
Всем привет! На самом деле нейросетка играет не в привычную Dota 2, а в RussianAICup 2016 CodeWizards. RussianAICup — это ежегодное открытое соревнование по программированию искусственного интеллекта. Участвовать в этом соревновании довольно интересно. В этом году темой была игра похожая на Доту. Так как я уже какое-то время занимаюсь обучением с подкреплением, то мне хотелось попробовать применить это в RussianAICup. Главной целью было научить нейронную сеть играть в эту игру, хотя занятие призового места — это, конечно, было бы приятно. В итоге нейросеть держится в районе 700 места. Что, я считаю, неплохо, ввиду ограничений соревнования. В этой статье речь пойдет скорее об обучении с подкреплением и алгоритмах DDPG и DQN, а не о самом соревновании.
В этой статье я не буду описывать базовую информацию о нейросетях, сейчас и так очень много информации о них на просторах интернета, а раздувать публикацию не хочется. Мне же хотелось бы сосредоточится на обучении с подкреплением с использованием нейросетей, то есть о том, как обучить искусственную нейронную сеть демонстрировать нужное поведение методом проб и ошибок. Я буду упрощенно описывать 2 алгоритма, база у них одна, а области применения немного отличаются.
Марковское состояние
На входе алгоритмы принимают текущее состояние агента S. Здесь важно чтобы состояние обладало свойством марковости, то есть по возможности включало в себя всю информацию, необходимую для предсказания следующих состояний системы. Например у нас есть камень, брошенный под углом к горизонту. Если мы в качестве состояния примем координаты камня, это не позволит нам предсказать его дальнейшее поведение, но если мы добавим к координатам вектор скорости камня, то такое состояние нам позволит предсказать всю дальнейшую траекторию движения камня, то есть будет марковским. На основе состояния алгоритм выдает информацию о действии A, которое необходимо сделать чтобы обеспечить оптимальное поведение, то есть такое поведение, которое ведет к максимизации суммы наград. Награда R — это вещественное число, которое мы используем для обучения алгоритма. Награда выдается в момент, когда агент, находясь в состоянии S, совершает действие А и переходит в состояние S'. Для обучения эти алгоритмы используют информацию о том, что они делали в прошлом и какой при этом был результат. Эти элементы опыта состоят из 4х компонентов (S, A, R, S'). Такие четверки мы складываем в массив опыта и далее используем для обучения. В статьях он имеет имя replay buffer.
DQN
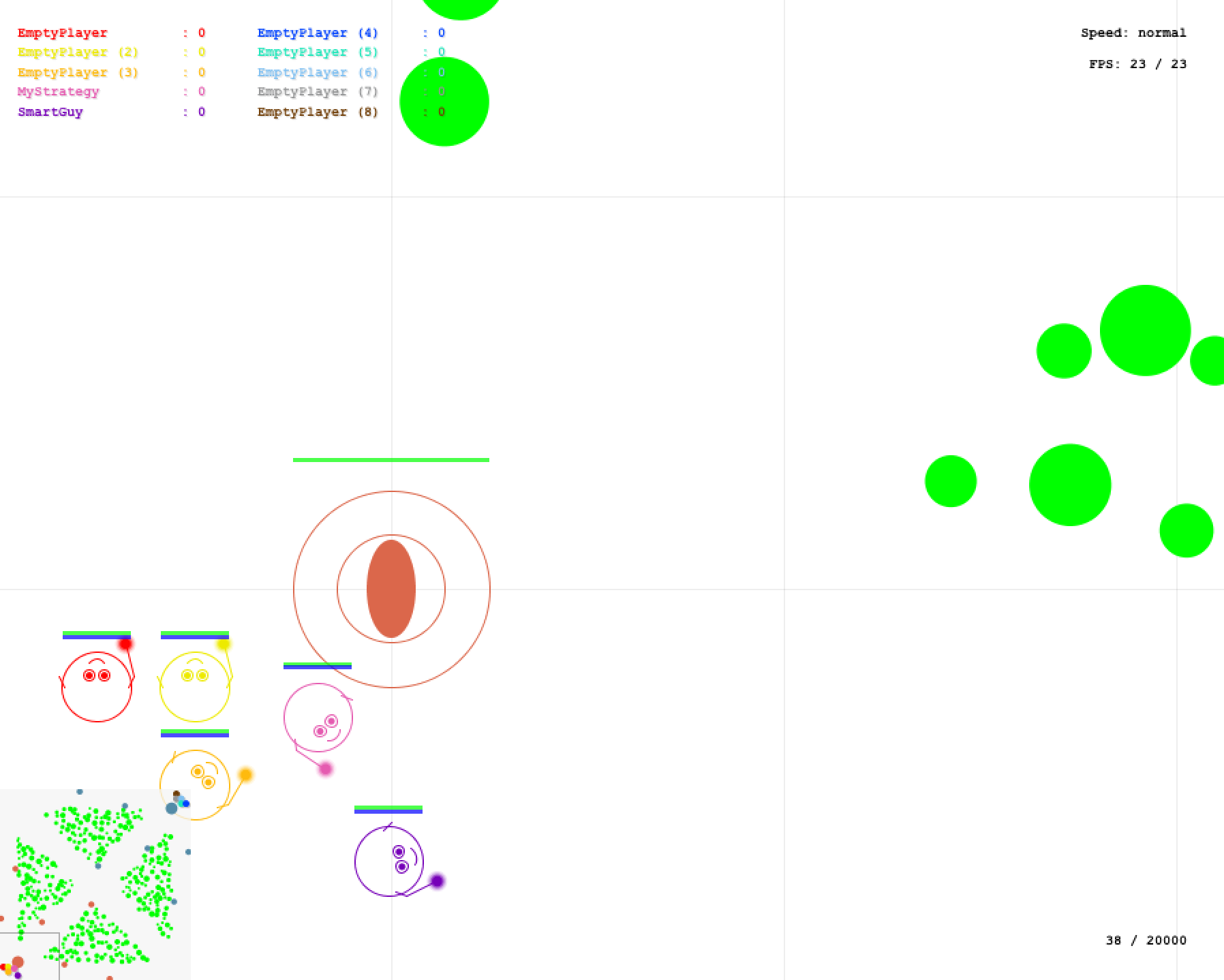
Или Deep Q-Networks — это тот самый алгоритм, который обучили играть в игры Atari. Этот алгоритм разработан для случаев, когда количество управляющих команд строго ограничено и в случае Atari равно количеству кнопок джойстика (18). Таким образом выход алгоритма представляет собой вектор оценок всех возможных действий Q. Индекс вектора указывает на конкретное действие, а значение указывает насколько хорошо это действие. То есть нам надо найти действие с максимальной оценкой. В этом алгоритме используется одна нейросеть, на вход которой мы подаем S, а индекс действия определяем как argmax(Q). Нейронную сеть мы обучаем с помощью уравнения Беллмана, которое и обеспечивает сходимость выхода нейросети к значениям, которые реализуют поведение максимизирующее сумму будущих наград. Для данного случая оно имеет вид:
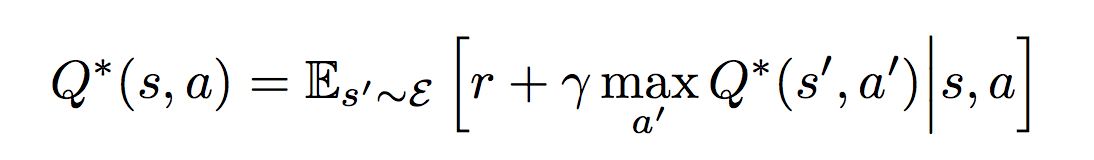

Если это расшифровать получается следующее:
- Берем пачку (minibatch) из N элементов опыта (S, A, R, S'), например 128 элементов
- Для каждого элемента считаем
y = R + ? * maxпо всем A' (Qpast(S', A'))
? — это дискаунт фактор, число в интервале [0, 1], которое определяет насколько для нас важны будущие награды. Типичные значение обычно выбираются в интервале 0.9 — 0.99.
Qpast — это копия нашей же нейросети, но какое-то количество итераций обучения назад, например 100 или 1000. Веса этой нейросети мы просто периодически обновляем, не обучаем.
Qpast = (1 — ?) * Qpast + ? * Q
? — скорость обновления Qpast, типичное значение 0.01
Этот трюк обеспечивает лучшую сходимость алгоритма
- Далее считаем функцию потерь для нашего минибатча
L = ?по элементам минибатча (y — Q(S, A))2 / N
Используем среднюю квадратичную ошибку
- Применяем любимый алгоритм оптимизации, используя L
- Повторяем пока нейросеть достаточно не обучится
Если внимательно посмотреть на уравнение Беллмана, то можно заметить, что оно рекурсивно оценивает текущее действие взвешенной суммой наград от всех последующих действий, возможных после выполнения текущего действия.
DDPG
Или Deep Deterministic Policy Gradient — это алгоритм, созданный, для случая когда управляющие команды представляют собой значения из непрерывных пространств (continuous action spaces). Например, когда вы управляете автомобилем, вы поворачиваете руль на определенный угол или нажимаете педаль газа до определенной глубины. Возможных значений поворота руля и положений педали газа теоретически бесконечно много, поэтому мы хотим чтобы алгоритм выдавал нам эти самые конкретные значения, которые нам необходимо применить в текущей ситуации. Поэтому в данном подходе используются две нейросети: ? (S) — актор, который возвращает нам вектор A, компоненты которого являются значениями соответствующих управляющих сигналов. Например это может быть вектор из трех элементов (угол поворота руля, положение педали газа, положение педали тормоза) для автопилота машины. Вторая нейросеть Q(S, A) — критик, которая возвращает q — оценку действия A в состоянии S. Критик используется для обучения актора и обучается с помощью уравнения Беллмана:
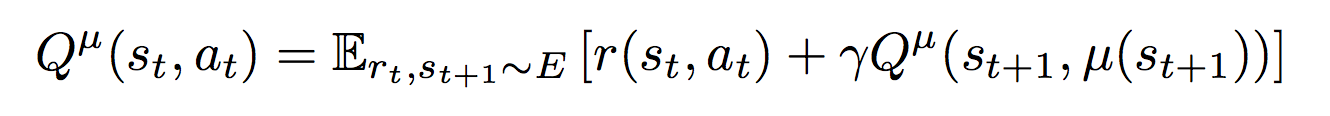
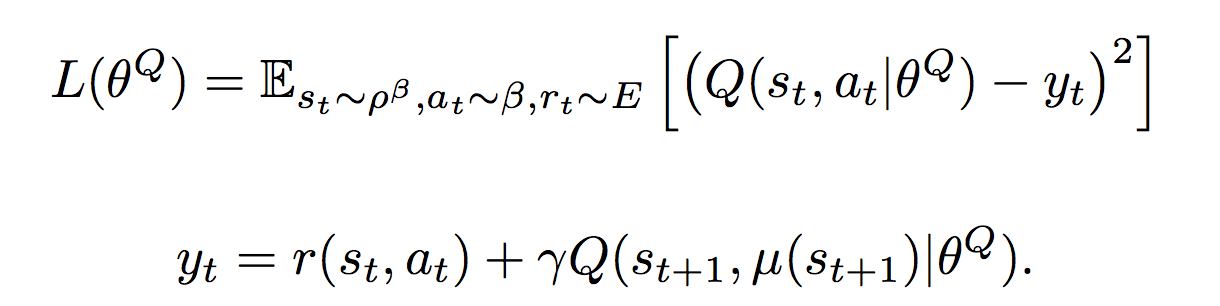
Критик обучается через градиент от оценки критика ?Q(S, ? (S)) по весам актора
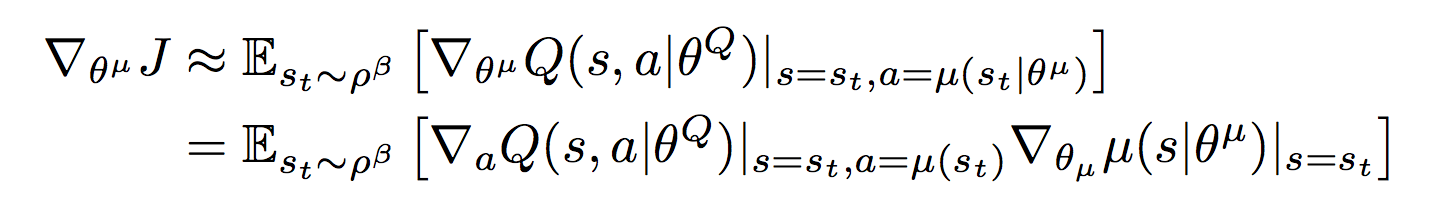
Если это расшифровать получается:
- Берем минибатч из N элементов опыта (S, A, R, S')
- y = R + ? * Qpast (S', ?past (S'))
Qpast, ?past — это тот же трюк что и в случае DQN, только теперь это копии двух сетей
- Считаем функцию потерь
L = ?по минибатчу (y — Q (S, A))2
- Обучаем критика используя L
- Берем градиент по весам актора ?Q(S, ? (S)) любимым алгоритмом оптимизации и модифицируем актора, с помощью него
- Повторяем пока не достигнем желаемого
RussianAICup
Теперь я расскажу об агенте, которого я тренировал для соревнования. Подробные правила можете почитать по ссылке, если интересно. Также можете посмотреть видео и описание на главной странице. В соревновании есть 2 типа игр, первый — это когда твоя стратегия управляет одним из десяти волшебников. И второй, когда твоя стратегия управляет командой из 5 волшебников, противник при этом управляет противоположной командой из 5ти волшебников. Информация, которая доступна для стратегии включает все объекты, которые находятся в области видимости всех дружественных волшебников, все остальное пространство покрыто туманом войны:
- волшебники
- миньоны
- строения (башни и базы)
- деревья
- бонусы
- снаряды
Юнит может иметь следующую информацию о себе:
- координаты
- количество хитпоинтов
- количество маны
- время до следующего удара
- другие параметры, их много, в правилах есть полное описание
Есть локальный симулятор (он на КПДВ), в котором можно погонять свою стратегию против самой себя или 2х встроенных противников, достаточно простых стратегий. Для начала я решил попробовать решить задачу в лоб. Я использовал DDPG. Собрал все доступные параметры о мире, их получилось 1184 и подал на вход. Выходом у меня был вектор из 13 чисел, отвечающих за скорость перемещения прямо и вбок, поворот, разные типы атаки, а также параметры атаки, такие как дальность полета снаряда, в общем все параметры, которые существуют. С наградой для начала тоже решил не мудрить, игра выдает количество XP, поэтому я давал положительную награду за повышение XP и отрицательную за уменьшение хитпоинтов. Поэкспериментировав какое-то время я понял, что в таком виде очень трудно добиться от нейросети толка, так как зависимости, которые должна была выявить моя модель, по моим прикидкам, были довольно сложными. Поэтому я решил, что надо упростить задачу для нейросети.
Для начала я перестроил состояние, чтобы оно представляло не просто сборник всей входящей информации, а подавалось в виде кругового обзора от управляемого волшебника. Весь круговой обзор делился на 64 сегмента, в каждый сегмент могло попасть 4 ближайших объекта в этом сегменте. Таких круговых обзоров было 3, для дружественных, нейтральных и вражеских юнитов, а также для указания куда следовало двигаться. В итоге получилось еще больше параметров — 3144. Также я начал давать награду за движение в нужном направлении, то есть по дорожке к вражеской базе. Так как круговой обзор включает информацию о взаимном расположении объектов, я еще пробовал использовать сверточную сеть. Но ничего не получалось. Волшебники просто крутились на одном месте без малейшего проблеска интеллекта. И я оставил на какое-то время попытки, чтобы почитать информацию о тренировке нейросетей и вдохновиться.
Через какое-то время я вернулся к экспериментам уже вдохновившись, уменьшил скорость обучения с 1e-3 до 1e-5, очень сильно сократил количество входных параметров до 714, попутно отказавшись от некоторых данных, чтобы ускорить процесс обработки информации. Также я решил использовать нейросеть только для движения и поворота, а стрельбу оставил за вручную прописанной простой стратегией: если можем стрелять поворачиваемся в сторону слабейшего врага и стреляем. Таким образом я снял с нейросети достаточно сложную для обучения, но легкую для прописывания задачу по прицеливанию и выстрелу. И оставил достаточно сложно формализуемую задачу наступления и отступления. В итоге стали заметны проблески интеллекта на обычной полносвязной сети. Потренировав ее какое-то время (пару суток на GeForce GTX 1080 на эксперимент), добившись неплохого качества управления (сеть обыгрывала встроенного противника), я решил загрузить сеть в песочницу.
Веса сети я выгрузил из Tensorflow и захардкодил их в виде h файлов. В итоге получился архив в несколько десятков мегабайт и песочница отказалась его принять, сказав что максимальный файл для загрузки 1 Мб. Пришлось намного сильнее сократить нейросеть и потратить кучу времени (порядка недели или нескольких недель, я уже точно не помню) на ее обучение, подбор гиперпараметров и уложиться в размер архива 1 Мб. И вот когда я наконец снова попробовал загрузить, оно выдало, что ограничение на разархивированный архив 2 Мб, а у меня было 4Мб. Фейспалм. Поборов бурные чувства, я принялся еще больше ужимать нейросетку. В итоге ужал до следующей архитектуры:
394 x 192 x 128 x 128 x 128 x 128 x 6
394 — это входной слой, во всех слоях кроме последнего и предпоследнего используется relu, в предпоследнем tanh в качестве активационной функции, в последнем, как водится, активационной функции нет. В таком виде контроль был не таким хорошим, но проблеск интеллекта заметен был и я решил загрузить этот вариант в аккурат за несколько часов до начала финала. С небольшими улучшениями он до сих пор и играет russianaicup.ru/profile/Parilo2 в песочнице в районе 700 места в рейтинге. В целом я доволен результатом на данный момент. Ниже видео с примером матча 1х1, моя стратегия управляет всей командой из 5ти волшебников.
Предложения по улучшению конкурса
В конкурсе довольно интересно участвовать. Есть плюшки в виде локального симулятора. Я бы хотел предложить несколько изменить формат. То есть запускать на сервере только серверную часть и рейтинговую таблицу, а клиенты чтобы коннектились через интернет к серверу и участвовали в поединках. Таким образом можно снять нагрузку с сервера, а также убрать ограничения по ресурсам для стратегий. В общем, так как это сделано во многих онлайн играх типа Старкрафт 2 или той же Доты.
Код
Код агента доступен на гитхабе. Используется С++ и для управления и для обучения. Обучение реализовано в виде отдельной программы WizardTrainer, которая зависит от TensorFlow, стратегия подключается по сети к тренеру, скидывает туда состояние среды и получает оттуда действия которые необходимо совершать. Также она туда отправляет весь получаемый опыт. Таким образом к одной нейросетке можно подключать несколько агентов и она будет управлять всеми одновременно. Собрать это все не так просто, если потребуется спросите меня как.
Ресурсы
Более подробно об обучении с подкреплением, этих, а также других алгоритмах можно посмотреть в замечательном курсе David Silver из Google DeepMind. Слайды доступны здесь.
Оригинальные статьи DDPG и DQN. Формулы я брал из них.
Спасибо, что дочитали до конца. Удачи вам на пути познания!
P.S. Прошу извинить за размер формул, не хотел, чтобы они были маленькие, перестарался с принтскрином.
Комментарии (56)
mayorovp
16.01.2017 08:51+2То есть запускать на сервере только серверную часть и рейтинговую таблицу, а клиенты чтобы коннектились через интернет к серверу и участвовали в поединках.
Это привело бы к тому, что победитель определялся бы не лучшим алгоритмом, а деньгами, вбуханными в железо и пингом до сервера. Кроме того, участие в соревновании было бы попросту дорогим.



dbf
16.01.2017 10:44+3Было бы интересно посмотреть на игру исходной (неурезанной) нейросети против хотя бы SmartGuy из поставки, а лучше, против какой-нибудь из стратегий лидеров, выложенных на GitHub — все же 700-е место это не так много.

Parilo
16.01.2017 10:49+1На досуге можно попробовать. Если займусь, то добавлю в пост еще одно видео.
Encarmine
16.01.2017 10:44Сервер подбирает оппонентов и запускает игры максимизируя равномерность оценки игроков. Для этого каждому участнику нужен 24/7 работающий сервер, что не очень удобно.
Parilo
16.01.2017 10:47Тут я бы предложил по аналогии со Старкрафтом, стратегия логинится и запрашивает поиск игры, тогда нет необходимости в 24/7
mayorovp
16.01.2017 12:53А что делать если две стратегии, между которыми назначен матч, не пересекутся во времени? Или вы предлагаете доверять случаю, не планируя матчи вовсе? В таком случае что делать с накрутками?
Parilo
16.01.2017 12:56Матч не назначается системой, стратегии логинятся и запрашивают матч, дальше система подбирает им соперников, которые есть он-лайн, с учетом рейтинга. С накрутками должен бороться рейтинг. Опять же в Старкрафте 2 нету проблемы частотой матчей. Есть игроки, которые часто играют и все равно находятся снизу в рейтинге и те, кто играет не часто и находится в топе, только за счет скилла.
mayorovp
16.01.2017 13:04Вот только в Старкрафте не разрешены боты, а тут только они и есть. И онлайн тоже разный.
Алгоритм накруток довольно прост. Делаем кучу ботов, которые сливаются в каждом матче — и запускаем у них поиск игры одновременно с основной стратегией. С большой вероятностью поиск игры сопоставит их друг другу — вот и накрутка.
Можно даже заранее выбрать время когда онлайн небольшой. А еще можно найти внеигровые способы проверить что два бота играют друг с другом (одинаковый порт / одинаковый ID игры / пр.)
Parilo
16.01.2017 15:24Периодически можно было бы устраивать ланы с расписанием, жеребьевкой и прочим. Ну и потом просто посмотреть в код перед определением победителя.



Shedar
16.01.2017 12:24+2пару суток на GeForce GTX 1080 на эксперимент
Насколько получается её загрузить? На днях поставил себе GTX 1080, пробовал позапускать примеры с gym/universe. Упирается в процессор, видеокарта не особо загружена. Или я что-то делаю не так, или процессор тоже пора менять (сейчас i5 2500), или для симуляций это типично и нет смысла менять еще половину системника.Parilo
16.01.2017 12:53+1У меня проц i7 6700k
Загрузка GPU сильно зависела от размера состояния, на 394 параметрах была около 20%, на 3144 опускалась ниже 10% вроде бы. И как я понял дело даже не в проце, просто надо реорганизовать обучение. У меня весь опыт по мере поступления складывается в replay buffer и оттуда же я выбираю минибатчи для обучения, затем отправляю их в TensorFlow. На supervised learning задачах, где изначально есть датасет и ты по нему бегаешь загрузка 99% на GPU. Я думаю, надо попробовать сделать как в supervised, то есть иметь отдельно буфер для складывания опыта и второй для обучения и периодически их синхронизировать. И еще лучше попытаться организовать этот буфер прямо в GPU.

Rogvold91
16.01.2017 13:15+2Для меня статья оказалась очень интересной — первые позывы, когда решил участвовать в конкурсе, были написать нейросеть или что-нибудь из машинного обучения. Однако, остановился на другом.
Как мне кажется, исходя из турнира, нейросети — это стрельба из пушки по воробьям. Намного важнее было:
1. Алгоритм движения (как пройти из точки а в точку б и обойти препятствие)
2. Алгоритм уклонения
3. Алгоритм движения в глобальном смысле (куда идти)
4. Древо развития талантов.
5. Взаимодействие с командой.
Я имел полный и бесповоротный фейл с 1 пунктом ( как раз перед вторым этапом. Захотелось написать нормальный поиск пути, вместо дуболомного, а получился фейл), 2ой отсутствовал, но кое-что сделал из 3 и 4. Как итог — когда 1 пункт ещё как-то работал ( тупой обход препятствий. Между первым туром и серединой междутурья) удавалось быть где-то в районе 400го места.
znsoft
16.01.2017 15:26+2Увы в этом году поиск/выбор пути был не самым приоритетным.
Развивал только его не вдаваясь в боевку и микру.
Получилось реализовать А* для дальних маршрутов и 10 симуляций мира на 200 тиков вперед (9 направлений + отступление). Итог раунд 1 = 180 место раунд 2 = 335.
Parilo
16.01.2017 15:43Соревнование действительно оказалось не очень подходящим для нейросетей, так как ресурсов мало и нельзя использовать готовые библиотеки. Но если есть какие-то заготовки то почему нет? У меня как раз некоторые заготовки были, поэтому я и решился. В прошлом году заготовок не было, поэтому не участвовал.

CrazyFizik
17.01.2017 01:381,2,3 — справиться одна небольшая сеть заточенная на движение, под это нейросеть обучить проще всего
4 — отдельный модуль нейросети для развития талантов, но можно обойтись и решающим деревом
5 — модуль нейросети, определяющий общую стратегию поведения, хотя в принципе, это может и модуль, отвечающий за движение
итого 2-3 нейросети + 1 для применения способностей, прицеливания и атаки
А так в тот же футбол может играть достаточно простенькая нейросетка, всего где-то на 22 нейрона
А писать известные алгоритмы для конкурса — ну как-то нудно и не интересно, а тот же А* так вообще читерство истой воды (навигация IRL у живых человеков чисто локальная)znsoft
17.01.2017 02:19Очень жду и надеюсь увидеть вашего бота в RAIC 2017
CrazyFizik
17.01.2017 02:40Ну если у меня на работе решат оторвать задач оптимизации, и скажут «пиши бота для RAIC 2017», то не вопрос :-)… ну или хотя бы еще программистов наберут…
А так я вообще только сегодня узнал, что в РФ такие конкурсы оказывается проводятсяznsoft
17.01.2017 03:13Все участники кого я знаю, участвовали в ущерб работе, сну, отношениям.
Бонусом можно взять какой-нибудь новый для себя ЯП.
Но все это того стоило, градус азарта перекрывал всю недополученную прибыль и недосып.
И да я впервые использовал А* в этом году… до этого вообще был ЛИ. так что в следующем году у вас есть все шансы обыграть таких как я )

alhimik45
16.01.2017 14:52+1Не знаком с машинным обучением, поэтому такой вопрос: А можно ли по аналогии с нейронными сетями использовать генетические алгоритмы в данной задаче? Если да, то это будет функция с 3000+ параметров или как вообще это делается?
Parilo
16.01.2017 15:32Я не спец в генетических алгоритмах, но я думаю что можно, только если тупо в лоб, то вероятно это будет долго, с учетом того, что локальный симулятор работает довольно долго. Наверное нужно как-то бить на подзадачи и какой-то свой симулятор писать.
Parilo
16.01.2017 15:40-2Про генетические алгоритмы есть довольно много инфы. Да, это нейросеть с большим количеством параметров — весов.
Rogvold91
16.01.2017 15:58+1Пример из этого же соревнования.
Я пушу нижний лайн. Снёс вышку.Начинаю бить в одиночестве вторую и вижу: мне на верхнем лайне вдвоём начинают сносить вторую вышку. Мои союзники пушат мид. Вчетвером троих. Диллема- что мне делать? Бежать на базу отбиваться? Присоединиться к пушу мида и сыграть наперегонки?
Побегу на базу — если отобьюсь, а наш пуш мида захлебнётся, то вероятно будет ничья( в турнире было ограничение по времени). А при ничьей я по очкам в конце буду тогда. А если наши выиграют, то я всё равно мало получу.
Плюнуть и пойти пушить мид? Если проиграем, то потери по очкам.
Вот в такой ситуации генетический алгоритм мог бы помочь принять решение.
Была бы оценочная функция. На вход ей подавалась бы инфа о моих союзниках — таланты, опыт, местоположение, о врагах, которых вижу, инфа о базах под прессингом, расстояние до базы. Задача генетического алгоритма- максимизировать мою прибыль по очкам. Ну, что-нибудь в таком духе
CrazyFizik
16.01.2017 22:38+3Можно. Задача обучения ИНС является многопараметрической задачей нелинейной оптимизации в пространстве состояний, соответственно все алгоритмы глобальной оптимизации: эволюционные алгоритмы, Particle Swarm Optimization (алгоритм роя частиц) и Simulated annealing (алгоритм имитации отжига) будут давать достаточно хорошие результаты, на порядок лучше классического обучения с учителем.
В контексте ИНС — это целое направление нейроэволюционных алгоритмов (Neuroevolution). Но это все можно считать разновидностью обучения с подкреплением, собственно Q-learning из той же области.
Только вот не стоит забывать, что алгоритмы глобальной оптимизации хоть и находят глобальный оптимум, но обычно крутятся в его горловине, поэтому желательно уточнять решение каким-нибудь классическим алгоритмом локальной оптимизации (для ИНС это будет back propagation, например) в таком случае будет получено наилучшее решение. Правда есть там все равно опредмеченные трудности, для такой избыточной сети (она реально избыточная для такой задачи) как у автора, наверное замучаешься обучать её.
CrazyFizik
16.01.2017 23:01Есть езе один момент: эволюционные и роевые алгоритмы хорошо справляются с задачами, где функционал задан в неявном виде и/или очень сложный, с целой кучей ограничений, да и в целом может оказаться неизвестным (учителя с розгами не приставишь уже), а полноценной обучающей выборки как таковой нет. А боты как раз этот самый случай => поэтому с ними проще ставить кибернетический эксперимент => смотреть как стайка ИИ взаимодействует с окружающей средой => от итерации к итерации эволюционировать их (ну где-то в районе 200-500 поколений наверное уже будут проявлять зачатки интеллекта). А учитывая что задача в общем случае нелинейна (поэтому всякие там back propagtion будут переобучаться, инфа 145%), то да, все эти метаэвристики будут хорошо работать… только вот надо правильно продумать весь алгоритм а то нифига не сработает: вот например на ютубе можете найти ролик Evolution of a self-organizing robot soccer team (а в гугле статьи по нему) где показано очень изящное и простое решение NN+GA которая играет в футболл, но в дотку такой ИИ играть врядли сможет (надо будет по другому реализовывать)
znsoft
17.01.2017 02:10В прошлом году 1 место занял алгоритм перебора, очень отдаленно напоминающий генетический алгоритм https://habrahabr.ru/post/273649/

defaultvoice
16.01.2017 15:20+1Прошу извинить за размер формул, не хотел, чтобы они были маленькие, перестарался с принтскрином.
А вы перепишите их на TeX – теперь уже можно
plartem
16.01.2017 21:36Почему это все называют дотой, если это просто moba?
mayorovp
16.01.2017 22:27+1Смотрим определение MOBA и видим: "жанр компьютерных игр, сочетающий в себе элементы стратегий в реальном времени и компьютерных ролевых игр и выделяющийся схожестью с DotA".
Дота — это родоначальник, жанр MOBA был выделен только после появления кучи клонов.
Разница тут такая же, как между ксероксом и копиром. Почему все говорят "ксерокс"? Привыкли потому что.
CrazyFizik
16.01.2017 22:52ИМХО, автор явно переусердствоал с задачей.
Во-первых, сеть вида 394 x 192 x 128 x 128 x 128 x 128 x 6 мягко говоря избыточная, очень избыточная.
Во-вторых, лучше использовать несколько маленьких ИНС, каждая для своей задачи: движение, стрельба, глобальная стратегия и т.п.(тут на самом деле большой простор для творчества, много чего можно наэксперемнтировать).
Нервные системы всяких человеков и прочьих животных и дажек букашек, на самом деле разбиты на отдельные подсистемы и отделы, каждые из которых занимаются конкретно своими делами (разделяй и властвуй, ёпс) и специализируются на определенном наборе функций. И это все не с проста, а результат эволюции — так то можно этот путь повторить используя ИНС и эволюционные алгоритмы (которые не просто подбирают веса, а подбирают структуру ИНС), там даже будут видны какие-то зачатки специализации, вот только сколько потребовалось челокам миллионов лет, шоб играть в дотку IRL? И сколько в итоге нейронов у человеков просто так бездельничают — более 90% (на самом деле они нужны на всякий случай, дабы после того как тюкнешься головой случайно не разучиться ходить и говорить, но то что мозг полностью функционален даже после 80% потери мозгового вещества — известный медицинский факт, хоть и не рядовой).
Поэтому лучше эту задачу решить самому, а не надеяться на обучение (оно то рано или поздно достигнет просветления, только эт вообще-то NP-полная задача) и сразу делать специализированные модули ИИ (собственно к чему автор и начал сам потихоньку приходить): быстрее обучишь, меньше нейронов потребуется (я имею ввиду суммарное число всех нейронов всех ИНС), а результат окажется куда более эффективным — на эту тему в принципе уже не одна научная статья писана.Parilo
16.01.2017 22:57А можно поподробнее про подбор архитектуры ИНС для задачи? Посоветуйте где можно почитать/посмотреть про подбор архитектур ИНС? Если не использовать эволюционные алгоритмы.
CrazyFizik
17.01.2017 00:02+1Только суровый метод научного тыка, тока хардкор…
Ну вот на tproger есть краткая шпаралка по нейросетям, прям так и называется: Шпаргалка по разновидностям нейронных сетей. Часть первая. Элементарные конфигурации
Правда второй части я не увидел, но это перевод, т.е. на буржуинском можно найти искомую статью полностью. Впрочем на хабре вроде тоже это было: Зоопарк архитектур нейронных сетей. Уже в 2-х частях.
Есть хороший обзор по нейросетям в играх с большим количеством ссылок. Презенташка разработчиков Supreme Command (да они там используют ИНС). Статья по модульным ИНС на примере классической космической пострелушке. Встречал очень много статей по Старкрафту, вот например одна из одна. И даже по шутерам, там как раз тоже модульная нейросетка.
Но вообще последнее время популярно использовать использовать именно генетику, например особенно популярен алгоритм NEAT там действительно хорошие результаты получались или вот
Но вообще, проще всего ИНС присобачить для гонок — для задач навигации их наверное проще всего обучить и там можно обойтись без генетики. Для стрельбы и прицеливания — тоже наверное лучше одну отдельную нейросетку использовать. И отдельную сеть для выборов шаблонов поведения как в одной книжке
CrazyFizik
17.01.2017 01:23Но от генетики никуда сейчас не денешься, обучать то как-то нейросеть нужно, и сделать это так, что бы она не переобучилась (не попала в локальный минимум), а тут тока GA и PSO. Ну и агент должен как-то учитывать прошлую информацию, т.е. сеть должна быть рекурентной (как раз таки отсюда глубокие нейронные сети и сверточные нейронные сети), цепи Маркова, машину Больцмана, т.к. они обладают памятью, а это нужно.
Вот кстати шпоры 1 и 2 на хабре, и на tproger. Вдруг пригодятся.
А вот пример эволюционирующей нейросети, обучаются достаточно резво.Parilo
17.01.2017 13:30Далеко не все глубокие нейронные сети рекуррентные, сверточная нейросеть тоже не рекуррентная.
CrazyFizik
17.01.2017 14:08Я и не писал, что свёрточная и рекуррентная одно и тоже, — я написал что они обе из одной степи, т.е. из глубинного обучения. Я хотел изменить на более понятный вариант, но Хабр не дает редактировать сообщения (сколько он там дает, 2 минуты где-то?)
CrazyFizik
17.01.2017 02:14И вот еще парочка ссылочек на одного канадского китайца с примерами на Жабе:
http://blog.otoro.net/2015/03/28/neural-slime-volleyball/
http://blog.otoro.net/2015/05/07/creatures-avoiding-planks/
http://blog.otoro.net/2015/03/10/esp-algorithm-for-double-pendulum/

QtRoS
17.01.2017 00:22Приятно видеть, что были и академические решения, а не только банальные 'if' на все случаи жизни!
P.S. Победители — без обид. Там тоже, уверен, непростая работа проделана.

ivodopyanov
17.01.2017 08:47Тоже хотел использовать DRL в турнире, но времени не было.
Мне кажется, правильнее было бы обучать две сети:
* первая отвечает за макро-стратегию — куда идти волшебнику;
* вторая отвечает за микро — боевой режим, который включается при приближении противника на некоторое расстояние.ivodopyanov
17.01.2017 08:51Бой богат на результативные действия, поэтому вторая модель должна довольно быстро обучаться. А первую стратегию даже можно было просто захардкодить для начала.
erwins22
17.01.2017 13:48можно вообще использовать лес стратегий.
вначале давать примитивной стратегии
преимущество, пусть ее копирует нейросеть
VaalKIA
Если бы она обучалась прямо во время матча, думаю комментариями бы уже завалили, но подход был основательный.
myxo
Как вы себе это представляете? Для обучения нужно N порядков (сколько там игр за 2 суток обучения прошло?) игр, а не 2-3, которые успеют сыграть во время матча.
Oplkill
Можно былобы брать информацию из реальных матчей где играют Профи против Профи. На этих матчах и тренировать ИИ
Parilo
Это другой метод, но это возможно, нужно только взять где-то эти данные