
В решениях, направленных на виртуализацию реальных сетевых функций, основным фактором является способность обеспечить предсказуемую и гарантированную производительность и пропускную способность для трафика заказчика. Во многих проектах, предназначенных для проверки концепции, уделялось значительное внимание повышению пропускной способности сети, но величина задержек является не менее важным показателем работы сетей (а в ряде случаев — гораздо более важным). В этой статье описывается тестовая среда в лабораториях BT Adastral Park на основе архитектуры Intel Open Network Platform. Эта тестовая среда разработана для оценки производительности локального оборудования заказчиков с виртуализацией.

Результаты тестирования свидетельствуют о значительном повышении производительности с точки зрения сокращения задержек и уменьшения дрожания при оптимизации с использованием Data Plane Development Kit. Например, средние задержки удалось сократить на 38–74 % (в зависимости от профиля пакетов), а максимальные задержки сократились в 6 раз. Подобный анализ оптимизации производительности приобретет особую важность для интеллектуального управления нагрузкой и ресурсами как в существующих сетях, так и в перспективных сетях 5G.
Технология виртуализации сетевых функций (NFV) быстро переходит из лабораторных условий в рабочие среды и в пробную эксплуатацию у реальных заказчиков1. Ведется работа по стандартизации: ей занимается соответствующая группа отраслевых технических условий (ISG) в Европейском институте стандартов связи (ETSI). Основные направления стандартизации — измерение производительности и лучшие методики2. Важнейшей метрикой производительности является пропускная способность сетей, но в этой статье проблема производительности рассматривается под другим углом: обсуждается вопрос чувствительности к задержкам. В частности, изучается случай использования локального оборудования заказчиков с виртуализацией (vCPE) в корпорациях, когда определенный набор виртуальных сетевых функций (VNF) обычно находится в локальной ИТ-среде заказчика. В документе ETSI3 такая модель называется VE-CPE (рис. 1).
Примеры сетевых функций в локальной среде заказчика, способных выполняться в качестве VNF на стандартных серверах архитектуры x86 с гипервизором, включают, не ограничиваясь перечисленным, маршрутизаторы, брандмауэры, контроллеры границ сеансов и ускорители глобальных сетей. Филиалам обычно требуется не слишком мощный канал доступа к глобальной сети (по сравнению с центральными офисами): зачастую пропускная способность подключения к глобальной сети может составлять несколько десятков или сотен мегабит в секунду, то есть относительно немного по сравнению с магистральными каналами, пропускная способность которых может достигать и превышать один гигабит в секунду. Поэтому с точки зрения производительности важна не столько максимальная пропускная способность реализации vCPE в филиале, сколько возможность свести к минимуму задержки и колебания (дрожание).
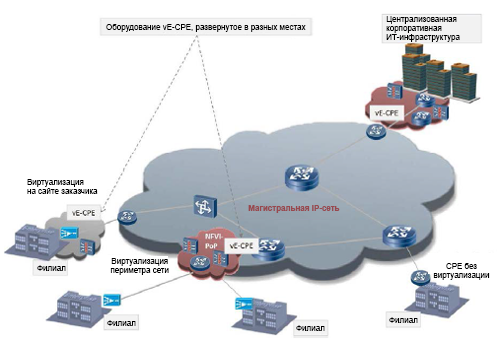
Рисунок 1. Пример использования виртуального корпоративного оборудования в локальной среде заказчика (VE-CPE) в филиалах.
В большинстве корпоративных сетей, где филиалы подключаются к инфраструктуре глобальной сети, часть трафика будет приходиться на передачу голоса по протоколу IP (VoIP). Для этого трафика характерны более жесткие рамки с точки зрения задержек и дрожания, необходимые для обеспечения предсказуемой и гарантированной производительности. Даже если сетевые функции, связанные с передачей голоса (например, контроллеры границ сеансов — SBC), реализованы с помощью физических устройств, без виртуализации, другие функции в локальной среде закаказчика, передающие трафик конечных пользователей, могут быть виртуальными: очевидным примером являются маршрутизаторы на стороне клиента (CE). Поэтому важно настроить производительность инфраструктуры NFV так, чтобы она обеспечивала такой же уровень предсказуемости для задержек и дрожания. Это позволит получить более четкое представление о влиянии компонентов инфраструктуры NFV на общую картину производительности приложений, чувствительных к задержкам.
Во второй части описывается платформа Intel Open Networking Platform (Intel ONP) и пакет Data Plane Development Kit (DPDK), а в третьей части говорится о тестировании среды vCPE с точки зрения оценки задержек и дрожания. Результаты фактических тестов приведены в четвертой части. Пятая часть содержит выводы, а шестая — рекомендуемые материалы для дальнейшего изучения.
Способы определения и реализации решений NFV операторами связи для различных сценариев использования, таких как vCPE, зависят от ряда факторов, в том числе от стоимости, технических условий и взаимодействия с решениями других поставщиков. В результате создаются решения для NFV с открытым исходным кодом, например использующие технологию гипервизора виртуальных машин на базе ядра (KVM) с Open vSwitch* (OVS), и открытые средства управления, такие как OpenStack*. Intel ONP объединяет ряд таких компонентов с открытым исходным кодом и образует модульную архитектурную платформу для NFV4.
Одним из важнейших компонентов архитектуры Intel ONP (с точки зрения производительности) является пакет DPDK, который можно использовать для повышения производительности VNF на гипервизоре KVM. На рис. 2(a) показана схема обычного Open vSwitch, а на рис. 2(b) — Open vSwitch с DPDK. В стандартной реализации OVS переадресация пакетов между сетевыми адаптерами происходит по пути, находящемуся в пространстве ядра виртуального коммутатора. Он представляет собой простую таблицу потоков, указывающую, что делать с поступающими пакетами. Только первым пакетам потока необходимо заходить в пользовательское пространство виртуального коммутатора (по «медленному пути»), поскольку они не совпадают ни с одной из записей в простой таблице в пути данных ядра. После того как пользовательское пространство OVS обрабатывает первый пакет потока, оно обновляет таблицу в пространстве ядра, и все последующие пакеты уже не попадают в пользовательское пространство. За счет этого снижается как количество записей в таблице потоков пространства ядра, так и количество пакетов, которым необходимо заходить в пользовательское пространство, обработка в котором требует значительных вычислительных ресурсов.
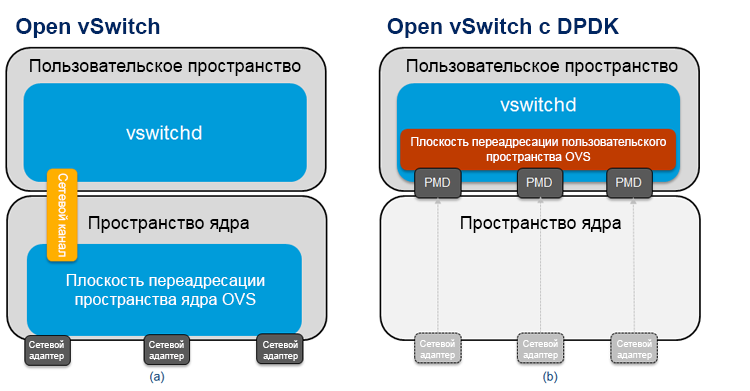
Рисунок 2. Схема (a) Open vSwitch* и (b) Data Plane Development Kit vSwitch.
В модели Open vSwitch с DPDK (рис. 2(b)) основная плоскость переадресации (иногда ее называют «быстрый путь») находится в пользовательском пространстве OVS и использует DPDK. Одно из основных отличий этой архитектуры состоит в том, что сетевые адаптеры здесь представляют собой драйверы опрашивающего режима (PMD), поскольку входящие пакеты непрерывно опрашиваются, а не управляются асинхронным образом с прерываниями. Начальные пакеты потока отправляются в другой модуль в пользовательском пространстве по тому же пути, по которому идут пакеты в случае с «быстрым путем» ядра.
На рис. 3 показаны фактические потоки трафика от OVS к гостевой виртуальной машине (ВМ), которая в контексте этой статьи выполняет функцию виртуального маршрутизатора. В стандартной реализации OVS переадресация OVS завершается в пространстве ядра (рис. 3(a)), а в модели OVS с DPDK переадресация OVS завершается в пользовательском пространстве (рис. 3(b)); очереди virtio гостевых виртуальных машин сопоставляются с OVS DPDK, поэтому OVS может напрямую читать и записывать в них данные. Путь трафика «из пользовательского пространства в пользовательское пространство» обычно обладает более высокой производительностью, чем путь через пространство ядра. Обратите внимание, что в обеих архитектурах гостевая ВМ может представлять собой как DPDK, так и стандартные драйверы Linux*. В тестах, описанных ниже, в сценарии высокой производительности используется VNF с драйверами DPDK.
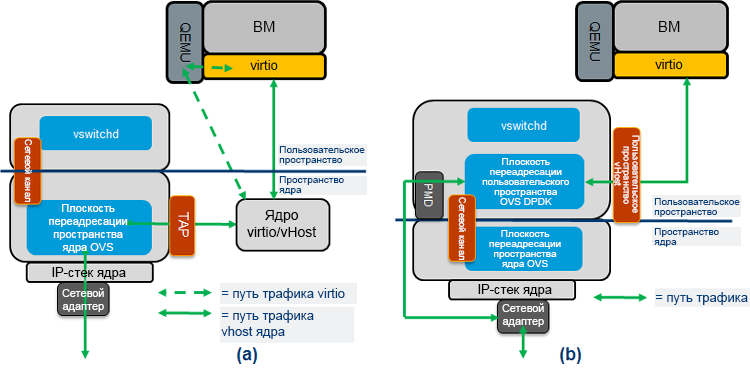
Рисунок 3. Поток трафика: (a) Open vSwitch* и (b) Data Plane Development Kit vSwitch.
Теоретически производительность Open vSwitch с DPDK должна быть выше, чем у стандартной модели OVS. Впрочем, важно проверить это на практике с помощью определенных тестов. В следующем разделе описывается тестовая система, а затем — фактически полученные результаты.
Основные компоненты тестовой системы показаны на рис. 3.
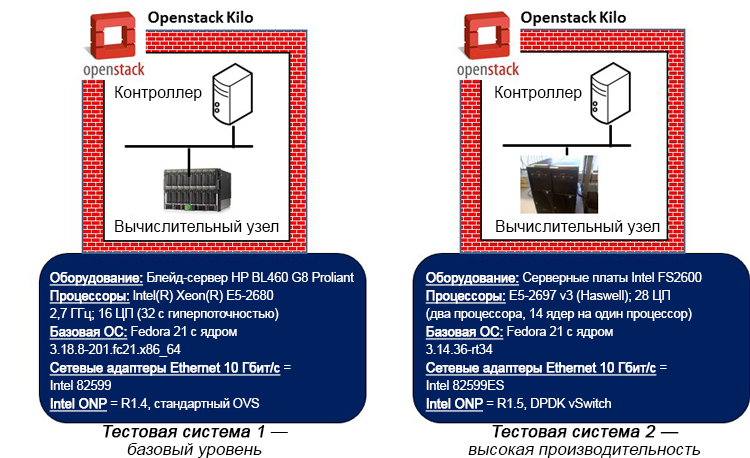
Рисунок 4. Тестовые системы базового уровня и высокой производительности (показанные сведения об оборудовании относятся к вычислительным узлам, представляющим тестируемые системы).
Для оценки и сравнения влияния высокопроизводительной архитектуры, такой как DPDK, на результаты задержек и дрожания, используются две эталонные тестовые системы. Каждая тестовая система включает один узел контроллера OpenStack и соответствующий вычислительный узел, построенный с помощью системы версии «Kilo». Вычислительный узел и связанные с ним гостевые VNF, запущенные на гипервизоре, представляют тестируемые системы.
В тестовой системе базового уровня используется процессор Intel Xeon E5-2680 (архитектура Sandy Bridge) без какой-либо оптимизации настроек BIOS. В высокопроизводительной тестовой системе используется процессор Intel Xeon E5-2697 v3 (архитектура Haswell) и проделана определенная настройка BIOS, направленная на повышение производительности при снижении потребляемой мощности, и отключение C- и P-состояний. В базовой системе используется стандартный путь данных в пространстве ядра, а в высокопроизводительной системе используется путь данных OVS DPDK. В качестве базовой ОС в обоих случаях используется Fedora* 21, но в системе базового уровня используется стандартное ядро не в реальном времени (3.18), а в высокопроизводительной системе используется ядро реального времени Linux (3.14) с соответствующей настройкой конфигурации (изоляция vSwitch и ядер ВМ от ОС основной системы, отключение расширенной безопасности Linux, использование опроса при бездействии и выбор наиболее подходящего таймера отметок времени). В базовой системе используются стандартные настройки OpenStack в отношении установки ВМ и назначения сетевых ресурсов. В высокопроизводительной системе настройка выполнена более точно: можно закреплять выделенные ЦП за vSwitch и VNF. Кроме того, в высокопроизводительной системе гарантируется использование для VNF центральных процессоров и памяти, установленных на одной и той же физической системе, а также использование определенных ЦП для прямого подключения к интерфейсам физических сетевых адаптеров на сервере.
В обеих тестовых системах в качестве фактической VNF во всех тестах использовался виртуальный маршрутизатор Brocade 5600* R3.5, а для длительного теста трафика использовалось устройство нагрузочного тестирования Spirent Test Center C1*. В высокопроизводительной системе виртуальный маршрутизатор использует драйверы DPDK. Как показано на рис. 5, были протестированы системы с одиночной VNF и со сдвоенной цепочкой обслуживания VNF.
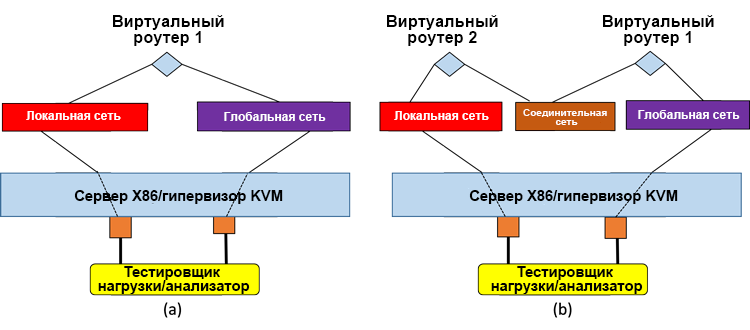
Рисунок 5. Тестируемые системы: (a) одиночный виртуальный маршрутизатор, (b) два виртуальных маршрутизатора в последовательной цепочке обслуживания.
Тестовые системы были настроены таким образом, чтобы обеспечить достаточную для работы офисов филиалов пропускную способность (не более 100 Мбит/с) не в ущерб точности измерений задержек и дрожания. Для всех тестов использованы следующие профили пакетов:
Тестовое оборудование использует подпись с отметкой времени для определения задержек между кадрами. Подпись находится в конце полезных данных рядом с контрольной последовательностью кадра (FCS), она содержит отметку времени, номера последова-тельности и идентификатор потока. Под «дрожанием» понимается разница во времени между двумя входящими кадрами в одном потоке. Поэтому так измеряется разница в задержках пакетов. Создавались одинаковые нагрузки трафика к тестируемой системе в каждом направлении, состоявшие из одного потока трафика. Результаты, приведенные в следующем разделе, описывают наихудшие метрики для определенного направления (т. е. приведенные значения задержек, дрожания и пр. даны только для однонаправленного трафика, а не для двусторонней передачи). Следует отметить, что показанные результаты относятся к установившейся работе сети: начальные результаты сбрасываются приблизительно через 20 секунд, а затем тест выполняется в течение назначенного времени. Такое решение позволяет получить достоверные результаты, на которые не повлияют первые пакеты потока, идущие по «медленному пути».
Средняя задержка одностороннего трафика, измеренная за пятиминутные интервалы для четырех различных профилей пакетов, показана для одиночной VNF на рис. 6 и на сдвоенной VNF на рис. 7.
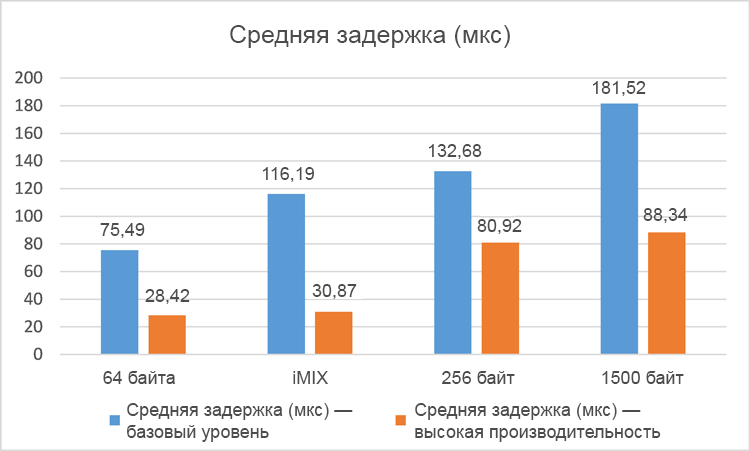
Рисунок 6. Средняя задержка (в микросекундах) для одной сети с виртуализацией (чем меньше, тем лучше).
Результаты средних задержек для разных профилей пакетов однозначно свидетельствуют о существенном повышении производительности (снижении средних задержек) в высокопроизво¬дительной системе по сравнению с системой базового уровня. В тестах с одиночной VNF задержки сократились на 38–74 %, а в тестах со сдвоенной VNF задержки снизились на 34–66 %. Как и следовало ожидать, общие задержки в случае со сдвоенной VNF оказались несколько выше в обеих тестовых системах из-за коммутации пакетов между двумя экземплярами VNF и в виртуальных коммутаторах в гипервизоре. Обратите внимание, что в этих тестах зафиксированы нулевые потери пакетов.
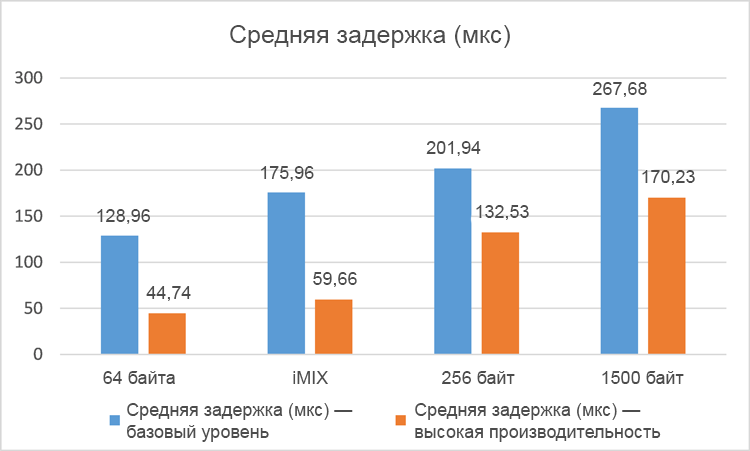
Рисунок 7. Средняя задержка (в микросекундах) для двух сетей с виртуализацией (чем меньше, тем лучше).
Имеет смысл подробнее рассмотреть результаты теста с определенным профилем пакетов. Например, тесты с 256-байтовыми макетами точнее воспроизводят кадры VoIP, формируемые протоколом RTP с кодированием G.7115. На рис. 8 показаны минимальные, средние и максимальные задержки одностороннего трафика для одиночной и сдвоенной VNF при использовании 256-байтовых пакетов.
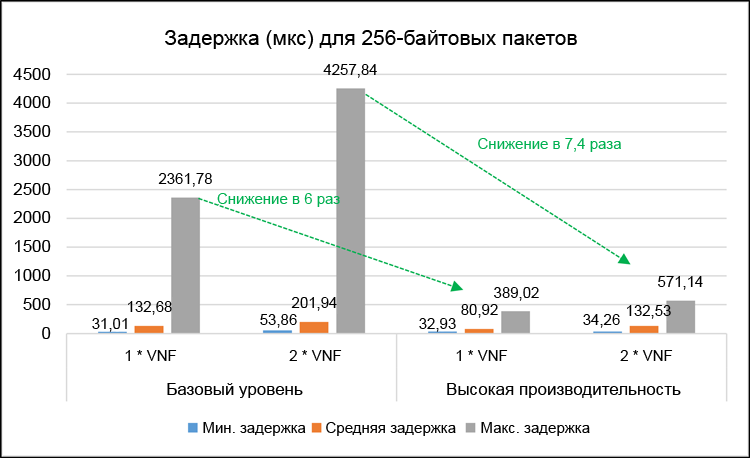
Рисунок 8. Подробные результаты задержек (в микросекундах) для 256-байтовых пакетов.
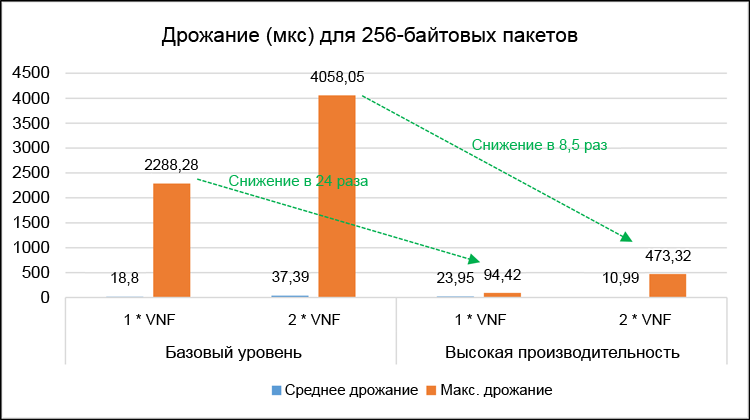
Рисунок 9. Подробные результаты дрожания (в микросекундах) для 256-байтовых пакетов.
На рис. 9 показаны соответствующие средние и максимальные значения дрожания одностороннего трафика. Максимальные значения задержек и дрожания важны для оценки наихудших характеристик производительности обеих тестовых систем. В высокопроизводительной системе максимальные задержки были снижены в 6 раз для одиночной VNF и в 7,4 раз для сдвоенной VNF. Максимальное дрожание сократилось, соответственно, в 24 раза и в 8,5 раз. Обратите внимание, что в этих тестах зафиксированы нулевые потери пакетов.
Важно не только оценить производительность за короткие интервалы, но и изучить возможные колебания производительности в течение длительного времени. На рис. 10 показаны результаты тестов максимальных задержек в тестах длительностью 5 минут в сравнении с тестами длительностью 16 часов для 256-байтовых пакетов и одиночной VNF. В целом, результаты свидетельствуют о приблизительно одинаковом повышении производительности в оптимизированной системе по сравнению с системой базового уровня: максимальные задержки снизились в 5 раз для 16-часового теста и в 6 раз для 5-минутного теста. При этом важно отметить, что значения максимальных задержек значительно выше в 16-часовых тестах. Это можно объяснить очень редкими событиями системного прерывания (т. е. задачами обслуживания), которые влияют на очень небольшое количество тестовых пакетов. Несмотря на это, значение максимальных задержек для одностороннего трафика в 16-часовых тестах с 256-байтовыми пакетами составило всего 2 мс. Это вполне пригодный результат, пороговым значением задержек для односторонней передачи голосового трафика является 150 мс согласно спецификациям МСЭ-Т G.1146. Другими словами, увеличение задержек, обусловленное добавлением vCPT, в наихудшем случае составляет всего 1,3 % от общей величины допустимых задержек. Даже в системе базового уровня максимальные задержки одностороннего трафика составили 9,95 мс, что составляет всего 6,6 % от общей допустимой величины.
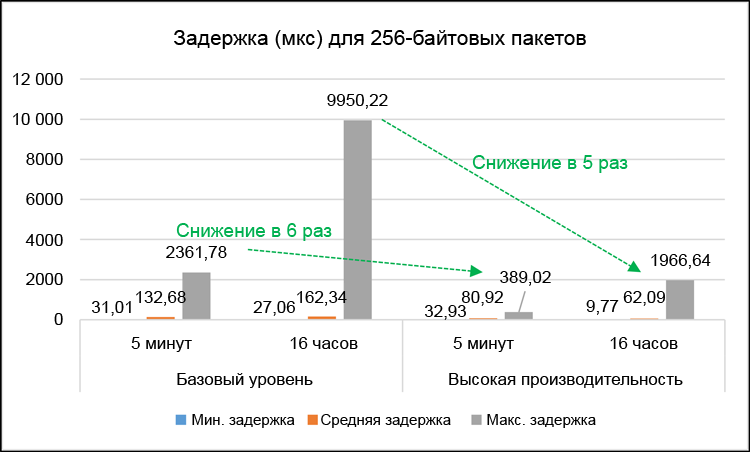
Рисунок 10. Результаты длительных тестов задержек в миллисекундах (сравнение 16-часовых и 5-минутных тестов).
В этой статье описана тонкая настройка виртуальной платформы инфраструктуры CPE на базе гипервизора KVM. В частности, использование некоторых компонентов архитектуры Intel ONP, таких как DPDK, может способствовать существенному повышению производительности по сравнению с базовой настройкой (без оптимизации). В тестах с одиночной VNF задержки одностороннего трафика сократились на 38–74 %, а в тестах со сдвоенной VNF задержки снизились на 34–66 %. В тестах, близких к трафику VoIP, где использовались 256-байтовые пакеты, максимальные задержки сократились в 6 раз (для одиночной VNF) и в 7,4 раз (для сдвоенной VNF), а максимальное дрожание, соответственно, в 24 раза и в 8,5 раз.
Опираясь на результаты экспериментов, можно заключить, что настройка производительности инфраструктуры NFV для чувствительных к задержкам приложений, таким как VoIP, позволит получить более определенные показатели общей производительности с точки зрения задержек и дрожания по сравнению с базовой конфигурацией (без оптимизации). Решение о применении оптимизации оператором сети будет в значительной степени зависеть от требуемого набора функций VNF, поддерживаемых инфраструктурой vCPE, а также от того, насколько метрики производительности, заданные в соглашении об уровне обслуживания (например, уровни задержек и дрожания), связаны со службами, опирающимися на эти функции VNF. На практике фактические соглашения об уровне обслуживания, используемые сетевыми операторами, будут содержать целевые показатели производительности в рамках собственной магистральной и транзитной сети оператора и будут различаться в зависимости от регионов. Значения времени двусторонней передачи IP-пакетов в 30–40 мс для Европы, 40–50 мс для Северной Америки и до 90 мс для трансатлантических каналов являются типичными примерами и эталонами средних задержек.
Если операторы сетей решат использовать оптимизацию NFV с помощью таких компонентов, как DPDK, вместо готовых решений с заводскими настройками, им следует оценить потенциальное влияние оптимизации на решения высокоуровневого управления: потребуется более четкое понимание параметров и настроек базовой инфраструктуры, чтобы обеспечить подготовку и управление функциями VNF согласно заданным требованиям производительности. Эксперименты, описываемые в этой статье, можно рассматривать в качестве основы для более подробного понимания способов оптимизации производительности, возможности их применения к существующим сетям и к перспективным инфраструктурам 5G.
Возможные темы для дальнейшего изучения включают следующие:
Очевидно, что в этой области существует еще немало интересных задач и проблем, требующих рассмотрения.
Результаты тестирования свидетельствуют о значительном повышении производительности с точки зрения сокращения задержек и уменьшения дрожания при оптимизации с использованием Data Plane Development Kit. Например, средние задержки удалось сократить на 38–74 % (в зависимости от профиля пакетов), а максимальные задержки сократились в 6 раз. Подобный анализ оптимизации производительности приобретет особую важность для интеллектуального управления нагрузкой и ресурсами как в существующих сетях, так и в перспективных сетях 5G.
I. Введение
Технология виртуализации сетевых функций (NFV) быстро переходит из лабораторных условий в рабочие среды и в пробную эксплуатацию у реальных заказчиков1. Ведется работа по стандартизации: ей занимается соответствующая группа отраслевых технических условий (ISG) в Европейском институте стандартов связи (ETSI). Основные направления стандартизации — измерение производительности и лучшие методики2. Важнейшей метрикой производительности является пропускная способность сетей, но в этой статье проблема производительности рассматривается под другим углом: обсуждается вопрос чувствительности к задержкам. В частности, изучается случай использования локального оборудования заказчиков с виртуализацией (vCPE) в корпорациях, когда определенный набор виртуальных сетевых функций (VNF) обычно находится в локальной ИТ-среде заказчика. В документе ETSI3 такая модель называется VE-CPE (рис. 1).
Примеры сетевых функций в локальной среде заказчика, способных выполняться в качестве VNF на стандартных серверах архитектуры x86 с гипервизором, включают, не ограничиваясь перечисленным, маршрутизаторы, брандмауэры, контроллеры границ сеансов и ускорители глобальных сетей. Филиалам обычно требуется не слишком мощный канал доступа к глобальной сети (по сравнению с центральными офисами): зачастую пропускная способность подключения к глобальной сети может составлять несколько десятков или сотен мегабит в секунду, то есть относительно немного по сравнению с магистральными каналами, пропускная способность которых может достигать и превышать один гигабит в секунду. Поэтому с точки зрения производительности важна не столько максимальная пропускная способность реализации vCPE в филиале, сколько возможность свести к минимуму задержки и колебания (дрожание).
Рисунок 1. Пример использования виртуального корпоративного оборудования в локальной среде заказчика (VE-CPE) в филиалах.
В большинстве корпоративных сетей, где филиалы подключаются к инфраструктуре глобальной сети, часть трафика будет приходиться на передачу голоса по протоколу IP (VoIP). Для этого трафика характерны более жесткие рамки с точки зрения задержек и дрожания, необходимые для обеспечения предсказуемой и гарантированной производительности. Даже если сетевые функции, связанные с передачей голоса (например, контроллеры границ сеансов — SBC), реализованы с помощью физических устройств, без виртуализации, другие функции в локальной среде закаказчика, передающие трафик конечных пользователей, могут быть виртуальными: очевидным примером являются маршрутизаторы на стороне клиента (CE). Поэтому важно настроить производительность инфраструктуры NFV так, чтобы она обеспечивала такой же уровень предсказуемости для задержек и дрожания. Это позволит получить более четкое представление о влиянии компонентов инфраструктуры NFV на общую картину производительности приложений, чувствительных к задержкам.
Во второй части описывается платформа Intel Open Networking Platform (Intel ONP) и пакет Data Plane Development Kit (DPDK), а в третьей части говорится о тестировании среды vCPE с точки зрения оценки задержек и дрожания. Результаты фактических тестов приведены в четвертой части. Пятая часть содержит выводы, а шестая — рекомендуемые материалы для дальнейшего изучения.
II. Open Network Platform и Data Plane Development Kit
Способы определения и реализации решений NFV операторами связи для различных сценариев использования, таких как vCPE, зависят от ряда факторов, в том числе от стоимости, технических условий и взаимодействия с решениями других поставщиков. В результате создаются решения для NFV с открытым исходным кодом, например использующие технологию гипервизора виртуальных машин на базе ядра (KVM) с Open vSwitch* (OVS), и открытые средства управления, такие как OpenStack*. Intel ONP объединяет ряд таких компонентов с открытым исходным кодом и образует модульную архитектурную платформу для NFV4.
Одним из важнейших компонентов архитектуры Intel ONP (с точки зрения производительности) является пакет DPDK, который можно использовать для повышения производительности VNF на гипервизоре KVM. На рис. 2(a) показана схема обычного Open vSwitch, а на рис. 2(b) — Open vSwitch с DPDK. В стандартной реализации OVS переадресация пакетов между сетевыми адаптерами происходит по пути, находящемуся в пространстве ядра виртуального коммутатора. Он представляет собой простую таблицу потоков, указывающую, что делать с поступающими пакетами. Только первым пакетам потока необходимо заходить в пользовательское пространство виртуального коммутатора (по «медленному пути»), поскольку они не совпадают ни с одной из записей в простой таблице в пути данных ядра. После того как пользовательское пространство OVS обрабатывает первый пакет потока, оно обновляет таблицу в пространстве ядра, и все последующие пакеты уже не попадают в пользовательское пространство. За счет этого снижается как количество записей в таблице потоков пространства ядра, так и количество пакетов, которым необходимо заходить в пользовательское пространство, обработка в котором требует значительных вычислительных ресурсов.
Рисунок 2. Схема (a) Open vSwitch* и (b) Data Plane Development Kit vSwitch.
В модели Open vSwitch с DPDK (рис. 2(b)) основная плоскость переадресации (иногда ее называют «быстрый путь») находится в пользовательском пространстве OVS и использует DPDK. Одно из основных отличий этой архитектуры состоит в том, что сетевые адаптеры здесь представляют собой драйверы опрашивающего режима (PMD), поскольку входящие пакеты непрерывно опрашиваются, а не управляются асинхронным образом с прерываниями. Начальные пакеты потока отправляются в другой модуль в пользовательском пространстве по тому же пути, по которому идут пакеты в случае с «быстрым путем» ядра.
На рис. 3 показаны фактические потоки трафика от OVS к гостевой виртуальной машине (ВМ), которая в контексте этой статьи выполняет функцию виртуального маршрутизатора. В стандартной реализации OVS переадресация OVS завершается в пространстве ядра (рис. 3(a)), а в модели OVS с DPDK переадресация OVS завершается в пользовательском пространстве (рис. 3(b)); очереди virtio гостевых виртуальных машин сопоставляются с OVS DPDK, поэтому OVS может напрямую читать и записывать в них данные. Путь трафика «из пользовательского пространства в пользовательское пространство» обычно обладает более высокой производительностью, чем путь через пространство ядра. Обратите внимание, что в обеих архитектурах гостевая ВМ может представлять собой как DPDK, так и стандартные драйверы Linux*. В тестах, описанных ниже, в сценарии высокой производительности используется VNF с драйверами DPDK.
Рисунок 3. Поток трафика: (a) Open vSwitch* и (b) Data Plane Development Kit vSwitch.
Теоретически производительность Open vSwitch с DPDK должна быть выше, чем у стандартной модели OVS. Впрочем, важно проверить это на практике с помощью определенных тестов. В следующем разделе описывается тестовая система, а затем — фактически полученные результаты.
III. Описание тестовой системы
Основные компоненты тестовой системы показаны на рис. 3.
Рисунок 4. Тестовые системы базового уровня и высокой производительности (показанные сведения об оборудовании относятся к вычислительным узлам, представляющим тестируемые системы).
Для оценки и сравнения влияния высокопроизводительной архитектуры, такой как DPDK, на результаты задержек и дрожания, используются две эталонные тестовые системы. Каждая тестовая система включает один узел контроллера OpenStack и соответствующий вычислительный узел, построенный с помощью системы версии «Kilo». Вычислительный узел и связанные с ним гостевые VNF, запущенные на гипервизоре, представляют тестируемые системы.
В тестовой системе базового уровня используется процессор Intel Xeon E5-2680 (архитектура Sandy Bridge) без какой-либо оптимизации настроек BIOS. В высокопроизводительной тестовой системе используется процессор Intel Xeon E5-2697 v3 (архитектура Haswell) и проделана определенная настройка BIOS, направленная на повышение производительности при снижении потребляемой мощности, и отключение C- и P-состояний. В базовой системе используется стандартный путь данных в пространстве ядра, а в высокопроизводительной системе используется путь данных OVS DPDK. В качестве базовой ОС в обоих случаях используется Fedora* 21, но в системе базового уровня используется стандартное ядро не в реальном времени (3.18), а в высокопроизводительной системе используется ядро реального времени Linux (3.14) с соответствующей настройкой конфигурации (изоляция vSwitch и ядер ВМ от ОС основной системы, отключение расширенной безопасности Linux, использование опроса при бездействии и выбор наиболее подходящего таймера отметок времени). В базовой системе используются стандартные настройки OpenStack в отношении установки ВМ и назначения сетевых ресурсов. В высокопроизводительной системе настройка выполнена более точно: можно закреплять выделенные ЦП за vSwitch и VNF. Кроме того, в высокопроизводительной системе гарантируется использование для VNF центральных процессоров и памяти, установленных на одной и той же физической системе, а также использование определенных ЦП для прямого подключения к интерфейсам физических сетевых адаптеров на сервере.
В обеих тестовых системах в качестве фактической VNF во всех тестах использовался виртуальный маршрутизатор Brocade 5600* R3.5, а для длительного теста трафика использовалось устройство нагрузочного тестирования Spirent Test Center C1*. В высокопроизводительной системе виртуальный маршрутизатор использует драйверы DPDK. Как показано на рис. 5, были протестированы системы с одиночной VNF и со сдвоенной цепочкой обслуживания VNF.
Рисунок 5. Тестируемые системы: (a) одиночный виртуальный маршрутизатор, (b) два виртуальных маршрутизатора в последовательной цепочке обслуживания.
Тестовые системы были настроены таким образом, чтобы обеспечить достаточную для работы офисов филиалов пропускную способность (не более 100 Мбит/с) не в ущерб точности измерений задержек и дрожания. Для всех тестов использованы следующие профили пакетов:
- 64-байтовые кадры (двунаправленная нагрузка 25 Мбит/с)
- 256-байтовые кадры (двунаправленная нагрузка 25 Мбит/с)
- Смешение кадров iMix в реалистичном представлении (двунаправленная нагрузка 50 Мбит/с)
- 1500-байтовые кадры (двунаправленная нагрузка 100 Мбит/с)
Тестовое оборудование использует подпись с отметкой времени для определения задержек между кадрами. Подпись находится в конце полезных данных рядом с контрольной последовательностью кадра (FCS), она содержит отметку времени, номера последова-тельности и идентификатор потока. Под «дрожанием» понимается разница во времени между двумя входящими кадрами в одном потоке. Поэтому так измеряется разница в задержках пакетов. Создавались одинаковые нагрузки трафика к тестируемой системе в каждом направлении, состоявшие из одного потока трафика. Результаты, приведенные в следующем разделе, описывают наихудшие метрики для определенного направления (т. е. приведенные значения задержек, дрожания и пр. даны только для однонаправленного трафика, а не для двусторонней передачи). Следует отметить, что показанные результаты относятся к установившейся работе сети: начальные результаты сбрасываются приблизительно через 20 секунд, а затем тест выполняется в течение назначенного времени. Такое решение позволяет получить достоверные результаты, на которые не повлияют первые пакеты потока, идущие по «медленному пути».
IV. Результаты тестирования
A. Смешанные тесты
Средняя задержка одностороннего трафика, измеренная за пятиминутные интервалы для четырех различных профилей пакетов, показана для одиночной VNF на рис. 6 и на сдвоенной VNF на рис. 7.
Рисунок 6. Средняя задержка (в микросекундах) для одной сети с виртуализацией (чем меньше, тем лучше).
Результаты средних задержек для разных профилей пакетов однозначно свидетельствуют о существенном повышении производительности (снижении средних задержек) в высокопроизво¬дительной системе по сравнению с системой базового уровня. В тестах с одиночной VNF задержки сократились на 38–74 %, а в тестах со сдвоенной VNF задержки снизились на 34–66 %. Как и следовало ожидать, общие задержки в случае со сдвоенной VNF оказались несколько выше в обеих тестовых системах из-за коммутации пакетов между двумя экземплярами VNF и в виртуальных коммутаторах в гипервизоре. Обратите внимание, что в этих тестах зафиксированы нулевые потери пакетов.
Рисунок 7. Средняя задержка (в микросекундах) для двух сетей с виртуализацией (чем меньше, тем лучше).
B. Тесты 256-байтовых пакетов
Имеет смысл подробнее рассмотреть результаты теста с определенным профилем пакетов. Например, тесты с 256-байтовыми макетами точнее воспроизводят кадры VoIP, формируемые протоколом RTP с кодированием G.7115. На рис. 8 показаны минимальные, средние и максимальные задержки одностороннего трафика для одиночной и сдвоенной VNF при использовании 256-байтовых пакетов.
Рисунок 8. Подробные результаты задержек (в микросекундах) для 256-байтовых пакетов.
Рисунок 9. Подробные результаты дрожания (в микросекундах) для 256-байтовых пакетов.
На рис. 9 показаны соответствующие средние и максимальные значения дрожания одностороннего трафика. Максимальные значения задержек и дрожания важны для оценки наихудших характеристик производительности обеих тестовых систем. В высокопроизводительной системе максимальные задержки были снижены в 6 раз для одиночной VNF и в 7,4 раз для сдвоенной VNF. Максимальное дрожание сократилось, соответственно, в 24 раза и в 8,5 раз. Обратите внимание, что в этих тестах зафиксированы нулевые потери пакетов.
Важно не только оценить производительность за короткие интервалы, но и изучить возможные колебания производительности в течение длительного времени. На рис. 10 показаны результаты тестов максимальных задержек в тестах длительностью 5 минут в сравнении с тестами длительностью 16 часов для 256-байтовых пакетов и одиночной VNF. В целом, результаты свидетельствуют о приблизительно одинаковом повышении производительности в оптимизированной системе по сравнению с системой базового уровня: максимальные задержки снизились в 5 раз для 16-часового теста и в 6 раз для 5-минутного теста. При этом важно отметить, что значения максимальных задержек значительно выше в 16-часовых тестах. Это можно объяснить очень редкими событиями системного прерывания (т. е. задачами обслуживания), которые влияют на очень небольшое количество тестовых пакетов. Несмотря на это, значение максимальных задержек для одностороннего трафика в 16-часовых тестах с 256-байтовыми пакетами составило всего 2 мс. Это вполне пригодный результат, пороговым значением задержек для односторонней передачи голосового трафика является 150 мс согласно спецификациям МСЭ-Т G.1146. Другими словами, увеличение задержек, обусловленное добавлением vCPT, в наихудшем случае составляет всего 1,3 % от общей величины допустимых задержек. Даже в системе базового уровня максимальные задержки одностороннего трафика составили 9,95 мс, что составляет всего 6,6 % от общей допустимой величины.
Рисунок 10. Результаты длительных тестов задержек в миллисекундах (сравнение 16-часовых и 5-минутных тестов).
V. Заключение и выводы
В этой статье описана тонкая настройка виртуальной платформы инфраструктуры CPE на базе гипервизора KVM. В частности, использование некоторых компонентов архитектуры Intel ONP, таких как DPDK, может способствовать существенному повышению производительности по сравнению с базовой настройкой (без оптимизации). В тестах с одиночной VNF задержки одностороннего трафика сократились на 38–74 %, а в тестах со сдвоенной VNF задержки снизились на 34–66 %. В тестах, близких к трафику VoIP, где использовались 256-байтовые пакеты, максимальные задержки сократились в 6 раз (для одиночной VNF) и в 7,4 раз (для сдвоенной VNF), а максимальное дрожание, соответственно, в 24 раза и в 8,5 раз.
Опираясь на результаты экспериментов, можно заключить, что настройка производительности инфраструктуры NFV для чувствительных к задержкам приложений, таким как VoIP, позволит получить более определенные показатели общей производительности с точки зрения задержек и дрожания по сравнению с базовой конфигурацией (без оптимизации). Решение о применении оптимизации оператором сети будет в значительной степени зависеть от требуемого набора функций VNF, поддерживаемых инфраструктурой vCPE, а также от того, насколько метрики производительности, заданные в соглашении об уровне обслуживания (например, уровни задержек и дрожания), связаны со службами, опирающимися на эти функции VNF. На практике фактические соглашения об уровне обслуживания, используемые сетевыми операторами, будут содержать целевые показатели производительности в рамках собственной магистральной и транзитной сети оператора и будут различаться в зависимости от регионов. Значения времени двусторонней передачи IP-пакетов в 30–40 мс для Европы, 40–50 мс для Северной Америки и до 90 мс для трансатлантических каналов являются типичными примерами и эталонами средних задержек.
Если операторы сетей решат использовать оптимизацию NFV с помощью таких компонентов, как DPDK, вместо готовых решений с заводскими настройками, им следует оценить потенциальное влияние оптимизации на решения высокоуровневого управления: потребуется более четкое понимание параметров и настроек базовой инфраструктуры, чтобы обеспечить подготовку и управление функциями VNF согласно заданным требованиям производительности. Эксперименты, описываемые в этой статье, можно рассматривать в качестве основы для более подробного понимания способов оптимизации производительности, возможности их применения к существующим сетям и к перспективным инфраструктурам 5G.
VI. Задачи на будущее
Возможные темы для дальнейшего изучения включают следующие:
- Изучение «уровней оптимизации» и влияние каждого из них на общую оптимизацию: выбор оборудования (в частности, влияние процессоров Intel Xeon E5-2680 и Intel Xeon E5-2697 v3 на различия в длительности задержек), настройки BIOS (например, можно включить P-состояние, чтобы разрешить использовать технологию Intel SpeedStep для повышения эффективности нагрузки на мощность), настройки ядра реального времени (например, «no hertz kernel», опрос операций чтения, копирования и обновления), настройки гипервизора и настройки VNF — все это определяет характеристики архитектуры. Поэтому следует получить более четкое представление о возможных мерах оптимизации и об их влиянии на каждый уровень.
- Следует рассмотреть возможность проведения аналогичных тестов оценки производительности для более широкого набора разных типов VNF, в том числе и специализированных для VoIP.
- Можно усовершенствовать аналитику тестов, чтобы оценить распределение значений задержек пакетов и дрожания в зависимости от профилей и частоты.
- Дальнейший анализ оптимизации NFV с точки зрения высокоуровневого управления: если модуль управления будет «знать» о базовых ресурсах и способности использовать определенные настройки инфраструктуры NFV с помощью таких возможностей, как DPDK, решение управления станет более сложным, но зато можно будет настраивать распределение чувствительных к задержкам VNF на наиболее подходящей инфраструктуре NFV.
Очевидно, что в этой области существует еще немало интересных задач и проблем, требующих рассмотрения.
Справочные материалы
- Дж. Стрэдлинг. «Глобальное обновление WAN: ведущие игроки и основные тенденции», отчет с рекомендациями по итогам текущего анализа, сентябрь 2015 г.
- «Производительность виртуализации сетевых функций и лучшие методики переносимости», спецификация ETSI ISG GS NFV-PER001, V1.1.1. Июнь 2014 г.
- «Примеры использования виртуализации сетевых функций», спецификация ETSI ISG GS NFV001, V1.1.1. Октябрь 2013 г.
- «Intel Open Network Platform Server (версия 1.5)», заметки к выпуску, ноябрь 2015 г.
- «Измерение производительности NFV для vCPE», отчет о тестировании сетей, Overture Networks, май 2015 г.
- «Спецификация МСЭ-Т G114 — время односторонней передачи», май 2003 г.
Поделиться с друзьями