
В целом задача, состояла в извлечении некоторых сущностей из большого массива текстов. Не сильно отличающаяся проблема от классической задачи извлечения именованных сущностей, с одной стороны. Но определения сущностей отличались от обычных и тексты были довольно специфическими, а сроку на решение проблемы было две недели.
Входные данные
Размеченных и доступных корпусов именованных сущностей на русском на тот момент не было вообще. А если бы и были, то там оказались бы не совсем те сущности. Или совсем не те сущности. Аналогичные решения были, но оказались они либо плохими (находили, например, такие организации как “Задняя Крышка” в предложении “после года работы Задняя крышка сломалась”) либо очень даже хорошими, но выделяющими не то, что надо (имелись требования, касающиеся того какие именно сущности нужно выделять и относительно границ этих сущностей).
Начало работы
Данные пришлось размечать самостоятельно. Из предоставленных специфических текстов была создана обучающая выборка. В течение недели усилиями полутора землекопов удалось разметить выборку объемом 112 000 слов, содержащую порядка 9 000 упоминаний нужных сущностей. После обучения нескольких классификаторов на валидационной выборке мы получили следующее:
| Метод | F1 |
| CRF (базовый набор признаков) | 67.5 |
| Двунаправленная многослойная сеть Элмана |
68.5 |
| Двунаправленная LSTM |
74.5 |
Для простых по содержанию сущностей это не очень хорошо, на сравнимых задачах специализированные системы часто выдают F1 районе 90-94 (по опубликованным работам). Но то на выборках из миллиона с лишним словоформ и при условии тщательного подбора признаков.
В предварительных результатах лучше всего себя показала модель LSTM, с большим отрывом. Но использовать ее не очень хотелось, ибо она относительно медленная, обрабатывать ей большие массивы текста в реальном времени накладно. К моменту получения размеченной выборки, и предварительных результатов до срока оставалась неделя.
День #1. Регуляризация
Основная проблема нейронных сетей на малых выборках – переобучение. Классически с этим можно бороться подбором правильного размера сети, или использованием специальных методов регуляризации.
Мы попробовали подбор размеров, max-norm регуляризацию на разных слоях, с подбором значений констант и dropout. Получили красные глаза, головную боль и пару процентов выигрыша.
| Метод | F1 |
| Уменьшение размера сети до оптимального |
69.3 |
| Max-norm |
71.1 |
| Dropout |
69.0 |
Dropout нам никак практически не помог, обучается сеть медленнее, и результат не особо хороший. Лучше всего показал себя Max-norm и изменение размера сети. Но прирост небольшой, до нужных значений как до луны, а все что можно вроде как сделано.
День #2. Rectified Linear
Статьи рекомендуют использовать RelU функцию активации. Написано, что улучшает результаты. RelU это простая функция if x>0 then x else 0.
Ничего не улучшилось. Оптимизация с ними вообще не сходится или результат ужасных. Провозились день, пытаясь понять почему. Не поняли.
День #3. LSTM-подобные монстры
Можно ли сделать так, чтобы было как LSTM, но на обычных слоях? После некоторых размышлений воображение подсказало конструкцию (рис.1). Перед рекуррентным слоем добавлен один feed-forward слой (он типа должен контролировать какая информация поступает в сеть), и сверху еще конструкция для управления выводом:
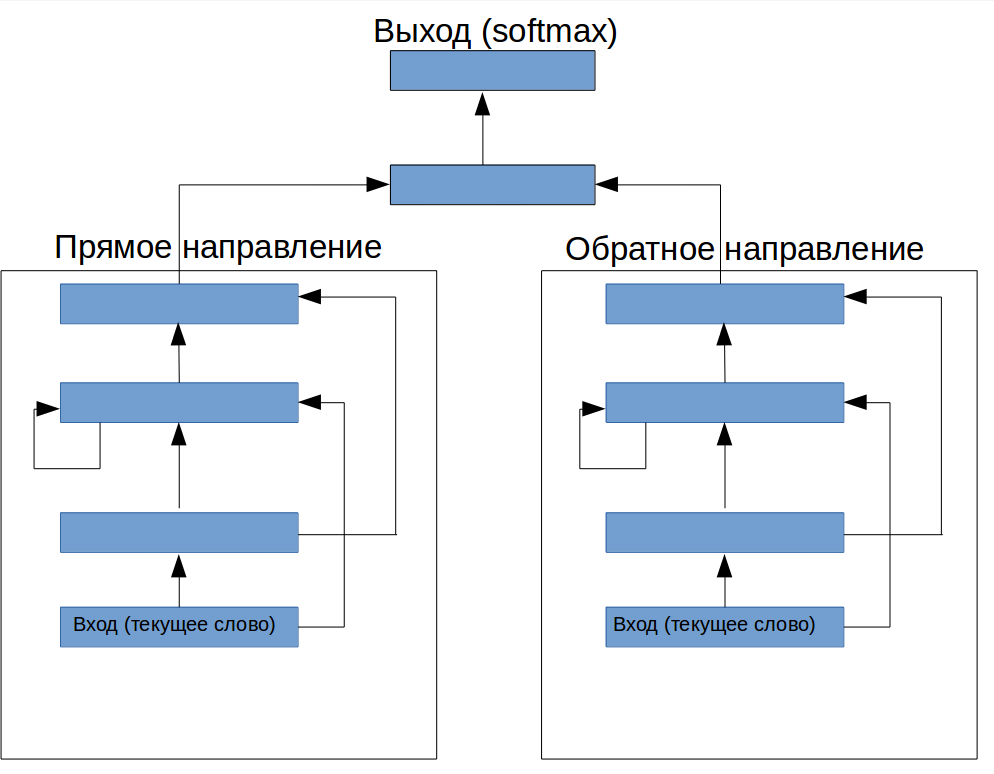
рисунок 1. Архитектура специальной нейронной сети для выделения терминов из текста
Как ни странно, при правильном подборе параметров эта конструкция дала прирост F1 до 72.2, что очень не плохо для полностью выдуманной архитектуры.
День #4. RelU Возвращается
Из упрямства попробовали RelU на “монстре”. Оказалось, что если RelU установить только на рекуррентный слой, то оптимизация не просто сходится, а получается F1 73.8! Откуда такое чудо?
Давайте разберемся. Почему работает хорошо LSTM? Обычно объясняют это тем, что он может запоминать информацию на более длительное время, и таким образом “видеть” больше контекста. В принципе, обычную RNN тоже можно обучить помнить длинный контекст, если использовать соответствующий алгоритм обучение. Но, применительно к нашей проблеме разметки последовательности с векторами слов на входе, обычная RNN сначала ищет зависимости в текущем временном промежутке и в ближайшем контексте, и успевает переобучится на них до того, как обучение дойдет до возможности осмысленного анализа данного контекста. В обычной RNN Элмана мы не можем нарастить “объем памяти” без того, чтобы значительно не увеличить способность сети к переобучению.
Если мы посмотрим на картинку новой архитектуры, то увидим, что здесь мы разнесли модуль, хранящий информацию и “решающий” модуль. При этом модуль памяти сам лишен возможности строить сложные гипотезы, поэтому его можно нарастить без того боязни того, что он будет вносить существенный вклад в переобучение. Этим мы получили возможность управлять степенью относительной важности памяти и информации в текущем окне для конкретной задачи.
День #5. Диагональные элементы
Следуя идеи, описанной в [1], мы исключили из рекуррентного слоя все рекуррентные соединения кроме от других нейронов, оставив на вход каждого нейрона только его собственное предыдущее состояние. Кроме того, мы добавили сделали верхний слой тоже рекуррентным (рис. 2). Это дало нам F1 74.8, что, на данной задачи являлось лучшим результатом, чем удалось вначале получить с помощью LSTM.
День #6. Объем выборки
Поскольку всю неделю мы продолжали размечать данные, то в этот день мы перешли к использованию новой выборки удвоенного размера, что позволило (после нового витка подбора гиперпараметров) получить F1 83.7. Нет ничего лучше выборки большего размера, когда ее легко получить. Правда удвоить объем размеченных данных обычно бывает совсем не просто. Вот что имеем в итоге:
| Метод | F1 |
| CRF (базовый набор признаков) | 76.1 |
| Двунаправленная многослойная сеть Элмана |
77.8 |
| Двунаправленная LSTM |
83.2 |
| Наша архитектура |
83.7 |
Выводы и сравнение с аналогами
Адекватно сравнить нашу систему распознания с аналогичными реализациями у упомянутых выше web-API нельзя, поскольку различаются определения самих сущностей и границ. Мы сделали некий очень приблизительный анализ, на небольшой тестовой выборке, попытавшись поставить все системы в равные условия. Нам пришлось вручную проанализировать результат по специальным правилам, использовав метрику binary overlap (засчитывается определение сущности, если система выделила хотя бы ее часть, что снимает вопрос несовпадения границ) и исключив из анализа случаи, когда сущности не надо было выделять из-за несовпадающих определений. Вот что вышло:
| Метод | F1 |
| Наша система | 76.1 |
| Аналог #1 |
77.8 |
| Аналог #2 |
83.2 |
Аналог #2 имеет лишь небольшое преимущество по данной метрике, а Аналог #1 показал себя еще и хуже. Оба решения будут выдавать менее качественные результаты, если тестировать их на нашей задаче с поставленными заказчиком уточнениями.
Из всего вышеизложенного мы сделали два вывода:
1. Даже хорошо определенные и решенные задачи извлечения именованных сущностей имеют подварианты, которые могут сделать применение готовых систем невозможным.
2. Применение нейронных сетей позволяет быстро создавать специализированные решения, которые находятся примерно в том же диапазоне качества, что и более сложные разработки.
Литература
1. T. Mikolov, A. Joulin, S. Chopra, M. Mathieu, and M. Ranzato. Learning longer memory in
recurrent neural networks
Комментарии (11)

erko
01.06.2016 12:41Интересно, что и в КЗ есть нужда в машинном обучении.
По статье было бы интересно узнать детали:
(Я изучаю машинное обучение как хобби и не собираюсь вытянуть вашу коммерческую новизну)
— Каким инструментом пользуетесь (TF, Theano, или самописный)?
— Какой объем текста в датасете и какой результат в известных/открытых датасетах выдает модель нейросети вашей компаний?
— Как я понял в вашей модели не используете LSTM, а предыдущий вывод передаете во вход текущего выполнения. Не считаете ли, что тут в вашей системе кроется проблема в случае длинных предложений (не запоминает больше 7(?) слов)?
— Такая реализация как бы запоминает информацию внутри модели. Т.е. возможность запоминания зависит напрямую от размера сети. Так если ваша модель fullyconnected — то на сложных задачах просто не будет запоминать высокоуровневую информацию, либо потребуется очень много времения для обучения большой сети.Durham
01.06.2016 13:25Каким инструментом пользуетесь (TF, Theano, или самописный)
То, что описано в этой статье, сделано на собственном инструменте. Про TF я писал ранее, там есть плюсы и минусы.
Какой объем текста в датасете
Объем для данного примера указан в статье. («удалось разметить выборку объемом 112 000 слов»). Данные на общедоступных датасетах, см. здесь
Не считаете ли, что тут в вашей системе кроется проблема в случае длинных предложений (не запоминает больше 7(?) слов)
На самом деле, даже простую сеть Элмана можно обучить запоминать контекст на сотню шагов назад выбрав правильную инициализацию и метод обучения. Проблема, как я написал в статье, в другом — то что переобучение на данных близких по времени наступает раньше, чем сеть учится использовать дальний контекст. Предложенная модель решает эту проблему.
Такая реализация как бы запоминает информацию внутри модели. Т.е. возможность запоминания зависит напрямую от размера сети
Да, но не от размера сети в целом, а от размера блока памяти.
Так если ваша модель fullyconnected
В блоке памяти рекуррентные нейроны не fullyconnected, они соединены только сами с собой (во времени). Поэтому могут хранить информацию дольше.

arreqe
01.06.2016 13:10Здравствуйте, интересная статья. Но хотелось бы по подробнее про признаки, так как сами понимаете, что Feature Engineering не менее важен самого алгоритма машинного обучения. Судья по тому что у Вас RNN скорее всего используется word2vec, так ли это?
Durham
01.06.2016 13:33Вообще метод с нейронными сетями тем и хорош, что можно получить приличные результаты, не занимаясь подбором признаков, типа «слово начинается с большой буквы, является существительным и оканчивается на -сь». На входе вектора слов, не word2vec, но аналогичный метод (детали, как вектора были получены и их размеры опубликованы в рамках другой работы).
elingur
02.06.2016 17:04А не могли бы уточнить, что значит базовый набор признаков CRF? Базовый — это один или тысяча признаков? Причем поскольку CRF граф, то вершины можно соединять как вздумается, т.е. этот «базовый набор» можно чередовать в произвольной последовательности и получать абсолютно разные результаты.
Сколько у вас типов (классов) сущностей? — От этого так же сильно зависит точность.
Дело в том, что на том же CRF я получал от 85 до 92 % точности на пяти типах сущностей. При этом скорость порядка 400-500кБ/с — но это уже от движка зависит.Durham
04.06.2016 22:57линейный CRF, признаки — слова, слова после стеммера, части речи (POS-tags), регистр слова, все в окне до 3 слов вперед и трех слов назад (подобрано до получения оптимального результата).
92% это accuracy, precision или F1? и на какой был объем обучающей и тестовой выборки?elingur
06.06.2016 09:58F1, объем обучающей — около 80 т. предложений.
Использую графематические признаки (их штук 10-15) и н-граммы слов (так же до трех).
POS-tags не дает прироста, нормализация слов (со снятием омонимии) дает прирост чуть более процента, но тормозит процесс в 3-4 раза. То есть модуль работает на потоке с плоским текстом, но быстро.Durham
07.06.2016 22:5680 тыс. предложений это примерно в 5 раз больше, чем выборка о которой идет речь в этой статье. Отсюда и разница в цифрах.
brickerino
Кхм.
«Мы попробовали LSTM и у нас что-то получилось. Про задачу не скажем, про фичи не скажем, про размер сети не скажем. Мы довольны. Мы работаем лучше, чем Аналог1 и также как Аналог2.»
1. У меня слов нету.
2. Попробуйте GRU в следующих раз и xgboost.
Durham
Хотелось бы, чтобы уважаемые комментаторы читали внимательно статью, прежде чем писать критику. Тем более такую. В статье нет «попробовали LSTM и у нас что-то получилось», а ясно сказано, что LSTM работает хорошо, но медленно. Для больших объемов текста это имеет значение. Рассмотренная модель гораздо проще чем LSTM или GRU, а дает тот же результат. В этом ее плюс.
Точные размеры сети значения не имеют, их подбирают под задачу. Кто разбирается, сможет это сделать, а кто не разбирается… ну, будет писать вот такую критику ни о чем.
Да, это не научная статья, это иллюстративный пример, что бывает на практике с подобными задачами, как они решаются и чего можно дробится. И тут раскрыто довольно много информации, которая может в аналогичном случае сэкономить много времени и нервов.
Pridachin_N_L
Соглашусь с Durham, технические аспекты реализации задачи отражены, «роад мап» передан, а что касается конкретных инструментов при реализации, так это как с фломастерами, они разные. И все же, это же статья, и ее автор преследовал цель отразить реальный опыт в реальном проекте при этом в разумных по объёму пределах. Думаю, чем больше статей в этой, интересной тематике не академического характера, а по реальным проектам тем лучше.
Смотря на беседу в комментариях, автор охотно отвечает на все вопросы по методам.