

До конца кампании на Kickstarter осталось чуть меньше недели, но графический редактор Krita уже собрал средства на две главные задачи этого года: анимацию и рисование огромных изображений. И если с анимацией все более менее понятно, то вот с большими изображениями возникают вопросы. Как просчитать и отобразить на экране изображение в 100 млн. пикселов? Как обеспечить, чтобы кисть размером в 1 млн. пикселов отрисовывалась без задержек 500 раз в секунду? На эти вопросы я постараюсь ответить в этой статье.
Откуда берутся задержки при рисовании?
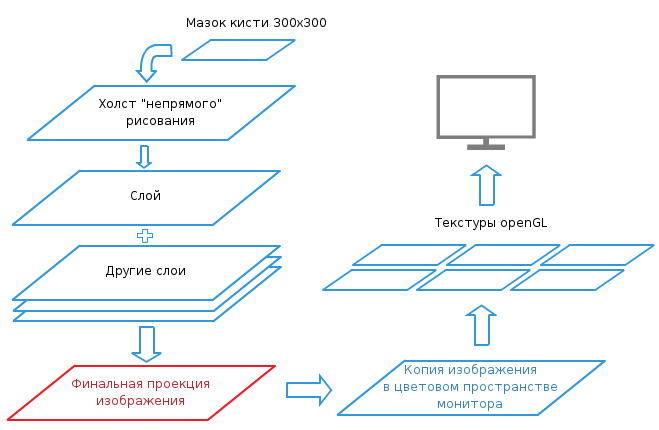
Для начала нужно разобраться, как происходит рисование в современном графическом редакторе. Любая кисть представляет собой изображение («мазок» или «dab»), которое либо загружается пользователем напрямую, либо генерируется параметрически. Когда пользователь делает штрих кистью, это изображение последовательно накладывается на холст с определенным шагом (spacing) (обычно 10-20% от размера кисти). Полученное изображение попадает в конвейер рендеринга, где оно сливается со всеми слоями и передается в пользовательский интерфейс, где уже отрисовывается на экране монитора. Со стороны это выглядит просто, но на самом деле даже для простой кисти на протяжении конвейера сделанный пользователем штрих будет обработан около 7(!) раз.
- Маска кисти заполняется цветом и формируется сам мазок
- Мазок рисуется поверх временного холста, который позволяет штрихам не накладываться друг на друга (режим непрямого рисования или «Wash Mode»)
- Временный холст рисуется поверх содержимого слоя
- Все слои сливаются в одно изображение
- Изображение копируется в пользовательский интерфейс
- В интерфейсе происходит преобразование цветового пространства изображения, чтобы соответствовать цветовому пространству монитора
- Финальная картинка загружается в текстуру openGL и отрисовывается на экране
Пример
Итак, каждый «мазок» претерпевает минимум 7 преобразований. Много это или мало? Давайте рассмотрим простой пример. Представим, что мы рисуем кистью 300х300 пикселов (300 * 300 * 4 = 312 КБ) на холсте формата A4 300dpi (3508x2480 пикселов).
Скорость, с которой художник может комфортно двигать стилус планшета (с учетом зума) составляет около 18 пикселов в миллисекунду. Тогда (при шаге кисти 10%) средняя скорость, с которой мы должны успевать отрисовывать кисть на холсте составит 600 «мазков» в секунду.
Кисть: 300 пикс.
Изображение: A4 300dpi (3508x2480 пикс.), зум 25%
CPU: Core i7 4700MQ
С учетом размера кисти получается, что на каждой стадии конвейера редактору нужно обрабатывать порядка 187 МБ в секунду, что составляет более 1,2 ГБ/с (!) на весь конвейер. И это даже не учитывая того факта, что почти на всех стадиях конвейер не просто преобразовывает одну область размером 300х300, а берет два изображения, просчитывает их композицию (минимум одна операция деления на пиксел) и записывает результат обратно в память. Получается, что даже на таких относительно небольших размерах кисти и изображения мы достаточно близко приближаемся к теоретическим пределам скорости работы оперативной памяти (10-20ГБ/с).
«WTF?!» — спросит внимательный читатель. «Как ж это тогда вообще работает?!» Конечно, на каждом этапе конвейера применяется множество оптимизаций. Вся область разбивается на несколько потоков, которые, мало того выполняются параллельно, так еще используют векторные инструкции SSE/AVX, позволяющие обрабатывать до 8 пикселов одновременно. Кроме того, в некоторых частных случаях (например, один из пикселов целиком прозрачен или непрозрачен), композиция вырождается в простое копирование байтов.
Однако все эти меры помогут очень слабо, если мы начнем говорить о кистях размером в 1000 пикселов и более. Ведь при увеличении размера кисти в 3 раза объем обрабатываемых данных увеличится уже не в 3, а в 9 раз! Обрабатывать по 12 ГБ в секунду? Ну уж нет! Так как же быть?
MIP-текстурирование и уровни детализации

В трехмерной графике есть известный прием, который позволяет повышать скорость и качество текстурирования объектов, находящихся далеко от камеры. Дело в том, что когда объект удаляется от наблюдателя, он становится меньше в размерах и, соответственно, его текстура должна так же масштабироваться. Чтобы ускорить этот процесс была придумана технология MIP-текстурирования. Её смысл заключается в том, что вместе с самой текстурой хранится множество ее уменьшенных копий: в 2, 4, 8, 16 и т.д. раз. И когда графическому процессору требуется нарисовать уменьшенную версию текстуры, он уже не занимается масштабированием оригинала, а просто берет заранее подготовленную копию и работает с ней. Это увеличивает не только скорость прорисовки объектов, но и сильно повышает их качество, так как при предварительной генерации можно использовать более точные «медленные» алгоритмы.
Уровни детализации в Крите
Здесь стоит учесть одно наблюдение, что если пользователь решит рисовать на изображении шириной в 10k пикселов, то большую часть времени он будет использовать масштаб в 20-15%. Иначе это изображение чисто технически не уместится на экране его Full HD монитора, шириной едва дотягивающего до 2k. Этим фактом мы и воспользуемся!
В начале этого года мы сделали прототип системы отложенного просчета изображения для Krita. Когда пользователь рисует кистью по холсту, Крита не спешит просчитывать все его действия. Вместо этого она берет уменьшенную копию изображения и отрисовывает все штрихи на ней. Так как уменьшенная копия имеет размер в 2-4 раза меньше оригинала, то и рисование на ней происходит в 4-16 раз быстрее, и поэтому отсутствуют какие-либо задержки, отвлекающие художника от его творческого процесса. А так как художник не может рисовать все 100% времени, то у Криты будет еще множество времени, когда можно в фоновом режиме, не торопясь, просчитать штрихи на оригинальном изображении.
Видео, демонстрирующее рисование 1k кистью на 8k изображении. Обратите внимание, как через несколько секунд после завершения штриха приходит вторая волна обновлений.
В итоге мы решили главную задачу. Теперь мы не пытаемся обработать гигабайты данных в реальном времени. В реальном времени нам нужно просчитать лишь превью, который позволит пользователю комфортно работать. А оригиналом можно заняться и потом.
Предварительные выводы
На данный момент у нас есть готовый прототип системы работы с уровнями детализации. В нем работает лишь один движок кистей, и то не со всеми параметрами. Однако он уже позволяет сделать нам некоторые выводы:
- Мы решили главную задачу: пользователь видит, что он рисует
- Качество превью достойное. Проблемы возникают лишь на границах областей обновления, где меняется алгоритм интерполяции, используемый в openGl-шейдерах. Нужно решать.
- В качестве бонуса openGL 3.0 и выше позволяет загружать/читать информацию напрямую с определенного уровня детализации (GLSL 1.3: textureLod(). Т.е. нам не нужно держать копии всех текстур, просто обновляем определенный уровень, говорим шейдеру про него, а тот читает напрямую
- Главный недостаток подхода заключается в том, что эта система привела к серьезному усложнению планировщика задач Криты. Требуется решить очень много проблем. Например, две копии изображения (оригинал и уменьшенная копия) нужно регулярно синхронизировать. И это усугубляется тем фактом, что не все действия в Крите можно выполнить над уменьшенной копией. Многие действия (т.н. legacy-действия) требуют полного контроля над изображением. Они работают подобно барьерам: перед их запуском все «раздвоенные» действия должны быть завершены, а после их завершения копии изображения должны быть синхронизированы.
- Соответственно, если пользователь запустит legacy-действие, то ему придется ожидать, пока завершится вся фоновая обработка. Что может, конечно, не совсем удобно. Единственным решением этой проблемы может быть лишь уменьшение количества legacy действий...
Наш проект на Kickstarter уже достиг минимальной цели, поэтому следующие несколько месяцев мы потратим на реализацию полноценной системы работы с уровнями детализации. И уже совсем скоро любой желающий сможет протестировать рисование огромными кистями в Крите!
Ссылки
Страница проекта на Kickstarter: ссылка
Группа русскоязычных пользователей в ВК: http://vk.com/ilovefreeart
Официальный сайт: krita.org
Комментарии (32)

Makeman
28.05.2015 18:23-1Как у вас реализован рендеринг, что у вас возникают большие задержки?
На практике даже на телефоне (Windows Phone) можно редактировать фотографии в 8Мп без значительных задержек с масштабированием и сохранением истории!
Посмотрите приложение Ease (Мольберт). Возможно, вам будут полезны исходные коды его прототипа. Используются стандартные примитивы xaml-разметки (например, Polyline), рендеринг которых выполняется встроенным видеоадаптером.
Достаточно просто каждый раз растеризовать изображение, когда закончен новый штрих. Основная проблема для телефона — это только нехватка памяти при обработке изображений с высоким разрешением.
Конечно, функционал не такой богатый, как в десктоп-редакторах, но мощности ПК намного выше, чем в телефонах…
dkazakov-dev Автор
28.05.2015 19:18+6Посмотрите приложение Ease (Мольберт). Возможно, вам будут полезны исходные коды его прототипа. Используются стандартные примитивы xaml-разметки (например, Polyline), рендеринг которых выполняется встроенным видеоадаптером.
Так в том-то и дело, что в Крите штрихи не векторные. И их нельзя представить в виде стандартных примитивов xaml (не проверял, но больше чем уверен). Поэтому растеризация происходит на каждом штрихе хотим мы этого или нет. Пользователь может выбрать произвольную кисть в виде растровой картинки и будь добр, рисуй! ;)
Растровые редакторы на телефоне обычно сильно упрощают рисование и поэтому могут работать быстро. Например, они отказываются от поддержки чего-либо, кроме RGB, ограничивают размер изображения, чтобы он мог поместиться в видеопамять/текстуру и рисуют картинку целиком на GPU. Такой вариант будет работать быстро, но пользователь будет сильно органичен в возможностях.
Крита же поддерживает множество «продвинутых» возможностей. Считайте, что каждая из них добавляет отдельный шаг конвейера и/или уровень абстракций, которые в итоге замедляют работу. Например:
- Работа с произвольными цветовыми пространствами: CMYK, Lab, Grayscale, RGB. Добавляет уровень абстракций над данными
- Полная поддержка менеджмента цвета по ICC или OCIO. Добавляет дополнительный шаг конвертирования цвета в цветовое пространство монитора перед отображением
- Динамичесчкие растровые кисти. Их каждый раз нужно считать, т.к. их размер и форма зависит от силы нажатия стилуса (в мобильных телефонах такого нет). Да, мы генерируем для них мипмапы. Да, мы их кешируем. И все-равно это занимает примерно 30% времени рисования
- Простое рисование на многослойном изображении подразумевает под собой, что каждый слой должен быть наложен на все предыдущие. Формула, по которой это делается содержит как минимум одну операцию деления, поэтому этот процесс в 20-30 раз медленнее, чем тупой memcpy. Memcpy на Core i7 2400 работает со скоростью около 8Гб/с. Вот и считайте :)
На самом деле, у нас есть одно место, которое теоретически можно оптимизировать, но я пока не знаю как. Дело в том, что «мазки» рисуются последовательно один поверх другого. Соответственно, при шаге в 10%, оставшиеся 90% пикселов пишутся как минимум дважды-трижды пока не произойдет насыщение. Это можно как-то оптимизировать, отказаться от «мазков» и рисовать сразу целыми линиями. Вот только как сделать, чтобы продолжение штриха можно было рисовать, не удаляя предыдущего куска? Т.е. как сделать этот алгоритм инкрементальным?
merhalak
28.05.2015 23:57Почему вы не используете OpenCV или что-то в таком духе? Увы, я конечно не разбираюсь, но там ведь есть операции деления матрицы на скаляр, к примеру (это я про пункт 4).

Keyten
29.05.2015 00:30Просто поделить матрицу на скаляр — совершенно не проблема. Проблема — сделать это быстро.
dkazakov-dev Автор
29.05.2015 09:40Мы и без openCV это деление оптимизируем как только возможно. Я даже один раз пробовал заменить его на reciprocal+multiplication. Выигрыш получается около 5-10 процентов. Однако вышестоящая библиотека (Vc) предоставляла интерфейс только для векторного reciprocal, а для скалярного нет. А так как мы должны держать и векторную, и скалярную копии кода (для не выровненных по 8 байт данных), то я забил на эту идею :)

amarao
28.05.2015 19:20+1Рисуя на cintiq, я обнаружил новую проблему, решения которой я не нашёл. Она аффектит всех — windows, mac, linux: аппаратный курсор. Когда идёт штриховка, то скорость обновления курсора на экране меньше, чем скорость обновления холста под ним. Если кисть двигается быстро, это очень раздражает.
Какие-то идеи?dkazakov-dev Автор
28.05.2015 19:27Эрм… Скорость аппаратного курсора меньше? Такое может быть?
Как вариант, попробуйте отключить аппаратный курсор. Также можете поэкспериментировать с опцией «Show brush outline while painting». На cintiq ее мне кажется можно смело отключить.

amarao
28.05.2015 19:59Да. По моим наблюдениям — 30 или 15 fps. Вы это можете сами увидеть — попробуйте мышой быстро влево-вправо подвигать на весь экран. Будет эффект стробоскопии, то есть мыша будет «видна» в нескольких местах.
За совет спасибо.
Я вообще из mypaint'овского лагеря, но если krita это как-то поправит/скроет, то это серьёзный аргумент за переключение.dkazakov-dev Автор
28.05.2015 21:11Ну что-то есть такое, но без cintiq'а это не раздражает. Попробуйте отключить курсор. Если поможет и если нужно будет, могу потом написать, чтобы курсор только во время штриха скрывался. Хотя, мне кажется, на синтике он вообще лишний.
amarao
28.05.2015 21:22Начал щупать krita.
Главный мучительный вопрос: КАК СДЕЛАТЬ ШРИФТ БОЛЬШЕ? Оно рисует каким-то микроскопическим шрифтом в 10 пунктов, даже линии букв в один пиксел толщиной.dkazakov-dev Автор
29.05.2015 09:45Текстом мы, честно, пока не занимались, там есть некоторые проблемы. Изменить размер можно в панели Tool Options, когда этот текст выделен.
amarao
28.05.2015 21:45… по поводу курсора. Если при рисунке радиус кисти меняется, то курсор показывает не «где рисовать будем», а «какого размера штрих будет». Цинтик и вакомы, к сожалению, не понимают техник карандашного-кистевого рисунков (когда толщина линии меняется наклоном карандаша или поворотом кисти).
dkazakov-dev Автор
29.05.2015 09:44+1Цинтик и вакомы, к сожалению, не понимают техник карандашного-кистевого рисунков (когда толщина линии меняется наклоном карандаша или поворотом кисти)
В смысле? И наклон, и поворот они измерять могут, причем очень хорошо. Для артпенов вроде даже есть специальные наконечники со скосами, как реальные срезанные маркеры.
А с курсором, если честно, я все еще не понимаю, в чем проблема и в какую сторону исправлять :)amarao
29.05.2015 18:03Я попробовал рисовать в крите с выключенным курсором. Выглядит довольно хорошо, спасибо. Сейчас пытаюсь прорваться через интерфейсы и ужасные кнопки (Ctrl-Z вместо 'z' очень напрягает).
Насчёт наклона и поворота: я попробовал — не вижу никакой разницы. У меня обычное перо от обычного cintiq 13HD, этого не достаточно? Поворот вокруг оси, ладно, но от наклона я бы не отказался.
А как Krita учитывает наклон? Что должно при этом меняться?dkazakov-dev Автор
30.05.2015 12:32Ctrl-Z можно переназначить на Z в менюшке:

Наклон можно подключить к любому параметру кисти через сенсоры:

Если лень возиться, можете воспользоваться любым готовым профилем с меткой Т в ЛВУ и словом «tilt» в названии. К ним всем наклон уже привязан:

amarao
31.05.2015 12:20Да, оно есть! Офигеть! Спасибо вам огромное, можно сказать, заново для меня вакомы открываете. Надо сцепить зубы и прорваться через начальный уровень интерфейса (когда не работают компульсивные навыки).
dkazakov-dev Автор
01.06.2015 12:47+1На самом деле у вакомов есть еще «скретная» функция. Windows-версия драйвера еще может возвращать «высоту стилуса над поверхностью планшета», т.е. то, на сколько высоко летает кончик стилуса :) Мы все хотим сделать полноценный аэрограф на этом, на руки не доходят ;)
amarao
01.06.2015 12:59У mypaint'а такие кисти, кстати, есть. Не могу сказать, что это сильно приятная вещь, потому что после выбора кисти она начинает рисовать «там, где менюшка была».
ЗЫ Почему Krita после переворота пера на eraser продолжает им «рисовать»? Как ей объяснить, что eraser — это eraser?dkazakov-dev Автор
01.06.2015 13:05Просто включите ластик кнопкой «Е» и она это запомнит. Для Криты два кончика стилуса это два отдельных инструмента, на которые можно вешать любые инструменты.
Вообще, вроде в последних версиях хотели, чтобы новые пользователи не смущались, сделать там ластик по-умолчанию. То ли не прошел патч, то ли у вас уже не самая новая версия.
amarao
31.05.2015 12:25Да, ещё, у меня всё-таки есть ощущение, что интерфейс под мышу делалали. Например, попапчики появляются только под мышой. Если на экране только перо, то никаких подсказок.
Salabar
28.05.2015 20:25+1Вся область разбивается на несколько потоков, которые, мало того выполняются параллельно, так еще используют векторные инструкции SSE/AVX, позволяющие обрабатывать до 8 пикселов одновременно.
Звучит, скорее, как работа для видеокарты, чем для процессора. Раз нормально работает, то пусть работает, но немного кощунственно какой-нибудь GTX или R2 заставлять рисовать единственный прямоугольник.dkazakov-dev Автор
28.05.2015 21:07+1Да, даже самая дешевая видеокарта с пассивным охлаждением считает это на 50% быстрее. Единственная проблема, эти 50% съедаются временем пересылки данных между CPU и GPU. Так что нужно либо считать все на CPU как раньше, либо переносить весь конвейер целиком на GPU. Последнее весьма проблематично, сами понимаете :)
Salabar
28.05.2015 21:19+2CL_MEM_USE_HOST_PTR и, вуаля, GPU напрямую общается с RAM через PCI-E на почти полной скорости шины. В случае AMD APU или встроенных видях Haswell и выше, видеокарта и процессор вообще одним проводом с памятью соединены. Но точных цифр у меня нет, спорить не буду.
dkazakov-dev Автор
29.05.2015 10:02Хм… интересно. Я тестировал только с CUDA. Там, насколько я понимаю, обязательно нужно выполнять cudaMemcpy()… Может там тоже какая-нибудь опция с прямым доступом есть?
На цифры, конечно, взглянуть было бы очень интересно. А то мои тесты два года назад привели к неутешительным выводам, и мы с тех пор это и забросили.
Salabar
29.05.2015 11:03Возможно, NVIDIA этого и не поддерживает, хотя это странно (в этом случае можно задействовать карту Интела, т.к. связка популярная). Но табличка по ссылке показывает, что у AMD скорость чтения видеокартой системной памяти всего в два раз меньше, чем процессором. Разве что для записи всё достаточно грустно. но это вполне может сгладиться, да и никто не заставляет сразу всё отгружать на GPU.
developer.amd.com/tools-and-sdks/opencl-zone/amd-accelerated-parallel-processing-app-sdk/opencl-optimization-guide/#50401315_77912dkazakov-dev Автор
29.05.2015 12:30Да, скорость передачи там хорошая. Всего где-то в полтора раза медленнее, чем в памяти. Проблема в том, что там счет уже шел на единицы memcpy'ев, т.е. каждый лишний трансфер — это уже 10-20% ко времени.
В общем случае задача для нас стоит так. Имеем два буфера А и Б одинакового размера. Их попиксельно нужно объединить и результат записать в буфер Б. Пусть 1 memcpy — это время копирования буфера А в буфер Б. Скорость выполнения операции с применением AVX (1-ой версии) по тестам занимает что-то около 10-12 memcpy. Скорость чистого расчета на (слабеньком) GPU — 5 memcpy. Кроме того, нам нужно передать два буфера туда и один обратно, соответственно нужно добавить еще минимум 3 memcpy. Итого нам остается всего 20% ускорения :(
Я после этого пришел к выводам, что нужно либо целиком переносить все-все-все на GPU (читай, переписать половину Криты), либо менять что-то глобально, но в другом месте…Salabar
29.05.2015 12:56Ну, как я и писал, пусть работает, пока не станет проблемой. Захотите картинки 20k x 20k — придется этим заниматься. :)
rPman
29.05.2015 01:49А вы храните и обрабатывайте все необходимое в GPU и транслируйте в CPU только то что нужн одля привью (этакий терминал сервер сессия между процессором и видеокартой, а что, на лицо медленный CPU использует узкий канал для работы на быстром GPU).
p.s. у меня внутри все переворачивается от такого использования вычислительных ресурсов ;)Salabar
29.05.2015 09:28+1Можно ВООБЩЕ ничего не отправлять на CPU, потому что текстуру OpenGL тоже можно сгенерировать на месте. Но для этого придется писать всё с нуля. Однако, ничто не мешает переходить на OpenCL постепенно, а той части программы, которая не переписана, просто скармливать указатель clMapBuffer. Это, скорее всего, будет работать быстрее, гарантированно жрать меньше батереи и будет запускаться везде (в комментриях на Кикстартере видел просьбу портировать на Андроид). Насколько это вообще нужно проекту — это другой вопрос.
anton9088
а зачем это нужно?
dkazakov-dev Автор
Кратко, это метод ускорить Криту в 5-10 раз для большинства пользовательских историй.
Пример с 10k, конечно, сильно утрирован. Но представьте, что вам нужно нарисовать иллюстрацию формата А4 600dpi (7k x 5k), или сделать фон для кино формата 4k. Во всех этих случаях работа с уровнями детализации очень сильно упростит процесс. Ускорение в 4-16 раз это не шутки. Это не какое-нибудь SSE/AVX, которое дает прирост в среднем 2-3 раза ;) Более того, ведь в Крите кроме рисования еще есть фильтры. Они тоже ускорятся, в том числе и предварительный просмотр.
amarao
Я часто рисую на большом разрешении (4х) — для 1920x1080 это 8k x 4k. Причина — возможность рисовать грубыми (быстрыми) мазками, а при необходимости увеличивать размер любого места и такими же грубыми мазками его уточнять. После зума обратно точность штрихов увеличивается в 4 раза.
Если изначально не делать большое разрешение, то при зуме с крупными пикселами начинается проблема с дискретностью ступенек пикселов и странной работой сложных кистей при размере кисти 1.1 пиксела на 1.05 пиксела.