
Shinken
Согласно официальному сайту, Shinken — фреймворк мониторинга; переписанный с нуля на питоне Nagios Core, с улучшенной поддержкой больших окружений и более гибкий.
Масштабируемость
Согласно документации, каждый тип используемых процессов может запускаться на отдельном хосте. Это очень полезная возможность, поскольку вы можете захотеть иметь базу данных в самом дешёвом месте, процессы сбора информации в каждом датацентре, и процессы рассылки уведомлений ближе к своему физическому расположению. Пользователь Shinken на схеме счастлив, это точно является хорошим признаком:
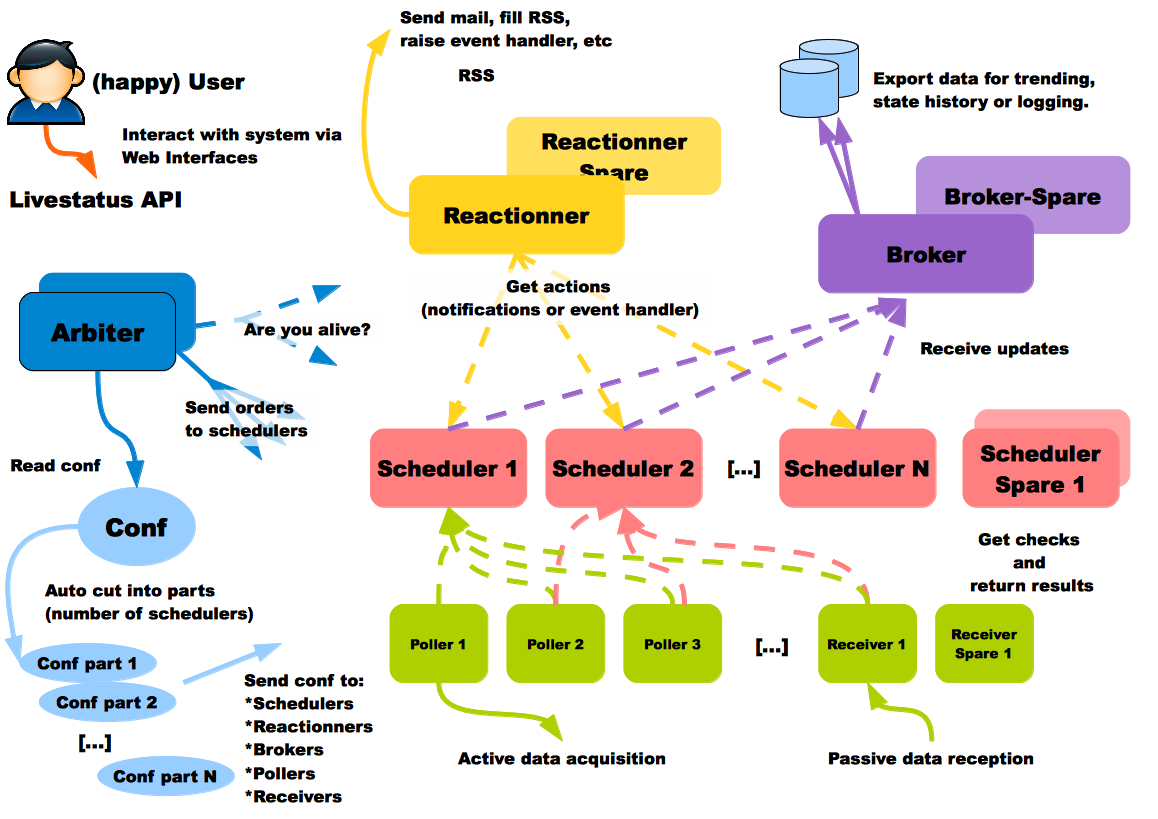
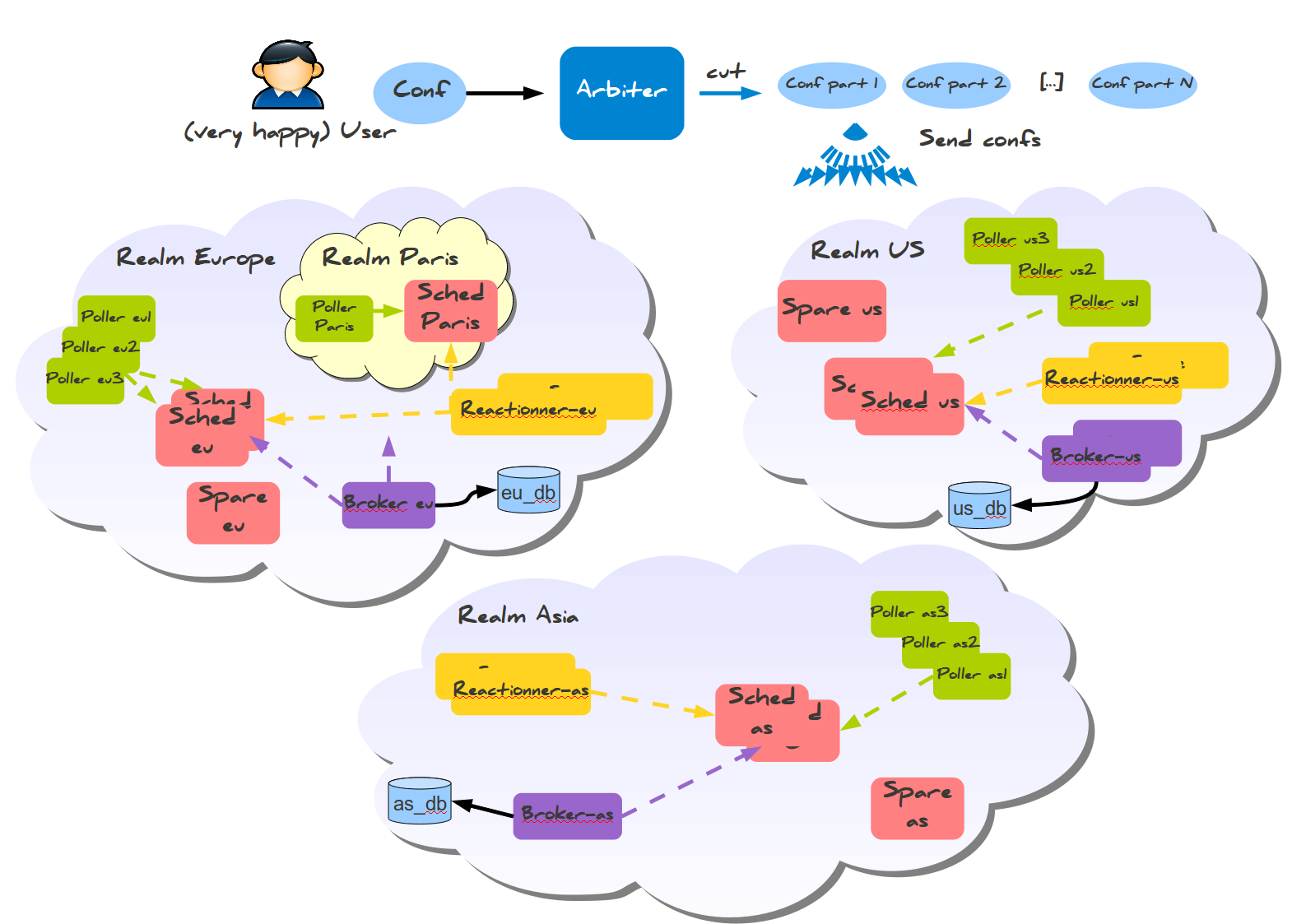
Эта система также имеет готовую конфигурацию для межрегионального мониторинга, называемая Realms (Сферы).
{kind=link}
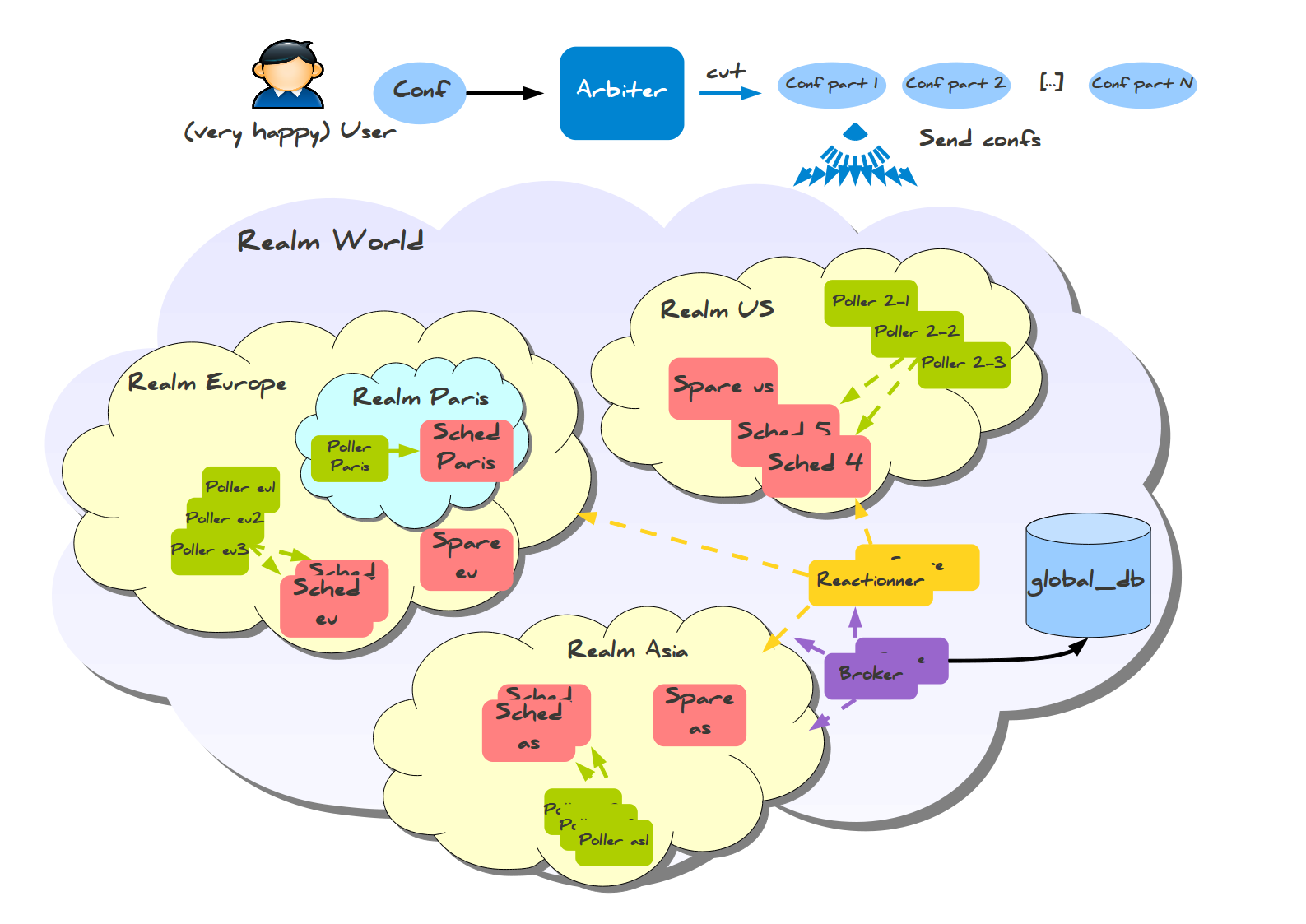
Здесь вы можете заметить кое-что изумительное: информация собирается в региональные базы данных, а не в одну мастер-базу. Также существует меньшая разновидность конфигурации со сферами для меньших распределённых конфигураций, которая требует всего одну базу данных и несколько хостов для установки:
Ещё одной болевой точкой при оценке масштабируемости является отказоустойчивость. Эту информацию я процитирую из документации:
Никто не идеален. Сервер может упасть, как и приложение, поэтому администраторы имеют подмены: они могут взять конфигурацию упавших элементов и переподнять их. На текущий момент единственный процесс, который не имеет подмены — Арбитр, но в будущем он будет доработан. Армибр регулярно проверяет, доступны ли все остальные процессы, и если планировщик или другой процесс мертвы, он посылает их конфигурацию на другую ноду, определённую администратором. Все процессы оповещаются об этом изменении, так что они могут использовать новую ноду для доступа к процессу, и не будут пытаться использовать зазбоившую. Если нода была потеряна из-за сетевых проблем, и вернулась в строй, Арбитр заметит это и попросит ноду, выступавшую заменой, сбросить свою временную роль.
Интеграция с системами управления конфигурацией
Автоматическое нахождение хостов и сервисов хорошо покрывается документацией, и, поскольку конфигурация хранится в файлах, вы довольно просто можете генерировать её с помощью Chef\Puppet, основываясь на информации, уже имеющейся в системе конфигурации (например, PuppetDB).
Логирование действий
Поскольку конфигурация хранится в файлах, вы можете использовать имеющиеся инструменты типа системы контроля версий (Git, Mercurial) для отслеживания изменений и их владельцев. В документации я не нашёл никаких подтверждений того, что Shinken записывает куда-либо действия пользователя в веб-интерфейсе.
UI

Shinken WebUI по заверениям использующих его людей хорошо показал себя при работе с тысячами машин и десятками групп.
Недостатки
Прошерстив документацию, я не нашёл видимых недостатков. Единственная вещь, которая меня смущает, это стремительная разработка в прошлом и очень медленный темп коммитов в настоящем: около 40 в этом году, большинство — вливание пулл-реквестов с багфиксами. Система или слишком хороша для дальнейшего развития (чего не бывает в природе, даже такие старички, как vim и emacs получают новые релизы), или теперь это ещё один открытый проект с недостаточно большим сообществом или проблемами с мейнтейнером — это такая информация, которую хотелось бы знать до начала использования такой комплексной вещи, как система мониторинга.
Frederic Mohier, бывший когда-то в команде разработки Shinken любезно предоставил информацию по этому вопросу: больше года назад несколько разработчиков из команды, будучи несогласными с политикой разработки, покинуло проект и сделало форк, названный Alignak, в данный момент активно разрабатываемый, первый стабильный релиз (1.0) планируется на декабрь 2016.
Ссылки
Sensu
Sensu — фреймворк для мониторинга (или платформа, как они сами о себе говорят), но не готовая система мониторинга.
Её сильные стороны включают:
- Интеграция с Puppet \ Chef — определяйте, что проверять, и куда отправлять уведомления прямо в вашей системе управления конфигурацией
- Использование имеющихся технических решений там, где это возможно, вместо изобретения велосипедов (Redis, RabbitMQ)
Sensu вытягивает события из очереди и выполняет на них обработчики, вот и всё. Обработчики (Handlers) могут посылать сообщения, выполнять что-то на сервере, или делать что угодно ещё, чему вы их научите.
Масштабируемость
Sensu имеет гибкую архитектуру, поскольку каждый компонент может быть продублирован и заменён несколькими путями. Пример простой отказоустойчивой системы описан в следующей презентации; вот общая схема:

С HAProxy и Redis-sentinel вы можете построить систему, в которой, при наличии хотя бы одной живой машины каждого типа (Sensu API, Sensu Dashboard, RabbitMQ, Redis) мониторинг будет продолжать работать без какого-либо ручного вмешательства.
Интеграция с системами управления конфигурацией
Встроенная (Puppet, Chef, EC2?!) но только в платной версии, что плохо, особенно если у вас тысячи серверов и вы не хотите платить за что-то, имеющее бесплатные аналоги.
Логирование действий
Встроенное, однако только в платной редакции.
UI
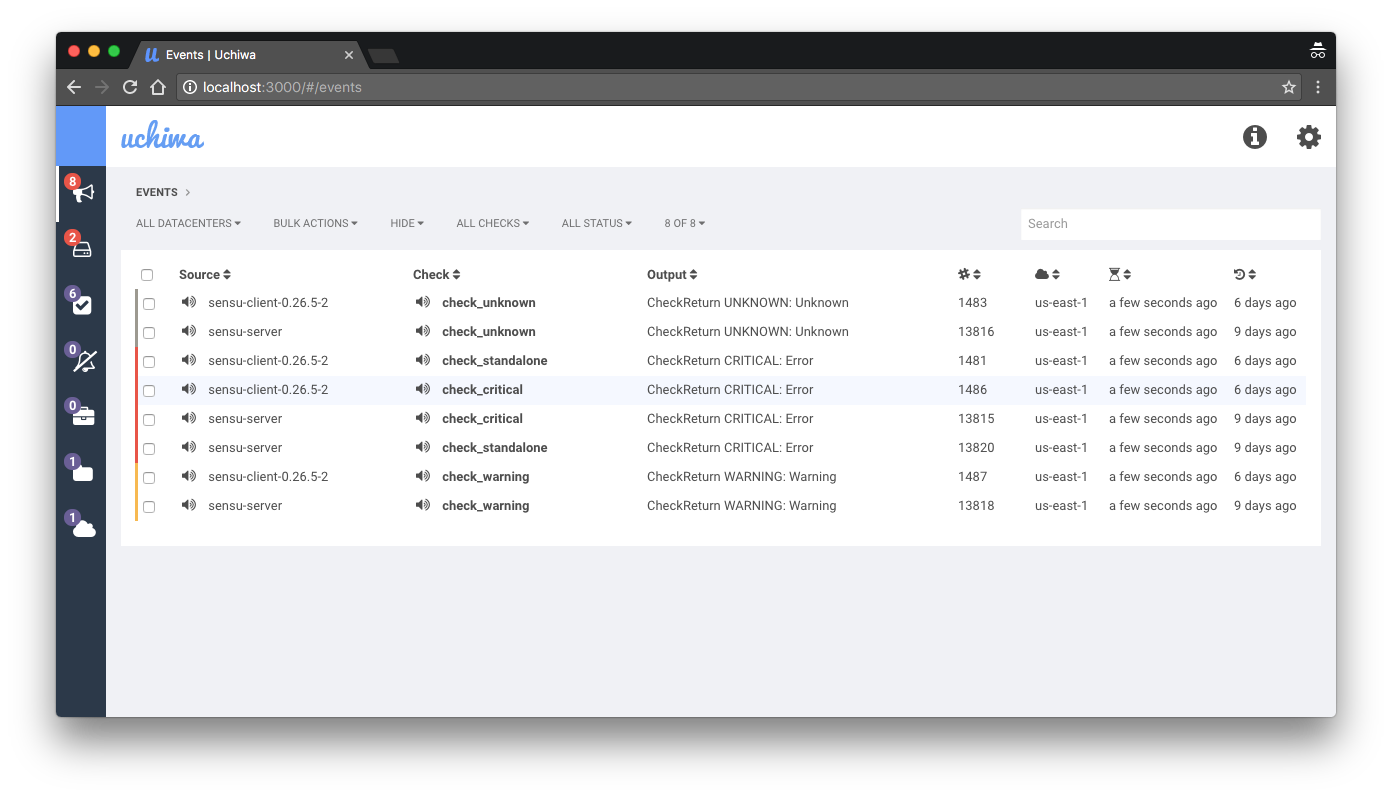
Интерфейс по-умолчанию для Sensu, Uchiwa, имеет много ограничений. Он выглядит слишком простым для окружения с тысячами хостов, которые имеют большой разброс по ролям. Платная версия имеет свой собственный дашборд, однако он не сильно отличается от бесплатной редакции, и только добавляет несколько выключенных из-коробки возможностей открытой версии.
Недостатки
- Отсутствие исторической информации и очень ограниченные возможности создания проверок, основанной на ней;
- Подход "сделай сам" — нет готового мониторинга, который можно было бы включить для вашей системы сразу после установки;
- Агрегирование событий нетривиально;
Замудрёная отправка сообщений, что страшно (потому что это та часть системы, которая должна быть самой простой и надёжной)— неправда, я получил неправильное впечатление от документации, спасибо x70b1 за разъяснение;- Путь "мы не хотим изобретать колесо" имеет свои ограничения, которые могут быть вам знакомы, если вы когда-либо использовали подобные системы (в моём случае, это была система мониторинга Prometheus, которая оставляла ряд функций на откуп пользователю, например, авторизацию\аутентификацию\идентификацию).
Ссылки
Icinga 2
Icinga это форк Nagios'а, во второй версии переписанный с нуля. В отличии от Shinken, этот живой, часто обновляющийся проект.
Масштабируемость
Общая архитектура:

Icinga 2 имеет хорошо продуманную схему распределённого мониторинга. Единственный минус, который я обнаружил при поднятии тестового кластера — сложная изначальная настройка даже самой простейшей распределённой схемы.
Интеграция с системами управления конфигурацией
Интеграция довольно хороша, вот две презентации по теме: The Road to Lazy Monitoring with Icinga 2 and Puppet от Tom de Vylder, и Icinga 2 and Puppet: Automated Monitoring от Walter Heck. Ключевой особенностью Icinga является хранение конфигурации в файлах, что позволяет легко генерировать конфигурацию средствами Puppet, что в моём случае получилось, используя PuppetDB в качестве источника информации о всех хостах и сервисах.
Логирование действий
Как я обнаружил, логирование действий представлено в модуле director. Встроенной поддержки аудита в IcingaWeb2 в данный момент нет.
UI

IcingaWeb2 выглядит неплохим UI с большим количеством дополнений под разные нужды. Из того, что я видел, он выглядит самым гибким и расширяемым, в то же время из коробки поддерживая все возможности, которые вы можете ожидать.
Недостатки
Единственным недостатком, который я встретил, является сложность изначальной настройки. Непросто понять взгляд Icinga на мониторинг, если вы до этого использовали что-то совершенно иное, как, в моём случае, Zabbix.
Zabbix
Zabbix — стабильная и надёжная система мониторинга с устойчивой скоростью развития. Он имеет огромное сообщество пользователей и большинство вопросов, которыми вы зададитесь, уже где-то отвечены, так что вам не прийдётся лишний раз волноваться, а возможно ли то или иное в Zabbix.
Масштабируемость
Сервер работает с единственной базой данных, и вне зависимости от ваших действий, с любыми другими ресурсами на руках (память, сеть, CPU), вы в какой-то момент упрётесь в ограничения IO на диске, используемом базой данных. С 6000 IOPS в Amazon мы поддерживаем около двух тысяч nvps, новых значений в секунду, что неплохо, но всё же оставляет желать лучшего. Прокси и partitioning базы данных улучшает производительность, однако с точки зрения отказаустойчивости вы всё ещё имеете одну-единственную БД, которая является точкой отказа для всей системы.
Интеграция с системами управления конфигурацией
Zabbix слабо подготовлен для разнообразного окружения, которое управляется системой управления конфигураций. Он имеет встроенные возможности для low-level обнаружения хостов и сервисов, но они имеют свои ограничения и не имеют привязки к системе конфигурации. Единственная возможность для подобной интеграции — собственное решение, использующее API.
Логирование действий
Zabbix хорошо логирует действия пользователей, за исключением одного слепого пятна: изменения, сделанные через API, большей частью не логгируются, что может быть или может не быть проблемой для вас. Ещё одна вещь, которую я хотел бы упомянуть, это то, что все проблемы с Zabbix записаны где-то в баг-трекере, и, если они получают достаточно внимания со стороны сообщества, то рано или поздно устраняются.
UI

UI Zabbix'а удобен и включает в себя много возможностей. Обратная сторона — он практически не расширяем, вы или смиряетесь с тем, что предлагает вам стандартный dashboard, либо создаёте свой собственный. Доработка стандартного UI является очень нетривиальной задачей из-за его сложности.
Недостатки
- Только базовая аналитика о том, что происходит в данный момент (не в плане текущих проблем, а частоты из происхождения и подобной информации). Ситуация сильно улучшилась с появлением "топ 100 стреляющих триггеров" в 3.0;
- Настройка плановых работ (maintenance), в отличии от систем, основанных на Nagios, не может быть выставлена на уровне триггера, и была довольно сложной до недавней переделки 3.2;
- Генерация алертов из-коробки оставляет желать лучшего (что, впрочем, является проблемой всех до единой систем мониторинга). В нашем случае пришлось разработать внешнюю систему аггрегации алертов (возможно, когда-нибудь она будет опубликована в opensource);
- Расследование проблем с производительностью без соответствующего опыта превращается в беспорядок, потому что у вас есть один неделимый сервер, который вам необходимо диагностировать.
Disclaimer
Это длинная запись с большим количеством картинок и ещё большим количеством текста. Здесь вы не найдёте однозначного ответа на простые вопросы наподобие "что лучше", но информацию для ответа на эти вопросы, основываясь на вашем опыте и желаниях. Я рассматриваю условия работы в Linux и слежения за Linux-хостами, поэтому поддержка системой разных платформ в расчёт не принималась. Также за условие принималось требование возможности следить за тысячами машин и тысячами сервисов.
По моему мнению, только Zabbix и Icinga 2 являются достаточно зрелыми для использования в "энтерпрайзе", главный вопрос, который должен задать себе тот, кто выбирает систему — какая философия мониторинга ему ближе, поскольку обе они позволяют получить один и тот же результат, используя совершенно разные подходы.
Комментарии (38)

Erelecano
28.12.2016 12:09Сравнивать клоны игрушечной системы типа Nagios не предназначенной для настоящей работы и Zabbix глупо. Zabbix — система мониторинга продакшен-левела, с сильной командой за ней, с платной поддержкой, с курсами, с собственными железными решениями с заббиксом на борту(до сих пор только в Японии вроде продающимся, правда) и нагиос написанный фриком для фрика и не способный работать больше чем с пятком серверов.
Использовал и то, и другое. О нагиосе вспоминаю, как о страшном сне. Хвала Владышеву и его команде, что есть Zabbix.
muon
28.12.2016 13:23нагиос написанный фриком для фрика и не способный работать больше чем с пятком серверов
Чтобы писать о Nagios такое, надо либо ничего про него не знать, либо быть обиженным неосилятором. В любом из этих двух случаев, лучше взять себя в руки и промолчать.Erelecano
28.12.2016 13:27-5Знаете, какая штука, вы еще учились в школе, а я уже админил *nix-like системы. Вот я до сих пор админю, а вы до сих пор не выросли из школьного уровня.
Я использовал нагиос около пяти лет, так что я могу очень хорошо судить об этой поделке. Извините, но поделие в котором для добавления адреса алерта нужно править конфиги на сервере, а не сказать секретарю «Добавь там в веб-морде» не имеет право на существование. И это я молчу про все остальное.
Лучше молчите, чем говорите глупости. Я понимаю, что вы админите свой локалхост и там этой глючной поделки хватает за глаза и уши, но однажды родители перестанут вас кормить и вам придется пойти работать, а там нагиос использовать не выйдет.muon
28.12.2016 16:02нужно править конфиги на сервере, а не сказать секретарю «Добавь там в веб-морде»
Сколько хостов можно добавить с помощью веб-морды? 10, 50, 100? Веб-морда как раз более ассоциируется с «пятком серверов». Когда нужно связать CMDB с сотней хостов и систему мониторинга, то в первую очередь думаешь об автоматически генерящихся конфигах или API, а в последнюю — о добавлении объектов через веб.Erelecano
28.12.2016 16:04-1И у заббикса есть API, а у Нагиоса нет. Как-то неудачно вышло с вашей защитой этой поделки.
muon
28.12.2016 16:14+1Ничего не имею против Zabbix. Четыре года не испытывал проблем с конфигами Nagios. Сейчас использую Icinga, с apply… where массовое управление стало ещё удобнее, а потребности что-то конфигурять из веба так и не возникло.
Erelecano
28.12.2016 16:16-2Изначально вы пытались оскорблять меня защищая глючную поделку под названием Nagios. Я понимаю, что делать это вас заставляет подростковый комплекс неполноценности, ведь вы же на локалхосте его используете, а тут кто-то посмел о нем сказать правду. Или вы уже забыли, что делали несколько комментов назад?
muon
28.12.2016 16:44Изначально вы пытались оскорбить разработчиков и пользователей Nagios. Если отбросить желчный неконструктив, то останется одна претензия — отсутствие настройки из веба. Вот мне и интересно, в каких случаях на масштабах больше «пятка серверов» может остро понадобиться такая настройка.
Erelecano
28.12.2016 16:48-2Я могу выложить тут список на сотню пунктов претензий к этой детской поделке. Только это смысла не имеет.
Поймите вы, что это поделие используют только мамкины какиры на своих локалхостах. Оно не работает в продакшене. Как только вы начнете админить хотя бы один реальный сервер вы забудете о нагиосе и поделиях на его основе.muon
28.12.2016 16:52+1вы пытались оскорбить разработчиков и пользователей Nagios
мамкины какиры на своих локалхостах
Ч. т. д.
Пейте ромашковый чай, хорошего настроения и здоровья.Erelecano
28.12.2016 16:53-2Оскорбить пользователя Nagios? ЛММ с вами! Я не могу это сделать. Он уже сам себя оскорбил использованием нагиоса и навязыванием его нормальным людям.

Angel2S2
28.12.2016 17:24+3Знаете… Я вот тоже начинал с нагиоса. И один из критериев моего выбора тогда был — правка конфигов, а не внесение хостов через веб-морду. Тогда я к заббиксу относился на «так себе» как раз, потому что думал, что запарюсь его настраивать через веб морду. Да и любитель консоли я, а не мышки. Но когда серверов перевалило за 30, я задумался…
Вспомнил про заббикс, прочитал документацию и понял, что эта система на много гибче и лучше нагиоса. После настройки я не добавляю хосты совсем, заббикс их сам обнаруживает и добавляет, автоматически настраивает необходимые элементы данных (что мониторим) и триггеры, автоматически обнаруживает новые диски, интерфейсы и т.п., автоматически обнаруживает виртуальные машины на гипервизорах и начинает отслеживание их состояния и много чего другого.
Все, что нужно было сделать — это один раз настроить/создать несколько шаблонов и низкоуровневое обнаружение. Все! Дальше заббикс самостоятельно обнаруживает и начинает мониторить все, что мне необходимо. И все это сделано средствами самого заббикса, без каких-либо вспомогательных инструментов.

DuD
30.12.2016 10:36У Zabbix как минимум 4 варианта добавления хостов.
1) Ручками через веб (по одному)
2) XML файлом через веб (пачками)
3) API (пачками)
4) LLD (пачками)

Berserkr
30.12.2016 10:36Кажется вы чего-то не знаете про нагиос — это давно уже система энтерпрайз-класса и она в принципе платная, то что доступно в опен сорс вообще не сравнимо с их готовым решением

timerbulatov
28.12.2016 13:51+1Также есть замечательный плагин для связи Zabbix и Grafana — grafana-zabbix, который позволяет реализовать дополнительные дашборды, алерты и прочее, комбинация классического интерфейса Zabbix и Grafana помогает, когда надо наблюдать много параметров(вроде как в классическом интерфейсе Zabbix еще нет возможности на один график наложить несколько метрик сразу от нескольких узлов?) и в том числе визуализировать проблемы производительности какой либо системы.
Это если говорить про плюсы…
Про минусы — до сих пор нельзя сделать нормальную выгрузку событий, которые не умещаются на одной странице… экспортируется в CSV стабильно первая страница. Приходится извращаться с API и прямой выгрузкой из базы.

gunya
28.12.2016 23:02+2У всех опенсорсных решений, с которыми я сталкивался, есть общая беда — нельзя одним продуктом покрыть все задачи мониторинга.
У Nagios-подобных не хватает статусов (critical/warning/ok недостаточно для кластеров).
У Zabbix не хватает возможности вывести подробное описание ошибки (mysql не работает, потому что: connection refused, connection timed out, no route to host, проблемы с dns или сам mysqld себя плохо чувствует?). Хотя здесь могу быть не прав — работал с Zabbix редко.
В обоих системах нельзя красиво реализовать уведомления на страшные вещи, наподобие «Пришел OOM Killer и всех убил».
В итоге использую связку Sensu + InfluxDB (grafana, telegraf) + Graylog (rsyslog), все уведомления от которых прилетают в alerta. С такой связкой у эксплуатации есть оперативный мониторинг с правильными приоритетами и максимумом информации, у разработчиков есть доступ к логам приложения с поиском, у тестировщиков есть APM c разрешением в 10 секунд.
Paskal
30.12.2016 12:28Подробного описания ошибок Zabbix действительно не хватает. Ситуация улучшается, но всё равно для диагностики проблем самой системы мониторинга нужно иметь довольно большой объём знаний — много нюансов, и сообщения об ошибках дают только необходимый минимум информации.
По моему опыту, можно обходится и одной системой, если дописывать свои обвязки к ней. У нас возле Zabbix крутится порядка двадцати разных скриптов и есть штук шесть-восемь патчей к коду (большинство опубликовано в zabbix-patches и в соответствующих ZBX- и ZBXNEXT-), я ещё подумаю, и, скорее всего, напишу о них отдельную запись — пока непонятно, будет ли это полезно\интересно сообществу.
gunya
30.12.2016 12:51У нас аналогично крутятся обвязки для sensu, по API скармливающие результаты проверок.
Если нужен только инфраструктурный мониторинг и базовый APM — тогда Zabbix может и подойти. Если же нужно с сотни серверов собирать 100-200 метрик с разрешением в 10 секунд и потом собирать данные в один dashboard — заббиксу с большой вероятностью станет плохо. InfluxDB такую нагрузку даже не замечает.
Если нужно собирать логи с серверов и делать поиск по ним — опять же, нужна еще одна система.
Опять же, для APM нужно вывести breakdown вида «10 самых тяжелых запросов в базу», плюс по statsd получать метрики самого приложения.Paskal
30.12.2016 13:47Для метрик есть Graphite, мы делим мониторинг и метрики, поскольку метрик очень много. В системе мониторинга есть только то, что важно (то есть то, по чему есть триггеры).
Я пока не видел живых систем, где всё пишется в метрики и мониторинг смотрит ровно туда же, куда и люди — думаю, это интересный подход, хотя и не без своих недостатков.gunya
30.12.2016 16:48Вот, то есть у вас уже минимум две системы для мониторинга :)
> Я пока не видел живых систем, где всё пишется в метрики и мониторинг смотрит ровно туда же, куда и люди
Я примерно такой подход реализую — в Sensu напрямую заводятся только те проверки, в которых nagios хорош: отпинать порт; проверить код ответа http; подключиться к БД; проверить, что на хосте нормально собираются метрики (запущены все агенты); плюс пара критичных проверок CPU/LA (на случай, если telegraf по какой-либо причине упадет).
Остальные метрики попадают в InfluxDB, дальше отдельная проверка делает select метрик и по API отправляет статусы (а-ля external check в nagios).
Из плюсов — не обязательно, чтобы на машине стоял агент sensu, достаточно отправлять метрики; можно делать довольно сложные запросы к метрикам (influxdb умеет по абсолютным значениям высчитывать изменение и количество операций в секунду); плюс метрики не собираются два раза.
Из минусов — для полноценного мониторинга надо два агента на сервере — telegraf и sensu, плюс rsyslog.
bravosierrasierra
30.12.2016 10:36Пробовал всё, nagios-подобное интересно, но плохо администрируется руками множества администраторов одновременно. Мой выбор — Zabbix. Ему главное партиционировать базу и выжидать на форуме не менее 2 месяцев с момента очередного релиза, даже если речь о минорных релизах, иначе будете немедленно наказаны сексом в неожиданных местах. Релизная политика не подразумевает выпуск фикса найденного бага ASAP, скажем фиксы ODBC-запросов в базы несколько релизов как сломана. Но остальные гораздо слабее по фичам и удобству для команды админов.
В мире опенсорса никто никому ничего не обязан, и я не устаю повторять: огромное спасибо Алексею и команде за этот замечательный продукт, которыми они так щедро делятся. Мои брюзжания это брюзжания того, работа кого каждый день добровольно связана с zabbix.gunya
30.12.2016 11:29Nagios-подобные системы очень хорошо интегрируются с системами управления конфигурациями. Софт ставится на мониторинг в том же месте, в котором он устанавливается.

Singaporian
30.12.2016 10:36Как каждый из этих сервисов выглядит в контексте #monitoringsucks, упомянутого в этой статье?
Paskal
30.12.2016 13:52Не знаю. Я всегда думал, что проблемы с плохим мониторингом — не технические, хорошему мониторингу мешает плохое видение, а не ограничения или архитектура системы. Конечно, если вы не используете Nagios.
gunya
30.12.2016 17:06Что у Zabbix, что у Nagios-подобных есть большие ограничения в плане архитектуры :)
Zabbix хочет, чтобы результат проверки был числом (и хочет иметь локальную копию этого числа), Nagios же хочет видеть exit code 0-3.
У Enterprise таких ограничений нет — в них системы генерируют Event-ы с произвольным текстом и метаданными. Под капотом может быть как проверка числовых метрик (Zabbix-like), так и проверка статуса (Nagios-like), так и единичные события, полученные из логов (Out of memory: kill process XXXX).
Более того, такой подход позволяет делать корреляцию событий, идеальная система может сразу искать root cause: «Сервис поиска выдает ответ более чем за 5 секунд, потому что одна VM лежит (гипервизор упал — нет питания), а вторая виртуалка упирается в I/O (на гипервизоре ребилдится raid)»Paskal
30.12.2016 17:14Zabbix может хранить какие угодно значения и делать очень продвинутые условия срабатывания, в случае с OOM killer — парсится dmegs на предмет сообщений об OOM, любые новые записи в моём случае поднимают триггер (и в сообщении приходят строки, которые увидел мониторинг на момент срабатывания триггера).
Другое дело, что OOM — очень плохой алерт, он говорит о проблеме с тысячей возможных причин, но это скорее тема для упомянутого #monitoringsucks.
Корреляция событий также возможна и в Zabbix, отличить "просел disk IO" от "просел disk IO из-за перестройки raid" можно, однако это никакая не магия — тебе нужно знать, чем одно событие отличается от другого, и соответствующим образом настроить триггеры. Насколько я понимаю, абсолютно везде делается так же, серебряной пули не существует — все системы требует вдумчивой настройки и продолжительной подгонки для нормальной работы.gunya
30.12.2016 17:57> Другое дело, что OOM — очень плохой алерт, он говорит о проблеме с тысячей возможных причин, но это скорее тема для упомянутого #monitoringsucks.
Здесь соглашусь, если в случае OOM пришел один alert (и он про OOM) — надо допиливать мониторинг.
Я его привожу в качестве примера event-а который пуляется один раз и висит в консоли независимо от метрик/проверок.
> Корреляция событий также возможна и в Zabbix.
Насколько я помню, там довольно базовая корреляция в рамках одной ноды. Если можно делать связь гипервизор — вм, то это уже хорошо. У enterprise строится граф зависимостей между узлами в системе.
Singaporian
02.01.2017 13:44+1Ну Ok, а что по поводу DevOps? Мне, например, кажется, что Zabbix API (других способов вроде нет) слишком сложен для постоянного изменения и деливери настроек мониторинга. Мне приходится выписывать вот такие кренделя каждый раз, когда мне что-то надо:
for node_type in node_types_list: groups_list = zapi.hostgroup.get( { "output": "extend", "filter": {"name": [node_type]} }) groupid = next(item for item in groups_list if item["name"] == node_type).get('groupid') templates_list = zapi.template.get({"output": "extend"}) templateid = next(item for item in templates_list if item["name"] == 'Template_Fides_{}'.format(node_type)).get('templateid') try: zapi.action.create( { "name": "Auto registration {}".format(node_type), # https://www.zabbix.com/documentation/3.2/manual/api/reference/event/object#event "eventsource": 2, # 2 - event created by active agent auto-registration "status": 0, "esc_period": 120, "def_shortdata": "Auto registration: {HOST.HOST}", "def_longdata": "Host name: {HOST.HOST}\r\nHost IP: {HOST.IP}\r\nAgent port: {HOST.PORT}\r\n", "filter": { "evaltype": 0, "conditions": [ { # https://www.zabbix.com/documentation/3.2/manual/api/reference/action/object#action_operation_condition "conditiontype": 22, # 22 - host name. "operator": 2, # 2 - like "value": node_type } ] }, "operations": [ { # https://www.zabbix.com/documentation/3.2/manual/api/reference/action/object#action_operation_condition "operationtype": 0, # 0 - send message "esc_period": 0, "esc_step_from": 1, "esc_step_to": 2, "evaltype": 0, "opmessage_grp": [ { "usrgrpid": "7" # Group 7 is Zabbix Admins } ], "opmessage": { "default_msg": 1, "mediatypeid": "1" } }, { # https://www.zabbix.com/documentation/3.2/manual/api/reference/action/object#action_operation_condition "operationtype": 2, # 2 - add host "evaltype": 0, }, { # https://www.zabbix.com/documentation/3.2/manual/api/reference/action/object#action_operation_condition "operationtype": 4, # 4 - add to host group "evaltype": 0, "opgroup": [ { "operationid": 1, "groupid": groupid, } ] }, { # https://www.zabbix.com/documentation/3.2/manual/api/reference/action/object#action_operation_condition "operationtype": 6, # 6 - link to template "optemplate": [ { "operationid": 0, "templateid": templateid, }, ], }, ] }, ) tools.log('Action for {} has been imported to Zabbix.'.format(node_type)) except ZabbixAPIException as e: tools.error(e)
не перебор? нужно жить системой мониторинга, чтобы в ней быстро ориентироваться и что-то менять. В Nagios это проще, но там свои проблемы тоже есть.Singaporian
02.01.2017 13:51+1не смог отредактировать комментарий. Дополню: обратите внимание, что я подписываю каждое значение, чтобы не ковыряться в документации каждый раз. И это еще только импорт экшенов. А есть еще десятки других сущностей. Я все же считаю, что мониторинг должен служить человеку, а не человек мониторингу. Потому что читая местные комменты я вижу глубокий уровень понимания мониторинга. И именно это меня пугает. Люди явно намучались с этим вместо того, чтобы писать свои основные приложения.
gunya
02.01.2017 17:25С sensu/nagios очень просто добавлять мониторинг через систему управления конфигурациями, причем это делается в том же месте, где устанавливается нужный компонент: Пример для Postgres на puppet, примерно то же самое можно и через ansible/salt stack делать.
С Zabbix сложнее, но вроде бы есть puppet-модуль, который умеет лезть в API Zabbix и добавлять нужные сущности.Singaporian
02.01.2017 19:01Puppet тут не причем. Он мне даст возможность сделать это на тысячах Zabbix'ов. Но на каждом из тысячи я встречусь именно с этой же проблемой. Потому что проблема не дуплицировать изменения, а автоматизировать. Соответственно, всё равно, чтобы добавить какую-то сущность, я должен каждый раз лезть в документацию к Zabbix API и вспоминать какой код что значит и какие параметры он принимает в каждом конкретном случае.
gunya
02.01.2017 19:12> Puppet тут не причем. Он мне даст возможность сделать это на тысячах Zabbix'ов.
Здесь вы не правы. Puppet даст возможность сконфигурировать один Zabbix-мастер на основании информации с тысячи агентов — для этого есть:
- В puppet — exported resources
- В salt stack — salt mine
- В ansible — delegation
Вот документация по exported resources, один из предполагаемых use-кейсов — настроить сервер мониторинга.
> Соответственно, всё равно, чтобы добавить какую-то сущность, я должен каждый раз лезть в документацию к Zabbix API
Для этого есть модули puppet, которые абстрагируют вызовы API в понятные ресурсы.gunya
02.01.2017 19:20С экспортированными ресурсами в puppet будет примерно такой flow (предположим, что модуль умеет такое делать):
На сервере с агентом:
@@zabbix_action { 'Auto registration ..' ... }
На сервере Zabbix:
Zabbix_action <<| |>>
varnav
Сколько же этих систем мониторинга существует — жуть.
Вот тут 51 насчитали.
muon
Там смешались в кучу сервисы, софт. И все возможные весовые категории: monit в одном ряду со стеком продуктов HP/IBM.