
 «Дело было вечером, делать было нечего» — именно так родилась идея сделать вью с возможностью зума, распределяющую юзеров по рангам в зависимости от кол-ва их очков. Так как до этого я не имел опыта в создании собственных вьюшек такого уровня, задача показалась мне интересной и достаточно простой для начинающего… но, *ох*, как же я ошибался.
«Дело было вечером, делать было нечего» — именно так родилась идея сделать вью с возможностью зума, распределяющую юзеров по рангам в зависимости от кол-ва их очков. Так как до этого я не имел опыта в создании собственных вьюшек такого уровня, задача показалась мне интересной и достаточно простой для начинающего… но, *ох*, как же я ошибался.В статье я расскажу о том, с какими проблемами мне пришлось столкнутся как со стороны Android SDK, так и со стороны задачи (алгоритма кластеризации). Основная задача статьи – не научить делать так называемыми “custom view”, а показать проблемы, которые могут возникнуть при их создании.
Тема будет интересна тем из вас, кто имеет мало (или не имеет вовсе) опыта в создании чего-то подобного, а также тем, кто хочет
1. Как это работает?
Демонстрация работы вьюшки (гифка)
Для начала кратко опишу то, как устроено сделанная вьюшка:
Иерархия (зеленым отмечены собственные вьюшки)
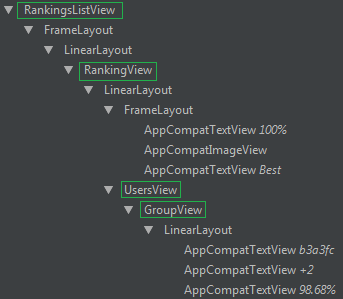
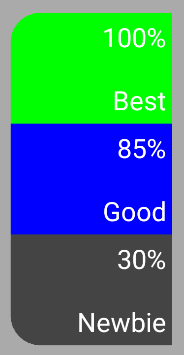
RankingsListView
Во главе стола –
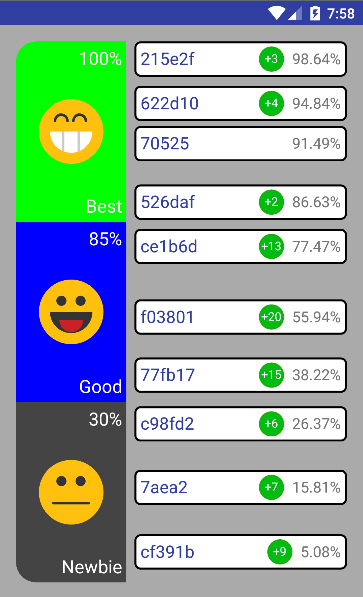
RankingsListView (наследник ScrollView). Он управляет скроллом (неожиданно, да?) и зумом, а также занимается созданием списка из RankingView.RankingView
RankingView отображает ранг (слева) и UsersView (справа).UsersView
UsersView, как вы могли уже догадаться, занимается отображением юзеров и показом анимаций объединения и разъединения юзеров в группы. GroupView
И юзер, и группа юзеров отображаются одним вью, называемым
GroupView. Только в случае, когда отображается один юзер, а не группа, будет отсутствовать зеленый круг (внутри которого отображается кол-во юзеров в группе). Ну а справа расположен показатель очков юзера/группы со знаком «%».Пожалуй всё со скучной частью, переходим к проблемам.
p.s. Ссылка на исходники в «Заключении».
2. Android SDK «хочет сыграть с тобой в игру» © Goog… Пила
Начнем с безобидного.
2.1. Inflate разметки внутрь кастомного View с использованием DataBinding
DataBinding с её генерацией кода творит чудеса:WidgetGroupViewBinding binding;
…
binding = DataBindingUtil.setContentView(this, R.layout.activity_main);
// binding.title доступен для работыПару строк и через переменную
binding доступны по id все вью, указанные в разметке, какой бы сложной эта разметка не была. Никаких больше:@ BindView (R.id.tb_progress) View loadingView;
@BindView (R.id.tb_user) View userView;
@BindView (R.id.iv_avatar) ImageView avatarView;
@BindView (R.id.tv_name) TextView nameView;
@BindView (R.id.l_error) View errorView;
@BindView (R.id.l_container) ViewGroup containerLayout;… и ещё с десяток подобных строк как при
ButterKnife. Но постойте! setContentView() – это метод Activity. А что же вьюшкам делатьДля того, чтобы добавить разметку внутрь текущего вью нужно вызвать метод
inflate(getContext(), R.layout.my_view_layout, this), например, внутри конструктора. Интересен последний флаг. Он добавляет вью, созданную по разметке, внутрь текущего вью. Это приводит к тому, что если в вашей разметке корневой тег, например, LinearLayout, и вы попробуете использовать inflate(…) внутри вашей вьюшки, унаследованной от LinearLayout, то вы получите два LinearLayout в иерархии… …И это вполне логично, хоть и не приятно, ведь один из
LinearLayout’ов избыточен. Что же делать? Обойти подобное достаточно просто. Нужно воспользоваться тегом <merge> внутри разметки, обернув в него всё, что должно быть внутри вашего вью, как это описано здесь.Но!
DataBinding не поддерживает <merge>. Его корневым тегом обязан быть тег <layout>, внутри которого должен быть единственный дочерний элемент-не-<merge> (на самом деле там может быть ещё тег <data>, но уже совсем другая история). Как итог, на данный момент нет способа использовать
DataBinding в собственный вьюшках, не наплодив дополнительных Layout’ов, что не лучшим образом скажется на производительности. ButterKnife по-прежнему наше всё.UPD: feature-request на code.google.com.
2.2. Measure & Layout passes
Несмотря на то, что я не имел опыта в создании вьюшек, я всё же читал изредка попадавшиеся на глаза статьи по этой тематике, а также же видел раздел документации, посвященной теме «как вьюшки отрисовываются». Если верить последней, то всё проще простого:
- вызывается пару раз
onMeasure()для определения размеров; - вызывается
onLayout()для расположения элемента внутри контейнера; - вызывается
onDraw()для отрисовки.
Ну о-о-о-очень просто. Именно по этой причине я считал, что реализовать собственную вьюшку не составит труда. Но не тут-то было (спойлер: автор отхватит больших проблем от метода onLayout далее по тексту). Вот список советов и правил, которые я вывел после создания вьюшки:
onMeasure()предназначен только для определения размеров. Не имеет абсолютно никакого смысла помещать в него что-либо ещё. Причина не только в том, что метод вызывается несколько раз, но и в том, что нельзя с уверенностью сказать, будет ли вызван он ещё раз доonLayout()или же текущий подсчитанный размер – финальный;
onSizeChanged(), который по какой-то невероятной причине зачастую не упоминается в статьях по кастомным вьюшкам, вызывается доonLayout(), но внутри методаlayout(), вызванным родителем. Суть такова, чтоlayout()вызываетsetFrame(), который вызываетonSizeChanged(), а уже потом (после выхода изsetFrame()) вызываетсяonLayout(). Это означает, что внутри методаonSizeChanged()вы всё ещё не можете положиться на то, что все дочерние вью внутри вашего вью расположены как нужно. Более того, у них ещё не были вызваны ихonSizeChanged(), не говоря уже обonLayout();
- Внутри
onLayout()можно вызыватьmeasureChildren()самостоятельно. Иначе говоря, если вью того пожелает, он может ещё несколько раз прогнать measurement pass;
- Последним методом в
onLayout()лучше оставлятьsuper.onLayout(). В противном случае вы можете создать ситуацию, при которой у дочерних вью будет дважды вызванonSizeChanged()сonLayout(). А уж если не повезет, то и вовсе можете зациклиться так, что каждые 16мс (60 fps ведь) будет вызыватьсяrequestLayout()(спойлер: автор здесь себе в ногу выстрелил, но об этом позднее).
Ни в одной статье, которую я читал по теме вьюшек, я не видел подобных описаний этих методов. То ли никто не сталкивается с подобным, то ли это первое правило клуба кастомных вью – не говорить об
onLayout() В моем случае внутри
UsersView.onLayout() происходит изменение Y-координат вьюшек, из-за чего некоторые вьюшки становятся видны, а другие прячутся, и это приводит к… (внимание на правый низ):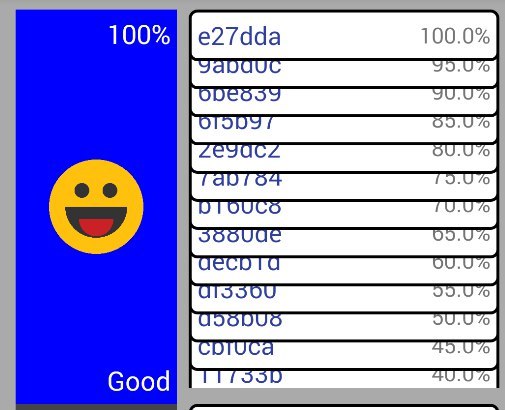
…обрезанию нижней вьюшки. Подобное происходило только при отдалении. Пришлось потупить повозиться, но удалось разобраться, что, похоже, дочерняя вьюшка определила, что со своей текущей позицией Y она в родителе появится лишь на половину, а посему можно обрезать свой
Bitmap drawingCache;. Тут на помощь и пришел тот самый дополнительный «measurement pass» в виде measureChildren() внутри onLayout(), заставивший вьюшку пересмотреть свои кэши после изменения её Y-координаты.2.3. ScrollView не разрешает менять размер ребенка
Пожалуй, многие из вас сталкивались с необходимостью установить высоту дочернего к
ScrollView элементу layout_height=match_parent, после чего мгновенно терпели неудачу, ведь результат был всё равно как при wrap_content, а затем находили статью вроде этой с описанием флага fillViewport, угадал? А теперь вопрос: как добиться такого же результата, как с флагом fillViewport, но при этом динамически изменять высоту дочернего элемента?Давайте по порядку. Как вообще можно изменить высоту элемента? Через
LayoutParams.height конечно же, больше никак. Проблема решена? Нет. Высота осталась неизменной. Что же произошло? Изучив onMeasure() в дочернем вью, я пришел к выводу, что ScrollView просто игнорирует установленный height в параметрах, отсылая ему сначала onMeasure() с mode равным «UNSPECIFIED», а затем onMeasure() с «EXACTLY» и значением height’а, равным размеру ScrollView (если установлен fillViewport). А так как единственный способ изменить height вьюшки – изменить его LayoutParams – то ребенок и не меняется.Решений я нашел два:
- Коль
ScrollViewтакойнаглыйумный и игнорируетLayoutParams, можно просто переписать методonMeasure()у ребенка и перед тамошнимsuper.onMeasure()добавить это:
if (MeasureSpec.getMode(heightMeasureSpec) == MeasureSpec.UNSPECIFIED && getLayoutParams().height > 0) { heightMeasureSpec = MeasureSpec.makeMeasureSpec( getLayoutParams().height, MeasureSpec.EXACTLY); }
Тем самым сделав работуScrollViewза него. Но естественно создавать каждый раз подкласс лишь для этого — не очень хорошая идея. Мало ли, какого именно класса должно быть дочернее вью:FrameLayout,LinearLayout,RelativeLayoutи т.д. Делать для каждого возможногоLayout’а свой подкласс – только мусорить. Поэтому вот вам решение №2.
- Обернуть ребенка во
FrameLayoutи изменять размер ребенка этогоFrameLayout’а.
Именно подход №2 использовал я, и он сработал на ура. Однако, я не уверен, что это действительно допустимый способ (хак). Возможно, данный хак работает не потому, что дополнительный
FrameLayout LayoutParams.height, а потому, что внутри ScrollView.onLayout() происходит Ах да, проблема с неизменяемым размером ребенка у
ScrollView есть на багтрекере, но как это обычно и бывает с Android’ом, оно всё ещё в статусе New с 2014-го года. 2.4. Закругленные углы у background
Сабж (слева снизу и слева сверху):
Казалось бы, что может быть проще — сделать
drawable с тегом <shape>, установить background’ом и готово… но нет. Задача такова, что цвет меняется программно, а закругленные края добавляются лишь первому и последнему элементам.Как ни странно, у класса
ShapeDrawable нет методов для работы с закругленными углами, как можно было бы ожидать. Но к счастью, есть наследник RoundRectShape и PaintDrawable Специфика задачи такова, что максимальный
zoom in может быть каким угодно, а значит вьюшка с её background’ом сильно растянутся, что приводет к… Logcat: W/OpenGLRenderer: Path too large to be rendered into a textureВыглядит это так, что после превышения некоторого размера,
background просто перестает отображаться. Как можно понять из предупреждения, некий Path слишком большой, чтобы можно было его отрисовать в текстуру. Чуток покопавшись в исходниках, я пришел к выводу, что виной всему этот товарищ:canvas.drawPath(mPath, paint);… в
mPath которого и помещают закругленный прямоугольник:mPath.addRoundRect(mInnerRect, mInnerRadii, Path.Direction.CCW);Решить данную проблему можно только унаследовав, например,
ColorDrawable и в его методе draw() вызвав не drawPath(), а:canvas.clipPath(roundedPath);Но, к сожалению, у данного подхода есть относительно существенный недостаток:
canvas.clipPath() не подвержен antialias. Однако за неимением другого способа сделать подобное, приходится довольствоваться этим.2.5. Позиционирование View внутри FrameLayout
Данная задача встала передо мной при попытке реализации
UsersView, внутри которого GroupView могли быть на любом месте вдоль оси OY.Первое, что приходило на ум (да и то, что я считал единственным возможным способом перемещения вьюшки внутри
FrameLayout) – использовать MarginLayoutParams и изменять параметр topMargin. Об этом же свидетельствуют большинство ответов на stackoverflow (раз, два, три).Недостатком данного подхода является то, что изменение
LayoutParams вызывает requestLayout(), а это крайне дорогая операция, особенно если она вызывается у всех GroupView внутри UsersView, даже с учетом того, что непосредственно сам layout pass откладывается до лучших времен (следующего 16мс-фрейма). Но к счастью, есть другой способ –
View.setY() (ответ на stackoverflow). Идеально для анимаций и для дочерних элементов внутри неизменяющихся Layout’ов. Он не вызывает requestLayout(), а использует только поля самой вьюшки и влияет лишь на фазу (pass) layout’а. А так как просчет новых позиций вьюшек происходит прямо в onLayout() до вызова super.onLayout(), requestLayout() и вовсе не нужен.2.6. Видишь отступы шрифта? Нет? А они тебя видят! © includeFontPadding
Когда юзеры объединяются в группу, добавляется иконка, отображающая кол-во юзеров в группе. Вот как она выглядит сейчас:
А вот как она выглядела раньше:
Замечаете разницу? Есть неприятное чувство, когда смотрите на вторую картинку? Если да, то вы меня понимаете. Я долго не мог сообразить, почему, когда я смотрю на эту иконку, она выглядит не так привлекательно, как предполагалось. Догадавшись взять пэинт в руки и подсчитать, сколько же пикселей слева/справа/сверху/снизу от текста, я понял причину – текст не центрирован до конца. Что-то явно не так гравитацией текста. Да?.. Нет. Гравитация была установлена верно, другие параметры тоже. Всё выглядело идеально.
В общем, не буду томить, решение оказалось очень простым, но вот найти сходу его не получалось просто потому, что я не понимал, что вообще. Вот, кстати, ссылка на решение. Суть в том, что, оказывается, у шрифтов самих по себе есть padding’и, которые и являлись причиной нецентрируемости. Добавив
TextView параметр includeFontPadding=false, проблема исчезла целиком и полностью.2.7. У ViewPropertyAnimator нет метода reverse()
Хотелось мне сделать анимацию сокрытия иконок рангов при определенном размере. Выглядеть это должно было так:

Чтобы определить момент запуска анимации, сверяем текущий размер с необходимым для умещения всех вьюшек и, если нужно, используем
view.animate().setDuration(fadeDuration).alpha(0 or 1).Однако, подобное работает хорошо только при быстрой анимации
fade’а. Однако если fade будет медленным, то при резком zoom in после zoom out, альфа канал вьюшки будет не 1 или 0, а, например, 0.5. Из-за чего, анимация будет проигрывается от 0.5 до 0 за те же fadeDuration. Выглядеть это будет так, словно анимация замедлилась в 2 раза. Добавлять до вызова view.animate() нечто вроде view.setAlpha(0 or 1) не является хорошим решением. Вьюшка начнет мерцать при быстром зуме.В идеале, здесь должен был бы быть какой-нибудь метод вида
setReverseDuration() (без параметров), который бы понял, что, «ага, я проигрывал анимацию fade’а 500мс, поэтому столько же и будет играть reverse-анимация». Но такого нет, увы. Единственный выход, что мне удалось найти, делать подобное ручками. В моем случае анимация была довольно простая, так что мне хватило этого для скрытия:final float realDuration = iconView.getAlpha() * animationDuration;final float realDuration = (1 - iconView.getAlpha()) * animationDuration;Ну а дальше как обычно:
view.animate().setDuration((long) realDuration) — и всё в ажуре.UPD: feature-request на code.google.com.
2.8. ScaleGestureDetector (он же «пинч», он же «зум»)
Сам по себе API у
ScaleGestureDetector довольно хороший – повесил listener и ждешь себе эвенты, не забыв передавать все onTouchEvent()'ы в сам детектор. Однако, не всё так радужно.2.8.1. Небольшие замечания
Во-первых, нигде не сказано, как разграничить внутри
onTouchEvent() эвенты между собственно самим ScaleGestureDetector и ScrollView (ведь, напоминаю, дело происходит внутри RankingsListView, который является наследником ScrollView). Как итог, метод выглядит так:@Override
public boolean onTouchEvent(MotionEvent ev) {
scaleDetector.onTouchEvent(ev);
super.onTouchEvent(ev);
return true;
}И таким его советуют делать все stackoverflow-ответы (пример). Однако такой подход обладает недостатком. Скролл происходит даже тогда, когда вы производите пинч. Может показаться что это пустяк, но на деле очень неприятно случайно листнуть вьюшку, когда пытался её прозумить.
Я был готов долго и нудно рыскать в поисках сложного решения разграничения ответственности между
super.onTouchEvent() и scaleDetector.onTouchEvent()… и я и правда искал… Но как оказалось, решение было ужасно простое:@Override
public boolean onTouchEvent(MotionEvent ev) {
scaleDetector.onTouchEvent(ev);
if (ev.getPointerCount() == 1) {
super.onTouchEvent(ev);
}
return true;
}Гениально, да?
super.onTouchEvent() не отслеживает id пальца, которым был произведен скролл в первый раз, поэтому даже если вы начали скролл пальцем №1, а закончили пальцем №2 – ему норм, схавает. К сожалению, я так был уверен, что Android SDK в который раз вставит палки в колеса, что удосужился попробовать подобное только после: гуглинга и изучения исходников. Что сказать, Android SDK умеет Во-вторых, если вы страдаете микро оптимизационной болезнью, то вам придётся следить за размером ваших дочерних вью с особой осторожностью. Как вы уже знаете, при пинче я увеличиваю высоту для child внутри child у
ScrollView. Этим child’ом является LinearLayout, дочерним элементам которого прописан layout_weight=1. Иначе говоря, все они одной высоты… хотя нет.Это совершенно никогда не заметно, но его дочерние вью не всегда могут быть одной высоты, ведь пиксели – атомарные единицы. То есть, если
LinearLayout имеет высоту 1001 и у него 2 дочерних элемента, то один из них будет размером 501, а другой 500. Заметить это на глаз практически нереально, но вот косвенные последствия могут быть. Когда я говорил про
ViewPropertyAnimator и reverse(), я показал анимацию сокрытия иконки ранга. Сама проверка простая – суммируем высоту 2-ух TextView и ImageView в onLayout(), и если они не влазят внутрь текущей вьюшки разом, то прячем fade’ом ImageView. Стоит отметить также, что эта суммарная высота (так сказать «порог высоты») не меняется. Как итог, если порог равен 500 пикселей, то в описанном случае, у одного вью размером 500 иконка спрячется, а у второго, размером 501, нет.Ситуация редкая и не слишком критичная (было не так уж просто (но и не сложно) двигать мышкой так медленно, чтобы обнаружить не скрытые и скрытые иконки одновременно). Но всё же если вам не нравится такое поведение, исправить это можно только одним способом – не использовать
getHeight() для сверки с порогом. В onSizeChanged() внутри LinearLayout’а находите наименьший размер у всех дочерних элементов и оповещаете всех о том, чтобы они сравнивали порог именно с этим числом. Я назвал это shared height и выглядит у меня это так:private void updateChildsSharedHeight() {
int minChildHeight = Integer.MAX_VALUE;
for (int i = 0; i < binding.lRankings.getChildCount(); ++i) {
minChildHeight = Math.min(minChildHeight, binding.lRankings.getChildAt(i).getMeasuredHeight());
}
for (int i = 0; i < binding.lRankings.getChildCount(); ++i) {
RankingView child = (RankingView) binding.lRankings.getChildAt(i);
child.setSharedHeight(minChildHeight);
}
}А сама сверка с пороговым значением так:
int requiredHeight = binding.tvScore.getHeight() + binding.tvTitle.getHeight() + binding.ivIcon.getHeight();
boolean shouldHideIcon = requiredHeight > sharedHeight;
UPD: feature-request на code.google.com.
2.8.2. Проблемы
А теперь поговорим не о придирках к
ScaleGestureDetector, а о его проблемах.2.8.2.1. Минимальный пинч
И-и-и-и-и-и… он (минимальный пинч) не отключаем. Во время кодинга я ещё не знал ни о какой «минимальной дистанции для срабатывания пинча», поэтому мне пришлось чуток поизучать логов, чтобы понять, косяк ли это в моем коде или же в чем-то ещё. Логи гласили, что если расстояние между пальцами было менее 510 пикселей, то
ScaleGestureDetector просто переставал реагировать на касания, присылая эвент onScaleEnd(). Информации о том, что есть какой-то там «минимальный пинч» не присутствовала ни в доках, ни на stackoverflow. Возможно, я бы даже не заметил подобное, если бы отладка происходила не на эмуляторе. На нём дистанция пинча может быть хоть миллиметровой, что и послужило поводом для поиска информации по вопросу. Однако, она оказалась куда ближе, чем я думал, а именно, как всегда, в исходниках:mMinSpan = res.getDimensionPixelSize(com.android.internal.R.dimen.config_minScalingSpan);И-и-и-и-и… конечно же у класса нет методов для изменения этого поля, и конечно же
com.android.internal.R.dimen.config_minScalingSpan равен магическим 27mm. Для меня вообще существование минимального пинча представляется очень странным явлением. Даже если и есть смысл в подобном, почему не дать возможность его изменить?Решением проблемы как обычно является рефлексия.
2.8.2.2. Слоп
Для тех, кто не знает, что такое «слоп» (как и я), перевожу:
Slop — чушь, бессмыслица © ABBYY Lingvo
Ладно-ладно, шутки в сторону. «Слоп» это такое состояние, когда считается, что юзер случайно задел экран и на самом деле не хотел ничего двигать/скроллить/зумить/ещё чего. Эдакая «защита от случайного движения». Гифка объяснит:

… на гифке видно, что до начала пинча допускаются минимальные движения, которые не будут считаться пинчем. В принципе, хорошая вещь, плюсую.
Но… слоп то тоже не изменяем!
ScaleGestureDetector описывает его так:mSpanSlop = ViewConfiguration.get(context).getScaledTouchSlop() * 2;ViewConfigeuration так:mTouchSlop = res.getDimensionPixelSize(
com.android.internal.R.dimen.config_viewConfigurationTouchSlop);Откуда именно такое значение? Зачем? Почему? Непонятно… В общем, Android SDK – это лучший учебник по рефлексии.
UPD: feature-request для Slop/Span на code.google.com.
2.8.2.3. Скачки detector.getScaleFactor() при первом пинче
Внутрь эвента
onScale(ScaleGestureDetector detector) передается detector, у которого при помощи метода detector.getScaleFactor() можно узнать коэффициент пинча. Так вот, при самом первом пинче, этот метод возвращает странные скачкообразные значения. Вот логи значений при строго движении zoom out:0.958
0.987
0.970
1.009
0.966
0.967
1.006Выглядело это, мягко говоря, не очень – постоянно дергался размер вьюшки, а уж как анимации при этих скачках выглядели – лучше и вовсе опустить.
Я долго пытался понять, в чем же проблема. Проверял на реальном устройстве (мало ли, вдруг проблема эмулятора), двигал мышкой так, будто за лишний миллиметр движения где-то умирает котик (мало ли, вдруг я дерганный и отсюда
коэф. > 1 в логах) – но нет. Ответ найден не был, но мне повезло. Так сказать «от балды», решил попробовал отправить в ScaleGestureDetector эвент MotionEvent.ACTION_CANCEL сразу после инициализации:scaleDetector = new ScaleGestureDetector(getContext(), new ScaleListener());
long time = SystemClock.uptimeMillis();
MotionEvent motionEvent = MotionEvent.obtain(time - 100, time, MotionEvent.ACTION_CANCEL,
0.0f, 0.0f, 0);
scaleDetector.onTouchEvent(motionEvent);
motionEvent.recycle();… и это помогло О_о… Покопавшись (который уже раз, а, Android SDK?) в исходниках, обнаружилось, что у первого пинча нет слопа (да-да, это того, о котором писалось выше). Почему так – для меня осталось загадкой, ровно как и то, почему этот хак помог. Вероятнее всего где-то они намудрили с инициализацией и часть класса считает, что самый первый пинч уже прошел проверку на слоп, а другая часть считает, что нет, и в итоге в пылу жаркой битвы вида «прошел / не прошел» попеременно побеждает одна из них. ?\_(?)_/? © SDK
UPD: Bug-report на code.google.com.
2.9. ScrollView.setScroll() срабатывает только после super.onLayout()?
Возвращаемся к проблеме с игнорированием
ScrollView установленных дочерними элементами height’ов. Ситуация следующая: как только происходит пинч, хотелось бы чтобы текущий фокус (куда ты кликнул мышкой и из какой точки вообще делаешь зум) остался тем же. Почему? Ну просто так зум выглядит более user-friendly, считай, ты не просто изменяешь height дочернего элемента, а именно зумишь к какому-то юзеру, в то время как все остальные разъезжаются от него:
Сделать это не сложно через
ScaleGestureDetector.getFocusY() вместе с ScrollView.getScrollY(). Затем, казалось бы, достаточно сделать ScrollView.setScrollY(newPosition) и дело в шляпе… Но нет, вью начинает странно дергаться при зуме к самому нижнему дочернему элементу: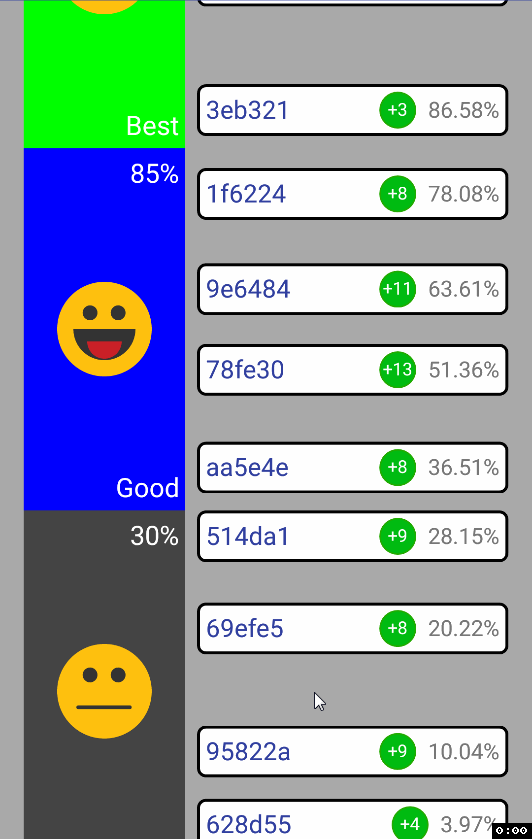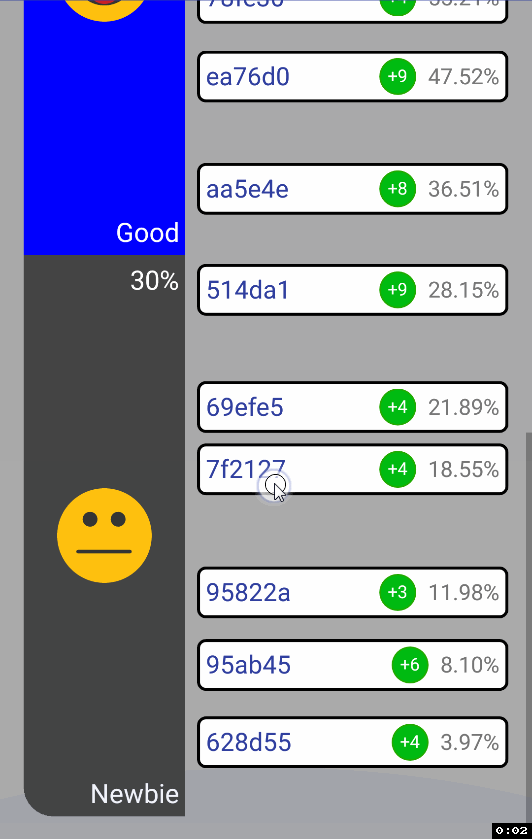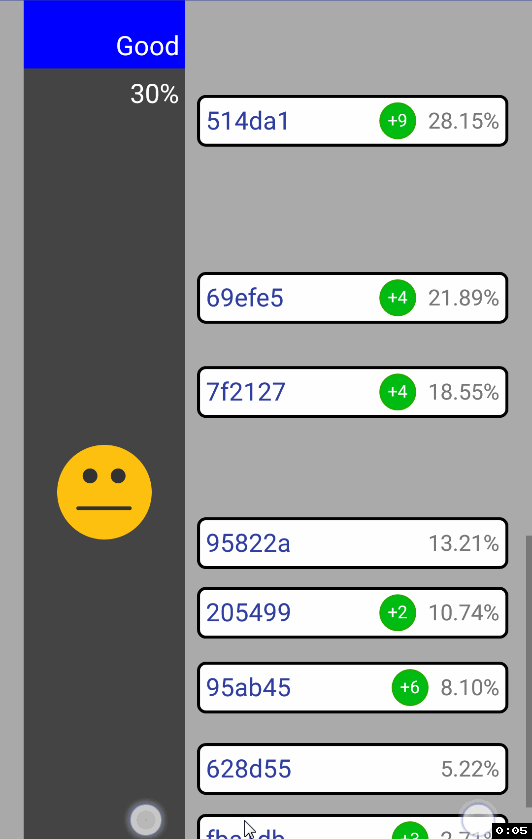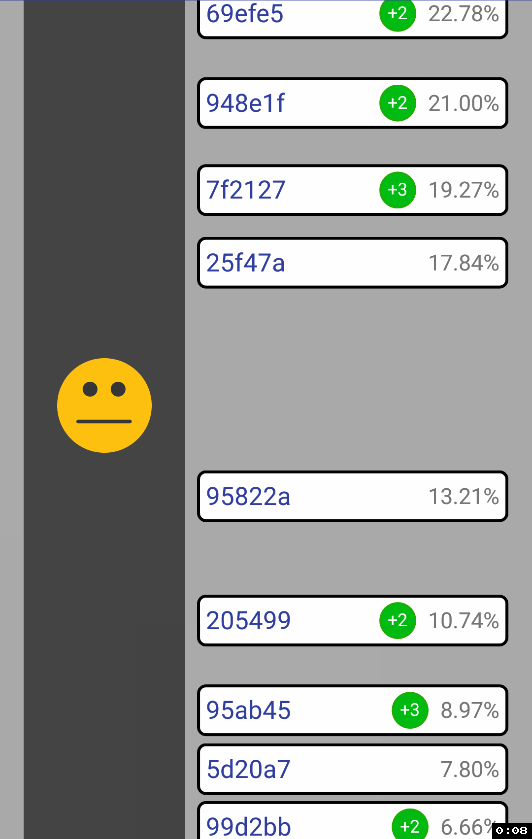
Решение нашлось здесь. Происходит следующее: в момент, когда мы делаем
setScroll() происходит проверка того, не выходит ли позиция скролла за размер дочернего элемента, и если выходит, то устанавливаем максимально возможную позицию. А так как setScroll() вызывается при зуме, то и получается следующая последовательность действий:- Просчитываем newHeight
- Просчитываем newScrollPos
- Устанавливаем newHeight через setLayoutParams()
- Устанавливаем newScrollPos через setScroll()
Проблема в пункте №3. Реальный
height не изменится до следующего super.onLayout(), поэтому setScroll() и делает не то, что ожидается. Исправляется следующий образом. Вместо setScroll() делаем так:nextScrollPos = newScrollY;onLayout() после метода super.onLayout() вызываем этот метод:private void updateScrollPosition() {
if (nextScrollPos != null) {
setScrollY(nextScrollPos.intValue());
nextScrollPos = null;
}
}Как вы помните, я писал, что лучше бы не вызывать никаких методов после
super.onLayout(). Это по-прежнему так. Позже я опишу ещё одну проблему, связанную с этим решением. Но факт остается фактом, это – решение для проблемы скачка скролла.p.s. Однако если не использовать хак с «меняем
height для child внутри child внутри ScrollView», то такой проблемы не будет. Но тогда возвращаемся к проблеме десятка подклассов.3. Задача кластеризации юзеров
Теперь время поговорить о самой задаче, её алгоритме и некоторых её особенностях.
3.1. Что делать с граничными юзерами?
Я говорю о юзерах, которые находятся на границе своего ранга:
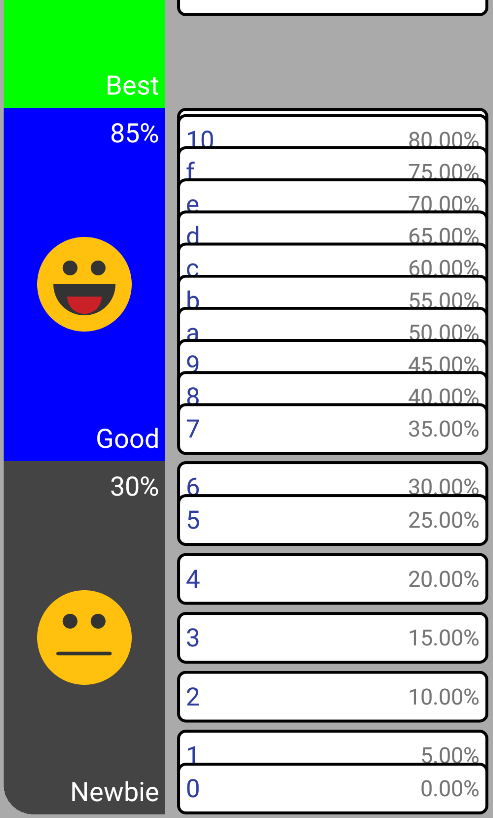
На картинке граничные юзеры — это юзеры с очками 0%, 30%, 85% (его почти полностью перекрыл юзер с 80%). Самым простым способом было бы рисовать их на своей законной позиции (равной: ), но в таком случае они начнут заезжать в чужие ранги, что выглядело бы мягко говоря «не комильфо». Основная причина отказа от этого – группировка. Представьте себе юзера с 29% очков. Он находится на границу ранга «Newbie». Но вот он вдруг объединяется с юзером с 33% очками и их совместная группа теперь расположена в позиции, соответствующей 31%, т.е., в ранге «Good». Мне не очень понравилась идея, что группировка вьюшек может менять ранги юзеров, поэтому от неё я отказался и решил ограничить юзеров внутри рангов так, как вы видели на картинке выше.
Забегая вперед отмечу, что это добавило очень много мороки алгоритму группировку и логике работы приложения в целом.
3.2. Какое кол-во очков показывать у группы?
Допустим, в группу объединились 2 юзера с очками 40% и 50%. Где расположить их совместную группу и с какими очками? Ответ простой: 45% у группы, позиция соответствует очкам группы.
Усложним задачу. А этих как объединить?

Здесь есть 2 способа решения:
- Так же, как с юзерами 40% и 50%. То есть, ставим группу на позицию 2.5%.
- Ставим группу в позицию , а очки уже вычисляем из позиции вьюшки в пикселях.
Разница подходов в том, что в первом случае вьюшка группы будет не по центру между вьюшками юзеров, во втором же она будет именно по центру, что куда более благоприятно с точки зрения user experience.
Предпочитая UX, я решил делать именно способом №2, однако у подхода обнаружился существенный недостаток: очки группы вычисляются совершенно криво. Дело в том, что юзер с 0% на самом деле расположен не в позиции 0 (ведь в таком случае он бы заезжал на территорию чужого ранга), поэтому можно сказать что у всех вьюшек в ранге не может быть очков меньше, чем некоторый
minScore, который ещё и меняется при зуме, ведь вычисляется по формуле (упрощенная версия):… так как
userViewHeight неизменен, а containerHeight меняется, то в разные моменты пинча очки у граничных вью будут разные.Более того, сама формула:
… привносит ошибку округления, т.к. позиция измеряется в пикселях, которая добавляет случайность последней цифре в числе очков (на самом деле всё не совсем так. Если использовать
view.getY(), то она возвращает float, а не пиксели, и всё в порядке, а вот если испоьзовать MarginLayoutParams.topMargin, то да, ошибка будет).Учитывая все эти недостатки способа №2, было принято решение использовать способ №1, хоть и групповая вьюшка будет появляться не точно по центру между юзер-вьюшками.
3.3. Алгоритм
Вот уж где можно разгуляться. Что я и сделал. У меня было по крайней мере 5 различных реализаций, которые так или иначе были подвержены «неприятным» эффектам, которые вынуждали меня вновь и вновь решать проблему по-новому.
Я мог бы написать финальную реализацию и закончить на этом, но всё же предпочел описать несколько своих реализаций. Если вам интересна описанная ниже проблема кластеризации, подумайте, как бы вы её решили (какой алгоритм бы придумали/использовали), а уже затем читайте абзац за абзацем, меняя своё решение, если оно, также как было моё, подвержено артефактам.
3.3.1. Задача
Сделать кластеризацию с хорошим UX, а это значит, что:
- Граничные вью должны оставаться внутри ранга.
- Юзеры должны объединяться в строго заданном порядке – не допускается, что при
zoom inс последующимzoom outи повторнымzoom inюзеры будут объединяться в группы как-то иначе. - Юзеры устанавливаются единожды и больше не добавляются/удаляются (правило добавлено из соображений по пункту №2).
3.3.2. Пару слов об алгоритмах
Важно отметить, что во всех реализациях перед запуском самого алгоритма производится сортировка всех юзеров по их очкам и каждый юзер оборачивается в класс
Group, ведь по сути, одиночный юзер — это просто группа из одного человека. Также, используя слово «юзер» я могу подразумевать как одного юзера до объединения в группу, так и группу юзеров.По поводу обозначений. Я буду отмечать номер юзера одной цифрой: «7», — а группы – двумя: «78». Цифры в номере группы обозначают номера юзеров в неё входящих, то есть группа 78 состоит из юзеров 7 и 8.
К каждому алгоритму будет приведено как словесное описание, так и псевдокод.
3.3.3. Алгоритм №1
Простой последовательный алгоритм, объединяющий юзеров в порядке следования, если они пересекаются.
Шаги:
1. Проверить, пересекаются ли юзеры с индексом i и i+1.
2.1. Если пересекаются – объединить и сделать ячейкой №1.
2.2. Если не пересекаются, инкрементировать индекс.
3. Повторять с шага 1 пока не достигнут последний индекс.for (int i = 0; i < groups.size() - 1; ) {
if (isInersected(groups[i], groups[i+1])) {
groups[i].addUsersToGroup(groups[i+1]);
groups.remove(i+1);
} else {
++i;
}
}Но у этого алгоритма есть проблема с UX:

Он объединяет всех юзеров воедино, если те достаточно близки изначально, что приводит к нерациональному использованию пространства, а значит – алгоритм не подходит по UX.
3.3.4. Алгоритм №2
Очевидно, проблема в том, что все юзеры проверяются последовательно. Поэтому я решил чуть доработать алгоритм №1. Теперь будет как минимум пара проходов по списку юзеров: четный и нечетный проходы. Как только в обоих проходах не будет найдено пересечение, алгоритм закончится.
Шаги:
0. i = 0.
1. Проверить, пересекаются юзеры с индексом i и i+1.
2.1. Если пересекаются – объединить, и записать в первую ячейку. Индекс инкрементируется на 1.
2.2. Если не пересекаются, индекс инкрементируется на 2.
3. Если не достигнут последний индекс, повторить шаг 1.
4. Если i == 1 и не нашлось пересекающихся групп, то закончить алгоритм.
5. Повторить с шага 0, инвертировав i (с 0 на 1 или с 1 на 0 – смена на нечетный или четный проходы).bool didIntersected, isEvenPass = false;
do {
didIntersected = false;
isEvenPass = !isEvenPass;
int i = isEvenPass ? 0 : 1;
while (i < (groups.size() - 1)) {
if (isInersected(groups[i], groups[i+1)) {
didIntersected = true;
groups[i].addUsersToGroup(groups[i+1]);
groups.remove(i+1);
i += 1;
} else {
i += 2;
}
}
} while(isEvenPass || didIntersected);Алгоритм решает предыдущую проблему, но появляется новая, связанная с неправильным разъединением после объединения (из-за иной скорости зума). Такую проблему я называю «проблема 21-12» (название поясню позже):
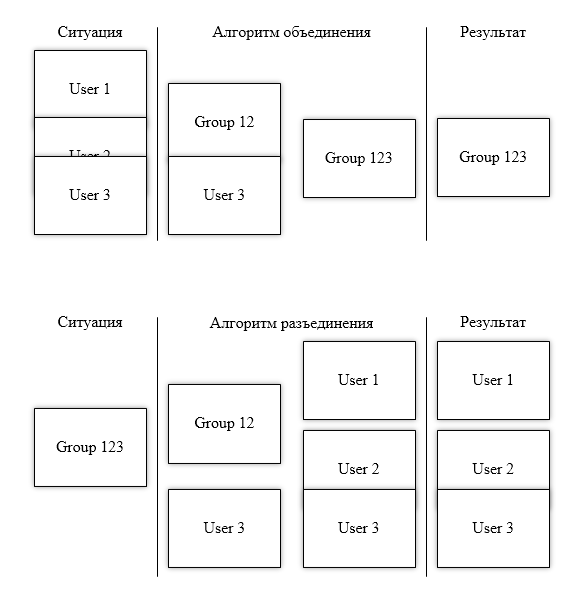
Объясню, что здесь произошло. При запуске алгоритма, было выявлено, что 1 и 2 юзеры пересекаются и образуют группу. С их группой пересекается 3ий юзер, а посему все они образуют ещё одну группу.
Однако если попробовать их расцепить при более быстром зуме, то произойдет то, что вы видите в нижней части картинки – два юзера будут пересекаться, но не будут образовывать группу.
Даже если после разбиения запускать ещё один проход объединения, мы получим группу 23, которой раньше не существовало. Раньше юзеры объединялись в группы с размером 2 и 1, а теперь, после разъединения, они образуют группы размером 1 и 2. Отсюда и название «проблема 21-12». Это плохо сказывается на UX, когда группу объединяются по-разному в зависимости от скорости зума, а значит алгоритм не подходит.
3.3.5. Алгоритм №3
Тут мне стало ясно, что тупо в лоб задачу не решить и придётся использовать артиллерию потяжелее. Поэтому я решил объединять юзеров на основе расстояния между ними (их вьюшками). Чем меньше расстояние между юзерами – тем первее их объединение. А для того, чтобы разбивать группы, можно просто ввести поле типа
Stack<Group> groupsStack; и добавлять туда каждую новую группу. Таким образом при разъединении потребуется проверять лишь самый верхний элемент на стэке.Шаги:
0. Создать массив дистанций между каждой последовательной парой юзеров (массив получится длиной groups.size() – 1, ведь пересечься юзер/группа может только со своими соседями слева и справа). Отсортировать массив дистанций по возрастанию
1. Проверить первую дистанцию между вьюшками. Она меньше либо равно 0?
YES.1. Объединить 2-ух юзеров в группу и добавить группу в стэк групп.
YES.2. Удалить текущую дистанцию. Обновить дистанции, которые зависели от этих 2-ух юзеров, заменив их на дистанцию до их совместной группы.
YES.3. Отсортировать массив дистанций по возрастанию.
YES.4. Перейти к шагу 1.
NO.1. Закончить алгоритм.distances.sortAsc();
while (!distances.isEmpty() && distances.getFirst().distance <= 0) {
firstDistance = distances.getFirst();
mergedGroup = new Group(firstDistance.groupLeft, firstDistance.groupRight);
groupsStack.push(mergedGroup);
distances.removeFirst();
firstDistance.groupLeft.notifyPositionChanged(mergedGroup.position);
firstDistance.groupRight.notifyPositionChanged(mergedGroup.position);
distances.sortAsc();
}
Я думал «ну уж этого точно будет достаточно». Но нет. Оказалось, и здесь есть своя проблема: неверный порядок объединения групп. «Как такое может быть?!» — подумали вы? Да очень просто. Что если сделать о-о-о-о-очень резкий зум?
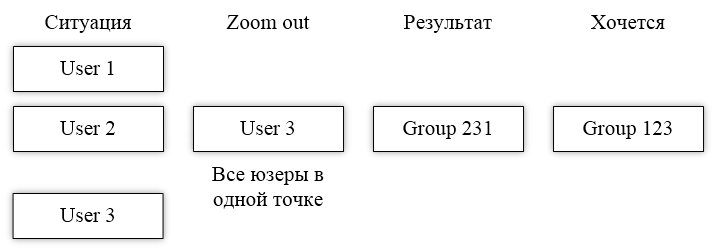
В результате резкого зума у всех юзеров позиция стала одной и той же, ведь они и до зума были достаточно близки друг к другу. Из-за этого
sortAsc() не знал, что делать, ведь расстояние между юзерами 1 и 2 равно 0, но и между юзерами 2 и 3 оно также равно 0. Как итог, группы объединились в неверном порядке. Особенно это будет заметно при разъединении. Первыми будут разъединены 12, ведь объединились они последними (стэк — это LIFO. Все помнят?), хотя они и ближе к друг другу.3.3.6. Алгоритм №3.1
Самый простой способ починить предыдущий алгоритм – дать понять для
sortAsc() разницу между разными «расстояние равно 0». И это можно сделать, просто добавив доп. проверку при сортировке, что, если distance == 0 сразу между 2-мя парами юзеров, то сверяй их group.scoreAfterMerge. Если пояснять кодом, то функцию сравнения для сортировки GroupsDistance, используемую при реализации в прошлом алгоритме:@Override
public int compareTo(@NonNull GroupsDistance obj) {
GroupsDistance a = this, b = obj;
final int distancesComparison = MathUtil.Compare(b.distance, a.distance);
if (distancesComparison != 0) {
return distancesComparison;
} else {
final int namesComparison = a.leftGroup.name.compareTo(b.leftGroup.name);
return namesComparison;
}
}
… заменяем этой с доп. сравнением
group.scoreAfterMerge'ов:@Override
public int compareTo(@NonNull GroupsDistance obj) {
GroupsDistance a = this, b = obj;
final int distancesComparison = MathUtil.Compare(b.distance, a.distance);
if (distancesComparison != 0) {
return distancesComparison;
} else {
final int scoresComparison =
MathUtil.Compare(a.scoreAfterMerge, b.scoreAfterMerge);
if (scoresComparison != 0) {
return scoresComparison;
} else {
final int namesComparison = a.leftGroup.name.compareTo(b.leftGroup.name)
return namesComparison;
}
}
}Действительно,
user.score и group.scoreAfterMerge всегда будут неравны (а если и равны, то нет разницы, в каком порядке их объединять — всё равно они никогда не расцепятся). Это означает, что доп. сравнения по score должно хватить для решения задачи… но нет, и в этом случае присутствует недочет. Помните условие задачи: «Граничные вью должны оставаться внутри ранга»? Проблема кроется в нём. Если бы не это условие,
distance между юзерами всегда изменялся бы пропорционально, а позиция вьюшки юзера однозначно отображала бы его score, но это не так. Из-за этого условия, у граничных вью нарушается зависимость позиции от score. Это довольно неочевидно, поэтому вот подробный пример подобного «нарушения»:Допустим, высота у вьюшек юзеров 100. Тогда если у юзера позиция 0, то его нижняя координата равна 100. Юзеров я буду отмечать вот так: [0, 100], то есть в виде [начало_вьюшки, конец_вьюшки]. Считайте, что мы работаем с 1D пространством. Для определения пересечения между двумя вьюшками (например, [0, 100] и [60, 160]) нужно вычесть из конца вьюшки №1 начало вьюшки №2, т.е. .
Итак, имеем вьюшку ранга высотой 1000 и 3-ех юзеров:
Юзер №1 с 60%: [600, 700].
Юзер №2 с 79%: [790, 890].
Юзер №3 с 100%: [900, 1000] (до коррекции: [1000, 1100]).Примечание: у юзера №3 позиция не [1000, 1100] потому, что выход за границы ранга недопустим. Поэтому его вьюшка была перемещена на ближайшую возможную позицию внутри вьюшки ранга.
Казалось бы, расстояние между №1 и №2 равно 90, между №2 и №3 равно 10. Последние пересекутся раньше при зуме, верно?.. Произведем зум с коэффициентом 0.5 (вьюшка ранга стала размером 500):
Юзер №1 со 60%: [300, 400].
Юзер №2 с 79%: [395, 495].
Юзер №3 с 100%: [400, 500] (до коррекции: [500, 600]).Расстояние между №1 и №2 равно -5, между №2 и №3 равно -95. №2 и №3 объединились раньше, чем №1 и №2, всё как и хотели, ура?.. Нет :D. Вернем зум обратно и на этот раз произведем зум с коэффициентом 0.2 (размер вьюшки ранга стал 200):
Юзер №1 со 60%: [100, 200] (до коррекции: [120, 220]).
Юзер №2 с 79%: [100, 200] (до коррекции: [158, 258]).
Юзер №3 с 100%: [100, 200] (до коррекции: [200, 300]).Расстояние между №1 и №2 равно 0, расстояние между №2 и №3 тоже равно 0. Как гласит алгоритм, сравним тогда вьюшки по user.score и… Совершенно внезапно, №1 и №2 объединились в группу раньше, чем №2 и №3, что в итоге приведет к рывкам при разъединении.
Ситуация может показаться довольно синтетической, однако она происходит не только на границе ранга, но и в центре, если сделать достаточно резкий зум. Просто для примера было проще показать проблему на границе.
«И этот алгоритм не подходит. Что же вообще делать? Что лучше, чем сортировка дистанций между вьюшками юзеров да сравнение по
score?!» — думал я в момент обнаружения проблемы.3.3.7. Алгоритм №4
Давайте создадим время. Континуум, если быть точнее. Это довольно известная задача в сфере компьютерной физики. Если квантовать время слишком большими отрезками, то объект «A» пересечет объект «B» и это не будет детектировано из-за слишком большой скорости движения. Вот пример:
Даже если мы квантуем время на наносекунды (), то в следующий момент времени позиция «B» будет считаться так:
То есть мы получим:
«B» просто прошел «A» насквозь, и мы этого никак не заметили, ведь их координаты никогда не пересекались и даже не находились вблизи.
С задачей кластеризации та же беда, только вместо скорости движения – скорость зума, а вместо позиции объектов – позиции вьюшек. В общем, суть нового, и последнего, алгоритма в том, чтобы считать не дистанции между вьюшками юзеров, а
height, при котором эти 2 юзера пересекутся! Затем останется лишь отсортировать этот массив willIntersectWhenHeight’ов и проделать всё то же самое, что с массивом дистанций в предыдущем алгоритме. Главное – не забывать, что у боковых (называемых также border или bound) юзеров/групп позиция меняется иначе, чем у остальных. Случаи пересечения с ними нужно рассматривать отдельно.Так как шаги алгоритма те же, что и раньше, то приведу только код функции, ответственной за подсчет
willIntersectWhenHeight’а в классе GroupCandidates. Пожалуй, важно отметить, что я использовал для обозначения групп не массивы, а двоичные деревья. Это позволило упростить логику работы как самого алгоритма, так и анимаций кластеризации.private float getIntersectingHeght() {
float intersectingHeight;
final Float height = calcIntersectingHeightWithNoBound();
final boolean leftIsBorder = leftGroup.isLeftBorderWhen(height), rightIsBorder = rightGroup.isRightBorderWhen(height);
if (!leftIsBorder && !rightIsBorder) {
intersectingHeight = space;
return;
}
if (leftIsBorder && !rightIsBorder) {
intersectingHeight = (itemHeight + itemHalfHeight) / right.getNormalizedPos();
return;
}
if (!leftIsBorder && rightIsBorder) {
intersectingHeight = (itemHeight + itemHalfHeight) / (1 - left.getNormalizedPos());
return;
}
if (leftIsBorder && rightIsBorder) {
intersectingHeight = ((float) (itemHeight + itemHeight));
return;
}
return intersectingHeight;
}
private Float calcIntersectingHeightWithNoBound() {
return itemHeight / (right.getNormalizedPos() - left.getNormalizedPos());
}getNormalizedPos() возвращает нормализованную (т.е., от 0 до 1) позицию внутри ранга.Этот алгоритм прошел все проверки, что я смог придумать, а также показал довольно резвую скорость работы. В общем, задача решена.
4. Нерешенные проблемы
А теперь о плохом. Изначально я планировал написать статью уже после того, как решу все проблемы, но из-за нехватки времени и мысли «а вдруг в комментах помогут – время сэкономлю», я решил выложить так, как есть. Как освободится время, я вернусь к этим проблемам, и, если не забуду, добавлю решение сюда.
4.1. ScrollView.setScroll() внутри ScrollView.onLayout() срабатывает корректно только после вызова super.onLayout() (если изменять размер child’а внутри child’а этого ScrollView)
Эта проблема была описана ранее. Я не нашел способа, как заставить
ScrollView воспринимать setScroll() до super.onLayout(). Почему это важно? Дело в requestLayout(). Данный вызов устанавливает флаг вида «нужно сделать layout pass» и откладывает просчеты до следующего 16мс-фрейма. То есть, сколько ты requestLayout() не вызывай, до тех пор, пока не будет вызвать super.onLayout() (который расставит дочерние вью и снимет флаг), layout pass произведен не будет.Однако, если вдруг
requestLayout() будет вызван после super.onLayout(), то флаг будет установлен заново. А это значит, что во время следующего фрейма отрисовки (через 16мс), произойдет новый layout pass, который вызовет ScrollView.onLayout(), в котором опять будет запрошен requestLayout() после super.onLayout() и… в общем, каждый 16мс-фрейм будет происходить полный пересчет Layout’ов всех вьюшек на экране. Короче, тихий ужас. Но если такое случается только после попытки сделать requestLayout() после super.onLayout(), а ScrollView.setScroll() не вызывает requestLayout(), то в чем же проблема? А вот в чем:4.2. View.setVisibility(GONE) вызывает requestLayout()
Текущая реализация алгоритма (которая с континуумом) работает очень быстро, но не реализация отрисовки вьюшек. В идеале, необходимо добавить recycling вьюшек юзеров/групп, да и вообще не пытаться отрисовывать вьюшки, что находятся за пределами экрана.
Такое возможно сделать, используя
View.getLocalVisibleRect() (возвращает координаты видимого окна) внутри UsersView и затем для каждого вью что попал на экран, делать groupView.setUsersGroup(group), внутри которого будет groupsCountView.setVisiblity(…).Однако! Его нужно использовать после того, как будет произведен
ScrollView.setScroll(), ведь данный вызов меняет результат View.getLocalVisibleRect(). А так как ScrollView.setScroll() вызывается после super.onLayout(), а groupView.setUsersGroup(group) может вызвать View.setVisiblity(GONE), который вызывает requestLayout(), то мы получаем бесконечный цикл, описанный в предыдущей проблеме.Более того, при каждом скролле даже не связанном с зумом будет меняться видимое окно, а значит нужно будет показывать иные вьюшки, вызывая заново
View.getLocalVisibleRect(), который приведет к вызовам View.setVisiblity(GONE), а они к requestLayout(). То есть, при каждом скролле будет происходить requestLayout() – это просто немыслимо!Я пытался решить это по-разному, но даже если переопределить метод
requestLayout() внутри GroupView, получается полурабочий результат (дочерние вью внутри GroupView начинают периодически «скакать»… сложно объяснить. Причину не нашел), да и способ «переопределить requestLayout()» мне не слишком то нравится. Слишком уж он «дерзкий», так сказать. Возможно, есть иное решение, но stackoverflow вместе с гуглом молчат как партизаны.5. Заключение
Задача оказалась куда сложнее и интереснее, чем я себе представлял. Хотел лишь поучиться делать анимацию пересечения, а в итоге поработал с алгоритмами, порылся в исходниках SDK и много чего ещё. С Android’ом скучать не приходится.
Большинство алгоритмических проблем вылезло из-за условия о том, что юзеры не должны заходить за границы ранга. Пока делал алгоритм, столько раз хотел выкинуть это условие, вы б знали -_-"… но по итогу я доволен. Надеюсь, и вы тоже.
Код приложения найти можно здесь — github.com/Nexen23/RankingListView
Если у вас есть предложения по решению «нерешенных проблем» — пишите в комментариях. Я проверю решение и, если всё хорошо, то обновлю текст.
UPD 04.03.17: как предложил мистер Artem_007, добавлены feature-request/bug-report ссылки на упомянутые проблемы.
Поделиться с друзьями
Комментарии (10)


andreich
27.02.2017 13:29Интересно читать чужой опыт, но надо было разбить статью на несколько и сделать серию. Дело в том, что получилась солянка. Да и читать несколько маленьких статей проще, чем одну огромную.

andrewgrow
27.02.2017 17:17С интересом прочитал статью. Возможно, кому-нибудь она покажется избыточной. С другой стороны — никаких подобных справочников по траблам при создании достаточно сложного элемента я, например, не встречал. Да пребудет с вами сила, а с материалу — вечное хранение на Хабре!
Спасибо )
Artem_007
28.02.2017 15:49Наконец что-то годное в хабе андроида)
А не ересь вида:
«Проблемы, возникающие при разработке android-приложений»
Не пробовали создавать ишью в багтрекере андроида?
у первого пинча нет слопа
и прочие?
Yoto
28.02.2017 15:52А ведь и правда, надо бы создать. Как закончу с оптимизацией вьюшки, добавлю все найденные issues на багтрекер.
shakagamii
Можно вопрос, а почему вы решили идти по такому сложному пути, а не решились просто сделать кастомный адаптер и LayoutManager для того же RecyclerView? Это скорее всего решило бы ваши проблемы, так и дало бы больше гибкости.
Yoto
Причины было две:
1. Я хотел поработать с вьюшками на уровне measure/layout. До этого я знал лишь как работать с
View.onDraw().2.
RecyclerViewотображает элементы последовательно друг за другом. В моем же случае между ними могут быть пробелы. Я мог бы извратиться, добавив вью типаSpaceмежду ними, или, возможно, установкаmarginTopдля каждого элемента сделала бы дело, или же использованиеRecyclerView.ItemDecorationрешило бы вопрос. Но в итоге я решил, что это чересчур большой костыль, с учетом того, что ещё и анимацию слияния придётся как-то добавлять в эту кашу, поэтомуRecyclerViewя отбросил ещё на первых этапах продумывания задачи.sergeyfitis
> RecyclerView отображает элементы последовательно друг за другом
RecyclerView не имеет никакого отношения к построению чаилдов, этим занимается LayoutManager. Если надо реализовать свой порядок построения элементов, то только через реализацию своего LayoutManager
Yoto
Кстати да, Вы правы. Кастомный
LayoutManagerещё не писал. Надо будет посмотреть, как оно бы через него реализовывалось.sbnur
Согласен — исходная организация данных и кастомный адаптер