

Чарли Чаплин в фильме «Новые времена»
Про Azure Service Fabric уже немало написано статей и даже книг, благо около года продукт находился в состянии preview. Однако 1 апреля 2016 года без всяких шуток Azure Service Fabric наконец достиг состояния General availability, и есть основания полагать, что он задержится здесь всерьез и надолго. А раз так — почему бы не пройтись по нему если не из прикладного, то хотя бы из академического интереса? Тем более что информации по Azure Service Fabric на русском языке явно маловато.
Зачем же вообще потребовался Azure Service Fabric? В мире ПО существует довольно много серверов, привязанных к экосистемам определенного языка или платформы. Исторически так сложилось, что в экосистеме Java таких серверов едва ли не больше всех — Tomcat, JBoss, WebSphere и пр. Увы, платформа .NET таким богатством выбора похвастаться пока не может. На ум приходят разве что IIS, “облачные” сервисы Azure и их “локальный” близнец Windows Azure Pack (не считая хелперов-оберток типа Topshelf). Azure Service Fabric призван расширить этот недлинный список в сторону популярной нынче концепции SOA и остромодной подконцепции микросервисов, упрощая развертывание сервисов и обеспечивая их масштабируемость и отказоустойчивость. И после этого лирического отступления перейдем, наконец, в наступление.
Галопом по Европам
Основной источник знаний об Azure Service Fabric (далее ASF) — документация. Настоятельно рекомендую и заодно замечу, что русский перевод отстает от исходного текста как минимум в скриншотах, так ориентироваться лучше на оригинал. Итак, поехали — физически ASF представляет собой кластер из нескольких серверов, на которых исполняются экземпляры сервисов. Что-то вроде этого:
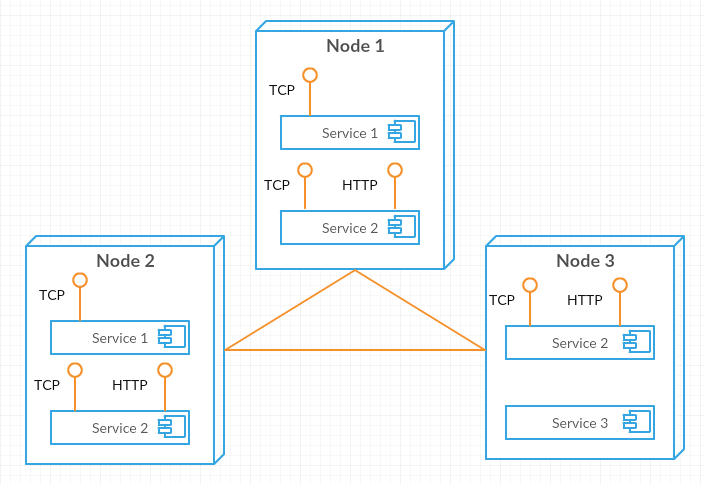
Нарисовано с помощью creately.com
Что есть сервис? Согласно Википедии сервис определяется как “A service is a self-contained unit of functionality”, иначе говоря, это “есть боевая единица сама в себе”, отдельно и независимо развертываемая и используемая. В ASF каждая такая “боевая единица” имеет свой манифест, в котором определены имя сервиса, конфигурация, конечные точки и пр. Несмотря на атомарность единицей развертывания является все же не сервис, а совокупность сервисов, называемая приложением — в манифесте приложения можно, кроме прочего, определить партиционирование сервиса для поддержания масштабируемости, а для отказоустойчивости в случае выхода из строя серверов ASF каждая партиция может иметь несколько экземпляров сервисов. И сервисы и приложения версионируются независимо, что позволяет обновлять приложение, не обновляя в нем все сервисы разом. Для развернутого приложения ASF создает нужное количество экземпляров сервисов, размещает на нодах кластера, запускает, синхронизирует состояние между экземплярами, пересоздает экземпляры для балансировки нагрузки — для примера на картинке выше Service 1 имеет конечную точку для общения по TCP и в двух экземплярах размещен на двух узлах, Service 2 имеет выходы на TCP и HTTP и по одному экземпляру размещен на всех трех нодах, а Service 3 внешних коммуникаций не предоставляет и в одном экземпляре крутится на одной ноде. Буде одна из нод безвременно помрет, ASF перебалансирует нагрузку на оставшихся. В целом же обеспечение безпроблемного функционирования сервисов и есть работа ASF.
Сервисы в ASF делятся на два типа — stateful и stateless, иначе говоря, хранящие свое состояние и не имеющие такового. Можно использовать эти типы, просто порождая от них свои сервисы, а можно на их основе возводить более сложные конструкции — скажем, технология ASF Actors сама построены на stateful сервисе. Для первого знакомства с ASF я использую stateless сервис как более простой.
Здесь будет город-сад
… но далеко не сразу. Для начала обустроим среду разработки. Отсюда скачиваем и устанавливаем желаемый вариант SDK — можно автономный, а можно с элементами для интеграции в Visual Studio. Для интегрированного варианта необходимы Visual Studio 2015 или “15” Preview, вероятно, подойдет и вариант Community, а при написании статьи использовалась Visual Studio Enterprise 2015 Update 2, и в ней все гарантированно работает. После установки SDK в списке шаблонов проектов (а именно в разделе Visual C#/Cloud) появляется Service Fabric Application и можно, наконец, перейти к делу — создаем новое ASF-приложение, называем его MyFabric, нажимаем OK, выбираем тип сервиса Stateless, называем MyStateless “и тупо смотрим, что к чему” в свежесозданном решении. Заметим, что решение безальтернативно создается для x64, и в его составе:
- проект MyStateless
- Program.cs — входная точка сервиса. Все, что она делает — регистрирует сервис в ASF, записывает это знаменательное событие в лог, после чего навсегда засыпает.
- MyStateless.cs — собственно код сервиса. Содержит простой бесконечный цикл, ежесекундно пишущий в лог и прерываемый внешним CancellationToken’ом.
- ServiceEventSource.cs — ASF использует ETW через EventSource. Этот класс описывает некоторые общеупотребимые события, предоставляя удобные методы для их логирования.
- ServiceManifest.xml — манифест сервиса MyStateless для ASF.
- Settings.xml — конфигурация сервиса, упомянутая в манифесте как ConfigPackage.
- проект MyFabric
- ApplicationManifest.xml — манифест всего приложения MyFabric для ASF.
- ApplicationParameters/(Local|Cloud).xml — переопределения параметров манифеста приложения.
- PublishProfiles/(Local|Cloud).xml — профили развертывания приложения в различных средах. Фактически представляют собой указание адреса ASF-кластера и переопределений из ApplicationParameters.
Запустим решение на исполнение и спустя сборку и развертывание видим вот такую вот симпатичную картинку SF Explorer (к слову — в настройках можно темную схему поменять на светлую):
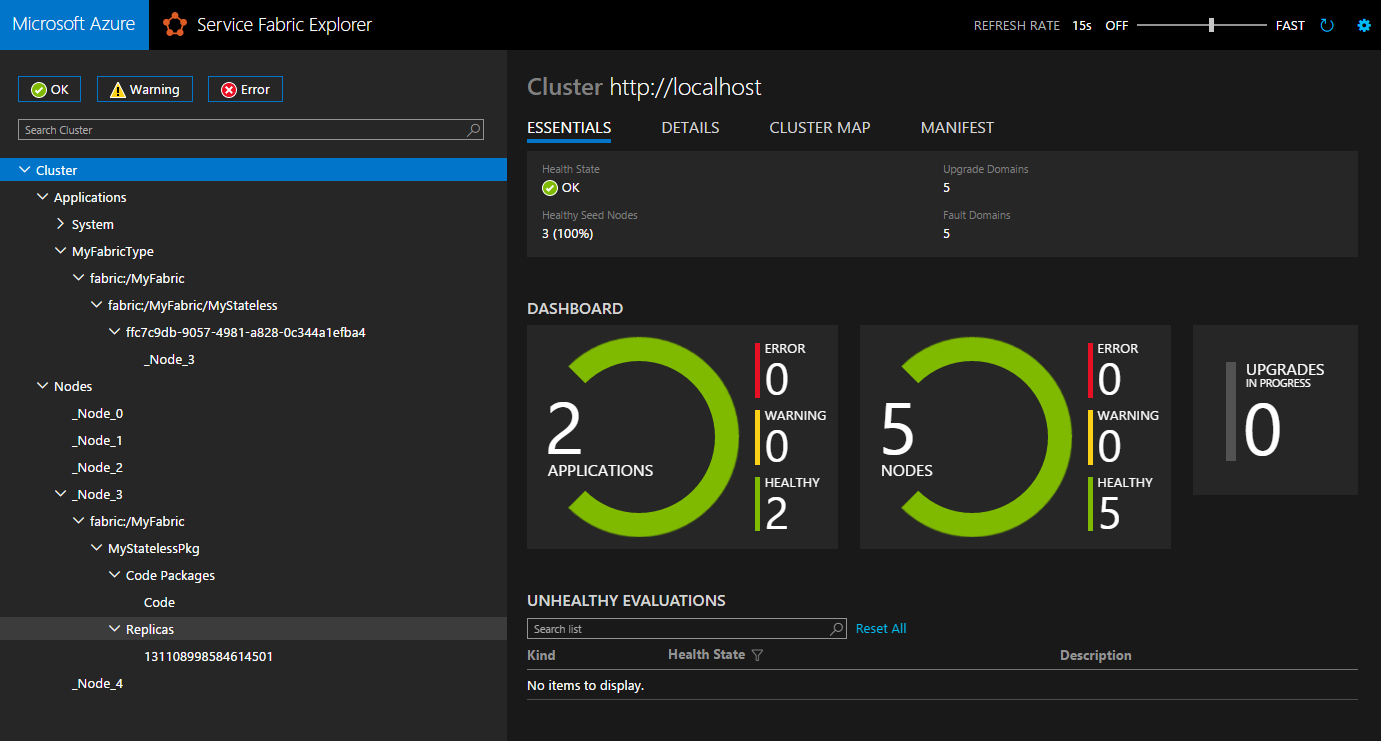
Что такое перед нами? Перед нами управление локальным 5-нодовым ASF кластером (как бы глупо это не звучало) с развернутым на нем приложением fabric:/MyFabric/MyStateless. Не стоит смущаться надписи “2 applications” — на кластере по умолчанию стоит приложение System из 4 stateful сервисов, используемое самим кластером. Согласно манифесту MyFabric сервис MyStateless требуется только в одном экземпляре, и в нашем случае этот экземпляр попал на 3-ю ноду кластера. Работу приложения можно видеть в окне Diagnostic Events:
Можно поразвлекаться, гоняя на единственный экземпляр по нодам — для этого из выпадающего справа меню Actions у нужной ноды выберите любой вариант Deactivate. При этом в окне VS Diagnostic Events отражаются все детали происходящего внутри ASF, в частности то, что “старый” экземпляр MyStateless отменился и остановился, а “новый” начал отсчет заново.

Что и неудивительно — состояния-то у сервиса нет.
Замечу тут, что и сам SF Explorer и прочее управление кластером доступно из “ромашки” в трее, а окно Diagnostic Events — из меню View/Other Windows. Если же это окно вдруг ничего не отображает — надо добавить строку “MyCompany-MyFabric-MyStateless” в список ETW провайдеров под шестеренкой.
Цикл жизнедеятельности
Поразвлекавшись ломанием кластера, перейдем к разбору деталей функционирования нашего сервиса. В целом жизненный цикл сервиса определяется набором виртуальных методов класса StatelssService, от которого порожден наш MyStateless, а именно:
protected virtual IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners()
protected virtual Task RunAsync(CancellationToken cancellationToken)
protected virtual Task OnOpenAsync(CancellationToken cancellationToken)
protected virtual Task OnCloseAsync(CancellationToken cancellationToken)
protected virtual void OnAbort()
Интересных нам методов всего пять, а для понимания последовательности их вызовов модифицируем код сервиса, переопределив методы и добавив логирование (да-да, старая добрая отладочная печать):
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners()
{
ServiceEventSource.Current.ServiceMessage(this, "CreateServiceInstanceListeners");
return new ServiceInstanceListener[0];
}
protected override Task OnOpenAsync(CancellationToken cancellationToken)
{
ServiceEventSource.Current.ServiceMessage(this, "OnOpenAsync");
return Task.FromResult(0);
}
protected override Task OnCloseAsync(CancellationToken cancellationToken)
{
ServiceEventSource.Current.ServiceMessage(this, "OnCloseAsync");
return Task.FromResult(0);
}
protected override void OnAbort()
{
ServiceEventSource.Current.ServiceMessage(this, "OnAbort");
}
protected override async Task RunAsync(CancellationToken cancellationToken)
{
long iterations = 0;
while (!cancellationToken.IsCancellationRequested)
{
ServiceEventSource.Current.ServiceMessage(this, "Working-{0}", ++iterations);
await Task
.Delay(TimeSpan.FromSeconds(1), cancellationToken)
.ContinueWith(_ => { }, TaskContinuationOptions.NotOnFaulted);
}
}
RunAsync дополнительно переделан для корректного завершения вместо выбрасывания исключения. Снова смотрим Diagnostic Events:

Первым ожидаемо вызывается CreateServiceInstanceListeners — в нем сервис создает все необходимые конечные точки для коммуникаций с внешним миром и внутри кластера. За ним ожидается OnOpenAsync — чтобы да? Так вот нет — дальше идет RunAsync. Логика такого поведения неясна, но согласно документации OnOpenAsync является в некотором роде дополнительным событием, необходимым же (и вполне достаточным) служит вызов RunAsync. После него действительно вызывается OnOpenAsync и сервис работает уже до остановки OnCloseAsync/OnAbort (вызванной, например, переразвертыванием сервиса):

Конфигурирование
В шаблонном коде конфигурировать особенно нечего, но кое-что все же найдется — ежесекундное логирование хорошо, но можно бы и пореже. Для этого в конфигурацию Settings.xml внесем параметр:
<Section Name="MyConfigSection">
<Parameter Name="MyFrequency" Value="10" />
</Section>
В код добавим получение этого значения:
var configurationPackage = Context.CodePackageActivationContext.GetConfigurationPackageObject("Config");
var frequencyInSeconds = int.Parse(configurationPackage.Settings.Sections["MyConfigSection"].Parameters["MyFrequency"].Value);
И используем полученное значение:
await Task
.Delay(TimeSpan.FromSeconds(frequencyInSeconds), cancellationToken)
.ContinueWith(_ => { }, TaskContinuationOptions.NotOnFaulted);
Теперь сервис пишет в лог раз в 10 секунд. Напомню, что параметры сервиса можно переопределять как в манифесте приложения, так и в профилях развертывания для различных сред — как правило, они разные для сред разработки и BETA/PROD.
Просто добавь коды
Сервис не сервис, когда без коммуникаций — пусть MyStateless будет сервисом времени a-la NTP, а для упрощения взаимодействий с ним используем ASF Remoting. Эта технология позволяет общаться с сервисом как с обычным .NET объектом через интерфейс сервиса. Создадим интерфейс IMyStateless c единственным методом Now():
public interface IMyStateless : IService
{
Task<DateTimeOffset> Now();
}
Для создания слушателя модифицируем CreateServiceInstanceListeners:
return new[] { new ServiceInstanceListener(this.CreateServiceRemotingListener) };
А в качестве клиента выступит обычное консольное приложение:
public static void Main()
{
while (!Console.KeyAvailable)
{
var myStateless = ServiceProxy.Create<IMyStateless>(new Uri("fabric:/MyFabric/MyStateless"));
Console.WriteLine(myStateless.Now().Result);
Thread.Sleep(TimeSpan.FromSeconds(10));
}
}
Добавляем только код, конфигурацию править не надо. Для того, чтобы использовать клиента, ASF-приложение надо сначала опубликовать — из контекстного меню узла MyFabric выбираем Publish, в качестве Target Profile выбираем Local.xml, нажимаем Publish и ждем сообщения об успешном завершении публикации. Теперь можно запустить клиента и убедиться, что время локального кластера в точности совпадает с системным (какая неожиданность).
Растем над собой
Строго говоря, под stateless сервисами ASF понимает сервисы, которые не хранят состояние с помощью самой ASF. Как совершенно справедливо сказано в документации, партиционировать stateless сервисы имеет смысл тогда, когда они все же хранят свое состояние любым другим удобным для них способом (в БД, кэшах, текстовых файлах и пр.). Впрочем, фактически партиционируются все сервисы — просто stateless используют частный случай SingletonPartition (и это отражено в манифесте приложения). Вот и начнем с масштабирования этой единственной партиции — увеличим количество экземпляров MyStateless, поправив ApplicationParameters/Local.xml:
<Parameter Name="MyStateless_InstanceCount" Value="5" />
Дерево узлов в SF Explorer уже не вмещается в скриншот, так что поверьте и проверьте самостоятельно, что пять экземпляров сервиса равномерно (то есть по одному) распределены по всем пяти нодам кластера. При таком масштабировании могут возникать проблемы, связанные с неразделяемыми ресурсами (например, портами), однако для Remoting в нашем случае ASF самостоятельно балансирует вызовы между запущенными экземплярами. Для простоты в метод Now() добавим логирование InstanceId и в окне Diagnostic Events увидим, что вызовы попадают в разные экземпляры MyStateless.
Умозрительно предположим, что MyStateless все-таки хранит какое-то состояние вне ASF и партиционируем его, используя схему партиционирования по именам:
<StatelessService ServiceTypeName="MyStatelessType" InstanceCount="[MyStateless_InstanceCount]">
<NamedPartition>
<Partition Name="even" />
<Partition Name="odd" />
</NamedPartition>
</StatelessService>
Переразвертываем и в SF Explorer видим, что две партиции по пять экземпляров каждая опять равномерно (то есть по одному экземпляру от партиции) распределены по всем пяти нодам кластера.
Совсем была наша победа, да теперь клиент не работает, падая с исключением FabricException и содержательным сообщением «Invalid partition key/ID '{0}' for selector {1}» — поправим клиента:
var isEven = true;
while (!Console.KeyAvailable)
{
var myStateless = ServiceProxy.Create<IMyStateless>(
new Uri("fabric:/MyFabric/MyStateless"),
new ServicePartitionKey(isEven ? "even" : "odd"));
Console.WriteLine(myStateless.Now().Result);
isEven = !isEven;
Thread.Sleep(TimeSpan.FromSeconds(10));
}
И заодно логирование сервиса:
ServiceEventSource.Current.ServiceMessage(this, "Now - " + Context.PartitionId + " - " + Context.InstanceId);
Вот теперь все хорошо — клиент направляет вызов в нужную партицию, а ASF балансирует вызовы между равноправными экземплярами сервиса внутри партиции. MyStateless отмасшабирован и стал отказоустойчивым.
Web API
И чтоб два раза не вставать, заодно вкратце затронем тему ASF Web API сервисов, поскольку из шаблонов они создаются так же без состояния. Из контекстного меню узла MyFabric/Services выбираем Add, тип сервиса Stateless Web API, называем MyWebApi и получаем новый проект с файлами:
- Program.cs — уже узнаваемо содержит регистрацию сервиса в ASF.
- MyWebApi.cs — код сервиса, который вместо реализации RunAsync регистрирует слушателя OwinCommunicationListener.
- ServiceEventSource.cs/ServiceManifest.xml/Settings.xml — играют те же роли с поправкой содержания на Web API.
- OwinCommunicationListener.cs — шаблоны Web API в ASF основаны на Owin, так что этот слушатель реализует методы ICommunicationListener, запуская и останавливая Owin Web-сервер.
- Startup.cs — конфигурирует роутинги в Owin
- ValuesController.cs — простой тестовый контроллер, путь к которому сконфигурирован в Startup.cs
После публикации в SF Explorer видим второй сервис fabric:/MyFabric/MyWebApi. Для проверки его работоспособности можно открыть страницу в браузере по адресу
http://localhost:8201/api/values — в ней ожидаемо появится XML-ответ контроллера от Get(), а по адресу http://localhost:8201/api/values/123 возвратится ответ от Get(int id). “Как выразился Джордж, тут было что пожевать!”
И на этом наши первые шаги заканчиваются. Очевидно, что эта короткая статья не исчерпала и десятой доли того, что можно рассказать про ASF. За бортом помимо тем помельче осталась такая масштабная тема, как stateful сервисы — для нее требуется отдельная статья, силы и время, но если получится, то там уже и до модели Actor’ов в ASF будет недалеко. Возможно, что дойдет и до этого — как говорится, пишите комментарии. Код из статьи доступен в GitHub, а вот здесь можно посмотреть “родные” примеры от Microsoft.
Поделиться с друзьями
Ogoun
По описанию похоже на Microsoft Orleans, ни его ни описанный продукт не пробовал, и хочу узнать, есть ли у кого опыт использования их в реальных условиях? И что лучше для решения задачи в которой будет использована микросервисная архитектура, в которой сервисы должны общаться, и где должно быть централизованное место для визуального отслеживания работы всей системы. Имеет ли какой нибудь из этих продуктов кроме RPC еще и поддержку durable шины сообщений?
Caraul
Отвечаю по порядку.
Опыт использования в реальных условиях MS Orleans есть — продукт новый, динамично развивается, проблемы иногда вылезают, но в целом сейчас релиз стабильный, и использовать его можно. Реального опыта по ASF пока нет, и мне самому интересно послушать тех, у кого уже появился.
Теперь об остальном. Сразу замечу, что Orleans — это framework (иначе говоря, библиотека), а ASF — серверное решение, поэтому для Orleans разворачивание, диагностику, мониторинг и пр. надо писать самому, а ASF сам строит кластер и сам себя диагностирует (годится ли такое “из коробки” для Вашего проекта надо смотреть по месту). Взаимодействие между акторами/сервисами есть в обоих решениях.
Далее — Orleans в основе предлагает actor model, ASF в основе предлагает микросервисы (как я упомянул в статье, сами ASF Actors построены на микросервисах). Несмотря на некоторое сходство, микросервис и актор — разные сущности. Система акторов — это система именованных объектов, доступ к которым осуществляется по имени через интерфейс. Система микросервисов — система неких объектов, запущенных на исполнение. Внешнего доступа к таким объектам может и не быть (если это сервис фоновой задачи), а если и есть, то тяготеет скорее к TCP/HTTP, чем к RPC. Актор является точкой синхронизации — в один момент времени исполняется не более одного вызова. И жизненный цикл актора/сервиса разный — при запросе актора можно активировать, а при отсутствии активности деактивировать (см. virtual actors и grains), экзмепляр сервиса же, будучи запущен, работает до полного останова. Сервис можно эмулировать бессмертным актором — такой фокус возможен, более того, в Orleans мы так и делали для фоновых задач, но концептуальную красоту это нарушает :)
Ну и наконец durable шина сообщений — в Orleans это Streams, а вот в ASF готовой шины нет (коллеги подсказывают, что были в ASF те же Streams, но вышли такими кривыми, что пока их выпилили от греха подальше и когда впилят обратно — неизвестно).