
Знакомьтесь: Ceph
Ceph — это программно определяемая распределенная файловая система с открытым исходным кодом, лишенная узких мест и единых точек отказа, которая представляет из себя легко масштабируемый до петабайтных размеров кластер узлов, выполняющих различные функции, обеспечивая хранение и репликацию данных, а также распределение нагрузки, что гарантирует высокую доступность и надежность. Система бесплатная, хотя разработчики могут предоставить платную поддержку. Никакого специального оборудования не требуется.
При выходе любого диска, узла или группы узлов из строя Ceph не только обеспечит сохранность данных, но и сам восстановит утраченные копии на других узлах до тех пор, пока вышедшие из строя узлы или диски не заменят на рабочие. При этом ребилд происходит без секунды простоя и прозрачно для клиентов.
Роли узлов и демоны
Поскольку система программно определяемая и работает поверх стандартных файловых систем и сетевых уровней, можно взять пачку разных серверов, набить их разными дисками разного размера, соединить всё это счастье какой-нибудь сетью (лучше быстрой) и поднять кластер. Можно воткнуть в эти серверы по второй сетевой карте, и соединить их второй сетью для ускорения межсерверного обмена данными. А эксперименты с настройками и схемами можно легко проводить даже в виртуальной среде. Мой опыт экспериментов показывает, что самое долгое в этом процессе — это установка ОС. Если у нас есть три сервера с дисками и настроенной сетью, то поднятие работоспособного кластера с дефолтными настройками займет 5-10 минут (если все делать правильно).
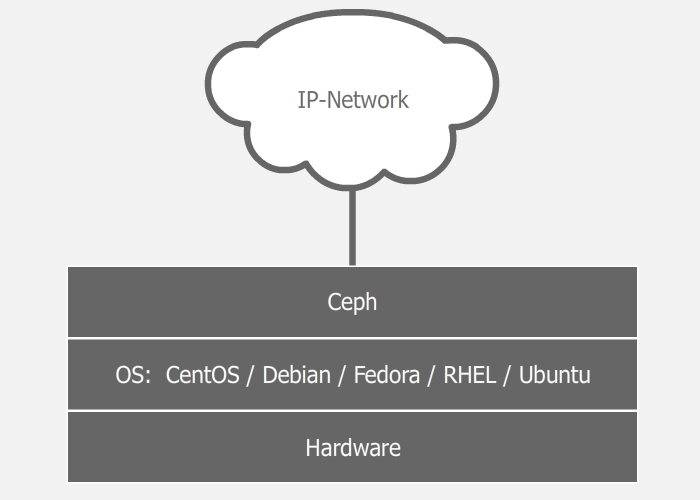
Поверх операционной системы работают демоны Ceph, выполняющие различные роли кластера. Таким образом один сервер может выступать, например, и в роли монитора (MON), и в роли хранилища данных (OSD). А другой сервер тем временем может выступать в роли хранилища данных и в роли сервера метаданных (MDS). В больших кластерах демоны запускаются на отдельных машинах, но в малых кластерах, где количество серверов сильно ограничено, некоторые сервера могут выполнять сразу две или три роли. Зависит от мощности сервера и самих ролей. Разумеется, все будет работать шустрее на отдельных серверах, но не всегда это возможно реализовать. Кластер можно собрать даже из одной машины и всего одного диска, и он будет работать. Другой разговор, что это не будет иметь смысла. Следует отметить и то, что благодаря программной определяемости, хранилище можно поднять даже поверх RAID или iSCSI-устройства, однако в большинстве случаев это тоже не будет иметь смысла.
В документации перечислено 3 вида демонов:
- Mon — демон монитора
- OSD — демон хранилища
- MDS — сервер метаданных (необходим только в случае использования CephFS)
Первоначальный кластер можно создать из нескольких машин, совмещая на них роли кластера. Затем, с ростом кластера и добавлением новых серверов, какие-то роли можно дублировать на других машинах или полностью выносить на отдельные серверы.
Структура хранения
Для начала коротко и непонятно. Кластер может иметь один или много пулов данных разного назначения и с разными настройками. Пулы делятся на плейсмент-группы. В плейсмент-группах хранятся объекты, к которым обращаются клиенты. На этом логический уровень заканчивается, и начинается физический, потому как за каждой плейсмент-группой закреплен один главный диск и несколько дисков-реплик (сколько именно зависит от фактора репликации пула). Другими словами, на логическом уровне объект хранится в конкретной плейсмент-группе, а на физическом — на дисках, которые за ней закреплены. При этом диски физически могут находиться на разных узлах или даже в разных датацентрах.

Далее подробно & понятно.
Фактор репликации (RF)
Фактор репликации — это уровень избыточности данных. Количество копий данных, которое будет храниться на разных дисках. За этот параметр отвечает переменная size. Фактор репликации может быть разным для каждого пула, и его можно менять на лету. Вообще, в Ceph практически все параметры можно менять на лету, мгновенно получая реакцию кластера. Сначала у нас может быть size=2, и в этом случае, пул будет хранить по две копии одного куска данных на разных дисках. Этот параметр пула можно поменять на size=3, и в этот же момент кластер начнет перераспределять данные, раскладывая еще одну копию уже имеющихся данных по дискам, не останавливая работу клиентов.
Пул
Пул — это логический абстрактный контейнер для организации хранения данных пользователя. Любые данные хранятся в пуле в виде объектов. Несколько пулов могут быть размазаны по одним и тем же дискам (а может и по разным, как настроить) с помощью разных наборов плейсмент-групп. Каждый пул имеет ряд настраиваемых параметров: фактор репликации, количество плейсмент-групп, минимальное количество живых реплик объекта, необходимое для работы и т. д. Каждому пулу можно настроить свою политику репликации (по городам, датацентрам, стойкам или даже дискам). Например, пул под хостинг может иметь фактор репликации size=3, а зоной отказа будут датацентры. И тогда Ceph будет гарантировать, что каждый кусочек данных имеет по одной копии в трех датацентрах. Тем временем, пул для виртуальных машин может иметь фактор репликации size=2, а уровнем отказа уже будет серверная стойка. И в этом случае, кластер будет хранить только две копии. При этом, если у нас две стойки с хранилищем виртуальных образов в одном датацентре, и две стойки в другом, система не будет обращать внимание на датацентры, и обе копии данных могут улететь в один датацентр, однако гарантированно в разные стойки, как мы и хотели.
Плейсмент-группа (PG)
Плейсмент-группы — это такое связующее звено между физическим уровнем хранения (диски) и логической организацией данных (пулы).
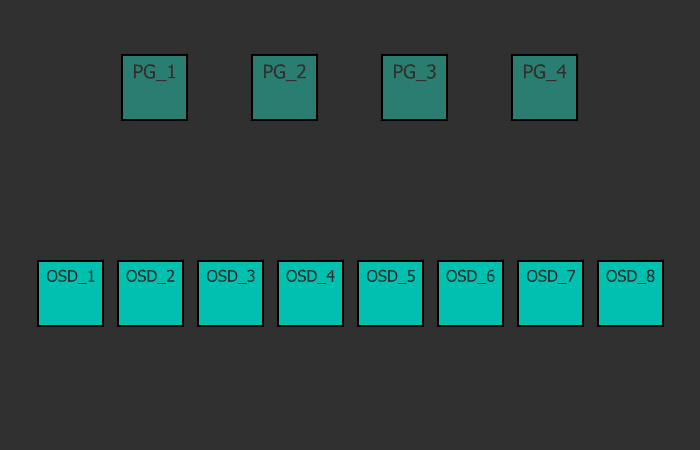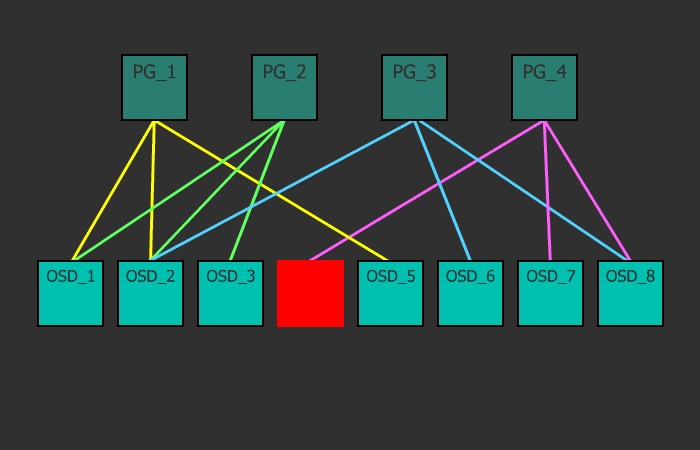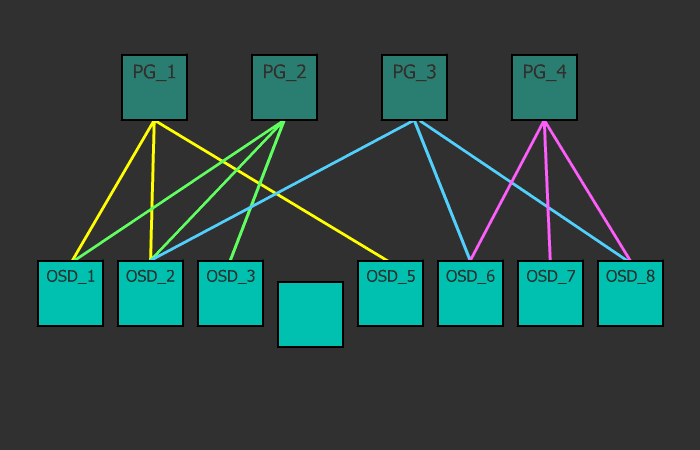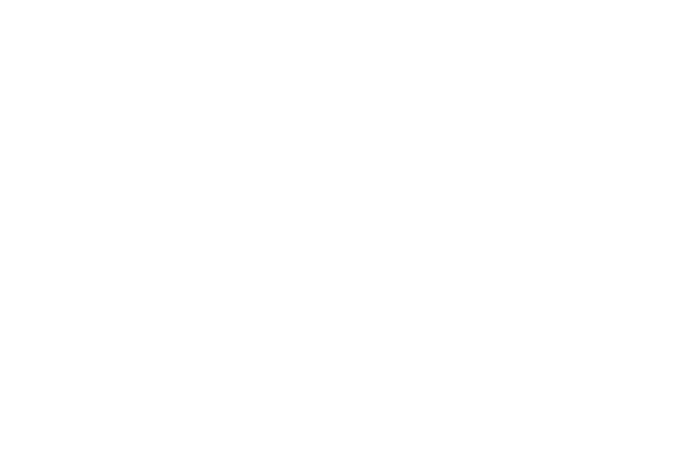
Каждый объект на логическом уровне хранится в конкретной плейсмент-группе. На физическом же уровне, он лежит в нужном количестве копий на разных физических дисках, которые в эту плейсмент-группу включены (на самом деле не диски, а OSD, но обычно один OSD это и есть один диск, и для простоты я буду называть это диском, хотя напомню, за ним может быть и RAID-массив или iSCSI-устройство). При факторе репликации size=3, каждая плейсмент группа включает в себя три диска. Но при этом каждый диск находится во множестве плейсмент-групп, и для каких то групп он будет первичным, для других — репликой. Если OSD входит, например, в состав трех плейсмент-групп, то при падении такого OSD, плейсмент-группы исключат его из работы, и на его место каждая плейсмент-группа выберет рабочий OSD и размажет по нему данные. С помощью данного механизма и достигается достаточно равномерное распределение данных и нагрузки. Это весьма простое и одновременно гибкое решение.
Мониторы
Монитор — это демон, выполняющий роль координатора, с которого начинается кластер. Как только у нас появляется хотя бы один рабочий монитор, у нас появляется Ceph-кластер. Монитор хранит информацию о здоровье и состоянии кластера, обмениваясь различными картами с другими мониторами. Клиенты обращаются к мониторам, чтобы узнать, на какие OSD писать/читать данные. При разворачивании нового хранилища, первым делом создается монитор (или несколько). Кластер может прожить на одном мониторе, но рекомендуется делать 3 или 5 мониторов, во избежание падения всей системы по причине падения единственного монитора. Главное, чтобы количество оных было нечетным, дабы избежать ситуаций раздвоения сознания (split-brain). Мониторы работают в кворуме, поэтому если упадет больше половины мониторов, кластер заблокируется для предотвращения рассогласованности данных.
OSD (Object Storage Device)
OSD — это юнит хранилища, который хранит сами данные и обрабатывает запросы клиентов, обмениваясь данными с другими OSD. Обычно это диск. И обычно за каждый OSD отвечает отдельный OSD-демон, который может запускаться на любой машине, на которой установлен этот диск. Это второе, что нужно добавлять в кластер, при разворачивании. Один монитор и один OSD — минимальный набор для того, чтобы поднять кластер и начать им пользоваться. Если на сервере крутится 12 дисков под хранилище, то на нем будет запущено столько же OSD-демонов. Клиенты работают непосредственно с самими OSD, минуя узкие места, и достигая, тем самым, распределения нагрузки. Клиент всегда записывает объект на первичный OSD для какой-то плейсмент группы, а уже дальше данный OSD синхронизирует данные с остальными (вторичными) OSD из этой же плейсмент-группы. Подтверждение успешной записи может отправляться клиенту сразу же после записи на первичный OSD, а может после достижения минимального количества записей (параметр пула min_size). Например если фактор репликации size=3, а min_size=2, то подтверждение об успешной записи отправится клиенту, когда объект запишется хотя бы на два OSD из трех (включая первичный).
При разных вариантах настройки этих параметров, мы будем наблюдать и разное поведение.
Если size=3 и min_size=2: все будет хорошо, пока 2 из 3 OSD плейсмент-группы живы. Когда останется всего лишь 1 живой OSD, кластер заморозит операции данной плейсмент-группы, пока не оживет хотя бы еще один OSD.
Если size=min_size, то плейсмент-группа будет блокироваться при падении любого OSD, входящего в ее состав. А из-за высокого уровня размазанности данных, большинство падений хотя бы одного OSD будет заканчиваться заморозкой всего или почти всего кластера. Поэтому параметр size всегда должен быть хотя бы на один пункт больше параметра min_size.
Если size=1, кластер будет работать, но смерть любой OSD будет означать безвозвратную потерю данных. Ceph дозволяет выставить этот параметр в единицу, но даже если администратор делает это с определенной целью на короткое время, он риск берет на себя.
Диск OSD состоит из двух частей: журнал и сами данные. Соответственно, данные сначала пишутся в журнал, затем уже в раздел данных. С одной стороны это дает дополнительную надежность и некоторую оптимизацию, а с другой стороны — дополнительную операцию, которая сказывается на производительности. Вопрос производительности журналов рассмотрим ниже.
Алгоритм CRUSH
В основе механизма децентрализации и распределения лежит так называемый CRUSH-алгоритм (Controlled Replicated Under Scalable Hashing), играющий важную роль в архитектуре системы. Этот алгоритм позволяет однозначно определить местоположение объекта, на основе хеша имени объекта и определенной карты, которая формируется исходя из физической и логической структур кластера (датацентры, залы, ряды, стойки, узлы, диски). Карта не включает в себя информацию о местонахождении данных. Путь к данным каждый клиент определяет сам, с помощью CRUSH-алгоритма и актуальной карты, которую он предварительно спрашивает у монитора. При добавлении диска или падении сервера, карта обновляется.
Благодаря детерминированности, два разных клиента найдут один и тот же однозначный путь до одного объекта самостоятельно, избавляя систему от необходимости держать все эти пути на каких-то серверах, синхронизируя их между собой, давая огромную избыточную нагрузку на хранилище в целом.
Пример:

Клиент хочет записать некий объект object1 в пул Pool1. Для этого он смотрит в карту плейсмент-групп, которую ему ранее любезно предоставил монитор, и видит, что Pool1 разделен на 10 плейсмент-групп. Далее с помощью CRUSH-алгоритма, который на вход принимает имя объекта и общее количество плейсмент-групп в пуле Pool1, вычисляется ID плейсмент-группы. Следуя карте, клиент понимает, что за этой плейсмент-группой закреплено три OSD (допустим, их номера: 17, 9 и 22), первый из которых является первичным, а значит клиент будет производить запись именно на него. Кстати, их три, потому что в этом пуле установлен фактор репликации size=3. После успешной записи объекта на OSD_17, работа клиента закончена (это если параметр пула min_size=1), а OSD_17 реплицирует этот объект на OSD_9 и OSD_22, закрепленные за этой плейсмент-группой. Важно понимать, что это упрощенное объяснение работы алгоритма.
По умолчанию наша CRUSH-карта плоская, все ноды находятся в одном пространстве. Однако, можно эту плоскость легко превратить в дерево, распределив серверы по стойкам, стойки по рядам, ряды по залам, залы по датацентрам, а датацентры по разным городам и планетам, указав какой уровень считать зоной отказа. Оперируя такой новой картой, Ceph будет грамотнее распределять данные, учитывая индивидуальные особенности организации, предотвращая печальные последствия пожара в датацентре или падения метеорита на целый город. Более того, благодаря этому гибкому механизму, можно создавать дополнительные слои, как на верхних уровнях (датацентры и города), так и на нижних (например, дополнительное разделение на группы дисков в рамках одного сервера).
Кеширование
Ceph предусматривает несколько способов увеличения производительности кластера методами кеширования.
Primary-Affinity
У каждого OSD есть несколько весов, и один из них отвечает за то, какой OSD в плейсмент-группе будет первичным. А, как мы выяснили ранее, клиент пишет данные именно на первичный OSD. Так вот, можно добавить в кластер пачку SSD дисков, сделав их всегда первичными, снизив вес primary-affinity HDD дисков до нуля. И тогда запись будет осуществляться всегда сначала на быстрый диск, а затем уже не спеша реплицироваться на медленные. Этот метод самый неправильный, однако самый простой в реализации. Главный недостаток в том, что одна копия данных всегда будет лежать на SSD и потребуется очень много таких дисков, чтобы полностью покрыть репликацию. Хотя этот способ кто-то и применял на практике, но его я скорее упомянул для того, чтобы рассказать о возможности управления приоритетом записи.
Вынос журналов на SSD
Вообще, львиная доля производительности зависит от журналов OSD. Осуществляя запись, демон сначала пишет данные в журнал, а затем в само хранилище. Это верно всегда, кроме случаев использования BTRFS в качестве файловой системы на OSD, которая может делать это параллельно благодаря технике copy-on-write, но я так и не понял, насколько она готова к промышленному применению. На каждый OSD идет собственный журнал, и по умолчанию он находится на том же диске, что и сами данные. Однако, журналы с четырёх или пяти дисков можно вынести на один SSD, неплохо ускорив операции записи. Метод не очень гибкий и удобный, но достаточно простой. Недостаток метода в том, что при вылете SSD с журналом, мы потеряем сразу несколько OSD, что не очень приятно и вносит дополнительные трудности во всю дальнейшую поддержку, которая скалируется с ростом кластера.
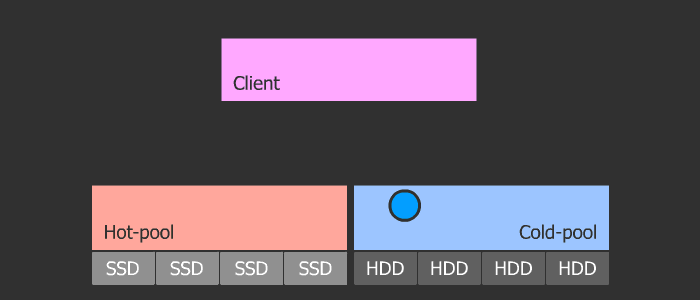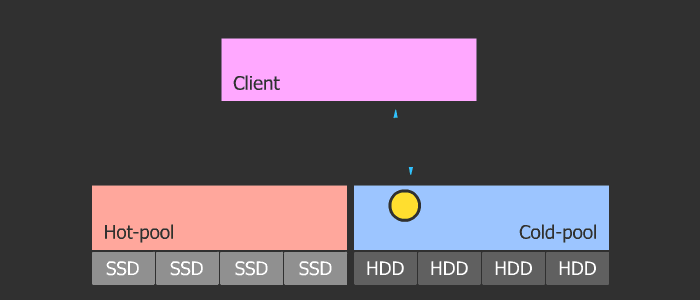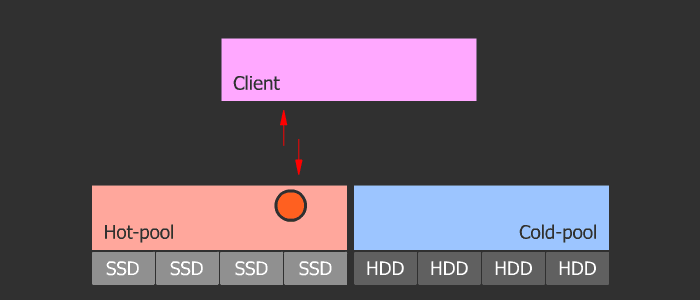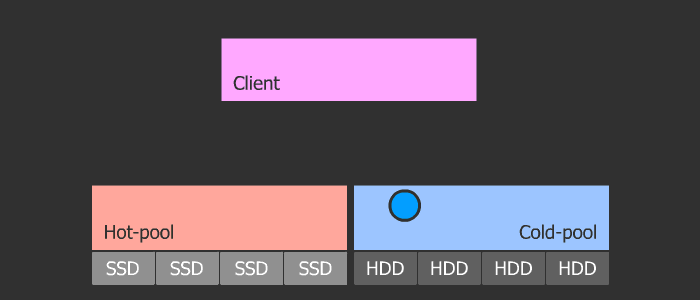
Кеш-тиринг
Ортодоксальность данного метода в его гибкости и масштабируемости. Схема такова, что у нас есть пул с холодными данными и пул с горячими. При частом обращении к объекту, тот как бы нагревается и попадает в горячий пул, который состоит из быстрых SSD. Затем, если объект остывает, он попадает в холодный пул с медленными HDD. Данная схема позволяет легко менять SSD в горячем пуле, который в свою очередь может быть любого размера, ибо параметры нагрева и охлаждения регулируются.
С точки зрения клиента
Ceph предоставляет для клиента различные варианты доступа к данным: блочное устройство, файловая система или объектное хранилище.

Блочное устройство (RBD, Rados Block Device)
Ceph позволяет в пуле данных создать блочное устройство RBD, и в дальнейшем смонтировать его на операционных системах, которые это поддерживают (на момент написания статьи были только различные дистрибутивы linux, однако FreeBSD и VMWare тоже работают в эту сторону). Если клиент не поддерживает RBD (например Windows), то можно использовать промежуточный iSCSI-target с поддержкой RBD (например, tgt-rbd). Кроме того, такое блочное устройство поддерживает снапшоты.
Файловая система CephFS
Клиент может смонтировать файловую систему CephFS, если у него linux с версией ядра 2.6.34 или новее. Если версия ядра старше, то можно смонтировать ее через FUSE (Filesystem in User Space). Для того, чтобы клиенты могли подключать Ceph как файловую систему, необходимо в кластере поднять хотя бы один сервер метаданных (MDS)
Шлюз объектов
С помощью шлюза RGW (RADOS Gateway) можно клиентам дать возможность пользоваться хранилищем через RESTful Amazon S3 или OpenStack Swift совместимое API.
И другие...
Все эти уровни доступа к данным работают поверх уровня RADOS. Список можно дополнить, разработав свой слой доступа к данным с помощью librados API (через который и работают перечисленные выше слои доступа). На данный момент есть биндинги C, Python, Ruby, Java и PHP
RADOS (Reliable Autonomic Distributed Object Store), если в двух словах, то это слой взаимодействия клиентов и кластера.
Википедия гласит, что сам Ceph написан на C++ и Python, а в разработке принимают участие компании Canonical, CERN, Cisco, Fujitsu, Intel, Red Hat, SanDisk, and SUSE.
Впечатления
Зачем я все это написал и нарисовал картинков? Затем что не смотря на все эти достоинства, Ceph либо не очень популярен, либо люди кушают его втихомолку, судя по количеству информации о нем в интернете.
То, что Ceph гибкий, простой и удобный, мы выяснили. Кластер можно поднять на любом железе в обычной сети, потратив минимум времени и сил, при этом Ceph сам будет заботиться о сохранности данных, предпринимая необходимые меры в случае сбоев железа. В том, что Ceph гибкий, простой и масштабируемый сходится множество точек зрения. Однако отзывы о производительности встречаются весьма разнообразные. Возможно кто-то не справился с журналами, кого-то подвела сеть и задержки в операциях ввода/вывода. То есть, заставить кластер работать — легко, но заставить его работать быстро — возможно, сложнее. Посему, я взываю к ИТ-специалистам, которые имеют опыт использования Ceph в продакшене. Поделитесь в комментариях о своих отрицательных впечатлениях.
Ссылки
Сайт Ceph
Википедия
Документация
GitHub
Книга рецептов Ceph
Книга Learning Ceph
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (48)

vasilisc
03.11.2016 09:49+2У меня нет технической возможности собирать как у вас кластера с SSD и 10G. Мой маленький (пока) кластер обладает 1Gb/s на public network в сторону клиента и 1Gb/s — private network. Да, это скудно, но суровая жизнь пока нагнула так. Планируется расширение ещё серверами, дополнительная карта для увеличения скорости хотя до 2Gb/s и если всё сложится, то и SSD под журнал.
Нет отрицательных отзывов за годы работы, рад что внедрили в него, поверив в него.

vistoyn
03.11.2016 10:06+1Спасибо за статью!
Возник вопрос. У Cepth есть веб интерфейс для обзора файлов в хранилище и администрирования всего кластера?vasilisc
03.11.2016 10:08+2Для мониторинга и администрирования есть Calamari
vistoyn
03.11.2016 10:41А для обзора файлов в хранилище что посоветуете? Например, как в Amozon S3, где можно посмотреть файлы и скачать их если нужно.

gbg
03.11.2016 10:49+1Там же три пути доступа к хранилищу — нативный (RADOS), как к блочным утройствам (RBD) и как к ФС c POSIX-семантикой.
Для первого — делать средствами своего приложения, КМК. Чтобы работало с учетом прикладного аспекта.
Для второго — мне хватает заклинанияrbd ls | grep XXX | less
Для третьего — ваш любимый файловый менеджер. Я люблю mc, а вы?

DyadyaMisha
03.11.2016 12:15+1Спасибо за статью, ещё хотелось бы увидеть статью по способам мониторинга и тюнинга системы, а так же операцию ввода\вывода нового железа из\в класстер
polifill
03.11.2016 12:15+1Написано весело — без точек отказа, мол все хорошо.
Забыли только упомянуть — не быстро.
Но я бы посоветовал обратить внимание на доводы из этой статьи:
https://habrahabr.ru/company/oleg-bunin/blog/313364/
https://habrahabr.ru/company/oleg-bunin/blog/313330/
Для решения проблем CEPH-подобных можно, к примеру, сделать с единой точкой отказа (координатор), которая лишь частично ограничивает кластер в случае выхода этой точки отказа из строя.
Я про то, что есть и альтернативный взгляд на эту тематику.
AlexBin
03.11.2016 12:21+1Забыли только упомянуть — не быстро.
1. не забыли
2. у кого-то быстро
А о каких доводах Вы говорите? Мне сегодня некогда читать приведенные статьи к сожалению.

a1ien_n3t
03.11.2016 13:35А можно получить небольшую консультацию. ы тут строим небольшой вычеслительный кластер. И рассматривали CEPH как один из вариантов. У нас следующие требования. Оперативное хранилище порядка 40TB. и около 26 нод. Мы думали совмещать, тоесть хостить вычисления и ceph osd на одной ноде. Но нас отговаривают от решения ceph тем что ему на 1tb данных нужно порядка 1,5 ГБ ram на ноде что при наших обемах нуочень приемлемо.
Предлогают решения поднять отдельные серваки с хранилищем и вобще поставить туда pNFS
Может я в чемто не прав?gbg
03.11.2016 13:53Арифметика показывает, что 40/26 = условно 2 терабайта на ноду. При size=3 — это 6 терабайт на ноду или 9 Гб RAM.
Учитывая, что современные серверы несут на борту от 64Гб RAM, отдать шестую часть под хранилище — не страшно. Или у вас ноды — музейные?a1ien_n3t
03.11.2016 14:04+1Нет ноды не музейные, но вот рам очень важные ресурс. Так-как основное нагрузочное приложение будет выедать подчистую, то чтобы OOMKiller не пребил CEPH предлогают запустить CEPH в гипервизоре.
А вот основное приложение недолжно быть под гипервизором, так-как туда еще придется прокидывать GPUgbg
03.11.2016 14:12+3Так, засуньте свое приложение в cgroup (что я настоятельно рекомендую делать со всеми числодробилками), ограничьте ему RAM чем-нибудь разумным.
ceph osd и так запускается в рамках systemd, и тоже попадает в cgroup, так что ему нужно просто задать MemoryLimit
Тащить сюда для изоляции гипервизор — немножко из пушки по микробам.
de1m
03.11.2016 15:06+1У нас небольшой кластер из трёх нод на 6ТБ (по два ТБ на каждом). Всё подключенно через 10Гб/с сеть, скорость получается 630-650МБ/с.
К этому кластеру подключен сервер, на котором крутится докер (тоже через 10Гб/с), докер пишет данные на кластер. Для этого используем RBD. Так как и там и там были SSD, то разницы не было. Уже примерно год работает, полёт нормальный.
Проблемной оказалась СеphFS, хотели сперва чтобы докер через неё писал, но если на неё писать много маленьких файлов и большим количеством (У нас это делал Jenkins), то скорость падает до 120-150кб/с. Так и не смогли решить, поэтому RBD.
Сейчас пытаюсь прикрутить к ней openstack, точнее glance. Но пока не очень.AlexBin
03.11.2016 16:36А как кластер чувствует себя в момент отвала OSD и как в момент отвала целой ноды? Мониторы на них же? Ноды в одной серверной? Снапшоты не используете?
de1m
03.11.2016 19:09Cегодня как-раз все три перезагружал (из-за openstack'a). Просидания производительности я не заметил, но я специально не замерял, хотя я думаю, что при большом размере кластера что-то такое будет. Хотя опять же, если на одной ноде не будет много OSD, то будет нормально. У меня при двух минутах простоя и 650МБ/с скорости, всё очень быстро синхронизироваллось.
Мониторы стоят на всех трёх. Спапшоты хотели использовать, чтобы потом с них делать бэкапы, но там тоже был какой-то косяк (уже не помню, но точно не технический) и теперь делаем через Btrfs, который стоит на RBD.
o_serega
03.11.2016 16:18+3Ни слова об erasure code http://docs.ceph.com/docs/jewel/rados/operations/erasure-code/, ни слова об BlueStore https://www.sebastien-han.fr/blog/2016/03/21/ceph-a-new-store-is-coming/ (исходя из ее архитектуры, плавной миграции я не вижу, но пока все это глубокая бетта).
Если исходить, что один osd — это один диск на ОДНОМ сервере — то тогда гигабита сети достаточно, а почему на одном сервере — сервера тоже дохнут и представьте ситуацию когда у вас на сервере висело порядка 12 дисков по 8 терабайт, которые были забиты так на 60 — 80%, думаю не сложно понять какой будет трафик при ребалансе и как начнут сыпаться другие диски, на которые резко пришла нагрузка.
Вообще производительность кластера напрямую зависит от количества дисков, чем больше — тем выше скорость работы. http://ceph.com/community/500-osd-ceph-cluster/ тут есть статья как церн строит свой сторедж на базе ceph
Кстати, тоже было бы полезно упомянуть сколько бы озу на один osd необходимо для нормальной жизни, исходя из объема диска, ибо при ребалансе osd любят кушать память.
Вообще много чего еще стоит упомянуть из неприятного о ceph)AlexBin
03.11.2016 16:33Согласен с каждым словом.
Про erasure code не рассказал намеренно, поскольку не работал с ним. Если кому интересно, это метод вместо репликации данных (чем то похож на RAID5, только с другим алгоритмом). Позволяет хранить больше данных на том же количестве свободного места в кластере. Однако, как я понял, немного проигрывает в производительности методу репликации. Такой алгоритм можно использовать для хранилищ бекапов например.
Про BlueStore даже не слышал, спасибо за наводку, почитаю.
Вообще много чего еще стоит упомянуть из неприятного о ceph)
Буду благодарен, если поделитесь этими неприятностями с нами.o_serega
03.11.2016 16:43+2200 терабайт raw сторедж, 5 машин в клстере (именно та ситуация о которой я писал ранее, мало серверов — много дисков), забит был от силы на терабайт 80, епунл 2 ноды, пошел ребаланс, диски были не старые, но и не свежие, сеть между нодами 10Г ерезнет, начали сыпаться диски, на который пришел трафик ребаланса, после такого нежданчика, потребление ОЗУ osd демонами резко возросло и 64 гига памяти на ноде не хватило, после этого кластер сказал ой! Окей, мы не гордые — возвращаем две погашенные ноды в строй, но кластер не оживает. Короче заработать тогда кластер я так и не заставил, данные побились, инструментария вытащить что-то из рассыпавшегося кластера — нет.
А строить один — два диска на сервер, на колокейшине — жутко дорого выходило, нам в перспективе хотелось петабайт raw места на дц (с запасом на роста), плюс с гео-репликацией все так не хорошо, редактирование CRUSH карты конечно дело хорошее, но это не асинхронная гео-репликация в мастер-мастер режимеAlexBin
03.11.2016 17:00Все правильно.
Думаю, тут нужно проектировать кластер с учетом количества нод и дисков на них. Если хотите много дисков на ноду, то нужно либо больше нодов, чтобы в ребалансе того же количества данных участвовало больше дисков, распределяя то же количество нагрузки на бОльшее количество физических устройств, либо выставлять минимальный приоритет ребалансингу (при size=3, думаю, это можно себе позволить).
Если не секрет, какими были size и min_size?o_serega
03.11.2016 17:17В конфигурации один сервер — много дисков у Вас сервер будет основной точкой отказа и если уже сдох сервер — то у вас проблемы, если на сервере было много дисков и большой процент занятости на них, поясню на римере, у вас есть сервер, на нем какое-то количество дисков, которые дают, допустим, 50 терабайт raw места, реальных данных из этого объема — 30 терабайт, а теперь смотрите, у Вас помер сервер, и ceph начинает ребалансить те самые 30 терабайт, ибо ему надо восстановить количество реплик.
Я потому и выше написал, что много серверов жутко не выгодно на колокейшине.
size и min_size = 3 и 2 соответсвенно, потом игрались с 3 и 1 — что бы быстрее отдавать ответ клиенту, что данные записаны, делали пулы с репликой 2 и 2 и 1 соответсвенно для size и min_size
Для меня была бы идеальная конфигурация кластерного стореджа с гео-репликацией — это внутри дц использовать коды избыточности, а между дц — хранить целую данных, это мой маленький манямирок)AlexBin
03.11.2016 17:25а теперь смотрите, у Вас помер сервер, и ceph начинает ребалансить те самые 30 терабайт, ибо ему надо восстановить количество реплик.
Я это понимаю. Но если у вас упало 2 ноды из 5, то 30 терабайт будут ребаланситься между тремя нодами. А если упадет например 2 из 10, то те же 30 терабайт будут ребаланситься между 8 нодами, а это почти в 3 раза меньше нагрузки на конечные OSD.
Вашу мысль я понял, мы это учтем, если будем строить кластер. Но я думаю, это проблема не Ceph, а в принципе любой такой системы с автоматической ребалансировкой, ибо упирается то все в железо и повышенную нагрузку на него в момент отвала почти половины кластера.o_serega
03.11.2016 17:26Я к тому, что надо строить с как можно с большей гранулярностью, что бы одна точка отказа хранила меньше данных, будет легче, ну и еще вопрос отказоустойчивости сети на уровне стойки и тп
Vasily_Pechersky
04.11.2016 01:27+2По теме:
Есть кластер 4 ноды. В каждой 2 SSD (один:os,mon второй: jornal) 3 hdd (WD RAID edition SATA) процы E5-1650.
Фактор репликации 3.
Proxmox с его дефолтными настройками ceph. Ничего не подкручивал.
Терминалы с 2008 около 150 пользователей всего. Полёт хороший. 350-400 iops на виртуалку под нагрузкой.
Решение имеет сравнительно низкую цену при приемлемых для работы показателях.
AlexBin
04.11.2016 01:30Правильно ли я понял, у Вас по монитору на каждой ноде? То бишь 4 штуки? А SSD выделены под ось с монитором и под журналы?
Vasily_Pechersky
04.11.2016 09:07Да — каждая нода — монитор.
Из минусов — если второй SSD накроется (на котором журналы) то отвалятся 3 OSD :-( — все, которые на ноде.
Ещё забыл упомянуть, что сеть для ceph 10гигабитная.AlexBin
04.11.2016 09:55+1У вас получается четное количество мониторов, сплитбрейна не боитесь? Зачем под ось и монитор SSD?
Vasily_Pechersky
04.11.2016 13:18Зачем под ось и монитор SSD? — Выполнял рекомендации ProxMox. На их сайте гайд, в котором сказано, что mon должен быть быстрым и SSD рекомендуют.
Датастор подсоединён по rbd.
Сплитбрейна не боитесь? — А об этом совершенно не подумал. Никак… В том бешеном угаре, когда за неделю с нуля поднять из состояния «в коробках» до виртуалки смигрированы от хостера и работают…
vadikgo
05.11.2016 16:51+1В ceph не бывает сплитбрейнов мониторов. При 4-х мониторах должно всегда работать не менее 3-х, иначе все операции в кластере приостанавливаются.

ufm
05.11.2016 15:06Кстати, о том, что повышать отказоустойчивость можно не только простым дублированием данных на разных OSD, но и организацией из OSD аналогов RAID5/6 — в ceph так и не додумались? Вроде-бы были-же какие-то телодвижения в эту сторону?

x86128
05.11.2016 17:58+2Что-то не попадалось еще статей о том как ceph правильно бэкапить. Вот помню, что он разваливался в труху у одного облачного провайдера и у самих авторов цеф недавно. Так, что данные было совсем не восстановить.
Есть ли методы как правильно бэкапить логику?
AlexBin
05.11.2016 18:20Очень скверно. Есть подробности?
Развалился прям кластер или данные потерялись? Второе вполне возможно, если вылетят все диски из одной плейсмент-группы. И если на них лежали блоки какого-нибудь RBD, которые являлись частью больших файлов (например образов виртуалок), то и остальные (живые) блоки из этого RBD станут скорее всего бесполезными.
iPrime
06.11.2016 15:26+2В development идет 11 версия (Кракен), там что-то вынесли в новый сервис менеджмента (Вроде как для улучшения общего контроля за кластером). Еще вышел очень интересный проект petasan.org на ceph. Из коробки собирается кластер мин за 5 (все на web) там же управление, плюс готовый для использования iscsi. Смотрю теперь за его развитием.
У себя используем для бэкапов и файлового сервера, пока вроде всем устраивает. Cеть — две по 1Gb.

kvaps
08.11.2016 11:09+1Спасибо за статью, все очень наглядно показали и объянили..
Грядет новый backend для ceph — bluestore, в новых версиях его сделают backend'ом по дефолту.
Было бы очень интересно почитать про него в том же формате, что и в этой статье. :)
https://www.sebastien-han.fr/blog/2016/03/21/ceph-a-new-store-is-coming/AlexBin
08.11.2016 13:29BlueStore очень вкусная штука судя по описаниям, она должна решить главную проблему производительности журналов, если я все правильно понял. Однако пока я не только не могу написать про нее статью, я даже ее пощупать не могу.
Пока я планирую написать статью (или две) по теме экспериментов на виртуалках, которые доступны каждому желающему на домашнем ПК.

phozzy
08.11.2016 16:34+5У нас в продакшене был IBM XIV, после того как кончилась его поддержка, а за продление межделмаш выкатил такой ценик, что it-бюджета региона не хватило на его оплату. В связи с чем, после того как его начало колбасить, мы его похоронили, и воскресили в облике Ceph.
В итоге получили выигрыш в 500 iops! И это, учитывая то, что одна из 6 нод отправилась на полный покой.
С тех пор система работает нонстоп. Железо потихоньку сыпется, система деградирует в емкости, но продолжает работать!
gbg
Я бы настолько категорично утверждать не стал. Гигабитную сеть ceph с удовольствием кладет на обе лопатки во время перебалансировки. Между OSD нужно тянуть 10 гигабит и никак иначе. Иначе получится крайне шаткая конструкция.
С другой стороны, поведение этой шаткой конструкции на время репликации является довольно мягким — тормозит, не, не так, ТОРМОЗИТ, но виртуалки ползут хоть как-то. Это гораздо приятнее внезапного визита STONITH на OCFS, который перезагружает весь кластер к такой-то матери, в случае малейших сетевых проблем.
Личный опыт, прод — 9 узлов, 36 osd, гигабитная клиентская и гигабитная кластерная сеть, size=1 для горячих данных и size=3 для образов ОС виртуалок, размер 9Т. Доступ через RBD.
Личный опыт, лаб — 2 узла, 12 osd, сеть 10G, size=2, доступ через ceph-fs + dokan. Клиенты — Windows 2012. Вполне неплохо бегало.
AlexBin
Да, именно об этом я внизу и уточняю, что собрать кластер можно на чем угодно, но чтобы собрать быстрое хранилище, нужно грамотно подойти к планированию. Спасибо за личную статистику.