
Всем привет. Идея создать коллекцию, позволяющую управлять массивом информации, в основе которой лежит матрица, зародилась достаточно давно. Воплотить идею в жизнь я решил после изучения языка программирования Java. В статье речь пойдет о коллекциях, которые реализуют интерфейс списка.
Java collections
На данный момент в распоряжении мы имеет больше чем достаточно, как родных JDK, так и сторонних библиотек для работы с коллекциями:
JDK
Open Source
Выбор основания
Для создании универсальной коллекции подходит использование принципов generics. Основу коллекции создает класс java.util.AbstractList. Обязательными к переопределению являются методы get и size.
public class FastArray<E> extends AbstractList<E> {
@Override
public E get(int index) {
return null;
}
@Override
public int size() {
return 0;
}
}К тому же, тело некоторых методов абстрактного класса AbstractList определено как throw new UnsupportedOperationException(), что заставляет нас их так же переопределить на нужное нам поведение:
public E set(int index, E element) {
throw new UnsupportedOperationException();
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public E remove(int index) {
throw new UnsupportedOperationException();
}Принцип хранения и работы с данными
Структура хранения данных в коллекции представлена в виде одной матрицы и одного массива c типом IndexData:
private Object[][] elementData;
private IndexData[] data;Для хранения элементов списка используется двухмерный массив elementData. Двухмерный массив в ущерб объему памяти позволяет обеспечивать более быстрый доступ к элементам списка в процессе чтения, записи и удаления быстрые операции вставки/удаления в начало/середину списка.
В отличии от стандартного поведения ArrayList (при добавлении элементов содержимое массива копируется в новый увеличенный массив), в FastArray первая размерность массива имеет переменную длину и меняется при необходимости, вторая размерность массива имеет постоянную длину равную 32 элементам.
private static final int CAPACITY = Integer.SIZE;То есть, все сводится к тому, что при нехватке размера хранилища elementData, будет выполнено:
- динамическое выделение памяти на новый размер первой размерности массива
- скопированы ссылки на все массивы второй размерности
- динамически создан новый массив второй размерности
Массив IndexData требуется для хранения занятых мест и их общего количества во второй размерности elementData:
private static class IndexData {
private int data;
private int size;
private boolean isFull() {
return size == CAPACITY;
}
private void take(final int index) {
if (isFree(index)) {
data = data | 1 << index;
size++;
}
}
private void free(final int index) {
if (isTaked(index)) {
data = data ^ 1 << index;
size--;
}
}
private boolean isTaked(final int index) {
return !isFree(index);
}
private boolean isFree(final int index) {
return (data & 1 << index) == 0;
}
private int getSize() {
return size;
}
private int getIndexLeadingFreeBit() {
return CAPACITY - Integer.numberOfLeadingZeros(data);
}
private int getIndexTrailingFreeBit() {
return Integer.numberOfTrailingZeros(data) - 1;
}
}32 места хранятся в битах одного 32-битого числа. Данный прием позволяет сократить некоторые циклы при обходе массивов. Например, поиск свободного места слева или справа во второй размерности.
private int getTakedIndexAt(int data, int number) {
int count = 0;
int index = -1;
number++;
do {
count += data & 1;
index++;
} while ((data >>>= 1) != 0 && count != number);
return index;
}Данный алгоритм должен найти, например, пятое занятое место с начала. Если есть идеи, как убрать цикл из данного алгоритма, то просьба указать их в комментариях.
Тесты
Коллекция FastArray начинает показывать положительные результаты после того, как превысит свой размер в 1000 элементов. В противном случае, время на выполнение операций существенно увеличено по сравнению с результатами других коллекций.
int count = 100000;
for(int i = 0; i < count; i++)
list.add(1);
for(int i = 0; i < count; i++)
list.add(rand.nextInt(count), 10);
for(int i = 0; i < count * 2; i++)
list.get(rand.nextInt(count));
for(int i = 0; i < count; i++)
list.remove(rand.nextInt(list.size()));Результаты тестирования коллекций
| # | Name | Time (ms) |
|---|---|---|
| 1 | FastArray | 804 |
| 2 | HPPC | 2857 |
| 3 | Guava | 2887 |
| 4 | Commons Collections | 2909 |
| 5 | ArrayList | 2949 |
| 6 | PCJ | 6370 |
| 7 | Trove | 6503 |
| 8 | LinkedList | 83002 |
UPD: JMH benchmark
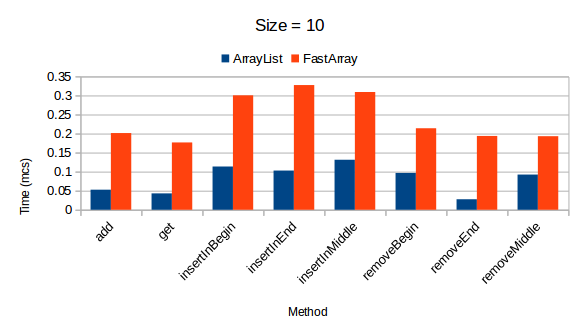
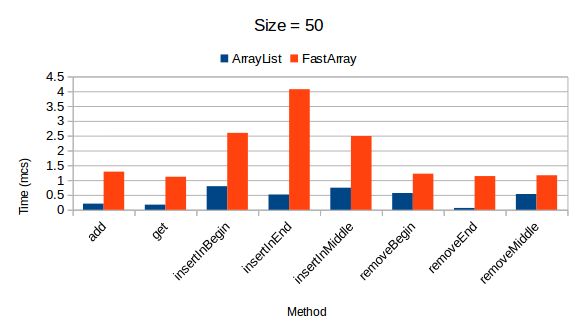
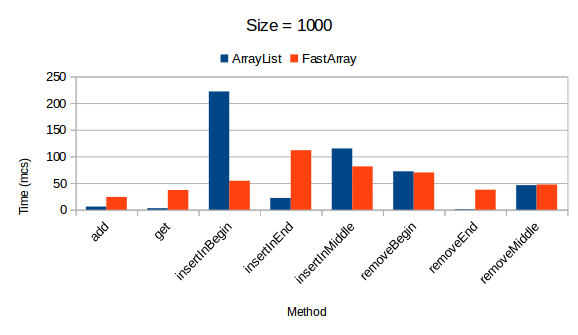
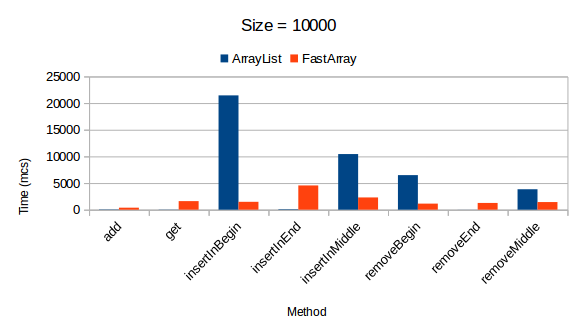

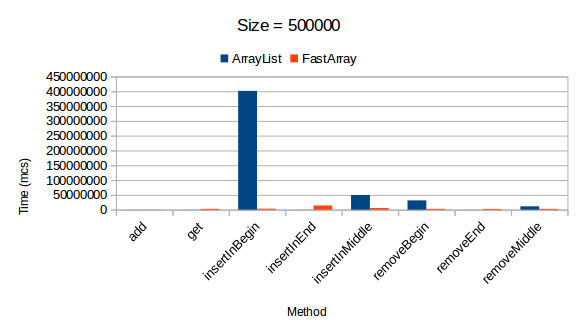
Исходный текст тестов представлен на github
Вывод
Ещё раз хочу заметить, что за уменьшение времени выполнения мы расплачиваемся объемом расходуемой памяти. При выполнении вышеуказанных тестов в процессе дефрагментации размер коллекции FastArray увеличился в 3 раза от номинального. Для уменьшения размера коллекции используется метод trimToSize().
Данная версия реализации не является финальной. Здесь реализован минимально требуемый функционал, который в последствии можно более тщательно оптимизировать.
Исходный текст полностью представлен на github
Благодарю за внимание
Комментарии (9)

AndreyRubankov
20.09.2016 18:48+3Вы в одном тесте замеряете время доступа по индексу, вставку, удаление одновременно. Вместе с этим вы замеряете время работы генерации псевдослучайных чисел.
Как минимум операции доступа и изменения коллекции нужно разбить на разные тесты. Доступ по индексу однозначно будет в разы хуже, чем в ArrayList, т.к. вместо 1 операции взятия элемента из массива, нужно будет сначала из индекса (data) взять данные, и лишь потом из elementData.
И как советовали выше, используйте JMH для тестов.

vladimir_dolzhenko
21.09.2016 11:03+1И, где же iterate? по последовательным и по случайным? И как бы даже из приведённых benchmark-ов — вывод очень неоднозначный

Alex_java
21.09.2016 11:15Данная коллекция изначально не претендовала на замену стандартным коллекциям, а представлена как идея. Плюс, реализован только базовый функционал без оптимизации.
Dionis_mgn
21.09.2016 11:51Возникает ощущение, что Вы пытались придумать std::deque. Думаю, поглядеть его реализацию в GCC/Clang будет полезным.
AndreyRubankov
21.09.2016 12:17+1Спасибо за добавленные JMH тесты, выглядит лучше. Но попробуйте поменять единицы измерения на op/sec, это будет нагляднее при данного рода тестах.
Как вариант, можно еще добавить столбец сравнения с LinkedList (на него будет ориентир при вставках в начало и середину).
relgames
А где тесты на JMH для каждого из случаев? Желательно на разных размерах: 10, 1 000, 1 000 000, 100 000 000
И для разных случаев: sequential access, random access.
vladimir_dolzhenko
— вставка в начало, в конец, в середину
— удаление элементов в начало, в конец, в середину
Alex_java
Добавлены тесты jmh benchmark
relgames
Спасибо. То есть вот эта фраза из поста «более быстрый доступ к элементам списка в процессе чтения, записи и удаления» на самом деле превращается в «более быстрое добавление/удаление в начале/середине».
Теперь финт ушами: для этих конкретных задач все равно ArrayList подходит больше, если эти операции выразить через добавление в конец и чтение задом наперед. Например, для добавления в середину можно использовать 2 ArrayList, а при чтении объединять.
Потому что стандартные коллекции Java предельно оптимизированы, и используют приемы, недоступные обычному программисту, типа JIT оптимизации.