
31 мая на конференции RootConf 2016, проходившей в рамках фестиваля «Российские интернет-технологии» (РИТ++ 2016), секция «Непрерывное развертывание и деплой» открылась докладом «Лучшие практики Continuous Delivery с Docker». В нём были обобщены и систематизированы лучшие практики построения процесса Continuous Delivery (CD) с использованием Docker и других Open Source-продуктов. С этими решениями мы работаем в production, что позволяет опираться на практический опыт.

Если у вас есть возможность потратить час на видео с докладом, рекомендуем посмотреть его полностью. В ином случае — ниже представлена основная выжимка в текстовом виде.
Continuous Delivery с Docker
Под Continuous Delivery мы понимаем цепочку мероприятий, в результате которых код приложения из Git-репозитория сначала приходит на production, а потом попадает в архив. Выглядит она так: Git > Build (сборка) > Test (тестирование) > Release (релиз) > Operate (последующее обслуживание).
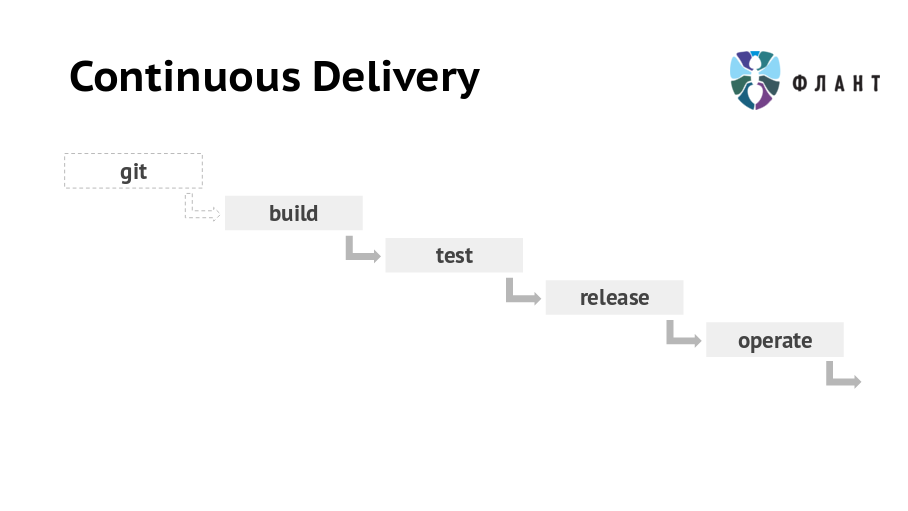
Большая часть доклада посвящена стадии build (сборка приложения), а темы release и operate затронуты обзорно. Речь пойдёт о проблемах и паттернах, позволяющих их решить, а конкретные реализации этих паттернов могут быть разными.
Почему здесь вообще нужен Docker? Не просто так мы решили рассказать про практики Continuous Delivery в контексте этого Open Source-инструмента. Хотя его применению посвящён весь доклад, многие причины раскрываются уже при рассмотрении главного паттерна выката кода приложения.
Главный паттерн выката
Итак, при выкате новых версий приложения мы непременно сталкиваемся с проблемой простоя, образующегося во время переключения production-сервера. Трафик со старой версии приложения на новую не может переключаться мгновенно: предварительно мы должны убедиться, что новая версия не только успешно выкачена, но и «прогрета» (т.е. полностью готова к обслуживанию запросов).

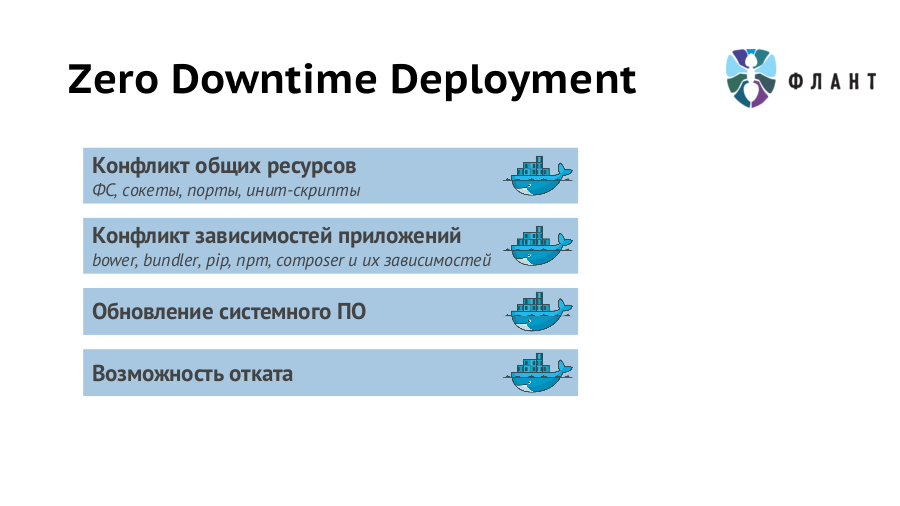
Таким образом, некоторое время обе версии приложения (старая и новая) будут работать одновременно. Что автоматически приводит к конфликту общих ресурсов: сети, файловой системы, IPC и т.п. С Docker эта проблема легко решается запуском разных версий приложения в отдельных контейнерах, для которых гарантируется изоляция ресурсов в рамках одного хоста (сервера/виртуальной машины). Конечно, можно обойтись некоторыми ухищрениями и без изоляции вовсе, но если существует готовый и удобный инструмент, то есть и обратный резон — не пренебрегать им.
Контейнеризация даёт много других плюсов при деплое. Любое приложение зависит от определенной версии (или диапазона версий) интерпретатора, наличия модулей/расширений и т.п., а также и их версий. И относится это не только к непосредственной исполняемой среде, но и ко всему окружению включая системный софт и его версии (вплоть до используемого Linux-дистрибутива). Благодаря тому, что контейнеры содержат не только код приложений, но и предварительно установленный системный и прикладной софт нужных версий, о проблемах с зависимостями можно забыть.
Обобщим главный паттерн выката новых версий с учётом перечисленных факторов:
- Сначала старая версия приложения работает в первом контейнере.
- Затем новая версия выкатывается и «прогревается» во втором контейнере. Примечательно, что сама эта новая версия может нести не только обновлённый код приложения, но и любых его зависимостей, а также системных компонентов (например, новую версию OpenSSL или всего дистрибутива).
- Когда новая версия полностью готова к обслуживанию запросов, трафик переключается с первого контейнера на второй.
- Теперь старая версия может быть остановлена.
Такой подход с развёртыванием разных версий приложения в отдельных контейнерах даёт ещё одно удобство — быстрый откат на старую версию (ведь достаточно переключить трафик на нужный контейнер).
Итоговая первая рекомендация звучит так, что даже Капитану не придраться: «[при организации Continuous Delivery с Docker] Используйте Docker [и понимайте, что это даёт]». Помните, что это не «серебряная пуля», решающая любые проблемы, но инструмент, который даёт замечательный фундамент.
Воспроизводимость
Под «воспроизводимостью» мы понимаем обобщённый набор проблем, с которыми встречаются при эксплуатации приложений. Речь идёт о таких случаях:
- Сценарии, проверенные отделом качества на staging, должны точно воспроизводиться в production.
- Приложения публикуются на серверах, которые могут получить пакеты с разных зеркал репозиториев (со временем они обновляются, а вместе с ними — и версии устанавливаемых приложений).
- «У меня локально всё работает!» (… и разработчиков на production не пускают.)
- Требуется проверить что-то в старой (архивной) версии.
- …
Общая их суть сводится к тому, что необходимо полное соответствие используемых окружений (а также отсутствие человеческого фактора). Как же гарантировать воспроизводимость? Делать Docker-образы на базе кода из Git, а затем использовать их для любых задач: на тестовых площадках, в production, на локальных машинах программистов… При этом важно минимизировать действия, которые выполняются после сборки образа: чем проще — тем меньше вероятность ошибок.
Инфраструктура — это код
Если требования к инфраструктуре (наличие серверного ПО, его версии и т.п.) не формализовать и не «программировать», то выкат любого обновления приложения может закончиться печальными последствиями. Например, на staging вы уже перешли на PHP 7.0 и переписали код соответствующим образом — тогда его появление на production с каким-нибудь старым PHP (5.5) непременно кого-то удивит. Пусть про крупное изменение версии интерпретатора вы не забудете, но «дьявол кроется в деталях»: сюрприз может оказаться в минорном обновлении любой зависимости.
Решающий эту проблему подход известен как IaC (Infrastructure as Code, «инфраструктура как код») и подразумевает хранение требований к инфраструктуре вместе с кодом приложения. При его использовании разработчики и DevOps-специалисты могут работать с одним Git-репозиторием приложения, но над разными его частями. Из этого кода в Git создаётся образ Docker, в котором приложение развёрнуто с учётом всей специфики инфраструктуры. Проще говоря, скрипты (правила) сборки образов должны лежать в одном репозитории с исходниками и вместе мержиться.
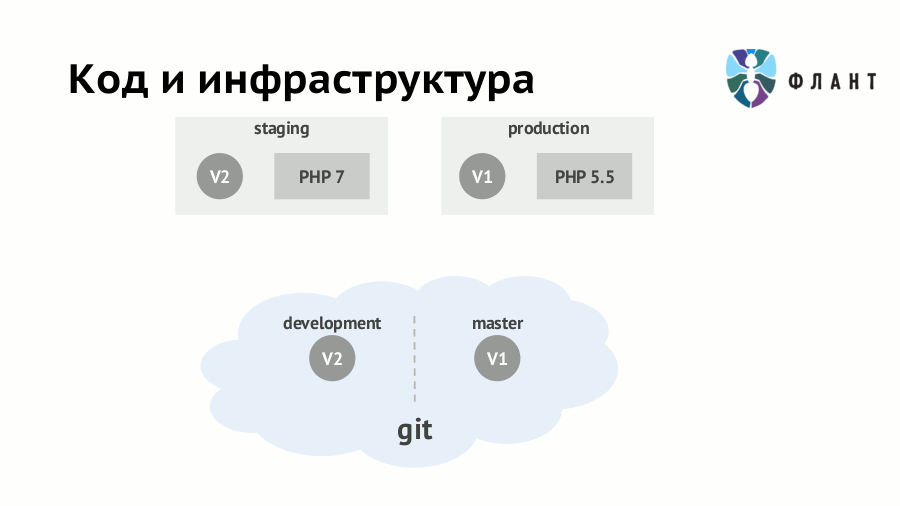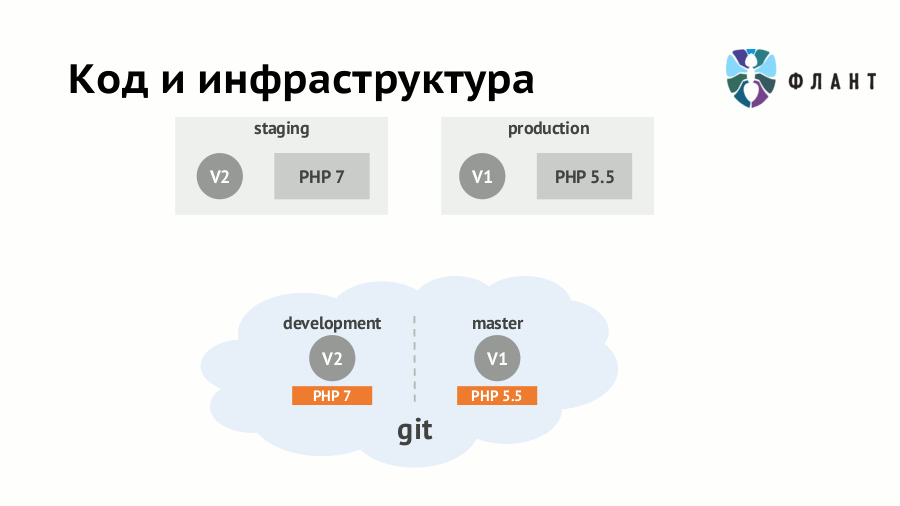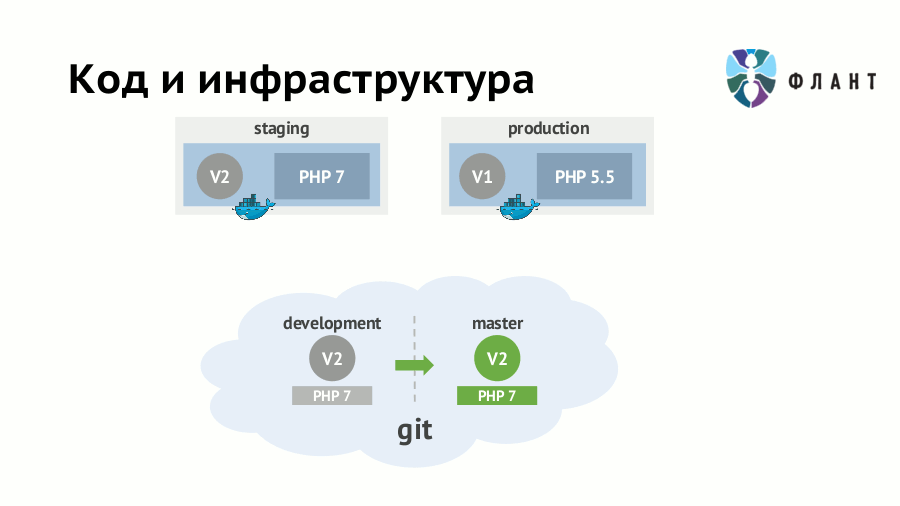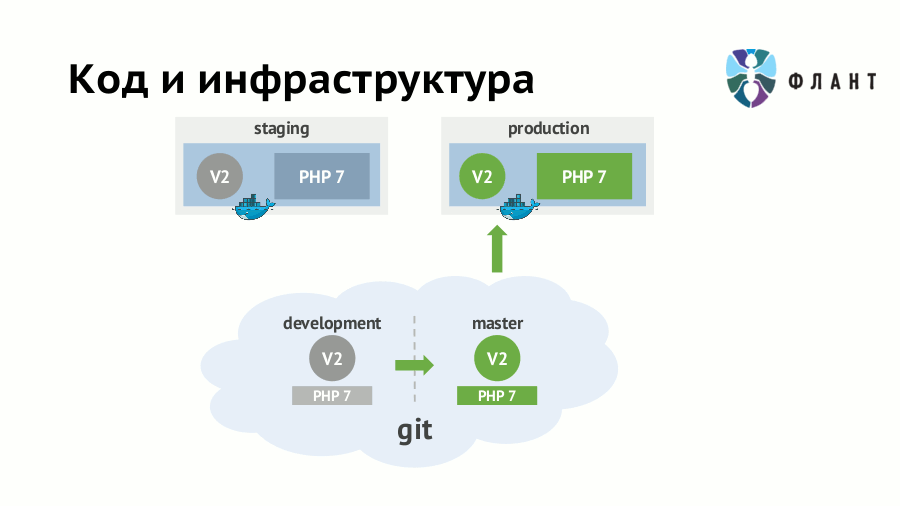
В случае многослойной архитектуры приложения — например, есть nginx, который стоит перед приложением, уже запущенным внутри Docker-контейнера, — образы Docker должны создаваться из кода в Git для каждого слоя. Тогда в первом образе будет приложение с интерпретатором и другими «ближайшими» зависимостями, а во втором — вышестоящий nginx.
Docker-образы, связь с Git
Все Docker-образы, собираемые из Git, мы разделяем на две категории: временные и релизные. Временные образы тегируются по названию ветки в Git, могут перезаписываться очередным коммитом и выкатываются только для предварительного просмотра (не для production). В этом их ключевое отличие от релизных: вы никогда не знаете, какой конкретно коммит в них находится.
Имеет смысл собирать во временные образы: ветку master (можно автоматически выкатывать на отдельную площадку, чтобы постоянно видеть текущую версию master), ветки с релизами, ветки конкретных нововведений.

После того, как предварительный просмотр временных образов приходит к необходимости перевода в production, разработчики ставят определённый тег. По тегу автоматически собирается релизный образ (его тегу соответствует тег из Git) и выкатывается на staging. В случае его успешной проверки отделом качества он попадает на production.
dapp
Всё описанное (выкат, сборку образов, последующее обслуживание) можно реализовать самостоятельно с помощью Bash-скриптов и других «подручных» средств. Но если так делать, то в какой-то момент реализация приведёт к большой сложности и плохой управляемости. Понимая это, мы пришли к созданию своей специализированной Workflow-утилиты для построения CI/CD — dapp.
Её исходный код написан на Ruby, открыт и опубликован на GitHub. К сожалению, документация на данный момент — самое слабое место инструмента, но мы работаем над этим. И ещё не раз напишем и расскажем о dapp, т.к. нам искренне не терпится поделиться его возможностями со всем заинтересованным сообществом, а пока присылайте свои issues и pull requests и/или следите за развитием проекта на GitHub.
Kubernetes
Другой готовый Open Source-инструмент, уже получивший значительное признание в профессиональной среде, — это Kubernetes, кластер для управления Docker. Тема его использования в эксплуатации проектов, построенных на Docker, выходит за рамки доклада, поэтому выступление ограничено обзором некоторых интересных возможностей.
Для выката Kubernetes предлагает:
- readiness probe — проверку готовности новой версии приложения (для переключения трафика на неё);
- rolling update — последовательное обновление образа в кластере из контейнеров (отключение, обновление, подготовка к запуску, переключение трафика);
- synchronous update — обновление образа в кластере с другим подходом: сначала на половине контейнеров, затем на остальных;
- canary releases — запуск нового образа на ограниченном (небольшом) количестве контейнеров для мониторинга аномалий.
Поскольку Continuous Delivery — это не только релиз новой версии, в Kubernetes есть ряд возможностей для последующего обслуживания инфраструктуры: встроенный мониторинг и логирование по всем контейнерам, автоматическое масштабирование и др. Всё это уже работает и только ожидает грамотного внедрения в ваши процессы.
Итоговые рекомендации
- Используйте Docker.
- Делайте Docker-образы приложения для всех потребностей.
- Следуйте принципу «Инфраструктура — это код».
- Свяжите Git с Docker.
- Регламентируйте порядок выката.
- Используйте готовую платформу (Kubernetes или другую).
Видео и слайды
Видео с выступления (около часа) опубликовано в YouTube (непосредственно доклад начинается с 5-й минуты — по ссылке воспроизведение с этого момента).
Презентация доклада:
Комментарии (14)

cag01
28.02.2017 11:16Как обновлять с zero-downtime пару контейнеров nginx, которые содержат статику из приложения? Понятно, что их надо спрятать за haproxy и обновлять поочередно? Но как сделать так, чтобы коннекты при этом не оборвались?

kemko
28.02.2017 11:23Ещё не решал такую задачу, но мне видится это, как сочетание
http://serverfault.com/questions/249316/how-can-i-remove-balanced-node-from-haproxy-via-command-line и
https://nginx.org/ru/docs/http/ngx_http_stub_status_module.html
Трафик снимается, затем через периодические запросы stub_status проверяется, что коннектов не осталось, затем можно обновлять.
Можно даже не заморачиваться с sub_status, у haproxy можно забирать по csv текущую статистику, включая и количество активных запросов к бэкэндам.

crezd
28.02.2017 12:37Можно просто выключить nginx «gracefully», он подождет пока все открытые коннекты отработают и выключится
kemko
28.02.2017 12:54Тоже вариант. Но всё равно стоит это соединить с предварительной просьбой frontend'у не слать новые запросы на этот backend. Без этого несколько запросов могут потеряться, пока frontend сам не поймёт, что этот backend больше ему недоступен.

distol
28.02.2017 13:32+1Если вкратце — то сочетание graceful shutdown, встроенного в nginx, и правильно подобранного таймаута. Если это обычная статика (js, css, картинки) и обычные клиенты, то таймаут в 10 секунд норм. Если превалируют медленные клиенты (мобилки, хот споты) или большие объемы (видео блобы и пр.) — таймаут можно увеличивать. Подбирать таймаут по перцентиль 99 response time в Nginx (он как раз и включает время до последнего отданного байта).
Ну и важный момент, что Docker по умолчанию шлет SIGTERM при остановке контейнера, а Nginx'у нужно послать SIGQUIT. Как этого добиться — очень сильно зависит (используете ли какой-то супервизор, или сразу запускаете Nginx, используете голый Docker, или с какой-то оркестрацией).

lukashin
28.02.2017 13:42Можно реализовать примерно так.
На haproxy настраиваете проверку «здоровья» серверов
backend app ... option httpchk GET /health_check/ http-check expect string success ...
А в приложении — ответ на этот урл. Для переключения можно использовать файл-флаг.

Freezy
Спасибо за статью!
Сейчас в процессе переезда на CI deploy с помощью Rancher.
В похожих статьях всегда обходят стороной проблему «zero downtime deployment» для баз данных.
Если с приложением нет особых проблем держать рабочими сразу одновременно несколько версий, то с БД все сложнее.
Приложение при выкладке может накатывать миграции. Миграции могут поменять структуру базы, а во время переключения пользователи уже сгенерируют данные в БД под старую структуру.
Есть ли хорошее решение этой проблемы?
sss116
Поддерживаю вопрос. Особенно интересно если миграция идёт например час, на большой базе.
square
А без контейнеров как вы это делаете?
crezd
По-моему очевидного ответа тут не будет.
distol
Да, вопрос с миграциями в базе очень важный. Решение есть, но серебрянной пули — нет. Нужно следовать одному простому правилу — миграции должны быть всегда обратносовместимы.
Катим новую версию, в ней миграции, эти миграции не должны ломать старую версию. Соответственнок катим сначала миграции, которые пусть и выполняются долго, но все продолжает работать, так как старый код с ними совместим. А уже как миграции прошли — катим новый код.
Следование этому правилу дополнительно дает возможность отката на предыдущую версию без отката базы. Это важный бонус, чтобы можно было быстро откатиться.
Какие это правило накладывает ограничения? С первого взгляда можно только добавлять колонки и только с необязательным значением. Если менять типы колонок, то только совместимо. Ну и добавлять новый таблицы безбоязненно. По началу выглядит пугающе, мол как так — мы не можем переименовать или удалить колонку. Но фактически, это надо делать редко. И это всегда можно сделать в два релиза (сначала выкатываем код, который больше не использует не нужную колонку/таблицу, а в следующем релизе — удаляем колонку/таблицу).
Ну и чтобы совсем торт был, нужно перед выкатом на стейджинг гнать базу с прода, выкатывать версию с прода, нагонять миграции и прогонять максимально расширенный смок тесты, чтобы получить какое-то формальное подтверждение, что миграции совместимы. Ну и обязательно все это автоматизировать. Вот как-то так.
distol
И еще момент. Если вдруг у вас миграции блокируют базу, то тут надо менять что-то в базе или в миграциях. В миграциях можно попробовать такие инструменты как pt-online-schema-change, но лучше подумать о том, как бы уменьшить базу.
Ну и есть еще схема с Blue Green Deployment, с остановкой слейва и накатом миграции только на нем, с SQL based репликацией. Но вживую я не видел.