
В этой статье мы поговорим о написании хорошего кода и о проблемах, с которыми мы при этом сталкиваемся. Понятный, декларативный, компонуемый и тестируемый — эти термины употребляются, когда речь заходит о написании хорошего кода. Решением проблем часто называют чистые функции. Но написание веб-приложений, в основном, связано с побочными эффектами и сложными асинхронными потоками операций, концепциями, которые по своей сути не являются чистыми. Ниже описан подход, который позволяет охватывать работу с побочными эффектами и сложными асинхронными потоками, сохраняя преимущества чистых функций.
Написание хорошего кода
Чистые функции — Святой Грааль в написании хорошего кода. Чистая функция — это функция, которая при одинаковых аргументах всегда возвращает одни и те же значения и не имеет видимых побочных эффектов.
function add(numA, numB) {
return numA + numB
}Полезным свойством чистых функций является то, что их легко тестировать.
test.equals(add(2, 2), 4)Компонуемость тоже является их сильной стороной.
test.equals(multiply(add(4, 4), 2), 16)К тому же их очень легко использовать декларативно.
const totalPoints = users
.map(takePoints)
.reduce(sum, 0)Но давайте взглянем на ваше приложение. Какая его часть действительно может быть выражена чистыми функциями? Насколько часто речь идёт о преобразовании значений, которые традиционно выполняют чистые функции? Могу предположить, что большая часть вашего кода работает с побочными эффектами. Вы выполняете сетевые запросы, DOM манипуляции, используете вебсокеты, локальные хранилища, изменяете состояние приложения и так далее. Это всё описывает разработку приложения, по крайней мере в Интернете.
Побочные эффекты
Как правило, мы говорим про побочные эффекты, в подобном случае:
function getUsers() {
return axios.get('/users')
.then(response => ({users: response.data}))
}Функция getUsers указывает на что-то "вне себя" — axios. Возвращаемое значение не всегда совпадает, так как это ответ сервера. Тем не менее, мы все еще можем использовать эту функцию декларативно и компоновать её во множестве различных цепочках:
doSomething()
.then(getUsers)
.then(doSomethingElse)Но тестирование будет даваться нам с трудом, так как axios находится вне нашего контроля. Перепишем функцию, чтобы она принимала axios в качестве аргумента:
function getUsers(axios) {
return axios.get('/users')
.then(response => ({users: response.data}))
}Теперь её легко протестировать:
const users = ['userA', 'userB']
const axiosMock = Promise.resolve({data: users})
getUsers(axiosMock).then(result => {
assert.deepEqual(result, {users: users})
})Но у нас будут проблемы компоновки функции в различные цепочки, так как axios должен быть явно передан на вход.
doSomething() // Должен вернуть axios
.then(getUsers) // чтобы передать сюда
.then(doSomethingElse)Функции, работающие с побочными эффектами на самом деле являются проблематичными.
Популярный совет в проектах наподобие Elm, Cycle, и реализациях в redux (redux-loop): "сдвигайте побочные эффекты к краю вашего приложения". В основном это означает, что бизнес-логика вашего приложения хранится чистой. Всякий раз, когда вам необходимо произвести побочный эффект, вы должны отделить его. Проблемой этого подхода, вероятно, является то, что это не помогает улучшить читаемость. Вы не можете выразить целостно сложный поток операций. Ваше приложение будет иметь несколько несвязанных циклов, скрывающих отношения одного побочного эффекта, которое может стать причиной другого побочного эффекта и так далее. Это не имеет значения для простых приложений, потому что вы редко имеете дело с более чем одним дополнительным циклом. Но в больших приложениях, в конечном итоге, вы столкнётесь с большим количеством циклов, и вам будет трудно понять как они соотносятся друг с другом.
Позвольте мне объяснить это более подробно на примерах.
Типичный поток приложения
Допустим, у вас есть приложение. Когда оно начало работу, вы хотите получить данные о пользователе, чтобы проверить, вошёл пользователь в систему или нет. Затем вы хотите получить список заданий. Они связаны с другими пользователями. Поэтому, на основании полученного списка заданий, вам надо динамически получить информацию и о этих пользователях тоже. Что же мы будем делать чтобы описать этот поток действий в понятном, декларативном, компонуемом и тестируемом виде?
Рассмотрим на примере простой реализации, используя redux:
function loadData() {
return (dispatch, getState) => {
dispatch({
type: AUTHENTICATING
})
axios.get('/user')
.then((response) => {
if (response.data) {
dispatch({
type: AUTHENTICATION_SUCCESS,
user: response.data
})
dispatch({
type: ASSIGNMENTS_LOADING
})
return axios.get('/assignments')
.then((response) => {
dispatch({
type: ASSIGNMENTS_LOADED_SUCCESS,
assignments: response.data
})
const missingUsers = response.data.reduce((currentMissingUsers, assignment) => {
if (!getState().users[assigment.userId]) {
return currentMissingUsers.concat(assignment.userId)
}
return currentMissingUsers
}, [])
dispatch({
type: USERS_LOADING,
users: users
})
return Promise.all(
missingUsers.map((userId) => {
return axios.get('/users/' + userId)
})
)
.then((responses) => {
const users = responses.map(response => response.data)
dispatch({
type: USERS_LOADED,
users: users
})
})
})
.catch((error) => {
dispatch({
type: ASSIGNMENTS_LOADED_ERROR,
error: error.response.data
})
})
} else {
dispatch({
type: AUTHENTICATION_ERROR
})
}
})
.catch(() => {
dispatch({
type: LOAD_DATA_ERROR
})
})
}
}Здесь просто всё неправильно. Этот код непонятен, недекларативен, некомпонуем и нетестируем. Однако есть одно преимущество. Всё что происходит при вызове функции loadData определено так как оно выполняется, упорядоченно и в одном файле.
Если мы отделим побочные эффекты "на край приложения", это будет выглядеть больше как демонстрация некоторых частей потока:
function loadData() {
return (dispatch, getState) => {
dispatch({
type: AUTHENTICATING_LOAD_DATA
})
}
}
function loadDataAuthenticated() {
return (dispatch, getState) {
axios.get('/user')
.then((response) => {
if (response.data) {
dispatch({
type: AUTHENTICATION_SUCCESS,
user: response.data
})
} else {
dispatch({
type: AUTHENTICATION_ERROR
})
}
})
}
}
function getAssignments() {
return (dispatch, getState) {
dispatch({
type: ASSIGNMENTS_LOADING
})
axios.get('/assignments')
.then((response) => {
dispatch({
type: ASSIGNMENTS_LOADED_SUCCESS,
assignments: response.data
})
})
.catch((error) => {
dispatch({
type: ASSIGNMENTS_LOADED_ERROR,
error: error.response.data
})
})
}
}Каждая часть читается лучше, чем в предыдущем примере. И их легче компоновать в другие цепочки. Однако, проблемой становится разрозненность. Трудно понять, как эти части связаны друг с другом, потому что вы не можете видеть какие функции приводят к вызову другой функции. Перемещаясь между файлами, мы вынуждены воссоздавать в своей голове как отправка (dispatch) одного действия (action) порождает побочный эффект, который вызывает отправку нового действия, порождающего другой побочный эффект, который, в свою очередь, снова приводит к отправке нового действия.
Вынося побочные эффекты к краю вашего приложения, вы действительно получаете преимущества. Но это также оказывает негативное влияние: становится сложнее рассуждать о потоке. Об этом, конечно, можно и даже нужно поспорить. Надеюсь, я смог донести свою точку зрения через примеры и рассуждения выше.
На пути к декларативности
Представим, что мы можем описать этот поток следующим образом:
[
dispatch(AUTHENTICATING),
authenticateUser, {
error: [
dispatch(AUTHENTICATED_ERROR)
],
success: [
dispatch(AUTHENTICATED_SUCCESS),
dispatch(ASSIGNMENTS_LOADING),
getAssignments, {
error: [
dispatch(ASSIGNMENTS_LOADED_ERROR)
],
success: [
dispatch(ASSIGNMENTS_LOADED_SUCCESS),
dispatch(MISSING_USERS_LOADING),
getMissingUsers, {
error: [
dispatch(MISSING_USERS_LOADED_ERROR)
],
success: [
dispatch(MISSING_USERS_LOADED_SUCCESS)
]
}
]
}
]
}
]Обратите внимание на то, что это валидный код, который мы сейчас разберём более подробно. А также, что мы не используем здесь какие-либо магические API, это просто массивы, объекты и функции. Но самое главное, мы в полной мере воспользовались декларативной формой записи кода, чтобы создать согласованное и читаемое описание сложного потока приложения.
Function Tree
Мы только что определили (задекларировали) дерево функции (function tree). Как я уже упоминал, мы не использовали никаких специальных API чтобы определить его. Это всего лишь функции определённые в дереве..., в дереве функции. Любая из функций, используемых здесь, а также фабрики функций (dispatch) могут быть повторно использованы в любом другом определении дерева. Это показывает простоту композиции. Не только каждая функция может состоять в других деревьях. Вы можете включать целые деревья в другие деревья, что делает их особенно интересными с точки зрения композиции.
[
dispatch(AUTHENTICATING),
authenticateUser, {
error: [
dispatch(AUTHENTICATED_ERROR)
],
success: [
dispatch(AUTHENTICATED_SUCCESS),
...getAssignments
]
}
]В этом примере мы создали новое дерево getAssignments, которое также является массивом. Мы можем компоновать одни деревья в другие, используя оператор разворачивания (spread operator).
Давайте посмотрим как работают деревья функций, прежде чем перейти к тестируемости. Давайте его запустим!
Выполнение дерева функций
Сжатый пример того, как запустить дерево функцию выглядит следующим образом:
import FunctionTree from 'function-tree'
const execute = new FunctionTree()
function foo() {}
execute([
foo
])Созданный экземпляр FunctionTree является функцией, которая позволяет вам выполнять деревья. В приведенном выше примере будет выполнена функция foo. Если мы добавим больше функций, они будут выполнены по порядку:
function foo() {
// Сначала я
}
function bar() {
// Потом я
}
execute([
foo,
bar
])Асинхронность
function-tree умеет работать с обещаниями (promises). Когда функция возвращает обещание, или вы определяете функцию как асинхронную, используя ключевое слово async, функция исполнения (execute) дождётся пока обещание не будет выполнено (resolve) или отклонено (reject) прежде чем двигаться дальше.
function foo() {
return new Promise(resolve => {
setTimeout(resolve, 1000)
})
}
function bar() {
// Я запущусь через 1 секунду
}
execute([
foo,
bar
])Зачастую асинхронный код имеет более разнообразные результаты. Исследуем контекст дерева функции для того, чтобы понять, как можно декларативно определять эти результаты.
Контекст
Все функции выполняемые с помощью function-tree принимают один аргумент. context — это единственный аргумент с которым должны работать функции определённые в дереве. По умолчанию контекст имеет два свойства: input и path.
Свойство input содержит полезную нагрузку (payload), переданную при запуске дерева.
// Мы используем деструктурирование аргумента
function foo({input}) {
input.foo // "bar"
}
execute([
foo
], {
foo: 'bar'
})Когда функция хочет передать новую полезную нагрузку вниз по дереву ей нужно будет возвращать объект, который будет объединен с текущей полезной нагрузкой.
function foo({input}) {
input.foo // "bar"
return {
foo2: 'bar2'
}
}
function bar({input}) {
input.foo // "bar"
input.foo2 // "bar2"
}
execute([
foo
], {
foo: 'bar'
})Не имеет значения, синхронная функция или асинхронная, надо просто вернуть объект или выполненное обещание с объектом.
// Синхронный
function foo() {
return {
foo: 'bar'
}
}
// Асинхронный
function foo() {
return new Promise(resolve => {
resolve({
foo: 'bar'
})
})
}Перейдём к изучению механизма выбора путей для выполнения.
Пути
Результат, возвращаемый из функции, может определить дальнейший путь выполнения в дереве. Благодаря статическому анализу, свойство path контекста уже знает по каким путям возможно продолжение выполнения. Это означает, что доступны только пути выполнения, которые определены в дереве.
function foo({path}) {
return path.pathA()
}
function bar() {
// Я сработаю
}
execute([
foo, {
pathA: [
bar
],
pathB: []
}
])Вы можете передать полезную нагрузку, передавая объект к методу пути.
function foo({path}) {
return path.pathA({foo: 'foo'})
}
function bar({input}) {
console.log(input.foo) // 'foo'
}
execute([
foo, {
pathA: [
bar
],
pathB: []
}
])Чем же хорош механизм путей? Прежде всего, он носит декларативный характер. Здесь нет выражений if или switch. Это повышает удобочитаемость.
Гораздо важнее то, что пути не имееют дела с "выбрасыванием" (throw) ошибок. Часто потоки мыслятся как: "сделай это или бросай всё, если произойдёт ошибка". Но не в случае с веб-приложениями. Есть много причин, почему вы решите пойти вниз по различным путям выполнения. Решение может быть основано на роли пользователя, возвращаемом ответе сервера, некотором состоянии приложения, переданном значении и так далее. Дело в том, что function-tree не отлавливает ошибки, не делает всплытия ошибок и тому подобных техник. Оно просто выполняет функции и позволяет им возвращать пути там, где исполнение должно расходиться.
Есть ещё несколько небольших скрытых особенностей. Например, вы можете определить дерево функции без реализации чего-либо. Это означает, что все возможные пути выполнения определены заранее. Это заставляет вас думать о том, какие случаи надо обработать. И значительно снижает вероятность, что вы проигнорируете или забудете о сценариях, которые могут произойти.
Провайдеры
На одних только input и path сложное приложение не построить. Поэтому function-tree построен на концепции провайдеров. На самом деле input и path тоже провайдеры. В комплекте c function-tree поставляется несколько готовых. И конечно же вы можете сами их создавать. Предположим вы хотите использовать Redux:
import FunctionTree from 'function-tree'
import ReduxProvider from 'function-tree/providers/Redux'
import store from './store'
const execute = new FunctionTree([
ReduxProvider(store)
])
export default executeТеперь у вас есть доступ к методам dispatch и getState в ваших функциях:
function doSomething({dispatch, getState}) {
dispatch({
type: SOME_CONSTANT
})
getState() // {}
}Вы можете добавить любые другие инструменты используя ContextProvider:
import FunctionTree from 'function-tree'
import ReduxProvider from 'function-tree/providers/Redux'
import ContextProvider from 'function-tree/providers/Context'
import axios from 'axios'
import store from './store'
const execute = new FunctionTree([
ReduxProvider(store),
ContextProvider({
axios
})
])
export default executeСкорее всего вы захотите использовать DebuggerProvider. В сочетании с расширением для Google Chrome вы сможете отлаживать вашу текущую работу. Добавим провайдер отладчика к примеру выше:
import FunctionTree from 'function-tree'
import DebuggerProvider from 'function-tree/providers/Debugger'
import ReduxProvider from 'function-tree/providers/Redux'
import ContextProvider from 'function-tree/providers/Context'
import axios from 'axios'
import store from './store'
const execute = new FunctionTree([
DebuggerProvider(),
ReduxProvider(store),
ContextProvider({
axios
})
])
export default executeЭто позволяет видеть всё что происходит при выполнении этих деревьев в вашем приложении. Провайдер отладчика автоматически обернёт и будет отслеживать всё что вы разместите в контексте:
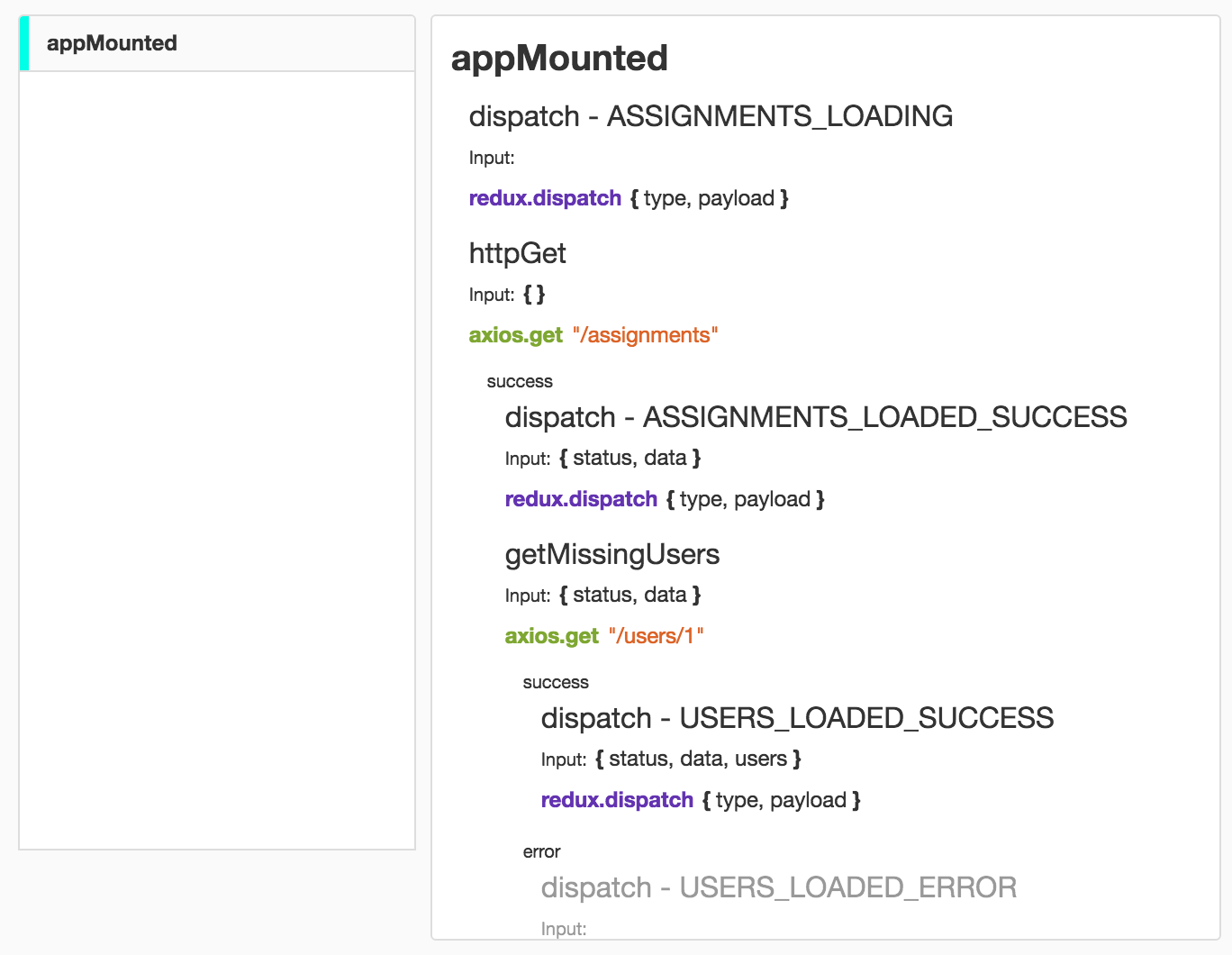
Если же вы решите использовать function-tree на серверной стороне, можете подключить NodeDebuggerProvider:
Тестируемось
Но, скорее всего самое важное, это возможность проверки дерева функции. Как выясняется, это очень легко сделать. Чтобы протестировать отдельные функции в дереве, просто вызывайте их со специально подготовленным контекстом. Рассмотрим тестирование функции создающей побочный эффект:
function setData({window, input}) {
window.app.data = input.result
}const context = {
input: {result: 'foo'},
window: { app: {}}
}
setData(context)
test.deepEqual(context.window, {app: {data: 'foo'}})Тестирование асинхронных функций
Многие библиотеки для тестирования позволяют вам создавать заглушки для глобальных зависимостей. Но нет причин делать это для function-tree, потому что функции используют только то, что доступно через аргумент контекста. Например, следующая функция, использующая axios для получения данных, может быть протестирована следующим образом:
function getData({axios, path}) {
return axios.get('/data')
.then(response => path.success({data: response.data}))
.catch(error => path.error({error: error.response.data}))
}const context = {
axios: {
get: Promise.resolve({
data: {foo: 'bar'}
})
}
}
getData(context)
.then((result) => {
test.equal(result.path, 'success')
test.deepEqual(result.payload, {data: {foo: 'bar'}})
})Тестирование всего дерева
Вот здесь становится ещё интереснее. Мы можем протестировать всё дерево точно так же, как мы тестировали функции отдельно.
Давайте представим простое дерево:
[
getData, {
success: [
setData
],
error: [
setError
]
}
]Эти функции используют axios для получения данных, а затем сохраняют их в свойстве объекта window. Мы протестируем дерево, создав новую функцию выполнения с заглушками для передачи в контекст. Затем мы запускаем дерево и проверяем изменения после окончания выполнения.
const FunctionTree = require('function-tree')
const ContextProvider = require('function-tree/providers/Context')
const loadData = require('../src/trees/loadData')
const context = {
window: {app: {}},
axios: {
get: Promise.resolve({data: {foo: 'bar'}})
}
}
const execute = new FunctionTree([
ContextProvider(context)
])
execute(loadData, () => {
test.deepEquals(context.window, {app: {data: 'foo'}})
})Не имеет значения какие библиотеки вы используете. Вы можете легко тестировать деревья функций, пока вы размещаете библиотеки в контексте дерева.
Фабрики
Так как дерево является функциональным, вы можете создавать фабрики, которые будут ускорять вашу разработку. Вы уже видели использование фабрики dispatch в примере с Redux. Она была объявлена следующим образом:
function dispatchFactory(type) {
function dispatchFunction({input, dispatch}) {
dispatch({
type,
payload: input
})
}
// Свойство `displayName` переопределяет имя функции,
// для отображения в отладчике.
dispatchFunction.displayName = `dispatch - ${type}`
return dispatchFunction
}
export default dispatchFactoryСоздавайте фабрики для вашего приложения, чтобы избегать создания специфичных функций для всего. Предположим вы решите использовать baobab, единое дерево состояния, для хранения состояния вашего приложения.
function setFactory(path, value) {
function set({baobab}) {
baobab.set(path.split('.'), value)
}
return set
}
export default setЭта фабрика позволит вам выражать изменения состояния прямо в дереве:
[
set('foo', 'bar'),
set('admin.isLoading', true)
]Вы можете использовать фабрики, чтобы построить собственный DSL вашего приложения. Некоторые фабрики на столько обобщённые, что мы решили сделать их частью function-tree.
debounce
Фабрика debounce позволяет придержать выполнение на указанное время. Если срабатывают новые исполнения одного и того же дерева, существующее будет уходить по пути discarded. Если за указанное время нет новых срабатываний, последнее пойдёт по пути accepted. Обычно такой поход используется при поиске по мере ввода.
import debounce from 'function-tree/factories/debounce'
export default [
updateSearchQuery,
debounce(500), {
accepted: [
getData, {
success: [
setData,
],
error: [
setError
]
}
],
discarded: []
}
]В чём отличие от Rxjs и цепочек обещаний?
И Rxjs, и Обещания управляют контролем исполнения. Но ни один из них не имеет декларативного условного определения путей исполнения. Вам придётся разносить потоки, писать выражения if и switch или выбрасывать ошибки. В выше приведённых примерах мы смогли разделить пути исполнения success и error также декларативно, как наши функции. Это улучшает читаемость. Но эти пути могут быть абсолютно любыми. Например:
[
withUserRole, {
admin: [],
superuser: [],
user: []
}
]Пути не имеют ничего общего с обработкой ошибок. function-tree позволяет вам выбрать путь на любом шаге исполнения, в отличие от обещаний и Rxjs, где бросание ошибок единственный способ прекратить исполнение текущего пути.
Rxjs и обещания основаны на преобразовании значений. Это значит, что следующей функции доступны только значения переданные как результат выполнения предыдущей. Это отлично работает, когда вам действительно надо преобразовывать значения. Но события в вашем приложении это не тот случай. Они работают с побочными эффектами и проходят по одному или многим путям исполнения. В этом и заключается главное отличие function-tree.
Где можно применять?
function-tree может помочь, если вы создаёте приложение работающее с побочными эффектами в сложных асинхронных цепочках. Преимущества "принудительного" разбиения логики вашего приложения на блоки "lego" и их тестируемости могут быть достаточно весомыми доводами. В основном это позволяет вам писать более читаемый и поддерживаемый код.
Проект доступен в репозитории на Github, а расширение отладчик для Google Chrome может быть найдено в Chrome Web Store. Обязательно посмотрите пример приложения в репозитории.
Первоисточником проекта function-tree можно считать cerebral. Вы можете считать реализацию сигналов в Cerebral абстракцией с собственным представлением над function-tree. В настоящее время Cerebral использует свою собственную реализацию, но в Cerebral 2.0 function-tree будет использоваться в качестве основы для фабрики сигналов. Выражаю благодарность Алексею Guria за переработку и оттачивание идей сигналов Cerebral, что привело к созданию самостоятельного и общего подхода.
Расскажите что вы думаете о данном подходе в комментариях ниже. Поделитесь, если у вас есть ссылки на другие шаблоны и методы решения проблем, обсуждаемых в этой статье. Спасибо за прочтение!
Комментарии (33)

napa3um
19.09.2016 01:13+4Сомнительное увеличение читабельности потока исполнения. Та же «co» выглядит в этом смысле значительно прозрачнее.
Вообще, подобные «решения» (святая война с каллбэками) решают проблему читабельности потока исполнения путём навязывания деления логики приложения на компактные атомистичные функции с ёмкими и понятными названиями, и кроме «красоты» кода ничего дополнительно, по-сути, не дают. Но оказывается, что если разделить логику на атомистичные функции с понятными названиями, то уже и не нужны никакие DSL для их композиции — хватает встроенных возможностей JS.
Guria
19.09.2016 13:55Christian:
it requires a very high level of discipline to uphold that dividing of logic which can be difficult to do in teams. With function-tree you are forced to divide your logic, in a good way. Also "built-in JS" features does not ensure testability, function-tree does because you put all "globals" on the context. And last but not least… you can not have a debugger that understands "built-in JS features"

ReklatsMasters
19.09.2016 02:00+1Оочень спорная статья. Сначала чувак создал один action creator на всё приложение, упростив и засунув туда всю логику. Потом всё же попытался это разделить, но теперь ему опять что то не нравится. Вообще не понятно какую проблему решает автор. Может пример не очень удачный, но я тоже ничего не понял.
Guria
19.09.2016 08:08+1Большой action creator действительно спорная часть статьи. Кристиан пытался показать весь поток при наступлении определённого события. Обычно в redux так не принято. Но в «правильном» redux не будет такого единого места где можно увидеть весь поток со всеми возможными путями, его придётся восстанавливать в голове каждый раз возвращаясь к этому коду.
Если есть идеи как этот поток можно выразить лучше, пожалуйста дайте пример. Возможны мы просто не умеем готовить редакс :)
Guria
19.09.2016 13:14К слову, Кристиан утверждает: «The example was typical for what I have seen in projects. Maybe we should change that example if it is not valid. I can understand if people use like Saga or something similar, but a lot of people do not.»

kahi4
19.09.2016 02:01+2Но тестирование будет даваться нам с трудом, так как axios находится вне нашего контроля. Перепишем функцию, чтобы она принимала axios в качестве аргумента
Откройте для себя sinonjs и будет вам счастье.
Тестировать асинхронный код, подставляя ему axios (window, jquery, что угодно), в действительно сложнее, чем кажется. Проблема в том, что в какой-то момент вы где-то можете начать передавать заголовки, вызывать каким-то нестандартным способом по той или иной причине (конкретно для axios — может понадобится создать экземпляр-наследник), таким образом в своих тестах вы перепишите половину функционала этого самого axios. С тем же sinon все становится гораздо проще, главное — не запутаться когда что ответить.
Вдобавок, в какой-то момент вы начнете тянуть достаточно большой контекст, например, вам понадобится тестировать по stab'ам, фикстурам, мокапам, окажется, что проверять нужно на конкретный момент времени, тогда придется тянуть Date и так далее.
Мало того, что вы вроде как выровняли и украсили свой код, сделав его полностью чистым, а на практике передвинули проблемы из угла в другой угол, так все еще начинает жутко тормозить: даже нативные функции пробрасываете через контексты, постоянно вызваете Object.assign, таскаете огромные хеш-таблицы (объекты) данных (к слову, оно не течет ли часом?), а потом удивляетесь, что это у меня хром отожрал 5 гб памяти на 3 вкладки и вините DOM в его тормознутости, когда без него хватает чему работать нерасторопно.
Хотя идея неплохая, присмотреться стоит.
Guria
19.09.2016 08:24Вы правы. Примеры в статье, к сожалению, немного гипертрофированы. В реальном приложении я бы обернул ajax запросы в сервис с понятными методами. Это позволит тестировать экшены предоставив мок сервис в контекст в тестовой среде.
Боевой же сервис (который и будет устанавливать нестандартнык заголовки) скорее надо тестировать с помощью интерсептеров.
По производительности, возможно, не самое лучшее решение. Однако обработка управления потока на клик пользователя врядли будет узким местом приложения.
А вот по опыту cerebral мы получаем множество положительных отзывов о итоговой читаемости. О том как легко становиться понимать приложение в целом. В итоге некоторое даже стали пытаться использовать cerebral в nodejs, например, для работы с firebase и т.п.

Klimashkin
19.09.2016 08:39Guria
19.09.2016 08:44Мы знаем про redux-saga. Возможно стоило добавить его к сравнению в статье. Однако внимательный читатель встретит аргументы касательно методов используемых в саге. Хотелось бы более развёрнутого комментария.
Klimashkin
20.09.2016 00:15+1В целом подход function-tree очень интересный — простое описание что отчего зависит здорово ускоряет разработку.
Но мне кажется декларативный подход ограничен, он обычно упирается в какой-нибудь сложный кейс, и чтобы его решить приходится вносить обработку такого кейса в библиотеку либо серьезно костылить в приложении. В мире реакта это нам регулярно демонстрирует react-router.
Тем более в мире data-flow. В сложном приложении двумя результатами не обойтись (success и error), нужна еще как минимум отмена, причем с выбором как отмена должна влиять на родительские процессы или на параллельные. Все это универсально в декларативном стиле не опишешь, всегда будет конкретный кейс который выбьется из возможностей библиотеки.
Плюс саги как раз в том что можно классически (императивно) описывать поток какой-либо функциональности (так же как она выполняется, упорядоченно и в одном файле) с наличием if, ловлей ошибок, отменами, каналами и тд.
В статье вы приводите аргументы чем function-tree лучше цепочек обещаний. Но саги это не цепочки обещаний. Они основаны на генераторах, а что в них класть — обещания или что-то еще это уже второй вопрос. Природа генераторов позволяет описывать поток «плоско»(как async/await) и так же отлично решает вопрос с тестированием без мокирования сайд-эффектов.
Мне понравилась реализация и плюшки function-tree, но саги, думаю, более гибкие


arvitaly
19.09.2016 16:19> Но тестирование будет даваться нам с трудом, так как axios находится вне нашего контроля.
Почему оно должно быть с трудом? Все unit-тесты основаны на mock-объектах, не важно, где и как их подменять. Главное, чтобы такая возможность была. В NodeJS, например, она уже есть из коробки в виде модулей и require.
> Однако есть одно преимущество.
> Всё что происходит при вызове функции loadData определено так как оно выполняется, упорядоченно и в одном файле.
Создайте папку.
> Трудно понять, как эти части связаны друг с другом, потому что вы не можете видеть какие функции приводят к вызову другой функции.
Создайте части по отдельности, а их композицию опишите в одном месте.
>Все функции выполняемые с помощью function-tree принимают один аргумент. context
Т.е. god-object или service-locator, оба антипаттерны.
> Вы можете передать полезную нагрузку, передавая объект к методу пути.
Goto метки, проходили.
> Многие библиотеки для тестирования позволяют вам создавать заглушки для глобальных зависимостей. Но нет причин делать это для function-tree, потому что функции используют только то, что доступно через аргумент контекста.
И не просто так, DI через конструктор хорош, но зачастую избыточен. А уж тем более, Service Locator.
> И Rxjs, и Обещания управляют контролем исполнения. Но ни один из них не имеет декларативного условного определения путей исполнения. Вам придётся разносить потоки, писать выражения if и switch или выбрасывать ошибки.
Это все делается, чтобы не придумывать названия меткам goto. И чтобы не создавать вручную бесконечные нечитаемые деревья.
А в целом, не нравится JS, ну не пишите на нем, зачем придумывать свой DSL поверх него? Проще транслятор написать или использовать тысячи имеющихся.Guria
19.09.2016 21:57Christian:
- Also Sinon was mentioned as a mocking tool. I can see the point, but personally I think it is better to mock arguments than global dependencies. Cause you do not need a mocking tool, you just mock the context as any argument to a normal function
- I do not agree that a folder with files gives the same readability as one file where you see the order of functions execution. Maybe a misunderstanding?
- With Elm/Redux-loop/Cyclejs you can not compose them in one place. The reason being that a state change is what returns a new side effect. Which means that for every side effect that causes a state change you have to return a new side effect. This can not be composed in one file as you define state changes one place and side effects an other place
- Yeah, this is totally true in general. But this context is created for each function tree. It is no more god-like than creating a class where the context is "this", in my opinion
- As I understand GOTO labels can jump wherever in the code. Function tree is stricter in that regard, it is not about "jumping", it is about choosing "the next possible step"
- I would argue that using mocking tools to mock global deps is not better than mocking an argument to a function. Mostly because most tools we mock returns promises, which means you do not need to mock the tool itself, you just mock the promise
- Decoupling is exactly what reduces readability. You need somewhere to compose it all together so you do not have to build up the mental image of how it runs. If the tree is endless I agree, but I have never met an endless tree I have met a lot of decoupled code that has been hard to compose a mental image of though
Have to say thanks for great comments if you have a chance But I think maybe one thing that goes missing a bit here is that you can achieve all the traits of what function-tree tries to give you with discipline. But that is very hard to achieve in code in general and especially in teams. Function-tree just helps you achieve these attributes that produces readable code. And to boot it is able to visualize your code in a way that is not possible with plain JS, using its debugger.
But yeah, great commentsПрошу прощения, что без перевода. Но лучше так, чем оставлять без ответа.
arvitaly
20.09.2016 16:341. Что такое глобальные зависимости? Я вот знаю в браузере window с детками и в NodeJS global, ну можно еще process и console. Для всего остальное существуют модули, импорты и экспорты, хоть requirejs с commonjs, хоть ES-modules, хоть AMD.
Если не нравится слово mock, есть другое слово DI через импорт модуля. Нужно это уже осознать, и не беспокоиться, что JS — не Java и не Haskell, что в JS принято считать единицей — модуль, а не класс или функцию.
2. Здесь, видимо, переводчик халтурит, я не говорил, что композицию нужно делать с помощью папок. Переводите нормально, или бросьте эту затею.
3. Не знаю, что не может автор. Нет side-эффектов, потому что все инъектируется через импорт, кроме разве что тех из 1 пункта. Вот их мокать трудно, но нужно очень редко.
4. Я классы не защищал, в JS лучше писать микро-функции и передавать туда только ту часть state, которая ей нужна. И уж точно не выдумывать контекст для еще большего state.
5. Сначала создать проблему, потом героически ее решать)
6. Как раз с обещаниями тестировать еще проще, достаточно проверять expectations в конце цепочки вызовов. Однако, не вижу ничего страшного и в подмене обещаний, я вот люблю подменять их тупо на синхронную версию в тестах.
7. Нам не нужно никакое дерево с контекстом, чтобы разделить код на куски, а композицию описать в одном месте.
В JS есть проблемы, иногда асинхронность, иногда tree-shaking, с синтаксисом и с типами, но никак не проблема управления потоком синхронного кода.Guria
20.09.2016 16:47- Здесь, видимо, переводчик халтурит, я не говорил, что композицию нужно делать с помощью папок. Переводите нормально, или бросьте эту затею.
Предложите перевод для Вашей фразы "Создайте папку", более адекватный чем "Create a folder". А то я прямо в растерянности. :)
При этом к фразе был приложен контекст из оригинальной статьи, аналогичный процитированному вами куску перевода.
Если вам будет удобно, можете обратиться к автору напрямую в нашем discord-чате. Если нет, то продолжу переводить. Нам важен фидбек и я его передам.
- Also Sinon was mentioned as a mocking tool. I can see the point, but personally I think it is better to mock arguments than global dependencies. Cause you do not need a mocking tool, you just mock the context as any argument to a normal function

atamur
19.09.2016 19:46Чистые функции и привычные конструкции типа
ifлучше списка значений. От колбеков позволяет избавится использование например генераторов, через них же можно и логгировать выполнение и тестировать и многое другое.

jt3k
20.09.2016 16:23-1Этот комментарий оставляю здесь для возможности комментирования после прочтения (завтра)

nikis05
21.09.2016 16:53function getA() { return Promise.resolve('a'); } function getB(a) { if (c) throw new CError(); // работа с ошибками через оператор throw, предусмотренный в языке специально для таких случаев return Promise.resolve(a + 'b'); } co(function* () { try { // настоящий try-catch a = yield getA(); // ключевое слово yield наглядно показывает, что выполнение прерывается и мы ждем завершения асинхронной операции console.log(yield getB(a)); } catch (e) { console.log('error'); } }); // возвращает промис, что позволяет при необходимости легко скомбинировать его с дополнительным кодом и добавить then/catch, или даже вызвать изнутри другого генератора function getA() { return Promise.resolve({result: 'a'}); // нельзя просто вернуть результат, каждый раз необходимо придумывать бессмысленное название поля для каждой конкретной функции. Ненужные поля продолжают копиться внутри context грудой хлама и гулять по всем функциям. } function getB(a) { if (c) return path.error(new CError()); // необходимость вручную вызывать path.error => возможность пропустить необработанную ошибку return Promise.resolve({result: a + 'b'}); } exec([ getA, // непонятно, синхронная функция или асинхронная, невозможно делегировать исполнение другому генератору через yield*, только через функцию-костыль { error: () => console.log('error'), success: [ getB, { error: () => console.log('error'), // не предусмотрено слияние веток исполнения; при возможности использовать всплытие мне не пришлось бы писать два раза одно и то же success: (context) => console.log(context.result) } ] } ]); // изящный танец скобочек в конце; в примере, приведенном в тексте статьи, это выглядело еще более впечатляюще: /* } ] } ] } ] */nikis05
21.09.2016 17:08Да, и getB получает не только аргумент, необходимый и достаточный для его работы, а целую пачку данных, включая path, весь context и провайдеры, и должен сам отбирать из этого всего то, что ему нужно. Мелочь, но не особо приятно. В принципе идея интересная, но тупиковая, хотя это очень интересный, «умный» тупик.
Guria
21.09.2016 18:30обычно это выглядит так:
function getB({ input: { smthImportantForMe } }){ }
Да, возможно, контекст не самое красивое решение, но он работает.
См. также:
https://youtu.be/vpc80c5iC6k?list=PLglJM3BYAMPH2zuz1nbKHQyeawE4SN0Cd&t=643
Guria
21.09.2016 18:25+1// работа с ошибками через оператор throw, предусмотренный в языке специально для таких случаев
Я не хочу exception. Неполучение данных для меня не исключение, а норма в условиях http. Использование try catch в качестве условия ветвления логики до добра не доводит.
Цитата из статьи:
Часто потоки мыслятся как: "сделай это или бросай всё, если произойдёт ошибка". Но не в случае с веб-приложениями. Есть много причин, почему вы решите пойти вниз по различным путям выполнения.
// ключевое слово yield наглядно показывает, что выполнение прерывается и мы ждем завершения асинхронной операции
Только зачем мне это при чтении потока?
exec([ foo, bar // наглядно показывает, что bar выполнится только после foo. И не важно синхронные они или нет. ]) exec([ foo, [ // параллельное выполнение bar и baz после foo bar, baz ], theEnd // выполнится только после bar и baz. Аналог Promise.all([bar, baz]).then(theEnd) ]) // exec кстати тоже возвращает Промис который резолвится объединённой полезной нагрузкой // Полезно для тестирования, но не рекомендуется для композиции, во избежание дробления. Дерево является полным и самодостаточным описанием потока. Нет необходимости оборачивать его в try catch.
// нельзя просто вернуть результат, каждый раз необходимо придумывать бессмысленное название поля для каждой конкретной функции. Ненужные поля продолжают копиться внутри context грудой хлама и гулять по всем функциям.
Поля копятся лишь для текущего исполнения, прямо как переменные внутри скоупа выполняемой функции. А переменным тоже приходится придумывать имена. Конечно при обычном выполнении иногда возможно избежать создания переменной скомпоновав несколько функций. Ну и конечно же далеко не каждая функция должна возвращать значение, поэтому придумывать придётся не для каждой. На практике в этом месте проблем не было ни разу. Аргумент верен, но с оговорками.
// необходимость вручную вызывать path.error => возможность пропустить необработанную ошибку
Использование try catch для отлова ошибки не возбраняется. Но обработать её надо там же где она возникла, не полагаясь на вызывающую сторону, если только вы не хотите восстанавливать поток по крупицам в своей голове.
function getA ({someService, path}) { try { return path.success({ importantThing: someService.dangerousGetSmth() }) } catch (e) { return path.error({ importantThingError: e.toString() }) } }
На самом деле лучше если обработка ошибки будет обработана в сервисе
function getA ({someService, path}) { return someService.saveGetSmth().then( entity => path.success({ importantThing: entity }), error => path.error({ importantThingError: error }), ) }
А ещё ошибки бывают разные:
exec([ getEntity, { sucess: [processEntity], notFound: [showError('entityNotFound'), showCreateEntityDialog], // 404 unuathorized: [showError('unuathorized'), showRequestPermissionsDialog] serviceFailed: [showError('serviceFailed'), showTryLaterNotification] // 503 } ])
// непонятно, синхронная функция или асинхронная, невозможно делегировать исполнение другому генератору через yield*, только через функцию-костыль
Синхронность функции — деталь реализации. Из описания дерева и так явно следует порядок исполнения.
// не предусмотрено слияние веток исполнения; при возможности использовать всплытие мне не пришлось бы писать два раза одно и то же
Я не знаю, что вам помешало вынести ветку обработки ошибки в отдельную функцию или даже цепочку. Дерево описывается в js синтаксе.
// chains/processErrors.js export default [ logErrorToConsole, showNotificationToUser, logErrorToGoogleAnalytics ] // chains/getSmth.js import getA from '../actions/getA' import getB from '../actions/getB' import processErrors from './processErrors' export default [ getA, { success: [ getB, { success: [({input}) => console.log(input.result)], error: [...processErrors, showRetryGetBDialog] } ], error: [...processErrors, showRetryGetADialog] } ] // и скобочки не танцуют :(nikis05
22.09.2016 00:45Что касается try-catch
Я не хочу exception. Неполучение данных для меня не исключение, а норма
Если неполучение данных — не исключение, то что же тогда можно считать исключением? Исключение — это вовсе не «Сделай код и бросай, если произойдет ошибка» Это не то чтобы норма, но вполне штатная ситуация, которую можно и нужно обрабатывать, именно в этом весь смысл оператора catch. Неполучение данных от сервера, невалидный JSON, ошибка чтения файла — все это классические примеры исключений. JSON.parse, fs.readFileSync и многие другие встроенные синхронные функции именно так и обозначают, что что-то пошло не так. Если считать, что использование исключений неуместно в этом случае, логично было бы посчитать, что оно неуместно в принципе, потому что ситуаций, когда можно просто все бросить, в мире веба не существует. Мы в любом случае должны как-то уведомить пользователя о том, что операция не получилась, если это Web UI, или сообщить клиенту, что запрос не обработан и произошла internal error, если у нас API. Если исключения воспринимать как нечто из ряда вон выходящее и повод дальше ничего не делать, то тогда использовать исключения вообще не следует. Такой подход имеет право на существование, многие ругают try-catch и считают его «завуалированным GOTO». На мой взгляд, это некоторая софистика, при желании «завуалированным GOTO» можно назвать вообще любую конструкцию в языке. Так что лучше подойти к вопросу с практической точки зрения.
1. Всплытие — хорошая вещь. Это логичная вещь. Позволять ошибке всплывать — это не значит «полагаться на вызывающую сторону». Это значит соблюдать инкапсуляцию, решать стоящую перед функцией задачу. Допустим, у нас функция foo получает данные пользователя и вызывает их отрисовку в UI. Функция bar делает запрос к API, парсит результат функцией baz и возвращает его. Допустим, функция baz у нас выкинула исключение. Оно имеет смысловую нагрузку, а конкретно — оно означает, что функция baz не смогла распарсить входные данные. Из этого следует, что и функция bar не справилась со своей задачей — не смогла получить и вернуть валидный результат. Ошибка всплывает дальше. Foo перехватывает ее, с ее точки зрения ошибка тоже имеет конкретный смысл — валидные данные не получены, нужно уведомить пользователя, что произошла ошибка, foo вызывает отрисовку соответствующего события в UI. Каждая функция берет на себя ответственность только за те исключения, которые может обработать.
2. Можно что-то сделать с uncaught exceptions. Человек не идеален и не всегда может просчитать все возможные пути исполнения программы. Если мы пропустим возможность получения ошибки, например, в функции baz, то функция foo в любом случае перехватит ее и уведомит пользователя о том, что случилась ошибка. В function-tree нам придется либо допустить, что мы могли о чем-то забыть, и возможна ситуация, когда произойдет ошибка и просто ничего не случится, потому что мы забыли вызвать path.error, либо вместо:
function() { }
писать везде
function({path}) { try { } catch(e) { path.error({aRandomKey: e}); } }
ну просто на всякий случай.
3. Исключение — наиболее простой и универсальный способ сообщить о том, что что-то пошло не так. Он традиционный и широко применяется, встроенные методы языка и Node.JS, к счастью, используют именно throw, а не path.error({anotherOneRandomKey: e}). Поэтому если моя функция должна, например, спарсить JSON, как-то обработать его и что-то пошло не так, она просто выкинет ошибку, см. п. 1:
function() { let parsedJSON = JSON.parse(json); // ошибка тут означает ошибку всей функции, в этом и смысл всплытия. //... }
function() { try { let parsedJSON = JSON.parse(json); //... } catch(e) { return path.error({andAnotherOneRandomKey: e}); // фактически ошибка все равно будет обрабатываться дальше снаружи, просто это потребовало больше букв, по-другому называется и выглядит более солидно (запутанно). } }
nikis05
22.09.2016 01:00+1Что касается нотации
Все субъективно, но лично мне кажется, что
function* () { let a = yield foo(); let b = yield bar(a); return yield baz(b); }
объективно более читаемо, чем
[ foo, { success: [ bar, { success: [ baz ] } ] } ]
И если операций у меня здесь будет не 3, а 50, то мы получим чудовищный лапшичный код, растягивающий экран на километры вправо, и вернемся обратно в callback hell, только теперь с блэкджеком и промисами.

DmitryKoterov
await foo;
await bar;
Не?
vintage
Не мешайте человеку изобретать Лисп. :-)
babylon
Дмитрий, это точно не Lisp…
Лишний раз убеждаюсь, что проектировать систему надо со структуры данных, а иначе беда.
Удивительно, что статья Вас заинтересовала. Вы со своим Tree гораздо ближе к Lisp -:)
vintage
Пока не лисп. Сейчас уже у вас есть декларативное дерево, которое исполняется некоторым примитивным интерпретатором. Не хватает только макросов. :-)
babylon
Дмитрий, не я автор этой статьи, но примитивный интерпретатор у меня тоже есть.В данном контексте я за примитивизм и минимализм. Чтобы, например, ввести разные скобочки или теги приходится прибегать к введению новых ключей. Я не говорю про введению лямд. Хотя ими по идее и должно всё завершаться. Но любое нововведение расширяет keyspace. Уверен, что любой конечный автомат это своего рода расширение regexp, Почему-то никто таким расширением на уровне индустриальных стандартов не занимается или я про это ничего не знаю:). Чтобы создать макрос достаточно ввести ключи операторов и соответственно их подавать и обрабатывать в loop в соответствии с типами ключей. Собственно ключ это уже тип.
Guria
На этом примере происходит знакомство с принципами работы function-tree, а не способов последовательного запуска асинхронных функций.
К слову, ваш вариант не является полноценным эквивалентом, т.к. в случае с function-tree функция bar может быть синхронной и не возвращать промисов.
DmitryKoterov
Guria
Именно. А промисы резолвятся не синхронно, а в микротаске.