
Рассмотрим следующую ситуацию: новый пользователь Хабра, получив «минус в карму» еще до первого своего поста/комментария на ресурсе, решает узнать, а кто же скрывается за изощренно придуманными никами пользователей Хабра и задается вопросом: who is Mr./Ms. Habraman?
Будем следовать разведывательному циклу:
Шаг 1. Постановка задачи
Задача может быть сформулирована так: требуется составить портрет среднестатистического пользователя Хабра.
Шаг 2. Планирование
2.1 Гипотезы
Для эффективного сбора информации нам потребуются рабочие гипотезы, исходя из которых мы поймем, какие данные нам нужны и где их искать. Чтобы сформулировать гипотезы зачастую необходимо некое предварительное знание о предмете.
Для получения предварительной информации о пользователях Хабра наш неискушенный пользователь обращается к сайту Lurkmore, который, как известно отличается многосторонним освещением любого явления в современном мире. Озадаченный негативным настроем автора заметки наш интернет-разведчик формулирует следующие гипотезы относительного того, кем все таки является среднестатистический пользователь Хабра:
- Гипотеза 1. Суровый IT-специалист в возрасте, проживающий в одной из наших столиц, озлобленный давками в метро или многокилометровыми пробками;
- Гипотеза 2. Инопланетянин, оставшийся на нашей планете до окончательной починки системы управления своего корабля, которую он надеется закончить по руководствам, размещенным на Хабре другими инопланетянами;
- Гипотеза 3. Молодой образованный человек с широким кругом интересов, которого интересуют не только компьютеры.
Обратите внимание, что при формулировании гипотез мы стараемся соблюдать правило MECE (mutually exclusive and collectively exhaustive, что можно перевести как «взаимоисключающий и совместно исчерпывающий список»).
2.2 Данные и их источники
Исходя из набора сформулированных гипотез, мы теперь можем определить, какие данные нам понадобятся, чтобы их можно было проверить.
Соответственно нам интересны следующие данные:
- Интересы (увлечения, кино, книги и т.п.);
- Пол;
- Возраст;
- Местоположение (город, страна).
Хорошим источником подобной информации, как мы знаем, являются социальные сети, в частности российская сеть «ВКонтакте», в которой наш герой находит группу Хабрхабр с почти 670 тысячами подписчиков и с девизом, косвенно подтверждающем одну из сформулированных гипотез: «НЛО с вами!».
Шаг 3. Сбор данных
3.1 Инструменты
Для доступа к данным подписчиков группы в сети «ВКонтакте» нам понадобятся:
- Маркер доступа к данным сети (access token);
- R — язык программирования для статистической обработки данных и их визуализации графикой;
- Библиотека для доступа к VK API: vkR;
- Среда разработки для R: RStudio;
- MS Excel и LibreOffice.
3.2 Получение доступа к данным
Для выгрузки данных пользователей социальной сети «ВКонтакте» необходимо использовать VK API. Благодаря Дмитрию Сорокину, создавшему библиотеку vkR, работа с VK API из среды R доступна теперь любому уверенному (да и неуверенному) пользователю.
Для того, чтобы иметь возможность обращаться VK API необходимо сгенерировать так называемый маркер доступа (access token).
3.3 Процесс сбора данных
Так как в комментариях к прошлой статье уважаемые читатели показали большой интерес к практической составляющей процесса сбора данных, мы приведем здесь пример кода на языке R, на основе которого при желании можно полностью воспроизвести описываемые далее шаги.
Для работы с данными пользователей группы Хабхабр в сети «ВКонтакте» потребуется ее уникальный идентификатор, который легко определить, наведя указатель мыши, например, на кнопку «Написать сообщение» и, увидев, ссылку следующего вида «vk.com/im?sel=-20629724». Цифры 20629724 и являются нужным ID.
#устанавливаем библиотеку vkR
>install.packages("vkR")
#загружаем библиотеку и теперь можем обращаться к ее методам напрямую
>library(vkR)
#подключаемся с помощью добытого маркера доступа
>setAccessToken(access_token = "000000000..000")
#выгружаем в переменную userids список всех идентификаторов пользователей группы
>userids<-getGroupsMembersExecute(group_id = "20629724", progress_bar = TRUE)
#формируем выборку из 3000 случайно выбранных элементов списка
>sampleids<-sample(userids, 3000, replace=FALSE)
#выгружаем данные по выбранным пользователям
#описание полей: https://vk.com/page-1_27445058
>groupdata<-getUsersExecute(sampleids,fields = "sex,bdate,city,country,education,universities,relation,interests,movies,tv,books,games,about", drop=FALSE, flatten = FALSE, progress_bar = TRUE)
#подсчитываем количество инопланетян, девушек и парней
> qofmale_female<-as.data.frame(table(groupdata$sex))
#смотрим, что получилось
> qofmale_female
Var1 Freq
1 0 2
2 1 853
3 2 2145
#добавляем столбец с подписями для красивой гистограммы
qofmale_female$name<-c("Инопланетяне", "Девушки", "Парни")
#добавляем столбец с кодами цветов
qofmale_female$color<-c("#51b828", "#ff5d4e", "#2879a8")
#выводим диаграмму
> barplot(qofmale_female$Freq, names.arg = qofmale_female$name, col=qofmale_female$color, border = NA)
#выгружаем в CSV-файл на память или для дальнейших манипуляций в MS Excel/LibreOffice
write.csv2(qofmale_female, "C://girlsboysaliens.csv")
3.4 Выборка
Интернет-разведка должна быть эффективной и результативной, поэтому «перелопачивать» все 670 тысяч пользователей – не очень хорошая идея. Нам нужна достаточно большая выборка, сформированная случайно. Нашему герою нравится цифра 3000 и он останавливается на ней. Учитывая рекомендации социологов, такого объема хватит даже в случае, если не все профили будут полностью заполнены.
Шаг 4. Обработка данных
Благодаря R, обработка данных оказалась довольно простой. Единственная проблема, с которой столкнулся наш разведчик оказалась проблема с кодировкой: после выгрузки данных из сети «ВКонтакте» в консоли RStudio текст корректно не отображался, но проблему удалось решить следующим образом:
- Выгружаем полученные из соцсети данные в переменную;
- Сохраняем в CSV-файл;
- Открываем в LibreOffice – проверяем, что все читается, как надо;
- Сохраняем CSV-файл, устанавливая кодировку unicode UTF-8;
- Загружаем обратно в R c использованием read.csv с указанием кодировки UTF-8.
Наверняка, есть более оптимальное решение этой проблемы, кто знает – делитесь информацией в комментариях к статье.
Шаг 5. Анализ информации
Приступим к анализу полученных данных.
5.1 Парни, девушки и инопланетяне
Если посмотреть на распределение по половым признакам можно увидеть следующую картину:

Мы видим, что примерно 2/3 составили парни, 1/3 — девушки, а вот инопланетян, которые не смогли определиться с принадлежностью к какому-либо определенному полу, в нашей выборке оказалось всего двое. Гипотезу 2 можем смело отбросить.
5.2 Города и страны
Проверяя первую гипотезу, включающую предположение, что среди пользователей Хабра преимущественно жители наших двух столиц, посмотрим на распределение по городам.
Данное поле в своей анкете указали всего 2092 пользователя из нашей выборки. Список из топ-15-городов получился таким:
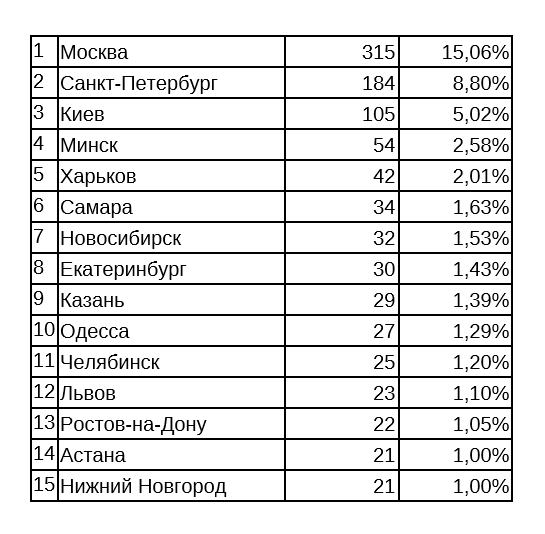
Две столицы занимают первые позиции, но общее количество пользователей, указавших Москву и Санкт-Петербург – менее четверти от 2092. Соответственно, чисто столичным Хабр назвать сложно.
Что же касается стран, в которых проживают наши пользователи, то видно, что в основном речь идет о России, Украине, Казахстане и Беларуси.

5.3 Возраст аудитории
Интересно посмотреть на распределение по годам рождения пользователей Хабра из выборки и увидеть, что возраст основной массы пользователей находится в диапазоне 20-30 лет.
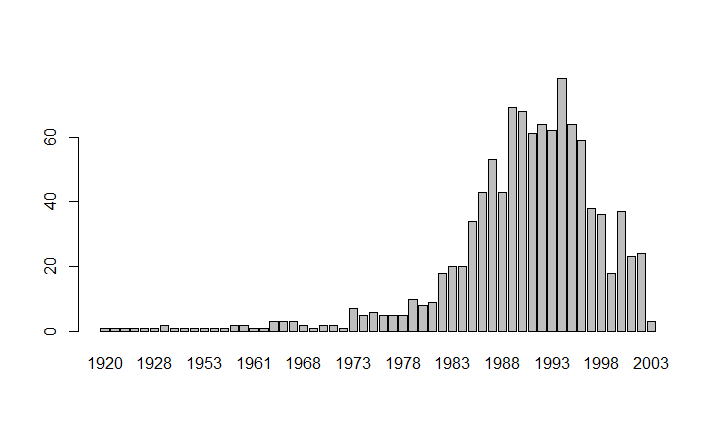
Предположение о возрасте из первой гипотезы можно смело исключить, а вот соответствующее предположение из третьей гипотезы подтверждается.
5.4 Интересы
Посмотрим, чем живут наши пользователи. Это можно сделать, как минимум, проведя анализ следующих полей, указанных в профилях: interests,movies,tv,books,games,about. Дополнительно можно провести анализ групп, в которых наши пользователи состоят, благо у нас есть замечательный метод getGroupsForUsers(). С анализа групп и начнем. Ниже представлены топ-15 групп сети «ВКонтакте», в которых любят состоять пользователи Хабра.
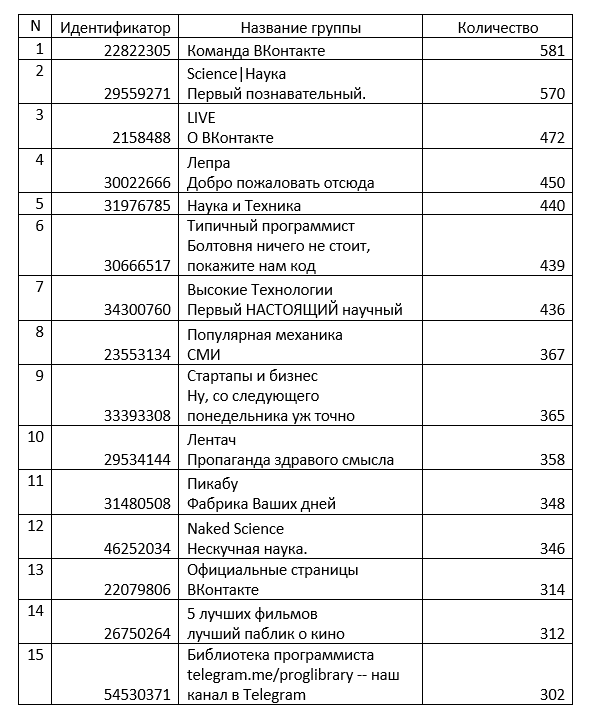
Как видим, информационные технологии и программирование занимают не последнее место в жизни пользователей Хабра, но явно только на них никто не зацикливается.
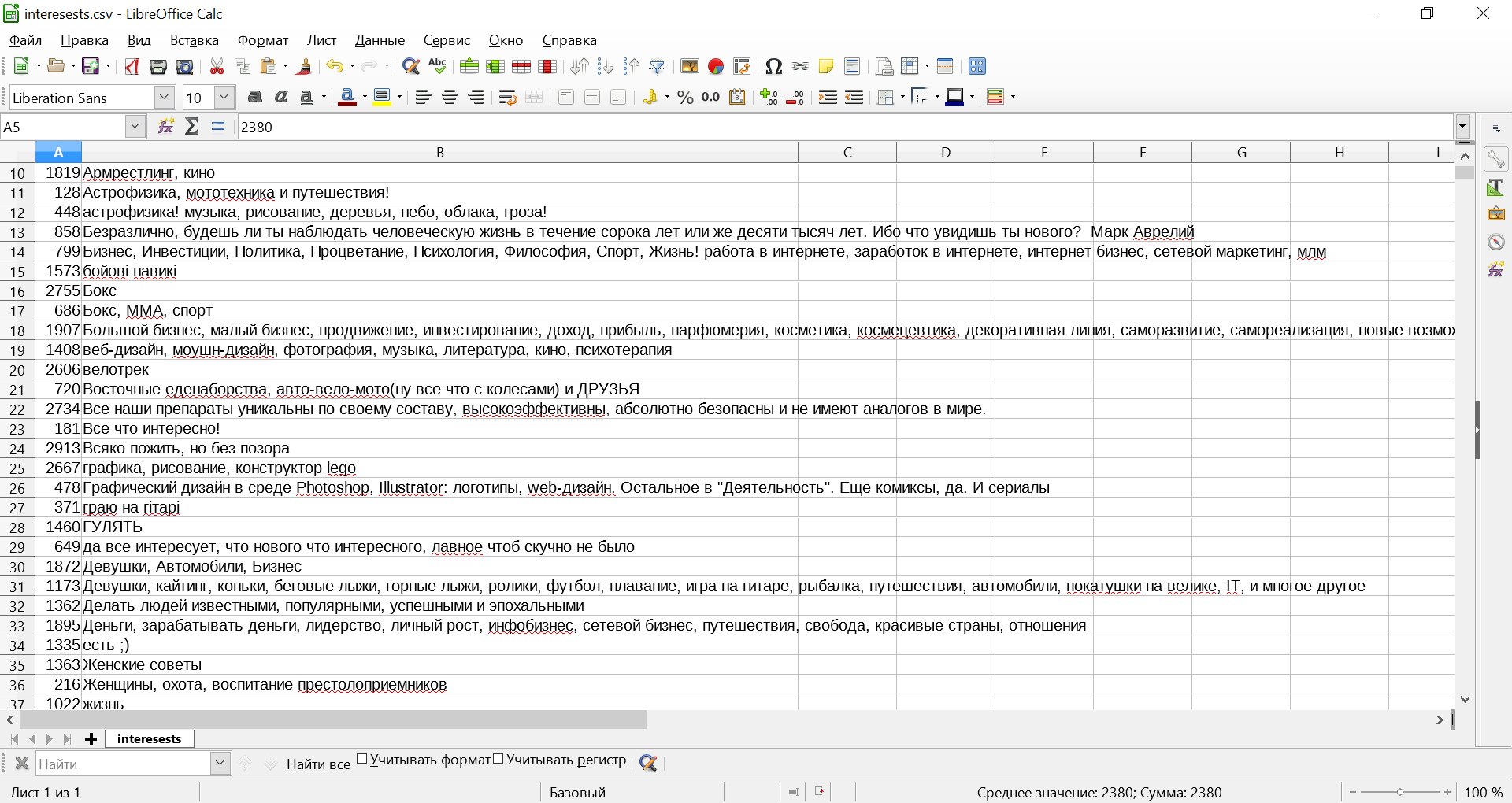
Строить гистограммы по значениям полей interests,movies,tv,books,games,about имеет смысл после долгого сопоставления того, что указали пользователи, с общими категориями, но на это времени, к сожалению, нет. Поэтому пройдемся по некоторым моментам, которые бросились в глаза.
1. По всей видимости значительное число аудитории Хабра не жалует телевизор, но это не факт, а предположение, так как мы видим всего порядка 20 чел, и мы не знаем, сколько людей предпочли не сообщать об этом, хотя поступают именно так.
2. Литература – самая разнообразная, и что характерно, произведения Дональда Кнута включены в список любимых книг на ночь далеко не всеми.
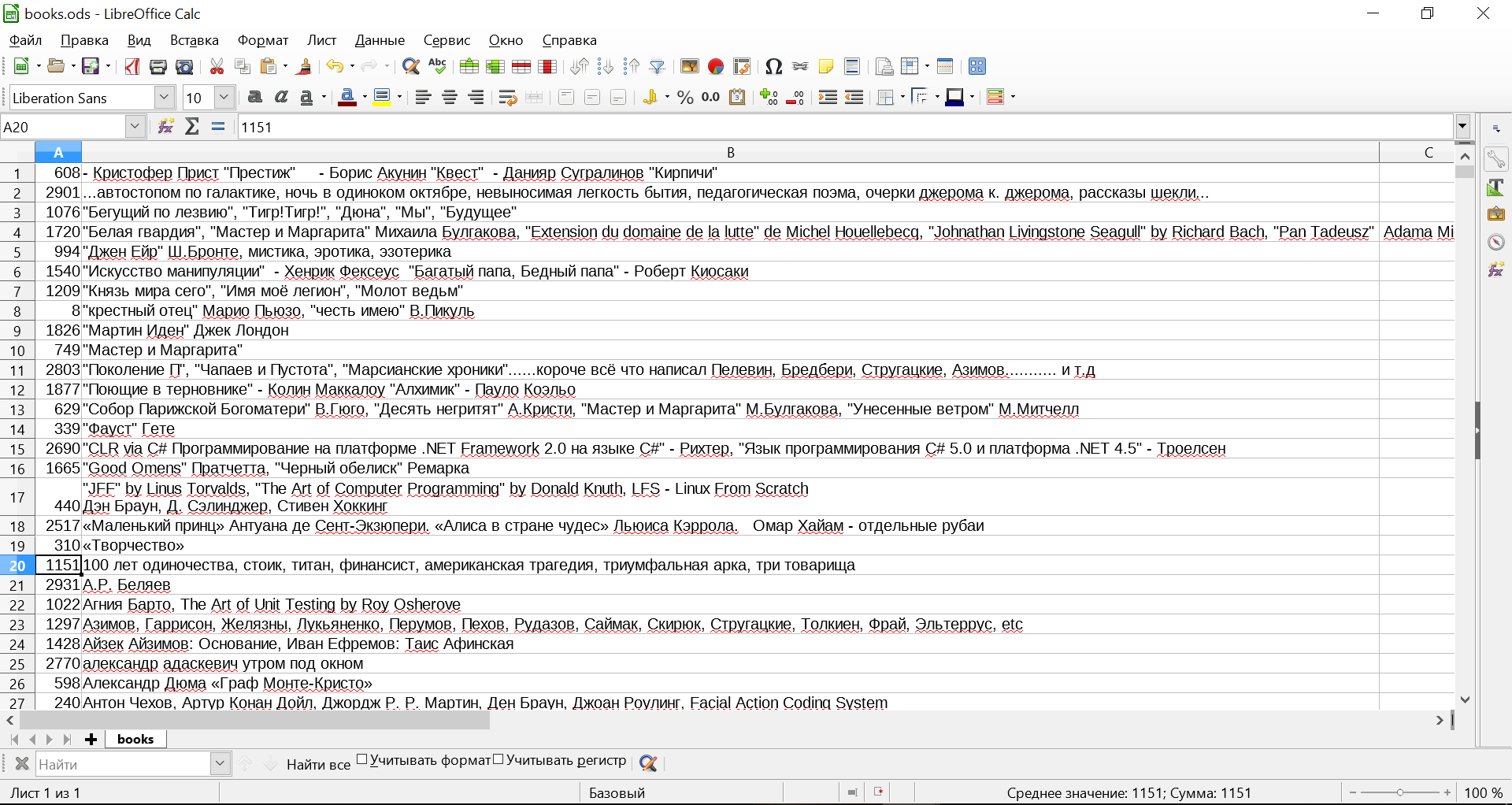
3. Интересы отличаются исключительным разнообразием, и, что особенно радует, – спорт занимает не последнее место.
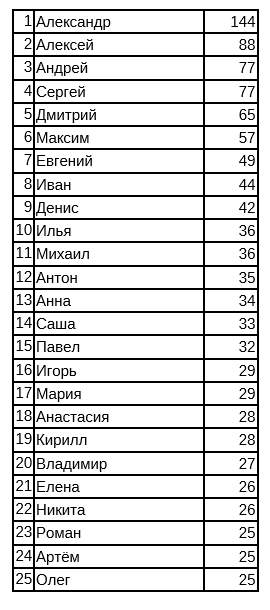
5.5 Просто любопытство: ТОП-25 имен
Проводя анализ собранных данных, стало интересно посмотреть, а какие самые распространенные имена у пользователей Хабра, в большинстве своем старающихся выбрать загадочный nickname. Получилась вот такая таблица из ТОП-25 имен из нашей выборки:
Шаг 6. Подготовка отчета и презентация результатов
Таким образом, подводя итоги проведенного небольшого исследования, можно смело описать портрет среднестатистического Мr. или Ms. Habraman:
- Возраст от 20 до 30 лет;
- Живет в крупном городе на территории России, Украины, Казахстана или Беларуси;
- Ведет активный образ жизни, интересуется ИТ, современной наукой и много чем еще;
- Вероятность того, что перед нами парень – 2/3, а что милая девушка – 1/3, и точно не инопланетянин.
Соответственно из сформулированных трех гипотез третья оказалась самой вероятной. Первые две были отброшены.
Проверка данных
Когда кто-нибудь представляет свой анализ, да еще и сообщает свои выводы, настоящий разведчик всегда перепроверит. Давайте это сделаем и мы – сопоставим полученные результаты с уже доступными данными из альтернативных источников.
Сверим с данными, которые представлены в разделе «Пользователи», доступного любому пользователю Хабра.
Совпадения:
- Всего пользователей: 739 159, а в группе «ВКонтакте» почти 670 тыс – порядок одинаковый.
- Очередность стран по количеству пользователей почти совпадает: Россия, Украина, Беларусь, Казахстан, США.
- Очередность городов: первые 5 совпадают.
Расхождения:
- По данным самого сайта, среди пользователей мужчин — 134 тыс, женщин — 10 тыс, а «остальных» — примерно 600 тыс. Возможно, это свидетельствует о нашествии инопланетян, но скорее всего пользователи, просто не стали заполнять полностью свои профили.
- Процентное соотношение по городам отличаются существенно. У нас Москва – не менее 15%, на сайте же указано, что в Москве всего 6 тысяч пользователей, что составляет 1% от всех зарегистрированных пользователей, что скорее всего вызвано также нежеланием пользователей полностью заполнять свой профиль на сайте.
Сверим также с данными, похожего исследования, проведенного в 2014-м году пользователем Apatic: Кто подписан на Хабрахабр?
Совпадения:
- 76% — мужчины, 24% — женщины, что очень близко к нашему результату;
- Распределение по возрасту совпадает;
- Топ-4 страны те в таком же порядке.
Заключение
Вот мы и разобрались как разведывательный цикл можно применить и для анализа информации о сообществах, что будет полезно и блогеру для понимания аудитории читателей, и маркетологу, анализирующему, кто покупает продукцию у конкурентов.
Литература
- Искусство визуализации в бизнесе. Как представить сложную информацию простыми образами. Нейтан Яу ISBN: 978-5-91657-737-2
- Много цифр. Анализ больших данных при помощи Excel. Джон Форман. ISBN 978-5-9614-5032-3, 978-5-9614-5954-8
Update:
У ряда читателей появились сомнения в том, что группа «Хабрхабр» в сети «ВКонтакте» значительно пересекается с группой пользователей самого Хабра. Чтобы проверить этот тезис, предлагаю небольшой опрос.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (22)

slavius
24.01.2017 09:23Это не разведка, это скорее опрос. Разведка — это узнать сведения, явно не указанные в открытых источниках.

alexdorofeeff
24.01.2017 10:32Мне лично нравится больше такое определение: разведка — знание или предвидение окружающего нас мира, необходимое для принятия решений и действий. В статье дан пример так называемой разведки по открытым источникам (Open Source Intelligence или OSINT). В одной из следующих статей, раз это интересно, разберем другие разные виды разведок (там есть, и HUMINT, и FININT, и CYBERINT и другие INT'ы)

user343
27.01.2017 11:00Лучше бы базу имён, IP, email, user-agent, (диз)лайков пользователей получили (нахождением пробоин в корпусе НЛО) и слили на peers.fm, а ссылку на лурк положили.
Вконьтакте далеко не все зарегистрированы.
Для уточнения картины желательностыритьзаиметь привязки браузеров оппонентов к twitter, linkedin, facebook, ok.ru и госуслугам (ИНН, СНИЛС и т.д.).


anonslou
24.01.2017 10:40Ваша проверка данных вызывает естественный вопрос — зачем всё усложнять, если сразу можно посмотреть на профили пользователей хабра? Нет никаких оснований полагать, что люди будут указывать о себе в разных социальных сетях противоречивые сведения. Кстати, выявить последних было бы куда интереснее!
alexdorofeeff
24.01.2017 10:42Мы смотрели одну сеть: «ВКонтакте» и, как раз, привели методы, как это можно сделать несколькими простыми командами из среды R.

Shamov
24.01.2017 14:30+3Женщин в исходном списке гипотез (исчерпывающем) вообще не было. А на деле их обнаружилась треть. После такого провала офицер разведки обязан застрелиться.
alexdorofeeff
24.01.2017 14:57Shamov, Вам, плюс в карму!) В реальной жизни исчерпывающий список не всегда получается подготовить, многое открывается в последствии. Стараемся следовать MECE, а там как пойдет. Процесс тестирования гипотез итеративным получается, здесь не стал перегружать текст этим.

OtshelnikFm
24.01.2017 15:47новый пользователь Хабра, получив «минус в карму» еще до первого своего поста/комментария на ресурсе, решает узнать, а кто же скрывается за изощренно придуманными никами пользователей Хабра и задается вопросом: who is Mr./Ms. Habraman?
Не, он хочет узнать кто те 39 человек поставивших ему + и — в карму. Не облик, а ники и ip. И он их по ip вычислит ))
facet
25.01.2017 08:28Наверняка, есть более оптимальное решение этой проблемы, кто знает – делитесь информацией в комментариях к статье.
Можно и не задействовать для перекодировки LibreOffice вообще, так как текстовый редактор встроенный в RStudio может пересохранить файл с любой кодировкой.

Akon32
25.01.2017 16:33-1В опросе "Ваш возраст" сумма 105%.
далеко идущие выводыАвтор инопланетянин. И среди проголосовавших пользователей их до 5%.
user343
30.01.2017 02:32А я нашёл человека-невидимку (наверное 33-го пола, он же занимает 5%
темной материиаудитории).
Связан с НЛО или администрацией.

кстати о порче изображений НЛОшникамиэто
дурацкоехабро-объекто-хоронилище зачем-то пересчитывает картинку
из 31.54 KB 920x693 8bit PNG в 32bpp, делая её вдвое "толще".
prostofilya
Наверное, кто-то должен сказать эти очевидны вещи…
Итак, сколько информации мы потеряли по дороге:
1) Население хабра больше, чем одни лишь подписчики группы. Теряем всех неподписавшихся. А ещё могут быть подписчики, не захаживающие на хабр.
2) Теряем народ, не указавший свои персональные данные. А учитывая то, что среди программистов параноиков не мало — процент может быть существенным.
3) Подписка на ту или иную группу совсем не достоверно отражает интересы человека.
4) Информация о себе тоже часто недостоверно отражает информацию о человеке, зачастую люди пишут какими бы они хотели бы видеть себя со стороны.
В конечном шаге мы накапливаем огромную ошибку.
Ну и, сомневаюсь по поводу возраста, так как вконтакте в основном зарегистрированы люди именно этого возраста.
alexdorofeeff
1) Согласен, но порядок один: на Хабре ~740 тыс, в группе ~670 тыс.
2) Для этого берем большую выборку, не 600 чел, а 3000.
3) Спорный тезис — зачем тогда человек подписывался? Коммерческих групп в топе нет практически — это не результат акций типа «подпишись и получи шанс выиграть что-нибудь».
4) По выявлению лжи — сделаем пост отдельный или парочку даже. Здесь считаем, что все пользователи Хабра исключительно честные.
RouR
1) Аккаунт на хабре ещё заработать надо. Если его нету, то, возможно, удобнее читать и комментить паблик вконтакте. При этом наврятли кто-то будет читать одну и туже статью дважды, смотреть две одинаковые ленты новостей, одну на хабре, другую в паблике. Возникает вопрос — кого анализировали? Хабравчан или желающих ими стать?
alexdorofeeff
Ну если допустить, что в группе «ВКонтакте» совершенно другая аудитория нежели на Хабре, то как тогда объяснить совпадения по статистике, которая у нас получилась и которую сам Хабр ведет?
Psychosynthesis
В группе хабра в контактике минимум у 50% вообще нет аккаунта на хабре. А ещё там полно тех, у кого аккаунт Readonly. Делайте выводы.
facet
Разумеется две эти аудитории не идентичны, но на мой взгляд у них — серьёзное пересечение, т.к активные пользователи вконтакте могут вполне захотеть иметь возможность читать и хабровские посты в общей ленте активностей.
Вообще всё это — отдельная гипотеза, и было бы интересно её проверить в одной из дальнейших статей этого цикла) Хотя бы на уровне прямого вопроса о чтении хабра в соцсетях )
Интуитивно мне кажется, что эти аудитории весьма близки.
alexdorofeeff
Psychosynthesis, prostofilya опрос пока показывает, что наши выводы то правильные ;) но за критику спасибо!