

Травим краулер

Извлекаем текст, удаляем мусор, генерируем пятисловные шинглы

На ответивших контентом страницах найдено 588,086,318 шинглов.
Складываем каждый шингл с дополнительной информацией в датасет top1m_shingles:
shingle,domain,position,count_on_page
Рассчитываем n-граммы
SELECT
shingle,
COUNT(shingle) cnt
FROM
top1m_shingles
GROUP BY
shingle
На выходе имеем таблицу shingle_w из 476,380,752 уникальных n-грамм с весами.
Дописываем вес шингла в рамках базы к исходному датасету:
SELECT
shingle,
domain,
position,
count_on_page,
b.cnt count_on_base
FROM
top1m_shingles AS a
JOIN
shingles_w AS b
ON
a.shingle = b.shingle
Если получившийся датасет сгруппировать по документам (доменам) и сконкатить значения n-грамм и позиций, получим развесованную табличку для каждого домена.
Обогащаем on_page показателями, средними, рассчитываем UNIQ RATIO для каждого документа (как соотношение количества уникальных шинглов в рамках базы к не уникальным), выводим n-граммы, генерируем страничку:


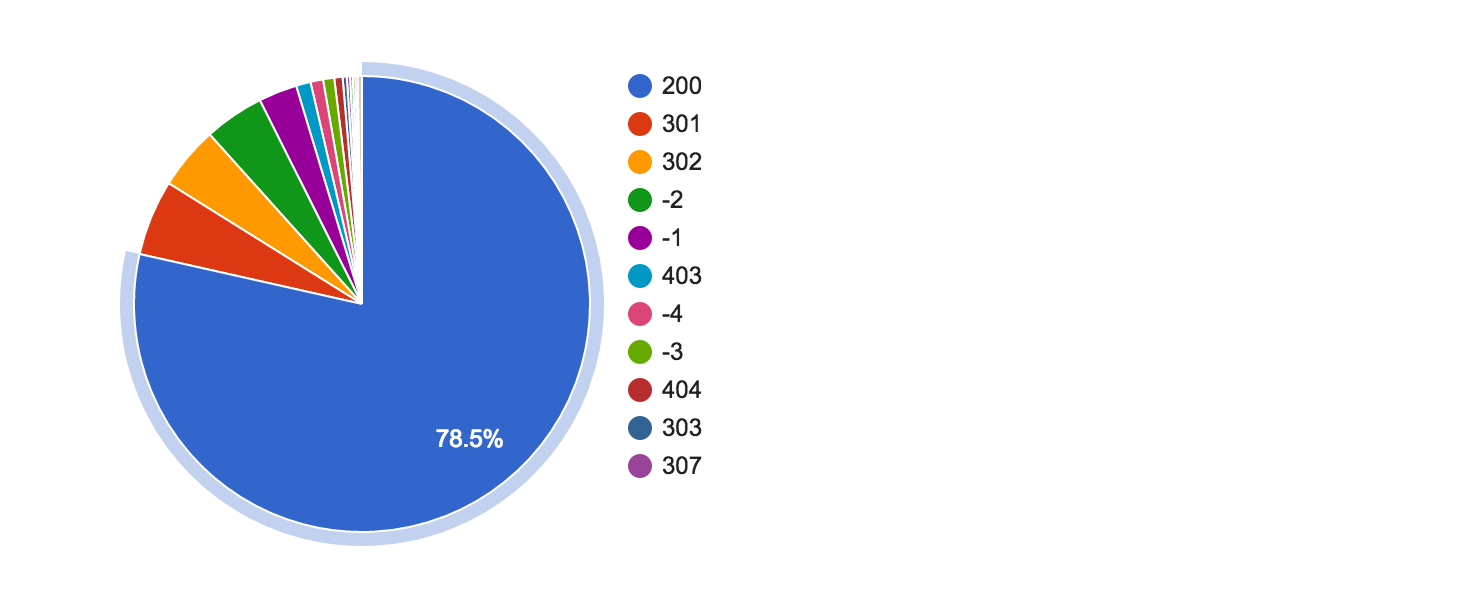
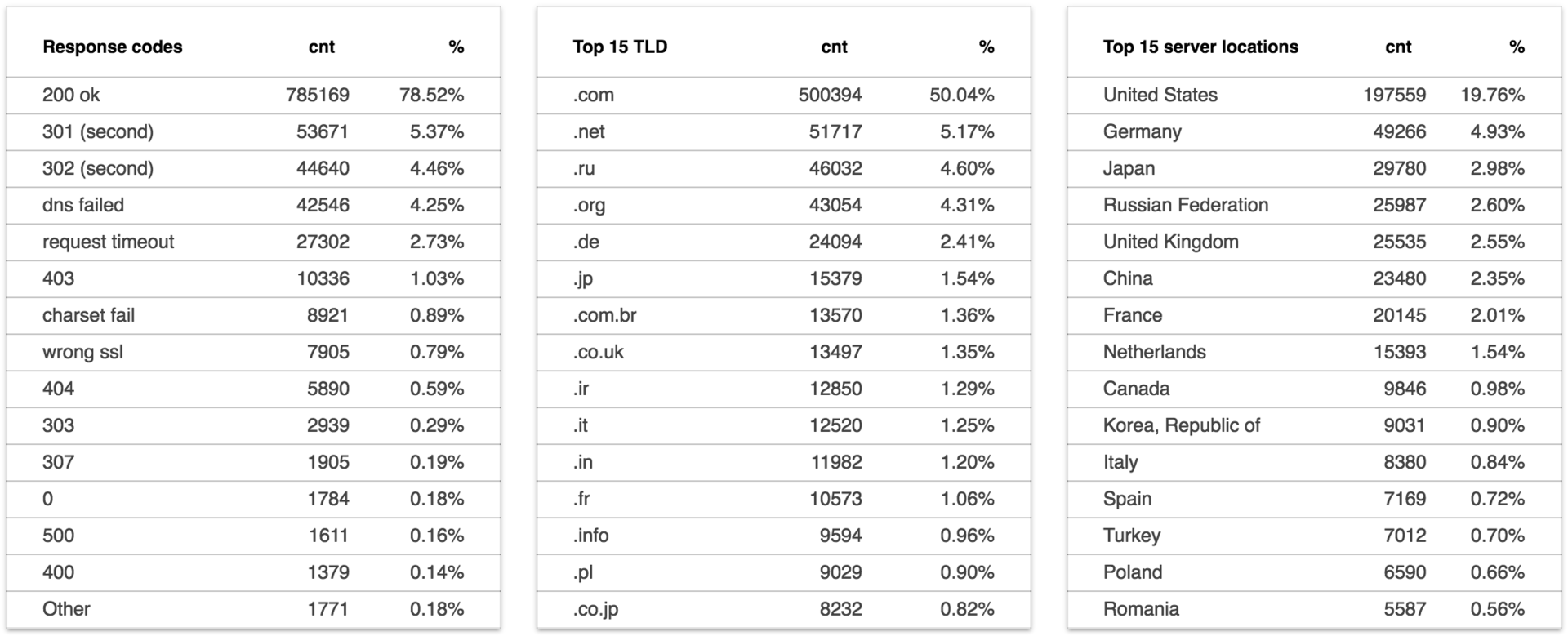
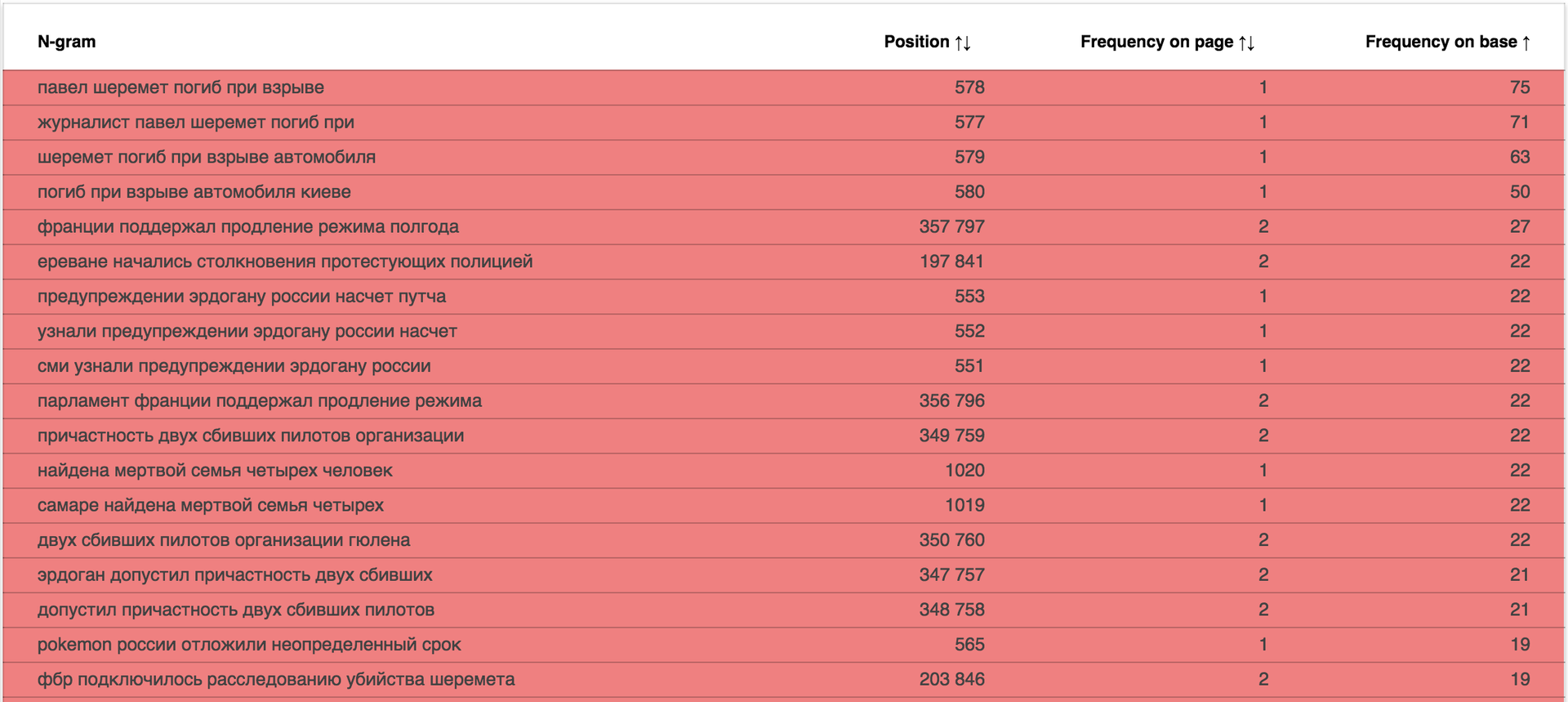
Отчёт доступен по адресу: data.statoperator.com/report/habrahabr.ru и содержит полную таблицу с текстами шиглов и их значениями. Шинглы изначально не отсортированы. Если хочется просмотреть их в том порядке, в котором они шли в документе — сортните таблицу по позиции. Или по частоте в базе, как на изображении:
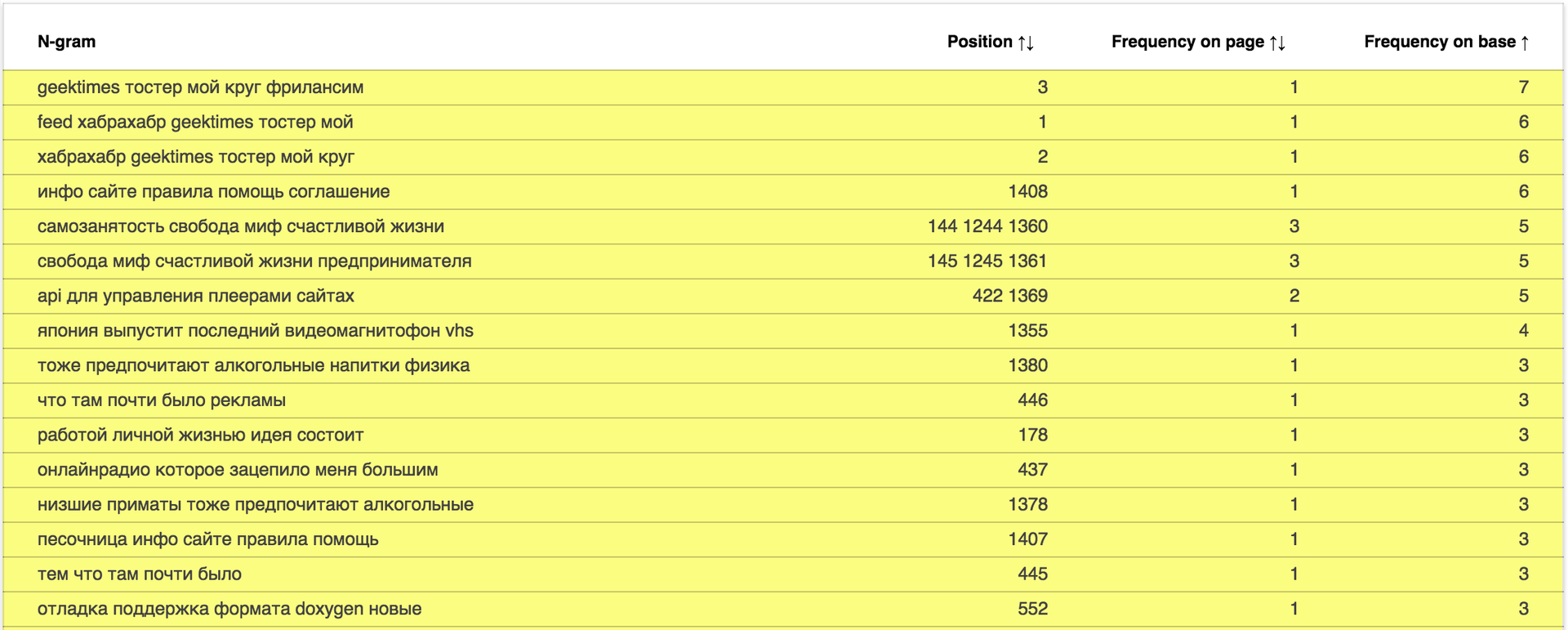
Меняем домен в урле или вводим в форме поиска и смотрим отчёт по любому домену из списка Alexa top 1M.
Интересно взглянуть на новостные сайты: data.statoperator.com/report/lenta.ru
Средний показатель уникальности страниц: 82.2020%
Сбор данных: 2016-07-21
Дата генерации отчёта: 2016-07-27
Комментарии (16)

azsx
07.08.2016 12:43+2Не совсем понятно про парсинг. Вы получили контент с 785 169 сайтов за 1 час 10 минут? Или только url получили для парсинга?
Как рассчитать нормальную скорость парсинга для разных доменов? Например, я обрабатываю 250 тысяч доменов в сутки, из них 70 тысяч не отвечают совсем (грязная база). Это нормально на 1 компьютере с интернетом в 30 мб/с или мало?

daocrawler
07.08.2016 22:11За 1 час 10 минут был получен контент всех адекватно ответивших серверов до второго редиректа в состоянии n-грамм.
Рассчитывать скорость собственной системы имеет смысл отталкиваясь от количества данных, которые она генерирует. Я не знаю, что вы парсите и сколько пишете. Мы генерируем данных больше, чем скачиваем, по железу упираемся в скорость записи хардов. Чем резолвить — тоже важно.
Master255
08.08.2016 01:14+5не важно какую работу вы проделали, если объяснить не можете. Я вообще ничего не пойму из статьи.
Во что превратился Хабр.
azsx
08.08.2016 02:01За 1 час 10 минут был получен контент всех адекватно ответивших серверов до второго редиректа в состоянии n-грамм.
всё таки мне этот момент не очень понятен. Раз 1 000 000 вы делаете за 70 минут, то в минуту вы делаете 14285 доменов. Допустим, 1 миллиард доменов, тогда ((1 000 000 000/14285)/60)/24 приблизительно за 49 часов вы спарсите все главные в интернете? Или «в состоянии n-грамм» не подразумевает получение всей страницы?
Также у вас мельком указано «извлекаем текст». Был извлечен текст, который просто вне тегов разметки внутри body?
bestfriend
08.08.2016 02:22скажите, пожалуйста, что именно вам кажется невозможным в задаче «спарсить миллиард главных за 50 часов»?
bestfriend
08.08.2016 02:34собственно, при 0.1 сек на получение и 0.1 сек на обработку данных (цифры из головы и, возможно, даже завышены), задача решается выполнением процесса уже всего лишь на 56 нодах =)
daocrawler
08.08.2016 02:22У вас ошибка в расчёте. Но в целом всё примерно так, ~ 49 суток одна нода будет выкачивать миллиард. Проблемы быстро накачать нет.
После получения html страницы текст извлекается вот так
Очищается и разбивается на n-граммы.azsx
08.08.2016 07:52+2извините, ошибся в расчетах. Точно 49 суток!!! Тогда нормально.
А в каком виде вы сохраняли результаты парсинга? В текстовых файлах или какое-то хранилище?
Также, для меня очень сложный вопрос, как вы решаете проблему с кодировками? Например, некоторые японские и арабские сайты никак не записываются в поля utf8 (стандартной БД). У меня не записываются. Приходится их править перед записью. Удалять недопустимые коды для utf8. У вас такая проблема была?
ps
очень интересны технические подробности.
alekciy
08.08.2016 11:54Влезу в тред. У меня была разок очень весела проблема. Страница в 1251 c utf-ым BOM.
Касательно приведенной теме лично я делаю конвертацию в utf-8 (нужны были бы япоцы или арабы, то использовал бы что-то в духе utf-16) + храню исходный код как бинарную строку (больше для дебага). Конвертация позволяет отделить подсистему загрузку страниц от парсинга при котором действует правило «все находится в utf и только в нем». Недопустимые последовательности либо конвертируются, если могут, либо просто игнорируются (т.к. это 100% какой либо мусор не именующий отношения к нужным данным).azsx
08.08.2016 12:08> если могут, либо просто игнорируются (т.к. это 100% какой либо мусор не именующий отношения к нужным данным).
я временно также игнорирую недопустимые последовательности, тем не менее — это не мусор. Это данные, просто написаны на ихних языках.
Разницу между utf 8 — 16 -32 кроме размера я не понимаю. Они вроде как одинаковые, нет?alekciy
08.08.2016 13:38Деталей с ходу не помню. Но вроде как да в контексте парсинга да, можно считать одинаковыми. И для международного парсинга использовать utf-32.
Если это не мусор, то через iconv конвертируется в корректные последовательности вполне нормально. При условии конечно правильного указания входной кодировки. Все остальное это будет уже либо мусор, либо ошибки (как приведенный мною пример с BOM).
questor
Можно было сформулировать какие-либо практические выводы в конце статьи. Сейчас сплошные сырые данные без анализа.
daocrawler
Для того, чтобы написать эту статью, мы:
— развернули кластер
— сделали 1,000,000 GET запросов
— проанализировали 785,169 документов
— выделили и обсчитали 588,086,318 n-грамм
— сгенерировали 769,459 документов для каждого домена из списка
— подняли интерфейс, настроили веб-сервис
— показали как работает анализ по n-граммам на примере новостного сайта, объяснили как смотреть по домену
— вывели средний показатель дуплицированности главных страниц всех самых популярных сайтов мира
и вы пишете первым комментарием к статье:
У вас совесть есть?
synedra
При чём тут совесть? У вас действительно сырые данные без анализа. Это же классическая проблема, например, дипломных работ на слабых кафедрах. Мы измерили экспрессию того и этого в разных условиях, мы молодцы. Молодцы, конечно, методы у вас вроде крутые, но анализ данных не самоцель. Зачем он проводился? Какие из полученных данных следуют выводы? На хабре могла бы проканать статья в стиле «Парсим и анализируем много страниц средствами такого-то фреймворка на таком-то кластере», но и используемые технологии не описаны.
Apatic
И обо всем этом вы почему-то пишите только в комментарии.