

Меня зовут Женя, я работаю в компании IPONWEB. Сегодня мы поговорим про развитие наших решений в балансировке высоконагруженных систем.
Сначала я пробегусь по понятиям, которыми буду оперировать. Начнём с того чем мы занимается: RTB, Real Time Bidding — показ рекламы с аукционом в реальном времени. Очень упрощенная схема того, что происходит, когда вы заходите на сайт:

Для того, чтобы показать рекламу, идет запрос на RTB-сервер, который запрашивает у рекламных серверов их ставки и потом решает, какую рекламу вам показать.
Особенности IPONWEB
У нас вся инфраструктура в облаках. Мы очень активно пользуемся Amazon и GCE, у нас несколько тысяч серверов. Главная причина, по которой мы полностью живем в облаках, — это скалируемость, то есть у нас реально часто нужно добавлять/удалять инстансы, иногда очень много.
У нас есть миллионы запросов в секунду, все эти запросы HTTP. Это может быть не до конца применимо к остальным протоколам. У нас очень короткие ответы. Может быть, и не очень, я думаю, в среднем от одного до несколько килобайт ответы. Мы не оперируем какими-то большими объемами информации, просто очень большим их количеством.
Для нас не актуально кэширование. Мы не поддерживаем CDN. Если нашим клиентам нужны CDN, то они сами занимаются этими решениями. У нас есть очень сильные суточные и событийные колебания. Они проявляются во время праздников, спортивных событий, каких-то сезонных скидок и т. д. Суточные можно хорошо посмотреть на таком графике:
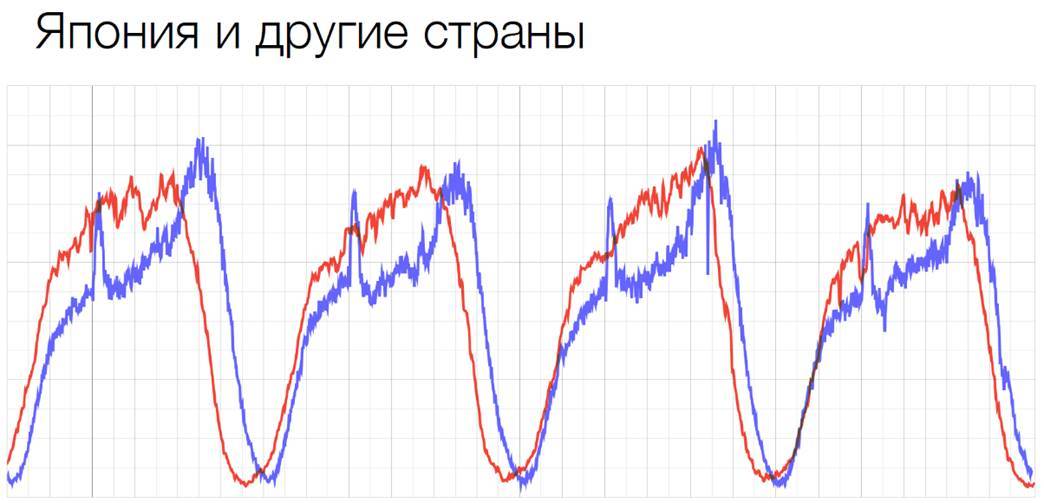
Красный график — обычный стандартный график в европейской стране, а синий график — это Япония. На этом графике мы видим, что каждый день примерно в двенадцать у нас есть резкий скачок, и примерно в час трафик резко падает. Связано это с тем, что люди уходят на обед, и как очень порядочные японские граждане они пользуются интернетом активно больше всего на обеде. Такое очень хорошо видно на этом графике.
У нас есть большой разброс пользователей по всему миру. Это — вторая большая причина, почему мы пользуемся облаками. Нам очень важно отдать ответ быстро, и если сервера находятся в каких-то других регионах от пользователей, то часто это неприемлемо для RTB-реалий.
И у нас есть чёткое разграничение серверного и пользовательского трафика. Вернёмся к той схеме, которую я показал на первом слайде. Для простоты всё то, что приходит от пользователя до первичного RTB-сервера — это пользовательский трафик, все то что происходит за ним — это серверный трафик.

Зачем балансировать?
Две главные причины — это масштабируемость и доступность сервисов.
Масштабируемость — это когда мы добавляем новые сервера, когда мы из одного сервера, который уже не может справиться, вырастаем как минимум до двух, и между ними надо как-то раскидывать запросы. Доступность — это когда мы боимся, что с этим одним сервером что-то случится. Опять же нужно добавить второй, чтобы между ними как-то всё это балансировать и распределять запросы только по тем серверам, которые могут на них ответить.
Что ещё часто требуется от балансировщиков? Эти функции, естественно, для целей каждого приложения могут быть разными. Для нас больше всего актуально SSL Offload. Как это работает, показано здесь.
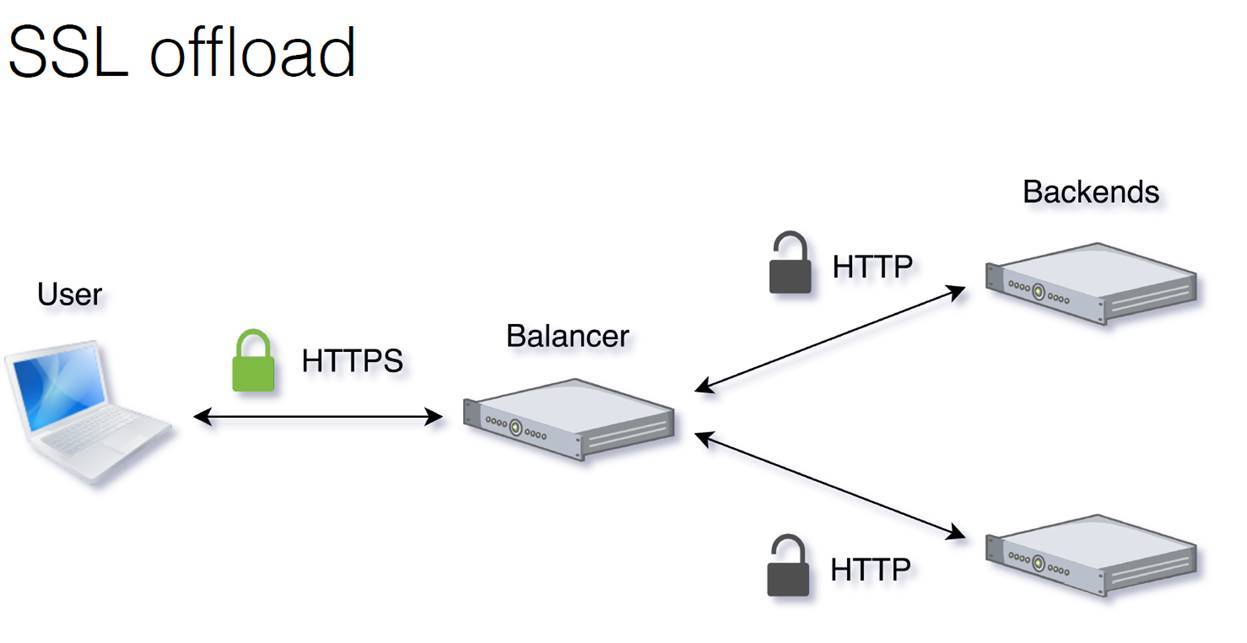
От пользователя до балансировщика идёт трафик, который зашифрован. Балансировщик расшифровывает его, раскидывает по бэкендам уже расшифрованный HTTP-трафик. Потом балансировщик обратно зашифровывает его и отдает пользователю опять в зашифрованном виде.
Ещё нам очень важна такая штука, как Sticky-балансировка, которую часто называют session affinity.

Почему для нас это актуально? Когда мы видим несколько слотов для рекламы на странице, мы хотим, чтобы при открытии этой страницы все запросы пришли сразу на один бэкенд. Почему это важно? Есть такая особенность как roadblock. Она означает, что если мы показали в одном из слотов баннер, например, Pepsi, то в другом мы не можем показать баннер той же самой Pepsi или Coca-Cola, потому что это конфликтующие баннеры.
Нам нужно понимать, какие баннеры мы показываем в данный момент пользователю. При балансировке нам нужно удостовериться, что пользователь пришел на один бэкенд. На этом бэкенде у нас создается некое подобие сессии, и мы понимаем, какие именно рекламы можно показать этому пользователю.
Также у нас есть Fallback. На примере сверху виден баннер, на котором он не работает, а справа — баннер, на котором он работает.
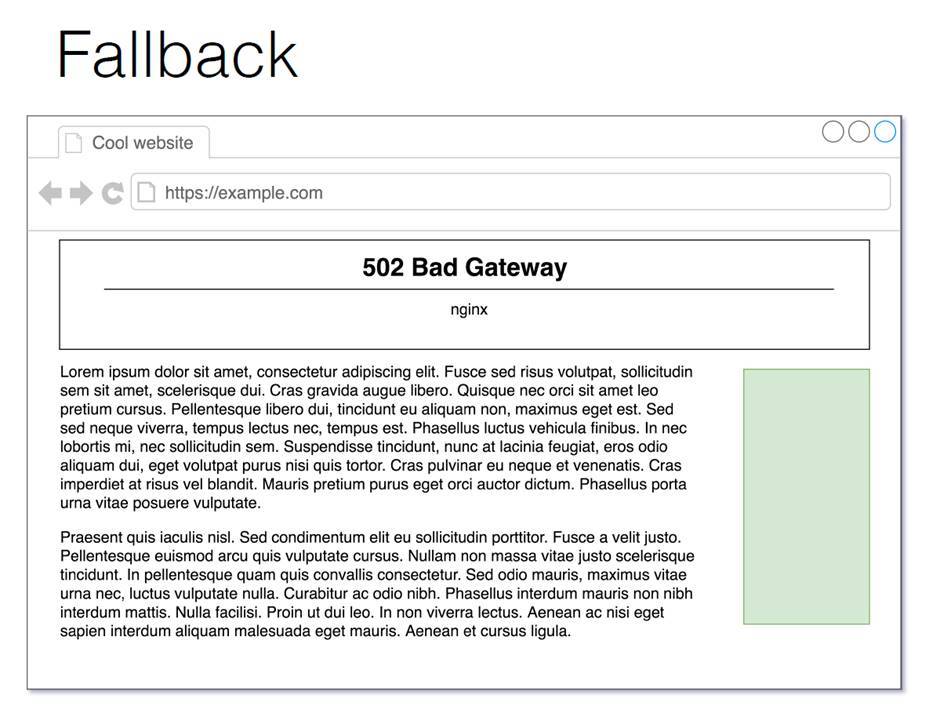
Fallback — это ситуация, когда по каким-то причинам бэкенд не справляется, и дабы не сломать страницу пользователю, мы отдаем ему обычно совсем пустой пиксель. Здесь я его нарисовал большим зеленым прямоугольником для понимания, но на самом деле обычно это просто маленькая гифка, двухсотый HTTP Response и правильный набор header’ов, чтобы у нас не сломалось ничего в верстке.
Так у нас выглядит нормальная балансировка.

Синяя жирная линия — это сумма всех запросов. Эти маленькие линии, много-много, — это идут запросы на каждый инстанс. Как мы видим, тут балансировка достаточно хорошая: практически все они идут почти одинаково, сливаясь в одну линию.
Это — балансировка курильщика. Здесь что-то пошло не так.
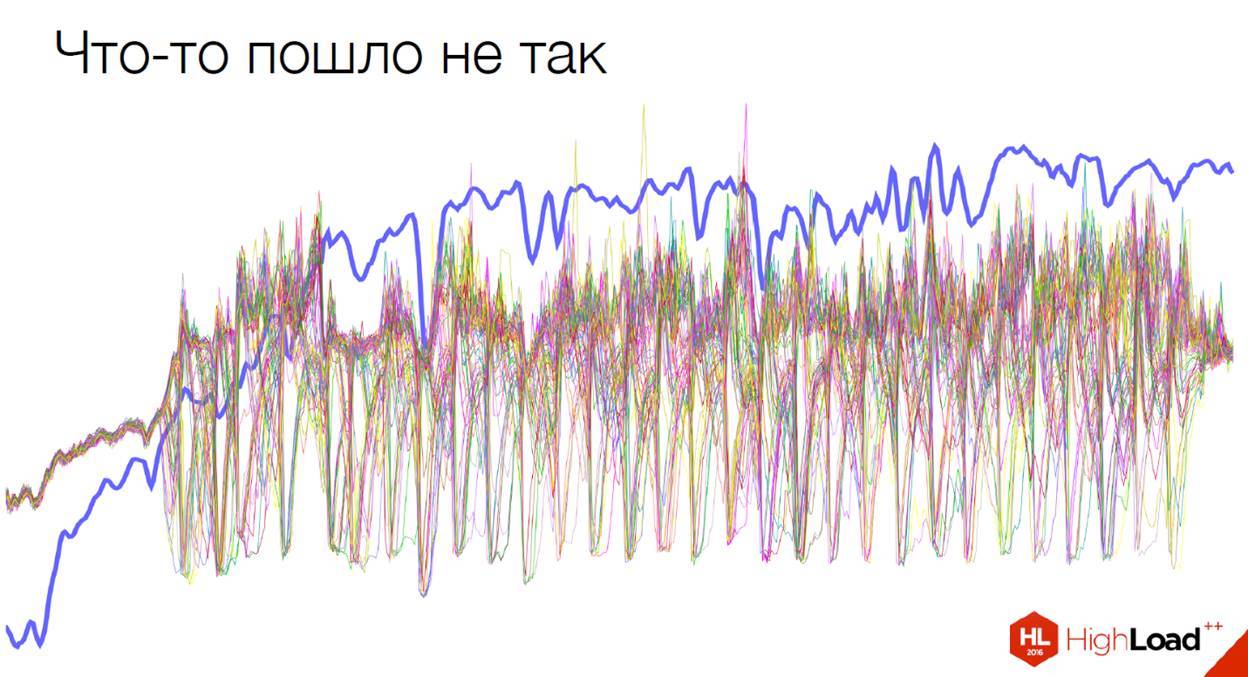
Проблема — на стороне Amazon. Подобное, кстати, произошло совсем недавно, буквально две недели назад. С амазоновских балансеров трафик стал приходить в таком виде.
Стоит сказать, что метрики — это хорошо. Здесь Amazon до сих пор не верит нам, что у нас происходит что-то плохое. Они видят только вот этот общий график, в котором видно лишь сумму запросов, но не видно, сколько запросов приходит по инстансам. До сих пор с ними боремся, пытаемся им доказать, что что-то с их балансировщиком идет не так.
Балансировка DNS
Итак, про балансировку я расскажу на примере одного из наших проектов. Начнем собственно с самого начала. Проект был молодой, мы примерно около начала этого проекта.

Большая часть трафика в этом проекте — серверный. Особенность работы с серверным трафиком: мы можем легко решать некоторые проблемы. Если у нас есть специфика у одного из наших клиентов, то мы можем как-то договориться с ним, чтобы они что-то поменяли на своем конце, как-то обновили свои системы, что-то еще сделали, чтобы у нас лучше работало с ними. Можно выделить их в отдельный пул: мы можем просто взять одного клиента, у которого есть какая-то проблема, привязать его к другому пулу и решить проблему локально. Либо, в совсем тяжелых случаях, можно даже его забанить.
Первое, чем мы начали пользоваться, — это была обычная DNS-балансировка.

Пользуемся Round-robin DNS-пулами.

Каждый раз при запросе на DNS, пул ротируется, и сверху оказывается новый IP-адрес. Таким образом работает балансировка.
Проблемы обычного Round-Robin DNS:
- У него нет никаких проверок статуса. Мы не можем понять, что с бэкэндом случилось что-то не то, и перестать отсылать на него запросы.
- У нас нет понимания геолокации клиента.
- Когда запросы идут с достаточно маленького количества айпишников, что актуально для серверного трафика, то балансировка может быть не очень идеальной.
Балансировка gdnsd
На помощь приходит gdnsd – это DNS сервер, который многие, наверное, знают, которым мы активно пользуемся и сейчас.
- Главная фича gdnsd, которой мы пользуемся, — это DYNA-записи. Это такие записи, которые выдают на каждый запрос, используя некий плагин, динамически либо одну A-запись, либо набор A-записей. Там внутри они могут использовать Round-robin.
- gdnsd умеет поддерживать базы данных geoIP.
- У него есть проверка статуса. Он может по TCP какие-то запросы посылать хосту, по HTTP смотреть Response и выкидывать из пула те серверы, которые не используются, в которых в данный момент есть какая-то проблема.
Чтобы поддерживать динамичность этих записей, нам нужно поддерживать довольно низкий TTL. Это сильно увеличивает трафик на наши DNS-сервера: довольно часто клиентам приходится перезапрашивать эти пулы, и поэтому DNS-серверов, соответственно, приходится иметь больше.
Через какой-то промежуток времени мы сталкиваемся с проблемой 512 байт.
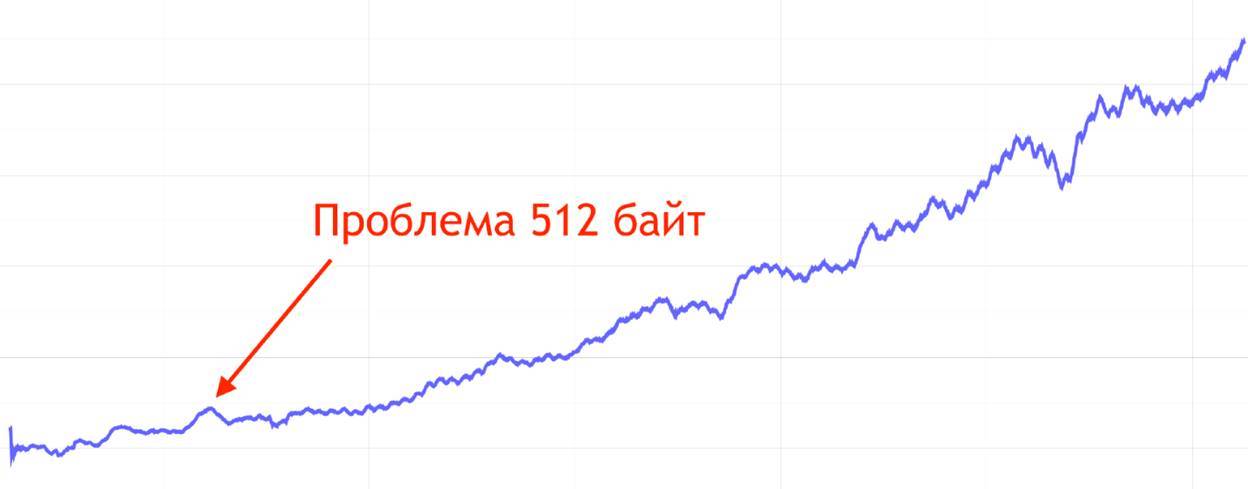
Проблема 512 байт — это проблема практически всех DNS-серверов. Изначально, когда DNS только проектировался, максимальный MTU у модемов был 576 байт. Это 512 байт + 64 длины заголовка. Пакеты от DNS исторически не отсылают больше чем 576 байт по UDP. Если у нас пул длиннее, чем 512 байт, то мы отсылаем только часть пула, включаем в нем флаг truncated. Потом уже от клиента приходит запрос по TCP, переспрашивая нас опять это пул. И тогда мы присылаем ему полный пул, теперь уже по TCP.
Эта проблема была только у части наших клиентов, примерно у 15%. Мы смогли выделить их отдельно в пул и использовать для них weighted-пулы в gdnsd.
Бонус weighted-пулов в этом случае — их можно разбивать. Если у нас, скажем, 100 серверов, мы их разбиваем на 5 частей. Мы отдаем на каждый запрос один из этих маленьких подпулов, в которых всего 20 серверов. И Round-robin проходит по этим маленьким пулам, каждый раз он выдает новый пул. Внутри самого пулa тоже используется Round-Robin: он шаффлит эти айпишники и каждый раз выдает новые.
Веса gdnsd можно использовать помимо этого для, например, staging серверов. Если у вас есть более слабый инстанс, вы на него можете изначально отсылать гораздо меньше трафика и проверять, что что-то там сломалось, только на нём, отсылая на него достаточно маленький набор трафика. Или если у вас есть разные типы инстансов, либо вы используете разные сервера. (Я часто говорю «инстансы» потому что у нас всё в облаках, но для вашего конкретного случая это может быть не так.) То есть вы можете использовать разные типы серверов и с помощью gdnsd слать на них больше или меньше трафика.
Тут у нас тоже возникает проблема — DNS-кэширование. Часто, когда идет запрос этого пула, мы отдаем только маленький пул, и этот пул кэшируется. С этим пулом у нас продолжает жить какой-то клиент, не переспрашивая наш DNS. Такое случается, когда DNS-клиент плохо себя ведет, не придерживается TTL и работает только с маленьким ограниченным набором IP-адресов, не обновляя его. Если он получил изначально полный лист по TCP, это нормально. Но если он получил только маленький пул, который weighted, то это может быть проблемой.
Через какое-то время мы сталкиваемся с новой проблемой.
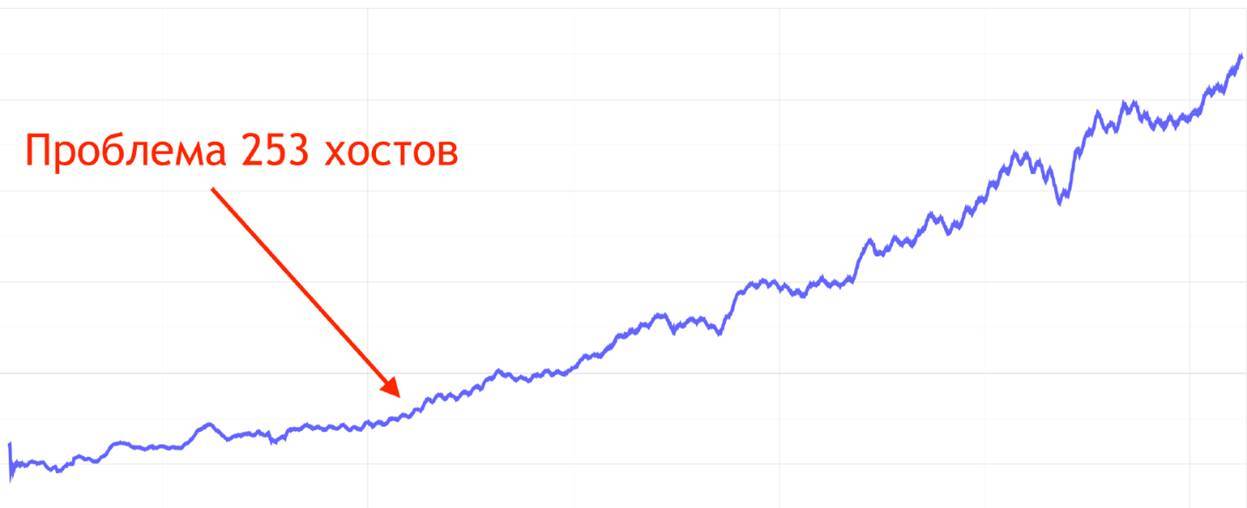
Те оставшиеся 85% серверного трафика всё ещё пользуются обычными мультифопулами, как это называется в gdnsd. С некоторыми из них начинаются проблемы.
Мы поняли, что проблема происходит только у амазоновских DNS. То есть у тех наших клиентов, которые сами хостятся в Amazon, при ресолве пула, в котором находится больше 253 хостов, им просто приходит ошибка NXDOMAIN, и они полностью не ресолвят этот целый пул.
Это произошло тогда, когда мы добавили около 20 хостов, и у нас их стало 270. Мы локализовали число до 253, мы поняли, что на этом количестве становится проблемно. Сейчас эту проблему уже починили. Но на тот момент мы поняли, что топчемся на месте, и надо как-то эту проблему решать дальше.
Так как мы находимся в облаках, первое, о чем мы подумали, — попробовать вертикальное масштабирование. Оно сработало, соответственно, мы сократили количество инстансов. Но опять же, это временное решение проблемы.
ELB
Мы решили попробовать что-то еще, тогда выбор пал на ELB.
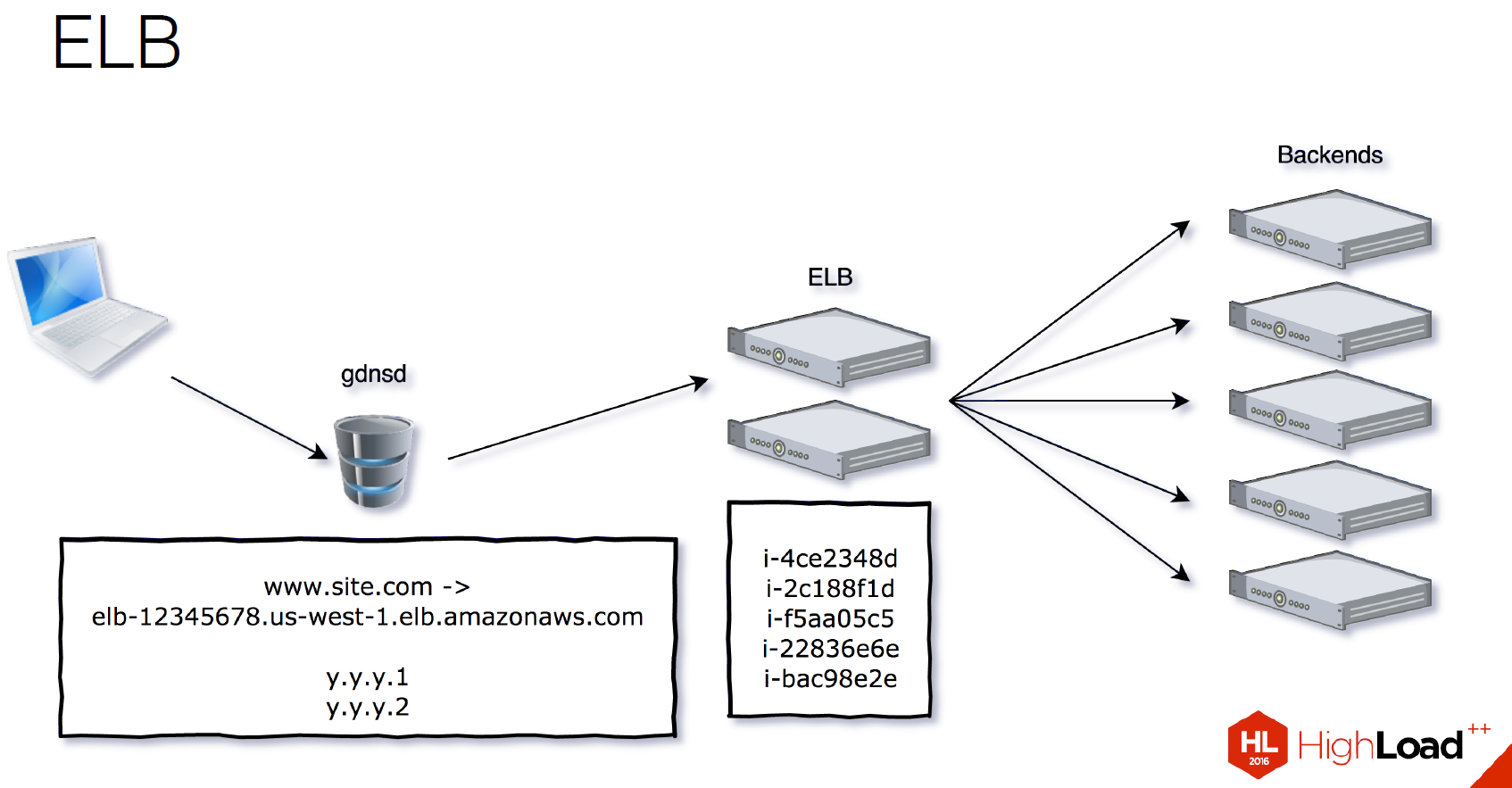
ELB – это Elastic Load Balancing, решение от Amazon, которое балансирует трафик. Как это работает?
Они предоставляют вам CNAME, в данном случае это вот эта страшная строчка под
www.site.com: elb, цифры, регион и так далее. И этот CNAME ресолвится на несколько внутренних айпишников инстансов, которые балансируют на наши бэкенды. В таком случае нам нужно всего один раз привязать их CNAME в нашем DNS к нашему пулу. Потом мы уже добавляем в группу серверы, на которые раскидывают балансировщики.ELB умеет SSL Offload, к нему можно прицепить сертификат. Также он умеет HTTP status checks, чтобы понимать, насколько живые у нас инстансы.
Мы практически сразу стали сталкиваться с проблемами с ELB. Есть так называемый прогрев балансировщиков ELB. Это нужно, когда вы хотите пускать больше 20—30 тысяч запросов в секунду. Прежде чем перевести весь ваш трафик на ELB, вам нужно написать письмо в Amazon, сказать, что мы хотим пустить много трафика. Вам присылают письмо с кучей страшных вопросов про характеристики вашего трафика, сколько, когда, как долго вы собираетесь это всё поддерживать. Затем они добавляют новых инстансов в свой пул и готовы к наплыву трафика.
И даже при предварительном прогреве мы столкнулись с проблемой. Когда мы у них запросили 40 тысяч запросов в секунду, примерно на 30 тысячах у них все сломалось. Нам пришлось все это дело быстро откатывать.
Ещё у них есть балансировка по скорости ответов. Это алгоритм работы амазоновского балансировщика. Он смотрит насколько быстро ваши бэкенды отвечают. Если он видит, что быстро, то шлет туда больше трафика.
Проблема здесь в чем? Если ваш бэкенд отчаянно пятисотит [выдаёт код состояния HTTP 5XX, что говорит об ошибке сервера] и не справляется, то балансировщик думает, что бэкэнд очень быстро отдает ответы, и начинает слать ему ещё больше трафика, загибая ваш бэкэнд ещё сильнее. В наших реалиях это ещё проблемнее, потому что мы, как я уже рассказывал, обычно отсылаем 200-ый ответ, даже если всё плохо. Пользователь не должен видеть ошибку — просто посылаем пустой пиксель. То есть для нас эту проблему решить ещё сложнее.
На последней конференции Amazon они рассказывали, что если у вас что-то плохое происходит, то в exception’ы заворачивайте какие-нибудь таймауты по 100-200 мс, искусственно замедляя 500-ые ответы, чтобы амазоновской балансировщик понимал, что ваш бэкенд не справляется. Но вообще, по-хорошему надо делать правильные status checks. Тогда ваш бэкенд понимал бы, что есть проблемы, и отдавал бы на status checks проверки проблему, и его просто выкидывало бы из пула.
Теперь у Amazon появилось новое решение: Application Load Balancer (ALB). Это довольно интересное решение, но нам оно не сильно актуально, потому что оно для нас ничего не решает и скорее всего будет стоить гораздо больше. Их система с хостами стала сложнее.
Но ALB поддерживает Path-based routing: это значит, что если у вас, например, пользователь приходит на
/video, то вы можете перенаправлять запрос на один набор инстансов, если на /static, то на другой, и так далее.Есть поддержка WebSocket, HTTP/2 и контейнеров. Если у вас Docker внутри одного инстанса, то он может распределять между ними.
GLB
В Google мы пользуемся GLB. Это довольно интересное решение. По сравнению с Amazon, у него есть много преимуществ.
Первое — у нас всего 1 IP. Когда вы создаете балансировщик в Google, вам даётся единственный айпишник, который вы можете привязать к своему сайту. Это значит, что вы можете привязать его даже к «голому» домену. CNAME же можно привязать к домену второго уровня.
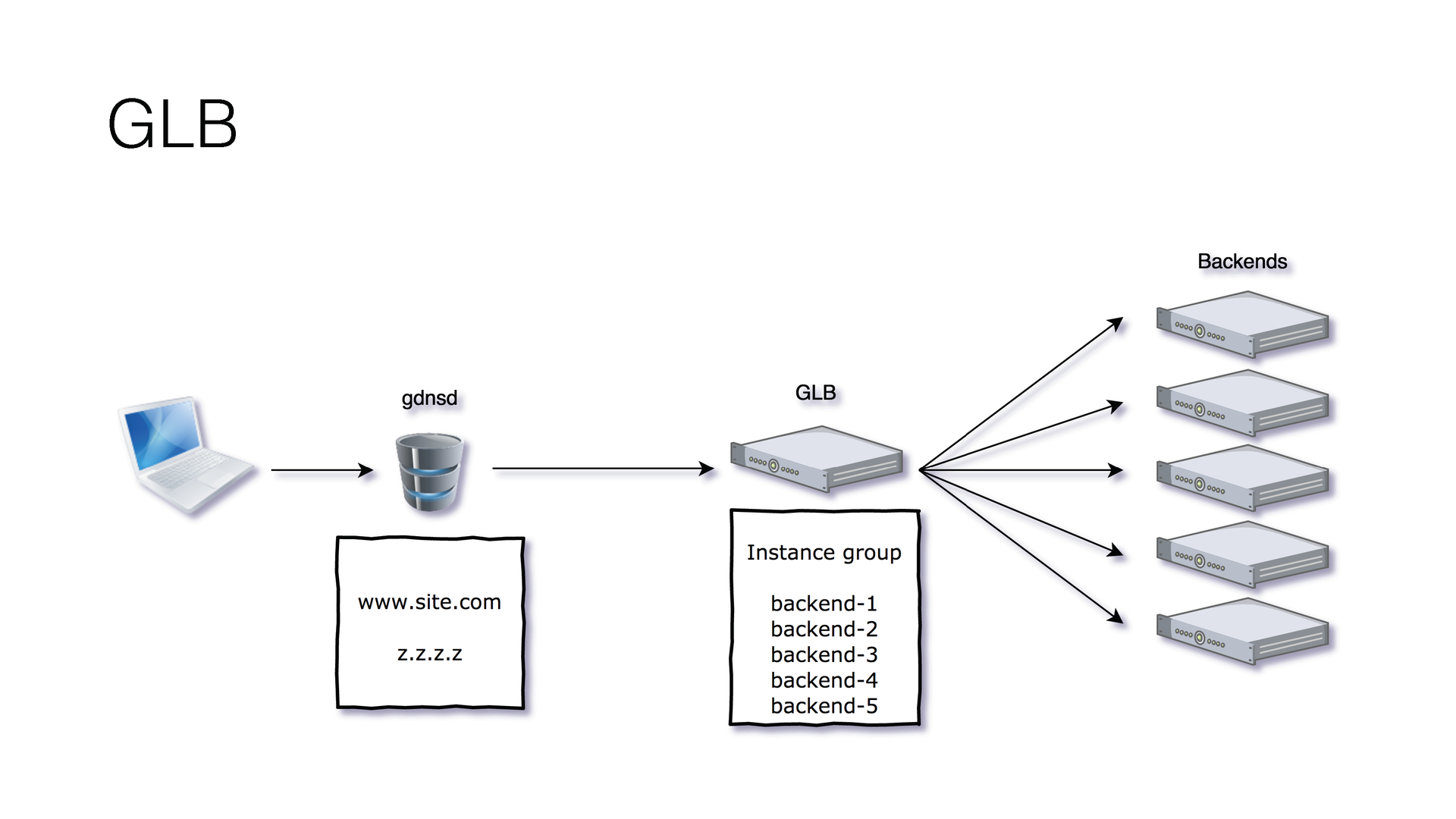
Вам нужно создать всего один балансировщик по всем регионам. То есть в Amazon нам нужно в каждом регионе создавать по балансировщику, чтобы балансировать между инстансами внутри этого региона, а в Google — всего один балансировщик, всего один один IP, и он балансирует между всеми вашими инстансами по разным регионам.
Гугловский балансировщик умеет Sticky и по IP, и по cookie. Я рассказывал, зачем нужен Sticky — нам нужно одного пользователя переслать на один бэкэнд. Амазоновские балансировщики умеют только по cookie, то есть они сами на уровне балансировщика выдают cookie. Потом его проверяют, и если видно, что у пользователя cookie, соответствующий одному из инстансов, его отсылают на тот же самый. Гугловский умеет IP, что нам гораздо лучше, хоть и не всегда решает все проблемы.
У балансировщика Google есть Instant warm-up: его не надо никак прогревать, на него сразу можно отсылать до миллиона запросов. Миллион запросов — это то, что они обещают сами точно, и то, что я сам проверял. Думаю, дальше они растут как-то сами внутри.
Но при этом у них есть проблема с резким изменением числа бэкендов. В какой-то момент мы добавили около 100 новых хостов. На этом этапе гугловский балансировщик загнулся. Когда мы стали общаться с инженером из Google, они сказали: добавляйте по одному в минуту, тогда будет вам счастье.
Также недавно в их HTTP-балансировщике подрезали порты, которыми вы можете пользоваться при создании балансировщика. Раньше было обычное поле для ввода, сейчас можно выбрать только между 80 и 8080 портами. Для кого-то это может быть проблемой.
Ни у одного из этих облачных балансировщиков нет поддержки SNI. Если вам нужно поддерживать несколько доменов и несколько сертификатов, то вам нужно на каждый сертификат создавать по отдельному балансировщику и к нему привязывать. Это решаемая проблема, но такая ситуация может быть неудобной.
Комментарии (9)

doom369
10.02.2017 23:21Сколько реквестов 1 инстанс хендлит? Какой траффик? Какие технологии бекенда?

pegas
12.02.2017 18:04У нас довольно много проектов и цифры отличаются от проекта к проекту.
Количество реквестов, с которыми может справится 1 инстанс может зависеть, например, от типа реквестов. Как я говорил, юзерский трафик != серверный трафик. Да и внутри пользовательского и серверного типы запросов могут сильно отличаться как по размеру, так и по времени процессинга.
Технологии бекенда — у нас свой in-house http-сервер, который парсит довольно сложную бизнес-логику, написанную отдельно (т.е. это не часть серверного кода как такового).doom369
12.02.2017 18:48+1Мне просто пришла идея, что если сделать отдельный сервер довольно мощным (заоптимизировать). Скажем чтобы он мог обрабатывать 10к рек-сек. Тогда проблем с балансировкой у Вас было бы поменьше.
Я 5 лет назад создавал подобную систему. Детали тут. Правда нам нужно было держать всего 11к рек-сек.

KIVagant
12.02.2017 16:07Хорошая статья. Для тех, у кого ещё нет столько траффика, есть о чем подумать и к чему готовиться.

koorchik
12.02.2017 16:21+1Отличная статья. Единственное, есть уточнение по:
Если ваш бэкенд отчаянно пятисотит [выдаёт код состояния HTTP 5XX, что говорит об ошибке сервера] и не справляется, то балансировщик думает, что бэкэнд очень быстро отдает ответы, и начинает слать ему ещё больше трафика, загибая ваш бэкэнд ещё сильнее.
ELB проверяет жизнь инстанса по настраиваемому URL. И 500-я ошибка говорит о том, что нужно выбросить инстанс с пула. То есть, если ELB смотрит на пользовательскую страницу и она вернет ошибку 500, то он корректно отработает. Зачастую этого достаточно.
pegas
12.02.2017 18:00Да, всё верно, более интеллектуальные health check'и, кажется, спасли бы ситуацию.
Но при этом «отчаянно пятисотит» в данном контексте может означать не «100% реквестов», а, например, 20%. В таком случае нагрузка на инстанс увеличивается, технически он всё ещё здоров, но за счёт бОльшего количества запросов, отсылаемого на него балансировщиком, ему становится хуже и он начинает дропать больше запросов.koorchik
12.02.2017 20:00Ну тогда просто делается end-point, который будет репортить статус опираясь на LA к примеру (ну или на любую другую метрику)
MaoDzeDun
13.02.2017 18:08Замечательные ребята из Spotinst относительно недавно сделали https://spotinst.com/products/multai-load-balancer/
Вы не рассматривали это решение?
le1ic
Точнее это назвать эластичностью. Скалируемость это свойство архитектуры поддерживать эластичность