
Идея для написания этой статьи возникла прошлым летом, когда я слушал доклад на конференции BigData по нейронным сетям. Лектор «посыпал» слушателей непривычными словечками «нейрон», «обучающая выборка», «тренировать модель»… «Ничего не понял — пора в менеджеры», — подумал я. Но недавно тема нейронных сетей все же коснулась моей работы и я решил на простом примере показать, как использовать этот инструмент на языке JavaScript.
Мы создадим нейронную сеть, с помощью которой будем распознавать ручное написание цифры от 0 до 9. Рабочий пример займет несколько строк. Код будет понятен даже тем программистам, которые не имели дело с нейронными сетями ранее. Как это все работает, можно будет посмотреть прямо в браузере.
Если вы уже знаете что такое Perceptron, следующую главу нужно пропустить.
Совсем немного теории
Нейронные сети возникли из исследований в области искусственного интеллекта, а именно, из попыток воспроизвести способность биологических нервных систем обучаться и исправлять ошибки, моделируя низкоуровневую структуру мозга. В простейшем случае она состоит из нескольких, соединенных между собой, нейронов.
Математический нейрон
Несложный автомат, преобразующий входные сигналы в результирующий выходной сигнал.
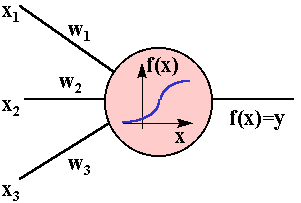
Сигналы x1, x2, x3 … xn, поступая на вход, преобразуются линейным образом, т.е. к телу нейрона поступают силы: w1x1, w2x2, w3x3 … wnxn, где wi – веса соответствующих сигналов. Нейрон суммирует эти сигналы, затем применяет к сумме некоторую функцию f(x) и выдаёт полученный выходной сигнал y.
В качестве функции f(x) чаще всего используется сигмоидная или пороговая функции.
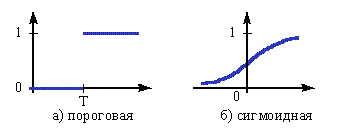
Пороговая функция может принимать только два дискретных значения 0 или 1. Смена значения функции происходит при переходе через заданный порог T.+
Сигмоидная – непрерывная функция, может принимать бесконечно много значений в диапазоне от 0 до 1.
UPD: В комментариях также упоминаются функции ReLU и MaxOut как более современные.
Архитектура нейронной сети может быть разной, мы рассмотрим одну из простых реализаций нейронной сети — Perceptron
Архитектура Perceptron

Есть слой входных нейронов (где информация поступает из вне), слой выходных нейронов (откуда можно взять результат) и ряд, так-называемых, скрытых слоев между ними. Нейроны могут быть расположены в несколько слоёв. Каждая связь между нейронами имеет свой вес Wij
Входные и выходные сигналы
Перед тем, как подавать сигналы на нейроны входящего слоя сети нам их нужно нормализовать. Нормализация входных данных — это процесс, при котором все входные данные проходят процесс «выравнивания», т.е. приведения к интервалу [0,1] или [-1,1]. Если не провести нормализацию, то входные данные будут оказывать дополнительное влияние на нейрон, что приведет к неверным решениям. Другими словами, как можно сравнивать величины разных порядков?
На нейронах выходного слоя у нас тоже не будет чистой «1» или «0», это нормально. Есть некий порог, при котором мы будем считать, что получили «1» или «0». Про интерпретацию результатов поговорим позже.
«Пример в студию, а то уже засыпаю»
Для удобства я рекомендую себе поставить nodejs и npm.
Мы будем описывать сеть с помощью библиотеки Brain.js. В конце статьи я также дам ссылки на другие библиотеки, которые можно будет сконфигурировать похожим образом. Brain.js мне понравился своей скоростью и возможностью сохранять натренированную модель.
Давайте попробуем пример из документации — эмулятор функции XOR:
var brain = require('brain.js');
var net = new brain.NeuralNetwork();
net.train([{input: [0, 0], output: [0]},
{input: [0, 1], output: [1]},
{input: [1, 0], output: [1]},
{input: [1, 1], output: [0]}]);
var output = net.run([1, 0]); // [0.987]
console.log(output);
запишем все в файл simple1.js, чтоб пример заработал, поставим модуль brain и запустим
npm install brain.js
node simple1.js # [ 0.9331839217737243 ]
У нас 2 входящих нейрона и один нейрон на выходе, библиотека brain.js сама сконфигурирует скрытый слой и установит там столько нейронов, сколько сочтет нужным (в этом примере 3 нейрона).
То, что мы передали в метод .train называется обучающей выборкой, каждый элемент которой состоит из массива объектов со свойством input и output (массив входящих и выходящих параметров). Мы не проводили нормализацию входящих данных, так как сами данные уже приведены в нужную форму.
Обратите внимание: мы на выходе получаем не [0.987] а [0.9331...]. У вас может быть немного другое значение. Это нормально, так как алгоритм обучения использует случайные числа при подборе весовых коэффициентов.
Метод .run применяется для получения ответа нейронной сети на заданный в аргументе массив входящих сигналов.
Другие простые примеры можно посмотреть в документации brain
Распознаем цифры
В начале нам нужно получить изображения с рукописными цифрами, приведенными к одному размеру. В нашем примере мы будем использовать модуль MNIST digits, набор тысяч 28x28px бинарных изображений рукописных цифр от 0 до 9:

Оригинальная база данных MNIST содержит 60 000 примеров для обучения и 10 000 примеров для тестирования, ее можно можно загрузить с сайта LeCun. Автор MNIST digits сделал доступной часть этих примеров для языка JavaScript, в библиотеке уже проведена нормализация входящих сигналов. С помощью этого модуля мы можем получать обучающую и тестовую выборку автоматически.
Мне пришлось клонировать библиотеку MNIST digits, так как там есть небольшая путаница с данными. Я повторно загрузил 10 000 примеров из оригинальной базы данных, так что использовать надо MNIST digits из моего репозитория.
Конфигурация сети
Во входном слое нам необходимо 28x28=784 нейрона, на выходе 10 нейронов. Скрытый слой brain.js сконфигурирует сам. Забегая наперед, уточню: там будет 392 нейрона. Обучающая выборка будет сформирована модулем mnist
Тренируем модель
Установим mnist
npm install https://github.com/ApelSYN/mnist
Все готово, обучаем сеть
const brain = require('brain.js');
var net = new brain.NeuralNetwork();
const fs = require('fs');
const mnist = require('mnist');
const set = mnist.set(1000, 0);
const trainingSet = set.training;
net.train(trainingSet,
{
errorThresh: 0.005, // error threshold to reach
iterations: 20000, // maximum training iterations
log: true, // console.log() progress periodically
logPeriod: 1, // number of iterations between logging
learningRate: 0.3 // learning rate
}
);
let wstream = fs.createWriteStream('./data/mnistTrain.json');
wstream.write(JSON.stringify(net.toJSON(),null,2));
wstream.end();
console.log('MNIST dataset with Brain.js train done.')
Создаем сеть, получаем 1000 элементов обучающей выборки, вызываем метод .train, который производит обучение сети — сохраняем все в файл './data/mnistTrain.json' (не забудьте создать папку "./data").
Если все сделали правильно, получите приблизительно такой результат:
[root@HomeWebServer nn]# node train.js
iterations: 0 training error: 0.060402555338691676
iterations: 1 training error: 0.02802436102035996
iterations: 2 training error: 0.020358600820106914
iterations: 3 training error: 0.0159533285799183
iterations: 4 training error: 0.012557029942873513
iterations: 5 training error: 0.010245175822114688
iterations: 6 training error: 0.008218147206099617
iterations: 7 training error: 0.006798613211310184
iterations: 8 training error: 0.005629051609641436
iterations: 9 training error: 0.004910207736789503
MNIST dataset with Brain.js train done.
Все можно распознавать
Осталось написать совсем немного кода — и система распознавания готова!
const brain = require('brain.js'),
mnist = require('mnist');
var net = new brain.NeuralNetwork();
const set = mnist.set(0, 1);
const testSet = set.test;
net.fromJSON(require('./data/mnistTrain'));
var output = net.run(testSet[0].input);
console.log(testSet[0].output);
console.log(output);
Получаем 1 случайный тестовый пример из выборки 10 000 записей, загружаем натренированную ранее модель, передаем на вход сети тестовую запись и смотрим правильно ли она распозналась.
Вот пример выполнения
[ 0, 0, 0, 1, 0, 0, 0, 0, 0, 0 ]
[ 0.0002863506627761867,
0.00002389940760904011,
0.00039954062883041345,
0.9910109896013567,
7.562879202664903e-7,
0.0038756598319246837,
0.000016752919557362786,
0.0007205981595354964,
0.13699517762991756,
0.0011053963693377692 ]
В примере в сеть на входящие нейроны поступила оцифрованная тройка (первый масив это идеальный ответ), на выходе сети мы получили массив елементов, один из которых близок к единице (0.9910109896013567) это тоже третий бит. Обратите внимание на четвертый бит там 7.56… в -7 степени, это такая форма записи чисел с плавающей точкой в JavaScript.
Ну что же, распознавание прошло правильно. Поздравляю, наша сеть заработала!
Немного «причешем» наши результаты функцией softmax, которую я взял из одного примера по машинному обучению:
function softmax(output) {
var maximum = output.reduce(function(p,c) { return p>c ? p : c; });
var nominators = output.map(function(e) { return Math.exp(e - maximum); });
var denominator = nominators.reduce(function (p, c) { return p + c; });
var softmax = nominators.map(function(e) { return e / denominator; });
var maxIndex = 0;
softmax.reduce(function(p,c,i){if(p<c) {maxIndex=i; return c;} else return p;});
var result = [];
for (var i=0; i<output.length; i++)
{
if (i==maxIndex)
result.push(1);
else
result.push(0);
}
return result;
}
Функцию можно поместить в начало нашего кода и последнюю строку заменить на
console.log(softmax(output));
Все друзья — теперь все работает красиво:
[root@HomeWebServer nn]# node simpleRecognize.js
[ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ]
[ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ]
[root@HomeWebServer nn]# node simpleRecognize.js
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 ]
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1 ]
[root@HomeWebServer nn]# node simpleRecognize.js
[ 0, 0, 0, 0, 0, 0, 1, 0, 0, 0 ]
[ 0, 0, 0, 0, 0, 0, 1, 0, 0, 0 ]
Иногда сеть может давать неправильный результат (мы взяли небольшую выборку и поставили не достаточно строгую погрешность).
А как распознать цифру, которую напишете вы?
Конечно, тут нет никакой подтасовки, но все же хочется самому проверить «на прочность» то, что получилось.
С помощью HTML5 Canvas и все тем же brain.js-ом с сохраненной моделью мне удалось сделать реализацию распознавания в браузере, часть кода для отрисовки и дизайн интерфейса я позаимствовал в интернете. Можете попробовать вживую. В мобильном устройстве рисовать можно пальцем.
Ссылки по теме
- Библиотеки на JavaScript для работы с нейронными сетями
- Все примеры из статьи на github
- Живой пример распознавания цифры в браузере
- [Eng] Почему стоит использовать библиотеку brain.js а не brain
UPD: Альтернативные реализации живого примера 1, 2 на JavaScript из комментариев и личной переписки.
Поделиться с друзьями
impwx
Статья очень наглядная и легко читается, спасибо.
Полагаю, нужен еще пороговый коэффициент, меньше которого считаем, что число не распознано вообще.
apelsyn
Спасибо, доработаем.
MximuS
Наверно у меня просто очень плохой подчерк.

А за статью спасибо, крайне наглядно и информативно.
ionicman
так-то я бы тоже ответил что это 3 :D
terloger
:)
DSL88
еще веселее

apelsyn
:) Я уже подумывал о том чтоб загрузить в обучающую выборку все 60 000 примеров + 10 000 тестовых картинок.
coller13
Думаю, дело не только в почерке
yadi.sk/i/IijN1bEKsvbmx
firya
С шестерками проблемы еще больше
apelsyn
Да так и есть, иногда путает 1 и 7-ку. Надо увеличивать обучающую выборку. В идеале прогнать через сеть все 60 000 примеров + ваши с правильным ответом. У меня на это не хватило терпения. :)
Zenitchik
А автоматизировать?
apelsyn
Для демонстрации того что есть достаточно, а на усложнение этого кода у меня нету времени.
Вы можете клонировать код на гитхаб и предложить свою реализацию, давайте вместе делать код лучше!
Zenitchik
Прицелился это сделать. Займусь, когда у меня будут задачи. Если выйдет что-то достойное выкладки (а я очень самокритичен) — выложу.
SazereS
У него явно проблемы с девятками

AleX_gRey
Вот тоже интересно

Roma-Pro
Здорово! Спасибо за статью!
A1one
А почему повторное определение цифры изменяет исходник и в последующих попытках приводит к самым непредсказуемым результатам?
apelsyn
Уточните суть проблемы, там могут быть проблемы с выделением памяти, т.к. загружается код размером 11M. Оновная часть кода сериализированная натренированная модель.
A1one
просто нарисуйте цифру и несколько раз понажимайте «распознать» — поймете, о чем я.
Исходная нарисованная цифра ниачинает видоизменяться, причем сильно. Соотв. и распознавание другое…
Как то так…
apelsyn
Я Вас понял, сегодня вечером пофикшу этот баг, повторно распознавать нету никакого смысла.
Mingun
Дело видимо в том, что распознаётся не та картинка, которую вы рисуете не холсте, а та, что находится справа-внизу и содержит уменьшенную копию нарисованного вами изображения. По нажатию на кнопку «распознать» картинка с большого холста копируется на маленький, соответственно, она уменьшается, но затем зачем-то эта уменьшенная версия копируется обратно на большой холст. В итоге, после нескольких итераций картинка изменяется до неузнаваемости.
apelsyn
Я понял — это баг. Уже пофиксил.
xytop
После определения показывается отмасштабированная картинка приведенного исходника ( 28х28 пикселей).
Каждое новое определение снова меняет масштаб, отсюда и разница.
anttoshka
В Firefox 47.0 не работает ввод (не рисуется символ). В хроме все цифры распознает правильно, ошибок не заметил.
Psychosynthesis
У меня тоже 47-й (стоит Adblock+стандартный набор дополнений), и всё работает. Очевидно проблема на вашей стороне.
Fen1kz
А мне не понравилось, описываете известные факты, а самое интересное заменяете библиотекой. Я думал будет статья по подобию вот этой, где автор вместе с читателем строит сеть на js сам
ezhikov
Спасибо за ссылку.
brickerino
От примерно того же автора (Карпатого) есть вот этот интересный материал: http://cs231n.github.io/
Этот курс дописан, в отличии от ссылки.
Также достаточно интересен tutorial от создателей theano: http://deeplearning.net/tutorial/
apelsyn
Это статья для начинающих. Упор на простоту. В идеале читатель загружает код и пробует у себя на компе тренировать сеть самомтоятельно. То о чем пишете вы — это усложнение задачи. Но идея интересная.
brickerino
Это не статья для начинающих. JS и нейросети это как автобус из буханки, на мой взгляд. Для начинающих — это какой-нибудь pybrain, и то он жутко медленный.
Тэги: JavaScript*, Big Data*
Ну да.
Zibx
JS таки заметно быстрее чем py.
brickerino
>JS таки заметно быстрее чем py
Есть ли под JS либы с jit-компиляцией? Обычно используют theano+[lasagne|keras] либо torch, caffe, tensorflow. Чем определен выбор JS?
Ладно, на самом деле в статье обычный пример обучения. Просто самого содержания статьи нету. Нейронные сети — это не про программирование, это про машинное обучение и deep learning. Это про то, что скрывается за net.train(). А тут в статье даже слова градиент нету.
>Код будет понятен даже тем программистам, которые не имели дело с нейронными сетями ранее.
Последовательность действий будет понятна даже тем программистам, которые никогда не занимались пайкой ранее.
>В качестве функции f(x) чаще всего используется сигмоидная или пороговая функции
Пороговая функция в качестве функции активации использоваться не может, потому что, внезапно, ее производная не равна нулю на множестве меры 0. Тут скорее надо упомянуть тангенциальную функцию, rectifier, leaky rectifier.
GoldJee
У меня тоже после прочтения этой фразы сложилось (возможно) неверное впечатление, что это умозрительные рассуждения на досуге человека, уставшего от ведения «однообразной жизни занимаясь софтом, железом, и отвечая на однотипные вопросы пользователей».
Хотя по тексту статьи видно, что человек более-менее разбирается в предмете, о котором рассуждает.
Просьба дать ссылку на исследование, подтверждающее результаты мысленного эксперимента из параграфа «Замедление времени». У меня не всплывают в памяти такие научные работы. Более того, вытягивание света в линию, параллельную движущимся зеркалам, кажется мне совсем неочевидным. Также для меня неочевиден следующий из этого вывод, что «фотон не имеет ни прошлого, ни будущего».
BelBES
А смысл в подобных знаниях на обезьяньем уровне? Ну т.е. на MNIST'е оно работает, а на более сложных задачах почти наверняка возникает масса проблем при тренировке, которые даже продиагностировать нельзя без понимания того, что находится под капотом у tran'а...
apelsyn
В статье достаточно информации для того чтоб заинтересовать человека, который никогда с этим не сталкивался. Ну Вам не угодил, — бывает.
BelBES
Да не сочтут за троллинг, но вы путаетесь в показаниях: сначала вы говорите, что JS-разработчик может использовать ML как черный ящик, а сейчас уже говорита о том, что статья вроде как должна заинтересовать к дальнейшему изучению темы, т.е. лезть внутрь train'а :-)
tretyakovpe
если не двигать зеркало, луч улетит вперёд и в сторону последнего отражения.
если зеркала двигаются со скоростью света, тогда луч всё время находится между ними.
я так понял.
про то, откуда берется энергия на бесконечное отражение, думаю не стоит задумываться
Zibx
Скоро всё будет. Это не тот язык, который ожидали, но именно он дотянет человечество до сингулярности. Недавно его стало возможно компилировать в native код. Исполнение из коробки на любом тостере. Чувствую грядущую бурю.
Dark_Daiver
И чем же JS лучше остальной кучи языков c компиляцией в native?
Paul_Smith
Пример очень наглядный, спасибо. Но сигмоида была «самой популярной» довольно давно, я бы сказал, что сейчас актуельнее ReLU
darkAlert
И во многих местах даже уже не ReLU, а MaxOut и его производные :)
BelBES
А можно подробней, где эти "многие места" можно посмотреть?
Если посмотреть на распознавание изображений, то там мейнстрим как-раз ReLU (причем самое тупое, с нулем в отрицательной области). Во всяких GoogLeNet, ResNet etc. именно такая активация используется.
gsaw
Судить о человеке по тому, чем он работает еше смешнее. Эйнштейн в патентном бюро работал, Циалковский в школе учителем, Франклин был газетчиком, послом.
rerf2010rerf
Так я не о человеке, я о ситуации в целом. Что-то мне подсказывает, что все вышеупомянутые люди сделали несколько больше, чем несколько дней думали в высоком.
apelsyn
Да, вы правы, я добавил в теоретическую часть Вашу ссылку
mlg
Здесь лучше распознаётся, да и работает быстрее.
apelsyn
Да, это хороший пример. Стоит отметить что в этом примере модель обучалась с помощью Matlab (это указано автором в коментариях). Это уже не чистый JavaScript.
xytop
Интересно, что размер модели меньше более чем в 10 раз при лучшем качестве :)
darkAlert
Под размером вы подразумеваете размер файла обученной сети, или количество обучаемых параметров (весов) сети?
Shifty_Fox
Ну так оно релятивисткое замедление движения группы частиц на квантовом\микро уровне, что выражается в ощущении замедлении времени, и время здесь снова искусственно введенная величина.
darkAlert
ну тут все зависит от способа упаковки данных. Размер сети лучше смотреть когда она загружена в оперативную память. Хотя тоже не показатель.
p.s. «У вас » — не у меня, я просто мимо проходил :)
apelsyn
Да вот такие они загадочные эти нейронные сети. Если нейронов мало — сеть «тупая», если нейронов много — сеть «зубрилка». Там автор в скрытом слое указал 200 нейронов c одинарной точностью (движок brain.js создал 392 нейрона с двойной точностью ). Для понятности и красоты модели используется JSON.stingify с отступами. Ну и формат серилизации у brain.js попрожористее.
Точность распознавания визуально оценивать сложно. Измерить можно на выборке для тестирования из базы MNIST. Там 10000 тестовых примеров. Я таких замеров не проделывал, т.к. для демонстации работы сети, того что я сделал — достаточно.
HunterXXI
согласен
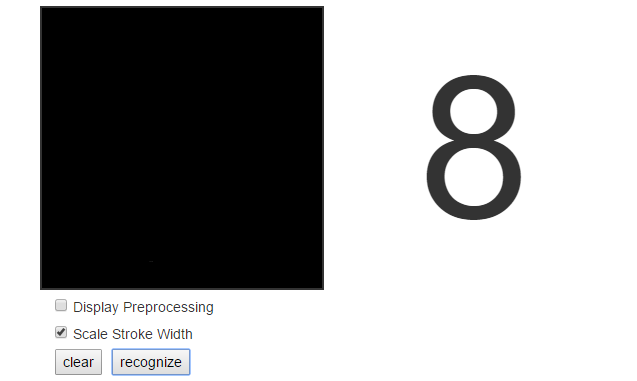
P.S. Кстати оба варианта в черном квадрате распознают восьмерку. Стабильно и без ошибок.
mlg
На восьмёрку больше всего «чернил» уходит, поэтому представляется логичным, что картинка, которая вообще вся чёрная, и распознаётся как восьмёрка.
HunterXXI
Думал даже римские распознает


Ан нет…
aledein
Спасибо за статью+++
muhaa
Просто прочитайте книгу Сасскинда «Квантовая механика. Теоретический минимум». Основы квантовой механики там разжеваны до такой степени, что понять их можно с начальной подготовкой инженерного вуза. На осознание скорее всего понадобится несколько месяцев. После этого можете пробежаться по начальным главам учебников, типа Ландау-Лифшица 3.
После этого посмотрите на свою идею снова.
У меня тоже когда-то сходной природы «идеи». Я сделал как советую Вам. Идеи не исчезли совсем, одни ушли, другие пришли. Для проверки этих других снова надо погружаться в учебники и так далее.
apelsyn
Я не проганял, после выходных отпишу.
apelsyn
Я еще раз потренировал модель на полной 60 000 выборке, прогнал тестовую выборку (10 000 записей) и получил 1,77% погрешность. Это средний показатель, если смотреть таблицу на сайте MNIST.
tretyakovpe
фундаментальная трудность в том, что нам нужно знать, что инфа пошла. т.е. начало сессии. но мы об этом узнаем только когда доживём до этого.
brainick
Краткое содержание статьи: мы взяли библиотеку, написанную умными людьми, подключили и решили игрушечную задачу.
apelsyn
А вы что в машинных кодах модели тренируете, или калькулятор предпочитаете? Я рассказал о хорошем инструменте для JavaScript.
Отличная задача для начинающих, простая и наглядная.
babylon
Почитаем статью все равно, но позже.
eavprog
На js нейронные сети — это не слабо. Автору респект.
NickKolok
Автору спасибо. В качестве пожеланий к следующей серии, если таковая будет — классификатор изображений, тоже на JS. Отличие котиков от некотиков, причём с подробностями: как сделать нормализацию сигнала, как обрабатывать произвольные изображения и т. д.
apelsyn
Не уверен что это задача для JavaScript. При распознавании изображений во входном слое будет очень много нейронов, а nodejs и др. реализации js однопоточные. (Это означает что в один момент времени будет задействовано только одно ядро). Но натренированную модель для классификации фото загрузить в js реально.
gearbox
Ну какже? С одной стороны баррикад желающие распознавать капчу прямо в броузере (например на фантоме), с другой стороны — желающие определять ботов по отличию в поведении от человека (выделения текста, поведение курсора — в общем паттерны поведения), и это идеальная задача для нейросетей, а решение ее прямо в броузере — бизнесом востребовано.
А опыт Америки в второй мировой показывает что торговать оружием с обеими сторонами — выгодно )
punkkk
Проблемы с единичками.
c2n.me/3zQaWvF
Rix
Вообще, круто было бы если хотя бы пример с xor'ом был описан как работает. Про библиотеку интересно, но как-то получается, что сначала общая схема перцептрона, а потом сразу распознавание с помощью библиотеки в две строчки. Без этого теория вначале как-то лишней выглядит.
youngmysteriouslight
Прошу прощения за дилетантский вопрос, снейросетями не работал до этого:
почему на выходе 10 нейронов по числу вариантов ответа, а не 4 по количеству фактической информации?
yar3333
Каждый выходной нейрон голосует за свою цифру. Какой нейрон выдал бОльший сигнал — та цифра и является правильной. Что за фактическая информация, которой здесь 4 штуки?
yar3333
А, понял. 4 — это вообще из другого примера — реализация XOR через нейронную сеть. Не имеет отношения к распознаванию цифр вообще.
youngmysteriouslight
Я не уверен, что Вы правильно меня поняли, поэтому опишу свой вопрос подробнее.
В первом примере с XOR написано:
Один нейрон «голосует» за результат XOR-а, т.е. за 0 или 1, и возвращаемое значение из интервала [0,1] мы интерпретируем как 0 или 1 в зависимости от того, к какому краю интервала ближе, а отклонение — как меру возможной ошибки. Скажем, чем ближе к 0.5, тем сложнее коррекно интерпретировать результат. Верно?
В задаче с цифрами есть 10 различных вариантов, то есть мы хотим получить чуть больше 3 битов информации.
Если делать по аналогии с тем, что написал выше, то должно быть 4 выхода по числу бит, которые мы хотим получить.
Если же мы говорим, что каждому варианту должен соответствовать свой выход и нейросеть голосует за каждый вариант отдельно, то в задаче с XOR должно быть 2 выхода.
Если мы говорим, что в задаче с XOR достаточно одного выхода, потому что «голос за 0» = 1 — «голос за 1» и нечего подавать на выход избыточную информацию, то в задаче с цифрами должно быть 9 выходов.
В общем, не получается у меня согласовать два примера, отсюда и вопрос.
yar3333
Вообще, нейросеть не особо налагает ограничений на то, как интерпретировать выходной слой. Однако, обычно (более правильный вариант) — по одному нейрону на один возможный вариант ответа. В противном случае натренировать нейросеть (да ещё и получать стабильные результаты) становится сильно сложнее.
Вот то, что ф-ия обучения справилась с таким вот сложным случаем — XOR на сети с одним выходом — нередко показывают в качестве демонстрации крутости алгоритма обучения (эдакий канонический пример). В реальных задачах так делать не нужно.
babylon
Ярик, чтобы что-то анализировать нейросетями, нужно довести анализируемое до состояния градуальности. В этом случае работают даже вероятностные алгоритмы. И тренировать ничего не надо.