
Яндекс работает над технологией машинного перевода с 2011 года, и сегодня я расскажу о нашем новом подходе, благодаря которому становится возможным создать переводчик для тех языков, для которых ранее это было сделать затруднительно.

Правила против статистики
Машинный перевод, то есть автоматический перевод с одного человеческого языка на другой, зародился в середине прошлого века. Точкой отсчета принято считать Джорджтаунский эксперимент, проведенный 7 января 1954 года, в рамках которого более 60 фраз на русском языке были переведены компьютером на английский. По сути, это был вовсе и не эксперимент, а хорошо спланированная демонстрация: словарь включал не более 250 записей и работал с учетом лишь 6 правил. Тем не менее результаты впечатлили публику и подстегнули развитие машинного перевода.
В основе таких систем лежали словари и правила, которые и определяли качество перевода. Профессиональные лингвисты годами работали над тем, чтобы вывести всё более подробные и всеохватывающие ручные правила (по сути, регулярные выражения). Работа эта была столь трудоемкой, что серьезное внимание уделялось лишь наиболее популярным парам языков, но даже в рамках них машины справлялись плохо. Живой язык – очень сложная система, которая плохо подчиняется правилам, постоянно развивается и практически каждый день обогащается новыми словами или конструкциями. Ещё сложнее описать правилами соответствия двух языков. Одни и те же слова могут иметь совершенно разные переводы в зависимости от контекста. Да и целые фразы могут иметь свой устойчивый перевод, которому лучше соответствовать. Например, "Нельзя так просто войти в Мордор".
Единственный способ машине постоянно адаптироваться к изменяющимся условиям и учитывать контекст – это учиться на большом количестве актуальных текстов и самостоятельно выявлять закономерности и правила. В этом и заключается статистический подход к машинному переводу. Идеи эти известны с середины 20 века, но особого распространения они не получили: машинный перевод, основанный на правилах, работал лучше в условиях отсутствия больших вычислительных мощностей и обучающих баз.
Грубая сила компьютеров – это не наука
Новая волна развития статистического подхода началась в 80-90-х годах прошлого века. Компания IBM Research получила доступ к большому количеству документов канадского парламента и использовала их для работы над системой проверки правописания. И для этого они применили достаточно интересный подход, известный под названием noisy channel model. Смысл его в том, что текст А рассматривается как текст Б, но с ошибками. И задача машины – устранить их. Обучалась модель на тысячах уже набранных документах. Подробнее о noisy channel можно почитать в других постах на Хабре, здесь же важно сказать, что этот подход хорошо показал себя для проверки правописания, и группа сотрудников IBM решила попробовать его и для перевода. В Канаде два официальных языка (английский и французский), поэтому с помощью переводчика они надеялись
Результаты их работы были опубликованы, но впечатлили они не всех. Организаторы конференции по компьютерной лингвистике COLING написали разгромный отзыв:

Результат оказался хуже, чем у лучших на тот момент систем, основанных на правилах, но сам подход, предполагавший сокращение ручного труда, заинтересовал исследователей со всего мира. И главная проблема, которая стояла перед ними, заключалась в отсутствии достаточного количества примеров переводов для обучения машины. В ход шли любые материалы, которые удавалось найти: базы международных документов ООН, документации, справочники, Библия и Коран (которые переведены практически на все языки мира). Но для качественной работы нужно было больше.
Поиск
В интернете каждый день появляются сотни тысяч новых страниц, многие из которых переводятся на другие языки. Этот ресурс можно использовать для обучения машины, но добыть его сложно. Таким опытом обладают организации, которые индексируют интернет и собирают данные о миллиардах веб-страниц. Среди них, например, поисковые системы.
Яндекс вот уже пять лет работает над собственной системой машинного перевода, которая обучается на данных из интернета. Ее результаты используются в Переводчике, Поиске, Браузере, Почте, Дзене и во многих других сервисах. Обучается она следующим образом. Изначально система находит параллельные тексты по адресам документов — чаще всего такие адреса различаются только параметрами, например, «en» для английской версии и «ru» для русской. Для каждого изученного текста система строит список уникальных признаков. Это могут быть редко используемые слова, числа, специальные знаки, находящиеся в тексте в определённой последовательности. Когда система набирает достаточное количество текстов с признаками, она начинает искать параллельные тексты ещё и с их помощью — сравнивая признаки новых текстов и уже изученных.
Чтобы переводчик соответствовал современным стандартам качества, система должна изучить миллионы фраз на обоих языках. Поисковые технологии могут найти их, но только для наиболее популярных направлений перевода. Для всех остальных можно пытаться по старинке обучаться только на Википедии или Библии, но качество перевода откатывается на десятилетия назад. Можно подключить краудсорсинг (Яндекс.Толока или Amazon Mechanical Turk) и усилиями большого количества людей из разных стран собрать примеры переводов. Но это долго, дорого и не всегда эффективно. Хотя мы и стараемся использовать краудсорсинг там, где это возможно, нам удалось найти альтернативное решение.
Язык как совокупность моделей
В основе статистического перевода долгое время лежали исключительно лексические модели, т.е. такие модели, который не учитывают родственные связи между различными словами и другие лингвистические характеристики. Проще говоря, слова «мама» и «маме» – это два совершенно разных слова с точки зрения модели, и качество перевода определялось только наличием подходящего примера.
Несколько лет назад в индустрии появилось понимание, что качество статистического машинного перевода можно улучшить, если дополнить сугубо лексическую модель еще и моделями морфологии (словоизменение и словообразование) и синтаксиса (построение предложений). Может показаться, что речь идет о шаге назад в сторону ручных правил лингвистов, но это не так. В отличие от систем, основанных на ручных правилах, модели морфологии и синтаксиса можно формировать автоматически на основе все той же статистики. Простой пример со словом «мама». Если скормить нейронной сети тысячи текстов, содержащих это слово в различных формах, то сеть «поймет» принципы словообразования и научится предсказывать правильную форму в зависимости от контекста.
Переход от простой модели языка к комплексной хорошо отразился на общем качестве, но для ее работы по-прежнему нужны миллионы примеров, которые трудно найти для небольших языков. Но именно здесь мы вспомнили о том, что многие языки связаны между собой. И этот факт можно использовать.
Родственные связи
Мы начали с того, что отошли от традиционного восприятия каждого языка как независимой системы и стали учитывать родственные связи между ними. На практике это означает вот что. Если у нас есть язык, для которого нужно построить перевод, но данных для этого недостаточно, то можно взять другие, более «крупные», но родственные языки. Их отдельные модели (морфология, синтаксис, лексика) можно использовать для заполнения пустот в моделях «малого» языка.
Может показаться, что речь идет о слепом копировании слов и правил между языками, но технология работает несколько умнее. Предлагаю рассмотреть ее сразу на реальном примере одного очень популярного в крайне узких кругах языка.
Папьяменто
Папьяменто – это родной язык населения Арубы, Кюрасао и Бонэйр, на котором говорят около 300 тыс. человек. В том числе один из наших коллег, который родился на Арубе. Он и предложил нам стать первыми, кто поддержит папьяменто. Про эти острова мы знали лишь по Википедии, но такое предложение упустить не могли. И вот почему.

Когда людям приходится разговаривать на языке, который ни для кого из них не является родным, появляются новые языки, которые называются пиджинами. Чаще всего пиджины возникали на островах, которые захватывали европейцы. Колонизаторы свозили туда рабочую силу с других территорий, и этим людям, не знавшим языков друг друга, приходилось как-то общаться. Единственным их общим языком был язык колонизаторов, усваиваемый обычно в очень упрощенном виде. Так возникло множество пиджинов на основе английского, французского, испанского и других языков. Потом люди передавали этот язык своим детям, и для тех он становился уже родным. Пиджины, которые стали для кого-то родными, называются креольскими языками.
Папьяменто – креольский язык, который возник, по-видимому, в XVI веке. Большая часть его лексики имеет испанское или португальское происхождение, но есть слова и из английского, голландского, итальянского, а также из местных языков. А поскольку ранее мы еще не испытывали нашу технологию на креольском языке, то ухватились за этот шанс.
Моделирование любого нового языка всегда начинается с построения его ядра. Каким бы «малым» ни был язык, у него всегда есть уникальные особенности, которые отличают его от любого другого. Иначе бы его просто нельзя было отнести к самостоятельному языку. Это могут быть свои уникальные слова или какие-то правила словообразования, которые не повторяются в родственных языках. Эти особенности и составляют то ядро, которое в любом случае нужно моделировать. И для этого вполне хватает малого количества примеров перевода. В случае с папьяменто в нашем распоряжении был перевод Библии на английский, испанский, голландский, португальский и, собственно, папьяменто. Плюс небольшое количество документов из сети с их переводом на один из европейский языков.
Начальный этап работы над папьяменто ничем не отличался от создания переводчика для любого большого языка. Загружаем в машину все доступные нам материалы и запускаем процесс. Она проходит по параллельным текстам, написанным на разных языках, и строит распределение вероятностей перевода для каждого найденного слова. Кстати, сейчас модно говорить о применении нейронных сетей в этом процессе, и мы тоже умеем это делать, но зачастую более простых инструментов вполне хватает. Например, для эльфийского языка (о нем мы поговорим чуть позже) мы изначально построили модель с применением нейронной сети, но в конечном счете запустились без нее. Потому что более простой статистический инструмент показал результат не хуже, а усилий потребовал меньше. Но мы отвлеклись.
Система, глядя на параллельные тексты, пополняет свой словарный запас и запоминает переводы. Для больших языков, где примеров миллионы, больше ничего делать и не надо – система найдет не только все возможны слова, их формы и запомнит их переводы, но и учтет разные случаи их применения в зависимости от контекста. С небольшим языком сложнее. Ядро мы смоделировали, но примеров недостаточно для полного покрытия всех слов, учета словообразования. Поэтому технология, которая лежит в основе нашего подхода, работает несколько глубже с уже имеющимися примерами и использует знания о других языках.
Например, согласно морфологии испанского языка, множественное число образуется с помощью окончаний -s/-es. Машина, встречаясь с множественным числом в испанском переводе, делает для себя вывод, что это же слово в переводе на папьяменто, скорее всего, написано во множественном числе. Благодаря этой особенности, автоматический переводчик вывел для себя правило, что слова в папьяменто с окончанием -nan обозначают множественное число, и если его перевода не найдено, то стоит отбросить окончание и попробовать найти перевод для единственного числа. Аналогично для многих других правил словоизменения.

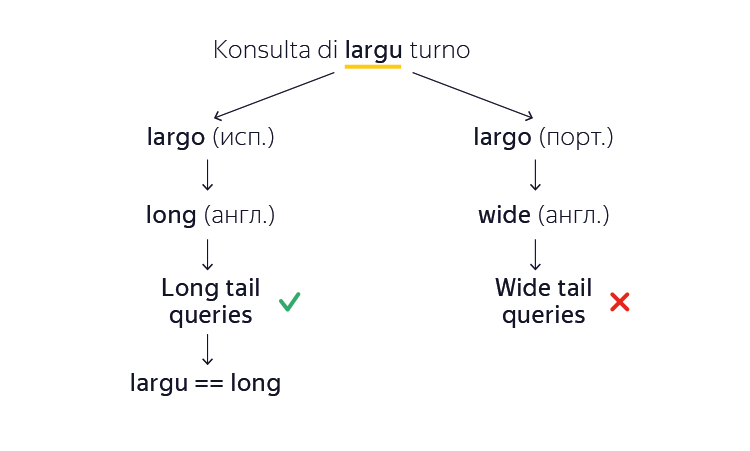
С морфологией стало понятнее, но что делать, если даже начальная форма слова машине еще не известна? Мы помним, что большинство всех слов папьяменто произошло от европейских аналогов. Допустим, что наш автоматический переводчик сталкивается с неизвестным словом «largu» в папьяменто и хочет найти перевод на английский. Машина замечает, что это слово очень похоже на слово «largo» как из испанского, так и из португальского языков. Вот только значения этих слов не совпадают («длинный» и «широкий» соответственно). И на какой язык ориентироваться? Система машинного перевода решает эту проблему следующим образом. Она строит оба варианта перевода, а затем, опираясь на миллионы изученных английских документов, делает вывод, какой из вариантов больше похож на естественный текст. Например, «long tail queries» (длинный хвост запросов) больше похож на правду, чем «wide tail queries» (широкий хвост запросов). Так она запоминает, что в данном конкретном случае слово «largu» произошло из испанского, а не из португальского. И так для большинства неизвестных слов – машина автоматически выучит их без готовых примеров и ручного вмешательства.
В результате, благодаря заимствованиям из более крупных языков, нам удалось построить перевода с/на папьяменто на таком объеме примеров, на которым классический статистический машинный перевод просто не справился бы.
Горномарийский
Другой пример. Мы регулярно добавляем поддержку языков народов России и в какой-то момент дошли до марийского, в котором с самого появления письменности (в XIX веке) различались два литературных варианта: луговой (восточный) и горный (западный). Они отличаются лексически. Тем не менее языки очень похожи и взаимопонимаемы. Первый печатный текст на марийском языке – «Евангелие» 1821 года – был горномарийским. Однако из-за того, что луговых марийцев намного больше, марийским языком «по умолчанию» обычно считается луговой. По этой же причине текстов на луговом марийском гораздо больше, и у нас не возникло проблем с классическим подходом. А вот для горного мы применили нашу технологию с заимствованиями. За основу мы взяли уже готовый луговой вариант, а словарный запас корректировали с помощью существующих словарей. Причем пригодился и русский язык, который за многие годы достаточно сильно повлиял на марийский.
Идиш
Идиш возник в X-XIV веках на основе верхненемецких диалектов — тех же, которые легли в основу современного немецкого языка. Поэтому очень многие слова в идише и немецком одинаковы или очень похожи. Это позволило нам использовать вспомогательные модели лексики и морфологии, собранные по данным для немецкого языка. При этом письменность в идише основана на еврейском алфавите, поэтому для ее моделирования использовался иврит. По нашим оценкам, перевод с/на идиш, дополненный заимствованиями из иврита и немецкого, отличается более высоким качеством в сравнении с классическим подходом.
Эльфийский
В нашей команде любят произведения писателя Толкина, поэтому перевод синдарина (один из языков эльфов Средиземья) был лишь вопросом времени. Как вы понимаете, язык редкий, и его носителей встретить не так уж и легко. Поэтому пришлось обратиться к лингвистическим исследованиям творчества писателя. Сочиняя синдарин, автор основывался на валлийском языке, и в нем есть характерные чередования начальных согласных. Например, «руна» будет «certh», а если перед ним идет определенный артикль, то получится «i gerth». Многие слова при этом заимствовались из ирландского, шотландского и валийского. К счастью, в свое время автор составил не только подробный словарь, но и правила транслитерации слов из существующих языков в синдарин. Всего этого оказалось вполне достаточно для создания переводчика.
Примеры языков, где мы использовали новый подход, можно было бы продолжать. К текущему моменту мы успели успешно применить технологию еще и в башкирском, узбекском, маратхи и непальском. Многие из этих языков даже формально нельзя назвать «малыми», но особенность нашего подхода именно в том и заключается – использовать его можно везде, где явно прослеживаются родственные связи. Для небольших языков он, в принципе, позволяет создать переводчик, для других – поднять планку качества. И это ровно то, чем мы и планируем заниматься в ближайшем будущем.
Комментарии (54)
erwins22
19.12.2016 16:35только мне кажется этот подход проигрывает гугловскому?

malbaron
19.12.2016 16:49+1У Гугля — примерно то же самое. С некоторыми своими нюансами.
erwins22
19.12.2016 17:02насколько я понимаю
«если дополнить сугубо лексическую модель еще и моделями морфологии (словоизменение и словообразование) и синтаксиса (построение предложений)» в гугловском переводчике не используется. он примитивнее, Скорее всего ему требуется существенно больше данных, чем подходу гугла…dvorkjoker
19.12.2016 17:09+4На самом деле, наоборот — при нашем подходе для построения машинного перевода хватает меньшего объёма данных. При этом для компенсации недостающих данных мы научились использовать данные родственных языков.
erwins22
19.12.2016 17:20Извиняюсь, я так и хотел сказать, что Яндексу требуется меньше данных за счет предобработки. Но вы становитесь заложниками такого подхода, правильности определения и т д.
Не пытались использовать SyntaxNet?
Прогоняете SyntaxNet, получаете дополнительную информацию о предложении и обучаете с доп информацией?
кроме единичного вектора слова, еще тип речи, взоимосвязанность и т д
кроме того для языков с падежами можно существенно сократить количество слов за счет передачи именительного падежа и принадлежности слова (кто ему подчинен, кому он подчинен), в принципе можно перестраивать предложение в языково независимую структуру. что должно упростить обучение разных языков.dvorkjoker
19.12.2016 18:34Если Вы говорите про парсинг предложения на малом языке с помощью SyntaxNet — так просто сделать не получится, так как для обучения SyntaxNet требуются составленные лингвистами сложные обучающие данные наподобие Universal Dependencies. Обычно составление таких корпусов занимает многие месяцы и даже годы ручного труда.
erwins22
19.12.2016 19:29- можно попробовать упростить.
есть начальный корпус и множество других предложений.
делаем допустим 5 сетей с разной инициализацией. и обучаем на размеченном корпусе.
далее прогоняем по оставшимся предложениям и там где все 5 сетей разбирают предложение одинаково включаем в обучающую выборку с коэффициентом 0,8 (если например коэффициент обучения 0,0001 то для этих данных будет 0,0001*0,8)
далее повторяем для оставшихся с последовательно убывающими коэффициентами обучения.
или можно сжимать информацию ставя на вход image
eiennohito
19.12.2016 20:11Если бы можно было знать, где сети ошибаются, а где нет, то эта штука помогла бы, но всё немного сложнее. Случаи когда все сети не ошибаются менее интересны, потому что среди уже аннотированных данных достаточно информации для нахождения правильного решения. Случаи когда все сети врут гораздо хуже — они заражают исходные данные, а нейросети сильно чувствительны к плохим аннотированным данным, особенно для языка, где пространство параметров очень разрежено по сравнению с обработкой изображениями.
Подход когда промежуточные результаты, где варианты сетей не сошлись в ответе показывать человеку и использовать проверенные деревья для увеличения примеров будет лучше на мой взгляд.erwins22
19.12.2016 20:32Ваш вариант конечно лучше, но требует вмешательство человека, а это дорого.
я пробовал нечто такое, сработало. Но это была игрушечный пример....
dvorkjoker
19.12.2016 16:58+2Насколько нам известно, Гугл-переводчик не применяет никаких специальных технологий для перевода малых языков. Соответственно, возможности переводить с/на языки, для которых крайне мало данных (например, башкирский, папьяменто, эльфийский) в нём пока что нет.
malbaron
19.12.2016 17:19Башкирский — достаточно много письменных источников имеет
dvorkjoker
19.12.2016 17:24Смотря для каких целей. Для создания системы машинного перевода нужны, во-первых, достаточно специфические данные — параллельные тексты (например тексты с одинаковым содержанием на русском и на башкирском языках). Во-вторых, этих данных требуется много — хотя бы сотни тысяч предложений (в идеале — десятки и сотни миллионов).
malbaron
19.12.2016 18:16Легко.
Государственные документы, например.
Эпосы.
avegorov
19.12.2016 18:32+1Да, тексты есть, и мы их используем. Тем не менее, если сравнивать их количество даже с татарскими, то их на порядок меньше, а это существенно. Кроме того, башкирский язык является агглютинативным, что дополнительно порождает разреженность в данных, с которой мы также вынуждены бороться.
В любом случае, текущая версия не финальная, и мы работаем над её улучшением.

aso
20.12.2016 12:10Художественные тексты, особенно поэтические — крайне плохо подходят для Sequence-to-sequence модели, как мне кажется (если верно высказанное выше утверждение про гугл).
eiennohito
19.12.2016 18:11+1Насколько я знаю, Гугл для языков с очень большим объёмом параллельных текстов использует end-to-end нейросети, в том числе в продакшне. Для большинства обычных — просто статистический подход с самой простой языковой моделью — Stupid Backoff. Хитрые вещи с морфологией они не делают, надеясь на просто языковую модель. Нейросети правда частично решают эту проблему, так как гугловская модель использует не слова, а subword units, что будет приводить к сегментации на что-то, похожее на морфемы, но я подробностей про русский не слышал. Разве что параллельный корпус у них примерно на 0.3B предложений.
aso
20.12.2016 12:03but I think this approach loses link?
Only it seems to me, this approach loses Googley?
(первый — яндекс, второй гугль. ;)


mngr
19.12.2016 16:35Вот вы пишете, что «перевод с/на идиш, дополненный заимствованиями из иврита и немецкого, отличается более высоким качеством в сравнении с классическим подходом».
А как вы измеряете качество перевода?
BarakAdama
19.12.2016 16:51+1Переводы машины сравниваются с переводами людей. Подробнее тут https://en.wikipedia.org/wiki/BLEU

Elanor
19.12.2016 16:35+1Что-то не узнаю язык с синей ногой. Вроде бы и похож на хинди, а вроде бы и так что бы очень (ни буквы, ни расположение)
на хинди было бы ???? ???? ??? — ваша синяя нога
а правильнее
???? ??? ???? ??
istar2metal
19.12.2016 16:49+6А как на эльфийский (и обратно) переводятся подобные вещи? :)

dvorkjoker
19.12.2016 17:03+4Для таких современных слов, конечно же, Профессор Толкиен переводов на эльфийский не придумал, поэтому нам приходится импровизировать :)
В таких случаях мы пытаемся заимствовать слова из кельтских языков — шотландского, ирландского, валлийского. При этом соблюдаем все правила орфографии письменности Тенгвар :)Erelecano
19.12.2016 17:25+4> В таких случаях мы пытаемся заимствовать слова из кельтских языков — шотландского, ирландского, валлийского
Позвольте сказать вам, как автор синдарино-русского словаря(первого достаточно полного, законченного в 2001 году, но так и не изданного), что вы глубоко неправы. Вы сами додумали за автора языка про заимствования и сами пытаетесь их делать. Не надо так. Прежде всего для неосиндарина нужно использовать имеющиеся корни, пример: вам кажется, что в синдарине нет слова «телевизор», но это же не так, ибо «теле» = палан, а «видеть» — тир, таким образом в языке уже есть слово «палантир»(множественное число «палантири») для телевизора, аналогично будет с телефоном, который у нас будет что-нибудь типа palanrhoss(сейчас не уверен, сходу вспомнил rhoss для звука, но может что-то иное, надо заглянуть в словарь, а его вот прямо сейчас под рукой нет, я не за своим компом). Не нужно тащить в язык чужие корни, нужно образовывать из его корней, если нет корней в синдарине смотреть в квэнья, смотреть как слово должно было изменяться при переходе в синдарин и делать из него.
Вы пытаетесь привязать синдарин к земным языкам, потому что вам так удобно, а у Толкина слова в синдарине происходили из квэнья.
Знаете классическую ошибку тех, кто прочитал пару статей и думает, что он разбирается в синдарине? Эта ошибка называется «Ошибка Гэндальфа» и она нам видна в «Lord of the Rings». Когда Митрандир смотрит на ворота Мории он там видит надпись «Pedo mellon a mino», но он не помнит(или не знает, ибо не жил в Смертных Землях), что у синдарина были диалекты. Он рассуждает, что эта надпись значит что если ты друг, то знаешь пароль по той простой причине, что надпись требующая сказать слово друг писалась бы через vellon, а не mellon, он не понимает, что в эрэгионском диалекте правильно так, как написано.
Вот и вы рассуждаете о синдарине не вдаваясь во внутреннюю историю в пределах мира описанного(выдуманного) JRRT. На синдарин внутри мира не могут влиять шотландские, ирландские и прочие японские языки, на синдарин влияют кхуздул и вестрон, синдарин не вышел из шотландского или ирландского, синдарин вышел из квэнья.
menelion_elensule
19.12.2016 18:16+7Извините, но вы не правы по нескольким пунктам. Во-первых, palantir со множественным числом palantiri — это не синдарин, а quenya. В синдарине множественное число образуется умлаутом по особым правилам (aran — erein > erain, toron — toryn > teryn, mellon — mellyn и т.д. См., например, обзор Хельге Фаускангера). Во-вторых, синдарин не происходит от quenya, оба они происходят от протоэльфийского (если быть совсем точным, от протоэльдарского, который, в свою очередь, происходит от протоквендианского, бывшего в ходу в часы Пробуждения у озера Куйвиэнен и породившего также шесть языков авари).
А по теме статьи: почему выбрали именно синдарин? У quenya словарный корпус больше и морфология прописана во многом тщательнее :). Кстати (сам убедиться не могу из-за отсутствия зрения), в сообществе Languages of Middle-Earth говорили, что у вас много где не перевод, а транслитерация английских слов на tengwar. Это правда?)Erelecano
19.12.2016 18:19-10Лень разбирать ваши частичные ошибки, вам и слово «нолдорин» ничего не скажет, вы не поймете влияния языков.
А про транслитерацию у Яндекса это чистая правда. Проверьте сами, тенгвар достаточно прост.menelion_elensule
20.12.2016 02:58+1Мне как раз слово noldorin скажет многое. Точно так же, как и Gnomish, Qenya, Ilkorin и прочие интересные слова. Проверить же Яндекс самостоятельно не могу по уже указанной выше причине. Если вам действительно интересны эти вещи, приходите в Google+-сообщество Languages of Middle Earth.

Acuna
20.12.2016 12:18+1Простите, а что Вы подразумеваете под фразой «сам убедиться не могу из-за отсутствия зрения»?
malbaron
19.12.2016 18:22+2вам кажется, что в синдарине нет слова «телевизор», но это же не так, ибо «теле» = палан, а «видеть» — тир, таким образом в языке уже есть слово «палантир»(множественное число «палантири») для телевизора
Дык Вы, по сути, предлагаете тянуть русский язык в эльфийский.
Пусть даже и разбитый по корням.
А почему тогда, все же, не более близкий к нему валийский?Erelecano
19.12.2016 18:23-3Где я предлагаю тянуть русский?
Далековизор буквально переводится на синдарин. Никакого русского. Прямой перевод.malbaron
19.12.2016 18:33+5А далековизор какое?
;)
Исходное слово нужно откуда-то взять и разбить на корни.
Вы взяли русское. В случае телевизора проблема не видна явно, так как аналогичное есть и английское и немецкое и еще в куче языков. Тут совпало.
Но есть слова, которые серьезно различаются в разных языках.
По вашей же системе получится, что русско-эльфийский перевод и, скажем китайско-эльфийский для одного и того же понятия будут давать разные эльфийские варианты.menelion_elensule
20.12.2016 03:01Вы абсолютно правы. Исландцы, например, почти не используют заимствований. Для слова «телефон» они взяли старое слово, которое означало «нить, верёвка», но которое перестало использоваться в речи уже давно. При этом, как видите, пошли по ассоциации: нить -> провод -> длинные провода -> телефон). Поэтому так трудно и так неоднозначно дело составления словарей для нео-quenya и нео-синдарина.

LSiazsaHrd
19.12.2016 17:08+2Удачи вам в дальнейшем расширении!
Эльфийский есть, чувашского нет :(.dvorkjoker
19.12.2016 17:12+1Спасибо!
Не отчаивайтесь, над чувашским мы работаем :)
А в будущем мы хотим добавить и другие языки народов России.
eiennohito
19.12.2016 17:53А у вас это есть где-нибудь в опубликованное в более подробном виде. Ссылки на arXiv/ACL Anthology были бы хороши.

UncleByte
19.12.2016 19:55+4Яндекс-переводчик прекрасен!
https://translate.yandex.ru/?text=humongous&lang=en-ru
edogs
20.12.2016 02:41+1Как бы это не кончилось по принципу «самосбывающегося пророчества» и не привело к обеднению языков, их искажению и утере особенностей.
Неоднократно уже на разных ресурсах в качестве аргумента «как правильно» видим не отсылки к словарям и/или книгам, а к гугл-транслейту, что характерно, к гугл-транслейту с неправильным и/или неточным переводом.
Чем более мощные будут автопереводчики, тем точнее они будут в целом (но ошибки все же будут), и в то же время детализацию (нюансы) они будут проглатывать всегда.
Люди все больше ориентируясь на автопереводы начнут совершать ошибки и упускать нюансы, но поскольку благодаря автопереводам будут понимаемы — эти ошибки (источник которых в автопереводчике) и отсутствие нюансов (источник которых в автопереводчике) постепенно изменят язык и станут правилом.
Например. Пока, пока яндекс считает кофе мужским родом. Но надолго ли? В разговорной речи он уже официально записан средним родом. В интернете употребление в среднем роде весьма распространено. А ведь яндекс на этом учится. Не получится ли завтра так, что переведет что-нибудь типа «в будующем оплатите за проезд, вообщем извени, надо ложить экспрессо или какое кофе будите, да и надо иметь ввиду выйгрышь»?
Rampages
20.12.2016 08:31Мне кажется, что вы привели так называемые минусы «статистического машинного перевода» (SMT). Прогресс не стоит на месте и машинный перевод не ограничивается одним только SMT.
molnij
20.12.2016 10:32+3Кофе уже давным давно допустимо в среднем роде. В том числе «официально» с 2009 года. Да и в целом — язык развивается, появляются новые слова, новые формы, возможно когда-нибудь, ваша фраза в кавычках станет допустимой нормой, как бы дико это сейчас ни звучало
Опять же, если встанет выбор между детализацией и свободном общении всего человечества, я всеми руками за последнее. В моем представлении это куда большая ценность, чем лингвистическое различение 40 видов снега, по преданию доступного экскимосам. Впрочем, крайне маловероятен жесткий выбор подобного рода — обычно находятся энтузиасты, исследующие и поддерживающие этнические особенности из разных побужденийedogs
20.12.2016 15:07Кофе уже давным давно допустимо в среднем роде. В том числе «официально» с 2009 года
Разумеется, поэтому мы и привели это в пример.
Да и в целом — язык развивается, появляются новые слова, новые формы, возможно когда-нибудь, ваша фраза в кавычках станет допустимой нормой, как бы дико это сейчас ни звучало
Может и станет допустимой нормой, но суть в том — почему это произойдет.
Если это произойдет в ходе естественного общения (образованных) людей — ок, если же это произойдет в ходе ориентации безграмотных людей на автопереводчик который ориентируется на безграмотных людей (а не правила языка) — это не ок.
Идиократию смотрели? Как Вам будущее?
Опять же, если встанет выбор между детализацией и свободном общении всего человечества, я всеми руками за последнее.
А мы все же предпочтем жить в разнообразном мире, там где есть пальмы и клёны, а не только упрощенные деревья без детализации.
Где люди общаются с хорошим словарным запасом выражая нюансы, а не на уровне эллочки людоедки, пусть даже все эллочки могут свободно общаться друг с другом и их это не напрягает.
Интернет и так уже отнял у человечества возможность выражать эмоции, заменив их упрощенным суррогатом ?\_(?)_/?. Теперь автопереводчики лишат нас словарного запаса, корректности языка и его разнообразия?
Реально хотите жить в мире «идиократии»?molnij
21.12.2016 00:48Идиократию не смотрел, занесу в список к просмотру.
Но я не очень понял вашу мысль.
Каким образом интернет отнял у человечества возможность выражать эмоции? К вам лично пришел интернет и отнял эту возможность? Кто вам мешает их выражать доступным для вас образом? Умеете восхитительно обращаться со словами — используйте навык. Не дано, нет времени, нет желания или неуместно — поставьте смайл. Каким образом, развивающиеся уже не первое десятилетие смайлы (что вы очень элегантно показали смайлом из условно «третьего поколения») могут запретить вам что-то делать? Лично я их рассматривал бы как расширение доступного инструментария общения, а не как какой-то запрет или деградацию. И кстати, оцените нюанс, смайлы «из коробки» доступны и относительно идентичны на всех языках.
Английский язык де-факто является общим языком мира и почему-то развивается год от года, а не вырождается в basic english.
Русский язык за время жизни интернета пополнился падонкафским языком, йожиным диалектом и многими другими, прошедшими мимо меня.
И я не могу понять, как вы приходите к мысли, что объединиться могут лишь эллочки-людоедки. Если у умных людей появиться потребность в детализации и нюансах — они найдут способ их выразить. Смайлами, мимикой, жестами, словообразованием, или любым другим доступным способом. Но я уже обозначил свою позицию — лучше пусть десять человек будут свободно общаться на языке, сколь угодно далеком от «корректного», чем это будут пять пар, где каждому человеку будет доступен лишь один собеседник. Это полезнее в любом плане — хоть в бытовом, хоть в общецивилизационном.

domix32
21.12.2016 01:01Но ведь для языков верны и обратные процессы, то бишь усложнение. Да и сомневаюсь что языковая ассимиляция позволит это сделать — слишком легко появляются новые диалекты — опять же усложнение. Поэтому думаю на ваш век сложности хватит.


Andreyjka
20.12.2016 08:53+3Я много перевожу субтитры для индийских фильмов, так вот яндекс словарь самый точный среди всех переводчиков.

pantlmn
20.12.2016 12:56Скажите, а имеющийся у вас инструментарий может помочь в правильном «запараллеливании» корпусов?
Задачка, которая у меня крутится в голове и к которой я пока не знаю, с какого конца подступиться, примерно такова:
Дано:
- Библия и большой слабо размеченный корпус богослужебных текстов на греческом языке.
- Библия и большой слабо размеченный корпус богослужебных текстов на церковнославянском языке.
- Известно, что зачастую перевод — это калька (тот же порядок слов и даже грамматические признаки)
Найти:
- церковнославянско-греческий словарь
- греческо-церковнославянский словарь
- различия между корпусами
fungikingdom
20.12.2016 19:19Пример с Мордором похоже захардкожен, что становится заметно при замене Мордора на другие топонимы.
Похоже, у яндекс переводчика будут проблемы при переводе мемов с Боромиром.
Grom1k
Так вы научили машину самостоятельно создавать переводы для редких языков или нет?
dvorkjoker
Можно сказать, что да :)
На самом деле, точнее будет сказать, что мы научили машину использовать родственные связи между языками для создания переводов для редких языков.