
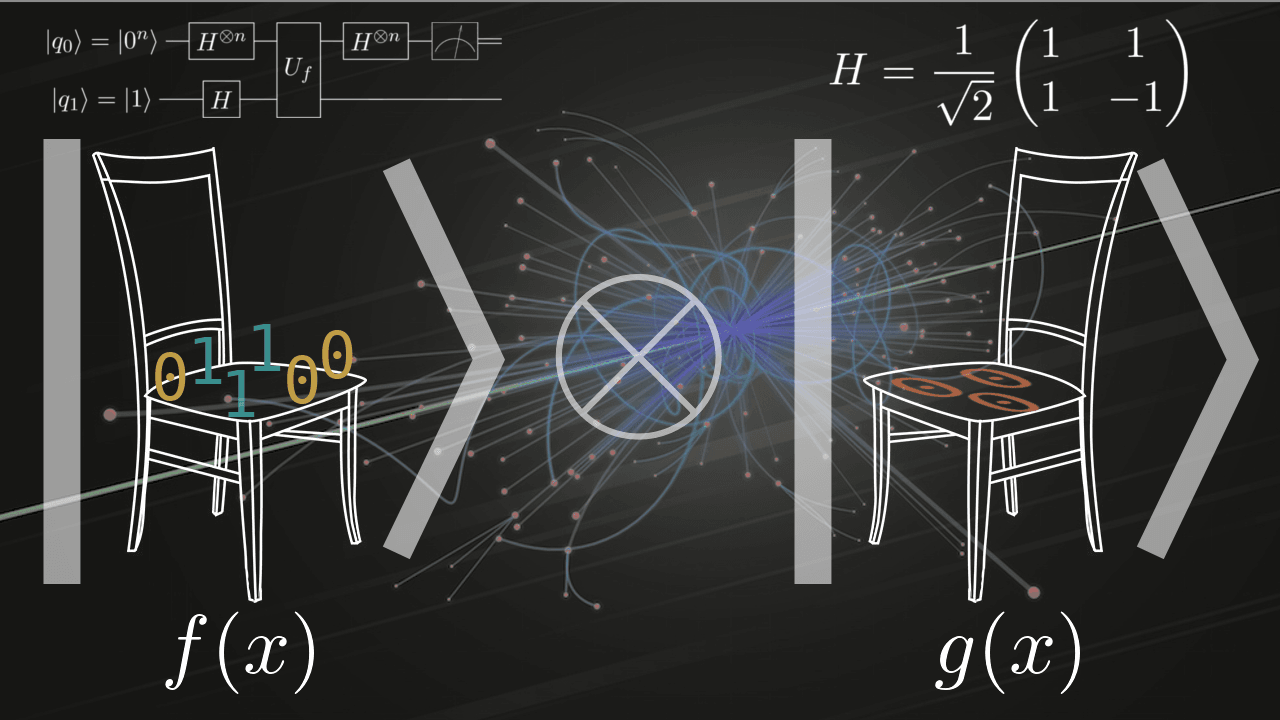
Есть две булевы функции
Если не знаешь, как решить подобную задачу, добро пожаловать под кат. Там я расскажу про квантовые алгоритмы и покажу как их эмулировать на самом народном языке — на Python.
I’ve come to talk with you again
Давайте чуть более формально поставим задачу о двух функциях. Пусть дана булева функция

Пример:
сбалансирована:
0 0 0 0 1 1 1 0 1 1 1 0
константна:
0 0 1 0 1 1 1 0 1 1 1 1
ни сбалансирована, ни константна:
0 0 0 0 1 0 1 0 0 1 1 1
Задача, безусловно, искусственная и навряд ли когда-нибудь кому-нибудь встретится на практике, однако она — классический проводник в дивный новый мир квантовых вычислений, а нарушать традиции я не осмелюсь.
Классическое детерминированное решение

Давайте, для начала, решим задачу в классической модели вычислений. Для этого в худшем случае понадобится вызвать функцию на
Алгоритм на Python:
from itertools import product, starmap, tee
def pairwise(xs):
a, b = tee(xs)
next(b, None)
return zip(a, b)
def is_constant(f, n):
m = 2 ** (n - 1)
for i, (x, y) in enumerate(pairwise(starmap(f, product({0, 1}, repeat=n)))):
if i > m:
break
if x != y:
return False
return True
Классическое вероятностное решение

А что, если вместо половины аргументов мы проверим меньшее их число и вынесем вердикт? Точным ответ уже не будет, но с какой вероятностью мы ошибёмся? Допустим, мы вычислили функцию на
Обратная функция:
При фиксированном
Алгоритм на Python:
import random
from itertools import product, starmap, tee
def pairwise(xs):
a, b = tee(xs)
next(b, None)
return zip(a, b)
def is_constant(f, n, k=14):
xs = list(product({0, 1}, repeat=n))
random.shuffle(xs)
xs = xs[:k]
for x, y in pairwise(starmap(f, xs)):
if x != y:
return False
return True
А если я скажу вам, что существует константное детерминированное решение со сложностью
Правда, прежде чем его рассмотреть, придётся отвлечься…
Because a vision softly creeping
Мифы
Пережде чем начать, хотелось бы обсудить несколько расхожих мифов, связанных с квантовыми вычислениями:
- Квантовые алгоритмы — это сложно.

Да, их сложно синтезировать, ибо требуется для этого математическое воображение и проницательность. Их сложно реализовывать на настоящих квантовых компьютерах: для этого необходимо превосходно знать физику и засиживаться каждый день допоздна в лаборатории на кафедре. Но что точно не требует никаких особых знаний и невероятного количества усердия, так это их понимание. Я утверждаю, что каждый может понимать квантовые алгоритмы: они опираются на крайне простую математику, доступную любому первокурснику. Всё, что от вас требуется — лишь немного времени на изучение.
- Уже существуют квантовые компьютеры на тысячи кубитов от D-Wave
Нет, это не настоящие квантовые компьютеры.
- Не существует ни одного настоящего квантового компьютера
Нет, существуют. В лабораторных условиях и располагают они лишь несколькими кубитами.
- Квантовые компьютеры позволят решать задачи, недоступные ранее
Нет, множество задач, вычислимых в классической и квантовой моделях, совпадают. Квантовые вычисления позволяют лишь снизить сложность небольшого подмножества этих задач.
- На квантовом компьютере Crysis на максималках будет летать

За исключением некоторого подмножества задач, которые квантовая модель вычислений способна ускорить, остальные могут быть решены лишь эмуляцией классического компьютера. Что, как вы понимаете, очень медленно. Crysis, скорее всего, будет лагать.
- Квантовый компьютер — это чёрная коробочка с входом и выходом, заглянув в которую можно всё испортить

Если вам 12 лет, такая аналогия сгодится. В любом другом случае она, как и все другие аналогии с коробками, котами, лупами и «связанными» нитками электронами, так активно продвигаемые во всех научно-популярных источниках, только лишь запутывает, создаёт иллюзию ложного понимания и скорее вредна, чем полезна. Откажитесь от этих аналогий.
Зачем?
Зачем прикладному математику (программисту) уметь разбираться в квантовых алгоритмах на прикладном уровне? Тут всё просто, я готов предложить вам два довода:
- Для саморазвития. Почему бы и нет?
- Они уже идут. Они, квантовые компьютеры. Они уже рядом. Моргнуть не успеете, как парочка появится в серверной вашей компании, а ещё через несколько лет и в виде сопроцессора в вашем ноутбуке. И бежать уже будет некуда. Придётся под них программировать, вызывать квантовые сопрограммы. А без понимания это делать сложно, согласитесь.
Left its seeds while I was sleeping
Самой базовой составляющей квантовых вычислений является квантовая система. Квантовая система — физическая система, все действия которой сравнимы по величине с постоянной Планка. Это определение и тот факт, что квантовые системы подчиняются законам матричной механики — все знания, которые нам потребуются из физики. Дальше — только математика.

Как и любая другая физическая система, квантовая система может находиться в определённом состоянии. Все возможные состояния квантовой системы образуют гильбертово пространство
- Линейное (векторное) пространство — множество элементов
с введёнными на нём операциями сложения элементов
и умножения
на элемент поля
(в нашем случае поля комплексных чисел). Операции эти должны быть замкнуты (результат должен принадлежать множеству
- В метрическом пространстве
определено расстояние
, которое удовлетворяет требованиям (аксиомам метрического
пространства):
, при этом
тогда и только тогда, когда
и
совпадают;
;
— неравенство треугольника.
- В нормированном пространстве
существует вещественное число
, называемое его нормой и удовлетворяюещее, опять же, трём аксиомам:
, если же
, то
— нулевой элемент;
;
.
Введём в полученном пространстве скалярное произведение, удовлетворяющее обычным требованиям скалярного произведения, введём норму как показано выше и получим пространство Гильберта.
Обсудим ещё понятие сопряжённого пространства. Пространством, сопряжённым к
где
В квантовой информатике по историческим причинам используются обозначения Дирака. Они могут казаться необоснованно громоздкими и вычурными, но они — стандарт, которого стоит придерживаться. В этих обозначениях элемент нашего гильбертова пространства, описывающий состояние системы, называется кет-вектором и обозначается
Бра-вектором называется элемент сопряжённого пространства
такой что
То есть, это линейный оператор, применение которого к нашему вектору состояния аналогично скалярному произведению на соответствующий ему элемент «оригинального» гильбертова пространства. Для удобства записи при приминении бра-вектора к кет-вектору две вертикальные черты сливаются в одну, что показано в выражении выше.
Важно то, что вектора, отличающиеся лишь умножением на некоторую ненулевую константу, отвечают одному и тому же физическому состоянию, поэтому часто рассматривают не все возможные состояния, а лишь нормированные, то есть такое подмножество
— норма каждого элемента равна единице. Все такие вектора живут на единичной гиперсфере.
Если мы выделим в нашем гильбертовом пространстве состояний некоторый базис
при этом матричная механика говорит нам, что квадраты модулей коэффициентов разложения
Вот оно — первое и основное свойство квантовых систем, которое так часто мусолят в популярных статьях: если измерить систему в некотором базисе, то она перейдёт в одно из базисных состояний, потеряет информацию и не сможет вернуться назад. Вот только при прочтении складывается ощущение, что всё происходит абсолютно случайно и повлиять на это никак нельзя, тогда как на самом деле вероятности перехода известны заранее и, более того, зависят от измерительного базиса. Если бы всё было так случайно, как нам представляют, детерминированные квантовые алгоритмы были бы невозможны.
Если мы можем представить элемент Гильбертова пространства вектором при некотором фиксированном базисе, то линейный оператор над этим пространством мы можем представить матрицей.
Действительно,
эквивалентно
где
Пусть оператор
Элементы матрицы — комплексные числа. Давайте возьмём каждый элемент и заменим его комплексно сопряжённым (комплексно сопряжённым к
Такая матрица
Второе правило, которое диктует нам матричная механика: на квантовую систему могут действовать только унитарные операторы. Почему? Потому что такие преобразования обратимы во времени и не теряют информацию. Действительно, если
то можно применить обратное преобразование
и получить исходное состояние системы.
Напоследок самое важное: тензорное произведение. Тензорным произведением двух гильбертовых пространств
- Размерность получившегося пространства равна произведению размерностей исходных пространств:
;
- Если
— базис
, а
— базис
, то
— порождающий базис
.
Тензорным же произведенем операторов
Такое произведение ещё называется произведением Кронекера: мы умножаем вторую матрицу на каждый элемент первой матрицы и из получившихся блоков составляем блочную матрицу. Если размерность A равнялась
Пример:
Третье важное свойство квантовых систем: две квантовые системы могут находиться в состоянии суперпозиции, при этом новое пространство состояний представляет собой тензорное произведение исходных пространств, а состояние новой системы будет являться тензорным произведением состояний исходных систем. Так, суперпозицией систем в состояниях
And the vision that was planted in my brain
Вот и вся математика, что нам понадобится. На всякий случай, резюмируя:
- При фиксированном базисе квантовую систему можно описать комплексным вектором, а эволюцию этой системы — унитарной комплексной матрицей;
- Квантовую систему можно измерить в каком-либо базисе и она перейдёт в одно из базисных состояний в соответствии с заранее определёнными вероятностями.
Получается, чтобы описывать, изучать, понимать и эмулировать на классическом компьютере квантовые алгоритмы, достаточно лишь умножать матрицы на вектора — это даже проще, чем нейронные сети: здесь нет нелинейностей!

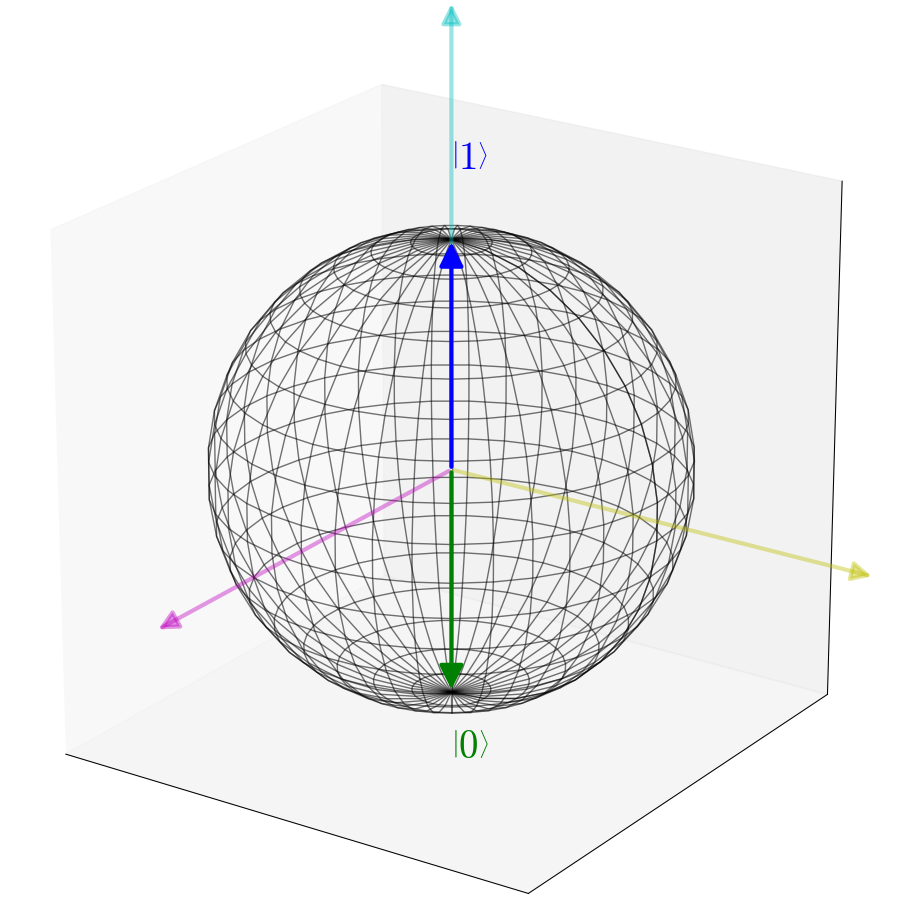
Кубит
Давайте рассмотрим некоторую квантовую систему, описываемую двумерным гильбертовым пространством
и произвольный вектор
где
Регистр
Один кубит, как и один бит — слишком скучно, поэтому сразу рассмотрим суперпозицию нескольких кубитов. Такая суперпозиция называется квантовым регистром (quantum register, qregister) из
Соответственно, любое состояние такого регистра
где
Далее аналогично. Квантовый регистр из
import numpy as np
class QRegister:
def __init__(self, n_qbits, init):
self._n = n_qbits
assert len(init) == self._n
self._data = np.zeros((2 ** self._n), dtype=np.complex64)
self._data[int('0b' + init, 2)] = 1
3 строчки кода для создания квантового регистра — совсем не сложно, согласитесь. Использовать можно таким образом:
a = QRegister(1, '0') # |0>
b = QRegister(1, '1') # |1>
c = QRegister(3, '010') # |010>
Квантовый алгоритм включает в себя:
- Инициализацию квантового регистра;
- Набор унитарных преобразований над ним;
- Измерение результата.
Измерение
С первым пунктом разобрались и научились его эмулировать, давайте теперь научимся эмулировать последний: измерение. Как вы помните, квадраты коэффициентов вектора состояния физически означают вероятности перехода в это состояние. В соответствии с этим реализуем новый метод в классе QRegister:
def measure(self):
probs = np.real(self._data) ** 2 + np.imag(self._data) ** 2
states = np.arange(2 ** self._n)
mstate = np.random.choice(states, size=1, p=probs)[0]
return f'{mstate:>0{self._n}b}'
Генерируем вероятности
probs выбора одного из states и случайно выбираем его с помощью np.random.choice. Остаётся только вернуть бинарную строку с соответствующим количеством дополняющих нулей. Очевидно, что для базисных состояний ответ всегда будет одинаков и равен самому этому состоянию. Проверим:>>> QRegister(1, '0').measure()
'0'
>>> QRegister(2, '10').measure()
'10'
>>> QRegister(8, '01001101').measure()
'01001101'
Почти всё готово, чтобы решить нашу задачу! Осталось лишь научиться влиять на квантовые регистры. Мы уже знаем, что сделать это можно унитарными преобразованиями. В квантовой информатике унитарное преобразование называется гейтом (quantum gate, qgate, gate).
Гейты
В рамках данной статьи рассмотрим лишь малое число самых основных гейтов, которые нам пригодятся. На самом деле, их намного больше.
Единичный
Единичный гейт — самый простой, какой только можно рассмотреть. Его матрица выглядит следующим образом:
Он никак не изменяет кубит, на который действует:
однако не стоит считать его бесполезным — он нам понадобится, и не раз.
Гейт Адамара
Не составляет труда проверить, что матрица унитарна:
Рассмотрим действие гейта Адамара на базисные кубиты:
Или в общем виде [1]:
Как можно заметить, гейт Адамара любое базисное состояние переводит в равновероятное — при измерении с равной вероятностью можно получить любой результат.
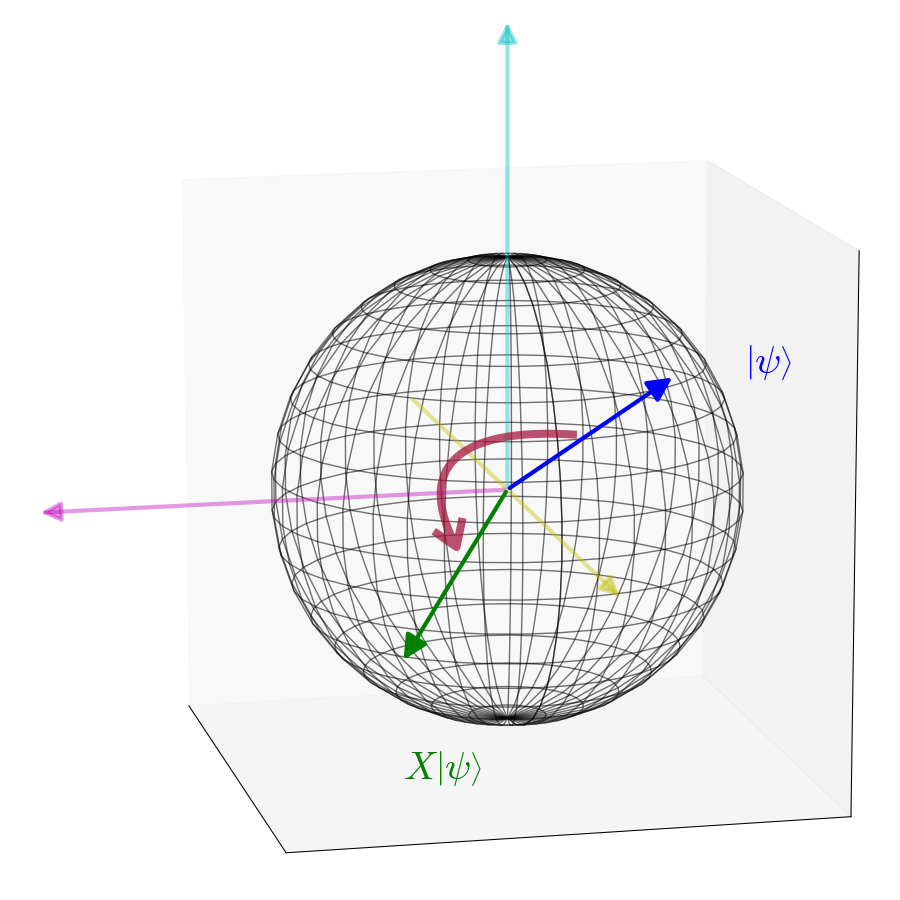
Гейты Паули
Три крайне важных гейта, которым соответствуют матрицы, введённые Вольфгангом Паули:
Гейт
а геометрически его применение эквивалентно повороту на сфере Блоха на
Гейты
Существует теорема, согласно которой с помощью гейтов
откуда видно, что гейт Адамара геометрически означает вращение на
Реализуем все рассмотренные гейты на Python. Для этого создадим ещё один класс:
class QGate:
def __init__(self, matrix):
self._data = np.array(matrix, dtype=np.complex64)
assert len(self._data.shape) == 2
assert self._data.shape[0] == self._data.shape[1]
self._n = np.log2(self._data.shape[0])
assert self._n.is_integer()
self._n = int(self._n)
А в класс
QRegister добавим операцию применения гейта:def apply(self, gate):
assert isinstance(gate, QGate)
assert self._n == gate._n
self._data = gate._data @ self._data
И создадим уже известные нам гейты:
I = QGate([[1, 0], [0, 1]])
H = QGate(np.array([[1, 1], [1, -1]]) / np.sqrt(2))
X = QGate([[0, 1], [1, 0]])
Y = QGate([[0, -1j], [1j, 0]])
Z = QGate([[1, 0], [0, -1]])
Орёл или решка?

Давайте для примера рассмотрим простейший квантовый алгоритм: он будет генерировать случайный бит — ноль или один, орла или решку. Это будет самая честная монета во вселенной — результат станет известен лишь при измерении, а природа случайности зашита в само основание вселенной и повлиять на неё невозможно никоим образом.
Для алгоримта нам понадобится всего один кубит. Пусть в начальный момент времени он находится в состоянии
Теперь применим к нему гейт Адамара
Если мы сейчас измерим полученную систему, с вероятностью
Проверим алгоритм, эмулируя его на нашем классическом компьютере:
from quantum import QRegister, H
def quantum_randbit():
a = QRegister(1, '0')
a.apply(H)
return a.measure()
for i in range(32):
print(quantum_randbit(), end='')
print()
Результаты:
? python example-randbit.py
11110011101010111010011100000111
? python example-randbit.py
01110000111100011000101010100011
? python example-randbit.py
11111110011000001101010000100000
Весь приведённый выше алгоритм может быть записан парой формул:
Однако, с такой записью не очень удобно работать: структура списка — последовательности действий, хорошо подходящая для классических алгоритмов, не применима в квантовом случае: здесь у нас нет ни циклов, ни условий, лишь течение состояния вперёд (а иногда и назад) во времени. Поэтому для описания алгоритмов в квантовой информатике широко используются квантовые схемы. Вот схема приведённого выше алгоритма:
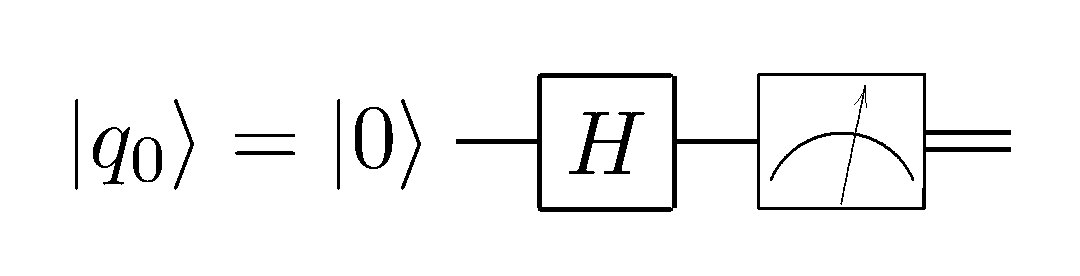
Слева всегда обозначено исходное состояние системы. В прямоугольниках указываются унитарные преобразования, производимые над этим состоянием, а в конце на всех или на нескольких кубитах распологается значок измерительного прибора — операция измерения. Существует ещё «синтаксический сахар» для некоторых многокубитных преобразований в виде точек, разветвлений и кружочков. И всё. Если вы умеете отличать квадрат от треугольника и круга, вы без проблем поймёте любую схему квантового алгоритма.

Больше кубитов богу кубитов
А что, если мы работаем не с одним кубитом, а с целым их регистром? И, допустим, хотим применить гейт лишь к одному кубиту? На помощь приходят свойства тензорного произведения. По определению тензорного произведения оператора
где
то есть, всё равно — применить ли гейт к одному кубиту, а затем связать его со вторым и получить квантовый регистр или же применить ко всему регистру оператор
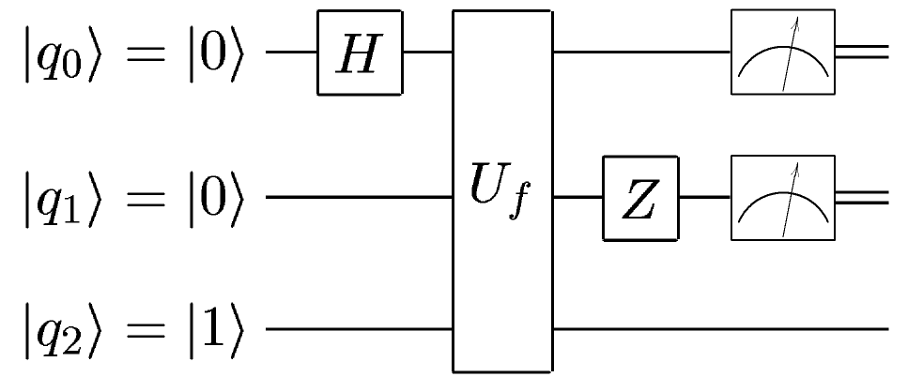
Полностью аналогична такой:
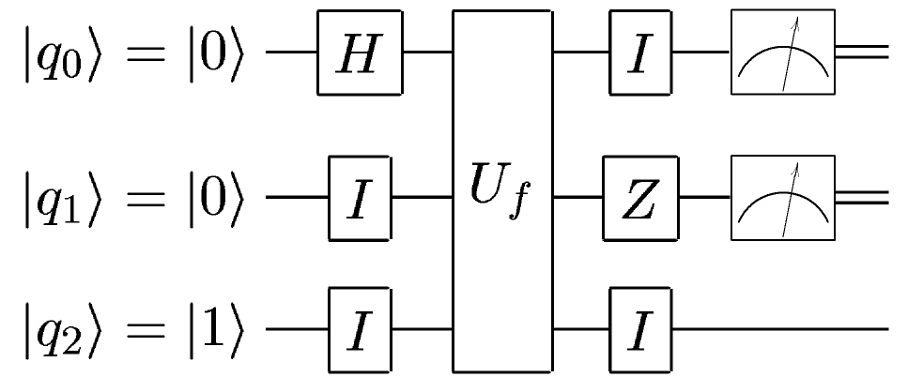
Только единичные гейты для удобства опускают.
А если мы, наоборот, хотим применить гейт сразу к нескольким кубитам? Опять же, из определения тензорного произведения, для этого мы можем применить к ним этот гейт, тензорно умноженный сам на себя необходимое количество раз:
означает: к каждому кубиту квантового регистра из
Добавим тензорное произведение и возведение в степень в наш
QGate:def __matmul__(self, other):
return QGate(np.kron(self._data, other._data))
def __pow__(self, n, modulo=None):
x = self._data.copy()
for _ in range(n - 1):
x = np.kron(x, self._data)
return QGate(x)
Квантовый оракул
Каждой бинарной функции
Почему его размерность
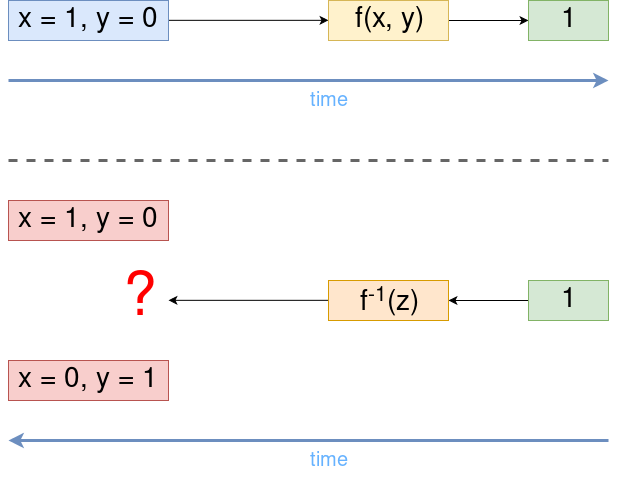
Один из способов избежать этого — запомнить аргументы, с которыми была вызвана функция.

То же самое происходит и в квантовой модели вычислений, только там оно встроено в саму их природу — без сохранения полной информации невозможно построить унитарное преобразование.
Квантовый оракул
Разберёмся на примере. Допустим, мы хотим построить оракул для функции одного аргумента
Оператор с единичной матрицей переводит любое состояние в себя же, так как при умножении матрицы на
Проверим:
Аналогично для любой другой функции произвольного числа аргументов. Реализуем оракл:
def U(f, n):
m = n + 1
U = np.zeros((2**m, 2**m), dtype=np.complex64)
def bin2int(xs):
r = 0
for i, x in enumerate(reversed(xs)):
r += x * 2 ** i
return r
for xs in product({0, 1}, repeat=m):
x = xs[:~0]
y = xs[~0]
z = y ^ f(*x)
instate = bin2int(xs)
outstate = bin2int(list(x) + [z])
U[instate, outstate] = 1
return QGate(U)
Still remains
Ну вот мы и рассмотрели весь базис, который необходим для решения поставленной задачи и даже успели написать небольшой фреймворк на питоне, который нам поможет это решение проверить. Алгоритм, позволяющий за один вызов функции определить, константна функция или сбалансирована, именуется алгоритмом Дойча — Йожи. Версия алгоритма для функции одной переменной была разработанна в 1985 году Дэвидом Дойчем, а затем обобщёна на случай нескольких переменных в 1992 году с помощью Ричарда Йожи. Вот схема этого алгоритма:
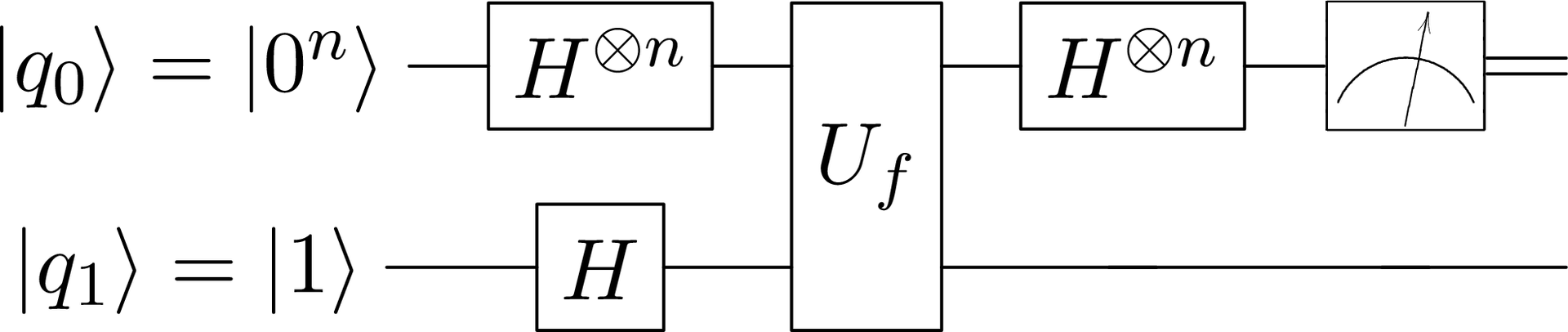
Если результатом измерения станет 0, то функция константна, иначе — сбалансирована. Сразу реализуем алгоритм:
from quantum import QRegister, H, I, U
def is_constant(f, n):
q = QRegister(n + 1, '0' * n + '1')
q.apply(H ** (n + 1))
q.apply(U(f, n))
q.apply(H ** n @ I)
if q.measure()[:~0] == '0' * n:
return True
else:
return False
И проверим:
def f1(x):
return x
def f2(x):
return 1
def f3(x, y):
return x ^ y
def f4(x, y, z):
return 0
print('f(x) = x is {}'.format('constant' if is_constant(f1, 1) else 'balansed'))
print('f(x) = 1 is {}'.format('constant' if is_constant(f2, 1) else 'balansed'))
print('f(x, y) = x ^ y is {}'.format('constant' if is_constant(f3, 2) else 'balansed'))
print('f(x, y, z) = 0 is {}'.format('constant' if is_constant(f4, 3) else 'balansed'))
Результат:
f(x) = x is balansed
f(x) = 1 is constant
f(x, y) = x ^ y is balansed
f(x, y, z) = 0 is constant
Работает. Замечательно. А почему он работает? Докажем корректность алгоритма и заодно посмотрим на принцип его работы.
Рассмотрим действие гейта
(по свойству тензорного произведения)
(применим к каждому отдельному кубиту)
(вынесем -1 за знак тензорного произведения)
(переобозначим для компактности)
где
В начальный момент времени система находится в состоянии
Оракул
Заметьте, что если на некотором фиксированном аргументе
На данном этапе отбросим неиспользуемый далее последний кубит и применим повторное преобразование Адамара к первым
А так как
Вот и всё. Мы рассмотрели достаточно упрощённую модель квантовых вычислений, написали мини-фреймворк на питоне для их эмуляции на классическом компьютере и разобрали один из самых простых «настоящих» квантовых алгоритмов — алгоритм Дойча-Йожи. Вот котик для тех, кто не поленился, прочитал статью и разобрался в теме:

> С кодом можно ознакомиться на GitHub
Спасибо за прочтение! Ставьте лайки, подписывайтесь на профиль, оставляйте комментарии, занимайтесь полезными делами. Дополнения приветствуются.
Литература
- [1] М. Вялый, «Квантовые алгоритмы: возможности и
ограничения»
- [2] А. С. Холево, «Введение в квантовую теорию информации»
- [3] M. A. Nielsen, «Quantum Information Theory»
P.S: Формулы на хабре — отстой. Спасибо Roman Parpalak за сервис upmath.me, без него пост с таким количеством формул был бы невозможен.
Комментарии (61)

izac
06.02.2017 22:35+6[irony] Возьму константную, срублю сбалансированную, сам сяду и фронтендера посажу. [/irony]


skyramp
07.02.2017 00:01+3и все-таки, в момент появления оракула сразу возникает вопрос о том, что таки понимается в этом случае под сложностью алгоритма, почему она осталась O(1) и как должна быть задана функция f на вход алгоритму так, чтобы при этом ее вычисление было более затратно нежели сама подача представления этой функции на вход алгоритму?

devpony
07.02.2017 10:15+1Ну допустим, прилетели инопланетяне с альфы центавра и сказали: «Вот вам функция. Если она константная, то мы вас уничтожим, если сбалансированная — вам повезло.» И дали чёрный ящик с входом и выходом для пучка электронов. Классическая версия, говорят, тоже есть, но она дома, шлите туда запросы: 5 лет в одну сторону, 5 обратно.
Про возможность построения оракулов — это скорее к физикам. У нас есть прекрасная стройная теория, в которой можно использовать любые необходимые нам объекты классического мира в виде оракулов и мы ей пользуемся, не заботясь особо о практической реализации. Существуют алгоритмы, где оракул можно заранее вычислить на классическом компьютере и уже с его помощью решать гораздо более сложную задачу в квантовой модели.
Возвращаясь к вашему вопросу. С помощью базовых логических квантовых элементов можно построить произвольную булеву функцию. Допустим, у нас есть функция 1010 аргументов. Но мы так же знаем, как без вычислений функции построить её квантовый оракул из логических элементов. Тогда квантовый алгоритм окажется предпочтительным.
Алгоритм Дойча-Йожи — не самый лучший пример решения практически важных задач, однако он крайне интересен с теоретической точки зрения, позволяет показать все возможные преимущества квантового подхода и идеален для первого знакомства с квантовыми вычислениями в силу своей простоты.
GlukKazan
07.02.2017 12:33+2«Вот вам функция. Если она константная, то мы вас уничтожим, если сбалансированная — вам повезло.»
Вот, именно при такой постановке задачи, по завету товарища Сухова, стоило бы помучиться с отсылкой запросов классической версии. Вдруг функция сбалансированная?
Классическая версия, говорят, тоже есть, но она дома, шлите туда запросы: 5 лет в одну сторону, 5 обратно.

dougrinch
07.02.2017 04:58-1Спасибо, было интересно, но понять так и не смог. Сдался чуть позже середины. В итоге решил скопипастить код и посмотреть просто посмотреть что будет. Ожидаемо, чуда не случилось. В эмуляторе функция вызывается с полным перебором всех возможных аргументов.


aso
07.02.2017 08:10+2Сначала говорили про «функцию можно вызывать только один раз» — а потом оказалось, что вызовов будет много.
Как только появляется слово «квантовая» — так сразу же начинается всяческая фигня и самозапутывание…
funca
07.02.2017 09:02+4Тут с пассажа про стулья уже было ясно, что автор, тензор ему в глаз, читателя за
фронтендерафраера принял :)
devpony
07.02.2017 10:18Вызовов много лишь при эмуляции: ведь у нас с вами нет квантового компьютера. В самом алгоритме вызов функции один — применение квантового оракула.
aso
07.02.2017 14:33В самом алгоритме вызов функции один — применение квантового оракула.
Э-ээ, а разве «вызов» в квантовых вычислениях эквивалентен вызову функции в обычных тьюринговых машинах? Что-то, как я понял — квантовый оракул сразу порождает ответы для всех значений входного вектора.
Ни?devpony
07.02.2017 14:46+1Конечно, «вызов» стоило взять в кавычки. Мы один раз получаем от оракула всю информацию о функции. Но чтобы построить оракул, совсем не обязательно вычислять классическую функцию: он может быть построен из логических элементов, может быть дан свыше, может быть найден в природе и т.д. В настоящем квантовом компьютере мы не будем вычислять и знать матрицу оракула, это будет некоторый физический объект с требуемыми нам свойствами, который переведёт нашу квантовую систему в нужное состояние. А для эмуляции квантовых вычислений, конечно, необходимо вызвать функцию на всех аргументах и построить оракул в явном виде.
skyramp
07.02.2017 18:05+1а на возникает тут сразу проблема следующего вида: вот дан черный ящик, нам сказали (или нам кажется) что этот ящик это оракул для функции f. как быстро можно проверить что черный ящик — действительно оракул для f и с какой точностью?
devpony
08.02.2017 01:14+1Ну, если оракул задан набором логических операторов, то достаточно легко. В любом другом случае, скорее всего, никак. Не стоит относиться к описанному алгоритму как к практически значимому :) У нас ещё квантовых компьютеров всего пара штук на всей Земле, а вы уже возмущаетесь, что мы оракулы строить и верифицировать не умеем…
alexzzam
07.02.2017 19:34Тогда и вовсе непонятно.
Операторы/гейты физически это что? Прибор, сигнал, ритуал?
В каком вообще сценарии без инопланетян мы можем получить интересный нам оракул для неизвестной нам функции?Kobalt_x
07.02.2017 19:51Оракул это просто линейный оператор параметризованный этой функцией.
|x,y>->|x,y + f(x)>.
Как оно реализовано в природе вообще говоря не важно. Говоря языком "фронтендера" оракул это нечто реализуете api указанное выше.
В задаче дойча-йожи да нужен оракул для произвольной функции.
Но есть задачи в которых функция оракула известна заранее, тогда просто реализуют такой оператор, что, вообще говоря, тоже не всегда просто.
funca
07.02.2017 21:26-1Пока все это напоминает историю с аналоговыми компьютерами и холодным термоядерным синтезом. Математики мамой клянутся, что давно просекли тему: пять минут страха, кропаль каких-то ярдов денег и, пацаны, вы в доле, все будет в шоколаде!
Но на практике попытки реализации упираются в очередное дурацкое несовершенство физического мира, с его инерционностями, нелинейностями и тому подобными гадостями. Пока еще ни кто не доказал, что физический квантовый мир обладает всеми нужными свойствами, каким его представляет себе модель КК, и из этой затеи выйдет что-то полезное.
aso
08.02.2017 07:26-1Но чтобы построить оракул, совсем не обязательно вычислять классическую функцию: он может быть построен из логических элементов, может быть дан свыше, может быть найден в природе и т.д.
Квантовый оракул не может быть построен из логических элементов, бо они — не квантовые.
Не подчиняются (на макроуровне) волновому уравнению Шредингера, и не нуждаются в волновой пси-функции для своего описания.
В настоящем квантовом компьютере мы не будем вычислять и знать матрицу оракула, это будет некоторый физический объект с требуемыми нам свойствами, который переведёт нашу квантовую систему в нужное состояние.
Вот смотрите:
— Вы рассматриваете логическую функцию. Для представления её результата достаточно одного бита, в случае квуантовых вычислений — простого кубита с двумя состояниями, к которому применяются соотв. унитарные преобразования для получения результата вычислений.
— квантовый оракул для своего представления требует n (или n+1, мне ломы разбираться, где n — число аргументов) простых кубитов, к которым дважды применяется преобразование Адамара + наша искомая функция.
Но таким образом получается, что реально наша функция вычисляется как минимум n раз — только в параллель.
Но что мешает нам взять ПЛМ-ку сделать то же самое — и причём тут «квантовые вычисления»?devpony
08.02.2017 14:31Квантовый оракул не может быть построен из логических элементов, бо они — не квантовые.
Не подчиняются (на макроуровне) волновому уравнению Шредингера, и не нуждаются в волновой пси-функции для своего описания.Естественно, в контексте квантовых вычислений речь идёт о квантовых логических элементах. Вот например, функция
f(x) = xиз статьи может быть выражена с помощью одного гейта CNOT:

А вот
f(x) = ~x:

Аналогично выражается любая логическая функция любого количества переменных. Доказано, что это возможно с помощью универсального гейта Тоффоли:

Но таким образом получается, что реально наша функция вычисляется как минимум n раз — только в параллель.
Нет, не получается.
Но что мешает нам взять ПЛМ-ку сделать то же самое
Вам мешает то, что в классической модели понадобится не n, а 2^n вычислений.
skyramp
08.02.2017 14:51но не получится ли так, что понять ответ в искомой задаче можно будет с меньшей сложностью просто посмотрев на структуру и связи используемых логических элеменов в этой функции, без необходимости запускать функцию вообще?
devpony
08.02.2017 14:57Нет — задача выполнимости булевых формул NP-полная. Кстати, квантовые алгоритмы и её ускоряют, но это уже другая история)
skyramp
08.02.2017 15:05но ведь решаемая задача — не задача о выполнимости, ибо тут очень сильно сужен класс рассматриваемых функций. она вообще остается NP-полной для выбранного класса функций?
devpony
08.02.2017 15:13Я не знаю никаких способов по виду функции определить константна она или сбалансирована и сомневаюсь, что это возможно, не вычисляя её. А задача о выполнимости, конечно, остаётся NP-полной для функций только константных или сбалансированных: ведь указанное свойство никак не коррелирует с видом функции.
skyramp
08.02.2017 16:28вы уверены? потому что если еще чуть-чуть сузить класс функций (например, до только константных), то задача вроде бы сразу превращается в полиномиальную. да и если подходить с другой стороны, вы привели пример вероятностного алгоритма решения задачи (который за 14 итераций), точность которого не зависит от размерности задачи. если решаемая задача NP-полна, то возможно этот алгоритм можно эффективно применять и для других NP-полных задач, в частности для задачи ВЫП в классе произвольных функций?
devpony
08.02.2017 18:30Не уверен. Ни в чём нельзя быть уверенным, пока это не доказано. О вероятностных алгоритмах решения задачи выполнимости тоже не слышал и не представляю, как они могли бы работать в общем случае.
aso
09.02.2017 12:34-1Нет, не получается.
Ну т.е. Вы вычисляете результат размером в кубит на n простых кубитов — но утверждаете, что «вычисления производятся только один раз»?
Удивительно.
Вам мешает то, что в классической модели понадобится не n, а 2^n вычислений
Да, но «классическая» модель в этом случае даёт детерминированный результат, а Ваша квантовая — только вероятностный.devpony
09.02.2017 12:50Да, но «классическая» модель в этом случае даёт детерминированный результат, а Ваша квантовая — только вероятностный.
В статье описан детерминированный квантовый алгоритм.
aso
10.02.2017 10:21-1Теперь Вы ещё и понятие «детерминированности» под себя переопределяете…
devpony
10.02.2017 13:32+2Алгоритм детерменированный, если для одинаковых входных данных он всегда производит одинаковый результат. Насколько я знаю, это достаточно общепринятое определение и алгоритм Дойча-Йожи ему удовлетворяет.
aso
10.02.2017 15:08-1В квантовой механике существуют принципиально не-стохастические решения? 0_0
devpony
10.02.2017 16:15Причём тут это, если мы обсуждаем детерменированность алгоритма? Это понятие из информатики, а не механики и применимо к любому алгоритму, в том числе и квантовому.
Какая разница, какие процессы происходят в основе, если они всегда приводят к детерминированному результату, что может быть доказано (и доказано в конце статьи)? Вопрос риторический, можно не отвечать. Эта ветка ушла уже далеко от темы статьи.
aso
13.02.2017 07:34-3Какая разница, какие процессы происходят в основе, если они всегда приводят к детерминированному результату
Шта-эээ? o_0 0_0 0_0
Молодой человек, Вы как-бы самые основы своей предметной области поизучать не пробовале? Дабы, чиста па-приколу — открыть для себя некоторые элементарные вещи в области квантмеха.
Ато неудобно как-то, ей-богу.
SmallSharky
07.02.2017 10:34Я правильно понимаю, что описанное бессмысленно при таком подходе:
1)Выполняем обе функции по одному разу;
2)Записываем два полученных булевых значения. Предположим, что получили i в первом случае и k во втором(вместо i, k подставить любое число являющееся 0 или 1);
3)Скармливаем эти(и только эти) полученные значения некоторому квантовому алгоритму;
4)Получаем ответ о типе функции.
?devpony
07.02.2017 10:36Я не очень понял ваш вопрос. Алгоритм позволяет узнать тип только одной функции по её квантовому представлению — оракулу.
Space_Cowboy
07.02.2017 10:44+12
yorko
09.02.2017 15:06+1Вам с самых основ рассказывают про математику, которая стоит за (возможно) самой перспективной технологией. Ну а пока пусть "Очень сложно. До свидания" набирает лайки.

igrishaev
07.02.2017 11:00-5Что, нельзя было без бредовых картинок?
dieworld
07.02.2017 11:59-8Можно немножко не по теме вопрос: у вас в профиле написано, что вы делите трехзначные числа на ноль. Вы что, не знаете, что на ноль делить нельзя? Зачем себя публично дураком выставлять?
//я надеюсь, вы поймете, что мой комментарий не следует воспринимать буквально.

Phaker
08.02.2017 11:19+1Картинки, песня, два стула — хорошо.
Python 3.5 и 3.6 вообще отлично:
gate._data @ self._data f'{mstate:>0{self._n}b}'
Но вот это уже пижонство и перебор:
x = xs[:~0] y = xs[~0]devpony
08.02.2017 12:40+4Оригинальный синтаксис питона в этом плане ужасен. Если я хочу получить третий элемент с начала, я пишу
xs[3], а если с конца —xs[-4]. Чувствуете неконсистентность? А если использовать синтаксисxs[~i], всё становится прекрасно и логично. И больше не надо беспокоиться, что забыл единицу в индексах вродеxs[-(i + j - 4)]. Я такой приём увидел где-то в комментариях на хабре и с тех пор не могу нарадоваться. И пишу так везде, чтобы подтолкнуть народ к красивой и консистентной индексации. Пора этот приём в учебники по питону добавлять.


qbertych
07.02.2017 11:48+1Наконец-то статья с нормальным описанием квантового алгоритма на Хабре!
Черт, у меня уже давно лежал черновик ликбеза по квантовым вычислениям — и на треть он совпадает с вашей статьей, ааааа! Будет урок на будущее слоупоку. Думаю, подправлю немного и в обозримом будущем выложу на ГТ.
yorko
07.02.2017 11:55В самом начале про классическое детерминированное решение:
Если все вычисленные значения одинаковы, то функция, очевидно, константна
Как-то неочевидно. Применяем к логическому И – функция не константна и не сбалансирована (3 пример чуть до этого).
Прошли половину + 1 аргументов – первые три пары, везде ответ 0. Но функция не константная.Jigglypuff
07.02.2017 12:02+4Пусть дана булева функция f и о ней априорно известно, что она или константна, то есть для любого из своих аргументов всегда возвращает либо 0, либо 1, или сбалансирована, то есть ровно на половине своих аргументов возвращает 0, а ровно на половине 1.
Логическое И не проходит по предусловию. Соответственно, если больше чем на половине входов возвращается одно значение, то функция может быть только константной.
devpony
07.02.2017 12:07+1В условии задачи априорно известно, что функция либо константная, либо сбалансированная. Это наше ограничение на входные данные. С функциями не константными и не сбалансированными все предложенные алгоритмы не работают и выдают, если так угодно, случайный результат. Конъюнкцию я привёл как раз как пример «плохой» функции.
Phaker
07.02.2017 14:46+1У меня про сферу Блоха вопрос. Понятно, что полезно покопаться в учебниках, но вдруг и одного комментария хватит для понимания. Википедия говорит, что на сфере находятся только чистые состояния квантовой системы, а смешанные внутри. Можно привести примеры чистых состояний (кроме |0> и |1>) и их взаимное расположение на сфере? А также примеры смешанных и где они находятся внутри.
qbertych
07.02.2017 18:26+1|0>±|1>, например, чистые. Если |0> — горизонтальная поляризация фотона, а |1> — вертикальная, то |0>±|1> — круговые (соответственно, левая и правая).
Смешанные состояния — это в духе "фотон поляризован то ли горизонтально, то ли вертикально". Не путать с круговой поляризацией, которая "одновременно" и горизонтальная, и вертикальная.
Разницу хорошо видно, если взять несколько фотонов. Все фотоны в чистом состоянии |0>+|1> будут одинаковыми, а в ансамбле смешанных половина будет горизонтальной, половина — вертикальной.

Shador
07.02.2017 20:49Не понял как в определении оператора <фи у нас получается скалярное произведение элемента Н на элемент Н*: (<фи|, |пси>). Это скалярное произведение какого из двух пространств?
Заранее спасибо за объяснение. Статья выглядит просто волшебной.devpony
08.02.2017 00:05+1Давайте каждому вектору x сопоставим такую функцию: f(y) = (y, x) — скалярное произведение на этот вектор. Можно считать, что мы «зафиксировали» второй аргумент или частично применили функцию скалярного произведения. Каждому вектору будет сопоставлена единственная такая функция. И каждая такая функция будет линейным оператором, поэтому всё их множество будет содержаться в множестве линейных операторов — сопряжённом пространстве. А теперь мы обозначим каждую такую функцию бра-вектором, внутри которого записан «зафиксированный» аргумент. Таким образом, запись <x|y> — скалярное произведение x на y в оригинальном пространстве кет-векторов, записанное в непривычной форме, но имеющее под собой чёткое обоснование.
В рамках данной статьи такое обозначение не несло никакого дополнительного смысла и его можно было бы и вовсе не использовать, однако оно общепринято в квантовой информатике, поэтому я и попытался его объяснить.
dpplgngr
08.02.2017 00:13+1Итак, не понял утверждение
Теперь можно сделать важную поправку: квантовую систему может описывать не любое гильбертово пространство, а лишь такое, что
…
то есть норма каждого элемента равна единице.
В любом гильбертовом пространстве есть вектора с любой вещественной нормой, так как вектор можно умножать на любую действительную константу, и норма умножится соответствующим образом.
dpplgngr
09.02.2017 01:34+2Если мы выделим в нашем гильбертовом пространстве состояний некоторый базис
Обязательно ортонормированный базис, иначе вместо простой суммы со скалярными произведениями в коэффициентах надо будет систему уравнений решать.
представляет из себя трёхмерную сферу
Тут, вероятно, стоит прояснить, что трехмерная сфера — это не самая обыкновенная сфера в трехмерном пространстве, а все-таки поверхность размерности 3 в четырехмерном пространстве над действительными числами, порожденном двумя парами коэффициентов, задающими числа альфа и бета. Картинка с обычной сферой тоже сбивает на представление об обычной сфере :) По крайней мере, мне показалось что вы подразумеваете такую сферу, иначе по размерности никак не вяжется…

Jigglypuff
Это очень круто. Спасибо!