
 Цифровая обработка изображений — весьма интересная область, но она таит в себе множество подводных камней, на которые постоянно натыкаются новички. Мы активно привлекаем студентов к участию в грантах и проектах, но когда мы пытались давать студентам реальные задания, которые требуют реализации новых алгоритмов обработки изображений, мы были в ужасе от совершаемых ими детских ошибок.
Цифровая обработка изображений — весьма интересная область, но она таит в себе множество подводных камней, на которые постоянно натыкаются новички. Мы активно привлекаем студентов к участию в грантах и проектах, но когда мы пытались давать студентам реальные задания, которые требуют реализации новых алгоритмов обработки изображений, мы были в ужасе от совершаемых ими детских ошибок.
Поэтому перед постановкой полноценных задач мы стали давать студентам ряд практических заданий по реализации стандартных алгоритмов обработки изображений: базовые операции над изображениями (поворот, размытие), свёртка, интерполяция с помощью простых фильтров (билинейная, бикубическая), направленная интерполяция, выделение границ с помощью алгоритма Канни, детектирование ключевых точек и т.д. Язык программирования мог быть любым, однако при выполнении заданий не допускается использование сторонних библиотек, за исключением чтения и записи изображений. Это связано с тем, что задания носят обучающий характер, самостоятельная реализация алгоритмов является хорошей практикой в программировании и позволяет понять, как работают методы изнутри.
Данная статья описывает наиболее частые ошибки, совершаемые студентами при выполнении практических заданий по обработке изображений. Изображения обычные, никакой экзотики типа 16-битной глубины цвета, панхроматичности и 3D-изображений нет.
Ошибка 1. Работа с пикселями, используя системные объекты Bitmap, HBITMAP и им подобные для хранения изображений
Данные объекты предназначены для взаимодействия с графической подсистемой (рисование примитивов и текста, вывод на экран) и не предоставляют возможности прямого доступа к участку памяти, в котором хранятся пиксели изображения. Доступ к пикселям осуществляется с помощью функций GetPixel и SetPixel. Вызов этих функций очень дорогой — на два-три порядка медленнее, чем прямой доступ к пикселям. Особенно велик соблазн так делать в C#, где тип Bitmap доступен «из коробки».
Решение: использовать данные классы только для чтения из файла, записи в файл и вывод на экран, в остальных случаях работать с классами, имеющими эффективный доступ к пикселям.
Замечание: в некоторых случаях в Windows удобно работать с DIB (device independent bitmap): есть и прямой доступ к пикселям, и возможность вывода на экран, минус — ограничение на тип пикселя.
Ошибка 2. Использование библиотек для работы с изображениями при отсутствии опыта обработки изображений
Использование библиотек чревато непониманием работы алгоритмов и дальнейшими трудностями при решении практических задач, требующих разработки собственных алгоритмов, которых нет в библиотеках. Я сталкивался с хорошо программирующими студентами, которые не могли реализовать даже элементарные операции типа свёртки: то не получалось подключить библиотеку, то работало не так, но на написание функции из 10 строчек ума уже не хватало.
Решение: не использовать сторонние библиотеки, а писать свои классы для работы с изображениями и самостоятельно реализовывать основные алгоритмы. Особенно полезно это для тех, кто не имеет достаточного опыта программирования. Лучше несколько раз сломать велосипед, чем завалить целый проект из-за глупых ошибок.
Ошибка 3. Потеря в точности при округлении
В результате применения различных алгоритмов обработки изображений возникают промежуточные результаты, имеющие вещественный тип. Пример: практически любой усредняющий фильтр, например, фильтр Гаусса. Приведение результатов к типу byte приводит к внесению дополнительной ошибки и менее точной работе алгоритмов.
Ниже приведён пример работы алгоритма детектировании контуров Канни, одним из составных частей которого является вычисление модуля градиента. Слева — модуль градиента после вычисления хранится в типе float, справа — округляется до byte.


Несложно заметить, что при округлении контуры становятся рваными.
Решение: если для алгоритма критична точность, то используйте тип float вместо byte для хранения значений пикселей, не занимайтесь преждевременной оптимизацией — сначала добейтесь нормальной работы алгоритма на float, а затем уже думайте, где можно использовать byte так, чтобы не снизилось качество.
Замечание: скорость работы современных процессоров с вещественными числами сопоставима с целыми. В некоторых случаях компилятор может применить автоматическую векторизацию, что приведёт к более быстрому коду с float. Также код с float может получиться более быстрым при большом количестве преобразований byte-float, округлений и отсечений. А вот использование double редко бывает оправдано, а мешанина из float и double так вообще является следствием непонимания типов и принципов работы с ними.
Использование целочисленных типов (byte, int16, uint16) особенно эффективно при использовании векторных операций, когда скорость доступа к памяти становится узким местом.
Ошибка 4. Выход значений пикселей за пределы диапазона [0, 255]
У вас нет проблем с точностью и вы всё ещё хотите для хранения значений пикселей использовать тип byte? Тогда возникает ещё одна проблема: многие операции, например бикубическая интерполяция или повышение резкости, приводят к появлению значений, выходящих за пределы указанного диапазона. Если не учитывать этот факт, то возникает эффект, называемый wrapping: значение 260 превращается в 4, а –3 — в 253. Появляются яркие точки и линии на тёмном фоне и тёмные — на светлом (слева — правильная реализация, справа — с ошибкой).


Решение: при выполнении промежуточных операций проверяйте на каждом шаге диапазон возможных значений, а при преобразовании в байтовый тип обязательна проверка на выход за границы диапазона, например, так:
unsigned char clamp(float x)
{
return x < 0.0f ? 0 : (x > 255.0f ? 255 : (unsigned char)x);
}Ошибка 5. Потеря значений в результате приведения к диапазону [0, 255]
Вы предпочитаете работать с типом byte и используете функцию clamp? А вы уверены, что ничего не теряете, как в случае с округлением?
Видел на практике, как студенты при вычислении производной или при применении фильтра Собеля таким образом теряли отрицательные значения.
Решение: используйте типы достаточного размера для хранения промежуточных результатов, а функцию clamp только для сохранения в файл или вывода на экран. Для визуализации производной добавляйте 128 к значению пикселя, либо берите модуль.
Ошибка 6. Неправильный порядок обхода по пикселям изображения, приводящий к замедлению работы программы
Память в компьютере одномерна. Двумерные изображения хранятся в памяти в виде одномерных массивов. Обычно они записываются построчно: сначала идёт 0-я строка, затем 1-я и т.д.
Последовательный доступ к памяти осуществляется быстрее, чем произвольный. Это связано с работой кэша процессора, который помещает данные из памяти в кэш большими блоками, например, по 64 байта для современных процессоров. В этот блок попадают сразу несколько соседних по горизонтали пикселей. Значит, при обращении к последующим пикселям в той же строке скорость доступа будет выше, чем к последующим пикселям в столбце.
Решение: Обход по изображению нужно делать так, чтобы доступ к памяти был последовательный: во внешнем цикле производится обход по вертикали, а во внутреннем — по горизонтали:
for (int y = 0; y < image.Height(); y++)
for (int x = 0; x < image.Width(); x++)
...Примечание: В разных языках способ представления многомерных массивов в памяти может быть различным. Имейте это в виду.
Ошибка 7. Путаница с шириной и высотой
Классическая проблема: тестирование либо отсутствует, либо осуществляется только на квадратных изображениях, в полевых условиях при работе с прямоугольными изображениями происходит выход за границу массива.
Решение: не забывайте про тестирование! Спор о TDD предлагаю не разводить: его использование — это личное дело каждого.
Ошибка 8. Отказ от абстракций
Боязнь плодить сущности — типичная ошибка новичков, она приводит к проблемам с читаемостью и восприятием кода. Здесь можно привести много примеров.
1. Обращение к пикселям через непосредственное вычисление индексов в массиве вместо использования методов getPixel(x, y) и setPixel(x, y). Помимо удобства, в этих методах можно проверять и корректно обрабатывать выход за границы изображения. Например, не выдавать ошибку, а эктраполировать значения изображения.
b1 = (float)0.25 * ( w1 - 1) * (w1 - 2) * (w1 + 1) * (h1 - 1) * (h1 - 2) * (h1 + 1);
b2 = -(float)0.25 * w1 * (w1 + 1) * (w1 - 2) * (h1 - 1) * (h1 - 2) * (h1 + 1);
b3 = -(float)0.25 * (w1 - 1) * (w1 - 2) * (w1 + 1) * (h1 + 1) * (h1 - 2);
b4 = (float)0.25 * w1 * h1 * (w1 + 1) * (w1 - 2) * (h1 + 1) * (h1 - 2);
b5 = -(1 / 12) * w1 * (w1 - 1) * (w1 - 2) * (h1 - 1) * (h1 - 2) * (h1 + 1);
b6 = -(1 / 12) * h1 * (w1- 1) * (w1 - 2) * (w1 + 1) * (h1 - 1) * (h1 - 2);
b7 = (1 / 12) * w1 * h1 * (w1 + 1) * (w1 - 2) * (h1 + 1) * (h1 - 2);
b8 = (1 / 12) * w1 * h1 * (w1- 1) * (w1 - 2) * (h1 - 1) *( h1 - 2);
b9 = (1 / 12) * w1 * (w1 - 1) * (w1 + 1) * (h1 - 1) * (h1 - 2) * (h1 + 1);
b10 = (1 / 12) * w1 * (w1 - 1) * (w1 - 2) * (w1 + 1) * (h1 - 1) * (h1+ 1);
b11 = (1 / 36) * w1 * h1 * (w1 - 1) * (w1 - 2) * (w1 - 1) * (h1 - 2) * (h1- 2);
b12 = -(1 / 12) * w1 * h1 * (w1 - 1) * (w1 + 1) * (h1 + 1) * (h1 - 2);
b13 = -(1 / 12) * w1 * h1 * (w1 + 1) * (w1 - 2) * (h1 - 1) * (h1 + 1);
b14 = -(1 / 36) * w1 * (w1 - 1) * (w1 + 1) * (h1 - 1) * (h1 - 2);
b15 = -(1 / 36) * w1 * h1 * (w1 - 1) * (w1 - 2) * (h1 - 1) * (h1 + 1);
b16 = (1 / 36) * w1 * h1 * (w1 - 1) * (w1 + 1) * (h1 - 1) * (h1 + 1);
image2.rawdata[y1 * image2.Width + x1].b =
image1.rawdata[h * image1.Width + w].b * b1
+ image1.rawdata[h * image1.Width + w + 1].b * b2
+ image1.rawdata[(h + 1) * image1.Width + w].b * b3
+ image1.rawdata[(h + 1) * image1.Width + w + 1].b * b4
+ image1.rawdata[h * image1.Width + w - 1].b * b5
+ image1.rawdata[(h - 1) * image1.Width + w].b * b6
+ image1.rawdata[(h + 1) * image1.Width + w - 1].b * b7
+ image1.rawdata[(h - 1) * image1.Width + w + 1].b * b8
+ image1.rawdata[h * image.Width + w + 2].b * b9
+ image1.rawdata[(h + 2) * image1.Width + w].b * b10
+ image1.rawdata[(h - 1) * image1.Width + w - 1].b * b11
+ image1.rawdata[(h + 1) * image1.Width + w + 2].b * b12
+ image1.rawdata[(h + 2) * image1.Width + w + 1].b * b13
+ image1.rawdata[(h - 1) * image1.Width + w + 2].b * b14
+ image1.rawdata[(h + 2) * image1.Width + w - 1].b * b15
+ image1.rawdata[(h + 2) * image1.Width + w + 2].b * b16;
image2.rawdata[y1 * image2.Width + x1].g =
image1.rawdata[h * image1.Width + w].g * b1
+ image1.rawdata[h * image1.Width + w + 1].g * b2
+ image1.rawdata[(h + 1) * image1.Width + w].g * b3
+ image1.rawdata[(h + 1) * image1.Width + w + 1].g * b4
+ image1.rawdata[h * image1.Width + w - 1].g * b5
+ image1.rawdata[(h - 1) * image1.Width + w].g * b6
+ image1.rawdata[(h + 1) * image1.Width + w - 1].g * b7
+ image1.rawdata[(h - 1) * image1.Width + w + 1].g * b8
+ image1.rawdata[h * image1.Width + w + 2].g * b9
+ image1.rawdata[(h + 2) * image1.Width + w].g * b10
+ image1.rawdata[(h - 1) * image1.Width + w - 1].g * b11
+ image1.rawdata[(h + 1) * image1.Width + w + 2].g * b12
+ image1.rawdata[(h + 2) * image1.Width + w + 1].g * b13
+ image1.rawdata[(h - 1) * image1.Width + w + 2].g * b14
+ image1.rawdata[(h + 2) * image1.Width + w - 1].g * b15
+ image1.rawdata[(h + 2) * image1.Width + w + 2].g * b16;
image2.rawdata[y1 * image2.Width + x1].r =
image1.rawdata[h * image1.Width + w].r * b1
+ image1.rawdata[h * image1.Width + w + 1].r * b2
+ image1.rawdata[(h + 1) * image1.Width + w].r * b3
+ image1.rawdata[(h + 1) * image1.Width + w + 1].r * b4
+ image1.rawdata[h * image1.Width + w - 1].r * b5
+ image1.rawdata[(h - 1) * image1.Width + w].r * b6
+ image1.rawdata[(h + 1) * image1.Width + w - 1].r * b7
+ image1.rawdata[(h - 1) * image1.Width + w + 1].r * b8
+ image1.rawdata[h * image1.Width + w + 2].r * b9
+ image1.rawdata[(h + 2) * image1.Width + w].r * b10
+ image1.rawdata[(h - 1) * image1.Width + w - 1].r * b11
+ image1.rawdata[(h + 1) * image1.Width + w + 2].r * b12
+ image1.rawdata[(h + 2) * image1.Width + w + 1].r * b13
+ image1.rawdata[(h - 1) * image1.Width + w + 2].r * b14
+ image1.rawdata[(h + 2) * image1.Width + w - 1].r * b15
+ image1.rawdata[(h + 2) * image1.Width + w + 2].r * b16;Это реализация бикубической интерполяции в исполнении студента.
Лишь немногие студенты догадались, что бикубическая интерполяция сепарабельна, и сумели обойтись четырьмя коэффициентами вместо шестнадцати.
2. Дублирование кода при работе с цветными изображениями, приводящее к ошибкам (см. пример выше). Вместо copy-paste кода и замены r на g и на b достаточно было бы использовать перегрузку операторов. В три раза меньше кода, в три раза понятнее.
3. Использование двумерных массивов вместо создания отдельного класса для изображения.
Проблема заключается в том, что индексация получается неестественной — (y, x) вместо (x, y), а размерности массива не очевидны: непонятно, что из GetLength(0) и GetLength(1) есть ширина, а что — высота. Высок риск просто перепутать индексы.
4. Использование трёхмерных массивов для хранения цветных изображений вместо создания отдельного класса для изображения. В дополнение к предыдущему пункту, приходится помнить, какой из индексов соответствует какой цветовой компоненте. Также видел, как трёхмерные массивы используются для хранения векторов, как в виде (vx, vy), так и в виде (v, angle). Запутаться легко.
5. Использование массива вместо класса. Угадайте, что возвращает следующая функция?
public static double[] HoughTransform2(GrayscaleFloatImage image, ref float[][] direction, ColorFloatImage cimage)Ответ: массив из 11 элементов, каждый из элементов имеет свой сакральный смысл, непонятный без длительного анализа кода. Не делайте так! Заведите класс и назовите каждое из полей по-человечески.
6. Переиспользование переменных с изменением семантики. Видите в коде gradx и grady и думаете, что это призводные по x и по y? А вот и нет, это модуль и угол:
gradx[x, y] = (float)Math.Sqrt(temp1 * temp1 + temp2 * temp2);
grady[x, y] = (float)(Math.Abs(Math.Atan2(temp2, temp1)) * 180 / Math.PI);Решение: никаких магических констант и индексов быть не должно. Оформляйте изображения как отдельные классы, сами пиксели тоже должны быть типизированы, а доступ к пикселям должен осуществляться только через специальные методы.
Ошибка 9. Применение некоторых математических функций неправильно или не к месту
Здесь виной всему слабое понимание архитектуры процессора, набора инструкций и времени их выполнения. Простительно, приходит с опытом, но некоторые моменты я отмечу:
1. Возведение в квадрат в виде Math.Pow(x, 2) или pow(x, 2) вместо x * x.
Компиляторы не оптимизируют эти конструкции, вместо однотактового умножения они генерируют довольно сложный код, включающий в себя вычисление экспоненты и логарифма, что приводит к снижению скорости на порядок-два.
Вызов pow(x, y) разворачивается в exp(log(x) * y). Это занимает около 300 тактов при использовании команд x87. В SSE же экспоненты и логарифма до сих пор нет, существует множество реализаций exp и log с различной производительностью, например, вот. В лучшем случае возведение в степень займёт 30-50 тактов. На умножение же уйдёт всего один такт.
2. Взятие целой части как (int)Math.Floor((float)(j) / k), причём k — вещественное и не меняется внутри цикла.
Здесь достаточно было бы написать (int)(j / k), а ещё лучше (int)(j * inv_k), где float inv_k = 1.0f / k.
Дело в том, что floor возвращает вещественное число, которое затем нужно дополнительно преобразовывать в целое. Получается лишняя довольно дорогая операция. Ну а замена деления на умножение — просто оптимизация, операция деления до сих пор дорогая.
(int)floor(x) и (int)x зквивалентны только при неотрицательных x. Функция floor всегда округляет вниз, тогда как (int)x — в сторону нуля.
3. Вычисление обратного значения.
double _sum = pow(sum, -1);Зачем так делать, когда можно написать _sum = 1.0 / sum?
Решение: применяйте математические функции только там, где они нужны.
Ошибка 10. Незнание языка
И опять проблемы с математикой:
1. Путаница с типами. Использование long long для индексов пикселей вместо int, постоянные преобразования между float, double и int. Например, зачем писать (float)(1.0 / 16), когда можно написать 1.0f / 16.0f?
2. Вычисление полярного угла через возню с atan и проблемой с делением на ноль вместо использования atan2, которая делает именно то, что надо.
3. Необычная экспонента и магические константы:
g=(float)Math.pow(2.71,-(d*d)/(2*sigma*sigma));
t=((float)1/((float)Math.sqrt(6.28)*sigma));Здесь студент просто забыл про существование функции exp и константы pi. А вместо (float)1 можно просто написать 1.0f.
Решение: программируйте больше, только так вы наберётесь опыта.
Ошибка 11. Обфускация кода
Начинающие программисты любят показать своё мастерство, предпочитая писать короткий код, а не понятный.
1. Сложные циклы
for (int x1 = x - 1, x2 = 0; x1 <= x + 1; x1++, x2++)
{
for (int y1 = y - 1, y2 = 0; y1 <= y + 1; y1++, y2++)
{Здесь правильно было бы сделать цикл от -1 до 1, а x1 и x2 вычислять уже внутри цикла, ну и порядок поменять:
for (int j = -1; j <= 1; j++)
{
int y1 = y + j, y2 = j + 1;
for (int i = -1; i <= 1; i++)
{
int x1 = x + i, x2 = i + 1;Получилось бы даже быстрее за счёт того, что компиляторы легко оптимизируют простые циклы.
2. Крутые функции
long long ksize = llround(fma(ceil(3 * sigma), 2, 1)), rad = ksize >> 1;А нормальные люди просто напишут
int rad = (int)(3.0f * sigma);
int ksize = 2 * rad + 1;А это вообще за гранью добра и зла:
kernel[idx] = exp(ldexp(-pow(_sigma * (rad - idx), 2), -1));Для тех, кто не понял: ldexp(x, -1) — это просто деление на 2.
Решение: просто помните, что рано или поздно вам отобьют пальцы молотком за такой код.
Ошибка 12. Порча значений обрабатываемых изображений
Вот кусок кода из подавления немаксимумов, являющегося частью алгоритма Канни:
for x in xrange(grad.shape[0]):
for y in xrange(grad.shape[1]):
if ((angle[x, y] == 0) and ((grad[x, y] <= grad[getinds(grad, x + 1, y)])
or (grad[x, y] <= grad[getinds(grad, x - 1, y)]))) or ((angle[x, y] == 0.25) and ((grad[x, y] <= grad[getinds(grad, x + 1, y + 1)])
or (grad[x, y] <= grad[getinds(grad, x - 1, y - 1)]))) or ((angle[x, y] == 0.5) and ((grad[x, y] <= grad[getinds(grad, x, y + 1)])
or (grad[x, y] <= grad[getinds(grad, x, y - 1)]))) or ((angle[x, y] == 0.75) and ((grad[x, y] <= grad[getinds(grad, x + 1, y - 1)])
or (grad[x, y] <= grad[getinds(grad, x - 1, y + 1)]))):
grad[x, y] = 0Здесь некоторые значения зануляются grad[x, y] = 0, а на последующих итерациях циклах к ним происходит обращение. Ошибка бы не произошла, если бы для вычисления промежуточного результата создавалось новое изображение, а не перезаписывалось текущее.
Решение: не стремитесь экономить память раньше времени, подумайте о функциональной парадигме.
Остальные ошибки
Остальные ошибки уже имеют непрограммистский характер. Это ошибки в реализации алгоритмов вследствие их непонимания, они индивидуальны. Например, неверный выбор размера ядра для фильтра Гаусса.
Фильтр Гаусса — один из основных фильтров в обработке изображений. Он лежит в основе огромного числа алгоритмов: детектирование контуров (edges) и хребтов (ridges), поиск ключевых точек, повышение резкости и т.д. Фильтр Гаусса имеет параметр «сигма», определяющий уровень размытия, его ядро описывается формулой:
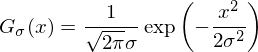
а график имеет вид:
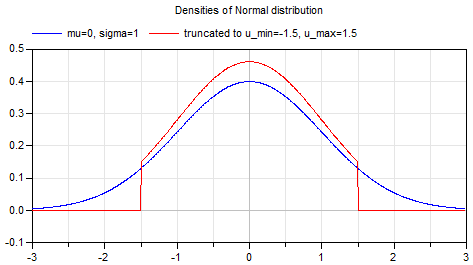
Данная функция нигде не обращается в ноль, а свёртка с ядром бесконечного размера не имеет смысла. Поэтому размер ядра выбирается таким, чтобы ошибка была ничтожно мала. Для практических задач достаточно взять ядро с радиусом (int)(3 * sigma) — ошибка будет меньше 1/1000. Выбор слишком маленького ядра (красная функция на графике выше) приведёт к искажению фильтра Гаусса. Использование ядра фиксированного размера, например, 5х5 и приводит к некорректным результатам уже при sigma = 1.5.
Итог: общие рекомендации для начинающих работать с изображениями
- Не используйте системные объекты Bitmap, HBITMAP и им подобные.
- Прежде, чем использовать библиотеки для работы с изображениями, начните с написания велосипедов, а уже затем бросайтесь в бой.
- Используйте тип float для хранения значений пикселей, если типа byte не хватает для хранения значений пикселей как по точности, так и по диапазону. А набравшись опыта, вы сможете использовать арифметику с фиксированной точкой и добиться максимальной эффективности.
- При преобразовании из float в byte помните об ошибках округления и выход за границы типа.
- Помните об отрицательных значениях.
- Совершайте обход по пикселям изображения в правильном порядке.
- Тщательно тестируйте код.
- Не бойтесь плодить сущности. Код должен быть понятным.
- Используйте математические операции с умом.
- Учите язык.
- Не пытайтесь показать мастерство.
- Читайте учебники по обработке изображений — там много всего полезного пишут.
Для облегчения написания программ я создал проекты, в которых уже реализовано чтение и запись изображений, созданы классы для хранения изображений с минимально возможным функционалом и приведён пример операции над изображениями:
> Visual Studio 2015, C++
> Visual Studio 2015, C#
Версий под Linux нет — студенты, использующие Linux, обычно не испытывают проблем с такими вещами.
Ну и на закуску — просто картинки.
Выделение контуров с помощью алгоритма Канни. Слева вверху — входное изображение, второе слева — правильный результат, остальное — ошибочные результаты.
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Увеличение с помощью бикубической интерполяции.
 |
 |
 |
 |
 |
Комментарии (99)
lookid
16.01.2017 13:17+1Как-то в перемешку. Можно было бы разбить на:
1) Работа с цветом. Преобразование RGBA ARGB в long/int, и обратно. Упаковка, распаковка. Путаница в размерах базовых типов.
2) Отказ он единообразия в плавающей точке. Мешанина float double, а не только float (например)
3) Ошибки кодирования. Не проверка границ массива, циклы итератором со знаковым типом вместо size_t. Краши.
4) С-каст вместо static_cast
5) Округление через int, а не floor, ceil (осмысленное).
6) Путаница [i][j] и [j][i]DistortNeo
16.01.2017 13:351) У студентов нет необходимости с этим возиться, к счастью.
2) Хотя это и не влияет на работоспособность алгоритмов, согласен, можно считать ошибкой.
3) Это уже неспецифичные для обработки изображений вещи.
4) Ну если и за такое драть, то вообще никто в итоге задания не сдаст.
5) Чем округление черезintплохо, когда аргумент положительный? Ведьfloorвозвращает вещественное число, которое нужно затем снова преобразовывать кint. К сожалению, в C++ это делается неявно.
6) см. ошибку номер 7.
Idot
16.01.2017 13:25Увеличение с помощью бикубической интерполяции.
Можно пояснить, что где на картинке с крышей дома?DistortNeo
16.01.2017 13:38Можно пояснить, что где на картинке с крышей дома?
Эталон + 4 ошибочные реализации, связанные с неверным вычислением коэффициентов из-за переусложнённого кода или неправильным выбором пикселей из-за ошибок, связанных с бездумным использованием
ceil.

SADKO
16.01.2017 13:31+4Подписываюсь почти под всем, проблема реальна, и даже не со студентами а с реальными сеньорами из крутых азиатских компаний имена которых у всех на слуху.
ИМХО беда в слишком «инженерном подходе», без попытки как-либо вникнуть в смысл происходящего и пользоваться, порядком подзабытым, элементарным математическим аппаратом. (как в примере с бикубической интерполяцией, я такого повидал не мало, правда в вещах более сложных, но и авторы там были отнюдь не студенты)
Однако в этом же аспекте, float не всегда панацея, там своя специфика ошибок о которых нужно знать\помнить (в ряде случаев это вообще ограничивает применение float ), а стремление к рациональному использованию памяти и оптимизации быстродействия оно более чем похвально, но именно в том случае когда вы отдаёте себе отчёт в том что делаете и зачем. (грамотная бинаризация, требует хорошего математического кругозора, и ИМХО велосипедостроение в этой области весьма полезно, по крайней мере для меня)
Операторы преобразования изображений, часто воспринимаются как некие аналоговые функциональные блоки, которые разработчик тупо коммутирует между собой, вместо того что бы выписать на бумажку и попробовать про решать, ибо здесь оптимизация именно так и делается.

onyxmaster
16.01.2017 13:38+1Я хочу ещё отметить, что существенное количество алгоритмов предназначено для работы с линейными (а не гамма-скорректированными, что является вариантом по умолчанию) значениями цвета или вовсе не предназначено для модели RGB.
А ещё есть цветовые профили, и всякие штуки типа low-light sRGB.DistortNeo
16.01.2017 13:40Конечно, у нас даже целый спецкурс посвящён этому. Но на практике с таким обычно редко сталкиваешься.
onyxmaster
16.01.2017 13:48Да, но когда человек берёт «в руки», грубо говоря, ImageMagick (то ещё решето, после известных дыр его только в сэндбоксе и запускать), и начинает им масштабировать картинку с почти любым не-nearest neighbour фильтром (хоть spline-based, например Catmull-Rom, хоть sinc-based, например Lanczos), то он уже совершает ошибку =)
Судя по тому, что «пишут в интернете» люди вообще не заморачиваются с отличением хотя бы device-dependent и device-independent цветов, а это весьма существенная проблема.
Мне очень хотелось бы, чтобы кто-нибудь развеял эти неприятные стереотипы, думаю статья об этом был бы _очень_ полезной.SADKO
16.01.2017 15:55Это ещё что, а вот ошибки в устройствах которые за не малую денежку покупаются…

dom1n1k
17.01.2017 01:32-1Что такое low-light sRGB?
onyxmaster
18.01.2017 23:11Существенное количество людей считает, что sRGB имеет гамму 2.2 (или 2.24). Это не так, степень там 2.4, но для имитации особенностей человеческого зрения, для тёмных цветов (low-light) используется линейная шкала. То есть на самом деле часть функции это просто линейная функция, а часть — степенная.
dom1n1k
19.01.2017 00:05То, что функция srgb-гаммы состоит из 2 частей — не секрет, но я нигде не видел такого термина и не гуглится он.
И линейный участок там не для имитации чего-либо, а просто чтобы привести функцию в ноль (степенной участок через ноль не проходит). То есть это такой небольшой чисто технический костылик.
DrZlodberg
16.01.2017 13:44+23. Иногда достаточно использовать uint16. Экономия памяти в 2 раза по сравнению с float, потери сильно меньше, чем с uint8. Если важен знак — int16
п.1 и п.8.1 противоречат друг другу. Когда привыкают использовать абстракции — используют их везде. Привыкают работать с массивом — перестают видеть смысл в лишних абстракциях.
7. При работ с абстракциями их трудно перепутать. И как можно получить переполнение при путанице индексов на прямоугольном массиве? Разве что перепутать и координаты и размеры одновременно. Но это уже надо постараться.
8.2 решается (для uint8) либо 3д массивом, либо 3мя цветовыми плоскостями, либо хранением RGBA в виде uint32. Во всех случаях никакого копипаста не нужно, достаточно подставить нужный индекс.
8.3 прекрасно решают макросы без создания лишних сущностей. И ничего не мешает кроме массива хранить структуру с его описанием.
8.4 непонятно. Обычно порядок стандартный, RGB(A). При чём тут vx и vy?
8.5 использование массива вместо структуры. Смысл тут городить лишний класс?
Решение. Видел результаты такого обучения. Человек городит классы из классов из классов с кучей именованных констант. Всё это странным образом взаимодействует чтобы в итоге показать MessageBox одного из 4х типов сообщений.DistortNeo
16.01.2017 14:023.Иногда достаточно использовать uint16. Экономия памяти в 2 раза по сравнению с float, потери сильно меньше, чем с uint8. Если важен знак — int16
Преждевременная оптимизация — зло.
Привыкают работать с массивом — перестают видеть смысл в лишних абстракциях.
И в итоге городят малочитаемый код.
7.При работ с абстракциями их трудно перепутать. И как можно получить переполнение при путанице индексов на прямоугольном массиве? Разве что перепутать и координаты и размеры одновременно. Но это уже надо постараться.
Легко. Например, когда изображение бьётся на квадратные блоки, и каждый блок обрабатывается независимо. Просто банально перепутанные индексы.
8.2 решается (для uint8) либо 3д массивом, либо 3мя цветовыми плоскостями, либо хранением RGBA в виде uint32. Во всех случаях никакого копипаста не нужно, достаточно подставить нужный индекс.
К сожалению, не решается. Любой нетривиальный алгоритм анализа изображений потребует использования вещественных значений.
8.3 прекрасно решают макросы без создания лишних сущностей. И ничего не мешает кроме массива хранить структуру с его описанием.
Зачем с современным C++ использовать макросы? Лишний класс не вызовет проблем, в отличие от макросов.
8.4 непонятно. Обычно порядок стандартный, RGB(A). При чём тут vx и vy?
Представьте себе, изображения бывают разные. Бывают изображения, где каждый пиксель — это не RGB, а какое-нибудь ROYGBP (мультиспектральные аэрокосмические изображения), либо комплексное число (результат преобразования Фурье), либо двумерный или трёхмерный вектор, либо вообще тензор (матрица 3х3).
8.5 использование массива вместо структуры. Смысл тут городить лишний класс?
Потому что изображения
Image<VectorXY>иImage<VectorRPhi>— это разные изображения, хотя и имеют идентичное представление в памяти. Это позволяет избежать путаницы и не допускать ошибок за счёт строгой типизации.
Видел результаты такого обучения. Человек городит классы из классов из классов с кучей именованных констант.
Сходите по ссылкам на проекты. Там простые классы-обёртки над куском памяти, ничего более сложного изобретать не нужно.
DrZlodberg
16.01.2017 15:07+3И в итоге городят малочитаемый код.
Его прекрасно можно городить и с абстракциями. А с массивами прекрасно можно писать читаемый. Не стоит считать это панацеей.
К сожалению, не решается. Любой нетривиальный алгоритм анализа изображений потребует использования вещественных значений.
Решается, поскольку первые 2 пункта безразличны к типу данных. Разве что он(тип) должен иметь константный размер.
Зачем с современным C++ использовать макросы? Лишний класс не вызовет проблем, в отличие от макросов.
Если макросы не переопределять где попало — проблем они обычно не вызывают. Ради возможности ставить индексы в «красивом» порядке вводить класс смысла нет. Зато приучает именно это и делать по любому поводу.
Представьте себе, изображения бывают разные. Бывают изображения, где каждый пиксель — это не RGB, а какое-нибудь ROYGBP (мультиспектральные аэрокосмические изображения), либо комплексное число (результат преобразования Фурье), либо двумерный или трёхмерный вектор, либо вообще тензор (матрица 3х3).
Ок, меня смутил термин «цветные изображения». Однако что мешает хранить любое количество компонент в 3х мерном массиве либо наборе 2х-мерных, либо в 2хмерном в виде структур по прежнему непонятно.
Потому что изображения Image<VectorXY> и Image<VectorRPhi> — это разные изображения, хотя и имеют идентичное представление в памяти. Это позволяет избежать путаницы и не допускать ошибок за счёт строгой типизации.
При чём тут изображение? В приведённом примере (на сколько я понял) просто возвращают набор величин в виде массива. Точно так же можно вернуть структуру или объект с бессмысленными именами. Для проверки типа достаточно и структуры.
Shadow_ru
16.01.2017 16:07| Точно так же можно вернуть структуру или объект с бессмысленными именами.
Нереально. Люди очень редко пишут поля вида b1, b2, и отучаются на раз-два. А в массив через невменяемые переменные напихать — почему то стандартно, плюс — сложно отслеживать.DrZlodberg
16.01.2017 18:37Ещё как пишут. Т.е. для себя называют нормально, каким-нибудь сокращением. Но для постороннего человека порой бывает не сильно лучше. А вот с массивом варианта не видел ни разу. Хотя навскидку можно использовать именованные индексы. Сам для работы с 3Д массивом (2Д * кучу параметров) использовал когда-то такой вариант. Не структуру из-за однотипных данных.
DistortNeo
16.01.2017 16:24Его прекрасно можно городить и с абстракциями. А с массивами прекрасно можно писать читаемый. Не стоит считать это панацеей.
Вот только в C++ нет двумерных прямоугольных массивов динамического размера. Абстракцию все равно придётся использовать и будет лучше, если это будет специальный класс для изображений, а не просто массив.
Если макросы не переопределять где попало — проблем они обычно не вызывают.
Отказ от макросов-объектов и макросов-функций в пользу конструкций языка, не связанных с этапом предварительной обработки, уменьшает вероятность появления ошибок и даёт возможность использования отладчика.
Впрочем, холивар на тему макросов продолжать не вижу смысла.
Ради возможности ставить индексы в «красивом» порядке вводить класс смысла нет.
Да, ради этого и имеет смысл вводить отдельный класс. А ещё — для функциональных объектов, когда обращение getPixel(x, y) является не прямым доступом к памяти, а некоторой функцией, например, суммой пикселей двух изображений.
Однако что мешает хранить любое количество компонент в 3х мерном массиве либо наборе 2х-мерных, либо в 2хмерном в виде структур по прежнему непонятно
Ничего не мешает. Но структура всегда предпочтительнее массива.
DrZlodberg
16.01.2017 19:00Вот только в C++ нет двумерных прямоугольных массивов динамического размера. Абстракцию все равно придётся использовать и будет лучше, если это будет специальный класс для изображений, а не просто массив.
По факту это всё равно будет массив. И менять размер внутри он будет точно так-же, как это пришлось бы делать снаружи. Одна функция прекрасно справится с изменением размера любого массива на любой. Вместо кучи для каждого класса.
Да, ради этого и имеет смысл вводить отдельный класс. А ещё — для функциональных объектов, когда обращение getPixel(x, y) является не прямым доступом к памяти, а некоторой функцией, например, суммой пикселей двух изображений.
Это уже навороты, о которых речи не было. Таким образом задачу можно усложнять до бесконечности, пока оппонент не сдастся. Однако не вижу принципиальной разницы между getpixel(x,y) и getpixel(x,y,img1)+getpixel(x,y,img2) Не считая того, что во втором случае мы
1. точно знаем, что это на самом деле не пиксел (название вводит в заблуждение) а их сумма, и каких именно.
2. не надо писать отдельный класс для реализации такого поведения. потому как в простом родительском оно вряд-ли будет столь странным. Объекты провоцируют рост количества абстракций.
Ничего не мешает. Но структура всегда предпочтительнее массива.
Т.е. писать
image2().b =
image2().g =
image2().r =
более удобно, чем
interpolate(r_idx);
interpolate(g_idx);
interpolate(b_idx);
И тут вы решили ещё альфу добавить…
У нас, видимо, очень разные понятия об удобстве. Для большого количества однотипных данных нет ничего удобнее массива.DistortNeo
16.01.2017 19:24По факту это всё равно будет массив. И менять размер внутри он будет точно так-же, как это пришлось бы делать снаружи.
По факту есть ещё особенности хранения данных: выравнивание строк по границе 32 байт (для AVX), выравнивание размера пикселей кратно ближайшей степени двойки.
Т.е. писать… более удобно, чем
Да. Вот только надо писать не
image2(x, y).b = ...; image2(x, y).g = ...; image2(x, y).b = ...;
а
image2(x, y) = color4f(..., ..., ...);
Потому что в подавляющем большинстве случаев обработка ведётся на уровне пикселей, а не на уровне независимых компонент. Да и вообще, чаще всего изображения однокомпонентны.
DrZlodberg
16.01.2017 19:35image2(x, y) = color4f(..., ..., ...);
Пардоньте, а как вы собрались это писать для примера с бикубической интерполяцией (код взят оттуда). Каждая цветовая компонента там обрабатывается независимо, если не ошибаюсь. Да и все цветовые фильтры работают с раздельными компонентами. В том числе и не раз упоминаемый тут Гаусс. Обработка «на уровне пикселей» идёт обычно только для монохромных (там просто разницы нет) изображений или при рисовании. Вариант с использованием раздельных компонент же универсален. Без лишних телодвижений.
Да и вообще, чаще всего изображения однокомпонентны.
Вы же чуть раньше приводили кучу примеров хитрых многокомпонентных изображений. Да и в статье речь о цветных везде, что подразумевает наличие хотя бы 3х компонент.DistortNeo
16.01.2017 19:45Каждая цветовая компонента там обрабатывается независимо, если не ошибаюсь
К каждой компоненте применяется одна и та же операция. Здесь с пикселем надо работать как с вектором значений.
Например, фильтр (в т.ч. фильтр Гаусса) можно реализовать следующим образом:
Код C++template <typename SourcePixelType, class SourceImageType, typename DestinationPixelType, class DestinationImageType, typename FilterPixelType> void FilterHorizontal(const ImageReadable<SourcePixelType, SourceImageType> &src, ImageWritable<DestinationPixelType, DestinationImageType> &dst, FilterPixelType *filter, int filter_len, int filter_center) { check(src.Width() == dst.Width() && src.Height() == dst.Height()); check(filter_len <= src.Width()); for (int j = 0; j < src.Height(); j++) { for (int i = filter_center; i < filter_len; i++) { DestinationPixelType s = DestinationPixelType(); for (int k = 0; k < filter_len /* i */; k++) s += src((std::max)(i - k, 0), j) * filter[k]; dst(i - filter_center, j) = s; } for (int i = filter_len; i < src.Width(); i++) { DestinationPixelType s = DestinationPixelType(); for (int k = 0; k < filter_len; k++) s += src(i - k, j) * filter[k]; dst(i - filter_center, j) = s; } for (int i = 0; i < filter_center; i++) { DestinationPixelType s = DestinationPixelType(); for (int k = 0 /* i + 1 */; k < filter_len; k++) s += src(src.Width() + (std::min)(i - k, -1), j) * filter[k]; dst(src.Width() + i - filter_center, j) = s; } } }DrZlodberg
16.01.2017 20:08Придётся 3 раза читать треть изображения. Если хранить компоненты раздельно. При этом компоненты хранятся более компактно, что может дать бонус (а может и нет) на лучшем кэшировании. Ну и позволяет легче добавлять/убирать компоненты. Попробуйте в свой вариант добавить альфа-канал в рантайме без пересоздания и копирования изображений в новый формат. И дублирования всего кода, поскольку под новый формат будет создан новый код по этому шаблону.
DistortNeo
16.01.2017 20:27Придётся 3 раза читать треть изображения
Зато когда нужно получить все три компоненты сразу, приходится читать сразу из трёх мест. Например, перевести изображение из RGB в YUV. Непоследовательный доступ к памяти — это нехорошо.
Ну и позволяет легче добавлять/убирать компоненты. Попробуйте в свой вариант добавить альфа-канал в рантайме без пересоздания и копирования изображений в новый формат.
Именно в рантайме? Да легко:
Вот кодclass ImageRGB_WithAlpha { private: ImageRGB &rgb; ImageFloat α public: ImageRGB_WithAlpha(ImageRGB &rgb, ImageFloat &alpha) : rgb(rgb), alpha(alpha) {} ColorRGBA GetPixel(int x, int y) const { ColorRGB crgb = rgb(x, y); return ColorRGBA(crgb.b, crgb.g, crgb.r, alpha(x, y)); } }DrZlodberg
16.01.2017 20:57Например, перевести изображение из RGB в YUV
И часто в работе возникает такая задача. Не в общем, а в процессе конкретной? Обычно конвертируют до обработки и после, для сохраннения. Т.е. задача единичная и потери на неё в общем случае не существенны. Единственный вариант — редактор где придётся постоянно демонстрировать картинку. Но там вообще обычно показывают кешированную превью уменьшенного размера, которая живёт своей отдельной жизнью.
Именно в рантайме? Да легко:
Угу, Отдельный класс под простую задачу. Масочку добавить — ещё класс? CMYK вдруг захотелось — ещё один? А альфу размыть если? Вроде про «плодить сущности» я уже писал.
Compiler option: Favor fast code
При чём тут fast? Я говорил про избыток и дублирование кода, а не про недостаток скорости. Кстати «быстрая» оптимизация количество кода как раз ещё больше увеличивает за счёт раскрытия циклов и прочего.DistortNeo
16.01.2017 21:11И часто в работе возникает такая задача
Довольно-таки, а точнее, вычисление Y, его обработка и применение полученных результатов к RGB-пикселям. Пример: направленное увеличение изображений, повышение резкости, когда коэффициенты вычисляются по Y, а применяются ко всем компонентам.
Вроде про «плодить сущности» я уже писал.
Не бойтесь сущностей, они не кусаются.
Я говорил про избыток и дублирование кода
Вот как раз с шаблонами дублирования исходного кода нет. Ну а то, что каждое инстанцирование шаблона приводит к генерации бинарного кода — для того шаблоны и задумывались.
DrZlodberg
16.01.2017 21:46Не бойтесь сущностей, они не кусаются.
Видимо вы не имели дел с запущенными случаями. А когда это входит в привычку до «запущенного» дойти не сложно. Кстати как раз недавние студенты этим очень страдают. Точнее страдают те, кому приходится потом иметь с этим дело.
Ну а то, что каждое инстанцирование шаблона приводит к генерации бинарного кода — для того шаблоны и задумывались.
Я как раз это и имел ввиду. Хотя сейчас 50 мегабайт для программы уже не размер. Даже многомегабайтные «вирусы» никого не удивляют. И это печально.

homm
17.01.2017 03:56выравнивание строк по границе 32 байт (для AVX)
Это не актуально начиная Sandy Bridge (как раз когда и появился AVX). Единственная разница — не выровненные данные имеют шанс занять две линейки кеша, но это не очень актуально, если обработка идет последовательно.
DistortNeo
17.01.2017 04:20Странно, потому что у меня Sandy Bridge, и разница между VMOVAPS и VMOVUPS есть и довольно заметна.
homm
17.01.2017 04:28Сколько я не экспериментировал на эту тему (на предыдущем компе с Sandy Bridge и на нынешнем с Haswell), единственная разница, которую я смог обнаружить — невыровненные функции были на пару процентов быстрее с любым выравниванием данных.
А можете накидать код с интринсиками?DistortNeo
17.01.2017 04:43Так вот же, в соседнем комментарии:
https://gist.github.com/e673/ded24a3cf958f55a6d5a63785d52ed12
Если начать менять _mm256_loadu_ps на _mm256_load_ps, время выполнения цикла начнёт меняться: при выровненном доступе (таких мест 3) оно уменьшится, а при невыровненном (таких мест 6) увеличится — раньше же кидалось исключение. Т.е. от VMOVAPS действительно есть выигрыш по сравнению с VMOVUPS, если данные действительно выровнены.
homm
17.01.2017 05:05К сожалению, я не знаю C++ (только C) и не смогу сходу запустить ваш проект под gcc. Но мой опыт был такой на обоих процессорах:
_mm_load_всегда бросает исключение при попытке доступа к не выровненной памяти. (сейчас еще раз проверил, верно и для_mm_load_и для_mm256_load_).- для
_mm_loadu_нет разницы в выравнивании, она работает за одинаковое время. _mm_loadu_работает с любыми данными чуть-чуть быстрее чем_mm_load_.- Как следствие, я всегда использовал
_mm_loadu_и не заморачивался с выравниванием. Это был самый быстры вариант.
Возможно, есть разница между AVX и SSE на Sandy Bridge и уже нет Haswell. Возможно на i3 и i7 другое поведение, у меня i5.

ErmIg
17.01.2017 11:53Померял влияние наличия выравнивания на Haswell при помощи тестов встроенных в https://github.com/ermig1979/Simd. Получилось, что в среднем по больнице, варавнивание дает где-то 6-7%. По отдельным алгоритмам разброс достаточно большой (от 0 до 40%). Хотя здесь в случае выровненных данных используется (_mm_load_ или _mm256_load_) иначе — (_mm_loadu_ или _mm256_loadu_). Так что не совсем ясно какая доля из этих 6% получается за счет использования специальных инструкций, а что за счет выравнивания памяти.
P.S. На более древних процессорах выигрыш от выравнивания в среднем был порядка 20-30%. А допустим, на PowerPC, так вообще более 50%.
ErmIg
16.01.2017 13:50+2Я бы еще обязятельно добавил, что width != row_size — многие реализации алгоритмов страдают этим багом.
DistortNeo
16.01.2017 14:10Не видел такого у начинающих студентов. Видимо, они не используют row_size.
onyxmaster
16.01.2017 13:52uint16 может очень сильно терять точность при повторении нескольких преобразований по цепочке. Если учесть, что для существенного количества алгоритмов нужна схема pow(f(pow(x, 1/gamma)),gamma), то получаемая потеря точности может сильно повлиять на результат из-за накопления ошибки и округлений, особенно если один из алгоритмов рассчитывает локальную производную методом сэмплирования (например, при генерации карт нормалей или edge detection).
MrGobus
16.01.2017 14:01После фразы
Лишь немногие студенты догадались, что бикубическая интерполяция сепарабельна
меня посетила мысль, что было бы неплохо увидеть ряд статей по алгоритмам обработки графики и их реализации в вашем исполнении.dom1n1k
16.01.2017 17:52+1Я не копал эту тему очень уж глубоко, но вроде бы раздельный вариант бикубической интерпоряции в общем случае всё-таки не тождественнен 2d.
DistortNeo
16.01.2017 19:25Тождественен.
Ядро интерполяции будет иметь вид:
K(x,y) = K(x)*K(y)homm
17.01.2017 03:01Тождественен в случае непрерывных функций. В случае дискретных нет.
Как раз поэтому в том же ImageMagick есть distort, который дает совсем другие результаты в некоторых случаях. Но на практике это конечно редко используется, слишко заманчиво получить O(2n) вместо O(n?).
homm
17.01.2017 04:03Если интересно подробнее, то вот результат уменьшения этой картинки бикубиком до 320?213 традиционным методом и честным:


Думаю, без пояснений понятно, где какое. Если честно, даже не ожидал, что разница будет настолько сильной.
Все эти люди, которые приходят в каждый топик про изображения и напоминают про sRGB и линейное цветовое пространство теперь мне кажутся немного странными: соринку они заметили, а бревна не видят.DistortNeo
17.01.2017 04:27Вот и ещё одна тема для статьи подобралась: "Как правильно уменьшать изображения, или почему бикубическую интерполяцию лучше не использовать для уменьшения". А всё дело в алиасинге.
homm
17.01.2017 05:23Вы не совсем по теме моего утверждения ответили. Я говорю, что ресемплинг в два прохода имеет существенное отличие от однопроходного.
бикубическую интерполяцию лучше не использовать для уменьшения
С удовольствием почитаю. Что бы вы посоветовали вместо него? С Ланцошем, например, алиасинг еще сильнее.
DistortNeo
17.01.2017 05:35Потому что сначала нужно применить фильтр низких частот. Лучше всего использовать фильтр Гаусса со следующим параметром:

где
s— коэффициент уменьшения.
Объяснение, почему нужно использовать именно этот фильтр, есть в методичке, страницы 24-25.
homm
17.01.2017 14:27Потому что сначала нужно
Уточните пожалуйста, нужно для чего и сначала — это перед чем?
Я получил такой результат для бикубика и Ланцоша: пространственная свертка с предварительным блюром почти неотличима от линейной двухпроходной свертки.
Так что я делаю вывод, что вы хотели сказать «чтобы результаты пространственной и линейных сверток совпали, перед пространственной нужно применить фильтр низких частот». Так?
DistortNeo
17.01.2017 14:55Перед применением интерполяционного фильтра. Свёртка с Гауссом убирает высокие частоты, которые при уменьшении частоты дискретизации не могут сохраниться на изображении и вызывают алиасинг.
onyxmaster
17.01.2017 08:59"Эти люди" просто предпочитают сначала починить базовый случай неправильного применения алгоритмов, а потом учитывать частные случаи. Масштабирование изображений это, хотя и, скорее всего, самое популярное преобразование, но не единственное, а вот игнорирование правильной работы с цветом происходит повсеместно :)
VioletGiraffe
18.01.2017 11:46Доктор, что делать? Я не вижу разницы!
homm
18.01.2017 14:40Например, открыть в соседних вкладках браузера и переключать между ними. Или открыть в графическом редакторе с режимом наложения difference.

Shultc
19.01.2017 17:06«Найти» разницу то можно, если она есть. Но я её, как вы заявляли выше, не вижу невооружённым глазом. И я тут, явно, далеко не один.
Пожалуйста, когда приводите примеры для сравнения, пишите не «это и ежу понятно», а пишите, что именно по-вашему должно быть понятно ежу.homm
19.01.2017 17:58Но я её, как вы заявляли выше, не вижу невооружённым глазом
А я вижу. И не смотря на ехидный тон спрашивающего, написал выше, что нужно сделать тем, кто не видит. У вас все равно не получилось?
что именно по-вашему должно быть понятно ежу
По моему мнению ежу должно быть понятно, что результат этих двух методов сильно различается, что я и написал.
DistortNeo
19.01.2017 18:41Я тоже разницу не увидел, пока не открыл в графическом редакторе и не попереключал слои.
Разница видна, когда знаешь, где её искать.
IliaSafonov
16.01.2017 17:11+1Спасибо! Важную тему подняли. Более 15 лет преподаю студентам обработку изображений. В принципе, согласен с перечисленными типичными ошибками и почти всеми рекомендациями. Однако, я призываю студентов отказываться от вычислений во float/double везде, где это целесообразно. Иначе у студентов укореняется привычка использовать только float, а до оптимизации дело никогда не доходит. Наоборот, развивается боязнь оптимизации. Преждевременная оптимизация это часто вредно, но и отсутствие умения оптимизировать тоже не хорошо.
скорость работы современных процессоров с вещественными числами такая же быстрая, как и с целыми
студентами хорошо бы понимать, что современные процессоры бывают очень разные. Бывают DSP, бывают для embedded. Для них картина может быть не такой радужной. К тому же справедливо замечено, что узким местом является обращение к памяти, а unsigned char, как не крути, в четыре раза меньше чем float.Лишь немногие студенты догадались, что бикубическая интерполяция сепарабельна
Строго говоря, не сепарабельна, а реализуется с помощью 5 одномерных интерполяций cubic convolution. Подобный приведенному в посте код я тоже видел много раз. Это потому, что в Википедии в статье про бикубическую интерполяцию написаны такие формулы. Согласен с предложением, написанным выше, может помочь делать посты с «правильным» описанием даже таких простых алгоритмов.DistortNeo
16.01.2017 20:14+1Бывают DSP, бывают для embedded
А бывают GPU, которые, наоборот, имеют очень быструю память и заточены под работу с float.
Задачи тоже бывают разные: конкретно в нашем случае — это разработка суровых математических алгоритмов по обработке изображений. Именно разработка алгоритмов, а не их программная реализация в железках. Соответственно, для нас важнее надёжность работы алгоритма, чем более высокие быстродействие с риском снижения точности и выходом за диапазон значений пикселя.
К тому же справедливо замечено, что узким местом является обращение к памяти, а unsigned char, как не крути, в четыре раза меньше чем float.
Зависит от реализации. Если это обычный однопоточный код, то никакой разницы не будет. А если векторизованный многопоточный, то приходится бороться за каждое обращение к памяти. Вот тогда и приходится опускаться с float до int16 и uint8.
Согласен с предложением, написанным выше, может помочь делать посты с «правильным» описанием даже таких простых алгоритмов.
Постараюсь написать — видимо, бикубик людям интересен.
IliaSafonov
16.01.2017 22:35Если это обычный однопоточный код, то никакой разницы не будет.
Можете пример показать с замерами времени для release с включенной оптимизацией? Что-то сомневаюсь я в правильности данного утверждения.DistortNeo
17.01.2017 00:15+1Да, могу. Вот, написал:
https://gist.github.com/e673/ded24a3cf958f55a6d5a63785d52ed12
Здесь реализован метод размытия изображения с окном 3х3
Результаты измеренийMSVC, x86 — compilation error С2719 — у меня __m256 в параметрах функций местами сидит (такой проблемы нет в x64, где параметры передаются через стек).
Intel Compiler, x86, Release, Full Release:
float: 307 us
byte: 750 us
float sse: 215 us
float avx: 191 us
byte sse: 126 us
MSVC, x64, Full Release:
float: 586 us
byte: 452 us
float sse: 211 us
float avx: 210 us
byte sse: 106 us
Intel Compiler, x64, Release:
float: 621 us
byte: 409 us
float sse: 216 us
float avx: 188 us
byte sse: 107 us
Intel Compiler, x64, Full Release:
float: 191 us
byte: 407 us
float sse: 213 us
float avx: 190 us
byte sse: 102 us
Отличие Release от Full Release лишь в небольшом количестве флагов — в Full Release включена более агрессивная оптимизация.
homm
17.01.2017 03:09В целом byte получается чуть быстрее float
Теперь было правильно исправить неверное утверждение в статье.
Компилятор C++ с удовольствием автоматически векторизует работу с float
Более верная формулировка: компилятор C++ от Intel в режимеFull Release векторизует работу с float, а с byte почему-то нет. Другой компилятор может поступить по-другому, в том числе полностью наоборот.
IliaSafonov
17.01.2017 09:26Спасибо за очень подробные и более чем показательные результаты скорости обработки!
Здесь реализован метод размытия изображения с окном 3х3. В целом byte получается чуть быстрее float.
Возьмем ядро свертки / окно больше, и преимущество byte получится значительнее.
Вы считаете, что следует учить студентов избегать возможных ошибок, связанных с переполнением и потерей точности, путем использования float. При этом больше внимания уделяете чему-то другому. OK, нормальная понятная позиция.
Я считаю, что надо дать студентам в процессе обучения возможность делать такого рода ошибки, чтобы указать на них, чтобы научиться понимать их причину и сознательно устранять. Давайте согласимся, что такая позиция также имеет право на существование.DistortNeo
17.01.2017 16:51Если есть возможность снизить вероятность ошибок и уменьшить время разработки, пусть и ценой более высокого потребления памяти и медленной работы, разве это плохо?
Я считаю, что надо дать студентам в процессе обучения возможность делать такого рода ошибки, чтобы указать на них, чтобы научиться понимать их причину и сознательно устранять.
Полностью согласен. Здесь проблема в "научиться понимать". Если подобные ошибки возникают в процессе решения какой-либо глобальной задачи, то студенты просто не понимают этого и не способны исправить в силу недостатка опыта.
IliaSafonov
17.01.2017 17:50+1разве это плохо?
Выше я написал: OK — это нормально.
Если дальше развивать мысль «уменьшить время разработки, пусть и ценой более высокого потребления памяти и медленной работы», то имеет смысл переходить на скриптовые языки Python, Matlab, etc…
Вы этого в своем курсе не делаете, т.к. ставите цель научить писать обработку изображений на C++/C#, в том числе «глобальные задачи». Я ставлю цель научить программировать (с элементами оптимизации) на С/С++ отдельные базовые функции обработки изображений. О «глобальных задачах» речь не идет.
Вы всегда рекомендуете использовать float для хранения пикселей. Я не рекомендую этого делать без необходимости, т.е. когда уже нельзя или сложно обойтись целочисленными типами без значительной потери точности.
Из немного разных целей курсов следуют немного разные рекомендации. Ваши, в целом правильные, рекомендации в разделе «Итог» апостулируются как абсолютно истинные для любого студента, изучающего обработку изображений, а это не совсем так.DistortNeo
17.01.2017 19:34Если дальше развивать мысль «уменьшить время разработки, пусть и ценой более высокого потребления памяти и медленной работы», то имеет смысл переходить на скриптовые языки Python, Matlab, etc…
Всё верно. Matlab — фактически стандарт для обмена научного кода, Python менее популярен в этой области.
Вы этого в своем курсе не делаете, т.к. ставите цель научить писать обработку изображений на C++/C#, в том числе «глобальные задачи». Я ставлю цель научить программировать (с элементами оптимизации) на С/С++ отдельные базовые функции обработки изображений. О «глобальных задачах» речь не идет.
Так и есть.
Вы всегда рекомендуете использовать float для хранения пикселей. Я не рекомендую этого делать без необходимости, т.е. когда уже нельзя или сложно обойтись целочисленными типами без значительной потери точности.
Ваш взгляд более инженерный. Разработка алгоритмов обработки изображений проходит два этапа:
Научный этап. На этом этапе производительность и экономия памяти не имеет существенного значения. Важно создать новый работающий алгоритм. Результатом работы на данном этапе являются научные статьи, отчёты, программный код на языках типа Matlab, Python, иногда C/C++, C#, Java.
- Инженерный этап. Здесь уже разработанный алгоритм оптимизируется по скорости и по памяти, анализируется возможность допущения неточностей и упрощений без существенной потери качества. Именно на этом этапе и создаётся конечный высокоэффективный программный код.
Проблема же заключается в том, что хороший учёный-математик редко бывает хорошим программистом, и наоборот. Поэтому разработкой и оптимизацией алгоритмов обычно занимаются разные люди.
Ну так как я работаю в университете, курс читается тоже в университете, то и цели преследую научные, а не инженерные.
IliaSafonov
17.01.2017 21:33Ну так как я работаю в университете, курс читается тоже в университете, то и цели преследую научные, а не инженерные.
Пардон, а все Ваши студенты после университета будут учёными. Вы курс для себя или для студентов читаете?
Поэтому разработкой и оптимизацией алгоритмов обычно занимаются разные люди.
В каком-то идеальном мире это так. Но я 15 лет работаю в Research подразделениях известных компаний и знаю буквально единичные примеры успешной оптимизации алгоритмов «другими людьми». Гораздо чаще ситуация такая: или алгоритм идет в корзину, или идет в production без изменений и оптимизации, или разработчик алгоритма сам оптимизирует код.DistortNeo
18.01.2017 00:46Пардон, а все Ваши студенты после университета будут учёными. Вы курс для себя или для студентов читаете?
Курс этот читается магистрам, т.е. тем, кто всё-таки решил связать себя хоть как-то с наукой. При этом, естественно, мы думаем и о себе — нам нужны люди, которые будут готовы заниматься наукой и дальше. Умение писать эффективный векторизованный код для нас менее важно, чем понимание, как работают алгоритмы и умение их реализовать.
Я считаю, что для обучения программированию университет не нужен. Нужна только практика и ничего больше. То, что люди поступают в университет, доучиваются до корочки, затем работают программистами, в принципе не используя полученные знания — это плохо.
В каком-то идеальном мире это так. Но я 15 лет работаю в Research подразделениях известных компаний и знаю буквально единичные примеры успешной оптимизации алгоритмов «другими людьми». Гораздо чаще ситуация такая: или алгоритм идет в корзину, или идет в production без изменений и оптимизации, или разработчик алгоритма сам оптимизирует код.
А в науке всё так: только один учёный из 1000 может придумать что-то действительно полезное. Но именно ради одного этого учёного и приходится содержать остальных, потому что дело тут даже не в способностях, а в случае.
Так и с алгоритмами. Не любой алгоритм перейдёт на второй этап. Стоимость внедрения алгоритма где-то на порядок выше стоимости его разработки. Поэтому крупные компании имеют большой R&D штат, заключают договоры на НИР с университетами — всё для того, чтобы иметь большое количество алгоритмов в своём распоряжении. А вот использовать эти алгоритмы на практике или нет — это уже их дело.
Если компания и разработку, и внедрение алгоритма навешивает на одного человека, значит, у этого алгоритма просто низкая наукоёмкость, типа скомбинировать 10 вызовов функций в OpenCV и оттюнить их параметры.
IliaSafonov
18.01.2017 11:23только один учёный из 1000 может придумать что-то действительно полезное. Но именно ради одного этого учёного и приходится содержать остальных, потому что дело тут даже не в способностях, а в случае.
Ну, я надеюсь, Вы или Ваши коллеги попадут в этот 0.1% и мы увидим пост «Как мы опубликовали статью в Nature» или, хотя бы, в IEEE Transactions on Image Processing.DistortNeo
18.01.2017 11:55Я будут более доволен, если алгоритм повышения качества изображений, которым я сейчас занимаюсь, через год-два будет использоваться в прошивках новых смартфонов. Тогда и можно говорить о 0.1%, а публикации может сделать кто угодно и чём угодно.
Как мы опубликовали статью в Nature
Это невозможно — мы не медики
в IEEE Transactions on Image Processing
В процессе рецензирования. Да и не так уж сложно там опубликоваться — нужно просто потратить много времени.
dom1n1k
16.01.2017 17:48Насчет масштабирования. Там неочевидный момент с пересчетом координат.
Предположим, нужно увеличить картинку ровно в 2 раза. Казалось бы, идеальный случай — просто засовываем между парами существующих пикселей еще по одному и готово. Но тогда получается, что либо в полученной картинке 2n-1 пикселей вместо 2n, либо последний пиксель переходит в предпоследний, а «самый последний» непонятно что делает.
Похожая ситуация и с уменьшением. Допустим есть 4 пикселя и их нужно отмасштабировать до 2-х. Чему будут равны 2 итоговых пикселя — крайним из исходной картинки или же средним арифметическим 1-2 и 3-4?DistortNeo
16.01.2017 19:40Да, в вашем случае наблюдается полупиксельный сдвиг. Вы просто не учитываете, что пиксели — не точки, а, в грубом приближении, квадраты, имеющие определённый размер. Введите систему координат, связанную не с пикселями, а с краями изображения: пусть изображение имеет размер X * Y, и разрешение (количество пикселей по осям) M и N соответственно.
Тогда получится, что координаты пикселей (x, y) будут равны
((x + 0.5) * X / M, (y + 0.5) * Y / N).
При увеличении в 2 раза M и N заменяются на 2M и 2N, и соответствие становится как на картинке

homm
17.01.2017 03:17Вы просто не учитываете, что пиксели — не точки, а, в грубом приближении, квадраты, имеющие определённый размер
Вы категорически неправы. A Pixel Is Not A Little Square. Пиксели — это именно точки, сэмплы. Просто координаты этих сэмплов на изображении находятся со смещением 0.5 относительно координатной сетки.
DistortNeo
17.01.2017 03:38+1Вы категорически неправы. A Pixel Is Not A Little Square. Пиксели — это именно точки, сэмплы. Просто координаты этих сэмплов на изображении находятся со смещением 0.5 относительно координатной сетки.
Вот именно, пиксели — это сэмплы. Пиксель неразрывно связан с Point Spread Function. Так как форма PSF обычно близка к квадрату, то и полагается, что пиксель квадратный. А точка — это просто координата, точка не может являться пикселем по определению.
DrZlodberg
16.01.2017 19:42Более очевидный — дублировать все пиксели. Если, конечно, не подразумевается интерполяция. С ней — вариантов определения «крайнего» придумать можно много, но очевидно правильного нет.
С уменьшением та же фигня. Вообще более корректный вариант — при уменьшении брать среднее для «схлопывающегося» блока. Правда при этом падает резкость и её стоит дополнительно поднять после уменьшения. Но к пересчёту координат обе проблемы imho отношения не имеют.dom1n1k
16.01.2017 19:58Там не только резкость.
Например, у меня есть изображение-градиент от цвета A к цвету B и я его уменьшаю.
Почти любой человек интуитивно будет ожидать, что цвета крайних пикселей при этом не должны измениться, только середина сплющится. Но они слегка изменятся, потому что в крайние цвета подмешиваются их соседи.DrZlodberg
16.01.2017 20:12+1Любые подобные манипуляции — это либо потеря информации, либо её создание из ничего (при увеличении).
Если крайние цвета не изменятся — градиент перестанет быть линейным(если он был таковым) по краям, что гораздо более заметно, чем небольшое изменение цвета. При сохранении цвета вы получите рамку, что не всегда приемлемо. А для текстур вообще фатально.

KVL01
16.01.2017 19:27Доступ к пикселям осуществляется с помощью функций GetPixel и SetPixel. Вызов этих функций очень дорогой — на два-три порядка медленнее, чем прямой доступ к пикселям.
Ну, в той же Delphi (ограничений на ЯП вы же не ставите) у битмапа есть Scanline – это просто указатель на кусок памяти с данными картинки (строку). Кастуете его, к чему вам надо, например к массиву из RGBQUAD, и работаете себе с отдельными пикселями.DistortNeo
16.01.2017 19:27Насколько я помню, в Delphi TBitmap — это и есть DIB. И прямой вызов GetPixel и SetPixel там тоже медленный.
Раньше так и делал со сканлайном, кстати.
mkarev
16.01.2017 22:35Эти советы хороши лишь для студентов, разбирающихся на коленке в реализации конкретного алгорима.
Если же рассматривать их с точки зрения реальных задач — это (местами) полнейший треш.
Не использовать готовые библиотеки — долго реализовывать и отлаживать свой велосипед
Ошибки округления (приведение к типу byte) — по максимуму используем арифметику с фиксированной точкой, чтобы оставаться в рамках целочисленных инструкций. Банально потому, что в тот же sse2 вектор влезет в 2 раза больше скаляров short, чем float.
Выход за границы диапазона — однозначно высчитывается на основании разрядности сигнала и коэффициентов фильтра. Из этого и выбирается разрядность скаляров фиксированной точки.
Используй float — см. предыдущий пункт, а также таблицу скоростей simd инструкций. У float латентность в несколько раз выше.
Используй абстракции, не используй индексацию по массивам — если ваш студент не может перебрать массив, то не понятно о чем с ним дальше можно разговариавать. Геттеры и сеттеры в данном контексте будут дичайшим бутылочным горлышком.
Путаница ширины и высоты — можно списать на невнимательность, а вот про stride или pitch стоило бы упомянуть, что ширину буфера иногда выгодно сделать кратной (в байтах) размеру кэш линии процессора, чтобы наиболее эффективно обрабатывать соседние строки.
Вангую стаю хейтеров с плакатами оптимизация — это зло!!!
Но вот когда от ваших студентов работодатель потребует realtime, им прийдеься учиться заново.DistortNeo
16.01.2017 23:01Эти советы хороши лишь для студентов, разбирающихся на коленке в реализации конкретного алгорима.
Если же рассматривать их с точки зрения реальных задач — это (местами) полнейший треш.Так прочитайте первые два абзаца. Эта статья ориентирована на студентов, имеющих нулевой опыт в обработке изображений и практически нулевой опыт программирования, как это обычно бывает в университетах. Такие студенты непригодны для привлечения к реальным задачам без предварительного практического обучения.
Чтобы разобраться в том, как работают алгоритмы, нужно хотя бы раз реализовать их самостоятельно. Написание велосипедов — непосредственный процесс обучения, от которого никуда не деться. Потому что реальные задачи, с которыми приходится сталкиваться студентам, не решаются с помощью библиотек.
Насчёт выхода за границы диапазона: обработка изображений не сводится к фильтрации и альфа-блендингу. Огромная часть алгоритмов вообще не может быть реализована с использованием fixed-point арифметики.
Векторные инструкции? Вы о чём? Студенты путают float и double, не знают, как оптимально размещать данные в памяти.
dom1n1k
17.01.2017 02:55Только непонятно в чем противоречие-то?
Да, в реальных задачах могут понадобиться и готовые библиотеки, и целочисленная арифметика, и оптимизации — иначе зачем их вообще придумали. Но прежде чем всё это использовать, нужно понять принципы работы. А как их понять? Пощупать своими руками.
Графика это такая штука, что когда читаешь теорию, про себя постоянно бубнишь — «так, это ясно… ясно… ну примерно понятно...»
Но когда начинаешь реализовывать, всплывает такая херова туча нюансов, что понимаешь — то была иллюзия ясности.
Mercury13
17.01.2017 00:24Ошибка 13. Помни о гамме! Сейчас повсеместно принята гамма 2,2, и даже Маки на неё перешли. Очень многие функции сглаживания из-за этого дают слишком тёмный или слишком светлый результат.
DistortNeo
17.01.2017 00:36И о том, что правильная формула для перевода из sRGB в grayscale выглядит так:
Y = 0.2126 * R + 0.7152 * G + 0.0722 * Bonyxmaster
17.01.2017 09:10В каком цветовом пространстве определён полученный grayscale?
DistortNeo
17.01.2017 13:38sRGB
onyxmaster
17.01.2017 16:41Вам так кажется. Эта «правильная формула» — компонента Y пространства CIE XYZ, отмасштабированный для конкретного иллюминанта. Я оставлю за скобками верность утверждения что Y компонент CIE XYZ, масштабированный для иллюминанта D65 является тем, что называется «grayscale» (хотя и CIE 1931 luminance не является, в общем-то, лучшим приближением ощущаемой интенсивности света), однако закрыть глаза на применение линейных коэффициентов к нелинейным значениям я не могу.
Если же R, G и B в данной формуле линейные, то про процесс их перевода из sRGB с учётом low-light conditions стоило бы упомянуть отдельно, иначе люди возьмут эту формулу и будут подставлять в неё значения пикселей из изображений, а этого делать нельзя.DistortNeo
17.01.2017 17:02Просто не усложняйте — иногда вообще достаточно использовать Y = (R + 2G + B) / 4. Иногда для значения числа "пи" вполне достаточно использовать 3.14, а для константы ускорения свободного падения — 9.8 или даже 10.
Точно так же нельзя использовать фильтр Собеля для выделения границ. Вместо него нужно использовать свёртку с честными производными функции Гаусса. Нельзя использовать прямоугольные фильтры для размытия — они имеют плохие частотные характеристики, вместо них правильнее использовать фильтр Гаусса.
onyxmaster
17.01.2017 16:44Я бы не рисковал утверждать что «все перешли на гамму 2.2». sRGB как «основное цветовое пространство интернета» имеет кривую, близкую, но не равную гамме 2.2, на самом деле это смещённая гамма 2.4.

Iceg
17.01.2017 00:26По поводу первой ошибки: я правильно понимаю, что для C# правильный вариант BitmapData.Scan0 и unsafe блок?

amakhrov
17.01.2017 03:37Про оптимизацию как-то непоследовательно получается.
С одной стороны, автор пишет, что не нужно заниматься преждевременной оптимизацией. С другой — предлагает заменятьpow(x, 2)наx * x.
Кстати, насчет последнего. Я далек от современного C++, но неужели компилятор сам не разберется с этим довольно простым выражением? Даже с -O3?
DistortNeo
17.01.2017 03:54Я предпочитаю, чтобы некоторые привычки вырабатывались сразу. Компилятор C++, скорее всего, соптимизует до умножения, а вот C# (студенты предпочитают писать на нём из-за других курсов) такую оптимизацию точно не делает.
dom1n1k
19.01.2017 03:35Ну тут он прав — вообще не вижу смысла в применении функции pow для малых целочисленных степеней. Написать просто x * x это и понятнее, и быстрее, и вообще вопросов не возникает. Это примерно как считать факториал через гамма-функцию — как бы можно, но смысла ноль.

Deosis
17.01.2017 11:38Какая ошибка привела к появлению рожицы с рожками на левой нижней картинке?
DistortNeo
18.01.2017 01:38Неправильная работа с вещественными числами. Нужно было дискретизовать вещественный полярный угол в одно из 8 направлений, т.е. найти, между каким из векторов (1, 0), (1, 1), (0, 1), (-1, 1), (-1, 0), (-1, -1), (0, -1), (1, -1) и направлением градиента угол наменьший. Код был такой:
angles[i][j]=(float)(Math.round(Math.atan2(gJ, gI)/(Math.PI/4))*Math.PI/4-Math.PI/2); dJ=(int)Math.signum(Math.cos(angles[i][j])); dI=(int)-Math.signum(Math.sin(angles[i][j]));
Данный код делает это неверно, выдавая только диагональные направления. Это приводит к появлению рожек.
astudent
можно еще проще:
а в c#:
DistortNeo
Это уже стиль. Лично меня коробит, когда перед или после точки нет цифры. Т.е. вместо
.5я предпочитаю писать0.5, а вместо5.—5.0.astudent
Запись (float)(1.0 / 16) — тоже стиль, константное выражения в любом случае будет вычислено еще на этапе компиляции. Так что если требуете краткую запись от «начинающих», то сокращайте по-максимуму, либо заранее обговорите правила игры (стиль кода).