
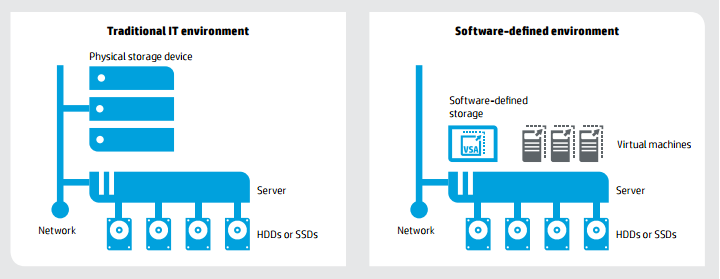
Программно-определяемые хранилища (в дальнейшем — SDS) считаются следующей вехой в развитии технологий хранения данных. Эта технология является новичком на рынке, поэтому однозначного и точного определения этому термину пока нет. Похожая ситуация присутствовала на заре «облаков», когда данным термином называли все подряд, не особенно вникая в его значение. По аналогии с упомянутыми «облаками», основная идея SDS заключается в абстрагировании от аппаратной составляющей и приходу к бизнес-ориентированной модели построения систем хранения и обработки.
Сейчас же, в большинстве случаев, мы говорим о программной виртуализации хранилищ данных. При этом речь идет не о пресловутой подмене одного СХД другим за счет встроенных функций или аппаратных шлюзов, а о виртуализации локальных дисков ваших вычислительных узлов.
У меня данный подход вызывает легкое недоумение, ведь уже на протяжении многих лет все производители А-класса ИТ-индустрии усиленно внушали нам мысль, что будущее за СХД, в основу которых заложена идея разнесения хранения и обработки данных, что приведет к повышению их доступности и защищенности.
Начало моей карьеры в ИТ пришлось на пору появления виртуализации, поэтому я лично наблюдал как нехотя и болезненно многие компании переходили от «ортодоксальной» схемы «одно приложение — один сервер» к виртуализированным кластерам с вынесенными хранилищами. И теперь, когда использование СХД уже многократно обосновано и повсеместно принято в «боевых» инфраструктурах, те же самые производители говорят нам, что новой вехой является возврат к использованию локальных дисков наших серверов. Именно поэтому в данной статье я не только хочу выразить свое мнение, но и услышать от вас вашу оценку как конкретно данного продукта, так и всей идеи SDS в общем.
Архитектура
HPE VSA является программным продуктом, устанавливаемым узлы на виртуального кластера. На текущий момент, поддерживаются продукты VMware vSphere, Microsoft Hyper-V, и KVM. Для vSphere и Hyper-V существуют плагины для интеграции с их консолями управления, что позволяет управлять всей инфраструктурой из единой точки.
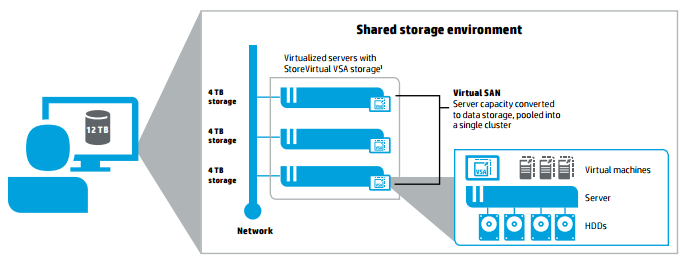
Для типового развертывания HPE StoreVirtual VSA необходимо 3 узла — два узла для отказоустойчивости, и третий для размещения Quorum Witness, который будет отвечать за консистентность данных на всех узлах в случае разрыва связи. Возможен сценарий с использованием только 2-х узлов, однако в этом случае необходима независимая NFSv3 файловая шара для размещения Quorum Witness.
С точки зрения администратора виртуального кластера, StoreVirtual VSA представляет собой виртуальные машины под управлением Enterprise Linux, по одной на каждый узел кластера. Установка может быть произведена как через специальный визард, так и путем развертывания OVF-образа. В обоих случаях вам необходимо будет сконфигурировать диск создаваемой виртуальной машины. Размер виртуального диска будет зависеть от размера блока, указанного при форматировании datastore.
Как и любое ПО, StoreVirtual VSA требуются вычислительные ресурсы процессора и оперативной памяти, и для разработки нового решения (или для проверки совместимости с имеющимся кластером) HPE выработали ряд рекомендаций:
| StoreVirtual VSA capacity (total of all storage devices) | Memory required (GB) not using Adaptive Optimization or Space Reclamation | Memory required (GB) when using Adaptive Optimization and/or Space Reclamation |
|---|---|---|
| <= 1 TB | 4 | 4 |
| 1 — <= 4 TB | 5 | 5 |
| 4 — <= 10 TB | 7 | 8 |
| 10 — <= 20 TB | 9 | 12 |
| 20 — <= 30 TB | 12 | 17 |
| 30 — <= 40 TB | 15 | 21 |
| 40 — <= 50 TB | 18 | 26 |
Лицензируется данный продукт по объему, который мы презентуем гипервизору в качестве datastore. Важно понимать, что это будет «сырой» объем с точки зрения конечного пользователя. В первую очередь локальные диски ваших серверов будут объединены в RAID-группы на уровне RAID-контроллера узла. Получившийся полезный объем и будет лицензироваться. После запуска каждой отдельной VSA они объединяются в кластер и суммируют дисковое пространство в один общий пул, доступный потом пользователям (серверам) по блочному протоколу (iSCSI).
Возможности
В наше время недостаточно просто предоставить некую емкость для хранения данных. Система хранения должна обладать возможностями по защите данных от сбоев, оптимизацией хранения, управления и обработки, и StoreVirtual VSA может предложить нам все основные функции, которые присутствуют у аппаратных систем хранения:
• Thin provisioning — «тонкие» тома, позволяющие системе выделять пространство по мере фактического наполнения данными;
• Peer Motion — миграция томов без прерывания доступа к ним;
• Multi-site SAN — распределенный по двум или трем площадкам единый том;
• Синхронная и асинхронная репликации;
• Создание консистентных снэпшотов на уровне приложений;
• Network RAID — построение отказоустойчивых схем на уровне узлов кластера;
• Split Site — создание географически разнесенных кластеров;
• Adaptive Optimization — двухуровневый автоматический тиринг с гранулярностью 256 KB.
Управление всеми функциями доступно как через CMC (Centralized Management Console), так и через плагин для консолей управления VMWare/Hyper-V.
На мой взгляд, наиболее интересной опцией будет являться Network RAID, защищающий данные от потери в случае выхода из строя целого узла кластера. По сути, это синхронная репликация между узлами, а уровень RAID регулирует количество копий блоков данных, хранящихся в кластере.

К примеру, в случае с уровнем Network RAID level 10, рекомендованный производителем как самый оптимальный, в кластере всегда будут храниться 2 копии каждого блока данных. Такая схема резервирования дает нам гарантированную защиту от потери данных в случае выхода из строя 1-го узла кластера (а при особой удаче — до половины узлов), однако оверхед будет составлять 1/2. Это означает, что при покупке лицензии на StoreVirtual VSA 2 Тб, мы получим виртуальное хранилище на 1 Тб полезной емкости.
Следующий уровень защиты — Network RAID level 10+1. В этом случае в кластере хранится 3 копии каждого блока данных. Допустимый уровень «потерь» — 2 узла. Оверхед будет составлять 1/3. Именно алгоритм резервирования Network RAID 10+1 лежит в основе технологии SplitSite, позволяя создавать кластер на 3х географически разнесенных площадках. Самое примечательное в этой технологии то, что в отличие от классической репликации аппаратных СХД у нас отсутствуют такие понятия как основная и второстепенная площадки. Приложению не важно на которой из площадок в данный момент располагается обрабатываемый блок, а в случае выхода из строя узла и обращения к дублирующему блоку на другой площадке, приложение не замечает разницы и, как следствие, отсутствует время простоя. С другой стороны, это накладывает жесткие требования на канал, соединяющий площадки между собой. Задержка в передаче данных, round trip, не должна превышать 5 мс.
Уровень Network RAID level 10+2 создает копии блоков на всех узлах кластера, что позволяет нам потерять n-1 узлов, но при этом оврехед будет равняться 1/n (где n — количество узлов в кластере). При этом минимально поддерживаемая конфигурация — от 3-х узлов, что на мой взгляд является чрезмерным и не применимо в реальных архитектурах.
По аналогии с аппаратными рейдами имеются уровни резервирования с контрольными суммами: Network RAID level 5 и 6. В этих архитектурах появляются блоки с контрольными суммами, которые равномерно распределены по всем узлам кластера. Такая схема резервирования является наиболее экономичной с точки зрения оверхеда (n-1 для level 5 и n-2 для level 6), а уровень отказоустойчивости равен level 10 и level 10+1 соответственно. Однако, необходимость считать контрольные суммы вызывают ощутимое снижение вычислительной производительности всего кластера, в следствие чего не рекомендуются для применения с высоконагруженными приложениями (самый явный пример — базы данных).
Позиционирование
Продукт StoreVirtual VSA входит в семейство решений гиперконвергентных систем. И, как и любая другая софтверная составляющая гиперконвергентных решений, является бюджетным аналогом своего аппаратного оригинала — выделенной СХД. В моем понимании основная задача данного продукта — создание отказоустойчивого защищенного хранилища для вашего виртуализированного кластера без покупки дополнительного оборудования. При этом не стоит недооценивать функционал Network RAID, позволяющий реализовывать синхронную репликацию между узлами кластера, в том числе и географически разнесенных.
Как можно увидеть из описанного мной функционала, данное решение можно назвать функционально самостоятельным, дающим своим пользователям возможности аппаратного хранилища начального уровня за более скромные деньги.
В заключение стоит отметить, что на текущий момент действует промо-программа: при покупке любого сервера HPE Proliant Gen9 вы получаете лицензию StoreVirtual VSA на 1 Тб бесплатно. Это является прекрасным поводом не только скачать триальные лицензии для детального изучения продукта, но и начать внедрять его в продуктив новых проектов без увеличения их бюджета.
Комментарии (19)

ximik13
24.08.2016 16:00+3В настоящее время все больше вендоров пробуют выпускать свои вариации на тему SDS. Естественно в каждом решении есть свои нюансы и интересные подходы и технологии.
Интересно бы увидеть более подробные TTX данного решения и рекомендации.
1) Максимальное число узлов в кластере?
2) Максимальный размер блочного тома, отдаваемого гипервизору? И общий максимальный поддерживаемый объем в рамках кластера (полезный или raw)?
3) Какие протоколы используются для того что бы подмапить блочный том гипервизору? Что-то кроме iSCSI поддерживается?
4) Как пробрасывается физический том с RAID контроллера в виртуальную ноду кластера?
5) Есть или нет условно бесплатная версия для тестов без покупки сервера HP?
6) Какая пропускная способность сети требуется\рекомендуется для кластера? Для Multi-site SAN?
7) Как работает тиринг? Вернее даже каким образом определяются блочные тома в конкретные тиры?
8) При помощи чего реализуется "Создание консистентных снэпшотов на уровне приложений"? И какие приложения поддерживаются?
9) Как кластер реагирует навременноеисчезновение Quorum Witness виртуалки или шары?
10) Каким образом проводится обновление данного решения? Узлы обновляются поочередно? С перезагрузкой? При перезагрузке ноды на начинается перестроения Network RAID?
andrijn
25.08.2016 09:391) Рекомендуется до 16 узлов на кластер в StoreVirtual VSA, до 32 узлов на кластер в аппаратных StoreVirtual 3200/4000. Для 1TB/4TB лицензий есть лимит в 3 узла на кластер. Лимит снимается после миграции на лицензию с объемом в 10TB и более.
2) 128TiB.
3) В StoreVirtual VSA поддерживается только iSCSI, в StoreVirtual 3200/4000 еще есть поддержка FC 8Gb/16Gb. Добавить поддержку CIFS (SMB3.1), NFS, HTTP & FTP возможно с помощью HPE StoreEasy 3830 Gateway Storage.
4) Через VMFS или RDM для VMware vSphere, также поддерживается разворачивание в средах Microsoft Hyper-V и KVM.
5) Есть тестовая лицензия без технических ограничений на 60 дней — http://h20392.www2.hpe.com/portal/swdepot/displayProductInfo.do?productNumber=StoreVirtualSW (нужна регистрация). Нужны следующие файлы:
— HPE StoreVirtual Centralized Management Console for Windows/Linux
— HPE StoreVirtual VSA 2014 for vSphere
— HPE StoreVirtual Multipathing Extension Module for Vmware
— HPE StoreVirtual VSA Installation and Configuration Guide
— HPE StoreVirtual Storage User Guide
— HPE StoreVirtual Multipathing User Guide
6) Для кластера/Multi-site требуется 1Gb/s, рекомендуется 10Gb/s.
7) Работает в реальном времени блоками 256 KB
8) Консистетнтные для VMware and Hyper-V VMs и Microsoft VSS
9) Давно проверяли с заказчиком на P4500 G2 Multi-Site — без происшествий.
10) С практики обновляется гладко. Узлы обновляются поочередно с перезагрузкой сервисов, без перестройки массива данных.
kuzz
25.08.2016 09:44Благодарю за оперативный ответ :)
Хочу добавить относительно StoreVirtual 3200 — продукт тоже крайне интерессный в плане переноса архитектуры SDS на аппаратную платформу. Коллеги обещали привезти его мне в демо до конца года. Как только получу на руки, то сразу напишу аналогичный обзор.andrijn
25.08.2016 17:53Пока уступает в цене MSA 1040 на аналогичных конфигурациях.
Очень мало даных по производительности.
ximik13
25.08.2016 09:52По 2-му 128TiB это размер чего? Или это ответ сразу на оба вопроса из второго пункта?
По 9-тому так и не понял как обеспецивается консистентность? В гипервизор ставится програмный агент? Если нет, то не вижу каким способом СХД сообщает OS или гипервизору на сервере о том что сейчас будет сделан снэпшот и нужно синхронизировать все буферы и кэши на диски.
andrijn
25.08.2016 17:51128TiB — это для одного LUN, лимитов для кластера не нахожу.
ximik13, все всерно, для сбрасывания «грязного» кэша используется агент под названием Application Aware Snapshot Manager:
— To use the Application Aware Snapshot Manager in VMware environments, the vSphere servers must be managed by VMware vCenter. The Application Aware Snapshot Manager must be installed on the vCenter server that manages all other vSphere servers connected to the StoreVirtual OS volumes.
— The Application Aware Snapshot Manager uses the VSS Provider to create an application-quiesced snapshot on the HP StoreVirtual SAN. The VSS Provider is the StoreVirtual plug-in for the Microsoft VSS (Volume Shadow Copy Service) framework.kuzz
26.08.2016 09:56128TiB — это для одного LUN, лимитов для кластера не нахожу.
Не совсем согласен с вашим ответом.
Как таковых ограничений на размер тома нет. Есть лиценизонное ограние 50Тб на узел, в кластер собирается до 16 узлов, что на входе дает 800 Тб полезной емкости (до объединения в Network RAID).
kuzz
26.08.2016 09:598) Консистетнтные для VMware and Hyper-V VMs и Microsoft VSS
Подробнее: в общем виде используется ПО Application Aware Snapshot Manager, которое ставится на внешний хост и управляет процессом создания консистентных снэпшотов (вернее его координирует, т.к. создание снэпшотов доступно и из консоли самой VSA). Поддерживаются ОС Windows Server 2012, Windows Server 2012 R2, Windows Server 2012 R2 Core, Windows Server 2008, 32-bit и 64-bit versions, vSphere (5.0, 5.1, 5.5 и 6.0). Перед созданием аппаратного снэпшота производятся необходимые действия по остановке (заморозке, снэпшоту) приложения (файловой системы).
7) (Тиринг) Работает в реальном времени блоками 256 KB
Чуть более подробно: можно определить два тира – 0 и 1. При подключении дискового пространства (датастора) в виртуальной машине VSA можно определить тип тира. По умолчанию все логические тома создаваемые внутри кластера используют оба тира. Все новые блоки всегда пишуться на тир 0 (пока там есть место), потом, по мере его заполнения, блоки начинают пистаться на тир 1. Все это время ведется т.н. heat map (карта горячих и холодных блоков на основе частоты обращений к них). Как только какие-то блоки становятся кандидатоми на миграцию, начинается миграция таких блоков. Для этого определяется равное кол-во холодных и горячих блоков и они перемещаются. Минимальный блок для миграции 256 КБ, общее кол-во таких блоков определяется динамически исходя из степени загрузки системы.
DonAlPAtino
25.08.2016 12:06«Именно алгоритм резервирования Network RAID 10+1 лежит в основе технологии SplitSite, позволяя создавать кластер на 3х географически разнесенных площадках...» А как себя поведет вся эта красота при падении каналов между датацентрами? Не знаю как в «у вас», а вот у нас падение каналов (или флаппинг, или резко пропавший в «неизвестном» направлении ipsec) происходит значительно чаще чем падение серверов или хранилищ.
kuzz
26.08.2016 10:01Сценарий будет идентичным как и при падении узла. Система перейдет в статус Degrade, начнут сыпаться алерты, но кластер продолжит работу на базе доступного для приложения датацентра.
DonAlPAtino
26.08.2016 15:48А если само приложение точно так же кластеризировано и разнесено по ЦОД. Мы ведь получим в результате ситуацию когда везде ничего не будет работать во избежании split-brain'а?
kuzz
29.08.2016 13:53В случае с разнесенным по ЦОДам приложением у нас всегда поулчается схема active-standby. Правильная настройка «Quorum Witness + активный узел кластера приложений» позволит избежать split-brain. Разница с другими аналогичными архитектурами в том, что в отличии от схемы active-standby, у нас не будет переключения на уровне системы хранения.
SemperFi
Добрый день.
не совсем понятен момент:
в моей терминологии «сырой» объем — это объем, получаемый путем сложения всех объемов всех дисков, а тут, видимо, это утверждение не совсем верно?
kuzz
В данном случае возникает два уровня RAID:
1. Аппаратный, собираемый на RAID-контроллерах серверов (узлов) до загрузки ОС. Полученный объем и лицензиурется.
2. Софтовый, собираемый в Network RAID на базе тех томов, которые мы создали на первом уровне. Для конечного пользователя (администратора\менеджера виртуального кластера) именно этот объем будет «полезным», т.е. пригодным для использования.
SemperFi
спасибо, так понятно
athacker
А собирать аппаратный RAID — это обязательное условие? Или можно презентовать JBOD, и данный продукт сам соберёт из них отказоустойчивую конфигурацию?
Просто ScaleIO, например, принимает пачку дисков, и совсем не обязательно собирать из них RAID на железе. Это даёт бОльшую гибкость в манипуляциях с дисками — их можно выкидывать и менять на диски бОльшего объёма, например, без остановки узла и пересборки аппаратного массива. Если же у вас аппаратный RAID, то это сделать будет малость затруднительно, как минимум потребуется поддержка такой операции RAID-контроллером (online capacity extension, OCE), а такое умеют не все контроллеры.
kuzz
Для VSA нет обязательного условия иметь аппаратный RAID, т.к. ему через гипервизор презентуется дисковая емкость — в виде сырых дисков или раздела на vmfs datastore (виртуальный диск). Пользователь сам решает, что ему важнее – надежность или гибкость. Надо понимать, что при выходе из строя даже одного диска, без наличия аппаратного RAID, весь узел кластера (целая VSA) остановится. А если есть RAID, то узел продолжит работать.
athacker
Именно это и означает, что аппаратный RAID всё же обязателен :-)