
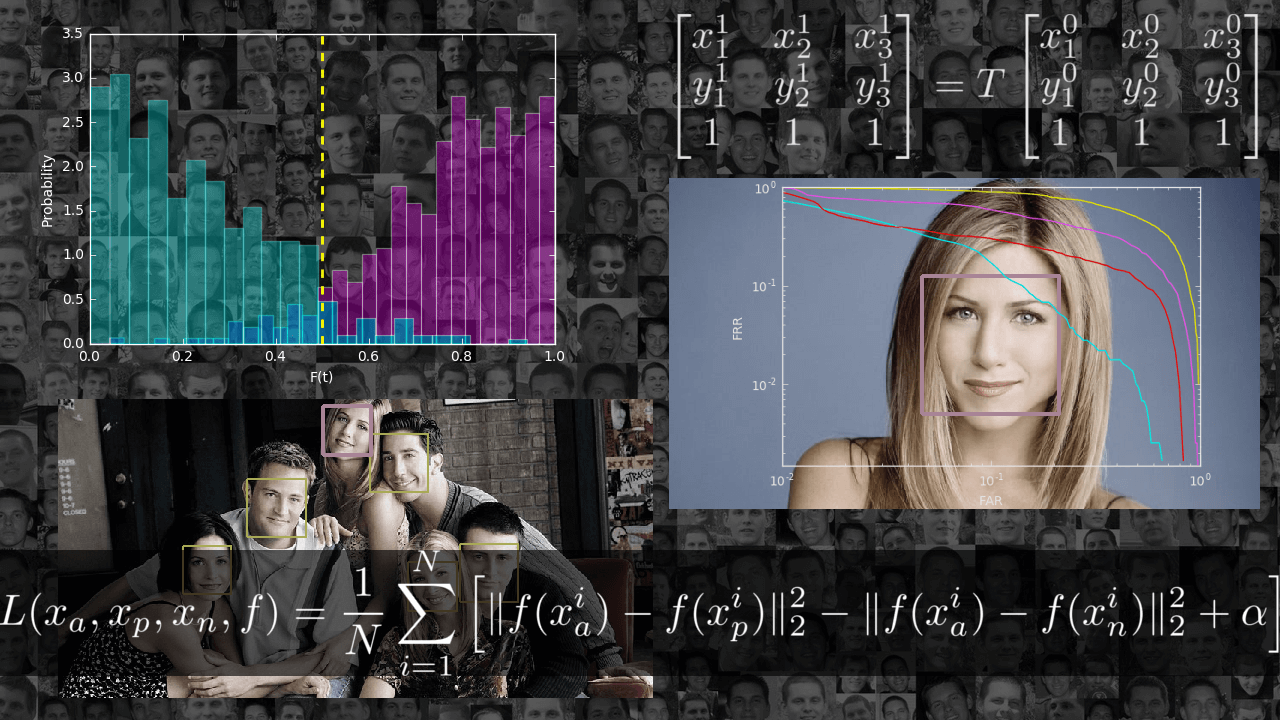
В статье я хочу познакомить читателя с задачей идентификации: пройтись от основных определений до реализации одной из недавних статей в данной области. Итогом должно стать приложение, способное искать одинаковых людей на фотографиях и, что самое главное, понимание того, как оно работает.
Идентификация Борна (и не только Борна)

Задача идентификации схожа с задачей классификации и исторически возникла из неё, когда вместо определения класса объекта необходимо стало уметь определять, обладает объект требуемым свойством или нет. В задаче идентификации обучающая выборка представляет собой набор объектов

Например, если требуется отделить лица людей от лиц обезьян, то это задача классификации — имеются два класса, для каждого объекта можно указать класс и сделать репрезентативную выборку из обоих классов. Если требуется определить какому человеку принадлежит изображение лица и люди эти — конечное фиксированное множество, то это тоже задача классификации.
А теперь представьте, что вы разрабатываете приложение, которое должно определять человека по фотографии его лица, причём множество запомненных в базе людей постоянно меняется и, естественно, во время использования приложение будет видеть людей, которых не было в обучающем множестве — реальная задача, которой в современном мире уже никого не удивишь. Однако, она уже не сводится к задаче классификации. Как же её решать?
Чтобы уметь узнавать человека, необходимо его хотя бы раз увидеть. А точнее, иметь хотя бы одну его фотографию или запомнить её в форме некоторого образа. Тогда, когда нам покажут новую, неизвестную доселе фотографию, мы сравним её со всеми запомненными образами и сможем дать ответ: видели мы уже этого человека и можем его идентифицировать или же этот человек нам ещё ни разу не встречался и мы можем разве что его запомнить. Таким образом изложенная выше задача сводится к следующей: имея две фотографии
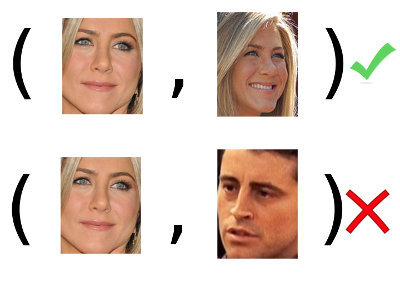
Вот и определение задачи идентификации: по обучающей выборке (в примере: множество пар лиц
Поставим последнюю задачу из примера чуть более формально и героически её решим, позвав на помощь arxiv.org, Python и Keras. Фотографии лица — матрицы из
Превосходство Борна
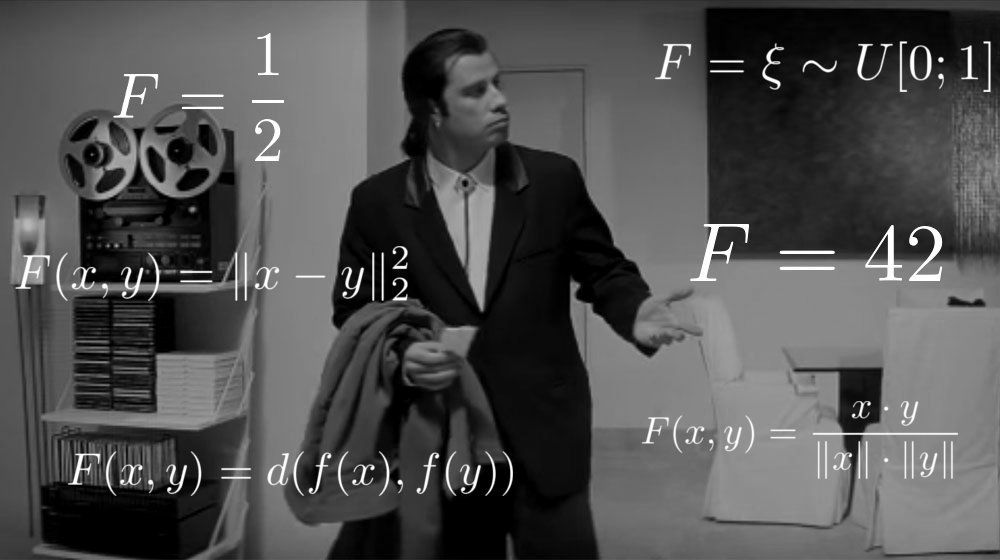
Что важнее всего в решении задач машинного обучения? Думаете, умение искать ответ? Нет, главное — умение этот ответ верифицировать. Функция
Давайте введём понятие target-попытки и imposter-попытки. Первым мы назовём объект
Теперь возьмём нашу построенную функцию
Так она выглядит для

Согласитесь, толку от такого идентификатора немного — в половине случаев он будет угадывать ответ, а в половине — ошибаться.
Такое распределение нам уже больше подходит:
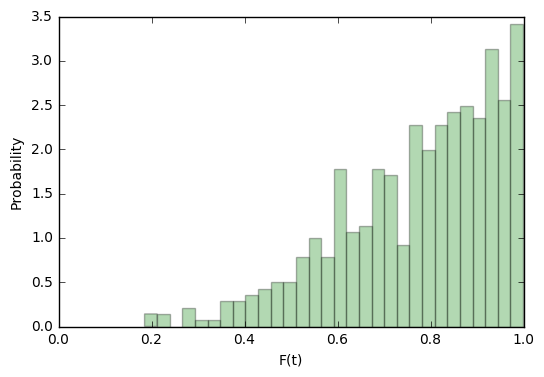
Для target-попыток такая функция будет скорее уверена в их правильности, чем нет.
Но рассмотрение распределения таргетов без распределения импостеров бессмысленно. Проделаем ту же операцию и для них: построим плотность распределения

Становится видно, что для imposter-попыток наша функция будет в большинстве случаев склоняться к правильному ответу. Но это всё ещё лишь визуальные наблюдения, они не дают нам никакой объективной оценки.
Допустим, нашей системе на вход подаётся пара изображений. Она может посчитать для них вероятность того, что это target-попытка. Но требуется от неё однозначный ответ: один и тот же это человек или нет, пускать его на секретный объект или нет. Давайте зададимся некоторым порогом
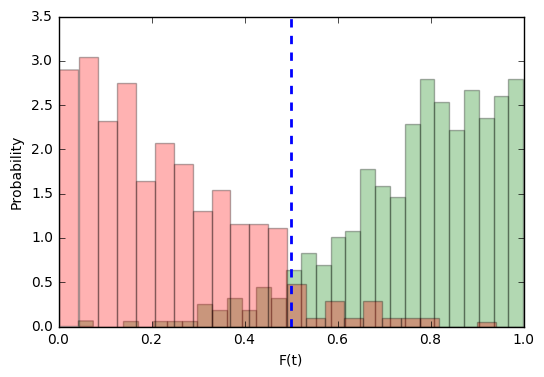
В скольких случаях наша система будет ошибаться при target-попытках? Легко посчитать:
- FRR (False Rejection Rate) — доля неправильно отклонённых target-попыток.
- FAR (False Acceptance Rate) — доля неправильно принятых imposter-попыток.
Давайте теперь зададимся некоторым шагом
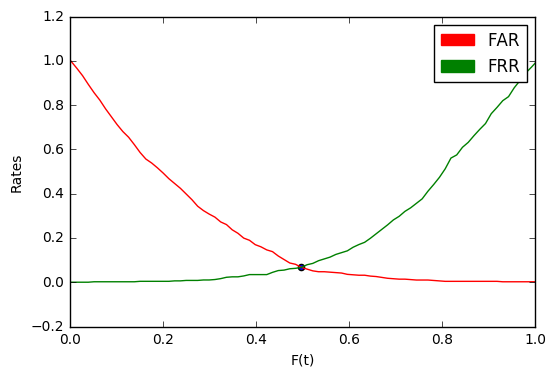
Теперь для любого выбранного расстояния можно сказать, какая доля target-попыток будет отклоняться и какая доля imposter-попыток приниматься. И наоборот, можно выбирать
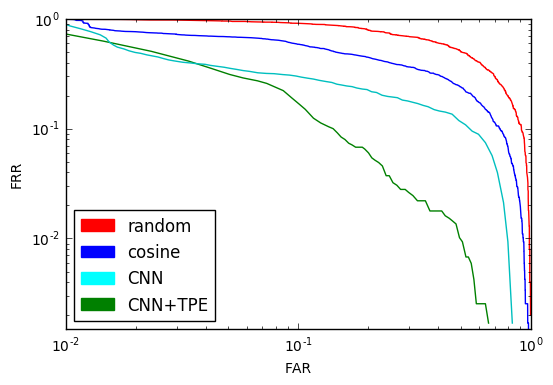
Обратите внимание на точку пересечения графиков. Значение в ней называется EER (Equal Error Rate).
Если мы выберем
В примере выше EER = 0.067. Значит, в среднем 6.7% всех target-попыток будет отклоняться и 6.7% всех imposter-попыток — приниматься.
Ещё одним важным понятием является DET-кривая — зависимость FAR от FRR в логарифмическом масштабе. По её форме легко судить о качестве системы в целом, оценивать какое значение одного критерия можно получить при фиксированном втором, и, что самое главное, сравнивать системы.

ERR здесь — пересечение DET-кривой с прямой
Наивная реализация на Python (можно более оптимально, если учесть, что FAR и FRR меняются только в точках из
import numpy as np
def calc_metrics(targets_scores, imposter_scores):
min_score = np.minimum(np.min(targets_scores), np.min(imposter_scores))
max_score = np.maximum(np.max(targets_scores), np.max(imposter_scores))
n_tars = len(targets_scores)
n_imps = len(imposter_scores)
N = 100
fars = np.zeros((N,))
frrs = np.zeros((N,))
dists = np.zeros((N,))
mink = float('inf')
eer = 0
for i, dist in enumerate(np.linspace(min_score, max_score, N)):
far = len(np.where(imposter_scores > dist)[0]) / n_imps
frr = len(np.where(targets_scores < dist)[0]) / n_tars
fars[i] = far
frrs[i] = frr
dists[i] = dist
k = np.abs(far - frr)
if k < mink:
mink = k
eer = (far + frr) / 2
return eer, fars, frrs, dists
С контролем разобрались: теперь, какую бы функцию
Важно: в задачах идентификации то, что мы выше называли валидационным множеством, принято называть development set (development-множество, devset). Будем придерживаться этого обозначения и в дальнейшем.
Важно: так как любой интервал вещественной оси
Подготовка базы
Существует множество датасетов для распознавания лиц. Некоторые платные, некоторые выдаются по запросу. Некоторые содержат большую вариативность по освещению, другие — по положению лица. Некоторые сняты в лабораторных условиях, другие собраны из фотографий, снятых в естественной среде обитания. Чётко сформулировав требования к данным, можно легко выбрать подходящий датасет или собрать его из нескольких. Для меня в рамках данной учебной задачи требования были таковы: датасет должен быть легко доступен для скачивания, содержать не очень много данных и содержать вариативность по положению лица. Требованиям удовлетворили три набора данных, которые я объединил в один:
Все они давно устарели и не позволяют построить качественную современную систему распознавания лиц, но для обучения они идеальны.
В полученной таким образом базе оказалось 277 субъектов и ~4000 изображений, в среднем по 14 изображений на человека. Возьмём 5-10% субъектов для development-множества, остальных используем для обучения. Система при обучении должна видеть лишь примеры из второго множества, а проверять её (считать EER) мы будем на первом.
Код для разделения данных доступен по ссылке. Необходимо лишь указать путь до распакованных датасетов, перечисленных выше.
Теперь данные необходимо предобработать. Для начала, выделить лица. Сами мы этим заниматься не будем, а используем библиотеку dlib.

import dlib
import numpy as np
from skimage import io
image = io.imread(image_path)
detector = dlib.get_frontal_face_detector()
face_rects = list(detector(image, 1))
face_rect = face_rects[0]

Как видите, используя эту библиотеку, можно получить ограничивающий лицо прямоугольник за пару строчек кода. И работает детектор dlib, в отличии от OpenCV, очень хорошо: из всей базы лишь десяток лиц он не смог обнаружить и не создал ни одного ложного срабатывания.
Формальная постановка нашей задачи подразумевает, что все лица должны быть одного размера. Удовлетворим это требование, заодно выровняв все лица так, чтобы ключевые точки (глаза, нос, губы) всегда находились в одном и том же месте изображения. Ясно, что такая мера может нам помочь безотносительно выбранного способа обучения и уж точно не навредит. Алгоритм прост:
- Имеются априорные положения ключевых точек в единичном квадрате.
- Зная выбранный размер изображения, рассчитаем координаты этих точек на нашем изображении простым масштабированием.
- Выделим ключевые точки очередного лица.
- Построим аффинное преобразование, переводящие второй набор точек в первый.
- Применим аффинное преобразование к изображению и обрежем его.
Эталонное положение ключевых точек найдём в примерах к dlib (face_template.npy, скачать здесь).
face_template = np.load(face_template_path)Для поиска ключевых точек на изображении лица опять-же воспользуемся dlib, используя уже обученную модель, которую можно найти там-же, в примерах (shape_predictor_68_face_landmarks.dat, скачать здесь).
predictor = dlib.shape_predictor(dlib_predictor_path)
points = predictor(image, face_rect)
landmarks = np.array(list(map(lambda p: [p.x, p.y], points.parts())))Аффинное преобразование однозначно задаётся тремя точками:
INNER_EYES_AND_BOTTOM_LIP = [39, 42, 57]
Пусть
Найдём его:
proper_landmarks = 227 * face_template[INNER_EYES_AND_BOTTOM_LIP]
current_landmarks = landmarks[INNER_EYES_AND_BOTTOM_LIP]
A = np.hstack([current_landmarks, np.ones((3, 1))]).astype(np.float64)
B = np.hstack([proper_landmarks, np.ones((3, 1))]).astype(np.float64)
T = np.linalg.solve(A, B).T
И применим к изображению с помощью библиотеки scipy-image:
import skimage.transform as tr
wrapped = tr.warp(
image,
tr.AffineTransform(T).inverse,
output_shape=(227, 227),
order=3,
mode='constant',
cval=0,
clip=True,
preserve_range=True
)
wrapped /= 255.0

Полный код препроцессинга, обёрнутый в удобный api, можно найти в файле preprocessing.py.
Финальным аккордом подготовки данных станет нормализация: посчитаем среднее и стандартное отклонение по базе обучения и нормируем каждое изображение на них. Не забудем и про development-множество. Код смотрите здесь.


Собранные, разделённые, выровненные и нормированные данные можно скачать здесь.
Ультиматум Борна
Данные нашли и подготовили, с методикой тестирования разобрались. Полдела сделано, осталось самое лёгкое — найти
Монетка
Начнём поиски с того самого примера плохой функции
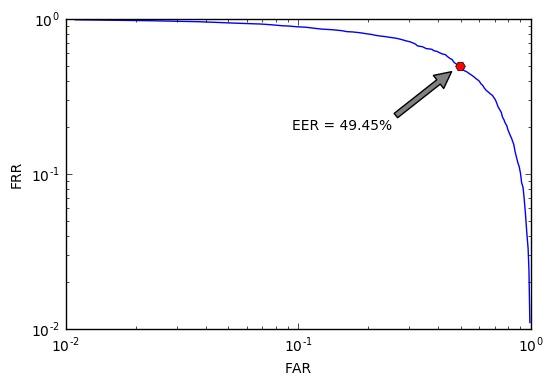

C EER = 49.5% такой идентификатор не лучше монетки, которую бы мы подбрасывали при принятии каждого решения. Конечено, это понятно и без графиков, но наша цель — научиться решать задачи идентификации и уметь объективно оценивать любые решения, даже заведомо плохие. К тому же, будет от чего оттолкнуться.
Расстояние
Какая функция от двух векторов из
Возьмём, например, косинусную дистанцию:
И проделаем все те же самые операции над development-множеством:
dev_x = np.load('data/dev_x.npy')
protocol = np.load('data/dev_protocol.npy')
dev_x = dev_x.mean(axis=3).reshape(dev_x.shape[0], -1)
dev_x /= np.linalg.norm(dev_x, axis=1)[:, np.newaxis]
scores = dev_x @ dev_x.T
tsc, isc = scores[protocol], scores[np.logical_not(protocol)]
eer, fars, frrs, dists = calc_metrics(tsc, isc)
Получим такую DET-кривую:

EER уменьшился на 16% и стал равен 34.18%. Лучше, но всё-ещё не применимо. Конечно, ведь мы до сих пор лишь подбирали функцию, никак не используя обучающее множество и методы машинного обучения. Однако, идея с расстоянием здравая: давайте его оставим и представим нашу функцию
где
CNN
Отлично, мы с вами только-что ещё сильнее упростили задачу. Осталось лишь найти хорошую функцию
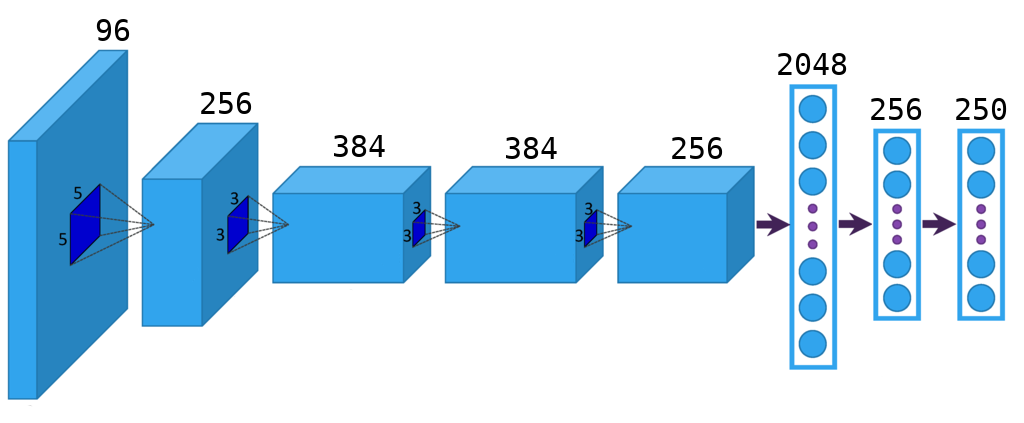
from keras.layers import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.layers.advanced_activations import PReLU
from keras.models import Sequential
model = Sequential()
model.add(Convolution2D(96, 11, 11,
subsample=(4, 4),
input_shape=(dim, dim, 3),
init='glorot_uniform',
border_mode='same'))
model.add(PReLU())
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(Convolution2D(256, 5, 5,
subsample=(1, 1),
init='glorot_uniform',
border_mode='same'))
model.add(PReLU())
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(Convolution2D(384, 3, 3,
subsample=(1, 1),
init='glorot_uniform',
border_mode='same'))
model.add(PReLU())
model.add(Convolution2D(384, 3, 3,
subsample=(1, 1),
init='glorot_uniform',
border_mode='same'))
model.add(PReLU())
model.add(Convolution2D(256, 3, 3,
subsample=(1, 1),
init='glorot_uniform',
border_mode='same'))
model.add(PReLU())
model.add(MaxPooling2D((3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(2048, init='glorot_uniform'))
model.add(PReLU())
model.add(Dropout(0.5))
model.add(Dense(256, init='glorot_uniform'))
model.add(PReLU())
model.add(Dense(n_classes, init='glorot_uniform', activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
И обучим её решать классическую задачу классификации на нашем обучающем множестве: определять, кому из 250 субъектов принадлежит фотография лица. Такую простую задачу решать умеют все, в keras для этого помимо приведённого выше кода понадобится ещё строчек 5-6. Скажу лишь, что для базы обучения, описанной в этой статье, жизненно необходимо применить аугментацию, иначе данных не хватит, чтобы достичь хороших результатов.
Спрашиваете, при чём здесь задача классификации и как нам поможет её решение? Правильно делаете! Чтобы описанные далее действия имели смысл, необходимо сделать очень важное предположение: если сеть научится хорошо решать задачу классификации в закрытом множестве, то на предпоследнем слое размерностью 256 будет сосредоточена вся важная информация об изображении лица, даже если субъекта не было в обучающем множестве.
Такая техника извлечения характеристик низкой размерности из последних слоёв обученной сети широко распространена и носит название bottleneck. Кстати, код для работы с bottleneck в keras находится по ссылке.
Сеть обучили, 256-мерные признаки из development-множества извлекли. Смотрим на DET-кривую:

Предположение оказалось верным, уменьшили EER ещё на 13%, достигнув результата 21.6%. В два раза лучше, чем подбрасывание монетки. А можно ещё лучше? Конечно, можно собрать базу побольше и повариативнее, построить более глубокую CNN, применить различные методы регуляризации… Но мы с вами рассматриваем концептуальные подходы, качественные. А количество всегда можно нарастить. Ещё один козырь в рукаве у меня всё-таки остался, но перед тем как выложить его на стол, придётся немного отвлечься.
Эволюция Борна

Ключ к улучшению наших результатов кроется в осознании того факта, что оптимизируя
Подход, предложенный ими, получил название TDE (Triplet Distance Embedding) и состоял в следующем: давайте построим

Обучать такую сеть было предложено с помощью троек
которое означает, что для данного anchor-а между сферами, на которых лежит positive и negative имеется зазор
Используя такой подход, авторы уменьшили ошибку на 30% на датасетах Labeled Faces in the Wild и YouTube Faces DB, что, несомненно, очень круто. Однако, есть у подхода и проблемы:
- требуется очень много данных;
- медленное обучение;
- дополнительный параметр
, который не ясно как выбирать;
- во многих случаях (в основном при малом количестве данных) проявляет себя хуже, чем softmax + bottleneck.
Тут на сцену выходит TPE (Triplet Probabilistic Embedding) — подход, описанный в работе Triplet Probabilistic Embedding for Face Verification and Clustering.
Зачем вводить лишний параметр
Оно проще исходного и легко интерпретируется: мы хотим, чтобы самый близкий к нам negative-пример лежал дальше, чем самый далёкий от нас positive-пример, но между ними не обязательно должен быть какой-либо зазор. Благодаря тому, что мы не прекращаем обновлять сеть, когда расстояние
Можем посчитать вероятность того, что триплет удовлетворяет приведённому неравенству:
Разделим на
Будем максимизировать логарифм вероятности, поэтому loss-функция будет выглядеть следующим образом:
А в качестве функции

Как видно, такой подход работает лучше оригинального и имеет множество плюсов:
- требуется меньше данных;
- крайне быстро учится;
- не требуются слишком глубокие архитектуры;
- можно использовать поверх уже существующей и обученной архитектуры.
Этот подход мы с вами и используем. Нужно для этого всего 20 строчек кода:
def triplet_loss(y_true, y_pred):
return -K.mean(K.log(K.sigmoid(y_pred)))
def triplet_merge(inputs):
a, p, n = inputs
return K.sum(a * (p - n), axis=1)
def triplet_merge_shape(input_shapes):
return (input_shapes[0][0], 1)
a = Input(shape=(n_in,))
p = Input(shape=(n_in,))
n = Input(shape=(n_in,))
base_model = Sequential()
base_model.add(Dense(n_out, input_dim=n_in, bias=False, weights=[W_pca], activation='linear'))
base_model.add(Lambda(lambda x: K.l2_normalize(x, axis=1)))
a_emb = base_model(a)
p_emb = base_model(p)
n_emb = base_model(n)
e = merge([a_emb, p_emb, n_emb], mode=triplet_merge, output_shape=triplet_merge_shape)
model = Model(input=[a, p, n], output=e)
predict = Model(input=a, output=a_emb)
model.compile(loss=triplet_loss, optimizer='rmsprop')
Если вы захотите использовать TPE в своих проектах, не поленитесь прочитать оригинальные работы, так как я не осветил самый главный вопрос обучения триплетами — вопрос их отбора. Для нашей небольшой задачи хватит и случайного выбора, однако это скорее исключение, чем правило.
Обучим TPE на наших bottleneck-ах и взглянем на DET-кривую последний на сегодня раз:

EER равный 12% — очень близко к тому, что мы хотели. Это в два раза лучше, чем просто использование CNN и в 5 раз лучше случайного выбора. Результат, конечно, можно улучшить, использовав более глубокую архитектуру и большую базу, но для понимания принципа и такой результат удовлетворителен.
Сравнение DET-кривых всех рассмотренных методов:
Осталось прикрутить к нашей системе всяческую машинерию и интерфейс, будь то web-интерфейс или приложение на Qt, и программа для поиска одинаковых лиц на фотографиях готова.
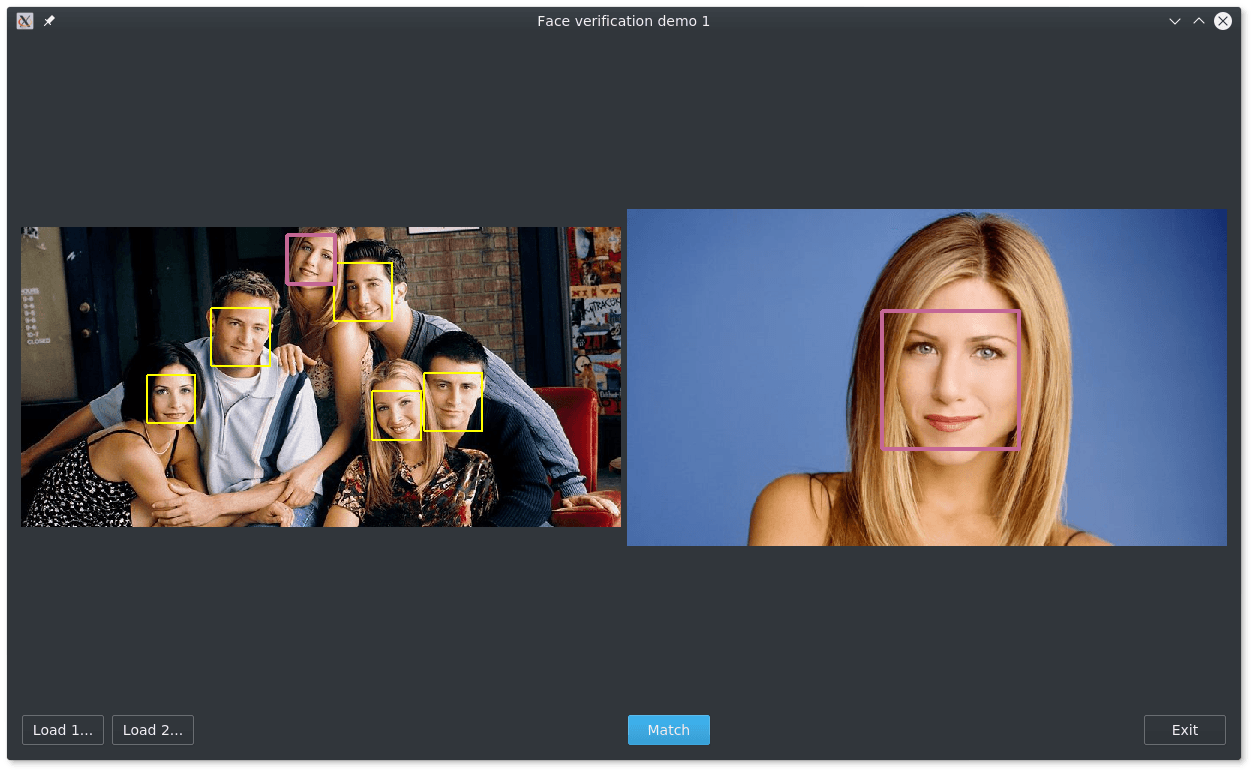
С приложением можно ознакомиться на GitHub.
Спасибо за прочтение! Ставьте лайки, подписывайтесь на профиль, оставляйте комментарии, учите машин хорошему. Дополнения приветствуются.
Литература
Комментарии (15)



weater
23.01.2017 19:47А зачем в последнем алгоритме ограничиваться линейной функцией, почему бы не прикрутить туда нейронную сеть? не такие уж CNN и гигантские, с точки зрения количества весов

devpony
23.01.2017 19:561) Авторы оригинальный статьи показали работоспособность подхода только для линейной функции.
2) Я пробовал встраивать в TPE более глубокую архитектуру в другой задаче, этот поход не работал. Даже добавление единственной нелинейности в виде гиперболического тангенса или сигмоиды ухудшает ситуацию.
3) С такими размерностями и количеством данных более глубокая архитектура, наверное, очень быстро переобучилась бы.
Идеологически подход заключается в том, что мы начинаем с обученного PCA и пытаемся его улучшить. Для более глубокой архитектуры, скорее всего, необходима подобная хорошая инициализация
mrgloom
29.01.2017 17:361. Так как всё таки формируется batch? Мы рэндомно дергаем из базы тройки сэмплов и смотрим выполняется ли неравенство и добавляем тройку в батч?
2. Как влияет на обучение (когда у нас задача классификации на N индивидов) то что у нас разное кол-во фоток на каждого индивида? (по идее не сбалансированная выборка должна плохо влиять).devpony
29.01.2017 18:181. В мой реализации — да. В оригинальной работе введены такие понятия, как hard negative — наиболее близкий негативный пример и hard positive — наиболее далёкий позитивный пример. Показано, что лучше начинать со случайного выбора, а затем включать hard negative.
2. Не изучал. Думаю, что никак не влияет. Тот же LFW очень не сбалансированный, однако на нём учат хорошие модели.mrgloom
30.01.2017 00:30Так получается c hard negative перед тем как сформировать batch нужно пробежать всю базу?
devpony
30.01.2017 04:05В идеале — да. На практике, конечно, так не делают. Используют выборку из базы некоторого фиксированного размера (порядка 2000 элементов, например), считают на ней расстояния и уже из неё формируют батч с выбором hard negative примеров.
DmitrySarov
31.01.2017 16:18спасибо за статью.
есть вопрос
В задаче классификации мы можем посмотреть accuracy на валидационном множестве — долю правильно классифицированных примеров. Для задачи идентификации такая метрика не применима.
поясните пожалуйста, почему?
и чем выбранные метрики отличаются от нее.devpony
31.01.2017 16:35Не применима потому, что у нас нет правильно или неправильно классифицированных примеров, для каждой пары примеров мы имеем лишь вероятность наличия признака — вещественное число. Если бы мы возвращали 1 или 0, то можно было бы использовать accuracy = 1 — EER.
Концептуально метрики в идентификации отличается от accuracy тем, что классы не равнозначны и их нужно рассматривать отдельно (см. пример про разные FRR и FAR в разных задачах).
roryorangepants
Кажется, в неравенстве, характеризующем TPE в правой половине неравенства перепутаны xp и xn
devpony
Спасибо, исправил.