
 Компонент, написанный на Rust, впервые заменил компонент на C++ в браузере Firefox, и это только начало!
Компонент, написанный на Rust, впервые заменил компонент на C++ в браузере Firefox, и это только начало!Mozilla любит Rust
Трудно поверить, что прошло почти семь лет с тех пор как Mozilla Research впервые начала спонсировать разработку Rust — системного языка программирования, нацеленного на безопасную работу с памятью, скорость и параллельное выполнение кода. В то время это был не более чем амбициозный исследовательский эксперимент, вокруг которого образовалось небольшое, но преданное сообщество. Удивительно, что несмотря на долгую историю изобретений и открытий, Rust сохранил свой ключевые принципы. Изначально разработчики хотели создать безопасную альтернативу C++, повысить эффективность системного программирования, защитить критическое программное обеспечение от эксплоитов памяти, упростить работу с параллельными алгоритмами — вот почему Mozilla поддержала проект Rust и, в конечном счёте, начала использовать Rust в стабильной версии браузера.
Столько же многообещающим событием стало то, что безопасность и современные функции Rust привлекают новых людей в системное программирование. Для Mozilla, где совместная работа сообщества буквально прописана в нашей миссии, расширение круга разработчиков жизненно важно.
Так что я рад отметить важную веху: в Firefox 48 Mozilla включит первый компонент на Rust для всех десктопных платформ, а скоро появится и поддержка Android.
Внедрение Rust в медиастек Mozilla
Одной из первых использовать Rust в Mozilla начала команда Media Playback. Сейчас вполне очевидно, что медиа является ключевым элементом работы в современном вебе. Что может быть не так очевидно для не-параноиков, так это что каждый раз, когда запускается безобидное, на первый взгляд, видео (скажем, как хамелеончик лопает пузыри), браузер считывает данные в сложном формате и созданные кем-то, кого вы не знаете и кому не доверяете. Как выясняется, с помощью медиаформатов можно манипулировать декодерами и вытаскивать неприятные уязвимости в безопасности. Они эксплуатируют баги в механизме управления памятью, которые реализован в коде веб-браузеров.
По этой причине безопасный для памяти язык программирования вроде Rust становится неотделимым дополнением в наборе инструментов Mozilla для защиты от потенциально вредоносного медийного контента в вебе. По этой причине, Ральф Жиль (Ralph Giles) и Мэтью Греган (Matthew Gregan) разработали в Mozilla первый медиапарсер на Rust. И я рад сообщить, что их код станет первым компонентом на Rust, который войдёт в состав Firefox. Это реальное достижение также для сообщества Rust: код Rust будет работать на сотнях миллионов компьютеров у пользователей Firefox. Наши предварительные исследования показывают, что компонент на Rust отлично проявляет себя и не уступает оригинальному компоненту на C++, место которого он займёт — но теперь реализован на безопасном для памяти языке программирования.
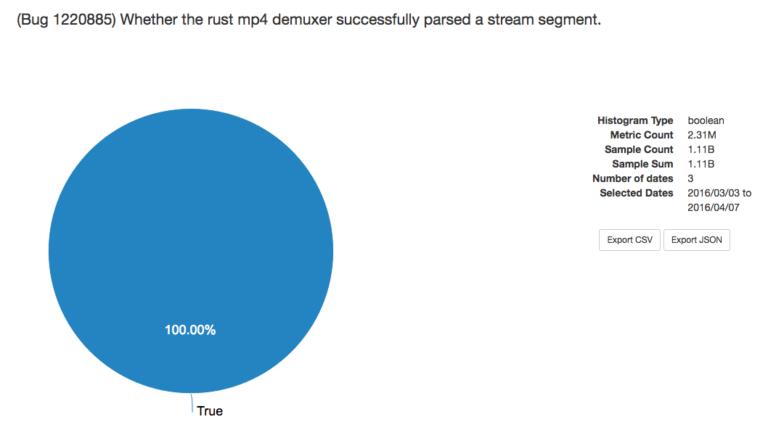
Телеметрия Firefox не показывает ни одной проблемы за более чем миллиард запусков нового кода на Rust
Ещё больше впереди!
Многие люди заслужили огромную благодарность за помощь. Ральф Жиль и Мэтью Греган реализовали компонент, а Натан Фройд (Nathan Froyd), Ник Нетеркот (Nick Nethercote), Тед Мильчарек (Ted Mielczarek), Грегори Шорц (Gregory Szorc) и Алекс Кричтон (Alex Crichton) способствовали интеграции Rust в билд Firefox и в его инструментальную систему, а также обеспечили его поддержку на всех платформах.
Rust сам по себе — продукт потрясающего, живого сообщества. Ничего из этой работы не стало бы возможным без невероятной помощи в разрешении проблем, разработке архитектуры, кода и много другого, что сделали подвижники Rust со всего мира. Являясь и сам таким, хочу позвать вас самих попробовать Rust. Сейчас самое время, чтобы начать и принять участие в проекте Mozilla с использованием Rust.
Видеть код Rust в стабильной версии браузера Firefox — словно завершение длинного путешествия. Но это только первый шаг для Mozilla. Следите за новостями!
Об авторе: Дэйв Херман (Dave Herman) — главный научный сотрудник и директор по стратегии Mozilla Research
Поделиться с друзьями
TerraDon
А что с производительностью? Firefox во сколько раз станет больше «жрать» память?
Исходя из benchmarksgame.alioth.debian.org/u64q/rust.html, пока Rust'у еще далеко до С++.
Язык должен быть «безопасным» в меру. Нужны просто прямые руки. Еще и статические анализаторы помогут.
И еще — почему синтаксис Rust не С-подобный? ИМХО, не правильно позиционировать его как замену С++.
DarkEld3r
Эх, если бы всё было так просто.
Исключительно из-за синтаксиса?..
ozkriff
Я бы только из подобных соревнований столь суровых выводов о языках не делал :)
Очень даже си-подобный. Конечно, зависит от того как определять это понятие, но вот под эти требования — http://dic.academic.ru/dic.nsf/ruwiki/249655 — вполне себе подходит.
Dark_Daiver
Ну судя по тестам по ссылке все относительно неплохо для молодого языка. С потреблением памяти больших проблем быть не должно, по идее — в rust нет gc.
Ну и ИМХО, синтаксис Rust слишком уж С-подобный, можно было и полаконичней
ozkriff
Как я понимаю, команда разработки решила слишком далеко от привычного большинству целевых программистов сишного синтаксиса не уходить, потому что язык и так сложностей в начальном обучении порядочно вызывает, а если еще и синтаксис будет непривычный — 100% в массы не пойдет.
AxisPod
Сравнивать чисто на математической синтетике, это как-то слегка не правильно. Да, памяти жрёт больше, тут ничего не поделать, но в реальной жизни в плане производительности вряд ли будет какая-то разница.
Jogger
Это вы серьёзно сейчас? Жрёт больше памяти — вряд ли будет разница? Да, может если у вас 32Гб — то вам и без разницы. Но блин, рынок ПК стареет. Многие люди не обновляют ПК по 5-10 лет. И вы знаете, на машине с 2Гб памяти — разница огромна. Сейчас в такой конфигурации хром вызывает глобальные тормоза всей системы после 3-4 открытых вкладок. Фаерфокс esr — уже спокойно открывает 20-30 вкладок. Чисто из-за того, что ест совсем немножко меньше памяти. Так что как раз в реальной жизни дополнительное потребление памяти — критично. Но конечно на пользователей как всегда забьют со словами «память же дешёвая»… Только вот многим чтобы поставить эту «дешёвую» память придётся новый компьютер покупать…
AxisPod
Прежде чем писать ответ, читать мой коммент не пробовали? Я вообще про производительность говорил, а про память я и сказал, что жрёт больше. Сам firefox как тормозил, так и тормозит, куда уж тормознее.
pengyou
Хром тормозит не из-за памяти, а из-за яростного interprocesscommunication, и на новых процессорах с малым объемом памяти (1 Гб) работает пристойно (терминалы-киоски).
Massacre
Вряд ли в терминалах именно хром — там, скорее всего, CEF, и процессов в итоге не более 1-2 (хотя, смотря как его настроить)…
mgis
В точку! У меня на Debian с 4gb ОЗУ, Chromium при запущенной IDE, Pycharm жутко тормозит систему. Сначал грешил на Pycharm, потом стал юзать Firefox, был приятно удивлен.
TargetSan
Rust "кушает больше" памяти из-за особенностей jemalloc — аллокатора. Если быть точнее, он не кушает больше — просто при старте jemalloc резервирует довольно большой пул под свои задачи по умолчанию. Т.е. этот "отжор" константный и к коду на русте прямого отношения не имеет.
Во-первых, на стабильной ветке уже можно собраться с системным аллокатором.
Во-вторых, обсуждение большого стартового пула jemalloc было, и меры собираются принять. К сожалению, ссылку сейчас не найду.
ozkriff
Я вот не уверен в этом так уж сильно, особенно если речь идет не о компактных синтетических тестах, а о реальных программах. За счет чего ржавчина должна "жрать" сильно больше памяти?
DarkEld3r
Когда-то аналогичный вопрос задавал и аргументом было то, что в расте "ссылки жирнее" (речь о трейт-объектах): в плюсах ссылка это просто один указатель, а дополнительный указатель на таблицу виртуальных функций лежит в объекте, а не в самой ссылке, в отличии от раста.
Но я как-то сомневаюсь, что данное различие большую роль играет. И уж точно её не должно быть в число-дробилках: там статическая диспетчеризация будет везде где можно.
TargetSan
Отвечал в соседней ветке, чуть выше. Несколько месяцев назад натыкался на возмущения по поводу того, что Rust кушает на синтетиках сильно много памяти. Вкратце, оказалось что jemalloc при запуске выделяет большой пул. Т.е. к тому, сколько "кушает" Rust, это не имеет прямого отношения. Переключаемся на системный аллокатор (уже можно) — и имеем паттерн работы с памятью как в C++.
Laney1
тесты на этом сайте некорректны, по ним нельзя делать выводы.
Например, «n-body», в котором C обгоняет Rust в 2.5 раза. Открываем исходники и обнаруживаем, что код на C использует SSE интринсики, а код на Rust — нет. О чем тут вообще можно говорить?
0xd34df00d
А на Rust эти самые интринсики-то доступны, компилятор умеет их разворачивать?
Если да, доступны и умеет — это нерелевантное сравнение, действительно,
Если нет, не доступны — это уже чуть более адекватно, как по мне, ведь проверяется в том числе и качество реализации, которое подразумевает наличие возможности спуститься и на более низкий уровень.
Впрочем, в обоих случаях интересно посмотреть на код, который генерируется компилятором без всяких там интринсиков. Задействуется ли векторизация? Достаточно ли в языке средств для того, чтобы компилятор вывел, что векторизация безопасна, и не надо ставить (в случае плюсов) всяких
#pragma clang loop vectorize(enable)?-ffast-mathи тому подобного, ведь векторизация переупорядочивает вычисления.homm
Простите, а если я в данном тесте из кода на Питоне «спущусь и на более низкий уровень» и вызову библиотеку на Си, это будет «уже чуть более адекватно»?
0xd34df00d
Если вы во всех тестируемых языках так сделаете, то да. Просто вы тогда скорость FFI тестировать будете, что, в общем, тоже полезно.
potan
Расход памяти мало зависит от языка программирования, больше от алгоритма и подхода к реализации.
В динамически типизированных языках добавляется информация о типах, что увеличивает расход памяти не более чем в константу раз. Для сборки мусора и рефлекшена требуется некоторая дополнительная информация, но очень незначительная.
Но все это к Rust не относится.
В Rust, по сравнению с C++ в объектах нет ссылки на vtbl — то есть экономия. Но эта ссылка добавляется к ссылкам на объект не известного на этапе компиляции типа — здесь некоторый проигрыш. Не очевидно, что перевесит, но разница не будет значительной.
Текущая реализация Rust проигрывает по размеру исполняемого файла из-за включения библиотек. От этого можно избавится, но надо приложить заметные усилия. Но размер бинарников сейчас все равно сильно меньше размера прилагаемых к ним данных.
TargetSan
Небольшая добавка. Любой кто жалуется на большой размер бинарников в русте может сделать статически слинкованную программу на C++ — и посмотреть на размер. Была статья (перевод был на днях на хабре), где разбиралось, почему Rust делает такие толстые бинарники.
По вопросу же Vtbl. У Rust есть в этом плане киллер-фича — явный полиморфизм. Если Trait Object — значит динамика.
Gitkan
Радует то, что если на Rust`е начали писать что-то в продакшн, значит синтаксис и прочие плюшки уже более мене устаканились.
SilentRider
Уже больше года как. 15 мая первый день рождения был)
Massacre
Главное, чтобы новых утечек памяти не было, а то в своё время это было большой проблемой для Firefox…
ozkriff
Тонкая отсылка к https://habrahabr.ru/post/281370?
Massacre
Не совсем (я, скорее, про багтрекер мозиллы), но статья показательная :)
ozkriff
Несмотря на название статьи, в Ржавчине с предотвращением утечек все-таки дела точно не хуже плюсовых.
mtlroom
Странно как-то, а чего такого можно в mp4 демуксере затолкать чтоб сломать парсер? Ведь там нужно каждое поле проверять на ошибки полюбому и все.
Ну и еще интересно было бы если линк на код в статью вставили чтоб можно было полюбоваться
ozkriff
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2015-3870
https://github.com/mozilla/mp4parse-rust
Обе ссылки из текста статьи :)
mtlroom
Детали того «CVE-2015-3870» не читаются. Я парсеры мп4 сам писал и поэтому немного удивился что кто-то умудрился в андроид закомитить код который парсит что-то без валидации размеров.
Вместо того чтоб нормально написать парсер переписать писать его на другом языке? А как же отладка кода (если это не gdb)? В VisualStudio нельзя будет пройтись по парсеру как будто это какой-то массивный opengl что ли?
ozkriff
Я так понимаю, речь об этом и всяком что гуглится по запросу "android stagefright exploit".
Люди время от времени ошибаются или забывают что-то сделать, так было и всегда будет :( .
Я думаю, что те ошибки, которые уже нашли, тут же исправили и выкатили обновления. Вопрос в том, сколько подобных уязвимостей еще не известны авторам, но известны злоумышленникам.
А ржавчина позволяет на порядок уменьшить возможность возникновения подобных косяков (совсем без unsafe на каком-то уровне и без ffi писать реальный код все-таки нельзя).
Отладка это отладка, как она уязвимости должна помогать находить?
mtlroom
«android stagefright exploit» — там в основном все про stagefright, только частично упомянается мп4 парсер, который меньше 5% от stagefright занимает. Сам мп4 парсер довольно таки легко написать без подобных проблем (для тех кто знают структуру мп4 это очевидно).
А в чем проблема к примеру использовать тогда custom C++ array with checked index bounds? Вроде как vector::[] calls vector::at()? Подобная run-time проверка тоже будет.
на счет отладки: если трудно пройтись по коду в отладчике это уж точно не поможет в отладке этих самых уязвимостей и прочих проблем короые могут привести к букету других проблем и уязвимостей.
ozkriff
Ну тогда я бы и сам не отказался от ссылок на подробности :(
Каюсь, я структуру mp4 не знаю и мне не очевидно. По моему опыту правильно написать хоть немного объемный код на плюсах, который работает с данными из недоверенного источника, очень сложно.
Можно, главное везде это последовательно делать (и аналогичную остальную опциональную защиту использовать). А я считаю, как выше написал, что все люди время от времени ошибаются и что-то забывают, так что рутину с человека надо максимально перекладывать на программу. И вот в ржавчине по умолчанию все безопасно и без UB — ты должен специально попросить компилятор если что-то опасное хочешь сделать. А в плюсах наоборот и без UB реальную программу больше сотни строчек написать практически нельзя.
Насколько я помню, что бы была проверка границ у плюсового вектора надо дергать метод
at, а не обычный оператор индексирования.Я не очень в курсе как там сейчас ситуация с отладкой в VS, вроде как подвижки какие-то есть, но в целом так себе работает. IDE для ржавчины и всякие мощные плагины для редакторов вообще пока в состоянии активного развития, тут время нужно.
А в отладчике пройтись по коду не трудно — gdb-то поддерживается.
Отладка уязвимостей, кмк, обычно аналитическая и отладчик тут вообще не нужен — главное узнать о уязвимости. А узнать отладчик никак не поможет, тут скорее статический анализатор нужен.
mtlroom
> Ну тогда я бы и сам не отказался от ссылок на подробности :(
Подробности «android stagefright exploit» или о том что мп4 парсер меньше 5%? stagefright это что-то вроде directx в андроиде, новая мультимедиа подситема заменившая старый медиа код от On2. Сам Mp4 формат нерально тяжелый, но в андроиде он в очень урезаном варианте, как вропчем и везде — mp4 формат нигде толком полностью не написан кроме возможно mp4box. Для обычного проигрывания mp4 или 3gp файлов достаточно маленького сабсета от формата mp4. В кратце формат состоит из «коробок» которые имеют подобную структуру: box = [size][data of size bytes], file: [box][box]...[box], некоторые коробки содержат другие коробки и тд, но ВСЕ они указывают размер данных и все. Есть там всякие ньюансы (32/64-бит size, 0-size и тд) но это все мелочи. Есть пару коробок которые имеют разную структуру в зависимости от того кто файл делал, но все это легко решаемо если код пишется тем кто знает что делает. Поэтому я просто не пойму как переписывание mp4 в другом языке может чем-то помочь, так как скорее всего проблема не в парсере а в том что в коробки засовываются битый bitstream который уже потом взрывает, либо там offsets не правильные указываюся (в коробке-таймлайне) или код который читает коробки с codec-specific-data, но их очевидно что надо проверять а не слепо читать и парсить без оглядки.
> По моему опыту правильно написать хоть немного объемный код на плюсах, который работает с данными из недоверенного источника, очень сложно.
Смотря где. В мп4 парсере нужно написать код для поддержки может 20-ти разных типов коробок, но все они имеют одну и ту же базовую структуру: [размер][данные], т.е. это в базовом классе проверка делается один раз и все.
> Насколько я помню, что бы была проверка границ у плюсового вектора надо дергать метод at, а не обычный оператор индексирования.
Да, именно так. Я имел ввиду что-то вроде этого:
struct xvector: vector<uint8_t>
{
uint8_t& operator[](int pos){ return at(pos); }
};
так как stagefright на С++ написан, класс буфера заменить на xvector и будет оператор[] с проверкой. Mp4 парсер не требует больших мощностей, вот в декодере уже не получится такое делать, там реально в многих местах (как FFT например) все регистры уже под завязку загружены, да и ко всему там часто уже HW-декодеры в зависимости от кодека.
ozkriff
Скорее о том, почему именно этот компонент решили переписывать, хотя про mp4 было интересно почитать, спасибо :). До этой новости я вообще думал, что в серво быстрее попадет https://github.com/servo/rust-url, но с его внедрением какие-то затруднения возникли внезапно.
Мне представляется, что почти все серьезные уязвимости можно сопроводить словами "очевидно, тут надо было просто ..." — иногда человеки просто забывают где-то сделать что-то очевидное.
Мне сама по себе разработка серво мало интересна — только как самый крупный проект на ржавчине, который и держит ее сейчас на плаву — так что я не слежу за подробностями ржавого браузеростроения и теперь не могу нагуглить конкретные причины создания и внедрения mp4parse-rust, видимо обсуждение было внутренним :(
Может конкретно этот компонент переписали просто потому, что его было просто переписать и надо уже начинать протаскивать ржавчину в огнелиса, вполне допускаю.
mtlroom
Да, это очень похоже на причину: парсер не трудно написать, плюс там нет огромных проблем со скоростью если следить за чтением данных. Вполне нормальный кусочек кода который можно переписать на другом языке если есть цель что-то переписать на другом языке. ИМО переписатли не потому что решили таким образом поченить проблеы, а просто решили переписать что-то…
dbanet
Ох блиа, теперь ещё один компилятор портировать...
grossws
Ваш target не поддерживается llvm? Или вы таки про libstd, а не компилятор?
dbanet
Это верно.
grossws
А что за экзотика такая?
Antervis
было бы странно если бы создатели языка им не пользовались
ozkriff
В теории могли бы и не внедрять ничего в огнелиса, а сосредоточить все силы на создание совсем нового браузера поверх servo.
naething
Интересно, а как в Rust решается задача проверки индексов массивов? Понятно, что при простой итерации эту проблему решают конструкции типа for each, которые гарантируют корректность. Но ведь иногда реально нужен доступ по произвольному индексу. Если каждый раз делать проверку, то может выйти дорого, особенно в задачах типа декодирования. А если не делать, то тогда ведь нет никакой безопасности памяти?
Кстати, про foreach: а можно ли в Rust устроить грабли с изменением размера вектора в то время, пока по нему идет итерация?
kstep
При использовании индексов есть проверка на выход индекса за границы массива (bounds check) в рантайме. Да, есть небольшой оверхед, но тут решили в сторону безопасности. Используете итераторы побольше, чтобы таких проверок избежать.
naething
Решение, в принципе, понятное.
Получается, что какой-нибудь FFT на Rust писать скорее всего не имеет смысла (хотя кто знает, вдруг возможно тот же FFT эффективно написать, используя хитрые итераторы вместо доступа по индексу).
ozkriff
Есть еще get_unchecked и get_unchecked_mut, если уж очень надо, но их надо в unsafe заворачивать.
Duha666
Rust бросает исключение при выходе за границу, на этапе компиляции даже для чисел проверки нет.
В foreach нельзя будет поменять вектор, потому что он будет «взят» циклом как неизменяемый, и компилятор это прямо запрещает.
QtRoS
В C# тоже есть эта проверка, и никакого особого влияния на скорость нет. Но при желании можно использовать unsafe, кстати, а как с этим обстоят дела в Rust?..
kstep
Unsafe есть, он позволяет делать много не безопасных штук. Но для алиасинг обычных ссылок всё равно не даст сделать, нужно будет ещё кастить явно в сырые указатели, да не по одному разу (чтобы ещё немутабельность убрать). В общем обойти проверки безопасности можно, но довольно сложно, проще этого не делать и писать безопасно.
GrigoryPerepechko
Вот лишь бы в лужу пёрнуть.
Ее компилятор либо вырезает (если это цикл по массиву), либо она есть и это просадка по скорости раза в 1.5 на очень простых циклах.
ozkriff
Как уже сказали, с честным циклом по массиву — нельзя, но на всякий отмечу, что при использовании явного индекса магии не произойдет:
https://play.rust-lang.org/?gist=43a890e5ead474df1c66ce25894b7e49
...
thread '<main>' panicked at 'index out of bounds: the len is 1 but the index is 1'Halt
(del)
ozkriff
Что нельзя? О.о Вон же ссылка на плейпен.
Спасибо, я в курсе :) При использовании явного индекса (что иногда бывает полезным при работе с массивами) одновременного заимствования массива может и не быть, тогда ошибка произойдет уже только во время работы программы.
Halt
У меня контекст поехал :) Сначала написал комментарий по исходной теме, а потом осознал, что вы о том же. Надо больше спать.
kstep
Погоди, но взятие по индексу ведь занимает массив, так что так просто его не модифицируешь, если где-то сохранились ссылки на значения, взятые по индексу. Или ты про что?
ozkriff
Я же пример кода прилепил)
Я про случай, когда мы сначала узнаем длину массива, а потом старым добрый сишным циклом с "ручным" индексом (язык этого не запрещает же) по нему проходимся — в такой ситуации никакого одновременного заимствования может и не быть.
kstep
Ну если про код из коммента, то да, в таком случае компилятор пропустит, но будет паника в рантайме.
Laney1
ну это ожидаемое поведение. Вообще многие не слишком четко понимают, что rust гарантирует и чего он не гарантирует.
Rust гарантирует, что программа не будет работать в случае классического сишного undefined behavior — либо выкинет исключение, либо вообще не скомпилируется.
Rust НЕ гарантирует, что все UB будут пойманы на этапе компиляции.
Frankenstine
Хм, 47-й ФФ вылетает на просмотре видео на ютубе (и наверное других сайтах), если браузер работает уже несколько часов (сразу после перезапуска исправно играет). Это ещё со старым медиапарсером?
ozkriff
заголовок:
Frankenstine
Меня сбивает с толку заявление
VEG
Возможно, это из-за фрагментации или недостатка памяти, если у вас 32-разрядная версия. В таком случае используйте 64-разрядную версию.
ozkriff
Не спорю.
Из-за этого, собственно, и написал.
Это еще с оговоркой про unsafe — при его неаккуратном использовании много что может пойти не так :(
upd: промазал, ответ на https://habrahabr.ru/post/305536/#comment_9698750
potan
Повод обновить браузер!
nzeemin
Ссылка «чтобы начать» — есть ещё перевод Rust the Book на русский — http://rurust.github.io/rust_book_ru/
WayMax
Если честно, статья из разряда татей про «веганов» доказывающих что они полноценные люди и получают из своей травы все нужные элементы для здорового питания.
— Я сделяль часть ФаерФокса на Руст.
— Ок, здорово, но зачем? Просто потому что мог? Что это дало ПОЛЬЗОВАТЕЛЯМ? Браузер стал быстрее запускаться? Быстрее работать? Отжирать меньше памяти?
— Но… но… я сделяль код на Руст который не крашит ФаерФокс
— Ок, здорово, но на C/C++ тоже можно писать код который не будет крашиться.
Так в чем смысл был? Банальная фаллометрия?
ozkriff
От самого факта переписывания этого компонента на ржавчину пользователям и правда прямо сейчас прямой выгоды нет (как и вреда).
Смысл в самом прецеденте — Ржавчина пробралась в стабильную ветку такого большого проекта. Для начала в небольшой компонент, но надо понимать сколько за этим стоит работы по подтягиванию инфраструктуры Ржавчины до нужного состояния (на андроиде вон до сих пор добивают) и адаптации сборки самого Firefox.
Т.е. это реальный и значительный шажок к будущему, когда процент ржавого кода сильно вырастет и уже это позволит добиться более быстрого времени запуска, лучшей производительности и меньшего потребления памяти.
Предполагается что на Ржавчине это делать проще, особенно в больших масштабах.
Раст
WayMax
Ну как я и сказал — фаллометрия. Я гордое: «я сделяль».
Всего 3 минуса — что-то хипстота некачественно негодует.
ozkriff
Можно подробней где тут эта самая очевидная фаллометрия? Кто с кем длинной чего меряется вообще?
Ленивые ретрограды всех так называют
DarkEld3r
Наверное, смысл в том насколько больше/меньше для этого усилий требуется? (:
WayMax
Был код на C/C++ который не крашился, потратили время переписывая его на Rust.
Оставить код = ноль усилий.
Переписать нафиг = овер9000 усилий.
Л — логика.
ozkriff
Логика в том, что плюсы — плохой инструмент (по крайней мере с точки зрения Мозиллы, иначе бы они разработку Ржавчины не оплачивали) и его постепенно заменяют на лучший инструмент — ржавчину. Да, поначалу это проносит мало прямой выгоды для пользователей, но в долгосрочной перспективе должно быть для них выигрышно.
Можно подумать это единственная проблема плюсового кода.
PsyHaSTe
Пока что браузер, у которого в тикетах только куча feature и ни одного bug существует только в моих мечтах. Наверное, все же не получается писать на С++ код, который не крашится. Либо все разработчики браузеров сговорились, конечно же.
ozkriff
А я правильно понимаю, что из-за этого теперь во всех линуксовых дистрибутивах (файерфокс же, наверное, практически во всех есть, кроме совсем уж узко специализированных) будет более-менее свежий стабильный rustc/cargo?
Laney1
скорее менее, чем более. В любом случае это не очень важно, так как есть rustup
ozkriff
Как минимум, 1.8 должен быть. Значит и дистрибутивам, что бы нормально собрать фаерфокс придется хотя бы такой же запаковывать.
Не критично (хорошо хоть оно уже давно "curl… | sudo sh" не требует), да, но мне массовое использование rustup видится временной мерой. С течением времени хотелось бы ставить cargo/rustc как обычный gcc — из пакетного менеджера, а не где-то сбоку.
ozkriff
Откуда я 1.8 взял? 1.10 текущая стабильная же.
kstep
Ну в арчике из оф.реп ставится стабильный раст и карго. Растап нужен для найтли и бет разве что.
ozkriff
Оперативность обновления пакетов — одна из его сильных сторон арча, тут вопросов нет) А вот во всяких убунтах/сусях с ржавчиной в стандартных репозиториях дела пока так себе.