
Что не так с репозиторием? Очевидно, что с самим паттерном все нормально, но разница в его понимании разработчиками. Я попробовал исследовать это и наткнулся на два основных момента, которые, на мой взгляд, являются причиной разного к нему отношения. Одним из них является «скользящая» ответственность репозитория, а другой связан с недооценкой unit testing. Под катом я объясню первый.
Скользящая Ответственность Репозитория
Когда речь заходит о построении архитектуры приложения у всех в голове сразу возникает представление о трех слоях: слой представления (Presentation Layer), бизнес логики (Business Layer) и слой данных (Data Layer) (см MSDN). В таких системах объекты бизнес логики используют репозитории для извлечения данных из физических хранилищ. Репозитории возвращают бизнес-сущности вместо сырых рекордсетов. Очень частно это обосновывается тем, что если бы нам нужно было заменить тип физического хранилища (база, файл или сервис), то мы сделали бы абстрактный класс репозитория и реализовали бы специфичный для нужного нам хранилища. Выглядит примерно так:
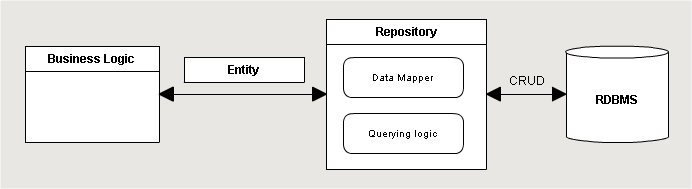
О таком же разделении говорит Мартин Фаулер и MSDN. Как обычно, описание — это, всего лишь, упрощенная модель. Поэтому, хотя это выглядит правильно для небольшого проекта, это вводит в заблуждение, когда вы пытаетесь перенести этот паттерн на более сложный. Существующие ORM еще сильнее сбивают с толку, т.к. реализуют многие вещи из коробки. Но представим, что разработчик знает только как использовать Entity Framework (или другой ORM) только для получения даных. Куда, например, он должен поместить кеш второго уровня, или логирование всех бизнес-операций? В попытке сделать это, очевидно, что он будем стараться разделить модули по функционалу, следую SPR из SOLID, и построить из них композицию, которая, возможно, будет выглядеть так:

Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища. Эта ответственность была перенесена в другой объект. На этой почве возникает первая нестыковка между лагерями абстракционистов и конкретистов.
Вместо анализа
Если принять за правило, что все термины должна сохранять свое значение вне зависимости от модификаций кода, то было бы правильно на первом этапе не называть репозиторием объект, который просто возвращает данные. Это DAO паттерн чистой воды, т.к. его задача спрятать конкретный интерфейс доступа к данным (ling, ADO.NET, или что-то еще). В то же время репозиторий может не знать о таких деталях вообще ничего, собирая в единую композицию все подсистемы доступа к данным.
Считаете ли вы, что такая проблема существет?
Комментарии (160)

indestructable
06.07.2016 12:07Для меня паттерн "репозиторий" выполняет две функции:
- Отделяет код работы с внешним состоянием (хранилищем, кэшем) от бизнес-логики (я предпочитаю SOA и anemic model), позволяя писать тесты с моками.
- Инкапсулирует код работы с данными, который потенциально может изменить место выполнения: например, был LINQ-запрос, стала table function, было ORM-сохранение, стала хранимая процедура.

ETman
06.07.2016 13:57Проблем с тестированием этого не возникнет? В одной сущности намешано несколько вещей (SPR не соблюдается), как я вас понимаю.
indestructable
06.07.2016 17:45Проблем с тестированием чего?
С тестированием бизнес логики нет проблем — код работы с состоянием вынесен в репозиторий, получаются практически stateless сервисы.
С тестированием репозитория — обычно тесты на репозиторий не пишу, т.к. код типовой и использует ORM.ETman
06.07.2016 17:52Если у вас в репозитории только linq запрос или вызов хранимки, разве это репозиторий? Это «тупой» DAO.
VolCh
06.07.2016 18:02Репозиторий — это не начинка, а функция для клиентов. Они обращаются к нему на языке домена, а не физического хранилища.

lair
06.07.2016 18:02+1Если у вас в репозитории только linq запрос или вызов хранимки, разве это репозиторий?
Конечно, репозиторий. До тех пор, пока вы снаружи предоставляете соответствующий интерфейс (а Expression, как ни странно, вполне удовлетворяет паттерну Query Object), совершенно не важно, что внутри.
ETman
06.07.2016 18:10Мне необходимо понять о чем именно вы говорите.
Вы считаете CRUD-интерфейс — это нормально для репозитория? Я о таком, где, например:
IList Load()
void Update(T item)
void Add(T item)
void Delete(T item)
Или в репозитории должны быть методы типа, но не CRUD:
IList GetItemsBy(int id)
IList GetItemByParent(TParent p)
?lair
06.07.2016 18:16Во-первых, ваши "но не CRUD" методы — это всего лишь специализация R из CRUD.
Во-вторых, вот что считает Эванс:
For each type of object that needs global access, create an object that can provide the illusion of an in-memory collection of all objects of that type. Set up access through a well-known global interface.
Provide methods to add and remove objects, which will encapsulate the actual insertion or removal of data in the data store. Provide methods that select objects based on some criteria and return fully instantiated objects or collections of objects whose attribute values
meet the criteria, thereby encapsulating the actual storage and query technology.
Таким образом, типичный CRUD-интерфейс
interface IRepository<T,TKey> { T Get(TKey key); IQueryable<T> Query(); Add(T entity); Delete(T entity); }
вполне является репозиторием по Эвансу (и по Фаулеру, поскольку Фаулер ссылается на Эванса).

areht
07.07.2016 01:31> IQueryable Query();
Никогда не наступали, что ORM не может выполнить запрос?
Где у вас «methods that select objects based on some criteria»? Где «encapsulating the actual storage and query technology»?lair
07.07.2016 01:36Никогда не наступали, что ORM не может выполнить запрос?
Наступал, конечно.
Где у вас «methods that select objects based on some criteria»?
Вот:
T Get(TKey key); IQueryable<T> Query();
Где «encapsulating the actual storage and query technology»?
А где вы видите, чтобы хранилище или механизм запросов были выставлены наружу?
areht
07.07.2016 01:55Наружу выставится не механизм, а его текущие абстракции и приседания с попытками заставить IQueryable выполниться.
То есть я утверждаю, что разница между
IQueryable Query();
IEnumerable Query(string whereSqlExpression);
только в синтаксическом сахаре.
lair
07.07.2016 01:59Наружу выставится не механизм, а его текущие абстракции и приседания с попытками заставить IQueryable выполниться.
Ну да, выставится текущая как решето абстракция
IQueryableот неизвестного вам провайдера. Эта абстракция особо ничем не лучше и не хуже любой другой.
IQueryable Query();
IEnumerable Query(string whereSqlExpression);
Ну если вы правда считаете, что синтаксическое дерево, привязанное к прикладной модели, по сравнению с неизвестной сторокой — это всего лишь синтаксический сахар… тогда и любая спецификация — это синтаксический сахар. В чем разница?
areht
07.07.2016 02:02Разница в том, что метод FindAllActiveCustomers даёт привязку прикладной модели, и не решето.
lair
07.07.2016 02:03Разница в том, что метод FindAllActiveCustomers даёт привязку прикладной модели, и не решето.
Угу. А потом вам надо найти всех активных кастомеров с вип-статусом, созданных за последнюю неделю. Что будем делать?
(ну и да, FindAllActiveCustomers — не спецификация)
areht
07.07.2016 02:11писать заведомо выполнимый linq в БЛ, например.
lair
07.07.2016 02:12В где, простите? (лучше сразу с примером)
areht
07.07.2016 02:16в бизнес-логике
FindAllActiveCustomers().Where(...)
Кстати, а как вы тестируете, что ваш неработающий запрос от IQueriable работает?lair
07.07.2016 02:18FindAllActiveCustomers().Where(...)
А что возвращает
FindAllActiveCustomers?
Кстати, а как вы тестируете, что ваш неработающий запрос от IQueriable работает?
Интеграционными тестами.
areht
07.07.2016 02:29fully instantiated collections of objects whose attribute values meet the criteria
IEnumerable Custumer
> Интеграционными тестами.
Тоже метод.lair
07.07.2016 12:32-1fully instantiated collections of objects whose attribute values meet the criteria
Если буквоедствовать, то
IEnumerable— это не fully instantiated collection, там же lazy.
IEnumerable Custumer
Ага. Полтора миллиона активных кастомеров — перебирать в памяти сервера под
Where. Круть.
Если серьезно, то все это опять компромисы.
На одном конце спектра — явные intention-revealing методы навроде
GetActiveCustomers,GetPendingBills, и все такое. Красиво, явно, читабельно, внутри максимально заоптимизировано, ничего никуда не течет. Но — количество таких методов растет как комбинация всех вариантов поиска/фильтрации (а у нас еще есть сортировки, группировки и агрегаты), а если какого-то метода недодали, то придется использовать локальную обработку на сервере со всеми вытекающими. Мой любимый пример — это требование построить поверх такого репозитория типичный для LOB-приложения грид на 18 колонок с сортировкой/фильтрацией по любой из них (включая любую их комбинацию по and/or).
На другом конце спектра — открытый
IQueryable. Максимальная гибкость, поддержка по инфраструктуре (есть и готове UI-компоненты, и готовые сервисные адаптеры), теоретическая возможность сделать оптимизацию по производительности для любого специфического кейса. Но — абстракция неизбежно течет, необходимо помнить возможности/недостатки конкретного query provider, каким бы хорошим он ни был, слишком легко написать ad-hoc вместо использования intention-revealing (заметим, она тем не менее возможна:repository.Query().AllActive().UpdatedSince(...)).
Где-то посередине — спецификации. The best and the worst of two worlds. Intention-revealing, компонуются, внутри можно написать что угодно, включая оптимизацию по производительности. Но — поддержки обычно нет ни в UI, ни в провайдерах, всю адаптацию надо писать самому, все надо придумывать самому (например, как сделать, чтобая была честная поддержка времени компиляции). В итоге, проектов, в которых эти вложения оправдаются, не так уж и много.
areht
07.07.2016 13:34> Если буквоедствовать, то IEnumerable — это не fully instantiated collection, там же lazy.
Если буквоедствовать, то IEnumerable — интерфейс. Причём «IEnumerable is the base interface for all non-generic collections that can be enumerated»
> Ага. Полтора миллиона активных кастомеров — перебирать в памяти сервера под Where. Круть.
Ну дёрнете ToList от своего IQueriable — получите 6 миллионов неактивных кастомеров. Мы репозиторий обсуждаем или как в памяти полтора миллиона объектов покрутить?
> а если какого-то метода недодали, то
Ну, доделайте.
> Мой любимый пример — это требование построить поверх такого репозитория типичный для LOB-приложения грид на 18 колонок с сортировкой/фильтрацией по любой из них (включая любую их комбинацию по and/or).
Спрошу страшное: зачем требовать делать это поверх репозитория?
Если серьёзно, то это задача оптимизации. Оптимизация требует костылей. Добавить в репу IQueryable ради грида можно, но _ради грида_. На это не будет ни одного теста (я не видел людей, желающих писать тесты на сортировку грида). И это не повод этот костыль узаканивать.
В своём коде я текущих абстракций видеть не хочу. Дать инфраструктуре IQueryable — на здоровье, UI-фреймворки вообще за рамками DDD.
Есть ещё грустная тема «IQueryable и попытка показать на UI кастомный DTO», где вся «гибкость» IQueryable превращается в поле с граблями.lair
07.07.2016 13:50Ну дёрнете ToList от своего IQueriable
Так зачем же его дергать-то?
Ну, доделайте.
Угу, тогда их будет бесконечный неуправляемый зоопарк.
Спрошу страшное: зачем требовать делать это поверх репозитория?
Потому что формально у нас любое общение с бизнес-сущностью должно начинаться с репозитория или фабрики. А если мы где-то отказываемся от репозиториев, то внезапно выясняется, что и дальше от них тоже неплохо можно отказаться.
Если серьёзно, то это задача оптимизации. Оптимизация требует костылей
Я потому и говорю: мы балансируем компромисы.
IQueryable— не самый худший из них.
В своём коде я текущих абстракций видеть не хочу.
А я не хочу видеть в своем коде комбинаторный взрыв псевдо-бизнесовых методов на репозитории.
UI-фреймворки вообще за рамками DDD.
Это сложный вопрос, неоднозначный. У нас есть куча сугубо бизнесовых задач, которые связаны с UI, и если мы половину из них поведем мимо DDD, у нас домен начнет рассыпаться.
Есть ещё грустная тема «IQueryable и попытка показать на UI кастомный DTO»,
Как ни странно, проекции обычно работают. А когда они не работают, все остальное не работает приблизительно так же, так что уже не важно.
areht
07.07.2016 14:33> Угу, тогда их будет бесконечный неуправляемый зоопарк.
Угу, когда вы напишите бесконечное приложение. Давайте не передергивать?
> А я не хочу видеть в своем коде комбинаторный взрыв псевдо-бизнесовых методов на репозитории.
Аргумент звучит хорошо. Но на практике комбинаторного взрыва не будет.
Именно потому, что методы бизнесовые, а не кодогенерацией.
> А если мы где-то отказываемся от репозиториев, то внезапно выясняется, что и дальше от них тоже неплохо можно отказаться.
Ну, если замена unit-тестов на интеграционные — «неплохо»… Да и до Эванса с фаулером программы писали.
А комбинаторного взрыва интеграционных тестов не боитесь?
> Я потому и говорю: мы балансируем компромисы.
Использовать IQueriable для UI — это практическая необходимость. Но она не диктует дизайн остального, она не должна учитываться в домене. Иначе «у нас домен начнет рассыпаться.».
> Это сложный вопрос, неоднозначный. У нас есть куча сугубо бизнесовых задач, которые связаны с UI, и если мы половину из них поведем мимо DDD, у нас домен начнет рассыпаться.
UI и UI-фреймворк — разные вещи.
> Как ни странно, проекции обычно работают. А когда они не работают, все остальное не работает приблизительно так же, так что уже не важно.
Если на SQL транслируется — работает. Может даже с фильтрацией. Может даже с фильтрацией без full table scans.
А программист в здравом уме не напишет такого(тем более без ленивого IQueryable в руках), что пользователь на гриде нащелкает. Так что нет, остальное вполне может работать.lair
07.07.2016 14:37Аргумент звучит хорошо. Но на практике комбинаторного взрыва не будет. Именно потому, что методы бизнесовые, а не кодогенерацией.
Это зависит от количества разработчиков на конкретном бизнес-секторе.
Ну, если замена unit-тестов на интеграционные — «неплохо»…
А кто что-то сказал про замену?
А комбинаторного взрыва интеграционных тестов не боитесь?
Нет, не боюсь. Машина железная, пусть считает.
Использовать IQueriable для UI — это практическая необходимость. Но она не диктует дизайн остального, она не должна учитываться в домене. Иначе «у нас домен начнет рассыпаться.».
Вы предлагаете не учитывать UI в домене? Это смело.
Если на SQL транслируется — работает.
Я согласен, когда проекции транслируются на SQL, они работают. Только они не всегда транслируются.
А программист в здравом уме не напишет такого(тем более без ленивого IQueryable в руках)
Зато он может написать вложенный цикл, дающий степенную сложность. Не надо недооценивать программистов.
areht
07.07.2016 14:47> Это зависит от количества разработчиков на конкретном бизнес-секторе.
Как у вас code review работает?
> Вы предлагаете не учитывать UI в домене? Это смело.
Нет, вы передергиваете смело.
> А кто что-то сказал про замену?
Вам для тестирования выполнимости запросов нужен интеграционный тест, мне для FindAllActiveCustomers().Where(...) — unit.
Звучит как замена.
> Зато он может написать вложенный цикл, дающий степенную сложность.
по IQueryable и без него — ооочень разный результат.lair
07.07.2016 14:50Как у вас code review работает?
Медленно.
Вам для тестирования выполнимости запросов нужен интеграционный тест, мне для FindAllActiveCustomers().Where(...) — unit.
А как вы тестируете, что
FindAllActiveCustomersдействительно возвращает то, что обещал?
Звучит как замена.
Домен можно продолжать тестировать юнит-тестами.
по IQueryable и без него — ооочень разный результат.
Your mileage may vary.
areht
07.07.2016 14:58> А как вы тестируете, что FindAllActiveCustomers действительно возвращает то, что обещал?
Если там dc.Customers.Where(x => x.IsActive).ToList() — аналитически (никак).
Если что-то сложнее — можно dc.Customers замокать.
Если хранимка или ещё что — интеграционный.
> Домен можно продолжать тестировать юнит-тестами.
Можно, но где кверя отвалиться — не узнаешь.lair
07.07.2016 15:02Если там dc.Customers.Where(x => x.IsActive).ToList() — аналитически (никак).
Тогда можно и "никак" не тестировать внешние запросы к
IQueryable.
Если что-то сложнее — можно dc.Customers замокать.
И как вам мок поможет от проблемы "тут написали запрос, который на самом деле не лезет в провайдер"?
Можно, но где кверя отвалиться — не узнаешь.
… и вот тут включаются интеграционные тесты. Да, покрытие меньше, но оно все равно есть.
Понятно, что выставленный наружу
IQueryableделает систему менее предсказуемой. Но это типичная плата за возможность более наглядной и простой разработки. Компромис.areht
07.07.2016 15:14> Тогда можно и «никак» не тестировать внешние запросы к IQueryable.
Если вы и ваши коллеги на глаз быстро и надежно оценивают запрос — можно.
За подобный надежно инкапсулированный запрос лично я уверен, за внешние — нет.
> И как вам мок поможет от проблемы «тут написали запрос, который на самом деле не лезет в провайдер»?
Что?lair
07.07.2016 15:21Что?
Ровно то, о чем написано выше. Вы же говорите, что проблема
IQueryableв том, что к нему можно написать запрос, который не выполнится (да, можно, сам неоднократно влетал). Теперь представьте, что кто-то написал такой запрос внутри репозитория, реализуя очередную business query. Как это поймать тестами?areht
07.07.2016 15:42Если запрос примитивный — видно, что он выполниться. Разве что с маппингом косяк, но тогда вообще ничего не заработает. Тестировать маппинг через сотни тестов отдельных кверей — не по феншую.
Если запрос не примитивный — перед «Как это поймать тестами?» стоит подумать «не стоит ли применить физическое воздействие за попытку утащить логику домена».
Ну и, раз у вас «Машина железная, пусть считает.» — напишите один тест, дергающий за все методы всех репозитариев на предмет отсутствия эксепшенов.lair
07.07.2016 15:44Если запрос примитивный — видно, что он выполниться. [...] Если запрос не примитивный — перед «Как это поймать тестами?» стоит подумать «не стоит ли применить физическое воздействие за попытку утащить логику домена».
О, а что же делать, когда нам надо (а) эффективно, т.е. быстро и (б) выполнить логику домена на данных?
Ну и, раз у вас «Машина железная, пусть считает.» — напишите один тест, дергающий за все методы всех репозитариев на предмет отсутствия эксепшенов.
Это хорошо, пока эти методы не принимают значений/не зависят от погоды на Марсе.
areht
07.07.2016 15:53> О, а что же делать, когда нам надо (а) эффективно, т.е. быстро и (б) выполнить логику домена на данных?
Как с любой оптимизацией, запилить как-нибудь. Если это больше 1% случаев — что-то в консерватории не так.
> Это хорошо, пока эти методы не принимают значений/не зависят от погоды на Марсе.
Autofixture в помощь. Если от погоды на марсе появляются необработанные исключения — тоже что-то в консерватории не так.
areht
07.07.2016 15:48> Понятно, что выставленный наружу IQueryable делает систему менее предсказуемой. Но это типичная плата за возможность более наглядной и простой разработки.
Я не против IQueryable. Но это не «fully instantiated objects or collections of objects whose attribute values
meet the criteria, thereby encapsulating the actual storage and query technology». То есть не репозиторий по Эвансу.
Лично у меня дальше встаёт вопрос «зачем тогда репозитории, да и вообще DAL, который простоты разработки не добавляет?», а потом «DDD ли это?»
Дело тут не в формализме, это просто совсем другой подход.lair
07.07.2016 15:50Но это не «fully instantiated objects or collections of objects whose attribute values meet the criteria, thereby encapsulating the actual storage and query technology».
Да ну? Это интерфейс, ничем не хуже
IEnumerable.
Лично у меня дальше встаёт вопрос «зачем тогда репозитории, да и вообще DAL, который простоты разработки не добавляет?», а потом «DDD ли это?»
Ну, без DAL вам обойтись (в современных условиях) не выйдет. А вот зачем нужны репозитории — это очень разумный вопрос.
areht
07.07.2016 15:59> Да ну? Это интерфейс, ничем не хуже IEnumerable.
Ну, есть ещё хорошие интерфейсы, IDisposable, например. Они тоже не коллекции.
> Ну, без DAL вам обойтись (в современных условиях) не выйдет. А вот зачем нужны репозитории — это очень разумный вопрос.
Я про выделенный слой.
indestructable
07.07.2016 14:15На одном конце спектра — явные intention-revealing методы навроде GetActiveCustomers, GetPendingBills, и все такое. Красиво, явно, читабельно, внутри максимально заоптимизировано, ничего никуда не течет. Но — количество таких методов растет как комбинация всех вариантов поиска/фильтрации (а у нас еще есть сортировки, группировки и агрегаты), а если какого-то метода недодали, то придется использовать локальную обработку на сервере со всеми вытекающими.
Наверное, лучше всего использовать эти методы и возвращать из них
IQueryable<T>, но использовать его только для гридов или OData, а не для бизнес-логики.lair
07.07.2016 14:19Я на месте программиста бизнес-логики в таком случае буду чувствовать себя идиотом: мне вернули
IQueryable, но использовать я его не могу. What?indestructable
12.07.2016 12:43Использовать-то его можно, но вот для чего?
Я вижу два применения:
- ad-hoc обработка данных на стороне источника (базы) как в бизнес логике, так и для выборки данных пользователем. Это нормально, клиент не может получить доступ к неподходящим данному сценарию данным.
- Применение бизнес-логики к "сырому" источнику данных — когда отдают полностью содержимое таблицы, и потребитель должен сам отфильтровать и выбрать данные, подходящие под сценарий, и так в каждом бизнес методе. А вот это уже плохо, хотя и позволяет, на первый взгляд, избежать "взрыва" количества методов репозитория. На самом деле, бизнес логика "на данных" никуда не денется, она все равно будет присутствовать, и в еще большем количестве.
lair
12.07.2016 12:53Использовать-то его можно, но вот для чего?
Для реализации бизнес-требований, очевидно. Было у меня "выведите в отчет десять последних измененных документов", стало "выведите в отчет десять последних просмотренных документов".
Применение бизнес-логики к "сырому" источнику данных — когда отдают полностью содержимое таблицы, и потребитель должен сам отфильтровать и выбрать данные, подходящие под сценарий, и так в каждом бизнес методе.
В этом предположении сразу две ошибки. Во-первых, отдают не содержимое таблицы, а интерфейс, позволяющий прочитать сущности (или проекции) по заданному выражению. Во-вторых, любая повторно используемая логика прекрасно инкапсулируется в extension-методы, поэтому никакого "в каждом бизнес-методе".
indestructable
12.07.2016 13:56Во-первых, отдают не содержимое таблицы, а интерфейс, позволяющий прочитать сущности (или проекции) по заданному выражению.
Вопрос в том, позволяет ли этот интерфейс получить данные, которые не нужны в данном сценарии.
Во-вторых, любая повторно используемая логика прекрасно инкапсулируется в extension-методы, поэтому никакого "в каждом бизнес-методе".
Это понятно, есть больше одного способа инкапсуляции повторно-используемого кода. Но extension методы еще нужно не забыть вызвать, особенно если их несколько, а при добавлении нового нужно не забыть добавить вызов во всех местах. То есть это лучше, чем ручная фильтрация через
Whereв бизнес методах, но все еще хуже бизнес методов в репозитории.lair
12.07.2016 14:04Вопрос в том, позволяет ли этот интерфейс получить данные, которые не нужны в данном сценарии.
Конечно, позволяет. Только вместе с этим он позволяет не получить данные, которые не нужны.
Но extension методы еще нужно не забыть вызвать, особенно если их несколько, а при добавлении нового нужно не забыть добавить вызов во всех местах.
У бизнес-методов на репозитории, кстати, то же самое: когда вы добавляете новый, более узкий метод — вам тоже надо не забыть все на него поправить в нужных местах.
То есть это лучше, чем ручная фильтрация через Where в бизнес методах, но все еще хуже бизнес методов в репозитории.
У бизнес-методов в репозитории, как уже сказано выше, есть фундаментальная проблема: либо их очень много (фактически, по одному на каждый сценарий, которых много), либо они неэффективны (например, классический
GetAllCustomers).indestructable
12.07.2016 15:40У бизнес-методов в репозитории, как уже сказано выше, есть фундаментальная проблема: либо их очень много (фактически, по одному на каждый сценарий, которых много), либо они неэффективны (например, классический GetAllCustomers).
Если этих методов много, то их будет много при любом способе реализации, будь то ad-hoc LINQ-запросы, методы расширения, или специализированные методы в репозитории. Вопрос в том, как удобнее сделать с точки зрения разработки и сопровождения.
На мой взгляд, методы в репозитории самые удобные — у них четкий контракт, их легко найти, они могут инкапсулировать сложную логику или разные способы доступа к данным.lair
12.07.2016 17:24+1Если этих методов много, то их будет много при любом способе реализации, будь то ad-hoc LINQ-запросы, методы расширения, или специализированные методы в репозитории.
А вот и нет. Проблема специализированных методов на репозитории в том, что они не поддаются композиции. Вот у вас был один метод —
GetVipCustomers, и другой —GetCustomersWithRecentOrders. Теперь для какого-то бизнес-сценария вам надо выбрать всех vip-клиентов с недавними ордерами; и у вас есть ровно два способа это сделать: либо вы пишете методGetVipCustomersWithRecentOrders, либо вы выбираете данные из обоих и делаете join. В случае с extension-методами вы можете написатьCustomers.OnlyVip().OnlyWithRecentOrders().indestructable
12.07.2016 18:09Мне ничего не остается, только согласиться с вами :) Спасибо за идею, выглядит прекрасно.
Но, все-таки есть сценарии, когда я бы использовал методы репозитория:
- Фильтрация для текущего пользователя(хотя можно передавать
user id) - Методы, потенциально могущие переехать в базу (для оптимизации)
- Ну и, опять же, я предпочитаю не давать доступ к "сырой" (нефильтрованной) выборке из таблицы, чаще всего есть непересекающиеся наборы данных (только активные, только доступные для редактирования и т.д.). Это надежнее метода расширения, который можно забыть, и попортить данные.
lair
12.07.2016 18:26Вы забываете, что
IQueryable, в итоге, превращается в AST. Поэтому все, описанное вами, можно сделать и поверхIQueryable, просто на этапе его разбора внутри репозитория.
- Фильтрация для текущего пользователя(хотя можно передавать
ETman
13.07.2016 12:36Если у вас extension-методы заточены под использование только с одним типом данных, то смысла в них столько же, сколько и в методах репозитория. В итоге получим одинаковое кол-во методов, только одни статик, а другие нет. Объясните еще раз разницу, пожалуйста, не уловил выше?
И второй момент: как в тестах замокать выборку не занимаясь настройкой данных? Например у вас проверяется алгоритм метода, который дергает такой вот .OnlyWithRecentOrders(), получая данные и что-то над ними делаеющий.lair
13.07.2016 12:40Если у вас extension-методы заточены под использование только с одним типом данных, то смысла в них столько же, сколько и в методах репозитория. В итоге получим одинаковое кол-во методов, только одни статик, а другие нет. Объясните еще раз разницу, пожалуйста, не уловил выше?
Во-первых, я могу делать generic extension-методы поверх интерфейсов (скажем, метод
Active<T>(): where T: IActiveOrPassive). Во-вторых, я уже приводил классический пример композиции: у нас есть методOnlyVIPиOnlyWithRecentOrders— теперь, чтобы получить випов с недавними заказами мы просто вызываемOnlyVIP().OnlyWithRecentOrders().
И второй момент: как в тестах замокать выборку не занимаясь настройкой данных?
Если вам хочется именно "не заниматься настройкой данных" — то пишете тестовый IQueryProvider, в котором разбираете AST. Но в среднем проще просто сгенерить in-memory dataset.
areht
13.07.2016 12:47Подозреваю, что вопрос был о том, что бы не генерить тестовый датасет с данными, удовлетворяющими OnlyWithRecentOrders() и OnlyVIP(). Ибо это boilerplate.
ETman
14.07.2016 00:22C extension-методами понятен подход. Но все же мне кажется сильно универсального тут не сделать. В итоге все равно получится ворох методов аля шоткатов для блоков кода. Типа инлайн функций в C++ (если память мне не изменяет). Поэтому, не совсем понимаю реальное преимущество, хотя согласен, что удобно так в некоторых случаях.
А что такое AST?
Да, кстати, этот IQueryProvider, по-сути, и есть DAO. Не так ли?lair
14.07.2016 00:25Но все же мне кажется сильно универсального тут не сделать.
Почему? Во-первых, у вас есть самый нижний уровень универсальности — это базовые
Where, универсальнее некуда.
В итоге все равно получится ворох методов аля шоткатов для блоков кода.
Ну и прекрасно. Если короткий метод может заменить собой три строчки кода, то в композиции выигрыш по читабельности будет очень ощутимый.
А что такое AST?
Abstract syntax tree.
indestructable
14.07.2016 16:07Мне кажется, дело тут не столько в универсальности.
Я, наверное, уже это писал где-то в комментах, но повторюсь.
У нас есть два, скажем так, вида бизнес логики "для данных".
Первый вид — это ограничения данных, доступных этому клиенту (здесь клиент и как пользователь, и как сценарий бизнес операции). Например, если у нас сервис для витрины веб-магазина, и репозиторий товара, то мы ни в каком виде не должны иметь доступа к неактивным товарам.
Для этих случаев, я считаю, лучше иметь метод в репозитории, который точно не позволит забыть экстеншн метод.
- Второй вид — это разнообразные методы для удобства. Это тоже бизнес логика, но она применяется ad-hoc. Это как бы сокращенные записи типовых выборок данных, для них методы расширения — отличное решение.
lair
14.07.2016 16:48Для этих случаев, я считаю, лучше иметь метод в репозитории, который точно не позволит забыть экстеншн метод.
А как не забыть вызвать нужный метод репозитория?
indestructable
14.07.2016 17:30Не иметь доступа к полной коллекции данных напрямую.
lair
14.07.2016 17:33Ну то есть у вас есть условие, что никто и никогда, ни при каких условиях не может прочитать из репозитория данные, не попадающие под какой-то критерий. В таком случае вы просто выставляете из репозитория
IQueryableповерх таких данных, а дальше применяете методы-расширения к нему.
(другое дело, что в моей практике в итоге это условие всегда нарушалось)
Pavel_Develop
07.07.2016 09:29А как вам такой подход, когда мы используем generic repository и specifications?
http://pastebin.com/sZYXHGv9lair
07.07.2016 12:46+1В моем опыте и личном мнении обобщенный репозиторий поверх хорошего ORM (или, в частности, поверх
IQueryable) — избыточен. Никакой дополнительной пользы он не приносит, а вот ошибиться в нем можно больше одного раза.
В вашем примере как раз хорошо видно: много лишнего кода (включая собственный UoW и сортировку-по-именам-колонок), при этом все, что этот код делает — это трансляция из одного паттерна в другой. Можно выкинуть все промежуточные этапы между
ProjectFilterDtoиIQueryable, получив приблизительно такое:
public DataTableList<ProjectItemDto> GetProjects(ProjectFilterDto filter) { if (filter == null) return null; return _dbContext .Projects .InStatus(filter.Status) .WithQueryOptions(filter) .ToDataTableList<ProjectItemDto>(); }Pavel_Develop
07.07.2016 14:12Благодарю за ответ.
Получается вы предлагаете проблему сложных выборок решить extensions-классами. Я думаю, в этом случае мы можем получить большой God-объект по всем возможным выборкам, который будет по сути напоминать репозиторий с GetProjectInStatus и так далее.
Меня очень давно мучает вопрос: как унифицировать сложные выборки при запросах из гридов, которые требуют фильтрацию, сортировку и прочее, и при этом не требовали бы больших усилий по реализации в жизнь.
По реализации выше: у меня всегда закрадывалась мысль о том, что код сам по себе избыточен и что надо как-то проще. Но данное вытекло именно из вашего подхода, так как сервисы были наводнены разными if в зависимости от того что выбрал пользователь на гриде и хотелось вынести это за рамки ответственности самого сервиса.lair
07.07.2016 14:18Получается вы предлагаете проблему сложных выборок решить extensions-классами
Extension-методами.
Я думаю, в этом случае мы можем получить большой God-объект по всем возможным выборкам
Не можем. Прелесть extension-методов именно в том, что они существуют сами по себе, отдельно от класса/интерфейса, которые они расширяют.
Но данное вытекло именно из вашего подхода, так как сервисы были наводнены разными if в зависимости от того что выбрал пользователь на гриде и хотелось вынести это за рамки ответственности самого сервиса.
Для этого и существуют типовые конвертеры UI-запроса (обычно стандартного в рамках фреймворка) в expression tree. Когда ваш сценарий сводится к "взять сказанные пользователем фильтры и наложить их" — это самое компактное решение.
Pavel_Develop
07.07.2016 16:11С другой стороны, в вашем случае мы не можем абстрагироваться от dbContext, отсюда:
1. Сложность в написании unit тестов для бизнес логики без заведения тестового контекста и соответсвенно тестовой базы данных.(в рамках EF6, в 7 версии придумали MemoryContext)
2. Использовать Ioc-контейнер, то есть нам придется напрямую писать какой контекст мы берем.
3. Писать using(dbContext) для сборки мусора, что в какой-то мере утомительно.
В таком случае, я думаю, мы получаем сервисный слой который имплемитирует под собой функции репозитория.lair
07.07.2016 16:13С другой стороны, в вашем случае мы не можем абстрагироваться от dbContext,
Почему не можем?
Pavel_Develop
07.07.2016 16:42Я имел ввиду без написания дополнительной обертки, то есть мы везде вынуждены писать:
var context = new SaleDbContext();
так как напрямую обращаемся к DbSet контекста.lair
07.07.2016 16:44Ну так зачем так делать-то? У меня в коде такого нет, там обращение к
_dbContext, которая прекрасно может быть типаIDatabaseContextсо свойствомIQueryable Projects(это если вы не ленивый, и не ходите черезSet<T>). А дальше все прелести DIP ваши.
michael_vostrikov
12.07.2016 18:20+1Я, возможно, чего-то не понимаю, но разве AllActiveCustomers — это отдельное самостоятельное бизнес-понятие?
Customer — это бизнес-сущность, Active — это ее бизнес-характеристика, All вообще связано с количеством и применяется уже к результату. Соответственно, наиболее близким к бизнес-логике будет какой-то такой вариант:
CustomerRepository.Find().Active().All()
Active() содержит бизнес-логику кого считать активным — у кого статус «активнен», или у кого активные контракты есть, или что-то еще. А в какую последовательность SQL-команд она потом превращается, это уже детали реализации.areht
12.07.2016 18:52«AllActiveCustomers» я взял из комментария выше, я бы так не назвал. В общем случае метод начинается с глагола, GetActiveCustomers.
> CustomerRepository.Find().Active().All()
.All() — бессмысленная штука. Не знаю что вы в ней писать решили.
.Active() — имеет смысл выделять, при отсутствии инкапсуляции этой логики в объекте. Почему вам может это придти в голову запрашивать из репозитория по какому-то правилу из бизнес-логики? Не знаю. Но, если там есть что выделять, то в БД это так просто не проброситься.
CustomerRepository.Find() — что возвращает?
Если IQueriable — вы получите описанные грабли generic-репозитория (который не репозиторий и никто не знает зачем он такой нужен).
Если коллекцию — вы получите *хрилион не нужных объектов.
Если какой-нибудь ICustomerRepositoryQueryBuilder — задолбаетесь писать под эти билдеры на втором десятке.
В общем, мне страшно представить что вы хотите нагромоздить, вместо одного метода с DB.Customers.Where(x => x.IsActive).ETman
13.07.2016 10:38Вопрос иного характера, но мне интересно, как в случае с DB.Customers.Where(x => x.IsActive) можно замокать данную выборку в тестах, если не иметь метода в неком интерфейсе? Мне хотелось бы избежать настройки данных в тесте.
Для данного случая я сам вижу только выделение этого в метод интерфейса какого-то DAO.areht
13.07.2016 12:39DB.Customers.Where(x => x.IsActive) лежит в репозитории, за интерфейсом репозитория. Просто одним методом.
areht
12.07.2016 19:17> Я, возможно, чего-то не понимаю, но разве AllActiveCustomers — это отдельное самостоятельное бизнес-понятие?
ActiveCustomers — отдельное.Иначе зачем вам выбирать только их?
Как только вы решите сегрегировать негров — у вас будут отдельные бизнес-правила для них, отдельный метод репозитория и т.п.michael_vostrikov
12.07.2016 20:58ActiveCustomers — отдельное
И абсолютно не связанное с InactiveCustomers и просто Customers? Иначе зачем вам его от них отделять?
Active — это отдельная характеристика, она не образует новых сущностей, а ограничивает подмножество существующих. То есть используется как фильтр. И так как в бизнес-требованиях фильтры могут комбинироваться (активные + юридические лица + из региона Урал), логично выделить их в отдельные методы и аналогично комбинировать в коде.
Так что да, специализированный Query Builder как вариант, а All заканчивает построение и вычисляет результат. А еще иногда бывают нужны не все, а только часть (первые 10 с самыми большими контрактами).areht
12.07.2016 21:22+1> Active — это отдельная характеристика, она не образует новых сущностей, а ограничивает подмножество существующих
Что, по-вашему, образует? Всё в этой жизни наследники Object, и только характеристиками определяется.
Давайте так: «совершеннолетний» — это термин из ubiquitous language, бизнесовая «характеристика», в терминах которой я общаюсь в коде. А «17 лет» — характеристика объекта.
Фильтровать по возрасту вы можете как угодно, но это не противоречит тому, что репозиторий вам может возвращать совершеннолетних.
> И так как в бизнес-требованиях фильтры могут комбинироваться (активные + юридические лица + из региона Урал), логично выделить их в отдельные методы и аналогично комбинировать в коде.
Когда и если эта комбинаторика нужна — можно выделить. А можно и нет (а, например, построить Query object тем же билдером). А можно эту категорию назвать «Уральские» и не придумывать, что нужны произвольные комбинации.
В остальных 99% Query Builder — адский оверхед на разработку. Ну и к «репозиторию» отношения не имеет.
VolCh
06.07.2016 18:17А почему не нормально? Разве что Load неудачное название, лучше что-то вроде getAll(). Репозиторий для клиента — это коллекция по сути. Добавление или удаление элемента из коллекции — обычная операция.
indestructable
06.07.2016 20:32Лично я являюсь противником generic CRUD репозиториев и предпочитаю создавать бизнес методы в репозитории, например FindAllActiveCustomers.
Я понимаю, что в этом случае часть бизнес логики уезжает в репозиторий, но, на мой взгляд, это лучше, чем ad-hoc linq запросы в бизнес методах. К тому же, есть вероятность, что сложная выборка переедет в базу, и лучше инкапсулировать ее в репозитории. Да и тесты писать проще, т.к. не нужно мокать данные так, чтобы не обрезало фильтром.

zelenin
06.07.2016 12:54+4>> Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища.
репозиторий абстрагирует от хранилища, а не непосредственно извлекает. Извлекать он может через цепочку любой длины (с кэшированием, логгером итд). Непосредственно извлекает например data mapper/http client/api client. На выходе мы получаем все равно одно и то же — сущности.
Pavel_Develop
06.07.2016 12:54В случае с EF мне больше всего нравится разделять доменную модель Entities и маппинг их на базу данных на разные проекты. Так как домен ничего не должен знать о том как его сохраняют и прочее. При этом используются «богатые» модели с логикой. В этом плане мне очень нравится как все раскладывает Jimmy Bogard здесь: vimeo.com/43598193
lair
06.07.2016 13:10+1Выполняет ли репозиторий ту же роль, что и ранее? Очевидный ответ «НЕТ», так как теперь он не извлекает данные из хранилища.
Ничего очевидного в этом ответе нет. Как раньше роль репозитория состояла в том, чтобы выступать абстрактным хранилищем данных для всего остального кода, так и сейчас она в этом состоит.
ETman
06.07.2016 13:54В общем, так и есть. Но некоторые считают, что репозиторий не для абстракции хранилища данных, а для абстракции доступа к данным. Из-за этого разница в понимании целей возникает. О чем я и написал.
lair
06.07.2016 14:08-1Абстракция хранилища данных автоматически является абстракцией доступа к данным. Я вообще не вижу смысла в этом разделении, если честно.
ETman
06.07.2016 14:55Он такая же абстракция над доступом к данным, как бизнес-объект. У него выхода нет и по цепочке ответственностей, конечно, он абстрагирует. Но куда поместить, например, поместить джойны, генерацию запросов и куда, скажем, системную нотификацию об операциях? Обычная связка: linq-запрос по EF Code First + бросить в очередь сообщение, которое отправится потом другой службой. Что есть что тут и как построить систему. Люди сваливают все это в одно место, не заботясь о разделении, когда думают, что все это — работа с данными. По факту, есть 1) linq-запросы с EF, 2) нотификатор и, что неочевидно некоторым, 3) логика в репозитории создающая сложные BO. Если смотреть с точки зрения тестирования этого всего, то 1) надо будет отделить от 3).
Возможно, частный случай, но, как мне кажется тут и возникает нестыков. Одни полагают, что можно все свалить в одно место, т.к. собираются тестировать руками, а не тестами.
Следите за мыслью?lair
06.07.2016 15:03Он такая же абстракция над доступом к данным, как бизнес-объект
Бизнес-объект — не абстракция над доступом к данным.
Но куда поместить, например, поместить джойны, генерацию запросов и куда, скажем, системную нотификацию об операциях?
Генерацию запросов надо помещать за репозиторий. Дальше все зависит от сложности приложения. С точки зрения пользователя запросы генерируются где-то внутри репозитория, а где — не важно.
системную нотификацию об операциях?
А это зависит от природы "системной нотификации", очевидно.
Следите за мыслью?
В вашей мысли есть одно ошибочное звено: вы полагаете, что если какая-то ответственность (например, уведомления) скрыта от пользователя репозиторием, то она репозиторием и реализуется. Но нет.
ETman
06.07.2016 15:20Не стоит полагать за меня и копаться в деталях. Если рассматривать детально, то одного поста не хватит.
Про BO — это пример эскалации абстракции, из-за которой репозиторий является, по вашим словам, абстракцией над доступом к данным. Кратко, А использует B, использующее С => A использует С.
Генерацию запросов надо помещать за репозиторий.
Верно. И это делает EF, например.
По-моему, мы об одном и том же.
lair
06.07.2016 15:24Если рассматривать детально, то одного поста не хватит.
А если детали не рассматривать, то не о чем и говорть.
Кратко, А использует B, использующее С => A использует С.
Это — протекшая абстракция. Если B абстрагирует C, то A ничего не знает про C.
Верно. И это делает EF, например.
… и? Никогда не писали репозитории на EF?

RouR
06.07.2016 14:26Cчитаю очень плохой идеей запихивать в репозитарий логирование и кэширование — их надо в слой выше.
ETman
06.07.2016 14:36В некий бизнес-объект?
zelenin
06.07.2016 16:56в сервис. поддерживаю RouR
ETman
06.07.2016 17:24Вы считаете это элементы бизнес-слоя?
zelenin
06.07.2016 17:25сервис приложения не является частью бизнес-слоя.
ETman
06.07.2016 17:53Вы про сервис из DDD?
zelenin
06.07.2016 17:58сервис сервисного слоя например — прокладка между реквестом и бизнесом-слоем, инкапсулирующая в себе инфрастуктурные моменты типа получить сущности, закэшировать, залогировать (в контексте нашей ветки).
http://martinfowler.com/eaaCatalog/serviceLayer.htmlETman
06.07.2016 18:03понял. согласен с тем, что выше.
zelenin
06.07.2016 18:05добавлю тут, а то не дает отправлять комменты чаще раз в 5 мин.
то есть сервис приложения знает о том как работает приложение и может оперировать понятиями типа «если в кэше есть, достанем из кэша, а если нет, то вытащим из хранилища и закэшируем». А репозиторий все-таки — хранилище, поэтому должен в чистом виде только уметь доставать из хранилища и класть в хранилище.VolCh
06.07.2016 18:13+1Спорно. Я обращаюсь к репозиторию чтобы получить какой-то объект, мне всё равно откуда он его достанет. Он отвечает за хранение и получение данных, а не какой-то сервис. Где он хранит (в базе, в кэше, в файлах, в облаке и т. д.) мне как клиенту репозитория всё равно.
zelenin
06.07.2016 18:22все верно. Если кэш выступает единственным хранилищем (CacheRepository), то хранилище оно и хранилище. Если же у нас например PostgresRepository с функцией кэширования, то репозиторий перестает быть ЧИСТОЙ абстракцией над хранилищем, т.к. получает еще одну ответственность — оптимизация с помощью кэша. В этом случае мы получаем сайд-эффект, когда запросив из хранилища сущность, мы получили ее вовсе не из хранилища, да и не ее, а старую версию.
В то время как сервис принимает эти риски, т.к. работает именно на уровне самого приложения, где можно применить кэширование и принять сайд-эффект за должное.VolCh
06.07.2016 18:30Репозиторий не перестаёт быть чистой абстракцией над физическим хранилищем, потому что он ею никогда не был. Его задача предоставить остальной модели коллекцию объектов. Как он это будет делать — детали конкретной реализации. Она может быть оптимизированной, а может быть тупой, а может быть конфигурируемой как глобально, так и параметрами вызова (но это обычно означает текущую абстракцию).
zelenin
06.07.2016 18:40>> Репозиторий не перестаёт быть чистой абстракцией над физическим хранилищем, потому что он ею никогда не был.
как не был, если репозиторий и есть прослойка между доменом и хранилищем, скрывающая в себе детали реализации? Да, реализация может быть не чистая, а декорирующая в себе например кэширование, но это уже дискуссионно, и лично я бы, кэширование выносил на слой выше — либо декорируя с помощью CacheRepository, либо в сервисе, чтобы репозиторий мне возвращал всегда валидные данные непосредственно из хранилища.
Аналогично, если писать http-клиент к стороннему апи, и в него заложить функцию кэширования. Пусть http-клиент всегда будет мне возвращать респонс непосредственно http-реквеста, а кэширование, если надо, я подниму на уровень выше, завернув клиент в сервис.VolCh
06.07.2016 18:44В определении репозитория нет ничего, чтобы указывало на его чистоту. Это не учитывая того, что кэширование может быть на многих уровнях за репозиторием, в том же DataMapper.
zelenin
06.07.2016 18:53В определении не может быть подопределений — чистого и нечистого. Само по себе определение и есть то, чем репозиторий должен заниматься — Mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects (http://martinfowler.com/eaaCatalog/repository.html) — прослойка между доменом и мапперами
Поэтому пусть репозиторий занимается тем, чем должен, а оптимизацией занимается слой приложения.
Что там может быть на других уровнях нас не должно интересовать — мы проектируем репозиторий.lair
06.07.2016 19:02Вот только в слове "mediates" может быть все, что угодно. Например (цитата из того же PoEAA):
It’s also conceivable, when the application is running normally, that certain types of domain objects should always be stored in memory. One such example is immutable domain objects (those that can’t be changed by the user), which once in memory, should remain there and never be queried for again.
zelenin
06.07.2016 19:07ок. Собственно все уже обсудили и донесли друг до друга. Я предпочитаю несколько сущностей с одной узкой ответственностью против одной более функциональной. Поэтому выделяю у сущности задачу, вынося подзадачи в декораторы/сервисы/другие уровни.
lair
06.07.2016 19:09Я предпочитаю несколько сущностей с одной узкой ответственностью против одной более функциональной
Я тоже. Но ни мое/ваше предпочтение, ни предпочтение разработчика, предпочитающего одну более крупную сущность, не меняет того, что кэширование не противоречит репозиторию как паттерну.
zelenin
06.07.2016 19:18а я нигде и не писал о противоречии — во всех комментах было написано ровно о том, что предпочтительнее выделить одну непосредственную задачу — вытаскивать/класть в хранилище, — а остальные — сервисные — выделить на другой уровень. Под чистой реализацией я имел в виду реализацию, выполняющую непосредственную задачу, следующую из определения. Кэширование — это уже фича.
lair
06.07.2016 20:48Проблема как раз в этом "другом уровне". Вот у меня есть сервис (доменный), считающий скоринг для запроса на кредит. На входе — сущность запроса, на выходе — сущность ответа (варианты кредитов со скорингом и объяснениями). Ему для работы нужно лазить за другими доменными же сущностями (например, другими клиентами с их кредитной историей). В лучших традициях DIP, он зависит только и исключительно от интерфейсов
IЧто-тос методамиДайМнеЧтоТо(критерий). По DDD, эти интерфейсы — это репозиторий. Так на какой "другой уровень" вынести кэширование таким образом, чтобы скоринг-сервис об этом не знал?zelenin
06.07.2016 21:20где у вас реквест от юзера попадает в домен?
по ddd вы принимаете в Presentation слое реквест, передали его в application — сервисы или хэндлеры cqrs, — а внутри уже оперируете доменным слоем. Чтобы скоринг-сервис об это ничего не знал, доменный сервис можно а) декорировать сервисом приложения б) опять же в домене оставить интерфейс, а реализовать там же где реализованы репозитории — в инфраструктурном слое, — учитывая потребности приложения с кэшем.
Еще раз: я считаю, что кэш — это ответственность приложения (в терминологии ddd). Домен — это бизнес и чистые данные без сайд-эффектов.lair
06.07.2016 21:40где у вас реквест от юзера попадает в домен?
Это не имеет значения.
Чтобы скоринг-сервис об это ничего не знал, доменный сервис
Скоринг-сервис — и есть доменный сервис. Который зависит от других доменных объектов. Откуда ему эти объекты получить?
zelenin
06.07.2016 21:43я все написал комментом выше.
lair
06.07.2016 21:48"Комментом выше" нет ответа на вопрос "откуда доменный сервис получает объекты". Ну или я его не вижу, в этом случае, повторите его, пожалуйста.
zelenin
06.07.2016 22:02доменный сервис получает объекты оттуда, откуда вы будете получать их в своей реализации интерфейса. А реализация может быть как с получением напрямую из репозитория, так и с использованием CacheRepository, или с подсчетом в сервисе приложения и тупой загрузкой окончательных результатов в сервис домена.
lair
06.07.2016 22:09доменный сервис получает объекты оттуда, откуда вы будете получать их в своей реализации интерфейса.
Какого интерфейса?
На пальцах:
class ScorerService: IScorerService { IX _smthToGetDataFrom; Scoring Score(CreditApplication a) { _smthToGetDataFrom.Get<BankClient>(someId); _smthToGetDataFrom.Get<BankClient>(someOtherId); } }
Какой паттерн экспонирует
IX? (BankClient— доменная сущность)zelenin
06.07.2016 22:20IX _smthToGetDataFrom — тут может быть например CacheBankClientRepository, декорирующий BankClientRepository
lair
06.07.2016 22:25Ну то есть, если предполагать, что мы используем честный DIP,
IX— этоIBankClientRepository, правильно?zelenin
06.07.2016 22:33ну конечно же. Но отмечу, что IX — не часть интерфейса IScorerService. Поэтому реализация может быть и без репозиториев вообще, а например с прямой загрузкой коллекции объектов из сервиса приложения — в зависимости от того, как реализовано кэширование и есть ли оно вообще.
lair
06.07.2016 22:36… а это, в свою очередь, означает, что
ScorerServiceне может знать, будет ли заIBankClientRepositoryкэширующая реализация или обычная; что означает, что кэширование происходит на том же уровне, что и репозиторий — уровне реализации интерфейсаIBankClientRepository. Более того, поэтому же мы больше не можем говорить, что репозиторий гарантированно не имеет побочных эффектов или возвращает актуальные данные (это нарушает LSP).zelenin
06.07.2016 22:43поэтому я и упомянул, что репозиторий не является частью интерфейса, а является частью вашей реализации. реализовывайте так, чтобы не было сайд-эффектов.
lair
06.07.2016 22:45поэтому я и упомянул, что репозиторий не является частью интерфейса, а является частью вашей реализации.
Частью моей реализации является зависимость от репозитория, причем, согласно DIP, от интерфейса репозитория.
реализовывайте так, чтобы не было сайд-эффектов.
В таком случае мы никогда не сможем добавить прозрачное кэширование.
zelenin
06.07.2016 22:52>> Частью моей реализации является зависимость от репозитория, причем, согласно DIP, от интерфейса репозитория.
вы несколько раз сделали упор на слове «интерфейс». Когда я пишу про зависимость от чего-то, я всегда имею в виду зависимость от интерфейса.
>> В таком случае мы никогда не сможем добавить прозрачное кэширование.
очевидно, что есть случаи когда кэширование нужно, а есть случаи когда кэширование не нужно. Поэтому я кэширование выношу на уровень приложения — туда, где все известно о юзкейсах. Этот сервис (приложения) нужен для подсчета критичных данных — тут кэширование не нужно. Этот сервис нужен для извлечения сущности и показа ее во вьюшке — тут кэширование нужно. Ни репозитории, ни доменные сущности/сервисы не знают о юзкейсах, т.к. оперируют бизнес-понятиями.lair
06.07.2016 22:55доменные сущности/сервисы не знают о юзкейсах, т.к. оперируют бизнес-понятиями.
Юз-кейс — это и есть бизнес-понятие.
Поэтому я кэширование выношу на уровень приложения — туда, где все известно о юзкейсах.
Прекрасно, и как же вы прокидываете это кэширование внутрь доменных объектов/сервисов, которым оно нужно? Не закэшированные объекты, а именно сам факт кэширования? Повторюсь: скоринг-сервис в моем примере инкапсулирует конкретную бизнес-логику, и только он знает, какие объекты ему понадобятся для ее реализации.
zelenin
06.07.2016 22:59>> Прекрасно, и как же вы прокидываете это кэширование внутрь доменных объектов/сервисов, которым оно нужно?
еще раз: кэширование — ответственность приложения. Домен о кэшировании ничего не знает и знать не должен.lair
06.07.2016 23:01+1Именно поэтому домен должен получить нечто (функцию id -> объект, если угодно), которая будет давать ему данные, про которые он не знает, закэшированы они, или нет. И вы не поверите, но в DDD такая функция называется репозиторием.
lair
06.07.2016 18:49как не был, если репозиторий и есть прослойка между доменом и хранилищем, скрывающая в себе детали реализации?
Никто не требует, чтобы она была чистая.
Да, реализация может быть не чистая, а декорирующая в себе например кэширование, но это уже дискуссионно, и лично я бы, кэширование выносил на слой выше — либо декорируя с помощью CacheRepository,
Вот это декорирование — по определению декорирования — для пользователя прозрачно. Пользователь все так же идет в
IRepository, совершенно не зная, что он получает неSqlRepository, аCache<SqlRepository>. И именно поэтому пользователю все равно, реализовано кэширование вSqlRepositoryили вCache<TRepository>.
Пусть http-клиент всегда будет мне возвращать респонс непосредственно http-реквеста, а кэширование, если надо, я подниму на уровень выше, завернув клиент в сервис.
Тем не менее, в дизайне
System.Net.Http.HttpClientсделано наоборот — у вас есть внешнийHttpClient, под которым лежит управляемая цепочка message handlers, каждый из которых может быть и кэширующим, а в конце цепочки, собственно,HttpClientHandler/WebRequestHandler, который отвечает за "чистый" запрос/ответ.zelenin
06.07.2016 19:00>> Вот это декорирование — по определению декорирования — для пользователя прозрачно. Пользователь все так же идет в IRepository, совершенно не зная, что он получает не SqlRepository, а Cache. И именно поэтому пользователю все равно, реализовано кэширование в SqlRepository или в Cache.
Причем тут пользователь? Мы о проектировании с т.з. разработчика.
>> Тем не менее, в дизайне System.Net.Http.HttpClient сделано наоборот — у вас есть внешний HttpClient, под которым лежит управляемая цепочка message handlers, каждый из которых может быть и кэширующим, а в конце цепочки, собственно, HttpClientHandler/WebRequestHandler, который отвечает за «чистый» запрос/ответ.
как правило комплексные библиотеки так и делаются. При разработке же лучше опираться на мелкие классы, композируя их между собой.lair
06.07.2016 19:04Причем тут пользователь? Мы о проектировании с т.з. разработчика.
"Пользователь" репозитория — это разработчик, который его вызывает.
При разработке же лучше опираться на мелкие классы, композируя их между собой.
Вот здесь так и есть: два мелких класса в качестве фронт- (
HttpClient) и бэк- (HttpClientHandler) эндов, и мелкие же — и легко повторно используемые! — хэндлеры между ними. Очень простая композиция, по сути, функциональный конвеер.zelenin
06.07.2016 19:12у нас есть один клиент (сервис), внутри которого цепочка хэндлеров (кэширование, логгеры) и непосредственно клиент, делающий запросы (репозиторий).
lair
06.07.2016 20:44У вас нарушилось соответствие аналогии (к сожалению, это регулярная проблема с аналогиями).
HttpClientHandler— это не "репозиторий", это аналог клиента БД или ORM, с одной операциейSend(ну илиExecuteCommand). А вот внешнийHttpClient— это как раз "репозиторий", с удобнымиGet,Put,Delete,ReadAsи так далее.zelenin
06.07.2016 21:05у меня ничего не нарушилось — я не проводил аналогии, а показал, предлагаемую композицию на примере клиента как абстрактного декоратора нескольких сущностей. Вариантов композиций может быть несколько. Например
+ сервис (HttpClient как декоратор всего)
++ кэш (мидлвари между реквестом и респонсом клиента)
++ логгер (мидлвари между реквестом и респонсом клиента)
++ репозиторий (непосредственно клиент делающий запрос, видимо HttpClientHandler в вашей терминологии)
+++ маппер (транспорт — curl, stream итд)
либо
+ сервис
++ репозиторий
+++ кэш
+++ логгер
+++ маппер
Я за первый вариант — за репозиторий, отдающий состояние без сайд-эффектов. Вы за маппер, отдающий состояние без сайд-эффектов. Мы разговариваем только об уровне. Поэтому вы называете маппер HttpClientHandler'ом (сущностью, отдающей результат без сайд-эффекта), а я репозиторий.
А аналогия у нас у каждого своя — в контексте желаемой композиции.lair
06.07.2016 21:41Проблема в том, что у вас сверху везде сервис, в то время как по DDD мы получаем объекты из репозитория.
zelenin
06.07.2016 21:51наличие сервиса не отменяет того, что объекты мы получаем из репозитория. Если мы говорим о ddd, то это сервис Приложения. Принимаем реквест в презентационном слое, кидаем в сервис Приложения, внутри сервиса репозитории, кэши, логгеры, мейлеры, сервисы домена.
lair
06.07.2016 21:57Тот сервис, который у вас сверху списка — это сервис приложения?
zelenin
06.07.2016 22:04именно
lair
06.07.2016 22:10… и он напрямую скидывает запросы в кэш, логгер, репозиторий, маппер, блаблабла. Никакого домена — ни в виде сущностей, ни в виде сервисов.
zelenin
06.07.2016 22:14как связаны кэш, логгер и домен? кэширование и логирование — это ваш бизнес-домен? Это все служебные фичи — уровень слоя Приложение или Инфраструктура, если мы делаем обертки репозиториев.
lair
06.07.2016 22:16Никак не связаны, про что и разговор: в вашей схеме есть application service, но вместо того, чтобы взаимодействовать с доменом, он взаимодействует с инфраструктурой. Более того, вы взяли и заменили репозиторий — который является внутренним сервисом приложения — на application service, который, по определению, внешний.
zelenin
06.07.2016 22:26application service взаимодействует с доменом через репозиторий и доменные сервисы. Какое еще взаимодействие с доменом вы хотите?
>> Более того, вы взяли и заменили репозиторий — который является внутренним сервисом приложения — на application service, который, по определению, внешний.
я не менял. Каждый на своем уровне занимается своими задачами.
http://i.stack.imgur.com/jYvXp.pnglair
06.07.2016 22:28application service взаимодействует с доменом через репозиторий и доменные сервисы. Какое еще взаимодействие с доменом вы хотите?
Доменных сервисов у вас в схеме нет, их мы вычеркиваем. А через репозиторий с доменом взаимодействовать нельзя, можно только получить доменный объект, и потом взаимодействовать с ним. А дальше возникает тот же вопрос, что и выше: application service знает о том, что вокруг репозитория есть кэш, или нет?
zelenin
06.07.2016 22:40у меня доменных сервисов нет, поскольку мы сейчас про репозитории.
>> вопрос, что и выше: application service знает о том, что вокруг репозитория есть кэш, или нет?
в моем приложении сервис будет выглядеть так:
collection = cacheService.getByKey(key)
if (collection is null) {
collection = repository.find(id)
cacheService.set(key, collection)
}
// дальше логирование, доменные сервисы и т.д.lair
06.07.2016 22:42То есть application service знает про то, что мы кэшируем доменные объекты. Прекрасно, как теперь всем остальным доменным объектам воспользоваться этой же логикой кэширования?
zelenin
06.07.2016 22:45еще раз: кэширование — задача приложения. домен — про бизнес-задачи, а не служебные. Домен про кэширование ничего не знает.
lair
06.07.2016 22:46еще раз: кэширование — задача приложения
Нет. Кэширование полученный из БД объектов — задача слоя, находящегося между доменом и БД. К приложению (в значении application) это отношения не имеет.
Домен про кэширование ничего не знает.
Конечно, эта логика инкапсулируется в инфраструктурный слой.
zelenin
06.07.2016 22:54>> Нет. Кэширование полученный из БД объектов — задача слоя, находящегося между доменом и БД. К приложению (в значении application) это отношения не имеет.
задача слоя, находящегося между доменом и БД — вытащить данные из БД и кинуть их в домен.lair
06.07.2016 22:56задача слоя, находящегося между доменом и БД — вытащить данные из БД и кинуть их в домен.
Я боюсь, что Эвансовское определение репозитория с вами не согласно; как впрочем, и Фаулеровское.
zelenin
06.07.2016 23:05вы видимо про репозиторий? я же про маппер, т.к. репозиторий — это часть домена. Задача маппера — вытащить данные и отдать их репозиторию в виде доменных сущностей.
lair
06.07.2016 23:07Я про репозиторий, это явно написано в моем комментарии.
zelenin
06.07.2016 23:17>> Нет. Кэширование полученный из БД объектов — задача слоя, находящегося между доменом и БД. К приложению (в значении application) это отношения не имеет.
между доменом и БД — маппер. Репозиторий — часть домена.lair
06.07.2016 23:24Репозиторий — часть домена.
Это, скажем так, весьма неоднозначное утверждение.
zelenin
06.07.2016 23:45ну не знаю чем оно неоднозначно. DDD — про домен. Домен: сущности, репозитории, VO, сервисы, агрегаты. Репозитории и сервисы в доменном слое представлены интерфейсами. Реализации — в инфраструктуре. Презентация — то, что видит клиент. Приложение — связь презентации и домена с помощью инфраструктуры.
Вернон, Эванс.
Ладно, спасибо за диалог. Надо и честь знать.lair
06.07.2016 23:47Репозитории и сервисы в доменном слое представлены интерфейсами. Реализации — в инфраструктуре.
Вот именно поэтому и неоднозначное: у вас интерфейс в домене, а реализация в инфраструктуре.
indestructable
07.07.2016 14:18Это все хорошо, но как же инвалидация кеша? При инкапсуляции кеша за интерфейсом репозитория есть хотя бы шанс прозрачно его инвалидировать при вызове метода записи. При размазывании кеширования по слою бизнес-логики это будет кошмар.
zelenin
07.07.2016 14:22инвалидируйте в CacheRepository или в CacheService. Чтобы не было размазывания, держите кэш в одном месте — вариантов реализаций много. Я лишь про уместность кэша в домене или в приложении.
indestructable
06.07.2016 22:31Ну так если представить, что httpclient — это интерфейс репозитория, то все так и получается — внутри добавлена цепочка миддлвеа, добавляющая функциональность без изменения интерфейса.
indestructable
06.07.2016 17:51+1Некая путаница возникает из-за того, что есть два смысла "репозитория" — как интерфейс для доступа к бизнес объектам и как реализация этого интерфейса при помощи, к примеру, EF. И если запихивать кеширование и аудит в реализацию вперемешку с доступом к данным — это, очевидно, плохая идея, то сделать, например, кеширующий или логирующий прокси репозитория — это нормально, как по мне.
ETman
12.07.2016 10:18Вы о том, чтобы одна реализация репозитория занималась получением данных из базы, а другая, например, кеширование? Т.е. в BLL дергается некий интерфейс, за которым на самом деле спрятана цепочка репозиториев, которые делают каждый свое. Об этом?
ksuvakin
06.07.2016 14:55А если использовать CQRS и аудит решать с помощью событий бизнес логики? Теоретически и актуализацию кэша можно повесить на те же события — тогда write model будет простая ( только CRUD ).
VolCh
Для меня репозиторий, прежде всего, элемент Business Layer. Что он зависит (если зависит) от Data Layer — деталь его реализации, скрытая от других элементов Business Layer и всего Presentation Layer. А DAO (если он используется) — как раз элемент Data Layer с которым работает репозиторий.
Разное понимание, по-моему, возникает прежде всего из-за универсальных конфигурируемых ORM. Их универсальность является основной причиной того, что через интерфейсы репозитория протекает Data Layer