

Коллизии существуют для большинства хеш-функций, но для самых хороших из них количество коллизий близко к теоретическому минимуму. Например, за десять лет с момента изобретения SHA-1 не было известно ни об одном практическом способе генерации коллизий. Теперь такой есть. Сегодня первый алгоритм генерации коллизий для SHA-1 представили сотрудники компании Google и Центра математики и информатики в Амстердаме.
Вот доказательство: два документа PDF с разным содержимым, но одинаковыми цифровыми подписями SHA-1.
$ls -l sha*.pdf
-rw-r--r--@ 1 amichal staff 422435 Feb 23 10:01 shattered-1.pdf
-rw-r--r--@ 1 amichal staff 422435 Feb 23 10:14 shattered-2.pdf
$shasum -a 1 sha*.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdfНа сайте shattered.it можно проверить любой файл на предмет того, входит ли он в пространство возможных коллизий. То есть можно ли подобрать другой набор данных (файл) с таким же хешем. Вектор атаки здесь понятен: злоумышленник может подменить «хороший» файл своим экземпляром с закладкой, вредоносным макросом или загрузчиком трояна. И этот «плохой» файл будет иметь такой же хеш или цифровую подпись.
Криптографические хеш-функции вроде SHA-1 — это универсальный криптографический инструмент, который повсеместно используется в практических приложениях. Они нужны при построении ассоциативных массивов, при поиске дубликатов в наборах данных, при построении уникальных идентификаторов, при вычислении контрольных сумм для обнаружения ошибок. Например, на хеши SHA-1 полностью полагается система управлениями версиями программного обеспечения Git.
Но ещё важнее, что хеширование критически важно в сфере информационной безопасности: оно используется при сохранении паролей, при выработке электронной подписи и т.д. В общем виде, хеш-функции преобразуют любой большой массив данных в небольшое сообщение.
Учитывая повсеместное распространение хеш-функций очень важным требованием является минимальное количество коллизий, когда два различных блока входных данных преобразуются в два одинаковых хеша.
В официальном сообщении авторы говорят, что эта находка стала результатом двухлетнего исследования, которая началась после вскоре публикации в 2013 году работы криптографа Марка Стивенса из Центра математики и информатики в Амстердаме о теоретическом подходе к созданию коллизии SHA-1. Он же в дальнейшем продолжил поиск практических методов взлома вместе с коллегами из Google.
Компания Google давно выразила своё недоверие SHA-1, особенно в качестве использования этой функции для подписи сертификатов TLS. Ещё в 2014 году, вскоре после публикации работы Стивенса, группа разработчиков Chrome объявила о постепенном отказе от использования SHA-1. Теперь они надеются, что практическая атака на SHA-1 увеличит понимание у сообщества информационной безопасности, так что многие ускорят отказ от SHA-1.
Специалисты начали поиск практического метода атаки с создания PDF-префикса, специально подобранного для генерации двух документов с разным контентом, но одинаковым хешем SHA-1.

PDF-префикс
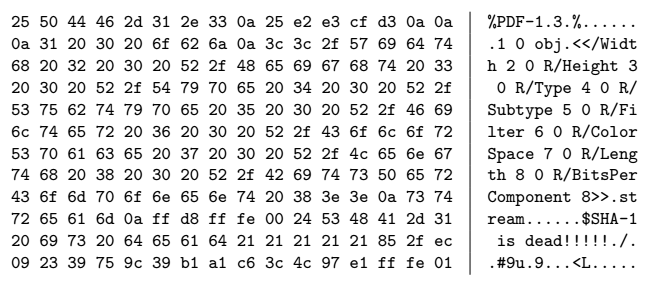
Идентичный префикс для коллизии, рассчитанной на инфраструктуре Google
Затем они использовали инфраструктуру Google, чтобы произвести вычисления и проверить теоретические выкладки. Разработчики говорят, что это было одно из самых крупных вычислений, которые когда-либо проводила компания Google. В общей сложности было произведено девять квинтиллионов вычислений SHA-1 (9 223 372 036 854 775 808), что потребовало 6500 процессорных лет на первой фазе и 110 лет GPU на второй фазе атаки.
Числа кажутся большими, но на самом деле такая атака вполне практически реализуема для злоумышленника, у которого есть крупный компьютерный кластер или просто деньги на оплату процессорного времени в облаке. По оценке Google, атака проводится примерно в 100 000 быстрее, чем брутфорс, который можно считать непрактичным.
Чтобы представить число хешей, которые обсчитала Google во время брутфорса, можно упомянуть, что примерно такое же количество хешей SHA-256 обсчитывается в сети Bitcoin каждые три секунды, так что в атаке нет ничего фантастического. Вполне можно предположить, что в криптографических отделах некоторых организаций с большими дата-центрами уже давно обсчитываются коллизии SHA-1. Правда, чтобы подобрать коллизию для конкретного сертификата TLS, нужен какой-то другой метод, потому что идентичный префикс из научной работы Google для PDF там не подойдёт. С другой стороны, содержимое сертификатов во многом совпадает, так что теоретически префикс для коллизии можно подобрать.
Сейчас Марк Стивенс с соавторами опубликовали научную работу, в которой описывают общие принципы генерации документов с блоками сообщений, которые подвержены коллизии SHA-1.
Блоки сообщений, которые подвержены коллизии SHA-1
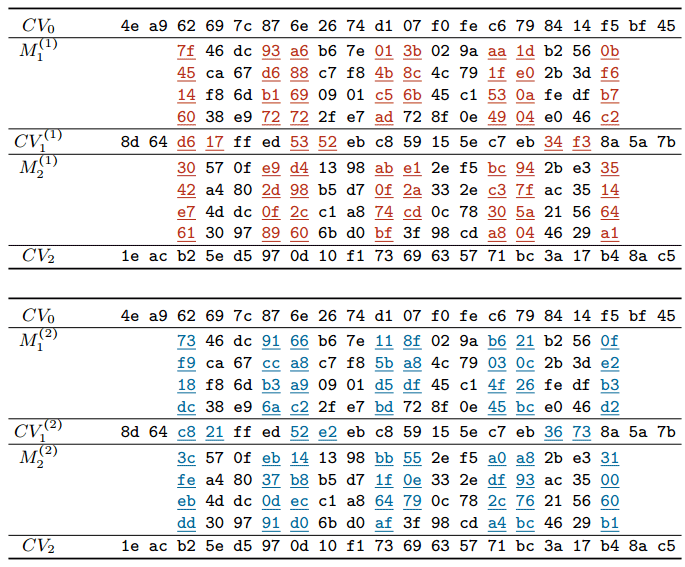
В соответствии с принятыми правилами раскрытия уязвимостей Google обещает через 90 дней опубликовать в открытом доступе полный код для проведения атаки. Тогда кто угодно может создавать разные документы с одинаковыми цифровыми подписями SHA-1. Возможно, даже разные сертификаты, разные обновления программного обеспечения в Git, разные раздачи на торрентах (хеши DHT), разные старые ключи PGP/GPG и т.д. Впрочем, не стоит преувеличивать опасность таких атак, ведь далеко не каждый документ будет подвержен атаке на поиск коллизии. То есть злоумышленнику придётся изначально создавать два файла: один «хороший», а второй «плохой» с такой же подписью. Затем распространять «хороший» документ по нормальным каналам (например, через Git или торрент-трекер), а впоследствии пробовать подменить его «плохим» файлом с той же цифровой подписью. Впрочем, всё это чисто теоретические рассуждения.
Защита от документов, подверженных коллизии хешей SHA-1 уже встроена в программное обеспечение Gmail и GSuite. Как уже упоминалось выше, детектор уязвимых документов работает в открытом доступе на сайте shattered.io. Кроме того, библиотека для обнаружения коллизий опубликована на Github.
В качестве защиты от атаки на отыскание коллизий SHA-1 компания Google рекомендует перейти на более качественные криптографические хеш-функции SHA-256 и SHA-3.
Комментарии (37)

Ivan_83
24.02.2017 00:21Очень странные рекомендации. Очень.
С SHA3 вроде не всё так однозначно.
И почему sha2-256 а не 512?
И опять же, как будто ничего кроме SHA не существует, хотя приличных хэш функций десятки.
2 pda0
Да никому не нужны пулрегвесты в гите, за такие деньги которых стоит поиск коллизии.
Подмену легко найти, и сам файл трудно распространить — ибо обычно куча народу уже имеют свою копию.
Кроме того, гит легко переедет на sha2: все файлы там в наличии, просто пересчитают и перестроят индекс или что у них там внутри.
bachin
24.02.2017 01:48+2> И опять же, как будто ничего кроме SHA не существует, хотя приличных хэш функций десятки.
Ну, вообще-то SHA — это аббревиатура Secure Hash Algorithm, то есть как раз «приличная хэш-фунция может быть признана SHA», а не наоборот, семейство SHA-функций входит во множество «приличных». Для этого её авторы должны попробовать доказать её криптографическую надежность, а ученые умы должны потыкать в неё своими инструментами, покачать убеленными сединами головами и либо одобрить, либо отклонить. Ну там всякие скорости, ресурсоемкости и прочие вещи всегда учитываются.Ivan_83
25.02.2017 01:52Вот только у SHA два значения.
С одной стороны это безопасный хэш алгоритм а с другой это статус который присваивают амеры при стандартизации для себя.
Собственно сейчас речь была статусы, ибо 1, 2 и 3 это то что они одобрили для себя в ходе состязания с одним(!) победителем.
При этом как в рамках самой процедуры было много достойных кандидатов, так и тех кто вообще в этом не участвовал.
Конкретно мне не нравится что рекомендуют всё то что сделано для одной конкретной страны делая вид что больше и выбирать не из чего.
ivlis
24.02.2017 04:09+9> Вектор атаки здесь понятен: злоумышленник может подменить «хороший» файл своим экземпляров с закладкой, вредоносным макросом или загрузчиком трояна. И этот «плохой» файл будет иметь такой же хеш или цифровую подпись.
Нет. Тут генерируются два файла одновременно с одинаковым хэшем. Сгенерировать один файл по известному хэшу в разы сложнее!
Bombus
24.02.2017 08:18+1Относительно простой способ проверить не скомпрометирован ли файл — иметь как минимум два разных типа хэшей у одного объекта (к примеру, SHA-1 и SHA-256). Представляется чем-то невероятным генерацию коллизий одновременно по двум типам.

user4000
24.02.2017 09:30Генерация коллизий по двум типам хэшей ничем не отличается от генерации коллизий по одному хэшу (по сложности равному сумме двух предыдущих).
Disasm
24.02.2017 11:47Сумме? Может, всё-таки, произведению?
At0mik
24.02.2017 12:54+1Ситуация еще хуже. Сам только сегодня узнал.
Оказывается что, теоретически, конкатенация 2-х хэшей не лучше чем самый слабый из 2-х.
В этом конкретном случае, ша1 + мд5 будет (скорее всего) лучше чем взломанный ша1 (2^50 colision resistence); и лучше чем взломанный мд5 (2^40).
Но, при этом, не устойчивее к генерации коллизий чем качественны, не взломанный, 160-битный хэш, каким считался ша1 (2^80)
Для большей информации, искать «Multicollisions in iterated hash functions. Application to cascaded constructions»stepik777
24.02.2017 14:07+1конкатенация 2-х хэшей не лучше чем самый слабый из 2-х.
То есть например конкатенация CRC-32 и SHA-512 не лучше чем CRC-32?
knstqq
24.02.2017 14:21+2Здесь скорее всего имеется последовательное применение
SHA-512(CRC-32(text)) или CRC-32(SHA-512(text)), а не конкатенация.
Конкатенация с увеличением суммарной длины хэша улучшает надёжность.
At0mik
24.02.2017 14:40Да, извиняюсь… механическая ошибка. Правильно будет: не сильнее самого СТОЙКОГО из 2-х
imkas
24.02.2017 16:00а зачем использовать конкатенацию, если можно проводить валидацию по 2 хэшам? например MD5 и SHA-1. в этом случае вероятности нахождения коллизий для каждого из использованных алгоритмов перемножаются.
вероятность нахождения коллизии для SHA-1 равна 2^-80 (=8.3e-25) а для MD5 — 2^-40(=9.1e-13). тогда произведение вероятностей будет равно 7.5e-37.At0mik
24.02.2017 16:33Мы говорим об одинаковых вещах по разному.
— Рассчитать оба хэша; конкатенировать их; а потом сравнить.
— Рассчитать оба хэша; и сравнить отдельно.
Очень часто в криптографии интуитивные выводы не верны.
И это один из таких случаев.
вероятность нахождения коллизии для идеального 160 -битного хэша: 2^-80
вероятность нахождения коллизии для идеального 128 -битного хэша: 2^-64
Вы правы, были бы эти хэши идеальными, вероятность коллизии в конкатенации была бы 2^(-80-64) = 2 ^ (-144).
Но!!! если рассчитать хотя-бы один из таких хэшей по итеративному принципу, вероятность коллизии становиться «чуть менее» 2^-80.
В реальности: и MD5, и SHA1, и SHA2… итеративные хэши; а вот SHA3 нет.
Так вот,
в SHA1 нашли возможность повысить вероятность до 2^-50
в MD5 и того хуже… 2^-40
Вероятность найти коллизию в SHA1 + MD5 где-то между 2^-50 (SHA1) и 2^-80+epsilon (теоретический максимум); но никак не 2^(-50-40) = 2^(-90)
il--ya
28.02.2017 14:13Вероятность найти коллизию в SHA1 + MD5 где-то между 2^-50 (SHA1) и 2^-80+epsilon (теоретический максимум); но никак не 2^(-50-40) = 2^(-90)
И всё-таки это лучше, чем один только SHA1 (2^-50) или один только MD5 (2^-40), нет?
Очень часто в криптографии интуитивные выводы не верны.
Никакой интуиции, одна суровая логика.At0mik
28.02.2017 15:04да, вы правы. Это лучше чем каждый по отдельности.
На много ли? скорее всего нет. Почитайте документ который я упомянул: «Multicollisions in iterated hash functions. Application to cascaded constructions»
Если коротко. Самая простая атака будет примерно следующей:
Генерируются 2 документа с одинаковым sha1: 2^50… а вот md5 у них будет разный.
После этого, добавляем (одинаковый) мусор в конец этих 2-х документов (почитайте про «Length extension attack»). Скорее всего, этот мусор будет незаметным в бинарном документе. Получаем другие 2 документа с одинаковым sha1, но с разным md5.
Повторяем 2^64 (md5) раз с разным мусором. С большой вероятностью, найдем 2 документа с одинаковым md5 И sha1.
В конце концов, нашли хэш за 2^64 + 2^50 = 2^64.
И это «тупой перебор». В реальность же дело (скорее всего) хуже.
Как я уже говорил, этот трюк не пройдет с sha3, но у него свой проблемы.
Если хэш важен, используйте sha2 и будьте готовы заменить когда взломают. Не надо надеяться что 2 слабых хэша спасут из-за того что их 2.
Плюс к этому, есть вероятность что sha1+md5 будет медленнее чем один хороший хэш. Зачем тогда мучатся?il--ya
28.02.2017 16:07Плюс к этому, есть вероятность что sha1+md5 будет медленнее чем один хороший хэш. Зачем тогда мучатся?
С этим не поспоришь, низкая эффективность — очевидный недостаток. Однако я тут вижу некоторый компромисс. В «хорошем» может обнаружиться фатальная уязвимость, в этом случае два хэша дают какой-то запас надёжности и времени за не очень высокую цену.
il--ya
28.02.2017 16:23После этого, добавляем (одинаковый) мусор в конец этих 2-х документов (почитайте про «Length extension attack»). Скорее всего, этот мусор будет незаметным в бинарном документе. Получаем другие 2 документа с одинаковым sha1, но с разным md5.
Тут у вас ошибка, по-моему. Если мусор добавили одинаковый, а документы изначально разные, то sha1 будет разный.
Корркетно было бы добавлять только к одному документу, сохраняя sha1 и подбирая при этом MD5, чтобы совпал со вторым.
Но в общем я согласен, что суммарная устойчивость может при определённых условиях оказаться не сильно выше, чем каждый хэш в отдельности.At0mik
28.02.2017 16:43Вы опять заблуждаетесь. По конструкции sha1, хэш у них будет будет одинаковый:
$ sha1sum shattered-*.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf
$ echo «musssor» >> shattered-1.pdf
$ echo «musssor» >> shattered-2.pdf
$ sha1sum shattered-*.pdf
589dec295aaa1fb915e767db80d5b7533b1b7e16 shattered-1.pdf
589dec295aaa1fb915e767db80d5b7533b1b7e16 shattered-2.pdfil--ya
28.02.2017 17:02Я думал, у sha1 состояние более, чем просто текущий хэш.
Согласен, заблуждаюсь. Но почему «опять»? ))At0mik
28.02.2017 18:10Эта главная (известная мне) причина почему 2 «итеративные» хэш функции не лучше самой стойкой из 2-х.
И почему на sha3 это правило не действует.
Кто его знает какие еще векторы атаки есть… о которых мне не известно но для криптографов очевидны.
Я погорячился сказав «опять» ))At0mik
01.03.2017 00:44Подумав немного… я понял что предложенный мной метод вообще-то не работает.
Почитайте предложенную мною статью: там правильный метод.
Вот и я положился на интуицию в криптографии… и она меня подвела.

Mendel
28.02.2017 16:45Оно выше число за счет _неожиданного_ взлома одного из алгоритмов.
Примерно как запаска у парашюта — заметно хуже основного, но если ты потерял основной купол, и не смог сесть со скоростью 5м/с, то лучше сесть с 10м/с, пусть даже зашибешь мягкое место, чем влететь со скоростью в пару сотен метров и гарантированно разбиться. Так и здесь — при потере более стойкого хеша у нас останется менее стойкий, а так то компрометированно было бы всё.
Xaliuss
24.02.2017 19:58Сложности тут будут перемножаться, то есть необходимое число вычислений увеличится соответственно в квинтильон раз…
Эта особенность атак связанных с перебором и приводит к тому, что увеличение длины ключа повышает защиту от брутфорса (и связанных вещей) на много порядков, при более-менее линейном (в принципе полиномиальном, в зависимости от алгоритма) увеличении затрат на шифрование/хеширование, единственной проблемой может быть только железная поддержка только ключей определенной длины.
imbasoft
24.02.2017 10:12Практическая схема атак, связанных с поиском коллизий второго рода может быть следующей:
1. Есть легитимный электронный документ подписанный электронной подписью (например, платежное поручение).
2. Злоумышленник, вносит изменения в оригинальный документ изменения (например, подменяет реквизиты получателя).
3. Используя алгоритмы поиска коллизий, злоумышленник ищет такое дополнение в к модифицированному файлу, которое позволит сделать его хэш идентичным оригиналу.
4. Злоумышленник подменяет оригинальный документ модифицированным с таким же хэшом.
Так же следует понимать, что создание электронной подписи, в общем случае, это шифрование хэша документа на закрытом ключе подписанта, поэтому в модифицированном документе, электронная подпись будет валидной и соответствовать ЭП оригинального документа.
grossws
26.02.2017 02:01-1- Есть легитимный электронный документ подписанный электронной подписью (например, платежное поручение).
- Злоумышленник, вносит изменения в оригинальный документ изменения (например, подменяет реквизиты получателя).
- Используя алгоритмы поиска коллизий, злоумышленник ищет такое дополнение в к модифицированному файлу, которое позволит сделать его хэш идентичным оригиналу.
- Злоумышленник подменяет оригинальный документ модифицированным с таким же хэшом.
Ваш вариант — про коллизии первого рода (она же second preimage attack), т. е. при наличии
H(M_1) = Xнайти такойM_2, чтоH(M_2) = X.
Если говорить про коллизии второго рода — то вектор такой: злоумышленник генерирует пару документов, один из которых подписывает атакуемый, а потом подменяет этот документ вторым из пары.
Так же следует понимать, что создание электронной подписи, в общем случае, это шифрование хэша документа на закрытом ключе подписанта, поэтому в модифицированном документе, электронная подпись будет валидной и соответствовать ЭП оригинального документа.
Шифрование и подпись — два разных процесса. Подпись не является шифрованием. В частном случае использования RSA для подписи оно технически неотличимо. В случае каких-нибудь DSA/ECDSA или EdDSA операции шифрования вообще нет.

Beholder
25.02.2017 11:18Можно ли, имея эти два файла, сломать Git-репозиторий? (пусть даже на искусственном примере)
grossws
26.02.2017 02:02В некотором смысле можно. Выше постил ссылку на webkit'овский багтрекер: https://bugs.webkit.org/show_bug.cgi?id=168774#c23.

pda0
Подписи это конечно хорошо, но по моему самое время подумать о ядовитых pull-request в git. Похоже коллизии могут повреждать репозиторий.
datacompboy
не повреждать, а терять новый объект.
в целом, выходит безопасно — перезаписать с помощью коллизии что-то нельзя.
grossws
webkit'овскую автоматизацию это развалило: https://bugs.webkit.org/show_bug.cgi?id=168774#c23
datacompboy
это разжевало свинину а не гит.