
Из того, что поменялось — теперь я могу не просто написать статью, а сделать это в блоге компании. И, надеюсь, не один раз. Самопиар окончен, теперь к делу.

Мое хранилище основано на методологии Anchor Modeling. В 2013 такой выбор методологии был, во многом, прыжком веры (leap of faith). Сейчас, по прошествии почти 4 лет, можно сказать, что прыжок удался. В первой статье было приведено довольно много аргументов за Anchor Modeling. Сейчас эти аргументы остались верны, но отошли на второй план.
На сегодняшний день главный аргумент за использование Anchor Modeling+Vertica один: возможен почти безграничный рост. Рост в объемах, скорости поступления и в разнообразии — все то, что принято называть 3V (Volume, Velocity, Variety), и что характеризует большие данные.
Представьте, что ваше хранилище — это маленькая грибница. Она начинается с одной споры, а потом начинает разрастаться, покрывая метр за метром, оплетает деревья, пока не получится многотонный монстр… рост которого не останавливается… никак не останавливается.
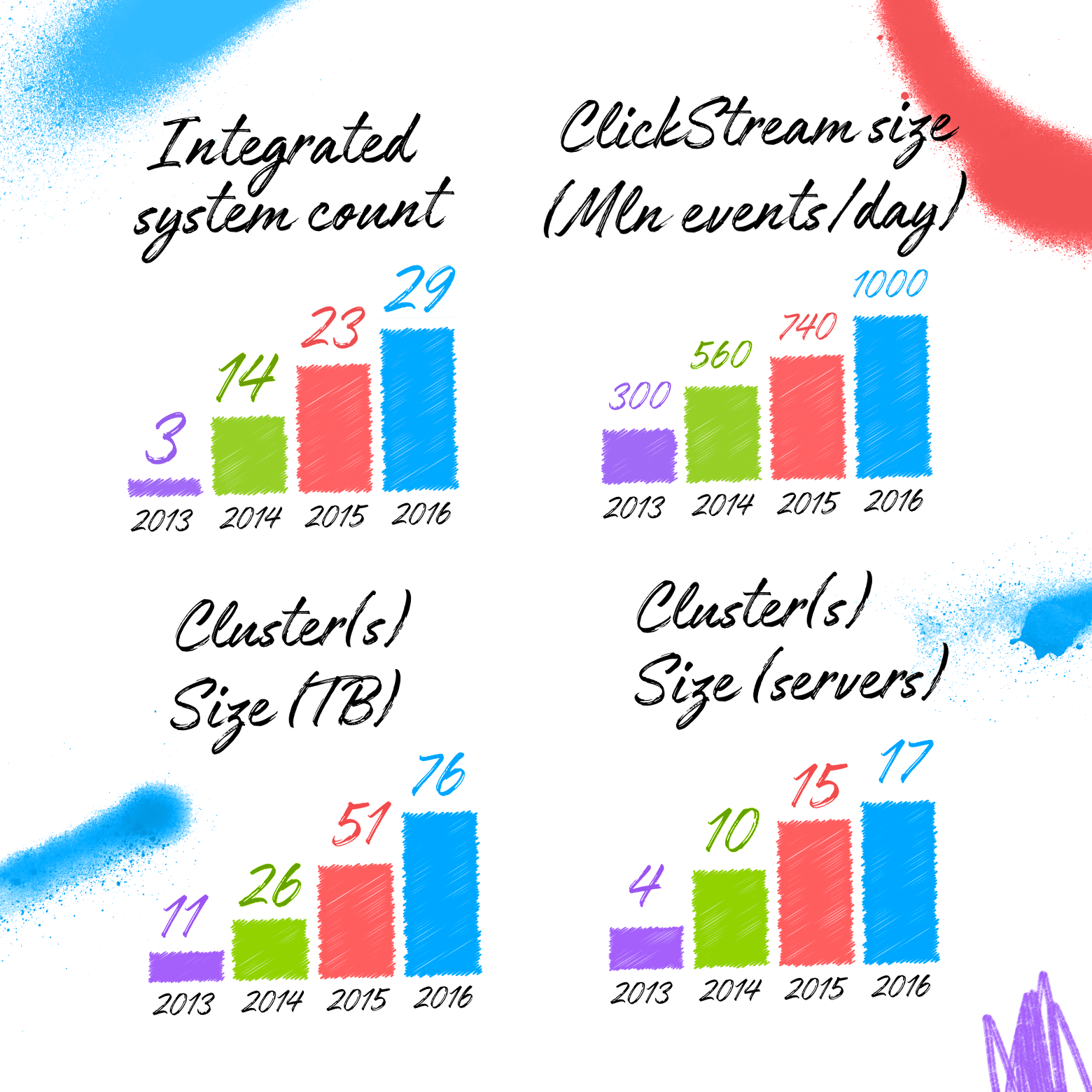
Представьте себя на месте архитектора хранилища. Хорошо, когда вы можете на старте оценить примерные объемы данных, интегрируемые системы, алгоритмы анализа данных. Тогда вы можете подобрать модель данных и платформу обработки под свою ситуацию. И не факт, что в таком случае выбор Vertica+Anchor Modeling будет оптимальным.
Сущность первая — Anchor

Anchor — это существительное, объект реального мира. Товар, пользователь, платеж. Соответственно, каждому существительному — своя таблица. Anchor таблица должна хранить ТОЛЬКО суррогатный ключ (в Vertica лучший ключ - int) и несколько технических полей. Концептуально Anchor нужен только для одной задачи — грузить каждый уникальный товар/пользователя/платеж только один раз. Избежать повторной загрузки, и помнить, в какой момент и из какой системы пришла исходная запись. Все.
Чтобы понять, как решается задача идентификации товара/пользователя/платежа — переходим ко второй сущности.
Сущность вторая — Attribute

Attribute — это таблица для хранения свойства, атрибута объекта. Названия товара, логина и даты рождения пользователя, суммы платежа. Одно свойство у объекта — одна Attribute-таблица. Десять свойств у объекта (имя, фамилия, дата рождения, пол, адрес регистрации, ...) — десять Attribute-таблиц. Все просто. Тяжело для психики, ведь количество таблиц по началу очень пугает, но просто.
Каждая Attribute-таблица содержит суррогатный ключ объекта, которым являетсяссылка на соответствующий Anchor, поле для значения атрибута, и, опционально, дату для историчности и технические поля. Соответственно, Attribute-таблица для имени (Name) покупателя (Customer) должна называться S_Customer_Name и содержать поля Customer_id (суррогатный ключ), Name (значение атрибута) и Actual_date (дата для SC2 историчности). Как видите, название таблицы и названия всех ее полей предельно однозначно определяются ее содержимым (имя покупателя).
Какой нюанс добавляет Vertica?… Все просто, все Attribute-таблицы для одного Anchor-а должны быть идентично сегментированы: сегментированы по хешу суррогатного ключа, отсортированы по суррогатному ключу и по дате историчности. Простое правило, соблюдая которое, вы получите гарантию, что все join между Attribute-таблицами одного Anchor-а будут MERGE JOIN — самым эффективным join в Vertica. Аналогично, указанная сегментация гарантирует оптимальность оконных функций, необходимых для обслуживания ETL операций с SC2 историчностью на одной дате.
В предыдущем разделе было анонсировано описание подхода к идентификации объектов: приходит строка данных про пользователя — как понять, этот пользователь уже есть в Anchor, или он новый? Естественно, ответ на этот вопрос ищется в атрибутах. Главное достоинство Anchor Modeling — возможность использовать сначала одни атрибуты (ФИО), а потом начать использовать другие (ФИО+ИНН). Причем с учетом историчности.
Сущность третья — Tie

Tie — это таблица для хранения связей между объектами. Например, таблица для хранения факта наличия у покупателя гражданства в определенной стране. Соответственно, таблица должна содержать суррогатный ключ левого объекта (customer_id), правого объекта (country_id) и, по необходимости, даты историчности и технических полей.
С точки зрения Vertica добавляется следующий нюанс — Tie таблица должна быть создана с двумя проекциями — сегментированной по левому суррогату и сегментированной по правому суррогату. Чтобы как минимум один из JOIN-ов этой таблицы был MERGE JOIN.
Важный нюанс с точки зрения моделирований — Anchor Modeling сильно отличается от Data Vault тем, что в Data Vault можно вешать данные (сателлиты) на связь (link), а в Anchor Modeling данные (Attribute) можно повесить только на Anchor, на Tie нельзя (важно — НЕЛЬЗЯ). Это на первый взгляд избыточное ограничение позволяет более точно моделировать реальный физический мир. Например, традиционная связь со свойствами в Data Vault — это факт продажи товара клиенту, свойством которого является сумма продажи. Anchor Modeling заставляет немного подумать и понять, что факт продажи товара клиента — это не элемент реального мира, а абстракция. Элементом реального мира является чек (бумажка) с номером, датой и т.п. Соответственно, в Anchor modeling описанный пример описывается тремя Anchor — Покупатель, Чек, Товар, и двумя Tie: Покупатель-Чек и Чек-Товар.
(внимательный читатель заметит, что даже картинка-пример в начале раздела не совсем корректна. Факт гражданства фиксируется определенным документом (паспортом), и более корректно представлять указанные данные именно через Anchor с паспортом).
Итого — 4 года с Anchor Modeling
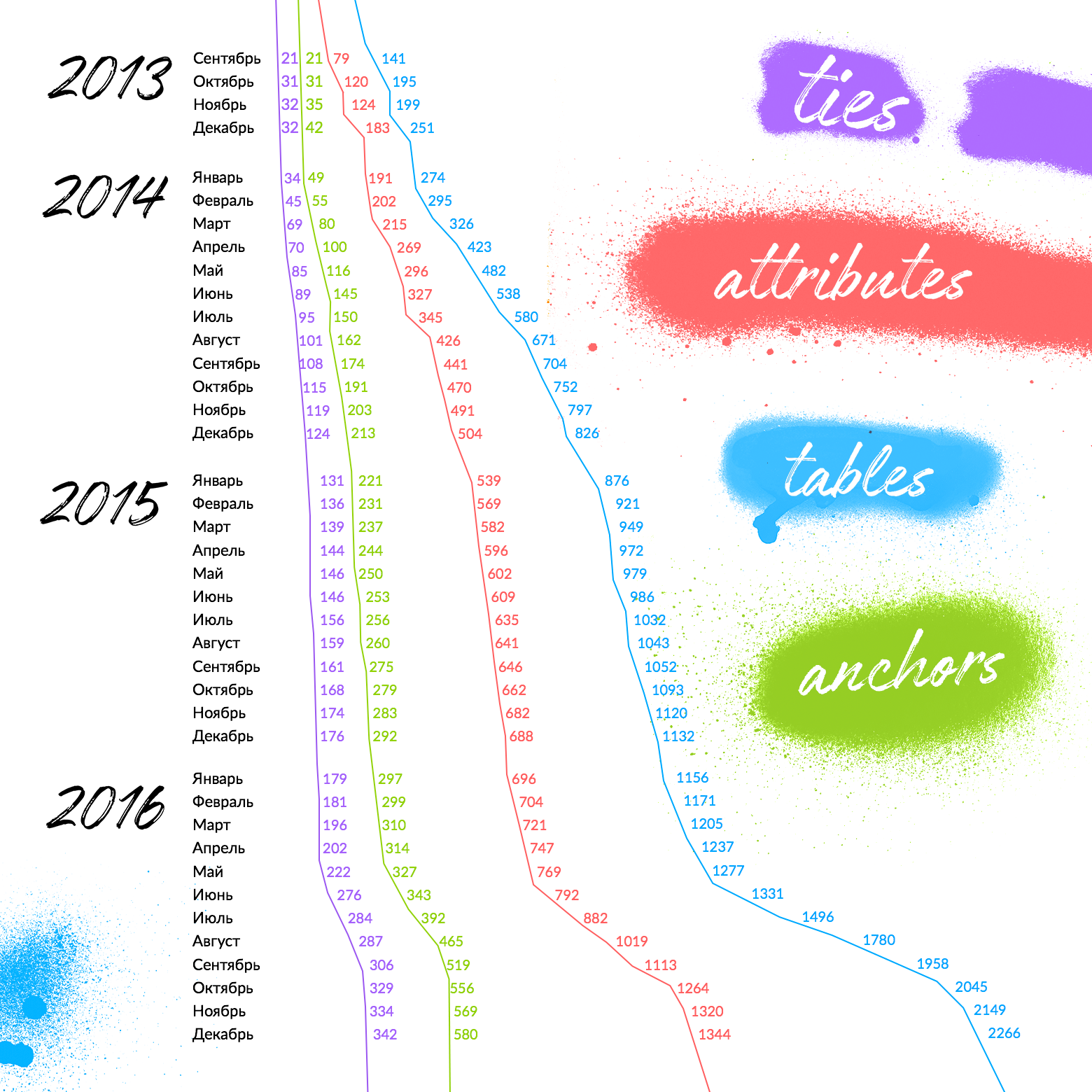
Когда первый раз читаешь про Anchor Modeling, становится страшно.
Страшно утонуть в таблицах. Страх справедлив, важно не дать ему себя остановить. Приведенная выше иллюстрация демонстрирует темпы роста количества таблица каждого типа в Avito на протяжении 4 лет (правый график — суммарное количество Anchor+Attribute+Tie).
Напомню вам первый график в статье — хранилище Avito в конце 2016 включало данные из более чем 29 исходных систем. Как видите, таблиц много. Но не устрашающе много. Можно сказать, что большой скачок количества таблиц происходит в начале, а потом, за счет нарастающего повторного использования старых таблиц, темпы роста снижаются. Резкий скачок количества таблиц в конце 2016 года объясняется подключением необычно большого количества новых систем и демонстрирует, что несмотря на размер системы, она по-прежнему способна расширяться.
Вторая причина опасаться большого количества таблиц — сложности анализа со стороны внешних аналитиков.
О способе борьбы с подобным опасением я расскажу в следующей статье. Надеюсь, в этот раз ее не придется ждать еще три года :) А пока можно изучить записи моих выступлений по теме на семинарах, конференциях и вебинарах.
Комментарии (21)

Workanator
03.03.2017 15:40Спасибо за интересную статью. Никогда не думал о том, чтобы разбивать сущности настолько мелко, хоть и стараюсь провести полную нормализацию БД. Но по опыту могу сказать, что во всех проектах боязнь получить большое количество таблиц «душит» только вначале, а потом, когда уже все нормализовано, становится очень даже удобно и просто.
У меня к вам вопрос, влияет ли на скорость выполнение запроса (по сравнению с «обычной» БД) такое количество таблиц, например, когда надо за раз выбрать ФИО + ИНН + еще какие-то персональные данные?
azathot
03.03.2017 15:45+1Конечно, извлечение из единой денормализованной таблицы работает быстрее. Но не принципиально быстрее. Описанная стратегия сегментации гарантирует очень высокую эффективность join-а атрибутов отдой сущностив рамках нашей кластерной MPP базы.
В нашей практике мы делаем денормализованные витрины, где храним, например актуальные ФИО+ИНН+перс. данные людей. Но только актуальные. Кому нужна историчность, ретроспектива, люди работают уже с полностью историчными нормализованными таблицам атрибутов.Ares_ekb
03.03.2017 20:43Я не делал такие замеры. Но, скажем, есть денормализованная таблица с 50 столбцами. Если из них запрашивается только часть, скажем, 5 столбцов, то наверное join'ы будут быстрее?
azathot
04.03.2017 07:31Это же колоночная база (!).
Даже при запросе 5 из 50 денормализованных простой селект будет быстрее.
Нормализация нужна для хранения. Если у вас с начала времен и до тепловой смерти вселенной будет 50 столбцов — одна денормализованная таблица выгоднее. Веселье начинается, когда у вас, например, у объявления сначала появляется метро, потом оно становится историчным, а потом разрешают вводить несколько метро (много-ко-многим). И такое за год-другой может произойти с дюжинами полей. В 2013 у нас у событий веб-лога было 30 атрибутов. Сейчас 90…Ares_ekb
04.03.2017 07:58Точно, колоночная, тупанул :) Просто это один из мифов, что нормализация приводит к какой-то дикой просадке производительности. Даже эта ветка началась с воспроса о производительности. Если данные хранятся по строкам, то, скорее наоборот, возможен рост производительности.
А, кстати, зачем денормализовывать? Чтобы была проще реализация клиентской части?azathot
08.03.2017 14:37Бизнес пользователи боятся кучи таблиц.
Опять же, в денормализванной таблице проще навернуть бизнес-логику.
Например, платежи можно представить тремя разными образами из одних и тех же сырых данных (сырые платежи, завершенные платежи, отраженные в фин-отчетности). Проще сделать три денормализованных таблицы платежей для разных подразделений. Меньше риск запутаться.

yusman
03.03.2017 18:01Спасибо за статью, есть несколько вопросов:
1. Не совсем понятно, по какому механизму генерируются суррогатные ключи, и где хранятся натуральные?
2. Как и какими средствами документируете все это?
3. С каким проблемами приходится сталкиваться?azathot
03.03.2017 18:111. Суррогат — автоинкремент. Identity в Vertica. Натуральные — либо в атрибутах, либо в особом поле в анкоре. Тут уже нюансы реализации.
2. Google Sheet + автогенерация документации для Confluence.
3… Постараюсь рассказать в следующих статьях :)
Ares_ekb
03.03.2017 18:31Возможно, будет интересно. Я делал редактор Anchor моделей с помощью Eclipse Sirius:
Разработка метамодели с помощью Eclipse Modeling Framework (и немного про моделирование данных)
Разработка визуального языка моделирования с помощью Sirius
Цикл статей планировал закончить генератором SQL, но пока пришлось отложить.azathot
03.03.2017 18:55Да, мы с Ларсом видели, сразу был неожиданный скачок посетителей из РФ :)
Ares_ekb
03.03.2017 19:12У нас, кстати, в одном проекте используется похожий подход. Немного похвастаюсь :) В модели порядка 1000 сущностей, 2200 повторно используемых атрибутов (в Anchor, на сколько я понимаю, их нельзя повторно использовать, хотя, имхо, в этом и соль сильной нормализации… с другой стороны, это можно понять), 1200 связей и 700 типов данных.
mkrupenin
06.03.2017 00:01«Когда первый раз читаешь про Anchor Modeling, становится страшно.»
Это точно :). Очень смелое решение, учитывая масштаб проекта. Смотрел видео вашего доклада на конференции HPE и судя по вопросам, присутствующие там дядьки были весьма удивлены :). Респект!
Пару вопросов:
1) Витрины для Tableau у вас по Кимбаллу или другой подход? И сколько в них примерно таблиц и Тб?
2) Учитывая поддержку историчности для атрибутов, как аналитики пишут запросы, когда нужно получить срез на заданную дату (в срезе, например, несколько десятков полей). В Data Vault для этого можно использовать PIT таблицы. Интересно посмотреть на такой SQL запрос.azathot
08.03.2017 15:16+1Спасибо :)
1. Либо по Кимбалу, либо еще более денормализованные, в единую таблицу. Tableau предпочитает минимум таблиц :) Таблиц — 160, примерно 15Тб. Про это будет следующая статья, с графиками.
2… Видимо, тоже следующая статья :)… Без PIT таблиц. Несколько подходов, все на основе оконных функций, либо через WITH, либо через join подзапросов. Выглядит немного тяжеловесно (в случае десятков таблиц), но очень единообразно, поэтому в реальности такой код обычно пишут формулы Excel. Размер кода, боюсь, будет слегка великоват для комента, поэтому — в следующей большой публикации :)
Ivan22
Так в чем плюс-то от того, что факты заменяются на лишние anchors ???
azathot
Становятся реальными не только slow changing dimensions, но и slow changing facts. Историчность становится очень простой, доступной для включения в любой точке — как в измерениях, так и в фактах.
Ivan22
все равно не понятно. почему факт с ценой не позволяет историчность делать, а чек с ценой позволяет??
azathot
Факт (линк) с ценой в атрибуте: постарайтесь смоделировать ситуацию, когда у вас у факта меняется цена И ссылка на измерение. Например, для продажи — неправильный товар и неправильная цена.
Подскажу: проблема в том, что факт идентифицируется ссылками на измерение.
Т.е. честная полная историчность приводит к изменению идентификатора.
Проблему можно решить, но тут огромный риск ошибиться.
А у чека номер есть :)
skullodrom
Тогда получается можно создать промежуточную структуру между стандартной и анкор — для всех атрибутов для которых нужна историчность создаются отдельные таблица (или даже одна таблица), а атрибуты для которых не нужна историчность хранятся в одной таблицы и имеют один суррогатный ключ. Рассматривали такой подход?
azathot
Этот подход называется DataVault, ему уже 20 лет.