
Для кого эта статья?
Каждый, кому будет интересно затем покопаться в истории за поиском новых фактов, или каждый, кто хотя бы раз задавался вопросом «как же все таки это, машинное обучение, работает», найдёт здесь ответ на интересующий его вопрос. Вероятнее всего, опытный читатель не найдёт здесь для себя ничего интересного, так как программная часть

В цифрах
С каждым годом растёт потребность в изучении больших данных как для компаний, так и для активных энтузиастов. В таких крупных компаниях, как Яндекс или Google, всё чаще используются такие инструменты для изучения данных, как язык программирования R, или библиотеки для Python (в этой статье я привожу примеры, написанные под Python 3). Согласно Закону Мура (а на картинке — и он сам), количество транзисторов на интегральной схеме удваивается каждые 24 месяца. Это значит, что с каждым годом производительность наших компьютеров растёт, а значит и ранее недоступные границы познания снова «смещаются вправо» — открывается простор для изучения больших данных, с чем и связано в первую очередь создание «науки о больших данных», изучение которого в основном стало возможным благодаря применению ранее описанных алгоритмов машинного обучения, проверить которые стало возможным лишь спустя полвека. Кто знает, может быть уже через несколько лет мы сможем в абсолютной точности описывать различные формы движения жидкости, например.
Анализ данных — это просто?
Да. А так же интересно. Наряду с особенной важностью для всего человечества изучать большие данные стоит относительная простота в самостоятельном их изучении и применении полученного «ответа» (от энтузиаста к энтузиастам). Для решения задачи классификации сегодня имеется огромное количество ресурсов; опуская большинство из них, можно воспользоваться средствами библиотеки Scikit-learn (SKlearn). Создаём свою первую обучаемую машину:
clf = RandomForestClassifier()
clf.fit(X, y)Вот мы и создали простейшую машину, способную предсказывать (или классифицировать) значения аргументов по их признакам.
— Если все так просто, почему до сих пор не каждый предсказывает, например, цены на валюту?
С этими словами можно было бы закончить статью, однако
Ближе к делу
— Получается, зарабатывать на этом деле я не сразу смогу?
Да, до решения задач за призы в $100 000 нам ещё далеко, но ведь все начинали с чего-то простого.
Итак, сегодня нам потребуются:
- Python 3 (с установленной pip3)
- Jupyter
- SKlearn, NumPy и matplotlib
Дальнейшее использование требует от читателя некоторых знаний о синтаксисе Python и его возможностях (в конце статьи будут представлены ссылки на полезные ресурсы, среди них и «основы Python 3»).
Как обычно, импортируем необходимые для работы библиотеки:
import numpy as np
from pandas import read_csv as read— Ладно, с Numpy всё понятно. Но зачем нам Pandas, да и еще read_csv?
Иногда бывает удобно «визуализировать» имеющиеся данные, тогда с ними становится проще работать. Тем более, большинство датасетов с популярного сервиса Kaggle собрано пользователями в формате CSV.
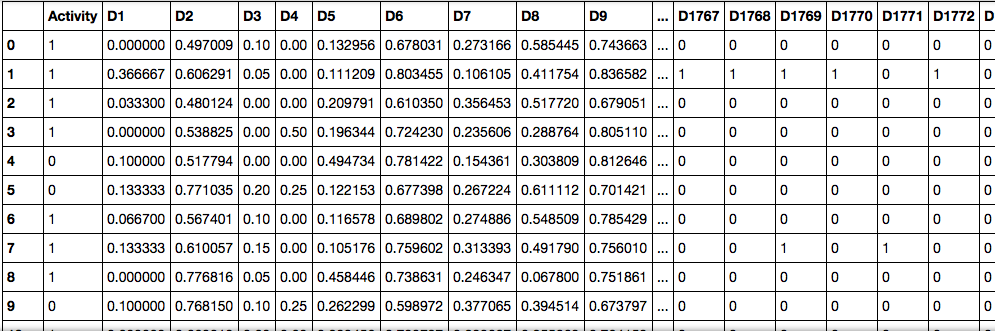
Здесь колонка Activity показывает, идёт реакция или нет (1 при положительном, 0 при отрицательном ответе). А остальные колонки — множества признаков и соответствующие им значения (различные процентные содержания веществ в реакции, их агрегатные состояния и пр.)
— Помнится, ты использовал слово «датасет». Так что же это такое?
Датасет — выборка данных, обычно в формате «множество из множеств признаков» > «некоторые значения» (которыми могут быть, например, цены на жильё, или порядковый номер множества некоторых классов), где X — множество признаков, а y — те самые некоторые значения. Определять, например, правильные индексы для множества классов — задача классификации, а искать целевые значения (такие как цена, или расстояния до объектов) — задача ранжирования. Подробнее о видах машинного обучения можно прочесть в статьях и публикациях, ссылки на которые, как и обещал, будут в конце статьи.
Знакомимся с данными
Предложенный датасет можно скачать здесь. Ссылка на исходные данные и описание признаков будет в конце статьи. По представленным параметрам нам предлагается определять, к какому сорту относится то или иное вино. Теперь мы можем разобраться, что же там происходит:
path = "%путь к файлу%/wine.csv"
data = read(path, delimiter=",")
data.head()Работая в Jupyter notebook, получаем такой ответ:
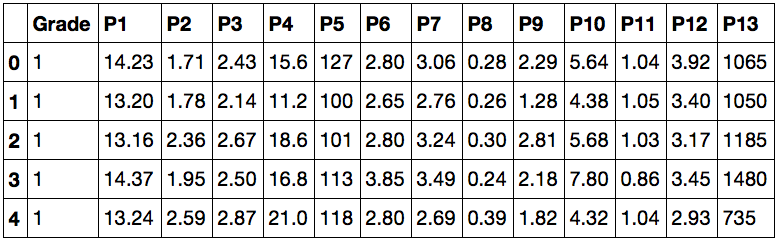
Это значит, что теперь нам доступны данные для анализа. В первом столбце значения Grade показывают, к какому сорту относится вино, а остальные столбцы — признаки, по которым их можно различать. Попробуйте ввести вместо data.head() просто data — теперь для просмотра вам доступна не только «верхняя часть» датасета.
Простая реализация задачи на классификацию
Переходим к основной части статьи — решаем задачу классификации. Всё по порядку:
- создаём обучающую выборку
- пробуем обучить машину на случайно подобранных параметрах и классах им соответствующих
- подсчитываем качество реализованной машины
Посмотрим на реализацию (каждая выдержка из кода — отдельный Cell в notebook):
X = data.values[::, 1:14]
y = data.values[::, 0:1]
from sklearn.cross_validation import train_test_split as train
X_train, X_test, y_train, y_test = train(X, y, test_size=0.6)
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)Создаем массивы, где X — признаки (с 1 по 13 колонки), y — классы (0ая колонка). Затем, чтобы собрать тестовую и обучающую выборку из исходных данных, воспользуемся удобной функцией кросс-валидации train_test_split, реализованной в scikit-learn. С готовыми выборками работаем дальше — импортируем RandomForestClassifier из ensemble в sklearn. Этот класс содержит в себе все необходимые для обучения и тестирования машины методы и функции. Присваиваем переменной clf (classifier) класс RandomForestClassifier, затем вызовом функции fit() обучаем машину из класса clf, где X_train — признаки категорий y_train. Теперь можно использовать встроенную в класс метрику score, чтобы определить точность предсказанных для X_test категорий по истинным значениям этих категорий y_test. При использовании данной метрики выводится значение точности от 0 до 1, где 1 <=> 100% Готово!
— Неплохая точность. Всегда ли так получается?
Для решения задач на классификацию важным фактором является выбор наилучших параметров для обучающей выборки категорий. Чем больше, тем лучше. Но не всегда (об этом также можно прочитать подробнее в интернете, однако, скорее всего, я напишу об этом ещё одну статью, рассчитанную на начинающих).
— Слишком легко. Больше мяса!
Для наглядного просмотра результата обучения на данном датасете можно привести такой пример: оставив только два параметра, чтобы задать их в двумерном пространстве, построим график обученной выборки (получится примерно такой график, он зависит от обучения):
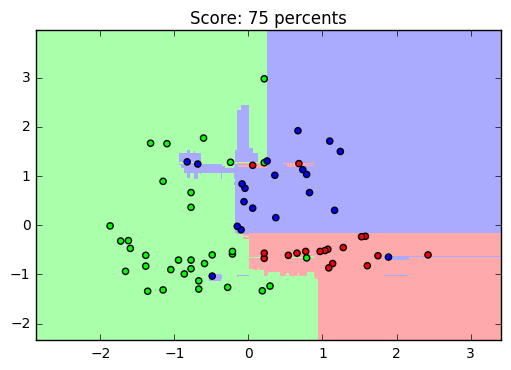
Да, с уменьшением количества признаков, падает и точность распознавания. И график получился не особенно-то красивым, но это и не решающее в простом анализе: вполне наглядно видно, как машина выделила обучающую выборку (точки) и сравнила её с предсказанными (заливка) значениями.
from sklearn.preprocessing import scale
X_train_draw = scale(X_train[::, 0:2])
X_test_draw = scale(X_test[::, 0:2])
clf = RandomForestClassifier(n_estimators=100, n_jobs=-1)
clf.fit(X_train_draw, y_train)
x_min, x_max = X_train_draw[:, 0].min() - 1, X_train_draw[:, 0].max() + 1
y_min, y_max = X_train_draw[:, 1].min() - 1, X_train_draw[:, 1].max() + 1
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
pred = clf.predict(np.c_[xx.ravel(), yy.ravel()])
pred = pred.reshape(xx.shape)
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
plt.figure()
plt.pcolormesh(xx, yy, pred, cmap=cmap_light)
plt.scatter(X_train_draw[:, 0], X_train_draw[:, 1],
c=y_train, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Score: %.0f percents" % (clf.score(X_test_draw, y_test) * 100))
plt.show()Предлагаю читателю самостоятельно узнать почему и как он работает.
Последнее слово
Надеюсь, данная статья помогла хоть чуть-чуть освоиться Вам в разработке простого машинного обучения на Python. Этих знаний будет достаточно, чтобы продолжить интенсивный курс по дальнейшему изучению BigData+Machine Learning. Главное, переходить от простого к углубленному постепенно. А вот полезные ресурсы и статьи, как и обещал:
Материалы, вдохновившие автора на создание данной статьи
Исторические очерки:
- Статья про то, зачем нужно машинное обучение сегодня, и что к этому привело
- Как ни странно, довольно таки замысловатая статья с Википедии про машинное обучение в целом
Подробнее про машинное обучение:
Изучаем python, или до работы с данными:
- Очень полезный курс от талантливых преподавателей из ИТМО и СПбАУ
- Отличный русскоязычный ресурс для изучающих Python, но плохо ориентирующихся на англоязычных ресурсах
Однако для наилучшего освоения библиотеки sklearn пригодится знание английского: в этом источнике собраны все необходимые знания (так как это API reference).
Более углубленное изучение использования машинного обучения с Python стало возможным, и более простым благодаря преподавателям с Яндекса — этот курс обладает всеми необходимыми средствами объяснения, как же работает вся система, рассказывается подробнее о видах машинного обучения итд.
Файл сегодняшнего датасета был взят отсюда и несколько модифицирован.
Где брать данные, или «хранилище датасетов» — здесь собрано огромное количество данных от самых разных источников. Очень полезно тренироваться на реальных данных.
Буду признателен за поддержку по улучшению данной статьи, а так же готов к любому виду конструктивной критики.
Комментарии (19)

Westernstorm
11.01.2017 14:00-3Сейчас много пишут про машинное обучение, но какой толк от текущих возможностей? Как то что есть можно применить на практике?
Самая главная проблема это в выборе начальных данных. Редкая организация имеет существенную базу данных по которой можно с минимальной точностью распознать паттерны. Да что тут говорить, Гугл порой показывает ерунду, несмотря на то что знает о каждом из нас больше чем кто либо еще.

Femistoklov
11.01.2017 15:58+1Маркетологи, менеджеры, гуманитарии… Чтобы был толк, надо просто убедить их всех, что вы умеете определять:
- какие овощи будут больше покупать в следующем месяце — хрен или редьку
- хочет ли Петров купить обручальное кольцо, памперсы, а может ему вообще надо билет в другую страну
- какова вероятность, что Иванов запьёт с получки и не отдаст кредит банку
- насколько опасно нынче инвестировать в РогаAndКопыта
- прибыльно ли заключить сделку с ООО «Вектор»
- будет ли рубль падать перед Новым годом
- диван изображён на картинке или леопард
- рак у пациента или он беременный
Для убеждения целесообразно применять математические методы, формальные модели и строгие доказательства, чтобы всё выглядело пристойно.Westernstorm
11.01.2017 17:45Убедить то можно, но я еще не встречал работающей модели.
Я бы с удовольствием почитал какие данные нужно обработать что бы скажем узнать какие овощи будут больше покупать.
QtRoS
12.01.2017 21:54Вот Вам необычный кейс — я на работе баги раскидываю по разработчикам, анализируя при этом только текст ошибок. Это моя проба пера в ML, на практике экономит до часа в день.

lingvo
11.01.2017 23:49Я думаю с появлением "умных домов" у машинного обучения появится множество интересных применений.
Вот у меня, например, сейчас пишутся логи всего, что я делаю со своим домом: включаю и отключаю свет, двигаю шторы, открываю и закрываю жалюзи, регулирую температуру отопления и т.д. Помимо этого в доме у меня есть куча датчиков освещения, температуры, движения, влажности, CO и т.д.
Я специально сохраняю эту информацию на сервере в архиве с временными штампами, хотя не знаю как использовать. Пока. За несколько лет накопятся мегабайты логов.
Что с этим можно было бы сделать с помощью МО?
Я думаю пара бы интересных вещей получилась бы. Например можно было бы заменить четкую логику различных типовых алгоритмов на нечеткую, основанную на МО.
Например, проанализировав логи можно было бы выяснить мой любимый профиль отопления, или при каких условиях я включаю свет в коридоре. И по результатам этого компьютер мог бы "предсказывать" мои желания и в конце концов обучался бы на моих привычках. А привычки изменились — компьютер подстроился.

djinninia
18.01.2017 10:07Ещё пример задачи машинного обучения.
Определить насколько имеющиеся статьи (например на Википедии) близки друг к другу по теме. Это помогает рекомендовать пользователю статьи на основе уже прочитанных.

Shedar
11.01.2017 15:16Из англоязычных вводных могу посоветовать еще цикл статей (в текущий момент 6 статей) Machine Learning is Fun! Легко и интересно читается, практически на пальцах объясняются типичные подходы к различным задачам, часть с кодом, часть без.

gadzhi15
11.01.2017 15:38На курсере есть еще одна замечательная специализация по машинному обучению и анализу данных от Яндекса и МФТИ. Мне он показался более простым для людей, которые только только постигают эту область. Ссылка на специализацию

Merlen_Gross
11.01.2017 15:53Таким образом вы, возможно, научитесь пользоваться инструментами для машинного обучения. Только вот чтобы действительно понять смысл происходящего, лучше начать с малого и реализовать всё вручную. Например, метод наименьших квадратов или перцептрон очень просты в программной реализации и дают хороший старт для изучения в целом.
AFakeman
11.01.2017 15:58Жалко, что есть столько статей для использования готовых библиотек, но почти нет на тему того, как системы машинного обучения выглядят с математической точки зрения.
falklol
11.01.2017 16:02Добрый день! В ближайшем будущем ожидайте цикл статей на эту тему, будем рассматривать реализации первостепенных алгоритмов машинного обучения, как раз для продвинутых пользователей)

Vinchi
11.01.2017 16:07Вот этого как раз тоже навалом. Обычно всех современные разработки систем машинного обучения сопровождаются научными статьями. А так же есть математические учебники.

kudablin_a
11.01.2017 15:58Огромное спасибо, статья как раз для таких как я.
Но заранее извиняюсь, что-то не совсем уловил: вот мы получили результат обучения датасета признаков вина. И даже нарисовали результаты на двумерном графике взяв только два признака, правильно?
Если да — а какие выводы можно сделать из полученных результатов и как применить эти выводы на практике? Например, с целью заработать деньги на полученных знаниях.Vinchi
11.01.2017 16:09Включите фантазию. Например, пусть у вас есть какие-то параметры пользователя, который зашел в магазин вина. Можно обучить рекомендательную систему, чтобы она показывала ему то вино, которое он скорее всего купит. А ну и конечно не забывайте что в нашей стране онлайн продажа алкоголя запрещена.
kudablin_a
11.01.2017 16:58Нет-нет, я про знания, применительно к полученному результата обучения указанного датасета признаков вина. Я правильно понял, что взятых двух признаков в принципе хватит, чтобы с вероятностью 75% предсказать, к какому сорту относится вино, если мы знаем только значения тех двух его признаков, но не знаем его сорта? Если да, что еще можно с этим делать?
Kanumowa
11.01.2017 16:20Я бы начал с лекций яндекса, чтобы войти в тему:
Яндекс ШАД
И если вы не испугались после просмотра видео
Еще пару ссылок:
udacity Deep Learning by Google
CS224n: Natural Language Processing with Deep Learning
CS231n: Convolutional Neural Networks for Visual Recognition
streetturtle
11.01.2017 18:45Так же у IBM достаточно инересные курсы по Big Data и Machine Learning / Deep Learning на Big Data University. Можно проходить либо отдельные курсы, либо модули (learning path)-несколько курсов на одну тему. Кстати при прохождении дают значки, который можно прикрутить в linkedIn.
А еще незаменимая вещь — Data Scientist Workbench.

SpyceR
Отличная статья! Когда я начинал работать с ML, то мне как раз таких и не хватало: меньше теории, больше кода (при том, что его и так очень мало).