

Снова Чарли Чаплин на фабрике в фильме «Новые времена»
Продолжаем разговор про Azure Service Fabric. В предыдущей статье я упомянул о планах написать сначала про stateful сервисы, а затем уже перейти к модели акторов в ASF. Концепция изменилась — подумалось мне, что неплохо бы для примеров использовать если уж не production-решение, то что-то близкое, чтобы была теоретическая польза и практический смысл. Можно объединить все компоненты ASF в одном флаконе — чтобы и корованы набигали, и лунапарк, и Винни-Пух и все-все-все. Вот с такими мыслями я и пошел на кладбище домашних проектов в поисках кандидата на оживление.
Живые мертвецы
И такой кандидат нашелся. Как любят писать в «железных» статьях, «порывшись в ящиках с запчастями» выудил оттуда когда-то недописанную библиотеку работы с протоколом Advanced Direct Connect. «На лицо ужасная, страшная внутри», однако, смахнув пыль напильником, убедился, что внутри еще теплится жизнь. Библиотека когда-то предназначалась для так и ненаписанного ADC-клиента, однако почему бы на ее основе не написать ADC-хаб? Вот это идея, свежая и оригинальная — можно попробовать.
Протокол ADC появился больше 10 лет назад, в 2004 году (последняя версия 1.0.3 в 2013 году) как наследник NMDC (он же просто DC). Как и в NMDC узлы сети ADC обмениваются простыми текстовыми командами. Типов узлов всего два — это центральный узел (хаб) и конечные клиенты, который присоединяются к хабу и друг к другу. Через хаб клиенты могут общаться (чатиться) и искать нужные файлы, а вот передача данных осуществляется напрямую между клиентами, минуя хаб. Грубо говоря, хаб служит для аутентификации клиентов, хранения их списка и пересылки команд между клиентами. Единственный известный мне существующий транспорт это TCP, схема адресации adc://, порт стандартом не определяется, но на практике используется привычный для DC 411. У клиентов есть собственный Private ID, но важнее, что каждому подключившемуся клиенту в первую очередь выдается SID (session identifier), по которому его (клиента) и адресуют другие клиенты.
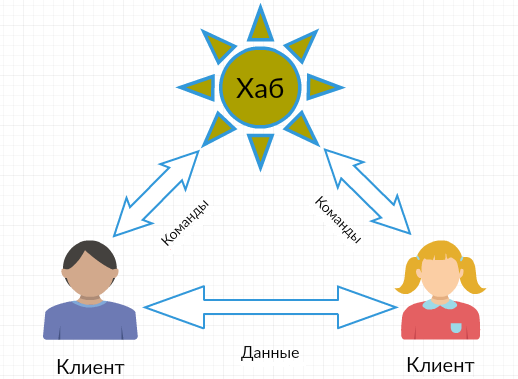
Типовая схема соединений P2P справедлива и для ADC
Протокол расширяем — можно добавлять как совершенно новые команды, так и параметры к уже существующим командам. Список поддерживаемых возможностей каждый хаб/клиент объявляют при установлении соединения. Обязательна поддержка базовых возможностей ADC для хаба и клиента, плюс TCPx/UDPx для клиента для обмена файлами. Расширения достаточно мощный механизм наращивания возможностей протокола — скажем, в расширения вынесены как несколько дополнительных функций хеширования (согласование используемой функции есть в базовых возможностях на этапе установки соединения клиент-хаб), так и защищенное соединение ADCS.
Что касается современного состояния дел, то, как ни странно, область P2P еще жива (разумеется, я не считаю торрентов, которые всегда на слуху). И хабы и наследники StrongDC++ (когда-то я и сам пользовался этим клиентом) до сих пор разрабатываются, так что решаемая задача еще не совсем потеряла свой прикладной смысл, перейдя в разряд академических.
К сожалению, спецификация ADC оставляет простор для фантазии — не то, чтобы совсем «музыка к игре написана профессиональными программистами», но и до, скажем, точности RFC или стандартов W3C ей далеко. Из-за этого по ходу дела пришлось уточнять детали по существующим реализациям ADC (ADCH++, AirDC++ и пр.).
Модель для сборки
Начну, как обычно, с общеархитектурных прикидок. Для простоты хаб будет открытый, то есть пользователи могут заходить без регистрации и паролей, но их имена должны быть уникальны. С ходу видны три логических части общей картины — это сервер соединений TCP, затем объекты, реализующие ADC для обмена с клиентами, по одному на каждого клиента (назову их пользователями) и, наконец, общий каталог всех активных клиентов.
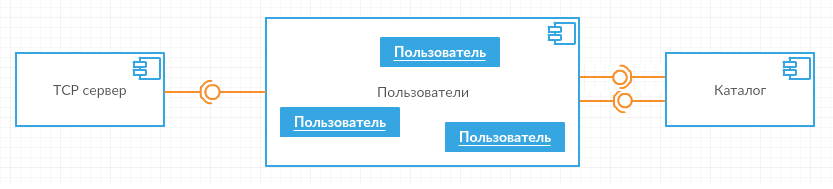
TCP-сервер будет заниматься установкой TCP-соединений и обменом сериализованными ADC-сообщениями с клиентом, пользователи отвечают за корректную реализацию протокола согласно спецификации, а на каталог возлагаются задачи по поддержанию списка активных клиентов (в том числе выдаче их идентификаторов) и широковещательной рассылке сообщений. Вот от этой печки и буду плясать.
Привязка к местности
Теперь каждой логической части надо подыскать соответствие среди компонентов ASF. Основное ограничение — минимум самописного кода и максимум существующих в ASF возможностей.
TCP-сервер
TCP-сервер состояния не имеет и нужен по одному экземпляру на каждом узле ASF-кластера — очевидно, это stateless сервис (описывал в предыдущей статье, так что повторяться не буду).
Пользователи
Обмен ADC-командами с клиентами попробую возложить на акторов.
Акторы
Модель акторов (actor model) появилась, как ни странно, из научной среды (впрочем, в 1973 году для тогдашних computer science это неудивительно). Согласно этой модели, актором называется некоторая сущность, которая (как правило) имеет состояние, функционирует независимо от остальных акторов, может асинхронно посылать и принимать сообщения, а также создавать других акторов. Совокупность (или система) акторов может объединять акторов разных типов. Для обмена сообщениями у каждого актора есть специальный адрес (как правило, числовой или текстовый). Важно понимать, что все акторы функционируют параллельно, обмен сообщениями асинхронен, но обработка этих сообщений идет последовательно — актор “однопоточен”, служит как точка синхронизации и в каждый момент времени обрабатывает не более одного сообщения.
Реализовать эту умозрительную модель можно различно — мне в разной степени известны три реализации акторов Akka.NET, Orleans и акторы ASF. В Akka.NET явно выделены и создание актора, и его удаление из системы, и посылка ему сообщений. Акторы Akka.NET образуют иерархию, так что “родители” могут следить за поведением “детей”. В Orleans и ASF пошли по другому пути — здесь взяли на вооружение плоскую модель распределенных виртуальных акторов, в которой все акторы существуют всегда, но до первого вызова в неявном состоянии. Будучи вызван, актор создается и далее его состояние сохраняется между перезагрузками. Асинхронная передача сообщений моделируется вызовами интерфейса C#, а для полной “гальванической развязки” в Orleans присутствуют персистентные Streams, которые реализуют Pub-Sub. В ASF Streams нет, зато есть события актора, на которые также можно подписаться. И (как и в Akka.NET) есть удаление актора и очистка его состояния — после удаления актор снова переходит в “мир теней” до очередного вызова. Как видно, во всех реализациях есть и похожие, и различающиеся черты.
Как ни странно, довольно част вопрос — чем ASF-актор отличается от ASF-сервиса? Смотрите сами — экземпляр сервиса создается однократно при старте кластера, работает затем до остановки или перезагрузки ASF, имеет внешние и/или внутренние точки коммуникаций. Экземпляры акторов создаются и удаляются внешними запросами, а их количество ограничено только физическими возможностями кластера. Поэтому если необходимо реализовать коллекцию объектов (возможно, разнотипных), которая должна динамически изменяться по ходу работы — это акторы. Если нужно создать известное наперед количество объектов, особенно если эти объекты реализуют внешние коммуникации или внутреннюю функциональность — это сервисы. И важно помнить, что акторы обрабатывают обращения к ним последовательно, а сервисы — параллельно.
Каталог пользователей
Возвращаясь к нашим компонентам — для каталога активных клиентов логично выбрать stateful сервис.
Stateful сервисы
Если коротко — stateful сервисы такие же, как и stateless, но с состоянием. И действительно, жизненный цикл у них похож — те же OnOpen, OnClose и RunAsync. Так же есть слушатели для коммуникаций, так же возможен ASF Remoting и пр. Однако наличие состояния привносит и заметные различия. В первую очередь это различия в терминологии — если для stateless сервисов имеет смысл говорить об экземплярах, то stateful сервисы имеют реплики. Реплики объединяются в наборы реплик (replica set), каждый набор реплик имеет свое состояние, независимое от остальных наборов в этом сервисе. В каждом наборе только одна реплика является первичной, а остальные вторичными — состояние может менять только первичная реплика (и только для нее вызываются функции жизненного цикла), все остальные состояние только читают. Если сервис партиционирован, то каждая партиция представляет собой такой набор реплик и, соответственно, имеет свое отдельное состояние. И партиции, и количество реплик в них задаются — опять же как и для stateless сервисов — через конфигурацию приложения. В случае падения первичной реплики одна из вторичных берет на себя эту роль, поэтому для надежности ASF раскидывает все реплики одного набора по нодам кластера, а состояние сервиса реплицируется между нодами. В состоянии можно хранить только объекты, порожденные от интерфейса IReliableState. Сам по себе интерфейс напоминает маркерный, реализовать его толком невозможно, так что “из коробки” фактически есть только два reliable-объекта: ReliableDictionary и ReliableQueue (словарь и FIFO-очередь). Для синхронизации изменений в нескольких reliable-объектах можно использовать транзакции.
Итого выходит:
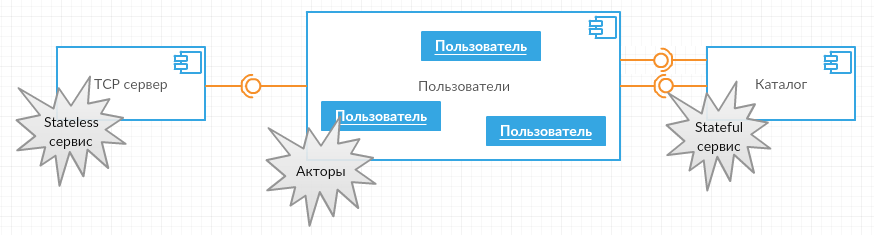
Дьявол в деталях
Мозговой штурм закончился и пора переходить к реализации всего вышеобдуманного. Здесь я постараюсь избежать углубления в технические детали, ограничась общим описанием и тонкими местами, при необходимости любознательный читатель может обратиться непосредственно к исходному коду (ссылка есть в конце статьи).
Итак, по порядку.
TCP-сервер
Для TCP-сервера можно использовать стандартные TcpListener/TcpClient, которые оборачиваются в нестандартный TcpCommuncationListener. TcpListener запускается на OpenAsync, останавливается на CloseAsync. а сам TcpCommuncationListener создается в CreateServiceInstanceListeners.
В конфигурировании есть мелкая деталь — для локальной отладки в Local.xml я ставлю
<Parameter Name="TcpServer_InstanceCount" Value="1" />, а в параметрах для Azure будет
<Parameter Name="TcpServer_InstanceCount" Value="-1" />Это потому, что узлы отладочного кластера запускаются локально на одном компьютере и поделить 411 порт между собой никак не могут, соответственно, нужен только 1 экземпляр сервиса. ‘-1’ означает, что один экземпляр сервиса должен быть запущен на каждом узле ASF-кластера — в Azure узлы ASF размещаются на разных VM и у каждой есть свой 411 порт.
Как связаться с нужным актором и какой у него вообще адрес? Это будет обсуждено далее в реализации акторов, а пока вот первая проблема (впрочем, предсказуемая) — установка TCP-соединения, создавшая экземпляр TcpClient, намертво приколачивает его же к узлу кластера, с которым соединился клиент. Актор может перемещаться по узлам, но его вызвать несложно — он адресуем, а вот как из актора вызвать TcpClient? Ведь сообщения надо как принимать, так и отправлять. Через сам stateless сервис нельзя — неизвестно, в каком из экземпляров сервиса находится нужный TcpClient. И тут на помощь приходят события акторов — TcpClient может подписаться на события “своего” актора и получать исходящие сообщения через них (я предпочел бы потоки, но стараюсь обходиться тем, что есть).
Пользователи
Функций у актора всего две — получить и обработать очередное сообщение, и отправить сообщение клиенту. И тем не менее это самая запутанная часть хаба, поскольку именно на актора возлагается поддержка протокола. Не бином Ньютона, но тоже есть над чем поразмыслить. Для начала нужно выбрать, чем адресовать актора. В протоколе клиент адресуется SID, который выдается хабом — отчего бы не использовать этот SID как адрес актора ASF? Далее, ADC предполагает четыре состояния протокола для хаба — PROTOCOL (согласование параметров подключения), IDENTIFY (информация о клиенте), VERIFY (проверка пароля), NORMAL (обычная работа). Поскольку хаб открытый, то паролей нет и VERIFY не требуется. А поскольку актор в ASF виртуальный, то имеет смысл добавить состояние UNKNOWN для актора, который вроде бы жив, но еще/уже никуда не подключен.
Как только есть состояния, то тут же появляется и state machine — приходящие ADC-команды будут обрабатываться текущим состоянием и послужат триггерами для перехода между состояниями. ASF насквозь асинхронна, так что и state machine нужна асинхронная. Поиск готовых библиотек выдал не так уж много вариантов. В качестве претендентов рассматривались stateless за авторством небезызвестного Nicholas Blumhardt (он же автор Autofac и Serilog) и Appcelerate (в девичестве bbv.Common). Обе не подошли, поскольку совершенно синхронны. Есть еще асинхронный наследник stateless LiquidState, но она не подошла уже по недостатку функциональности. Очень не люблю писать велосипеды, но тут пришлось, благо несложно. За основу взято описание UML State Machine (кстати, рекомендую — это неплохая формальная модель, включающая автоматы Мили и Мура).
В этой части разработки проблем возникло аж две. Первая и главная — “однопоточность” актора. Формально это означает, что вызвать другой объект из актора можно, а вот из этого вызова обратно вызвать актор уже не получится. Фактически же ASF все-таки поддерживает реентерабельность актора, но только если цепочка вызовов началась с него же самого. Причем касается такое разрешение только вызовов между акторами — вызвать, скажем, сервис из актора и обратно вызвать актор опять нельзя. А такая функциональность нужна, например, для широковещательной рассылки, которую инициирует актор, а выполняет каталог, причем сообщение должно уйти и самому автору рассылки. Хорошего решения я не нашел, так что просто разделил актора на две части — одна основная, принимающая сообщения от клиента и управляющая состоянием актора, и вторая дополнительная, которая просто отсылает сообщения клиенту. В результате имеем два актора, через которых идут однонаправленные потоки данных. Типы акторов различны, поэтому адресовать их можно одинаково через SID (в ASF тип актора входит в его адрес, так что даже для одинаковых SID адреса акторов будут различны).
Вторая проблема — время установки соединения (в терминах ADC это переход к состоянию NORMAL). Его имеет смысл ограничить, а ситуация усугубляется еще и тем, что прародитель DC использует тот же порт, причем в DC первое сообщение отправляет именно хаб. В результате DC-клиенты, подключившись, будут ждать ответа до второго пришествия. Самое время применить таймеры и ремайндеры ASF.
Таймеры и ремайндеры
Таймеры и ремайндеры в ASF служат, как следует из их названий, будильниками. Они похожи, но только тем, что вызывают заданные функции согласно заданным интервалам. Таймер — это более легковесный объект, который существует только при активном акторе, а при деактивации актора пропадает. Ремайндер сохраняется и работает отдельно от актора, так что может активировать даже деактивированного актора. Вызовы методов актора для таймеров и ремайндеров, как и все прочие, исполняются все так же “однопоточно”, но вот вызов от ремайндера считается “полноценным” вызовом, который учитывается при деактивации бездействующих акторов. Вызов от таймера использованием актора не считается, так что таймером удержать актора от деактивации невозможно.
Для ограничения времени соединения проще всего использовать одноразовый ремайндер, который посылает псевдо ADC-команду ConnectionTimedOut — состояние NORMAL ее просто проглотит, а все прочие разорвут соединение согласно протоколу.
Каталог пользователей
Внешних коммуникаций сервис не имеет и предназначен исключительно для выполнения внутренних задач, так что для общения с ним логично использовать Remoting. Партиционировать каталог особого смысла нет — состояние сервиса хранит коллекцию идентификаторов, а сам сервис реализует операции над ней в целом. Однако широковещательные рассылки могут создавать нагрузку, для которой одной primary-реплики сервиса может не хватить. И вот тут можно воспользоваться любопытной особенностью stateful сервисов — они могут открывать слушателей даже на вторичных репликах, но только для чтения. Поскольку рассылки в состоянии каталога ничего не меняют, то ничто не мешает для них задействовать все реплики сервиса.
Список текущих SID хранится в словаре ReliableDictionary — в рамках транзакции его можно перечислить, а в значениях ключей хранится информация о пользователе (имя, поддерживаемые возможности клиента и пр.). Отдельный ReliableDictionary приходится использовать и для проверки уникальности имени клиента — просто как уникальный ключ без значений. В разработке каталога каких-то особых граблей не нашлось, но есть нюанс, связанный с отключением клиента.
Причин для отключения клиента всего две — это ошибка в канале связи (источник — TCP-сервер) и ошибка в протоколе (источник — актор). Обе ошибки буду считать фатальными и обрывать соединение с клиентом. Обрабатывать ошибки хотелось бы централизованно, и логично это делать в акторе, как отвечающем за протокол. Для этого можно поступить так же, как и с ремайндером — добавить еще одно псевдо ADC-сообщение DisconnectOccured и включить его в конечный автомат актора. Для полной очистки хорошо бы совсем удалять актора, но как это сделать, если инициатором отключения является сам актор? Эту функциональность можно передать в каталог, в котором воспользоваться ReliableQueue — в эту очередь складываются SID отключаемых клиентов, а в RunAsync каталога эта очередь обрабатывается в бесконечном цикле, который получает из очереди идентификаторы и удаляет соответствующих акторов.
Вот такой вот state выходит:
И в целом разработка подошла к концу. В тестировании на локальном кластере два ADC-клиента (я использовал AirDC++), подключенные к свежеиспеченному хабу, “увидели” друг друга и смогли обменяться файлами. Еще не ура, но уже можно попробовать развернуть хаб в Azure.
Развертывание в Azure
Самая скучная часть повествования, поскольку развертывание прошло как по нотам. Для развертывания использовал Free Trial подписку, управление ASF доступно с нового портала. Для начала выбирается имя кластера, данные RDP-пользователя, группа ресурсов и местоположение. Для количества узлов кластера выбрал три, поскольку “Choosing less than 5 initial VM capacity for your primary node type will designate this cluster as a test cluster.” — не нашел, что такое test cluster, но эту рекомендацию пишет сам портал. В custom endpoints надо не забыть поставить 411, чтобы load balancer пропускал соединения по этому порту. Для тестовых целей проще создать unsecure кластер — вот в целом и все. Несмотря на видимую простоту ASF-кластера в Azure создается целый набор ресурсов:
В список входят хранилища vhd для VM (неясно, почему их 5, а не 3), хранилища для логов и информации Azure Diagnostics, набор виртуальных машин, объединенных в VPN, и прикрывающий все это load balancer с приданным ему публичным IP-адресом.
Развертывание в Azure все же выявило одну проблему, которую я так и оставил нерешенной. Похоже, что Azure проверяет доступность 411 порта, создавая и сразу обрывая TCP-соединения по нему. TCP-сервер же сразу по возникновении соединения создает SID, который тут же оказывается ненужным. Теоретически это правильное поведение — сервер может быть полон (в ADC есть предел количества пользователей для одного хаба), но вот на практике такой подход дает сбой. С другой стороны, для простой проверки эти пустые соединения слишком часты — в общем, пока это тайна, покрытая мраком.
Впрочем, на функционирование это не влияет, так что снова тест, снова два клиента ADC, снова обмен файлами — похоже, все работает. Вот теперь совсем ура.
Заключение
В целом идея себя оправдала — удалось пройтись по всей ASF, и если не задействовать, то хотя бы ознакомиться с различным возможностями и деталями ее функционирования. И хотя не все легло гладко на ASF, но конечный результат не так уж плох для тестового проекта. Надеюсь, что и читателям было любопытно. Исходный код всего проекта можно найти на GitHub — засим прощаюсь до новых статей.
Комментарии (10)

centur
07.08.2016 02:27Ну кстати в сообществе, есть желание сделать глубокую интеграцию с SF, чтобы не было всякого головняка с деплоем и обновлениями. И я знаю что так некоторые делают (и мы тоже возможно соберемся). потому как орлеанс не предоставляет хостинг сам по себе — нужно или в консольке или в вин-сервисе или в клауд сервисе хостить. Там у каждого свой велосипед с обновлениями, кластером и мониторингом здоровья. А СФ именно предлагает полный стек — с хорошей штукой вокруг инфраструктуры и убого скопированной моделью акторов.
Низкоуровневые кейсы это например про описанный сценарий TcpListener. Может я не очень понял для чего такие сложности, хотя видно необходимы без поддержки клиентской подписки. А при наличии стримов — такие коммуникации организовываются очень просто.

Caraul
07.08.2016 11:53Вот мы в Cloud Service и хостим — нам еще нужен WebApi, так вот в ASF это было бы все вместе, а в Cloud Service приходится поднимать Web Role. Зато масштабируем как хотим. Как обычно «сразу из коробки» vs «делай сам как хочешь».
TcpListener нужен для ADC, тут без вариантов.centur
07.08.2016 13:16Та же самая схема…
Ну учитывая что орлеанс хост жадный до памяти и CPU чтобы работать наиболее эффективно — засовывать все на одну машину все равно не рекомендуется, что в cloud service, что в SF. Сейчас вы это тоже можете сделать захостив Host или клиента в отдельном AppDomain, примеры есть в тестах. Это даст отсутствие раундтрипа по сети только если клиент обращается к зерну в сило на нем самом. А так — будете также общаться по сети между вебролями.
А теперь представьте кейс когда в SF у вас по какой-то причине на одной машине будет 2-3 сило крутиться и драться за CPU — чем это полезно то? Да, фабрика из коробки прикольная, но все же я бы ставил на орлеанс.Caraul
07.08.2016 16:53А откуда в ASF «на одной машине 2-3 сило»? Насколько я понимаю, там на каждом узле крутятся инстансы stateless и реплики stateful (поскольку акторы в AFS это специальная разновидность stateful), причем ASF старается primary реплики раскидывать по разным узлам. Они, конечно, могут и сойтись на одном узле, но это все-таки не «монолитное» silo Orleans, внутренняя организация скорее всего другая.
centur
08.08.2016 10:51Да, точно, это я смешал со своими размышлениями о потенциальных граблях Орлеанс когда они поверх SF… Мой косяк.
А вы кстати тут упомянуты ? Если нет — отправляйте PR, adoption cases всегда интересны.
Caraul
08.08.2016 21:06Нет, мы только-только прошли коммерческий релиз (не скажу что во избежание рекламы), да и надо согласовать с NDA, но, может, и объявимся.
centur
07.08.2016 13:17а, про Tcp теперь понял, у нас наверное похожая ситуация с вебсокетами — стримы просто сказка для этого...
centur
А почему не взяли Orleans? Из всего что вы описали выглядит так, что решение принималось — "потому что это Майкрософт", а не исходя из объективных потребностей проекта и удобств фреймворков.
А тут так много описаний низкоуровневых кейсов, т.е. то что фремворк призван решить и спрятать — он выдает наружу и создает сложности программистам. К тому же можно взгромоздить Orleans на SF в Stateless Worker, хотя мы чем дальше — тем более скептически смотрим на это решение. SF выглядит хорошо в плане возможностей devops, но в плане актеров — Orleans ощутимо впереди. В gitter проекта Orleans народ плачет когда их заставляют переходить на SF...
Caraul
Ключевое слово тут «для примеров». Это не реальная разработка, а изучение ASF. Orleans есть у нас в реальном проекте, и да, по акторам Orleans выглядит симпатичнее. Но у ASF и Orleans разные цели — ASF это все «из коробки», включая какую-нито панель управления, Orleans именно что фреймворк. Завести Orleans в Stateless сервис наверное, можно, но с ходу выглядит как уж с ежом — на мой взгляд если уж Orleans, то и вся обвязка должна быть своя. А про какие низкоуровневые кейсы Вы говорите?