
Александр Крижановский (NatSys Lab.)

Нас сегодня будет интересовать операционная система – ее внутренности, что там происходит… Хочется поделиться идеями, над которыми мы сейчас работаем, и отсюда небольшое вступление – я расскажу о том, из чего состоит современный Linux, как его можно потюнить?
По моему мнению, современная ОС – это плохая штука.

Дело в том, что на картинке изображены графики сайта Netmap (это штуковина, которая позволяет вам очень быстро захватывать и отправлять пакеты сетевого адаптера), т.е. эта картинка показывает, что на одном ядре с разной тактовой частотой до 3 ГГц Netmap позволяет 10 Гбит – 14 млн. пакетов в сек. отрабатывать уже на 500 МГц. Синенькая линия – это pktgen – самое быстрое, что, вообще, есть в ядре Linux’а. Это такая штуковина – генератор трафика, который берет один пакет и отправляет его в адаптер много раз, т.е. никаких копирований, никакого создания новых пакетов, т.е., вообще, ничего – только отправка одного и того же пакета в адаптер. И вот оно настолько сильно проседает по сравнению с Netmap (то, что делается в user-space показано розовой линией), и оно вообще где-то там внизу находится. Соответственно, люди, которые работают с очень быстрыми сетевыми приложениями, переезжают на Netmap, Pdpdk, PF_RING – таких технологий море сейчас.
Второй поинт – это о базах данных. Было о сетях, теперь о базах данных. Если кто-нибудь заглядывал в базы данных, мы знаем и сегодня посмотрим, что можно использовать MMAP, можно использовать O_DIRECT. В больших базах данных – Postgres, MySQL, InnoDB – в основном, используют O_DIRECT, и еще в 2007 году было обсуждение в LKML’е, и было сказано, что O_DIRECT – это грязная подборка, она неправильная. Если мы посмотрим на код операционной системы, на код мощной базы данных, то мы увидим, что база данных загребает себе большую область памяти и сама ею управляет. Она сама держит пул страничек, работу со страницами, вытесняет их, сбрасывает, т.е. все, что делает операционная система на уровне виртуальной памяти, уровне файловой системы и пр.
Linux тогда сказал о том, что, пожалуйста, используйте madvise для того, чтобы вам работать. Петр Зайцев спросил: «А как же мы будем без O_DIRECT’а жить? Потому что нам нужно знать, когда какую страничку сбрасывать». Ответа не было, и мы продолжаем так же жить.
Следующий поинт о том, как мы программируем свои приложения. Если вы пишете многопоточные сетевые демоны, то у вас, как правило, должен возникать вопрос: «Что же я буду использовать? Будут ли там процессы, ивенты, потоки, как много потоков там можно будет запускать, как подружить стейт машины для того, чтобы каждый поток обрабатывал много событий, стейт машины и потоки, или, может быть, использовать корутины, как делает Erlang?» и т.д. Это достаточно сложный вопрос.
Есть замечательные статьи – «Why Events are A Bad Idea» (Rob von Behren) и «SEDA: An Architecture for Well-Conditioned, Scalable Internet Services» (Matt Welsh), которые совершенно противоречат друг другу. Одни говорят то, что нужно все делать на потоках, что современная ОС очень хорошо работает с потоками, и мы можем дать ей столько потоков, сколько хотим, и хорошо их синхронизировать и хорошо все будет работать. SEDA говорит о более тяжелой архитектуре, о том, что мы запускаем какое-то количество потоков, мы их перераспределяем между определенными задачами, там довольно сложный механизм планирования потоков и задач по этим потокам.
В общем, довольно-таки геморройный вопрос, который надо решать, и, по сути, либо мы используем какой-то фреймворк потоковый, например, Boost.Asio, либо мы сами все делаем это руками и должны задумываться над тем, что нужно. Нам нужен перфоманс, мы должны задумываться об этом.
Мы живем в мире, где у нас очень много аллокаторов памяти, т.е. если мы пишем что-то простое, то мы используем malloc либо new в С++ и не задумываемся, как у нас и что происходит. Как только мы выходим на высокие нагрузки, мы начинаем уже тащить jemalloc, hoard и другие готовые библиотеки, либо мы пишем свои распределители памяти – SLAB, pool и др. Т.е. если мы делаем сервер, сначала мы начинаем с простой программы и потом уходим к ре-имплементации ОС в user-space.

Мы делаем буфер пул для быстрого ввода – вывода, мы делаем свои потоки, какие-то механизмы планирования, синхронизации, свои аллокаторы памяти и т.д.
С другой стороны десктоп. Я вчера посмотрел, что у меня запущено – у меня запущено 120 процессов, многие из них мне даже неизвестны. Я люблю легкие системы и, в принципе, я понимаю, что у меня работает. Если я запущу KDE или GNOME, то там будет море процессов – 200-300, о которых я даже не догадываюсь, что это такое, что они делают. Какую нагрузку они дают на систему, я тоже не догадываюсь, и, в целом, мне это не важно. Я печатаю, собираю код, в целом, я не интересуюсь максимальным бенчмарками в моем декстопе, мне интересны максимальные бенчмарки на моем сервере – там, где мне нужно ставить рекорды.
Второе – то, что десктопы сейчас достаточно маломощные, это какой-то обычный один процессор, немножко ядер, немножко памяти, никакой NUMA, т.е. все очень просто, все очень маленькое. И, тем не менее, мы знаем, что у нас Linux работает на наших телефонах и на больших серверах. Это не очень правильно.
Если мы посмотрим, как живет прогрессивный мир… Может, если кто сталкивался с тяжелым DDoS, знают эту табличку:

Это табличка данных от одного из пионеров построения больших датацентров по фильтрации трафика, они работают на обычном Intel’овском железе без всяких сетевых акселераторов, и люди делают собственную ОС. Красным цветом показано то, что они убрали, и они получили данные, что могут с базового дешевого сервера снимать 10-ки Гбит трафика.
Если вы просто так запустите Linux, то вы ничего не снимете. Тем более эти люди делают достаточно серьезную фильтрацию на уровне Application Layer DDoS. Они залазят не только в IP/TCP – то, что делает обычная ОС, но они еще и парсят HTP, разбирают его, запускают какой-то классификатор, и они успевают один пакет разобрать за сколько-то тактов процессора – все очень быстро.

Если мы попытаемся ответить, почему так вот мы живем с Linux’ом, мы рады. Где-то в 2000-х годах крепкие были позиции у Solaris’а, был спор о том, что Solaris стар, тяжел, Linux быстрый и легкий, потому что он маленький – это тоже можно найти в списках рассылки. Теперь имеем то, что тогда имел Solaris – Linux очень большой, его код просто колоссальный, там куча опций, он кучу всего умеет делать, все, что вы хотите сделать, вы можете в нем сделать. Есть другие ОС типа OpenBSD, NetBSD, которые сильно проще, они менее используемые, но Linux – это очень мощная штука.
Я содрал картинку выше из википедии – они попытались изобразить Linux в некотором разрезе. У нас есть вертикальные столбцы – его подсистемы по его директориям в ядре, и внизу они прошли от более высокого уровня к более низкому. Здесь очень сложный граф. На самом деле, если посмотреть на какую-то точку, например, на планирование ввода-вывода на уровне стораджа – синяя и сине-зеленая – там далеко не все показано. Все на самом деле сложнее, там большие связи, очень много различных очередей, очень много блокировок, и все это должно работать, и работает это все медленно.
Давайте пройдемся по вертикальным столбикам, посмотрим на подсистемы Linux’а, и что с ними можно делать, где там могут быть проблемы. Отчасти с точки зрения администратора, отчасти с точки зрения разработчика прикладного кода.

Во-первых, работа с процессами и тредами. У Linux’а есть планировщик ввода-вывода, справедливый, который работает за логарифмическое время. Он сейчас дефолтный планировщик, до этого был планировщик, который работает за константное время. Мне никогда не приходилось влезать в сам планировщик с целью оптимизации, получения из него большей производительности, т.е., как там работает, я знаю, а оптимизировать его никогда не приходилось. Там как-то все планируется и, наверное, оно планируется хорошо. Проблемы обычно возникают в другом месте.
Как я уже сказал, десктопы и сервера – это совершенно разные миры, т.е. если есть сервер с одним процессором, 8 или 16 ядер – это один вариант. Если у нас сервер, где стоит 4 процессора, у каждого по 10 ядер – у нас 40 ядер в системе, плюс hyper-threading, у нас 8 потоков. Сейчас процессоры стали более массивными, там еще больше параллельных контекстов, и картинка совсем другая.
Прежде всего, если говорить о потоках, о процессах, об ивентах, то чтобы мы ни выбрали – потоки, процессы либо стейт машины – это все о вашем удобстве.
Если вы хотите написать быстро, берите какой-то фреймворк и используйте его, либо Vent, либо Boost.Asio с кучей потоков, что угодно.
Если вам нужен перформанс, то нужно точно понимать, что у вас определенное количество железа, ядер, которые могут в единицу времени что-то делать. Если вы одну единицу заставите делать больше, чем она может, на один хардварный поток отдадите много софтварных потоков, то ничего хорошего не произойдет. Произойдет первый Context switch. Context switch’и у нас дешевы, если у вас происходит системный вызов. У нас есть специальная оптимизация в операционной системе, что если прикладной процесс уходит в ядро и тут же возвращается обратно, то у него кэши не так сильно вымываются, и у него не происходит инвалидации кэшей. Немного происходит вымывание, но, в целом, мы хорошо живем. Если у вас начинают перепланироваться прикладные контексты, то становится все очень плохо.
- На современных Intel’овских процессорах мы должны инвалидировать кэши 1-го уровня, т.е. самое наше ценное, то, что у нас самое маленькое и самое дорогое, то, что нам позволяет работать действительно быстро при медленной памяти – мы это теряем. Более старшие кэши L2, L3 просто вымываются. Если у вас работает параллельно несколько потоков, несколько процессов, программ, которые работают с достаточно большим объемом данных, и они у вас перепланируются, то, понятно, что память, с которой каждая программа или каждый поток работает, загружается в кэши и вымывает то, что делала предыдущая, та, что набирала себе в кэши. И когда происходит обратный Context switch, когда первая программа снова получает управление, она переходит, по сути, на холодные кэши и начинает тянуть данные из памяти, и у нас становится совершенно другой порядок времени работы.
- Следующее. Что у нас не встречается на десктопах, на наших смартфонах – это NUMA. Современные X86, до этого раньше были AMD, теперь уже и Intel, они стали несимметричной архитектуры. Суть в том, что наш планировщик ОС – а у нас есть разные процессоры – это разные наши ноды. Каждая нода работает со своей физической локальной памятью, и если планировщик ОС вздумает из одной ноды переместиться, из одного процессора переместить процесс на другой процессор, то у нас становится все очень плохо. У нас тянется память через медленные каналы. К счастью, ОС знает топологию ядер, на которых она работает, она старается этого не делать, но, тем не менее, иногда ей это делать приходится, в силу каких-то своих соображений.
- Далее. У нас немного поменялся механизм того, как мы работаем с разделяемыми данными. Если мы сколько-то лет назад могли спокойно брать spin lock и считать, что это самое быстрое, т.е. брать какую-то маленькую переменную, крутиться в цикле, ожидать ее в некоторых значениях на этой переменной, то сейчас мы так делать не можем. Если наши 80 ядер ломятся на один байт, на 4 байта, то шина данных у нас страдает, и у нас все становится очень медленным, т.е. мы не можем пользоваться механизмами синхронизации, которыми мы пользовались раньше.
Я очень советую почитать «What Every Programmer Should Know about Memory» (Ulrich Drepper) – замечательная книга, она немного старая, но общие концепции там очень хорошие, она показывает, как работает и что можно делать.
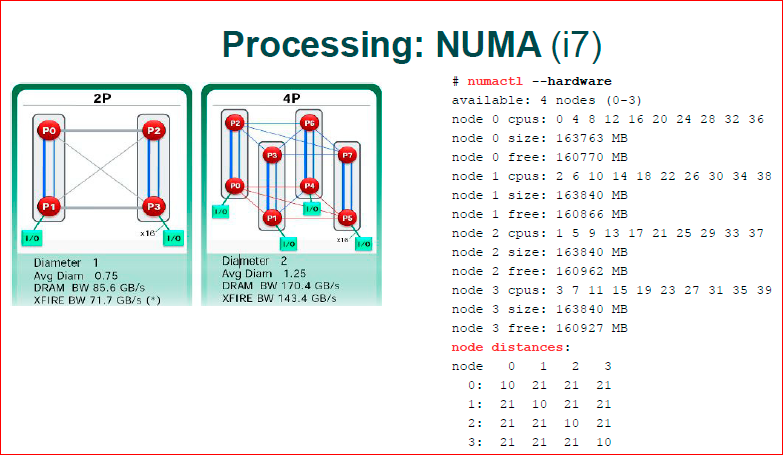
Первая картинка – 2008 или 2009-го года от AMD, когда все начинало входить в широкие массы. У нас два процессора всего. Синенькие каналы – это те каналы, по которым общаются два ядра, т.е. здесь у нас 2 процессора по 2 ядра. Между двумя ядрами у нас очень быстрый трансфер, а между разными процессорами – очень медленный. Соответственно, если у нас ядро 0.3 – они работают с одной и той же блокировкой, с одним и тем же интом, то они по медленному каналу памяти начинают гонять эти 4 байта – это очень медленно. Если у нас работают P0 и P1 с одними и теми же интовыми переменными, то у нас все очень быстро.
В современной архитектуре они приблизились, наверное, они даже дальше прошли, чем картинка с 4-мя процессорами. Если здесь у нас плоская структура – у нас есть 2 процессора, быстрые и медленные каналы, то там у нас уже трехмерная конструкция, и там уже не все ядра и не со всеми общаются. Например, P3 не общается с P4, он должен сделать два хопа. Т.е. если нам нужны данные в P3 из P4, мы сначала идем в P0, а потом P0 уже идет в P4, т.е. нам надо еще один процессор задействовать в нашем трансфере.
Современная Intel’овская архитектура i7 – у нее очень серьезная шина, у нее KPI. По сути, там эта инфраструктура, общение ядер и синхронизация данных. Они построили свой TCP/IP, т.е. там многоуровневый протокол общения, свои пакеты бегают по шине данных между процессорами, там достаточно сложная вещь и разобраться в современном i7, где у него трансфер быстрее, где медленнее, очень тяжело. Numactl показывает node distances. Это если мы посмотрим по диагонали, это ядро само с собой – это некоторые веса, некоторые попугаи – у него самое дешевое. В любой другой узел ему уже тяжело ходить, т.е. там уже веса по 21 считается.
Даже утилита, которая должна вам показать топологию вашего железа, она считает, что любое ядро, которым вы пойдете, – оно имеет одинаковую цену. На самом деле, это немного не так, но если мы работаем с NUMA, то проще считать, что в локальном процессоре все быстро, а в чужом – все медленно.

Что мы можем сделать и что правильно делать, чтобы код работал быстро? Во-первых, spin lock, разные структуры данных, lock-free, которые в 2010-х годах стали очень сильно популярны. Разные lock-free очереди и прочее не работает на больших машинах. Недавно меня спрашивали о том, что «вот у нас есть 20 тыс. потоков, и их человек хотел написать быструю очередь, которая позволяла бы быстро вставлять и забирать данные. Оно так не будет работать, т.е. будет все очень медленно. 20 тыс. потоков будут кэшировать, они будут безобразно дергать атомарные инструкции, данные, и все будет очень медленно. Соответственно, если вы пишете код для NUMA системы, вы считаете, что у вас есть маленький кластер внутри вашей машины, внутри одной железки, и вы строите свой софт так, что у вас маленькая машинка, один процессор, она многоядерная, там 8-10-16 ядер, она делает что-то свое локально и иногда общается с чужими. А дальше, если вы объединяете кластер из машин, у вас будет еще более медленная коммуникация. У вас получается такая иерархия кластеров – более быстрый кластер и более медленные кластера.
Хороший пример разделяемых данных о том, что нехорошо использовать разделяемые данные, когда С++ shared_ptr, т.е. у нас есть указатель на данные – это наши смарт поинтеры, и у них есть reference counter, который при каждом копировании указателя изменяется, соответственно, если вы пишете нагруженный сервер, то shared_ptr’ами пользоваться нельзя.
Одна из причин, почему там boost осел, например, никогда не даст вам хорошей производительности на сервере – это то, что он очень сильно использует shared_ptr, смарт поинтеры и прочие высокоуровневые вещи, которые сильно замедляют действия, т.е. этот высокоуровневый объектный код не рассчитывает на то, что он должен максимально быстро работать с сырым железом.
Дальше. False sharing. Так или иначе, мы в разных языках высокоуровневого программирования оперируем одним байтом-двумя-четырьмя, восемью байтами. Процессор оперирует 64-мя байтами – это одна кэш-линейка процессора. Т.е. если у вас переменные хранятся в одной кэш-линейке в 64-х байтах, то для процессора – это одна переменная, и он будет все свои алгоритмы делать именно над вашими двумя переменными. Если у вас по каким-то причинам ваши две горячие переменные, например, два spin lock’а совершенно разные и идеологически ложатся в одну кэш-линейку, то у вас большие проблемы. У вас разные ядра, того не желая, начинают драться за одни и те же данные, хотя они должны работать параллельно. И вы приходите к тому, что у вас, по сути, блокировки две, а работают как одна.
Привязывать процессы – это, как раз, случай про NUMA. Достаточно старый тест. Здесь была машина 4 процессора по 4 ядра. Сначала, когда мы запускаем dd и отправляем его на nc, у нас dd запускается на одном ядре, nc – на другом. И в тот момент, почему-то ОС решала так, что «у нас же разные процессоры, лучше нам процесс прикладной разбросать пqо разным процессорам», и она отдавала один процесс на один процессор, другой – на другой, и получали достаточно низкую производительность. Если мы жестко пропишем, что у нас оба процесса должны жить на одном процессоре, то у нас сильно возрастал трансфер. Т.е. ОС делает не всегда хорошие вещи, не всегда умные вещи по планированию процессов.
Еще одно – у нас бывают разные сервера, т.е. у нас десктопы есть, на которых вообще что попало крутится, и мы не знаем, что там такое. У нас есть сервера, на которых, может быть, работает apache, nginx, MySQL, роутер или еще что-то, т.е. бывают такие сборные солянки. Но если мы строим высокопроизводительный кластер, если посмотреть то, как строятся большие компании, как правило, есть кластер, есть уровни, там первый уровень – у нас стоит, например, nginx на 10-и машинах, и на каждой машине только nginx и ОС. Следующий уровень – у нас Apache с какими-то скриптами, следующий уровень – у нас MySQL, т.е. у нас получается, что одна машина – одна высокоуровневая задача. Это совершенно другой подход, и при таком раскладе наше приложение, nginx или apache может рассчитывать на то, что он владеет всеми ресурсами, ему не нужна виртуализация, которую дает ОС – это виртуальная память, это изоляция адресных пространств, то, что каждая программа считает, что она работает с каким-то неизвестным количеством CPU. Мы можем привязать, например, когда мы запускаем веб-сервер, мы запускаем воркеров либо равно количеству ядер, либо в два раза больше, т.е. мы основываемся – количество воркеров на количество ядер. Это как раз тот пример, что у нас одно приложение полностью использует всю машину.
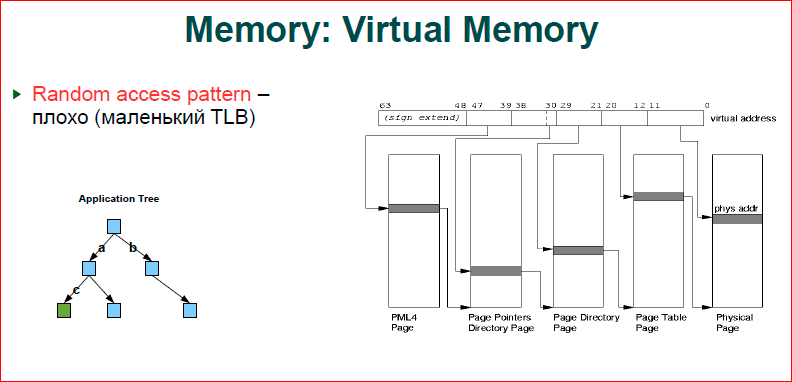
Про память. Если коротко, то чем больше памяти вы используете, тем вам хуже. Если посмотреть на картинку – это то, как работает наша виртуальная память. У нас есть адрес (это линеечка сверху) – от 0 до 63-х бит, и когда мы работаем в виртуальном адресном пространстве, а железо у нас с физическим адресным пространством, у нас, как всегда, происходит маппинг виртуального адресного пространства в физическое. Соответственно, если у вас работают две программы, у них адреса переменных могут быть одинаковыми, но эти адреса ссылаются на разные физические ячейки памяти. Это принцип работы виртуальной памяти. Соответственно, когда у нас процессор обращается к некоторому адресу, мы должны сделать резолвинг этого виртуального адреса в физический.
У нас работает так page table – то, что показано. Page table состоит из четырех уровней. У нас есть первые четыре уровня, откуда ссылается с 39-ый по 47-ой бит – это страничка. Эта страничка представляет собой табличку, в ней индексом служит число, которое кодируется битом, мы прыгаем на следующий уровень, потом резолвим следующую часть битов и т.д. Здесь показана плоская структура того, что одна страница, один уровень ссылается на следующий. Понятно, что на первом уровне старшие адреса в программе, как правило, совпадают.
ОС, когда делает аллокацию памяти, выбирает младшие адреса максимально близко к тем, что имеется, т.е. мы получаем дерево. Первая серая линеечка будет одна, вторая может быть тоже одна, потом на третьем уровне у нас происходит две, на последнем уровне мы начинаем полностью использовать весь уровень, т.е. у нас получается такое дерево с рутом в главной странице, и потом оно ветвится. Т.о., чем больше у нас памяти расходуется, тем более ветвистое дерево мы получаем, и, понятное дело, что это тоже должно где-то храниться, это тоже наша физическая память. Дальше посмотрим, как это все расходуется и, прежде всего, расход памяти.
Второе. Допустим, мы создаем какое-то бинарное дерево, считаем, что у нас есть синенькие узлы и зелененькие узлы, куда мы хотим прийти. Для нас это дерево, для ОС – это дерево внутри дерева, т.е. когда мы проходим по ключу a – из первого уровня во второй, у нас происходит трансфер по нашему дереву и полностью мы проходим четыре уровня дерева. Теперь мы прыгаем от второго уровня к третьему – к с, следующему моменту. У нас снова дерево резолвится, т.е. у нас для того, чтобы пройти из верха дерева вниз, будет восемь трансферов памяти – это много.
У нас, к счастью, есть TLB-кэш. Это, на самом деле, достаточно маленький кэш, всего там помещается порядка 1000 адресов, т.е. таблицы трансляции мы адресуем страницами. 4 Кб страниц, 1000 страниц – получаем 4 Мб, т.е. 4 Мб – это то, что у нас закэшировано в TLB. Как только у вас приложение выходит за 4 Мб, вы начинаете бегать уже по дереву, а 4 Мб для современного приложения – это, вообще говоря, ничто. И у вас достаточно часто возникает выход из TLB-кэша, т.е. чем больше памяти мы расходуем, тем у нас сильнее деградирует производительность.
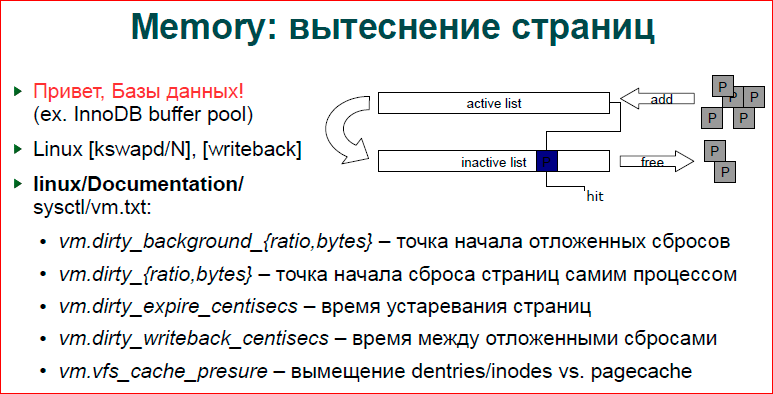
Про вытеснения страниц. Я уже говорил, что у нас базы данных это делают, и действительно, некоторые механизмы очень похожи в базах данных и в ОС, а Linux держит двойной список LRU, т.е. у нас есть активный список и неактивный. Соответственно, страничка, когда вы только делаете аллокацию или что-то делаете со страничкой, помещается в active list. Потом, через какое-то время, она вытесняется в inactive list. Демон kswapd, если вы сделаете ps, вы увидите kswapd – их по одной штуке на ядро, они, как раз, занимаются этими перебросами страничек из листа в лист. И когда страничка совсем устаревает второй раз, она уже вытесняется из inactive list, и если это анонимная страничка, например, какой-то malloc, она уходит в swap. Если это замапленный файл, то страничка просто выбрасывается, мы пойдем в файл замапленный.
Кроме того, что у нас есть active и inactive list, у нас страничка может быть грязной и чистой. Т.е. если мы только читаем страничку, она чистая. Если мы что-то записали, то она грязная, пока она не будет сброшена на вторичные хранилища – это либо swap, либо обратно в файл записана. Каждый раз, как мы записали что-то в память, мы не хотим идти и сбрасывать все это на диск. Очевидно, что это замедлит работу. Но иногда нам сбрасывать нужно, потому что если у нас идет массивная нагрузка, если мы сейчас все пишем, пишем в память, а потом ничего никуда не сбрасываем, то потом у нас памяти не хватает. Приходит запись в какой-то один байт памяти, и у нас начинается активный сброс, проход по этим спискам, сброс этого всего на диск, и мы, вообще, встаем.
Соответственно, у нас есть writeback-процесс, и файловые системы добавляют в этот процесс свои работы. И writeback, как раз, делает сброс грязных страниц на вторичные хранилища.
У нас есть sysctl-переменные. Я для sysctl пользуюсь документацией внутри ядра, у меня всегда под рукой есть ядро, я туда заглядываю, и в ядре есть документация, где хорошо написано, что делает каждый sysctl.
Соответственно, dirty_background_{ratio,bytes} – это точка начала отложенных сбросов, т.е. когда у нас файловая система решает, что надо поместить работу для writeback’a, о том, сколько байт мы уже написали, сколько у нас есть грязных байт, либо сколько процентов грязных страниц от чистых мы достигаем, и тогда мы начинаем сбрасывать эти данные на диск.
dirty_{ratio,bytes} – это когда у нас процесс записывает данные и делает новую грязную страницу, и в этот момент он смотрит, сколько у нас уже есть грязных страниц. Если у нас их много, то он сам будет сбрасывать прямо сейчас на вторичные хранилища, если их мало, то он это оставит в работу для writeback’a, т.е. так мы пытаемся уйти от ситуации, когда мы очень интенсивно записываем, но writeback-поток не успевает все сбрасывать.
Writeback_centisecs контролирует то, как у нас страничка проходит по листам, и как часто они выталкиваются.
Cache_presure – это некоторый компромисс между тем, как мы выталкиваем какие данные. Т.е. если это какой-то файловый сервер, то нам нужны много inode и много писателей директорий. Если это просто база данных, которая замапливала большую область памяти, то нам inode не нужны. Например, ngnix открывает файл и держит его в своем кэше, нам там директории особо не нужны, inode, может, и нужны, но скорее всего нет, и ему более важны page cache.

Про большие страницы. Я говорю, что наши таблицы страниц работают со страницами по 4 Кб и, действительно, у нас получается, что в TLB мы можем адресовать только 4 Мб – это мало. Таким образом, у нас есть на уровне ядра и на уровне процессора оптимизация – это большая страница. Я, честно говоря, не знаю как процессор с ней работает, но суть в том, что если вы аллоцируете страницу, у нас нет физической страницы в 2 Мб либо 1 Гб. Физически у нас все равно 4 Кб. И когда вы аллоцируете большую страницу, у вас операционка, на самом деле, ищет непрерывный блок по 4 Кб, который составит вам эту большую страницу. Эта большая страница будет составлять всего одно вхождение page table и одно вхождение в TLB.
Беда здесь заключается в том, что если у нас TLB первого уровня для обычных страниц – это порядка 1000 вхождений, то для больших страниц – это, наверно, около 8 для 2 Мб, и 1-2 для Гб. Исходя из этого, если у вас большая база данных, то вам могут не подойти большие страницы, и если вы пишете всего 1 байт, у вас на этот байт выделяется 1 Гб, и он дергается с файла, вам в итоге не выгодно становится. Если вы держите какой-то очень интенсивный сторадж сравнительно небольших данных, т.е. не так как вы поднимаете MySQL на 40 Гбайт памяти, а если у вас есть небольшая база, буквально на 1 Гбайт, на 2-4 Мб, которая очень интенсивно работает со структурами данных, то имеет смысл использовать hugh pages.
Прелесть состоит в том, что Linux 2.6.38 ввел прозрачные большие страницы. Какое-то время нам нужно было специально заморачиваться большими страницами, монтировать специальную файловую систему для работы с ней, сейчас Linux может делать все самостоятельно. Если вы указываете для вашей области памяти, делаете madvise, потому что вы хотите, чтобы эта область памяти использовала большие страницы, то когда вы выделяете страницы, скажем в mmap’е большом, Linux будет стараться вам выделить большую страницу. Если он не может выделить, он скатится к 4 Кб, но он будет делать все возможное для этого. Поддержку для больших страниц можно посмотреть по xdpyinfo.

Про дисковый ввод-вывод. Здесь у нас три варианта, которые можно разделить на две большие интересные категории: первая – это файловый ввод-вывод с копированием, вторые два – это без копирования.
На картинке показана нормальная работа. Если мы делаем обычный open, делаем read, write, у нас все идет через наш кэш, т.н. page cache. Для любого происходящего ввода-вывода файла есть странички, в которые пишутся данные, считанные из файла, записанные в файл, и они с помощью kswapd, с помощью writeback-потоков сбрасываются в файл или, наоборот, поднимаются из него. Здесь мы получаем копирование. Если у нас есть в нашей прикладной программе буфер, мы сделаем из него read либо write, то мы пишем данные в этот буфер, и мы пишем еще в page cache, т.е. у нас происходит двойное копирование. Это медленно, соответственно, большие базы данных используют O_DIRECT ввод-вывод, мы минуем page cache, мы говорим о том, что у нас есть своя большая область памяти, выделяем его тем же mmap’ом и делаем прямой ввод-вывод из контроллера диска в эту область.
Второй подход – это мы делаем mmap. Это значит, что если в случае с O_DIRECT мы сами делаем read либо write на определенных страничках и сами ее сбрасываем на диск, то в случае mmap у нас ОС как-то когда-то что-то сбросит, мы не знаем, когда и что она сбросит. Соответственно, если у нас есть транзакционный лог, и мы говорим о том, что этот блок данных должен обязательно быть записан перед другим блоком, мы не можем этого делать, мы можем это делать только в случае O_DIRECT’a.
Еще интересная штука с mmap. Вообще говоря, у нас большое адресное пространство в X86, есть соблазн, поскольку у нас виртуальная память, поскольку мы можем замапить 128 Тб памяти, а иметь всего 10 Гб – это просто мапить, мапить много файлов и как-то с ними работать. В частности, мы пробовали сделать, поскольку мы знаем, что у нас есть page 3, мы можем замапить 128 Тб, сделать один mmap, и вот эти 128 Тб – это сколько-то бит в нашем адресе.
Допустим, там будет младший сколько-то n бит, мы делаем mmap и получаем уже железное дерево, которое дает нам аппаратура. Т.е. мы берем любой адрес, берем биты в качестве нашего ключа, который мы храним, и кладем их на шину и получаем уже данные в этом mmap.
Так можно работать. В каком-то варианте оно будет работать быстро, но у нас сильно разрастается page table и проседают кэши. Т.о., page table – это достаточно дорогая штука, на 128 Тб у нас 256 Гб используется page table, т.е. на порядок меньше, но цифра очень серьезная.

По поводу стораджа. У нас есть планирование ввода-вывода на наших стораджах. На картинке то, что красным показано. Представим, что у нас есть три блока, которые хранятся на разных местах разных дорожек нашего диска, и мы их в каком-то порядке кидаем контроллеру. Контроллер начинает бегать сначала на внутренней дорожке, потом он, к счастью, сразу видит второй блок, потом он должен пробежать достаточно большую дистанцию, чтоб сбросить третий и четвертый. Т.е. у нас диск все время крутится, если он не припорядочивает.
Зеленым показан механизм оптимизации. Он сможет двигать нашу головку по мере того, как вращается диск, он может ее еще двигать между дорожками и, соответственно, делать ввод-вывод с разных дорожек параллельно. И получается – за один оборот мы успеваем все сделать. Здесь мы три оборота делаем.
Это работает так же резво, но есть еще в Linux’е свои планировщики ввода-вывода. Т.о., у нас есть простой планировщик, который, по сути, ничего не делает, просто сливает запросы и полагается на то, что хардварный планировщик все сделает. Сливает он запросы для того, чтобы сократить время CPU и работы ОС на ввод-вывод, т.е. большой пачкой сразу отдать выгоднее.
Deadline планировщика – это то, что рекомендуется для баз данных, он обеспечивает нам гарантию того, что через какое-то время наши данные будут скинуты, т.е. они не будут там вечно жить. Это достаточно простой планировщик и позволяет он базам данных хорошо понимать, как будут их данные ложиться на диск.
Есть сейчас CFQ – это дефолтный планировщик, наверное, во всех дистрибутивах, он делает сложные вещи, если у вас есть виртуализация, разные пользователи, он пытается всех не обидеть, балансировать ввод-вывод, давать одинаковое качество обслуживание каждому пользователю. Но для баз данных, для серверов это не очень хорошо подходит.

По поводу оптимизации. Есть в sysctl параметры, я здесь перечислил, их можно потюнить, в частности поменять планировщик, изменить длину его очереди. Т.о… эту очередь, которую мы кидаем на контроллер, если она более длинная, то контроллер и планировщик сможет лучше делать свою задачу по переупорядочиванию, построить очередь запросов оптимальнее. Если она более короткая, то у нас, например, read с диска будет быстрее, потому что мы не ждем переупорядочивания.
Read_ahead – это, когда мы читаем какой-то блок с диска, то мы читаем еще и следующие сколько там. Здесь у нас просто переменная, которая задает, сколько нам читать. В частности, в InnoDB более сложный механизм, который адаптировано пытается понять, как у нас идет нагрузка, и подстроиться под префетчинг.
Если вы пишите свои приложения, тут есть ряд системных вызовов, которые вам позволяют лучше контролировать сброс данных на диск.

Сеть. У нас есть zero-copy вывод, к сожалению, у нас нет zero-copy вводa. Т.е. если у нас есть htp сервер, который находится в таких условиях, что у него очень интенсивный ввод, и он его фильтрует, либо какой-то user space firewall строите, то вы не можете сильно оптимизировать.
Второй недостаток этого подхода в том, что вверху в user space написано два системных вызова, т.е. для каждого вывода вам нужно позвать два системных вызова и сделать, соответственно, больше контекстных свичей. Здесь есть бенчмарк, который сделал сам Джен Саксбург, который, собственно, все это имплементировал. Здесь используется размер 64 Кб. На 64 Кб у акселерация очень сильная, в 4-5 раз. Если мы сократим размер, например, до 100 байт, наш zero-copy вывод будет хуже, чем с копированием всего большего количества системных вызовов.
Еще один недостаток, неудобство работы. Когда вы берете страницу, отдаете ее в zero-copy, ваша страница данных напрямую помещается в TCP/IP стек ОС. Вы отдали, и вы не знаете, когда TCP отправит данные. Он может делать ретрансмит и т.д., вы не знаете, когда можно будет переиспользовать эту область памяти. Т.о., используется подход двойного буфера. Если у вас, например, 64 Кб буфера отправки TCP, то вы делает буфер 128 Кб. И вы можете быть точно уверены, что если вначале вы записали полностью 64 Кб, пошли уже на вторые 64 Кб, и сокет не блокируется на этих вторых, то, значит, он уже что-то отправил, и вы можете начать использовать первую часть буфера. Т.е. двойной буфер обеспечивает то, что TCP буфер будет полностью протолкан до того, как мы будем переиспользовать эти данные снова.
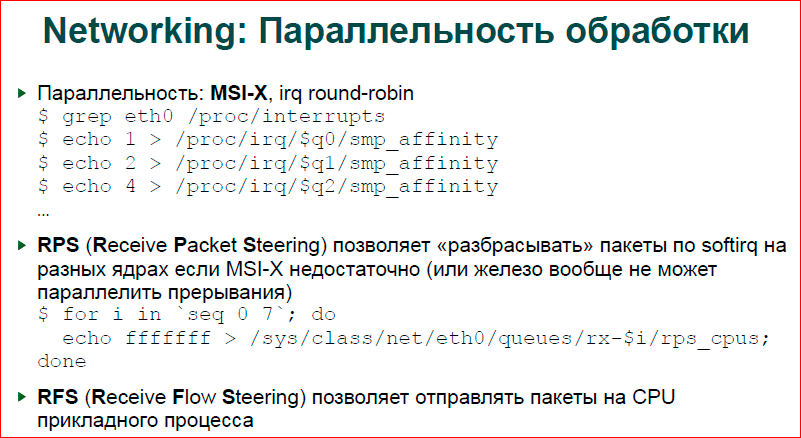
Параллельность обработки. На самом деле, эта информация теряет актуальность, потому что современные сетевые адаптеры уже действительно дешевые и имеют варианты уже с хардварной параллелизацией. Т.е. если сделать grep /proc/interrupts на ethernet карту, то вы увидите не одно прерывание для нашего адаптера, а 16, 24, 40, много, в общем. Это, как раз, очереди этого адаптера. Т.е. мы можем на сетевую обработку использовать до 20-40 прерываний, т.о., если мы на каждое ядро положим по отдельному прерыванию, то у нас все ядра будут параллельно работать.
Есть cофтварная реализация RPS, т.е. если ваш адаптер имеет всего одну очередь, то вы можете воспользоваться софтварной реализацией, и уже ОС, имея одно прерывание, решит на какое ядро отдать обработку этого пакета. Преимущества софтварной реализации в том, что там неплохой хэш читается, т.е. хардварная реализация считает хэш от IP-адреса назначения и отправки, двух портов TCP, и плюс прикладной протокол TCP, IGP и т.д. Эта пятерка используется в качестве хэша для выбора ядра. По идее, должно быть так, но, по всей видимости, по умолчанию адаптер использует довольно плохую хэш-функцию, и если у вас достаточно много ядер, вы сделали много очередей, то вы часто увидите неравномерную нагрузку ядер. RPS, с другой стороны, использует достаточно хорошие хэш-функции и позволяет вам лучше распределить трафик.

Offloading. Если вы можете использовать Jumbo frames, используйте их, потому что ОС приходится намного меньше работать. Обработка каждого пакета в силу мощности стека очень дорога, и GRO и GSO помогают решить эту проблему немного другим способом. Если ваше приложение генерирует разные пакеты, например, по 64 байта, то ОС соберет все ваши пакеты в одну большую цепочку и эту цепочку разом отдаст на адаптер, и адаптер ее разом выплюнет. Как правило, GSO, GRO оперируют 64 Кб, и в принципе, вы можете рассчитывать, что если ваша прикладная программа генерирует данные небольшими кусочками, то на больших скоростях ОС их будет собирать и будет работать с участками в 64 Кб. Другое дело, что это не настоящие пакеты как в случае с Jumbo frames, a это именно сегменты, которые некоторые пути ОС проходят намного быстрее за счет того, что это собранная цепочка.
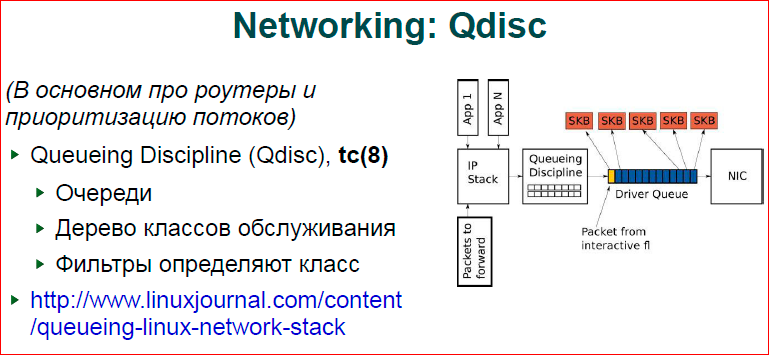
По поводу Qdisc – это больше для роутеров. Если вы строите на Linux’е сложную систему, например, у вас есть роутер, и вам нужно дать определенную полосу всем wi-fi юзерам, а каких-то юзеров пустить на большем качестве обслуживания. Вы можете построить несколько дисциплин очередей, каждой дисциплине определить параметры, как вы определите, например, пул IP-адресов, маска сетевая – это будет у вас одна дисциплина с одним качеством обслуживания, другие адреса будут с другим качеством обслуживания и т.д. В частности, она хорошо решает проблему. Если у вас есть какие-то данные, например торренты (на картинке синие пакеты) – массивная обработка данных, а желтенький один пакет – это ваш скайп, ваш голос, вы не можете ждать долго, пока ваш пакет с голосом пройдет всю цепочку вместе с торрентом. Qdisc позволяет назначить более высокий приоритет и пропихнуть пакет раньше, чем менее приоритетные. Есть хорошая статья в livejournal по этим дисциплинам – www.linuxjournal.com/content/queueing-linux-network-stack.

Sysctl я включил в презентацию просто потому, что это должно быть. В целом, любая статья на том же хабре по тому, как оптимизировать nginx, обязательно скажет о том, что есть такие sysctl, их везде можно найти, и мы можем это делать.
Контакты
» ak@natsys-lab.com
» Блог компании NatSys Lab.
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior. Сейчас мы активно готовим конференцию 2016 года — в этом году HighLoad++ пройдёт в Сколково, 7 и 8 ноября.
В этом году Александр Крижановский продолжит для нас экскурс в внутренности операционной системы (вообще, Александр один из самых серьёзных специалистов в России в этой области) — "Linux Kernel Extension for Databases".
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Комментарии (45)

kashey
23.09.2016 19:42+16Как я скучал по таким статьям!

se11er
23.09.2016 22:48+9По чему именно вы скучали?
Может у меня недостаточно квалификации, или я вообще попал в топик в котором не должен находиться, но вот этот фрагмент (взят исключетельно для иллюстрации) меня ввел в ступор:
Недавно меня спрашивали о том, что «вот у нас есть 20 тыс. потоков, и их человек хотел написать быструю очередь, которая позволяла бы быстро вставлять и забирать данные. Оно так не будет работать, т.е. будет все очень медленно. 20 тыс. потоков будут кэшировать, они будут безобразно дергать атомарные инструкции, данные, и все будет очень медленно. Соответственно, если вы пишете код для NUMA системы, вы считаете, что у вас есть маленький кластер внутри вашей машины, внутри одной железки, и вы строите свой софт так, что у вас маленькая машинка, один процессор, она многоядерная, там 8-10-16 ядер, она делает что-то свое локально и иногда общается с чужими. А дальше, если вы объединяете кластер из машин, у вас будет еще более медленная коммуникация. У вас получается такая иерархия кластеров – более быстрый кластер и более медленные кластера.
Здесь же ничего не написано по сути. И так весь текст.

RPG18
23.09.2016 23:43По сути было сказано выше про spinlock и NUMA. Атомарная инструкция заставляет обращаться в память, плюс еще блокировка памяти. В общем происходит насилие шины.
stargazr
24.09.2016 16:09+1Ну уж, по крайней мере, не все эти жалобы старых пердунов о том, что, видите ли, их коллеги-хипстеры айфоны обсуждают и на самокатах катаются (был тут и такой пост, да), и как там очередную пищалку-светилку на ардуино сделать, или вообще полная ахинея в духе «слышал а че за хрень такая opengl? — не, не слышал» (да, это почти дословно).
Сама статья, кстати, очень содержательная, спасибо автору.


pda0
23.09.2016 21:23+1Второе – то, что десктопы сейчас достаточно маломощные, это какой-то обычный один процессор, немножко ядер, немножко памяти, никакой NUMA, т.е. все очень просто, все очень маленькое.
Не плохо бы автора принудительно пересадить на пару лет за 486 DX2 с 8 Mb. (Мы же не звери, чтобы сразу за 286 с одним метром.) А потом поспрашивать насчёт маломощности.third112
23.09.2016 22:24+3Думаю, что если автора, как и любого другого хорошего специалиста, пересадить сейчас на 286, то особых проблем у них не возникнет. Просто они вернутся к подходам и методам, которые зарекомендовали себя в эпоху 286 :) Говорят, что и сейчас такое встречается: где-то недавно читал, что одна европейская сеть супермаркетов вернулась к MS DOS и соответственному железу. Они посчитали, что для элементарных кассовых операций этого достаточно. Не уверен на 100% в правдивости этой инфы, однако ИМХО в любом случае в ней полезная идея: крутой комп в супермаркете, который периодически зависает из-за невысокой квалификации кассирши — не всегда лучшее решение.
Barafu
24.09.2016 20:48+3Думаю, что рабочий ПК на 486 сейчас стоит больше, чем рабочий ПК на каком нибудь несчастном производящемся селероне, и оба они дороже Raspberry. На Raspberry я бы и посадил кассиров и прочих операторов блокнота.
У сети магазинов же, скорее всего, есть ПО под DOS для работы, но нет исходников, вот они и посчитали, что проще интегрировать DOS, чем переписывать ПО под винду. Про Linux в таких местах обычно даже не знают.third112
25.09.2016 01:32Ok, возможно. К Raspberry стоит присмотреться, если цены такие, как в рувики, то м.б. можно соорудить, что-то забавное. Спасибо.

LynXzp
25.09.2016 15:29Укрзалізниця: DOS приложение в DOSBox под Linux.
Сильпо (укр. сеть суперамаркетов) — приложение на Delphi (узнаю по дефолтным иконкам).
Но если честно меня печалят больше всего синие экраны на банкоматах и когда выбивает приложение в терминале приема денег — то можно увидеть «рабочий стол» Windows. По сравнению с ними — в «Укрзалізниці» продвинутые админы (и ни одного программиста).Barafu
25.09.2016 15:47+3я когда по пол-часа ждал девушку на платформе электрички, делал так: легонько пинал раздолбанную розетку, от чего платёжный терминал перезагружался. Когда мелькуал десктоп, бысто-быстро щёлкал по «мой компьютер» на рабочем столе, отчего поверх платёжного приложения открывался проводник. Оттуда можно попасть в ишак, в нём открыть msn или как его, оттуда по рекламе пройти на арстехнику.
Когда подружка приезжала, я снова шевелил розетку, и терминал загружался в нормальный режим.
Единственная на моей памяти польза от винды и от рекламы. А нет, ещё я таким же способом на кинотеатре (не домашнем) в Angry Birds играл, пока админ не спалил. Потом он играл.
Pakos
26.09.2016 09:27Зависит от номенклатуры. Делали номенклатуру в 40к изделий на 8088 с 512к, но это была боль, т.к. там не только наименования, но и учёт прихода-наличия-расхода с отчётами «что бы закупить». Современные счётные задачи на таком просто не решить(в память не влезет миллион замеров по сотне байт просто, а читать с диска — это в этом веке не закончить). А терминал забрать код-запросить сервер-отдать полученное на экран можно хоть на ардуине делать, на то он и терминал.

Grox
23.09.2016 22:50Я думаю, что автор сравнивал здесь десктопы с серверами. И когда имеешь дело с десятками ядер и сотнями гигабайт оперативки, то десктопы, вдруг, становятся маломощными.
third112
23.09.2016 23:07Бывают случаи, когда рабочие станции десктопами обзывают, а если вникнуть в детали, то они составляют мощный кластер ;)

robert_ayrapetyan
23.09.2016 21:28>>Это табличка данных от одного из пионеров построения больших датацентров по фильтрации трафика, они работают на обычном Intel’овском железе без всяких сетевых акселераторов, и люди делают собственную ОС.
А поподробнее? Что за пионеры и ОС?
third112
23.09.2016 22:04+2ИМХО очень много информации для размышления, спасибо! Но позвольте немного критики по структуре статьи — на мой взгляд, не хватает выводов. Однако формат публикации позволяет добавить их, например, в ответ на данное сообщение. Мне кажется, что это будет интересно большинству читателей.
Еще раз большое спасибо за интересную статью.
andybelo
23.09.2016 22:49-2Очевидно, что без нового железа для серверов ничего не сдвинется. Но Интелу некогда, АМД денег нет. Арм — єто не их профиль. Значит Китай всех обгонит.
nckma
23.09.2016 23:14Ну Интел купила Альтеру. Будут встраивать плис на платы серверов.
Это поможет?andybelo
24.09.2016 09:33Понимаете, грузовик нужен что бы возить много тонн. Траффик юзверей и серверов — более 99% — видеострим.
1. Зачем там HTML (думаю и TCP ни к чему)?
2. Зачем для обработки видео х86?
3. У Интела мало спецов по видео, ибо были не особо нужны, да и в Альтере, а теперь поезд уехал.
4. Скорее наоборот, на плате плис будут «атОмы» рисовать, ибо чую, это дешевле.
А уж про сервера я и не говорю. Передача клиентам миллионов разных видео — это главная стоимость серверов.
Если в Альтере+Интел это понимает большинство, то поможет, ещё не было, что б не помогло. А на нет суда нет.
lizarge
24.09.2016 00:40Хорошая статья. Жаль что следить за этим практически не вероятно, например даже актуальный курс по оптимизации работы с памятью с учетом архитектуры железа (на момент курса информация была уже устаревшая) имеет такой обьем информации что изучать это на уровне прикладной разработки, почти не возможно.

stalkerg
24.09.2016 01:44+1В больших базах данных – Postgres, MySQL, InnoDB – в основном, используют O_DIRECT
Для справки оставлю тут: Postgres не использует O_DIRECT, а использует простой write и если надо сбросить несколько страниц из буфер менеджера делает mmap (но это редко).
Но да… у него свой Clock-SI буфер менеджер (на самом деле ещё RLU для CLOG к примеру).
Saffron
24.09.2016 05:07+18О чём речь? Операционная система с некооперативной многозадачностью имеет оверхед? Логично. Давайте вынесем функции ОС в юзер спейс? Зачем же. Если вы оптимизируете железо для работы конкретно с одной единственной программой — то вам не нужна многозадачная ОС. Возьмите однозадачную. Ну или напишите сами, если не осталось ни одной. Там и кеши, и виртуальная память и всё-всё-всё будет управляться исходя из потребностей этой единственной программы, которую вам надо запустить.
А линукс такой, как он есть, потому что он создан многозадачным. Более того, задачи разные, значит нельзя оптимизировать ядро под один конкретный тип задач — нужно быть универсальным. В статье много рассказывается о том, какой громоздкий линукс, но так и не сказано, а где конкретно ошибка, что можно поменять к лучшему. Может быть какие-то алгоритмы не оптимальны? Или нужна другая архитектура? Нет, всё что мы слышим, это что одна единственная задача, запущенная на голом железе, будет работать быстрее чем если бы проходила через прослойку ОС. Удивили.DistortNeo
24.09.2016 20:13Согласен. Задача многозадачных ОС общего назначения — создание универсальных механизмов, позволяющих организовать совместный доступ задач к разделяемым ресурсам. Логично, что для этого необходимо использование определённого уровня абстракций от железа с ненулевыми накладными расходами. Но для подавляющего большинства задач эти накладные расходы действительно получаются низкими. Более того, есть такой момент, как стоимость разработки. Чем ниже уровень абстракции, тем выше стоимость разработки.
Если специфика задачи такова, что даже простое копирование данных в памяти уже является узким местом, то это не проблема конкретной ОС, это ваша проблема. Используйте ту ОС, которая больше подходит для вашей задачи, либо делайте свои реализации стека TCP/IP и т.д. Не зря же написано про «1 задача — 1 сервер».
P.S. Для работы на скоростях 10 гбит/с и выше вообще используется FPGA.Saffron
25.09.2016 02:36Так это одна задача очень хочет прямого доступа к поторохам. Например, к системе управления виртуальной памятью, потому что она предоставляет ряд интересных возможностей вроде пометок памяти, вызова прерываний при доступе, которые можно использовать для увеличения эффективности работы с памятью.
Авторы таких программ готовы к погружению в дебри. Так что им скорее нужна полу-библиотека, полу-ОС, которая имеет небольшой набор выполняемых функций, и даёт подменить дефолтное поведение прикладной программе, которая может поставить свои собственный процедуры вместо системных.
sbnur
24.09.2016 07:42+1Любая современная вещь — плохая штука, котороя вскоре изменится, модифицируется, исчезнет наконец
Поэтому броскость преамбулы — не более чем броскость
Является ли современная организация ОС тупиковой — скорее всего нет, тем более, что все упирается в железо, точнее в две рабочие лошадки — софт и хард, которые помимо общего тягла взаимно подтягивают друг друга.
Пока не видно особых проблем, связанных с ОС
Другое дело изменить концепцию ОС
Например, в свое время я задумывался об ОС по типу муравейника, где ядро, как матка, генерирует необходимые обработчики в каждый момент времен, которые выполнив свои задачи, исчезают, то есть структура ОС пластична в зависимости от конкретной ситуацииthird112
25.09.2016 02:01Любая современная вещь — плохая штука, котороя вскоре изменится, модифицируется, исчезнет наконец
Согласен.
Является ли современная организация ОС тупиковой — скорее всего нет, тем более, что все упирается в железо, точнее в две рабочие лошадки — софт и хард, которые помимо общего тягла взаимно подтягивают друг друга.
ИМХО софт давно и сильно отстает от харда. Многопоточность никак освоить многие компании не могут, но все делают вид (ИМХО) :)
Пока не видно особых проблем, связанных с ОС
ИМХО есть. Одна из первых — малая надежность. Не говорю про бортовые ОС, где сбой = фатальный исход. Но и в быту частые зависы и прочие проблемы ОС раздражают и… снижают прибыль всяких лавочек, магазинов, банков и т.д. В «Виндах» ИМХО очень мало настроек при установке. Чтобы сделать минимальную версию нужно много чистить после установки. В линуксах можно делать чудеса, но и там очень долго делать чудо. В общем везде встает куча ненужного для целей конкретного пользователя хлама, который зачастую мешает.
Другое дело изменить концепцию ОС
Хорошая идея! Не слабо такое в линуксе сделать? ;)
Например, в свое время я задумывался об ОС по типу муравейника, где ядро, как матка, генерирует необходимые обработчики в каждый момент времен, которые выполнив свои задачи, исчезают, то есть структура ОС пластична в зависимости от конкретной ситуацииDistortNeo
25.09.2016 18:36Одна из первых — малая надежность
Не путайте надёжность операционной системы с надёжностью прикладного софта.
В подавляющем большинстве случаев в ненадёжности виноват именно софт.third112
25.09.2016 21:29Частый случай: два компа похожей конфигурации, на них одинаковые прикладное ПО и ОС. На одном ОС встала нормально, а на другом криво. На первом проблем почти нет, а на втором постоянные проблемы. Беда в том, что многие ОС норовят встать криво. Эта тенденция («норов») и называется ненадежностью. К сожалению, если ОС встала нормально, это не значит, что ее не искривит со временем :(
Pakos
26.09.2016 09:37+2Зачастую низкая надёжность ОС == низкая надёжность драйверов, именно они зачастую вызывают BSOD'ы и KP.
К чему претензии в WIN — это к системе апдейтов, которые очень громоздкие, обновляют одни файлы при разных апдейтах, начинают конфликтовать сами с собой и вообще перестают устанавливаться, загнав систему обновления в какой-то циклический маразм. Более простой вариант «последняя версия библиотек для W7.Pro.x64» как аналог пакетов в Linux была бы предпочтительней по крайней мере по надёжности.
stalkerg
24.09.2016 12:14+2Во всей этой истории меня напрягает только дублирование функционала.
К примеру хотелось бы как то иметь возможность переиспользовать буфер менеджер из ядра эффективным способом.
glowingsword
24.09.2016 21:00Спасибо за интересную и содержательную статью. После "воды" и материалов скорее рекламного, чем информативного характера данная статья как бальзам на душу. Хабр опять торт!

stigory
25.09.2016 04:46+10Нда. Читать стенограмму живого выступления без промежуточного редактирования и причесывания текста сложно. У статьи получился очень невнятный и ломанный язык. Но, мысли, высказываемые в докладе, позволяют простить все. Очень интересно было читать.

lexy
26.09.2016 17:50-1во! а я как раз хотел спросить — меня одного коробят «ивенты», «стейт машины» и «корутины»?
хорошая статья, но автор — в России живешь!

Seboreia
28.09.2016 18:18Соглашусь, что читать статью трудновато, хотя внизу статьи и имеется приписка «расшифровка выступлений». Что же тогда до расшифровки было?)

cdriper
27.09.2016 11:04либо мы используем какой-то фреймворк потоковый, например, Boost.Asio
Asio, например, расшифровывается как «asynchronous I/O» и никакой это не фреймворк и никакой не потоковый.
Доклад сумбурный, беспорядочный поток сознания.

handicraftsman
Поддержку многих ненужных вещей можно выпилить во время сборки ядра. Так что linux не такой уж и громоздкий.