

Но для начала нужно понять главное: зачем мы вообще взялись за офлайн-поиск, если сайты из результатов поиска все равно недоступны при отсутствии сети?
EDGE-поиск
На радарах Яндекса традиционно видны люди, которые вводят запрос, но затем покидают страницу, не дождавшись загрузки из-за плохого мобильного интернета. В этой ситуации мы не могли повлиять на общее качество сети и скорость загрузки всех сайтов, но сделать менее болезненным хотя бы процесс поиска и сэкономить этим немного времени стоило попытаться. Собственно, поэтому этот проект изначально и назывался EDGE-поиском, т.е. поиском при медленном интернете.
Ускорить поиск можно двумя способами. Во-первых, максимально оптимизировать веб-версию и те API, которые использует приложение. И эта работа тоже ведется, но даже этого недостаточно. Во-вторых, можно заранее загрузить на устройство то, что пригодится при плохом соединении. Очевидно, что уместить весь индекс интернета в телефоне физически невозможно. Поэтому нужно было зайти со стороны локального хранения уже готовых результатов поиска по конкретным запросам. По каким? Предсказывать будущие запросы человека с высокой точностью пока никто не умеет (но мы учимся). Поэтому берем популярные повторяющиеся запросы.
Когда мы говорим про популярные запросы, то многие представляют себе запрос [вконтакте] и несколько подобных. На самом деле у нас сотни тысяч менее очевидных запросов, которые регулярно повторяются в больших количествах. А это уже многие сотни мегабайт результатов. Причем сохранять мы планировали не только результаты поиска, но и подсказки, которые появляются в процессе ввода запроса. И здесь многие спросят: зачем хранить в офлайне подсказки, ведь человек вполне способен ввести запрос и без них?
При вводе запросов в приложении Яндекс пользователи видят не обычные поисковые подсказки, а в виде отдельных слов/пар слов (т.е. предиктивный ввод текста). Обычные подсказки нельзя отредактировать: если нужно дописать слово, то придется вводить весь запрос самостоятельно. Подсказки в виде слов позволяют вносить правки, покрывают куда бОльшее число запросов и значительно ускоряют их ввод человеком.
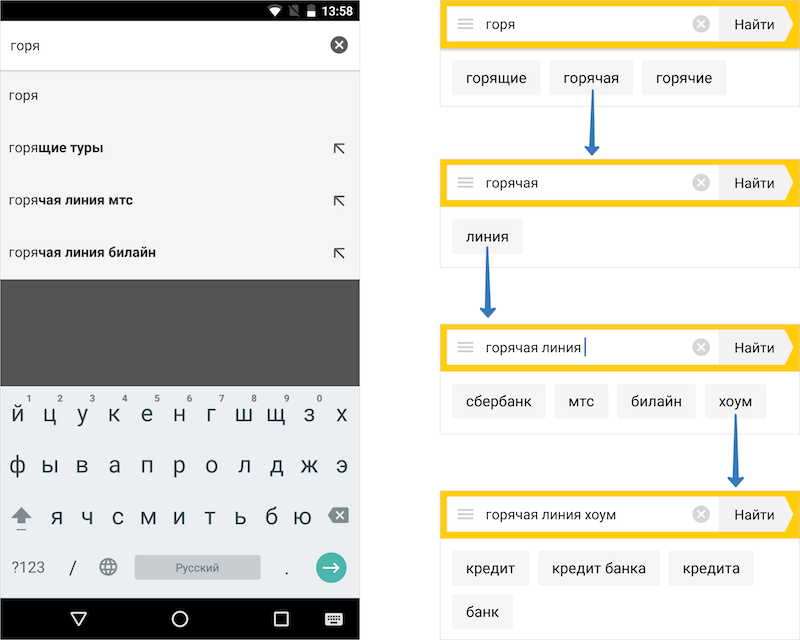
Но главное в том, что подсказки оказались особенно полезны при работе в офлайн-режиме. Эти подсказки помогают людям сформулировать свой вопрос так, как это делает большинство, а это, в свою очередь, увеличивает шанс того, что ответ будет получен из локального кэша. Именно поэтому важно было сохранить и подсказки.
Эмпирически мы подобрали определенный минимум поисковых запросов (порядка 150 тыс.) и подсказок, меньше которого хранить смысла уже не оставалось. Но объем всего этого багажа по-прежнему выходил за рамки приличного (несколько сотен мегабайт). Даже с учетом того, что для каждого запроса хранились лишь топ-10 результатов. Нужно было что-то делать.
От оптимизации к офлайну
Начали искать все то, что можно было отправить «под нож». Каждый результат содержал в себе не только ссылки на сайты, но и фавиконки и сниппеты. Фавиконки – это картинки, а значит, здесь можно было добиться серьезной экономии. Один и тот же сайт может встречаться в результатах для совершенно разных запросов, поэтому мы изначально не дублировали фавиконки, а хранили их по сайтам. А дальше мы сделали так, что вероятность сохранения фавиконки прямо пропорциональна частоте появления сайта в результатах поиска. Иными словами, мы отказались от большинства фавиконок, но визуально это не сильно бросается в глаза.
А вот от сниппетов отказаться уже не так просто, потому что это не менее важная для людей информация, чем заголовок. Именно в сниппете зачастую уже содержится ответ на вопрос. Поэтому для обычных запросов мы отбросили сниппеты лишь у двух последних результатов. Для навигационных, где первые результаты обычно уже хорошо отвечают на запросы, мы сократили не только количество сниппетов до первых 3-4, но и сами результаты до 5 сайтов вместо 10. Аналогично сократили все выдачи, где есть ответ колдунщика.
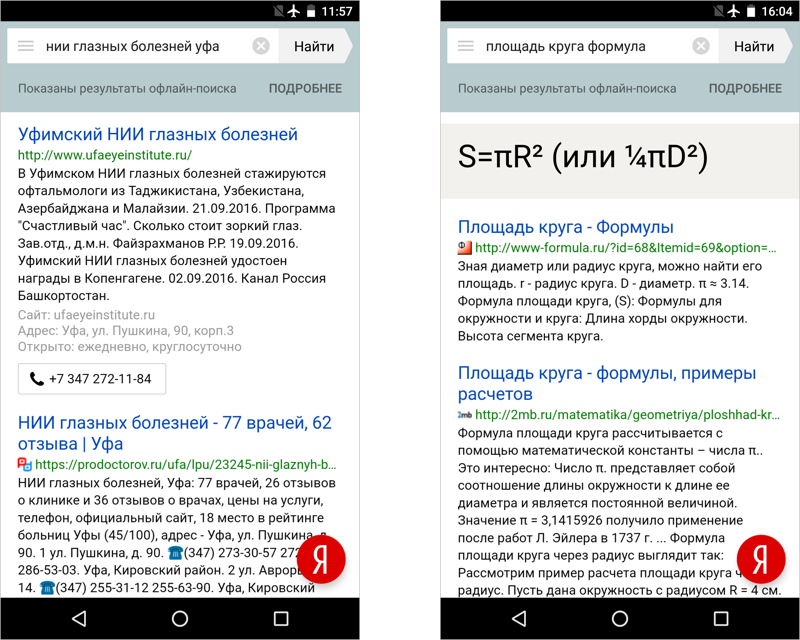
Чем больше мы сокращали обычные результаты поиска в пользу уже готовых ответов, тем ближе подходили к пониманию, что наш EDGE-поиск уже не просто ускоряет работу, а способен отвечать на широкий круг вопросов вообще без соединения с интернетом. Сами того не замечая, мы уже работали над офлайн-поиском. А значит, ставку надо делать на готовые ответы. Осознав это, мы приступили к обогащению базы важными фактами, которые до этого не могли попасть туда из-за ограничения популярности запроса. Эти результаты содержат только ответы, без выдачи сайтов.
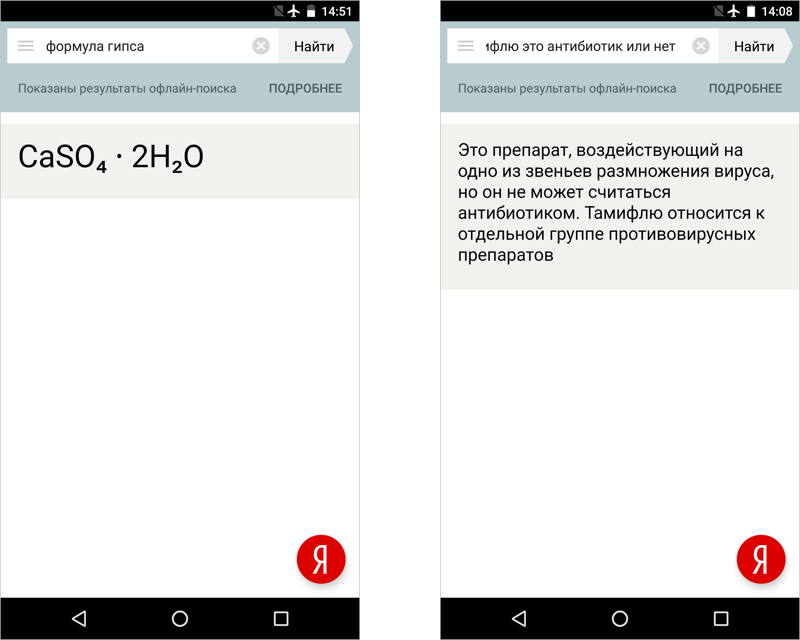
По похожей схеме мы скопировали в базу все карточки объектного ответа и все запросы, для которых объектный ответ доступен. Карточки при офлайн-поиске отличаются от оригиналов почти полным отсутствием картинок: мы убрали их из соображений экономии.
Рост базы фактов требовал дальнейшей работы над оптимизацией и такой структуры хранения данных, которая бы бережно относилась к ресурсам устройства.
Словари
База скачивается на устройство не целиком, а в виде отдельных словарей, причем только при Wi-Fi-соединении и только при достаточном уровне заряда. Разбивка на словари сделана по двум причинам. Во-первых, если при загрузке соединение рвётся, то во время следующей попытки будут скачиваться только те словари, которые не успели скачаться раньше. Во-вторых, для дополнительной экономии места база загружается и хранится на устройстве в сжатом виде, но при каждом запросе распаковывается не целиком, а только нужными частями.
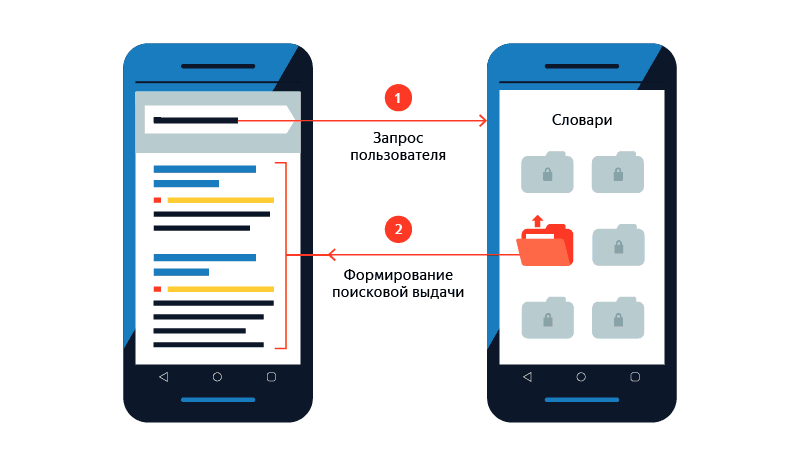
Каждый словарь содержит запросы, начинающиеся на определенные буквы, а также все данные для выдач и подсказок по этим запросам. Отсортировать данные перед разбивкой на словари именно по первым буквам запросов оказалось логичнее, чем, например, по их популярности. Представьте ситуацию: в первом словаре лежат самые популярные запросы, во втором — чуть менее популярные и так далее. Но популярность запросов часто меняется, а это приведет к необходимости регулярно обновлять словари только ради того, чтобы переместить запрос из одного в другой. Это затраты трафика, энергии и времени. Поэтому было важно сделать так, чтобы при актуализации базы запросы не перемещались между словарями. Алфавитный порядок оказался простым и эффективным решением.
Ответы на одни и те же запросы могут различаться в разных частях страны, поэтому для разных регионов формируются свои словари. Причем при кратковременных визитах в другой регион приложение не будет спешить с обновлением словарей – мы предусмотрели сценарии командировок и туризма.
Как бы мы ни старались, офлайн-поиск покрывает не все возможные запросы, но уже сейчас выручает в среднем при каждом третьем. Как и для любого среднего результата, это значит, что одна часть пользователей сталкивается с офлайн-ответами куда чаще, чем другая. Поэтому мы, конечно же, позволяем полностью отключить офлайн-поиск в настройках.
Нашей команде было бы интересно узнать мнение читателей Хабра об этом направлении и получить отзывы о работе беты приложения Яндекс для Android. Спасибо.
Комментарии (31)

vlad230596
09.03.2017 13:14+1Интересно, какой в итоге получился размер оффлайн базы после оптимизации хранимой информации?

BarakAdama
09.03.2017 13:38+3Сильно зависит от региона и конкретного периода. В среднем в районе 150МБ. Для сравнения: кэш браузеров для Android занимает около 300МБ.
The535
09.03.2017 13:20+2Идея очень хорошая. И наверное на территории России выручает в некоторые моменты, но в Азербайджане это неактуально. Гугл лучше индексирует наши сайты. Банальный пример, не мог никак в яндексе найти банк республика, даже думал, что закрылся, потом нагуглил таки.
И еще, часто пользователи не доходят даде до 5-ой ссылки (не считая ппрограммистов:) ), поэтому имело бы смысл анализировать по скольким ссылкам проходит пользователь и выбирать только их в количестве 5 штук. Это бы сэкономило память, которую можно использовать под еще больше запросов. Еще можно убрать из оффлайна запросы с поиском интернет магазинов, ибо зачем человеку без интернета нужен таковой. В принципе идея очень хорошая, даже хотел бы сам над чем-то таким поработать. Спасибо за статью.VaalKIA
10.03.2017 05:46+1Еще можно убрать из оффлайна запросы с поиском интернет магазинов, ибо зачем человеку без интернета нужен таковой
Что бы позвонить и узнать где этот чёртов пунк выдачи, не?

nezdhanov
09.03.2017 13:21На мой субъективный взгляд слегка нелогично получается… Поисковик априори должен обладать актуальной информацией, а ситуация, когда на телефоне только 4g и wifi был включен только в момент покупки смартфона для регистрации учетки, например, может быть реальней реального. Получается, база может и не обновиться никогда?
Или я статью снизу-вверх читал...

Loriowar
09.03.2017 13:47А будет ли доступна такая штука без приложения яндекс? То есть, чтобы со стороны пользователя нужно было поставить чудесное приложение и любой любимый браузер начинал местами работать без интернета? Я конечно не знаю на сколько правильно в мобильных платформах перехватывать часть трафика, чтобы заэмулировать ответ сервера, либо на сколько глючным и медленным будет браузерное расширение таких размеров, но принципиальных проблем для такого решения придумать не могу.
Второй вопрос: писали, что исходная база была порядков сотен МБ. То есть не космические размеры для современных железок. Можно ли будет выбирать размер, который могут занять словари? Я бы скачал минимум на железяку с 3-4 андроидом так как там места кот наплакал и сказал бы большое спасибо тем, кто уместил поиск в десятки метров, но и рад бы был скачать базу побольше в планшет (или новый телефон), так как места много и не жалко хоть пару гигов выделить для такого.
Ну и финальный вопрос: а в будущем будет расширение базы и её разделение под конкретные аудитории? Пример: хочу продолжать писать на любимом ruby/erlang/etc в самолёте, который 8 часов летит в Тай. Загружаю основную выдачу по руби и 40-80% ответов у меня уже есть. Можно не лезть в документацию, а юзать поисковик и радоваться жизни. Тут же будет интересно посмотреть на размеры таких тематических баз и получить первое оценочное представление о количестве "знаний", содержащихся в конкретной области.

WarFollowsMe
09.03.2017 20:23+1Можно сделать тематический (с выбором по тегам) дамп stackoverflow и прикрутить к нему офлайн поисковик. Я б такой штукой пользовался часто.
a5b
10.03.2017 06:09+1С начала 2014 года полный дамп всей сети stackexchange загружается в интернет-архив https://archive.org/details/stackexchange, есть torrent (история: пост https://stackoverflow.blog/2009/06/04/stack-overflow-creative-commons-data-dump/, о переезде — https://stackoverflow.blog/tags/cc-wiki-dump/).
Список файлов — https://archive.org/download/stackexchange, на 15-Dec-2016 посты из stackoverflow занимают 9.6 ГБ в 7z (stackoverflow.com-Posts.7z). Архивы superuser, serverfault, askubuntu имеют размер по 600-500 МБ. Дамп обновляется 4 раза в год: https://meta.stackexchange.com/a/290254.
Для просмотра делали "StackDump" — http://stackapps.com/questions/3610/stackdump-an-offline-browser-for-stackexchange-sites — https://bitbucket.org/samuel.lai/stackdump/overview (JRE 6 solr + Python 2.5 web server).
Еще есть http://data.stackexchange.com/ с онлайн-доступом к свежему дампу.
xmax
09.03.2017 14:19Вот про туризм и командировки — надо отдельный режим. Если человек искал «гостиница в Х», то есть вероятность, что он туда поедет. Будет ли у него там интернет — вопрос открытый. А чаще — не будет, либо дорого. Не у всех отсутствует роуминг по стране.
eXoToL
09.03.2017 23:47Вообще, очень странно, Яндекс так активно нападает на Гугл из-за андроида, но потом размещает свое приложение только в Google Play, а на «яндесовской» альтернативе этого приложения что-то не видно… При этом андроид от яндекса ну никак не хочет без сторонней прошивки, я бы даже сказал канонической, работать с гугл плей. И что получается — яндекс пытается развивать свои сервисы, а новинки не спешит туда выкладывать… Обидно даже

TimsTims
10.03.2017 00:28тем ближе подходили к пониманию, что наш EDGE-поиск уже не просто ускоряет работу, а способен отвечать на широкий круг вопросов вообще без соединения с интернетом
Главное, чтобы этого не поняли ваши новые «эффективные менеджеры». А то они поймут, что весь яндекс умещается в 1 смартфоне и посокращают «лишний» штат…
Devastor
10.03.2017 07:39-12gis — вмещает всю необходимую инфу по твоему городу менее чем в 100 МБ

DarkVedmakl
14.03.2017 13:01А оффлайн википедия не влезает на DVD, но, как я понял, много информации из вики есть в оффлайн словарях яндекса. Очень полезно.

beremour
13.03.2017 08:15+2А вы можете идею того, что интернет не всегда есть, объяснить команде «навигатора»?
Rieha
14.03.2017 14:08«Команде» навигатора надо многое объяснить. Очень бы хотелось их всех вывести на ковер (хотя бы в он-лайне) перед требовательными пользователями, вразумить и наставить на пусть истинный. Но это уже совсем другая история.
Я очень рад, что гугл взялся за свою навигацию и делает серьезные и правильные шаги — только после этого яндекс начал хоть что-то делать в навигаторе.

peacemakerv
14.03.2017 14:22+1Мне уже давно не хватало такого типа поиска, когда на многие вопросы можно выдать недлинное текстовое описание, без простыни ссылок (и вообще лучше бы автоматический итерационный поиск — вторичный поиск ключевых слов, взятых из результатов первичного поиска).
А так же плюсую за настройки:
1) доступного объема хранимого кэша
2) и выбора тематики кэша: разработать классификацию из 20-40 вариантов максимум, выбор которых может отсечь совершенно ненужные в данный момент времени отрасли знаний (к примеру, биология, развлечения, игры, реклама :))
Т.е. чтобы был такой карманный поисковик только тех областей знаний, который нужен сейчас, в текущей работе, или в текущей поездке. Вплоть до кэширования только одной области знаний.

devbutch
15.03.2017 14:50Недавно читал статью по поисковику DuckDuckGo.
У этого ест такое понятие как Instant Answers — оно прямо соответствует вашему понятию «важные факты», которые вы отображаете (как я понял) без привязки к сайту, а просто вычленяя инфу на основе надёжного источника. Помимо этого, Instant Answers поддерживает специфичные запросы — например «linux cheat sheet», или " debian version vim". Мне кажется это отличное подполье для вас — ведь по факту, вы владеете информацией о пользователе (в большистве случаев), который пользуется вашим сервисом. Можно проанализировать подобные запросы (определить род его деятельность) и закинуть ответы на них в локальную базу. Например, если я имея акк-т на Яндексе постоянно ищу vim hotkeys, почему бы мне не иметь подобную табличку в локальном кэше? Тоже самое с другими областями — астрлогия (карты звёзд например), математика (таблицы, формулы итд). Что именно хранить, будет зависеть от конкретного пользователя.
SamUoker
"… если нужно дописать слово, то придется вводиться весь запрос самостоятельно. " у Вас ошибка.
BarakAdama
Спасибо.
SamUoker
За подсказку об ошибках у нас теперь в минус уйти можно? Интересно o????? • ?? • ??o???
vvzvlad
Можно, так традиционно это делается в личке
SamUoker
Каюсь, не знал и не любопытствовал о таком функционале. Спасибо.