
The distinguishing characteristic of industrial-strength software is that it is intensely difficult… the complexity of such systems exceeds the human intellectual capacity… we may master this complexity, but we can never make it go away.
Grady Booch
Давайте вернемся на несколько десятилетий назад и взглянем на то, как выглядели типовые программы тех лет. Тогда доминировал Императивный подход. Напомню, что название он получил благодаря тотальному контролю программы над процессом вычислений: в программе четко указывается, что и когда должно быть выполнено. Словно набор приказов Императора. Большинство операционных систем предлагали для написания исполняемых программ именно этот подход. Он широко используется и по сей день, например при написании различного рода утилит. Более того, с данного подхода начинается изучение программирования в школе. В чем же причина его популярности? Дело в том, что Императивный стиль очень прост и понятен человеку. Освоить его не сложно.
Взглянем на пример. Я выбрал Pascal для придания коду архаичности. Программа выводит приглашение ввести значение для переменной «x», считывает введенное значение с консоли, затем то же для переменной «y», в конце выводит сумму «x» и «y». Все действия инициирует программа — и ввод, и вывод. В строгой последовательности.
var
x, y: integer;
begin
write('x = ');
readln(x);
write('y = ');
readln(y);
writeln('x + y = ', x + y);
end.
Теперь немного перепишем код и введем ряд абстракций (да, термин «абстракция» не является собственностью ООП), для того чтобы подчеркнуть основные действия программы.
var
x, y: integer;
begin
x := receiveArg;
y := receiveArg;
sendResult('x + y = ', x + y);
end.
На самом деле ввод абстракций там, где без них вроде бы можно было бы обойтись, — еще один инструмент для борьбы со сложностью; это все та же инкапсуляция, пусть здесь нет ни классов, ни модификаторов видимости. Позже мы еще вспомним про этот код. А пока двинемся дальше.
Эволюция операционных систем привела к появлению графических оболочек, и императивный стиль перестал быть доминирующим. ОС с графической оболочкой предлагают совсем иной подход к структуре программ, т.н. event-driven подход. Суть подхода в том, что программа большую часть времени простаивает, ничего не делает и реагирует лишь на «раздражители» со стороны операционной системы. Дело в том, что графический интерфейс дает пользователю одновременный доступ ко всем элементам управления окна и мы не можем опрашивать их последовательно, как это происходит в императивных программах. Напротив, программа должна оперативно реагировать на любые действия пользователя с любой частью окна, если это предусмотрено логикой или это ожидается пользователем. Подход event-driven — это не выбор разработчиков прикладных программ, это выбор разработчиков ОС, т.к. такая модель позволяет более эффективно использовать ресурсы машины. Кроме того, ОС берет на себя обслуживание графической оболочки и в этом смысле является «толстым» посредником между клиентом и прикладными программами. На самом деле технически прикладные программы остаются императивными, т.к. они имеют императивное «ядрышко», т.н. message loop или event loop. Но в большинстве случаев это ядрышко является типовым и скрыто в недрах используемых программистами графических библиотек.
Является ли event-driven подход эволюционным развитием разработки ПО? Скорее это необходимость. Просто так оказалось проще и экономичнее. У этого подхода есть известные недостатки. Прежде всего, он менее естественен, чем императивный подход, и приводит к дополнительным накладным расходам, но об этом чуть позже. Заговорил я об этом подходе вот почему: дело в том, что данный подход распространился далеко за пределы прикладного ПО. Именно так устроен внешний интерфейс большинства серверов. Грубо говоря, типовой сервер декларирует список команд, которые он может выполнить. Как и прикладная графическая программа, сервер простаивает до тех пор, пока извне не придет команда (event), которую он может обработать. Почему же event-drive подход перекочевал в серверную архитектуру? Ведь тут нет ограничений со стороны графической оболочки ОС. Думаю, что причин несколько: это в первую очередь особенности используемых сетевых протоколов (как правило, соединение инициируется клиентом) и все та же потребность в экономии ресурсов машины, потребление которых легко регулировать в event-driven подходе.
Response onRequest(Request request) {
switch (request.type) {
case "sum":
int x = request.get("x");
int y = request.get("y");
return new Response(x + y);
...
И вот здесь я бы хотел обратить внимание на один из существенных недостатков event-driven подхода — это большие накладные расходы и отсутствие в коде явных абстракций, отражающих логику поведения сервера. Прежде всего я имею в виду взаимосвязь между различными командами, которые декларирует сервер: не все из них являются независимыми, некоторые должны выполняться в определенной последовательности. Но т.к. при использовании event-driven не всегда удается отразить взаимосвязь между разными операциями, появляются накладные расходы в виде восстановления контекста для выполнения каждой операции, и в виде дополнительных проверок, которые нужны, чтобы убедиться, что данная операция может быть выполнена. Другими словами, в случае, если протокол, реализуемый сервером, сложен, то экономия ресурсов от использования event-driven подхода становится не такой очевидной. Но не смотря на это, есть и другие веские причины его использования: языковые средства, стандарты и используемые библиотеки не оставляют разработчику выбора. Однако дальше я хочу поговорить про важные изменения, которые произошли в последние годы, и про то, что данный подход неплохо вписался в новую реальность.
Здесь я должен отметить, что императивный стиль также используется при написании серверного кода: он вполне подходит для p2p соединений, либо в программах «реального времени», например в играх, где объем используемых ресурсов ограничен, и очень важна скорость реакции со стороны сервера.
for (;;) {
Request request = receive();
switch (request.type) {
case "sum":
int x = receiveInt();
int y = receiveInt();
send(new Response(x + y));
break;
...
Вспомните код на Pascal, в который я добавил операции receiveArg и sendResult. Согласитесь, что он очень напоминает то, что мы видим в данном примере: мы последовательно запрашиваем аргументы и отправляем результат. Разница лишь в том, что здесь роль консоли играет сетевое соединение с клиентом. Императивный стиль позволяет избавиться от накладных расходов при обработке связанных операций. Однако без использования специальных механизмов, о которых речь пойдет позже, он более агрессивно эксплуатирует ресурсы машины, и непригоден для реализации серверов, обслуживающих больше количество соединений. Судите сами: если в event-driven подходе поток выделяется на отдельную операцию, то здесь поток выделяется как минимум на сессию, время жизни которой существенно больше. Спойлер: агрессивное использование ресурсов в Императивном подходе — устранимый недостаток.
Теперь взглянем на «типичную» реализацию сервера — код ниже не связан с каким-либо фреймворком и отражает лишь схему обработки запросов. За основу я взял процедуру регистрации нового пользователя с подтверждением через SMS-код. Пусть эта процедура состоит из двух связанных операций: register и confirm.
Response onReceived(Request request) {
switch (request.type) {
case "register":
User user = registerUser(request);
user.confCode = generateConfirmationCode();
sendSms("Confirmation code " + user.confCode);
return Response.ok;
case "confirm":
String code = request.get("code");
User user = lookupUser(request);
if (user == null || !Objects.equals(code, user.confCode)) {
return Response.fail;
}
return user.confirm() ? Response.ok : Response.fail;
...
Пробежимся по коду. Операция register. Здесь мы создаем нового клиента, используя данные из реквеста. Но давайте подумаем, что включает в себя процесс создания клиента: это, потенциально, серия обращений к одной или нескольким внешним системам (генерация кода, отправка SMS), операции с диском. К примеру, операция sendSms, вернет нам управление лишь после того, как SMS сообщение с кодом будет успешно отправлено пользователю. Обращения к внешним системам (время доставки запроса, время его обработки, время передачи результата обратно) и операции работы с диском занимают время, и будут приводить к простоям текущего потока. Обратите внимание: мы привязываем сгенерированный код к клиенту (поле confCode). Дело в том, что после обработки данного реквеста мы покинем обработчик, и все локальные переменные будут сброшены. Нам же необходимо сохранить код для последующего его сравнения, когда поступит запрос confirm. При его обработке мы первым делом восстанавливаем контекст выполнения. Это те самые накладные расходы, о которых я говорил.
Синхронная обработка запросов, как в нашем примере, связана с обилием блокирующих операций, приводящих к простою ценного системного ресурса. И все бы ничего, но к обслуживающим системам предъявляются все большие требования по пропускной способности и времени отклика. Простои системных ресурсов становятся непозволительной роскошью. Давайте взглянем на диаграмму.
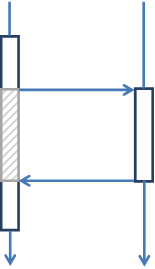
Здесь я изобразил блокирующий вызов. Заштрихованный участок это простой вызывающего потока. Существенен ли он? Вспомните размеры и количество таймаутов, используемых в вашей системе. Они красноречиво говорят вам о величине возможного простоя. Речь идет не о миллисекундах, а об десятках секунд, а иногда и о минутах. При нагрузке 1000 TpS, простой в 1 секунду — это 1000 операций, на обработку которых был выделен дополнительный ресурс.
Какие же решения предлагает нам индустрия для увеличения пропускной способности и уменьшения времени отклика? Разработчики железа, к примеру, предлагают многоядерность. Да, это расширяет возможности отдельно взятой машины. Event-driven подход, благодаря масштабируемости, легко утилизирует новый ресурс. Но синхронная реализация обработчиков запросов делает использование потоков малоэффективным. И вот здесь на помощь нам приходят асинхронные вызовы.

Задача асинхронного вызова в том, чтобы инициировать выполнение операции и как можно скорее вернуть управление. Результат же операции мы получаем через callback функцию, которую передаем в качестве дополнительного параметра. Таким образом, сразу после такого вызова мы можем продолжить работу, либо завершить ее до тех пор, пока не будет получен результат. Давайте модифицируем наш пример и перепишем его в асинхронном стиле.
void onReceived(Request request) {
switch (request.type) {
case "register":
registerUser(request, user -> {
generateConfirmationCode(code -> {
user.confCode = code;
sendSms("Confirmation code " + code, () -> {
reply(Response.ok);
});
});
});
break;
...
Здесь я привел лишь одну операцию register. Но этого уже достаточно, чтобы увидеть основной недостаток асинхронного стиля: худшая читаемость кода, увеличение его размеров. Появления «лесенки» callback-ов, вместо серии синхронных вызовов. Данный пример выглядит сносно лишь благодаря лямбдам. Без них воспринимать асинхронный код было бы куда сложнее. Другими словами, язык Java недостаточно адаптирован к новым требованиям. В нем нет необходимых инструментов, делающих работу с асинхронным кодом более комфортным.
Как же быть? Есть ли способ сохранить комфорт работы с синхронным кодом, и при этом избавиться от его ключевых недостатков, используя асинхронные механизмы?
Да, такой способ есть.
Континуации
Континуации — еще один механизм управления ходом выполнения программы (в дополнение к циклам, условным ветвлениям, вызовам методов и пр.), позволяющий приостанавливать выполнение метода в определенной точке на неопределенный срок с высвобождением текущего потока.
Вот основные артефакты данного инструмента.
- Suspendable method — метод, исполнение которого может быть приостановлено на неопределенный срок, а затем возобновлено
- Coroutine/Fiber сохраняют стек при приостановке исполнения. Стек может быть передан по сети на другую машину для того, чтобы возобновить исполнение приостановленного метода там
- CoIterator позволяет создавать разновидность итераторов, называемых генераторами (реализован в библиотеке Мана)
Это далеко не полный список. Такие артефакты, как Channel, Reactive dataflow и Actor, также очень любопытны, однако это темы для отдельных статей. Здесь я рассматривать их не буду.
На данный момент континуации поддерживаются рядом Web-фреймворков. Общие же решения, позволяющие использовать континуации в Java, к сожалению, можно пересчитать по пальцам. До недавнего времени все они были по большей части кустарными (эксперимент) или сильно устаревшими.
- Jau VM — надстройка над JVM, «экспериментальный» проект (2005 год)
- JavaFlow — попытка создания капитальной библиотеки, не поддерживается с 2008 года
- jyield — небольшой «экспериментальный» проект (февраль 2010 года)
- coroutines — еще один «экспериментальный» проект (октябрь 2010 года)
- jcont — относительно свежая попытка (2013 год)
- Continuations library Матиса Мана — наиболее простой и удачный, на мой взгляд, солюшн для Java
Концепция, реализованная Маном, проста и легка в освоении. К сожалению, она на данный момент не поддерживается. Кроме того, буквально недавно недоступна стала и оригинальная статья, с описанием библиотеки.
Но не все так плохо. Господа из Parallel Universe, взяв за основу библиотеку Мана, переработали ее, сделав свою уже более увесистую версию — Quasar.
Quasar унаследовал у библиотеки Мана основные идеи, развил их, и добавил к ней некоторую инфраструктуру. Кроме того, на данный момент это единственное такое решение, работающее с
Что нам дает данный инструмент? Прежде всего, мы получаем возможность писать асинхронный код, не теряя при этом наглядности синхронного. Более того, теперь мы можем писать серверный код в императивном стиле.
?
for (;;) {
Request request = receive();
switch (request.type) {
case "register":
User user = registerUser(request);
int confCode = generateConfirmationCode();
sendSms("Confirmation code " + confCode);
reply(Response.confirm);
String code = receiveConfirmationCode();
if (Objects.equals(code, confCode) && user.confirm()) {
reply(Response.ok);
} else {
reply(Response.fail);
}
break;
...
Это пример все той же регистрации пользователя. Обратите внимание на то, что от парного реквеста register/confirm остался только один: register. confirm исчез, т.к. здесь он нам больше не нужен. В данной реализации минимум накладных расходов: весь контекст операции сохраняется в локальных переменных, нам не надо запоминать сгенерированный код, лукапить заново пользователя. После его регистрации, генерации кода и отправки СМС, мы просто ожидаем получения этого кода от клиента и ничего более. Не новый реквест с кучей лишних атрибутов, а всего лишь один код!
Как же это работает? Предлагаю начать с библиотеки Мана. Библиотека содержит всего несколько классов, основным из которых является Coroutine.
?
Coroutine co = new Coroutine(new CoroutineProto() {
@Override
public void coExecute() throws SuspendExecution {
...
Coroutine.yield(); // suspend execution
...
}
});
...
co.run(); // run execution
...
co.run(); // resume execution
Coroutine — это, по сути, оболочка для Runnable. Точнее, не для стандартного Runnndable, а для специальной версии данного интерфейса — CoroutineProto. Задача корутины — сохранять состояние стека в моменты приостановки исполнения вложенной задачи. Сами по себе корутины ничего не делают: выполнение вложенного когда инициируется методом run, который начинает либо возобновляет, после остановки, выполнение кода в методе coExecute. Управление из метода run возвращается после того, как метод coExecute закончит свою работу, либо приостановит ее, вызвав статический метод Coroutine.yield. О том, в каком состоянии находится метод coExecute можно узнать через вызов Couroutine.getState. Три метода — run, yield и getState, по сути, описывают весь значимый интерфейс класс Coroutine. Все очень просто. Обратите внимание на исключение SuspendExecution. Прежде всего, это маркер, указывающий на то, что метод может приостанавливаться. Особенностью библиотеки Мана является то, что данное исключение реально пробрасывается в момент приостановки (единственный «пустой» — без стека — экземпляр). Данный эксепшн нельзя «душить». Это одно из неудобств библиотеки.
Одно из применений корутин Ман увидел в создании особой разновидности итераторов: генераторы. По всей видимости, Мана (как и его предшественников) угнетал тот факт, что поддержка генераторов есть во многих языках, в т.ч. в C# (yield return, yield break). В свою библиотеку он включил специальный класс CoIterator, который реализует интерфейс Iterator. Для создания генератора необходимо пронаследовать CoIterator и реализовать абстракный приостанавливаемый метод run. В конструкторе CoIterator содается корутина, которой «скармливается» абстрактный метод run.
?
class TestIterator extends CoIterator<String> {
@Override
public void run() throws SuspendExecution {
produce("A");
produce("B");
for(int i = 0; i < 4; i++) {
produce("C" + i);
}
produce("D");
produce("E");
}
}
После того, как идея, заложенная Маном в его библиотеку, становится понятна, освоение Quasar не составляет труда. В Quasar использована немного иная терминология. К примеру, Fiber используемый в Quasar в роли корутин, является, по сути, облегченной версией потока (термин, вероятно, позаимствован из Win API, где файберы присутствуют довольно давно). Использовать его так же просто, как и корутины.
Fiber fiber = new Fiber (new SuspendableRunnable() {
public void run()
throws SuspendExecution, InterruptedException {
...
Fiber.park(); // suspend execution
...
}
}).start(); // start execution
...
fiber.unpark(); // resume execution
Здесь мы видим уже знакомый нам SuspendExecution. Однако в Quasar он честно исполняет роль маркера, и не обязателен. Вместо него можно использовать аннотацию @Suspendable.
?
class C implements I {
@Suspendable
public int f() {
try {
return g() * 2;
} catch(SuspendExecution s) {
assert false;
}
}
}
Таким образом, мы получаем возможность создавать suspendable реализации практически любых интерфейсов, чего не позволяла нам делать библиотека Мана, требующая наличия маркерного исключения.
В библиотеке Quasar есть все необходимое, для «превращения» асинхронных интерфейсов в псевдосинхронные, обеспечивая клиентский код наглядностью синхронного и эффективностью асинхронного. Кроме того, экземпляры Fiber являются сериализуемыми, т.е. и их можно частично выполнять на разных машинах: начать на одной ноде, приостановить, передать по сети на другую ноду, и там возобновить выполнение.
Чтобы понять мощь файберов, давайте представим себе следующую ситуацию. Предположим, у нас имеется классический сервер с синхронной обработкой реквестов. Пусть, обрабатывая реквесты пользователей, наш сервер время от времени обращается к внешним ресурсам. К БД, например. Допустим, для работы сервера мы выделили 1000 потоков. И вот, в какой-то момент, наш внешний ресурс начал «подтупливать». В этом случае обработчики новых реквестов при обращении к этому ресурсу начнут подвисать, блокируя свои потоки. При высокой нагрузке на сервер пул потоков будет быстро израсходован, и начнутся реджекты. Если пул потоков общий, то реджектиться будут даже те реквесты, которые с внешним ресурсом ни как не связаны. При этом сервер может вовсе ничего не делать. Узким местом во всей нашей системе оказался внешний ресурс, который не справился с нагрузкой и вышел из строя.
Чем же нам помогут файберы? Файбер превращает наш синхронный обработчик в асинхронный. Теперь, при обращении к внешнему ресурсу, мы можем спокойно вернуть поток в пул, и запросить у машины лишь немного памяти для сохранения текущего стека выполнения. Когда от внешнего ресурса поступит ответ, мы возьмем в пуле свободный поток, восстановим стек и продолжим обработку реквеста. Красота!
Но тут надо сделать оговорку: это все сработает, только если интерфейс к внешнему ресурсу будет асинхронным. К сожалению, очень много библиотек предоставляют лишь синхронный интерфейс. Типичный пример JDBC. Но надо отметить, что Java движется в сторону асинхронности. Старые интерфейсы переписываются (NIO, AIO, CompletableFuture, Servlet 3.0), новые часто являются асинхронными изначально (Netty, ZooKeeper).
Конечно, очень хотелось бы видеть подвижки в этом направлении со стороны Oracle. Работа ведется, но очень медленно, и в ближайшей версии Java штатной поддержки континуаций ожидать не стоит. Будем надеяться, что библиотека Quasar не останется единственной в своем роде, и мы увидим еще много интересных решений, делающих написание асинхронного кода простым и удобным.
Комментарии (26)

Sirikid
19.10.2016 12:06+1Немного режут глаза слова «континуация», «солюшен» и некоторые другие. (Продолжение: goo.gl/A3UDjH, решение.)

wetnose
19.10.2016 12:45Наверное, вы правы. С терминологией я явно перегнул палку… Жаргонизмы, используемые в разговоре с коллегами, не всегда подходит для публикаций. Вероятно, проработав с Java слишком долго я перестал их замечать.
guai
20.10.2016 11:44Не слушайте их. Переводить термины — всё портить. Пусть будет не по-русски, зато понятно, чем гадать потом. Каноничный пример: thread (поток, нить) vs stream (поток) vs fiber(нить) — на английском 3 слова, на русском 2.
KeLsTaR
20.10.2016 17:57+1Fiber — это не нить, а волокно. И в этом контексте особенно, ведь такое название пошло именно от аналогии с тем, что нить состоит из волокон, точно так же как fiber не является полноценным thread`ом, а несколько fiber`ов вливаются и составляют один полноценный thread (передавая управление друг другу внутри него через suspendable points). Так что в русском 3 слова, точно так же, как и в английском.
guai
20.10.2016 18:55И часто вы встречали в статьях про файберы, чтоб их переводили как «волокно»? Я нет, ни разу не припоминаю.
Thread — тоже не поток, но таков устоявшийся перевод, чтоб ему пусто было.

zelyony
19.10.2016 12:57+1что делать, если клиент "завис" после получения СМС и не продолжает континуацию/фибру/корутину?
если таких клиентов накапливается тысячи, их фибры жрут память/стек.
как впендюрить механизм убивания "нежити"?
как решение: должны поддерживаться таймаутные операции — не ответил за пару часов, фибра убивается.
плюс объекты для фибр должны поддерживать псеводасинхронность: при обращении к ним фибра переключается на другую, пока эта не сможет продолжаться после "подводной" асинхронной работы.
пока имеем: псеводасинхронные операции с таймаутом. дальше.
как работать с GUI из фибры? обычно последние однопоточные в своих loopах.
в общем, должен быть целый фреймворк для работы с фибрами — те же файлы, сети, бд и тд, но в альтернативной реализации
Throwable
19.10.2016 13:37+1В свое время искал решение для написания логики бизнес процессов на Java, что есть по сути обычная StateMachine. Хотелось бы, чтобы flow был написан натуральными конструкциями, но при этом код был асинхронный. Необходимо было: а) корутины, б) сериализация состояния, в) возможность полного перехватывания после suspend. Ничего не нашел, что бы могло бы на 100% удовлетворить.
На мой взгляд основное неудобство Quasar в том, что выполнение файберов сильно завязано на FiberScheduler (которых фреймворк предоставляет два: FiberExecutorScheduler и FiberThreadPoolScheduler). Вся магия выполнения лежит в нем. Если я хочу кастомно выполнять файбер после прерывания Continuation.continueWith©, как это делается в javaflow, то придется писать свой Scheduler.
Другое основное неудобство всех корутинных библиотек на Java — жесткое трюкачество на уровне байткода: требуется настройка тулзов и добавление агентов в рантайм. Все это сильно усложняет архитектуру, дебагинг и тесты.
Так что лучше подождем, пока официально запилят корутины Kotlin-е.
P.S. Добавьте еще одну библиотеку, которая на самый момент наиболее продвинутая — https://github.com/offbynull/coroutines
Работает с Java8. Основной недостаток — приходится въявную таскать во все suspendable-методы объект Continuation.wetnose
19.10.2016 14:08При инициализации FiberExecutorScheduler можно указать свой executor. В простейшем случае это будет выглядеть так
FiberScheduler scheduler = new FiberExecutorScheduler("MyScheduler", Runnable::run)
В принципе, можно сделать синглтон. Излишеством, на мой взгляд, злесь является экземпляр FiberTimedScheduler, который создается в конструкторе FiberExecutorScheduler безусловно.Throwable
19.10.2016 16:00Файберы — это не совсем континуации, это suspendable threads. Для континуаций не нужны никакие экзекьюторы. Весь экзекьютор — это простой цикл:
Continuation d = Continuation.startWith(new MySuspendable());
while(d!=null) {
d = Continuation.continueWith(d);
}
т.е. фактически выполняются вручную, что дает полный контроль выполнения, и что как бы и требуется для задачи: при необходимости можно сериализовать и сохранить состояние в БД, при получении внешнего месседжа загрузить континуацию и продолжить.
А поскольку файберы подобно тредам должны выполняться автоматически, им нужен внешний шедулер, который будет контролировать их выполнение. И чтобы свести случай к предыдущему, нужно писать свой шедулер. А в API квазара это как бы не совсем предусмотрено.

dougrinch
19.10.2016 22:26Ха, только успел подумал что надо посоветовать переходить на котлин, как на тебе:
Так что лучше подождем, пока официально запилят корутины Kotlin-е.
lany
20.10.2016 07:15Вроде уже более-менее стабильны они, хотя официального релиза не было. Но Котлином люди игрались задолго до того как вообще версия 1.0 вышла. Смело берите свежий EAP и пробуйте.
Throwable
20.10.2016 09:43Там пока корутины не сериализуемы. Обещают подумать над темой в будущих релизах.
lany
20.10.2016 09:55А сильно надо?
Throwable
20.10.2016 20:55Более, чем можно себе представить.Если мы хотим при помощи корутин определять долгоиграющие StateMachine-ы, то состояние после suspend-а хотелось бы персистить, а перед resume-ом восстанавливать. Юзкейсов десятки, от всяких WebFlow, BPM до high availability.

VVit1
19.10.2016 14:58var user = await registerUser(request); user.confCode = await generateConfirmationCode(); Task.Run(()=>sendSms("Confirmation code " + user.confCode)); return Response.ok;
То чувство когда как шарпист слегка злопыхаешь над мучениями жавистов в случае асинхронного кода))wetnose
19.10.2016 15:10Имненно для борьбы с комплеском неполноценности, провоцируемым оператором await в C#, был создан Java проект coroutines, о котором я не упомянул в статье.
Вообще, надо сказать, C# в плане эволюции является полным антиподом Java: язык очень агрессивно модифицируется. Иногда кажется, что скоро не останется слов английского языка, которые бы не были ключевыми словами в C#. Java в этом плане крайене консервативна. И мне такой подход ближе. В индустрии слишком сильно влияние моды, и поспешная адаптация языка может вызвать проблемы в будущем.withoutuniverse
20.10.2016 14:00Чем плох Future? Идея такая же — выполнить в другом потоке и подождать результат обратно в текущий.
wetnose
20.10.2016 15:41Дело не в Future, дело в том, как выглядит код, который его использует. Часто серверный код, выполненный в классическом стиле, выглядит дольно сложным. Но когда ты начинаешь писать асинхронный код, то понимаешь, насколько более сложным и путанным он может стать.

LEQADA
19.10.2016 15:35+1Было бы лучше, если бы первой строчкой статьи шло определение термина «континуация». А то статья вроде на конкретную тему по Java, а начинается с какой-то философии.
wetnose
19.10.2016 15:38Я посчитал, что здесь важнее понимать, зачем все это нужно. Сами решения второстепенны. На мой взгляд, довольно важному вопросу уделяется недостаточно внимания. Собственно поэтому я и начал с философии…

igor_suhorukov
20.10.2016 16:03Смотрел как-то на Quasar и запомнились 2 вещи — javaagent и использование в тестах Nanocloud, который очень часто использовал на работе.
MzMz
java.util.concurrent.CompletionStage (и RxJava как развитие)
Googolplex
Угу. CompletionStage это по сути Future в других языках. В Scala, например, Future'ы являются основной абстракцией для описания асинхронного кода, и на них определено множество комбинаторов для объединения и обработки асинхронных значений. Кроме того, с библиотеками типа scala-async код на Future'ах выглядит почти неотличимо от синхронного кода без них.
Кстати, в русскоязычной литературе continuation переводится как "продолжение".
Googolplex
Но, справедливости ради, scala-async и аналогичные механизмы в других языках в своей теоретической основе имеют как раз продолжения. Например, scala-async из
async-блоков создаёт конечный автомат из продолжений, где код "после" вызововawaitавтоматически преобразуется в продолжение, которое будет вызвано после завершения асинхронного вызова.