

Недавно мы добавили в сервис «Виртуальное приватное облако» новый образ с операционной системой RancherOS и обновили образ CoreOS.
Эти операционные системы будут интересны пользователям, которым необходим инструмент для простого управления большим количеством приложений в контейнерах и использования различных систем кластеризации контейнеров — Kubernetes, Docker Swarm, Apache Mesos и других.
CoreOS и RancherOS отличаются от большинства популярных дистрибутивов Linux: они содержат лишь минимальный набор программного обеспечения для запуска приложений внутри контейнеров. В этих системах отсутствуют пакетные менеджеры и интерпретаторы различных языков программирования (Python, Ruby и других.).
Ниже мы рассмотрим специфику CoreOS и RancherOS, разберём особенности конфигурации сервисов etcd и fleet, а также приведём пример настройки кластера Docker Swarm на базе RancherOS.
CoreOS
Дистрибутив CoreOS разработан специально для быстрого и массового развертывания большого количества пользовательских приложений в изолированных контейнерах.
CoreOS содержит предустановленные инструменты для удобного управления множеством нод и контейнеров в кластере:
- etcd — распределенное хранилище данных, которое используется нодами для получения информации о доступных сервисах в кластере, конфигурационным и временным файлам;
- Docker — основная платформа для доставки и запуска приложений внутри контейнеров;
- rkt — альтернатива Docker, разработанная создателями CoreOS;
- fleet — распределенная система инициализации, позволяющая управлять множеством systemd-инстансов на отдельных нодах кластера и производить запуск необходимых сервисов на менее загруженных нодах.
Конфигурация
Основной метод изменения системных параметров ? это описание необходимых настроек при помощи декларативного языка YAML в конфигурационном файле cloud-config.yml. Этот файл используется утилитой Cloud-init для настройки системы.
Обратите внимание, что в CoreOS используется собственная реализация Cloud-init, конфигурационные файлы которой лишь частично совместимы с настройками для более распространенной версии Launchpad-cloud-init, используемой в большинстве обычных дистрибутивов для конфигурации системы в различных облачных сервисах, в том числе и в сервисе «Виртуальное приватное облако».
Приведем пример файла cloud-config.yml:
#cloud-config
# Set hostname
hostname: "node01"
# Set ntp servers
write_files:
- path: /etc/systemd/timesyncd.conf
content: |
[Time]
NTP=0.ru.pool.ntp.org 1.ru.pool.ntp.org
coreos:
units:
# Configure static network on eth0 interface
- name: iface-eth0.network
runtime: true
content: |
[Match]
Name=eth0
[Network]
DNS=188.93.16.19
DNS=188.93.17.19
DNS=109.234.159.91
Address=10.11.12.13/24
Gateway=10.11.12.1
# Change standard SSH port
- name: sshd.socket
command: restart
runtime: true
content: |
[Socket]
ListenStream=2345
FreeBind=true
Accept=yes
При помощи заданных параметров утилита Cloud-init сменит хостнейм и стандартный порт 22 для сервиса SSH, настроит статическую сеть на интерфейсе eth0 и добавит ntp-серверы для синхронизации времени.
Подробнее о структуре конфигурационного файла cloud-config.yml можно прочитать в официальной документации.
При создании сервера из готового образа CoreOS в сервисе «Виртуальное приватное облако» вам не потребуется производить базовую настройку системы при помощи cloud-config.yml. Мы уже внесли необходимые изменения в образ, при помощи которых автоматически производится стандартная конфигурация сервера, в том числе настройка сетевых интерфейсов.
Доступ по SSH к серверу под управлением CoreOS изначально будет возможен только по ключу, указанному при создании сервера. Указанный ключ будет добавлен для пользователя core.
В дополнение к собственной версии cloud-init создатели CoreOS разработали утилиту Ignition. Этот инструмент дублирует возможности cloud-init и еще позволяет производить низкоуровневые настройки системы, — например, изменение таблиц разделов дисков и форматирование файловых систем. Это возможно благодаря тому, что Ignition начинает работать во время ранних этапов загрузки системы, в процессе запуска initramfs.
В Ignition для конфигурационных файлов используется формат JSON.
Ниже представлен пример файла, при помощи которого Ignition отформатирует корневой раздел в Btrfs, и настроит систему с параметрами, аналогичными примеру выше для Cloud-init:
{
"ignition": { "version": "2.0.0" },
"storage": {
"filesystems": [{
"mount": {
"device": "/dev/disk/by-label/ROOT",
"format": "btrfs",
"create": {
"force": true,
"options": [ "--label=ROOT" ]
}
}
}],
"files": [{
"filesystem": "root",
"path": "/etc/systemd/timesyncd.conf",
"mode": 420,
"contents": { "source": "data:,%5BTime%5D%0ANTP=0.ru.pool.ntp.org%201.ru.pool.ntp.org%0A" }
},
{
"filesystem": "root",
"path": "/etc/hostname",
"mode": 420,
"contents": { "source": "data:,node01" }
}
]
},
"networkd": {
"units": [{
"name": "iface-eth0.network",
"contents": "[Match]\nName=eth0\n\n[Network]\nDNS=188.93.16.19\nDNS=188.93.17.19\nDNS=109.234.159.91\nAddress=10.11.12.13/24\nGateway=10.11.12.1"
}]
},
"systemd": {
"units": [{
"name": "sshd.socket",
"command": "restart",
"runtime": true,
"contents": "[Socket]\nListenStream=2345\nFreeBind=true\nAccept=yes"
}]
}
}
Подробнее о всех возможностях Ignition можно узнать в официальной документации.
Пример настройки кластера CoreOS
Для этого примера нам потребуется заранее создать три сервера под управлением CoreOS в панели управления VPC со следующими параметрами:
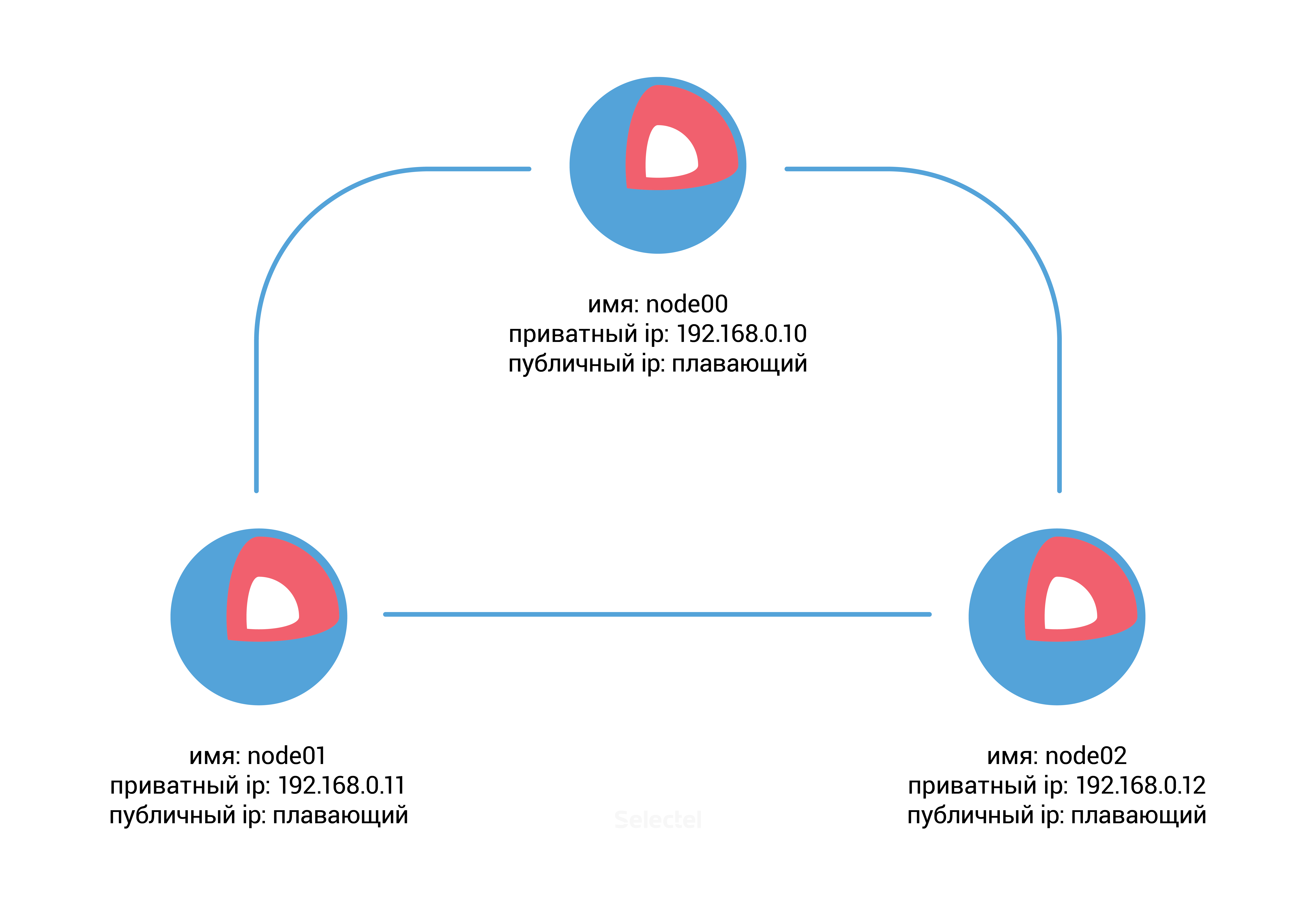
После создания серверов потребуется discovery-url для сервиса etcd. Для этого мы можем воспользоваться публичным бесплатным сервисом discovery.etcd.io. Запустим на хосте node00 следующую команду:
core@node00 ~ $ curl -w "\n" 'https://discovery.etcd.io/new?size=3'
https://discovery.etcd.io/ec42cfef0450bd8a99090ee3d3294493
Добавим полученный URL и дополнительные параметры etcd в файл /usr/share/oem/cloud-config.yml на каждом сервере:
coreos:
etcd2:
discovery: https://discovery.etcd.io/ec42cfef0450bd8a99090ee3d3294493
advertise-client-urls: http://192.168.0.10:2379,http://192.168.0.10:4001
initial-advertise-peer-urls: http://192.168.0.10:2380
listen-client-urls: http://0.0.0.0:2379,http://0.0.0.0:4001
listen-peer-urls: http://192.168.0.10:2380
units:
- name: etcd2.service
command: start
- name: fleet.service
command: start
Параметры в разделе etcd2 обозначают URL-адреса в формате protocol://address:port, которые необходимы для анонсирования ноды и обмена данными с другими членами кластера.
Раздел units позволяет управлять юнитами systemd в системе; в нашем случае он запустит юниты etc2d.service и fleet.service.
Для серверов node01 и node02 вам будет необходимо добавить аналогичные изменения в cloud-config.yml, изменив ip-адрес с 192.168.0.10 на 192.168.0.11 для сервера node01, и на адрес 192.168.0.12 для сервера node02.
После добавления новых настроек запустим утилиту Cloud-init на всех трех серверах (либо можно просто перезапустить эти серверы):
core@node00 ~ $ sudo coreos-cloudinit --from-file /usr/share/oem/cloud-config.yml
Также проверим статус сервиса etcd:
core@node00 ~ $ etcdctl cluster-health
member 3aaf91fd1172594e is healthy: got healthy result from http://192.168.0.11:2379
member 8cf40790248e1dcd is healthy: got healthy result from http://192.168.0.12:2379
member 96b61f40c082cd0b is healthy: got healthy result from http://192.168.0.10:2379
cluster is healthy
Проверим доступность распределенного хранилища, добавим новую директорию (в терминологии etcd — ключ) со значением на сервере node00:
core@node00 ~ $ etcdctl set /common/cluster-name selectel-test-cluster
selectel-test-cluster
Затем убедимся, что наш новый ключ со значением доступен с любой другой ноды кластера:
core@node01 ~ $ etcdctl get common/cluster-name
selectel-test-cluster
Отлично, etcd функционирует, и мы можем приступать к использованию сервиса fleet.
В нашем примере мы будем использовать fleet для запуска Nginx в изолированном контейнере Docker. Для начала создадим systemd-юнит /etc/systemd/system/nginx.service:
[Unit]
Description=Nginx Test Service
[Service]
EnvironmentFile=/etc/environment
ExecStartPre=/usr/bin/docker pull nginx
ExecStart=/usr/bin/docker run --rm --name nginx -p 80:80 nginx
ExecStop=/usr/bin/docker kill nginx
[X-Fleet]
Conflicts=nginx.service
Параметр Conflicts в секции X-Fleet запрещает запускать два и более сервиса Nginx на одной ноде, что позволит «размазать» нагрузку на кластер и повысить доступность сервиса. Дополнительные параметры X-Fleet, которые можно использовать внутри юнитов systemd описаны в документации fleet.
Остальные секции в файле являются стандартными для systemd, вы можете ознакомиться с ними например в небольшой вводной инструкции от CoreOS.
Запустим новый юнит nginx.service в нашем кластере при помощи fleetctl:
core@node00 ~ $ fleetctl start /etc/systemd/system/nginx.service
Unit nginx.service inactive
Unit nginx.service launched on 1ad018e0.../192.168.0.11
После этого мы можем увидеть наличие Nginx в списке юнитов на любой ноде кластера:
core@node02 ~ $ fleetctl list-units
UNIT MACHINE ACTIVE SUB
nginx.service 1ad018e0.../192.168.0.11 active running
core@node02 ~ $ fleetctl list-unit-files
UNIT HASH DSTATE STATE TARGET
nginx.service 0c112c1 launched launched 1ad018e0.../192.168.0.11
Как мы видим, контейнер с Nginx запустился на сервере с ip-адресом 192.168.0.11, которому соответствует сервер node01.
Мы можем отключить или полностью удалить сервер node01, после чего fleet автоматически перенесет Nginx на другую доступную ноду.
Etcd сообщит о недоступности члена при проверке статуса кластера:
core@node00 ~ $ etcdctl cluster-health
failed to check the health of member 3aaf91fd1172594e on http://192.168.0.11:2379: Get http://192.168.0.11:2379/health: dial tcp 192.168.0.11:2379: i/o timeout
failed to check the health of member 3aaf91fd1172594e on http://192.168.0.11:4001: Get http://192.168.0.11:4001/health: dial tcp 192.168.0.11:4001: i/o timeout
member 3aaf91fd1172594e is unreachable: [http://192.168.0.11:2379 http://192.168.0.11:4001] are all unreachable
member 8cf40790248e1dcd is healthy: got healthy result from http://192.168.0.12:2379
member 96b61f40c082cd0b is healthy: got healthy result from http://192.168.0.10:2379
cluster is healthy
Но как мы видим, статус сервиса Nginx в норме, он запустился на другой рабочей ноде:
core@node00 ~ $ fleetctl list-units
UNIT MACHINE ACTIVE SUB
nginx.service 4a1ff11c.../192.168.0.10 active running
Мы разобрали элементарный пример конфигурации кластера etcd + Docker + fleet на базе CoreOS. В следующем разделе мы рассмотрим другой дистрибутив — RancherOS, который основан на CoreOS и также предназначен для активного использования контейнеров.
RancherOS
Дистрибутив RancherOS представляет собой форк CoreOS. Отличительная особенность этой системы заключается в том, что в контейнерах запускаются не только пользовательские приложения, но и все системные сервисы. Более того, в RancherOS Docker имеет PID = 1, поэтому запускается сразу после ядра системы.
Операционная система содержит два Docker-инстанса; один из них является системным, в нём запускаются контейнеры udev, acpid, syslog, ntp и другие базовые сервисы, необходимые для работы системы. Системный Docker-инстанс заменяет собой традиционные системы инициализации (systemd, Upstart, SysV), присутствующих в обычных дистрибутивах Linux.
Второй Docker-инстанс используется для запуска пользовательских приложений и представляет собой специальный контейнер, запущенный внутри системного Docker’а.
Такое разделение обеспечивает защиту системных контейнеров от некорректных действий пользователя.

Так как Docker-инстанс в RancherOS представляет собой обычное Docker-окружение, то мы можем использовать стандартный набор команд Docker для управления как пользовательскими так и системными контейнерами.
# проверка версии Docker
[rancher@rancher-os ~]$ docker --version
Docker version 1.12.1, build 23cf638
# установка нового контейнера из Docker Hub
[rancher@rancher-os ~]$ docker run -d nginx
Unable to find image 'nginx:latest' locally
latest: Pulling from library/nginx
…
Status: Downloaded newer image for nginx:latest
# просмотр списка запущенных контейнеров
[rancher@rancher-os ~]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2ec5126e8dd5 nginx "nginx -g 'daemon off" About a minute ago Up About a minute 80/tcp, 443/tcp sad_fermat
Для доступа к системным контейнерам необходимо использовать команду system-docker вместе с утилитой sudo.
Просмотреть список запущенных базовых сервисов операционной системы можно с помощью команды:
[rancher@rancher-os ~]$ sudo system-docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a566d0c7cc4c rancher/os-docker:1.12.1 "/usr/bin/user-docker" 8 minutes ago Up 8 minutes docker
8697a04e90a4 rancher/os-console:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes console
c8c337282aaa rancher/os-base:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes network
1e55244fc99c rancher/os-base:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes ntp
fd6a03fdb28f rancher/os-udev:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes udev
7e9e50c28651 rancher/os-acpid:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes acpid
5fec48b060f2 rancher/os-syslog:v0.6.1 "/usr/bin/ros entrypo" 8 minutes ago Up 8 minutes syslog
Перезапуск системного контейнера осуществляется так:
[rancher@rancher-os ~]$ sudo system-docker restart ntp
Конфигурация
Основным инструментом автоматической конфигурации системы является собственная имплементация cloud-init, который был разделен на две отдельные утилиты: cloud-init-execute и cloud-init-save. По аналогии с другими реализациями cloud-init, версия RancherOS использует декларативный язык YAML, однако cloud-config.yml для другого дистрибутива не будет совместим с RancherOS.
Все возможные директивы конфигурационного файла описаны в официальной документации docs.rancher.com/os.
Системные сервисы используют параметры, полученные из файлов, в описанной ниже последовательности (каждый последующий файл из указанного списка перезаписывает предыдущие параметры, если они совпадают):
- /usr/share/ros/os-config.yml — настройки системы по умолчанию;
- /usr/share/ros/oem/oem-config.yml — в нашем случае это файл, позволяющий производить автоматическую конфигурацию статических настроек сети, в соответствии с параметрами из панели управления VPC;
- YAML-файлы в директории /var/lib/rancher/conf/cloud-config.d/;
- /var/lib/rancher/conf/cloud-config.yml — файл, хранящий значения, установленные утилитой ros, о которой мы расскажем далее;
- параметры ядра, начинающиеся с ключевого слова «rancher»;
- /var/lib/rancher/conf/metadata — метаданные из используемого облачного сервиса, добавленные утилитой cloud-init-save.
Вы можете изменять конфигурацию системы при при помощи утилиты ros, после чего новые параметры будут отображаться в файле /var/lib/rancher/conf/cloud-config.yml:
[rancher@rancher-os ~]$ sudo ros config set rancher.network.dns.nameservers "['188.93.16.19','188.93.17.19', '109.234.159.91']"
[rancher@rancher-os ~]$ sudo cat /var/lib/rancher/conf/cloud-config.yml
rancher:
network:
dns:
nameservers:
- 188.93.16.19
- 188.93.17.19
- 109.234.159.91
Помимо изменения конфигурации системных сервисов утилита ros также используется для управления версиями операционной системы, версиями Docker, настройкой TLS и SELinux.
При использовании готового образа RancherOS в сервисе «Виртуальное приватное облако» вам нет необходимости настраивать базовые параметры системы (конфигурацию сетевых интерфейсов и т.п.)
После установки сервер будет доступен по выбранному вами IP-адресу в панели управления VPC. Вы сможете подключиться к серверу, используя протокол SSH, однако аутентификация изначально будет возможна только по ключу, указанному при создании сервера. Этот ключ будет добавлен для пользователя rancher.
Управление версиями
Чтобы узнать текущую версию операционной системы, используйте команду:
[rancher@rancher-os ~]$ sudo ros os version
v0.6.1
А для проверки всех доступных релизов:
[rancher@rancher-os ~]$ sudo ros os list
rancher/os:v0.4.0 remote
rancher/os:v0.4.1 remote
rancher/os:v0.4.2 remote
rancher/os:v0.4.3 remote
rancher/os:v0.4.4 remote
rancher/os:v0.4.5 remote
rancher/os:v0.5.0 remote
rancher/os:v0.6.0 remote
rancher/os:v0.6.1 remote
Вы можете установить последнюю стабильную версию системы при помощи команды sudo ros os upgrade, либо выбрать требуемую версию, указав параметр -i:
[rancher@rancher-os ~]$ sudo ros os upgrade -i rancher/os:v0.5.0
Так как указанная нами версия 0.5.0 старше, чем установленная 0.6.1, то вместо обновления системы произойдет даунгрейд
Управлять версией Docker не менее просто. Приведём несколько примеров:
#просмотр доступных версий
[rancher@rancher-os ~]$ sudo ros engine list
disabled docker-1.10.3
disabled docker-1.11.2
current docker-1.12.1
#установка версии 1.11.2
[rancher@rancher-os ~]$ sudo ros engine switch docker-1.11.2
INFO[0000] Project [os]: Starting project
INFO[0000] [0/19] [docker]: Starting
…
INFO[0010] Recreating docker
INFO[0010] [1/19] [docker]: Started
Кластер Docker Swarm на RancherOS
В Docker 1.12 появились интегрированные инструменты для управления кластером контейнеров Docker Swarm, благодаря чему настроить готовый кластер стало гораздо проще.
В нашем примере мы будем использовать готовый образ RancherOS в сервисе «Виртуальное приватное облако». В нём используется Docker версии 1.12.1.
Нам понадобится создать три сервера со следующими параметрами:
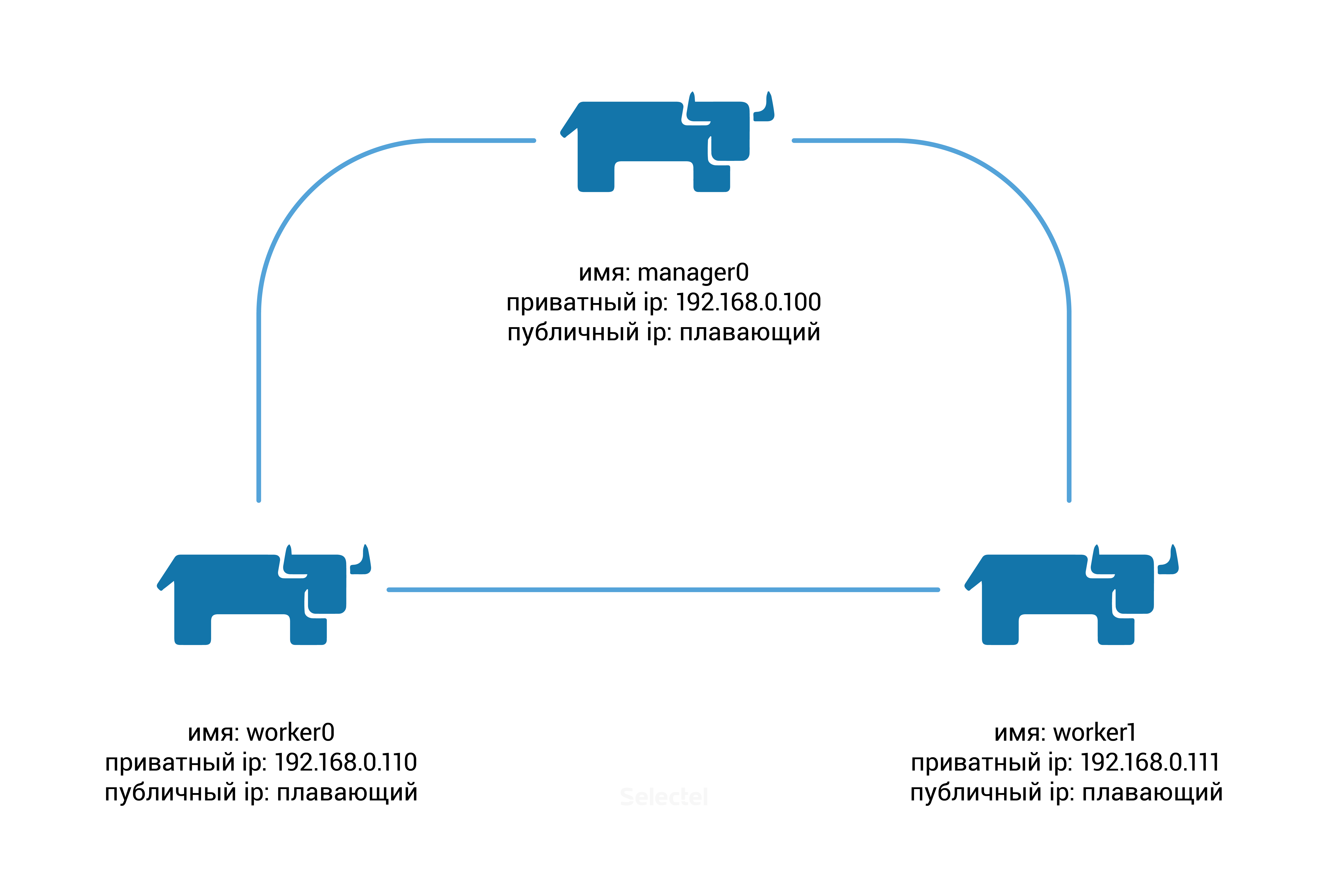
Для начала нам необходимо инициализировать создание кластера Docker Swarm, для этого на ноде manager0 выполним следующую команду:
[rancher@manager0 ~]$ docker swarm init --advertise-addr 192.168.0.100
Swarm initialized: current node (8gf95qb6l61v5s6561qx5vfy6) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0hlhela57gsvxzoaqol70n2b9wos6qlu3ukriry3pcxyb9j2k6-0n1if4hkvdvmrpbb7f3clx1yg 192.168.0.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.Как вы можете заметить из появившейся подсказки, на нодах worker0 и worker1 вам необходимо выполнить команду:
docker swarm join --token SWMTKN-1-0hlhela57gsvxzoaqol70n2b9wos6qlu3ukriry3pcxyb9j2k6-0n1if4hkvdvmrpbb7f3clx1yg 192.168.0.100:2377
Проверим статус нод кластера, для этого на manager0 запустим команду:
[rancher@manager0 ~]$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
366euocei01dw3ay66uwzb3pv worker0 Ready Active
67pt4fo5gi13cxkphtfzfbfbo worker1 Ready Active
8gf95qb6l61v5s6561qx5vfy6 * manager0 Ready Active Leader
Docker Swarm готов к использованию!
По умолчанию новые сервисы будут запускаться на всех нодах кластера. Подкорректируем данные настройки таким образом, чтобы все сервисы запускались на нодах worker0 и worker1, а нода manager0 выполняла только управляющую роль.
Для внесения этих параметров изменим «доступность» ноды manager0:
[rancher@manager0 ~]$ docker node update --availability drain manager0
Запустим сервис с контейнером Nginx:
[rancher@manager0 ~]$ docker service create --name webserver --replicas 1 --publish 80:80 nginx
В ответ мы получим идентификатор сервиса:
av1qvj32mz8vwkwihf0lauiz8
Изначально количество реплик будет равно 0, а единственная задача, относящаяся к этому сервису, будет находится в статусе «Preparing»:
[rancher@manager0 ~]$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
av1qvj32mz8v webserver 0/1 nginx
[rancher@manager0 ~]$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
cjxkza3qzx5m73bgbls0r26m6 webserver.1 nginx worker1 Running Preparing about a minute ago
Через несколько секунд необходимый образ Nginx будет автоматически скачан из Docker Hub, после чего статус сервиса изменится на «Running»:
[rancher@manager0 ~]$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
av1qvj32mz8v webserver 1/1 nginx
[rancher@manager0 ~]$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
cjxkza3qzx5m73bgbls0r26m6 webserver.1 nginx worker1 Running Running 8 minutes ago
Как мы видим, сервис запустился на ноде worker1 (значение в столбце «NODE»). Отключим эту ноду через панель управления VPC и снова проверим статус сервиса webserver:
[rancher@manager0 ~]$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
5lwf4z54p74qtoopuilshw204 webserver.1 nginx worker0 Running Preparing 32 seconds ago
cjxkza3qzx5m73bgbls0r26m6 \_ webserver.1 nginx worker1 Shutdown Running 16 minutes ago
Статус сервиса изменился на «Preparing», Docker Swarm пытается перенести сервис на другую рабочую ноду worker0, задержка связана с тем, что перед запуском на ноду worker0 должен быть добавлен образ Nginx из Docker Hub.
После автоматического добавления образа сервис webserver успешно запустится на ноде worker0:
[rancher@manager0 ~]$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
5lwf4z54p74qtoopuilshw204 webserver.1 nginx worker0 Running Running about a minute ago
cjxkza3qzx5m73bgbls0r26m6 \_ webserver.1 nginx worker1 Shutdown Running 19 minutes ago
Чтобы избежать простоя при переносе сервиса с упавшей ноды, мы можем увеличить количество реплик этого сервиса.
Выполним команду (не забудьте включить ноду worker1 обратно):
[rancher@manager0 ~]$ docker service update --replicas 2 webserver
Сервис начнет реплицироваться на вторую ноду worker1:
[rancher@manager0 ~]$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
5lwf4z54p74qtoopuilshw204 webserver.1 nginx worker0 Running Running 11 minutes ago
cjxkza3qzx5m73bgbls0r26m6 \_ webserver.1 nginx worker1 Shutdown Complete 6 minutes ago
f3o7icke69zw83ag92ywol0dr webserver.2 nginx worker1 Running Preparing 2 seconds ago
Заключение
В этой статье мы проделали обзор дистрибутивов Linux, предназначенных для быстрого развертывания и удобного управления кластером из изолированных контейнеров.
Будем рады, если вы поделитесь собственным опытом использования CoreOS, RancherOS и подобных им операционных систем.
Комментарии (2)

shuron
02.12.2016 20:07Было бы интресно найти сравнение о стабильности или экономии ресурсов этих двух дистирибутивов.
А так спасибо интересно и хочется попробовать особенно ранчер
iborzenkov
Установка нескольких пакетов на обычную убунту (а именно docker, etcd, fleet и при необходимости flannel) дает нам полный функционал coreos и отсутствие необходимости лепить те костыли которые в coreos прикрутить забыли, но необходимость в них возникла из-за гениального решения запускать как init процессы которые для этого не предназначены.