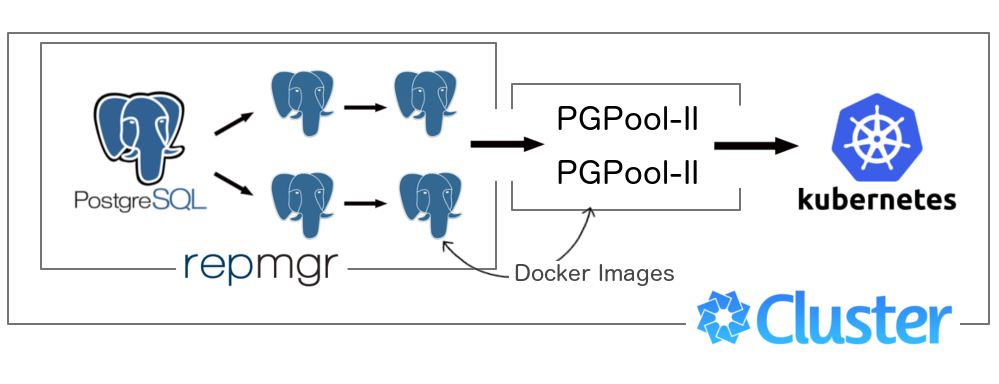
В этой статье я попробую рассказать о своем опыте настройки почти бессмертного Postgresql кластера внутри другого отказоустойчивого решения от Google — Kubernetes (aka k8s)
Содержание
Статья вышла немного больше чем ожидалось, а потому в коде много ссылок, в основном на код, в контексте которого идет речь.
Дополнительно прилагаю оглавление, в том числе для нетерпеливых, чтобы сразу перейти к результатам:
- Задача
- Решение методом "Гугления"
- Консолидация и сборка решения
- Результат
- Документация и использованный материал
Задача
Потребность иметь хранилище с данными для почти любого приложения — необходимость. А иметь это хранилище устойчивым к невзгодам в сети или на физических серверах — хороший тон грамотного архитектора. Другой аспект — высокая доступность сервиса даже при больших конкурирующих запросах на обслуживание, что означает легкое масштабирование при необходимости.

Итого получаем проблемы для решения:
- Физически распределенный сервис
- Балансировка
- Не ограниченное масштабирование путем добавление новых узлов
- Автоматическое восстановление при сбоях, уничтожении и потери связи узлами
- Отсутствие единой точки отказа
Дополнительные пункты, обусловленные спецификой религиозных убеждений автора:
- Postgres (наиболее академическое и консистентное решение для РСУБД среди бесплатных доступных)
- Docker упаковка
- Kubernetes описание инфраструктуры
На схеме это будет выглядеть примерно так:
master (primary node1) --|- slave1 (node2) ---\ / balancer \
| |- slave2 (node3) ----|---| |----client
|- slave3 (node4) ---/ \ balancer /
|- slave4 (node5) --/При условии входных данных:
- Большее число запросов на чтение (по отношению к записи)
- Линейный рост нагрузки при пиках до x2 от среднего
Решение методом "Гугления"
Будучи, искушенным в решении IT проблем, человеком, я решил спросить у коллективного разума: "postgres cluster kubernetes" — куча мусора, "postgres cluster docker" — куча мусора, "postgres cluster" — несколько вариантов, из которых пришлось воять.

Что меня расстроило, так это отсутствие вменяемых Docker сборок и описание любого варианта для кластеризации. Не говоря уже о Kubernetes. Кстати говоря, для Mysql вариантов было не много, но все же были. Как минимум понравился пример в официальном репозитории k8s для Galera(Mysql cluster)
Гугл дал ясно понять, что проблемы придется решать самому и в ручном режиме..."но хоть с помощью разрозненных советов и статей" — выдохнул я.
Плохие и непреемлимые решения
Сразу замечу, что все пункты в этом параграфе могут быть субъективными и, вполне даже, жизнеспособными. Однако, полагаясь на свой опыт и чутье, мне пришлось их отсечь.

Когда кто-то делает универсальное решение (для чего бы то ни было), мне всегда кажется, что такие вещи громоздки, неповоротливы и тяжелы в обслуживании. Так же вышло и с Pgpool, который умеет почти все:
- Балансировка
- Хранение пачки коннектов для оптимизации соединения и скорости доступа к БД
- Поддержка разных вариантов репликации (stream, slony)
- Авто определение Primary сервера для записи, что важно при реорганизации ролей в кластере
- Поддержка failover/failback
- Cобственная репликация master-master
- Согласованная работа нескольких узлов Pgpool-ов для искоренения единой точки отказа.
Первые четыре пункта я нашел полезными, и остановился на том, поняв и обдумав проблемы остальных:
- Восстановление с помощью Pgpool2 не предлагает никакой системы принятия решения о следующем мастере — вся логика должна быть описана в командах failover/failback
- Время записи, при репликации master-master, сводится к удвоенному по отношению варианта без него, вне зависимости от количества узлов… ну хоть не растет линейно
- Как построить каскадный кластер (когда один slave читает с предыдущего slave) — вообще не понятно
- Конечно же хорошо, что Pgpool знает о своих братьях и может оперативно становиться активным звеном при проблемах на соседнем узле, но эту проблему для меня решает Kubernetes, который гарантирует аналогичное поведение для, вообще, любого сервиса установленного в него.
Собственно, тоже почитав и сравнив найденное с уже знакомой и работающей "из коробки" поточной репликацией (Streaming Replication), легко далось решение даже не думать о Слонах.
Да и ко всему прочему, на первой же странице сайта проекта ребята пишут что, с postgres 9.0+ вам не нужны Slony при условии отсутствия неких специфичных требований к системе:
- частичная репликация
- интеграция с другими решениями ("Londiste and Bucardo")
- дополнительное поведение при репликации
Вообщем, мне кажется Slony не торт… как минимум если у вас нет этих самых трех специфичных задач.
Осмотревшись вокруг и разобравшись в вариантах подхода идеальной двусторонней репликации, оказалось, что жертвы не совместимы с жизнью некоторых приложений. Не говоря о скорости, есть ограничения в работе с транзакциями, сложными запросами (SELECT FOR UPDATE и другие).
Вполне вероятно, я не так искушен именно в этом вопросе, но увиденного мне хватило, чтобы тоже оставить эту идею. И еще раскинув мозгами, мне показалось, что для системы с усиленной операцией записи нужны совершенно другие технологии, а не реляционные базы данных.
Консолидация и сборка решения
В примерах я буду говорить о том, как принципиально должно выглядеть решение, а в коде — как это вышло у меня. Для создания кластера вовсе не обязательно иметь Kubernetes (есть пример docker-compose) или Docker в принципе. Просто тогда, все описанное будет полезно, не как решение типа CPM (Copy-Paste-Modify), а как руководство по установке cо снипетами.
Primary и Standby вместо Master и Slave
Почему же коллеги из Postgresql отказались от терминов "Master" и "Slave"?.. хм, могу ошибаться, но ходил слух, что из-за не-полит-корректности, мол, что рабство это плохо. Ну и правильно.

Первое что нужно сделать — включить Primary сервер, за ним первый слой Standby, а за тем второй — все согласно поставленной задачи. Отсюда получаем простую процедуру по включению обычного Postgresql сервера в режиме Primary/Standby с конфигурацией для включения Streaming Replication
wal_level = hot_standby
max_wal_senders = 5
wal_keep_segments = 5001
hot_standby = onВсе параметры в комментариях имеют краткое описание, но если вкратце, эта конфигурация дает серверу понять, что он отныне часть кластер и, в случае чего, нужно позволить читать WAL логи другим клиентам. Плюс разрешить запросы во время восстановления. Отличное описание по подробной настройке такого рода репликации можно найти на Postgresql Wiki.
Как только мы получили первый сервер кластера, можем включать Stanby, который знает, где находится его Primary.
Моя задача здесь свелась к сборке универсального образа Docker Image, который включается в работу, в зависимости от режима, как то так:
- Для Primary:
- Конфигурирует Repmgr (о нем немного позже)
- Создает базу и пользователя для приложения
- Создает базу и пользователя для мониторинга и поддержки репликации
- Обновляет конфиг(
postgresql.conf) и открывает доступ пользователям извне(pg_hba.conf) - Запускает Postgresql сервис в фоне
- Регистрируется как Master в Repmgr
- Запускает
repmgrd— демон от Repmgr для мониторинга репликации (о нем тоже позже)
- Для Standby:
- Клонирует Primary сервер с помощью Repmgr (между прочим со всеми конфигами, так как просто копирует
$PGDATAдиректорию) - Конфигурирует Repmgr
- Запускает Postgresql сервис в фоне — после клонирования сервис вменяемо осознает, что является standby и покорно следует за Primary
- Регистрируется как Slave в Repmgr
- Запускает
repmgrd
- Клонирует Primary сервер с помощью Repmgr (между прочим со всеми конфигами, так как просто копирует
Для всех этих операций важна последовательность, и посему в коде напиханы sleep. Знаю — не хорошо, но так удобно конфигурировать задержки через ENV переменные, когда нужно разом стартануть все контейнеры (например через docker-compose up )
Все переменные к этому образу описаны в docker-compose файле.
Вся разница первого и второго слоя Standby сервисов в том, что для второго мастером является любой сервис из первого слоя, а не Primary. Не забываем, что второй эшелон должен стартовать после первого с задержкой во времени.
Split-brain и выборы нового лидера в кластере
Split brain — ситуация, в которой разные сегменты кластера могут создать/избрать нового Master-a и думать, что проблема решена.

Это одна, но далеко не единственная проблема, которую мне помог решить Repmgr.
По сути это менеджер, который умеет делать следующее:
- Клонировать Master (master — в терминах Repmgr) и автоматически настоить вновьрожденный Slave
- Помочь реанимировать кластер при смерти Master-а.
- В автоматическом или ручном режиме Repmgr может избрать нового Master-а и перенастроить все Slave сервисы следовать за новым лидером.
- Выводить из кластера узлы
- Мониторить здоровье кластера
- Выполнять команды при событиях внутри кластера
В нашем случае на помощь приходит repmgrd который запускается основным процессом в контейнере и следит за целостностью кластера. При ситуации, когда пропадает доступ к Master серверу, Repmgr пытается проанализировать текущую структуру кластера и принять решение о том, кто станет следующим Master-ом. Естественно Repmgr достаточно умен чтобы не создать ситуацию Split Brain и выбрать единственно правильного Master-а.
Pgpool-II — swiming pool of connections
Последняя часть системы — Pgpool. Как я писал в разделе о плохих решениях, сервис все же делает свою работу:
- Балансирует нагрузку между всеми уздами кластера
- Храннит дескрипторы соединений для оптимизации скорости доступа к БД
- При нашем случае Streaming Replication — автоматически находит Master и использует его для запросов на запись.

Как исход, у меня получился довольно простой Docker Image, который при старте конфигурирует себя на работу с набором узлов и пользователей, у которых будет возможность проходить md5 авторизацию сквозь Pgpool (c этим тоже, как оказалось, не все просто)
Очень часто возникает задача избавиться от единой точки отказа, и в нашем случае — этой точкой является pgpool сервис, который проксирует все запросы и может стать самым слабым звеном на пути доступа к данным.
К счастью, в этом случае нашу проблему решает k8s и позволяет сделать столько репликаций сервиса сколько нужно.
В примере для Kubernetes к сожалению этого нет, но если вы знакомы c тем как работает Replication Controller и/или Deployment, то провернуть вышеописанное вам не составит труда.
Результат
Эта статья — не пересказ скриптов для решения задачи, но описание структуры решения этой самой задачи. Что означает — для более глубокого понимания и оптимизации решения придется почитать код, как минимум README.md в github, который пошагово и дотошно рассказывает как запустить кластер для docker-compose и Kubernetes. Ко всему прочему, для тех, кто проникнется и решится с этим двигаться дальше, я готов протянуть виртуальную руку помощи.

- Исходники и документация на GitHub
- Docker Image для cluster-ready Postgresql из примера
- Docker Image для Pgpool c настройкой через ENV переменные
Документация и использованный материал
PS:
Надеюсь, что изложенный материал будет полезен и подарит немного позитива перед началом лета! Удачи и хорошего настроения, коллеги ;)
Комментарии (14)

rostel
31.05.2016 15:02Года полтора назад, пощупав pgpool-II, понял что с «подготовленными выражениями» он не дружит.
Может я его готовить не умею.
throttle
31.05.2016 15:02Вот такой любопытный вопрос меня давно мучает, глядя на подобные решения — а что если подобное решение нужно размазать равномерным слоем на 2 ДЦ? И, самое интересное, что произойдет, если связь между ДЦ сломается?
Скажем, в каждом ДЦ остался отдельный, изолированный инстанс repmgr. Выбрал из оставшихся узлов нового мастера. А дальше как? Если предположить, что приложение, использующее СУБД тоже равномерно размазано на 2 ДЦ, и способно обслуживать запросы.
Мне видится только вариант оставлять один из изолированных сегментов в рид онли, но хочется верить, что тут я ошибаюсь, и есть какие-то изящные решения.
ZmeeeD
31.05.2016 15:10Это и есть состояние Split brain, и, вроде как, repmgr пытется решить эту проблему но опять же есть нюансы, и по факту так и есть сегмент может остаться в RO режиме, при чем outdated. (исходя из опытов что я ставил)
Ко всему прочему repmgr предлагает witness режим сервера — но в этом нет необходимости, если в этих двух разных ДЦ не одинаковое число серверов.

Melkij
31.05.2016 15:12Классика CAP-теоремы. Если вы хотите систему, устойчивую к разделению и с сохранением доступности — вы должны отказаться от консистентности данных. Значит ваше приложение должно всегда иметь в виду, что у вас может быть несколько наборов противоречащих себе данных, но все они верны, просто случился split brain. И что-нибудь придумываете по поводу, как эти данные синхронизировать после восстановления связи. Например, писать метку времени и оставлять только самую свежую копию. Просто так выкидывать данные как-то не очень интересно, поэтому сильно специфично для конкретного приложения.
throttle
31.05.2016 16:16Если вы хотите систему, устойчивую к разделению и с сохранением доступности — вы должны отказаться от консистентности данных.
Отож и оно. Но от консистентности отказываться нельзя, т.к. это финансовые данные.
Просто так выкидывать данные как-то не очень интересно, поэтому сильно специфично для конкретного приложения.
Это одинэс, тут особо ничего не придумаешь, КМК. Остается только в RO уводить один из инстансов, как ZmeeeD выше подсказывает.
gueux
31.05.2016 17:05Какой смысл использовать для деплоя Kubernetes если Вы, по сути, не используете его функционал (тот же Replication Controller) для «самовосстановления кластера БД». Если умирает один из Pod«ов, то нужно в руками запускать на его место новый, предварительно еще и проверив primary или stand-by это должен быть. На сколько я вижу в манифестах кубернейтса, Вы не монтируете физический диск внутрь контейнера с базой.
Получатся, что все данные хранятся в „виртуальном“ пространстве контейнеров, и при остановке контейнеров данные уничтожаются. Из этого следует, что при поднятии нового stand-by контейнера, ему необходимо будет скопировать ВСЮ базу с primary сервера, что, в условиях большого объема данных, займет не один час времени. В итоге, это решение ничем не отличается от обычного кластера postgresql, кроме быстроты начального развертывания, за счет уже собраных образов с конфигами.

slysha
Решение-то хоть рабочее или чисто теоретические изыскания?
ZmeeeD
Задача была вполне реальной — решение рабочее, но не проходило стресс тесты.
Да и вообщем то по архитектуре и схеме для Postgres тут нет никаких хитростей, основная проблема, по факту, была упаковать это все в контейнеры и k8s.
Но а вообще рекомендую попробовать — всего одна команда запустит схему (
docker-compose upили./k8s/scripts/up.sh)rawsik
у меня основная проблема, при реализации подобного решения ( правда другими средствами), было то,
что:
при выключении(жёстком) или пропадании master, к standby может приехать не тот timestamp без архив лога. И соответственно не подключиться стрим репликация ( или подключиться, но не забирать новые данные).
риски, как минимум в этом решении, после пару «выключенных» мастеров, slave'ы могут иметь разную версию ( timestamp) базы. И каждый новый мастер, может добавлять slave с «не тем» timestamp. в итоге кластер будет неконститентен.
как PoC очень хорошо, на практике, как мне кажется, много подводных камней,
в целом не из-за docker on kubernetes, а из-за особенности реализации БД.